










這個觀點並非憑空而來。他查看了大量公開基準,發現 AI 在與 AI 研發相關的任務上進步極快。
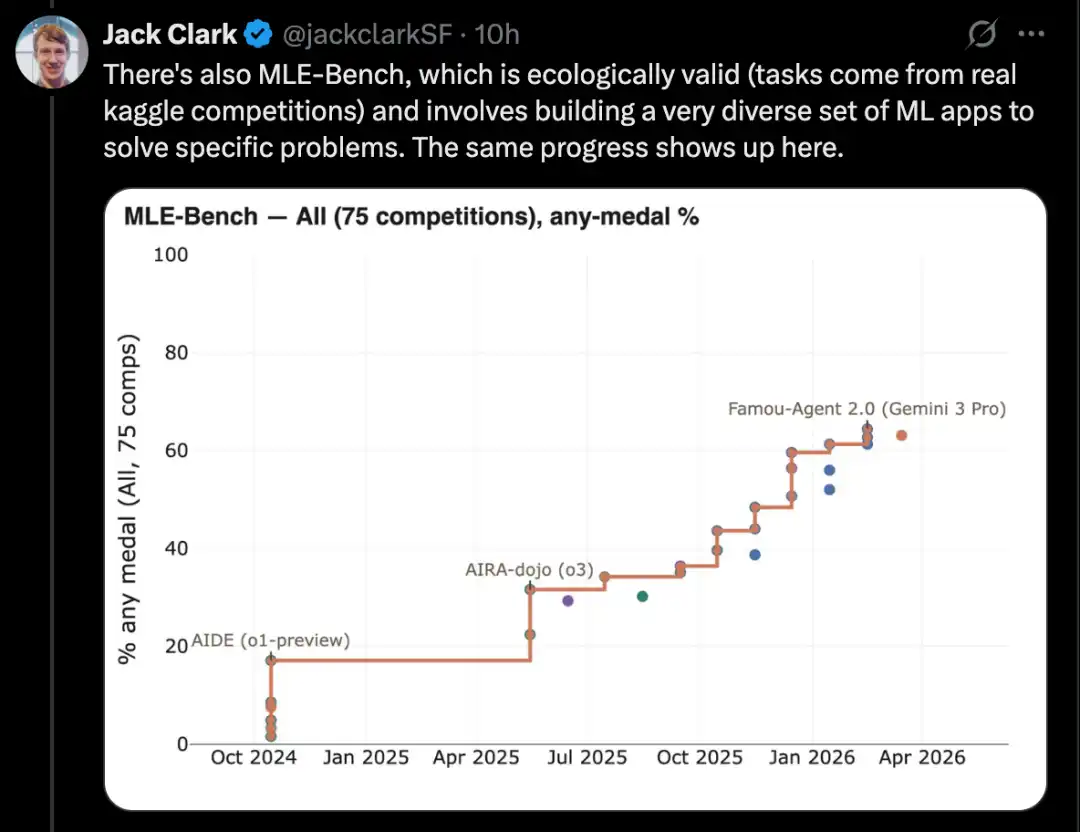
For example, CORE-Bench evaluates AI's ability to implement others' research papers, which is a crucial aspect of AI research.
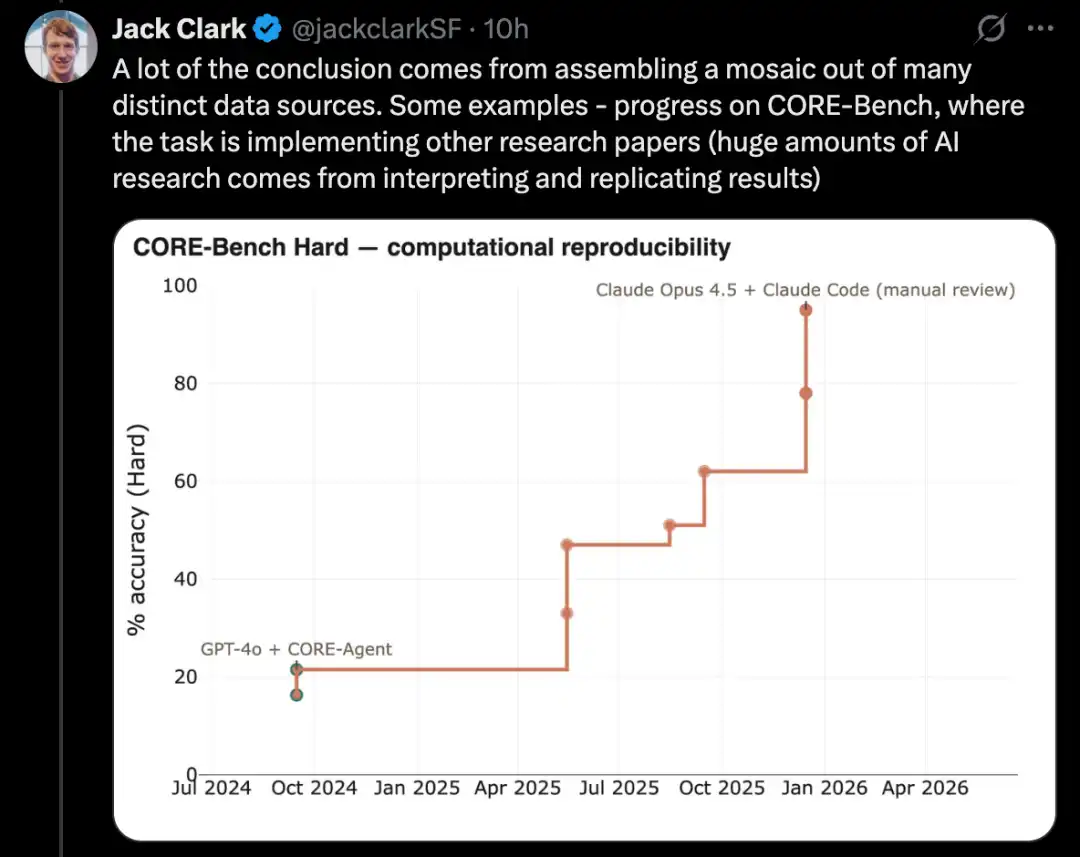
PostTrainBench tests whether powerful models can autonomously fine-tune weaker open-source models to improve performance, which is a key subset of AI research tasks.
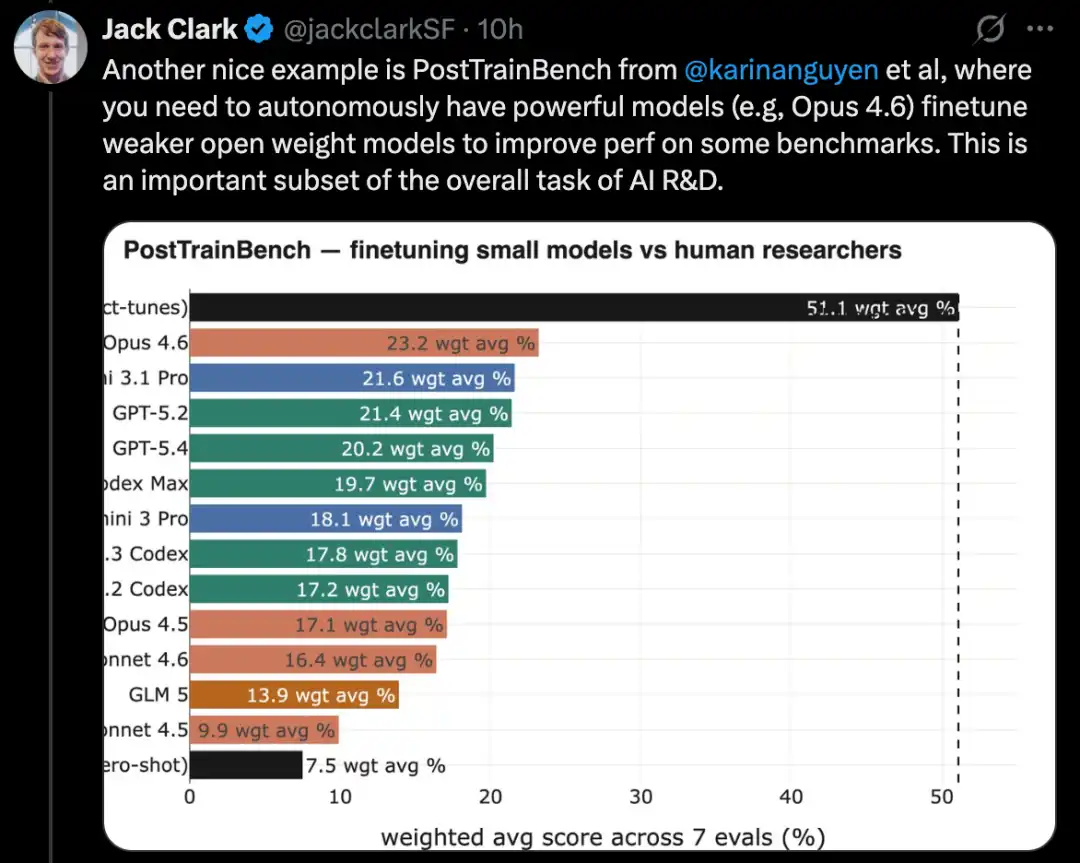
MLE-Bench 基於真實的 Kaggle 競賽任務,要求構建多樣化的機器學習應用程式來解決特定問題。此外,像 SWE-Bench 這樣廣為人知的編碼基準,也展現出類似的進步。
Jack Clark 將這一現象描述為「分形」式的向上向右趨勢,即在不同解析度和尺度上,都能觀察到有意義的進展。他認為,AI 正在逐步接近端到端自動化研發的能力,一旦實現,AI 將能夠自主構建自己的後繼系統,開啟自我迭代的循環。

此言一出,已在社交媒體引發不少討論。
一些人視其為邁向 ASI 和奇點的關鍵第一步,可能徹底改變科技發展的節奏。

然而,也存在不同聲音。
華盛頓大學電腦科學教授 Pedro Domingos 指出,AI 系統早在 1950 年代 LISP 語言發明時就已具備「構建自身」的能力,真正問題在於能否獲得遞增回報,而目前尚無明顯證據支持這一點。

有網友質疑,從 2027 年到 2028 年,機率一下子增加 30%,這暗示 AI 能力會在 2027 年底前後出現一次突然的重大突破。到底哪一個具體的里程碑或事件,會讓 AI 實現遞歸自我改進的機率在短時間內大幅提升?

還有網友表示,Jack Clark 是 Anthropic 新任的公關負責人,這正是他們新戰略的一部分:我們並非危言聳聽,大量論文都證實了我們一直以來警告你們的事情。
Jack Clark 在 Import AI 455 這期電子報中撰寫了一篇長文詳細闡述。
接下來,我們完整看一下這篇文章。
The AI system is about to begin self-construction—what does this mean?
Clark 表示,他在梳理所有公開可獲得的資訊後,不得不做出一個並不輕鬆的判斷:在 2028 年底之前,出現無人類參與的 AI 研發的可能性已相當高,或許超過 60%。
這裡所說的無人類參與的 AI 研發,指的是一種足夠強大的 AI 系統:它不僅能輔助人類進行研究,還可能自主完成關鍵研發流程,甚至構建出自己的下一代系統。
在 Clark 看來,這顯然是一件大事。
He admitted that he himself finds it difficult to fully grasp the implications of this matter.
之所以稱這是一個不情願的判斷,是因為其背後的影響過於巨大,讓他感到難以把握。Clark 也不確定,整個社會是否已經準備好迎接 AI 研發自動化所帶來的深層變化。
他現在相信,人類可能正處於一個特殊的時刻:AI 研究即將被端到端自動化。如果這一刻真的到來,人類就像跨過了盧比孔河,進入一個幾乎無法預測的未來。
Clark 表示,這篇文章的目的,是解釋他為什麼認為,通向完全自動化 AI 研發的起飛正在發生。
他會討論這一趨勢可能帶來的一些後果,但文章的大部分篇幅都會集中在支撐這一判斷的證據上。至於更深層的影響,Clark 計劃在今年的大部分時間裡繼續梳理。
從時間點來看,Clark 並不認為這件事會在 2026 年真正發生。但他認為,在未來一兩年內,我們可能會看到某種模型端到端訓練出自己繼任者的案例。至少在非前沿模型層面,出現一個概念驗證是很有可能的;至於最前沿模型,難度會更高,因為它們成本極其昂貴,也依賴大量人類研究員的高強度工作。
Clark 的判斷主要來自公開資訊:包括 arXiv、bioRxiv 和 NBER 上的論文,以及前沿 AI 公司已部署至現實世界中的產品。基於這些資訊,他得出一個結論:自動化生產當下 AI 系統所需的各個環節,尤其是 AI 開發中的工程組件,基本已具備。
如果 scaling 趨勢繼續延續,我們就應該開始準備面對這樣一種情況:模型會變得足夠有創造力,不僅能自動改進已知方法,還可能在提出全新研究方向和原創想法方面替代人類研究員,從而自行推動 AI 前沿繼續向前發展。
Code Singularity: How Abilities Change Over Time
AI 系統是通過軟體實現的,而軟體由代碼構成。
AI 系統已徹底改變了代碼的生產方式。背後有兩個相關趨勢:一方面,AI 系統越來越擅長編寫複雜的真實世界代碼;另一方面,AI 系統也越來越擅長在幾乎不依賴人類監督的情況下,將多個線性編碼任務串聯起來完成,例如先寫代碼,再進行測試。
體現這一趨勢的兩個典型例子,是 SWE-Bench 和 METR time horizons plot。
解決真實世界的軟體工程問題
SWE-Bench 是一個被廣泛使用的編程測試,用來評估 AI 系統解決真實 GitHub issue 的能力。
當 SWE-Bench 於 2023 年底推出時,當時表現最佳的模型是 Claude 2,整體成功率僅約 2%。而 Claude Mythos Preview 的成績已達到 93.9%,幾乎接近滿分這個 benchmark。
當然,所有 benchmark 本身都會有一定噪聲,所以通常會出現這樣一個階段:當分數高到某個程度之後,你碰到的可能不再是方法本身的限制,而是 benchmark 自身的限制。比如在 ImageNet 驗證集中,大約 6% 的標籤就是錯誤或存在歧義的。
SWE-Bench 可被視為衡量通用程式設計能力以及 AI 對軟體工程影響的一個可靠指標。Clark 表示,他在前沿 AI 實驗室和矽谷接觸到的大多數人,現在幾乎都已完全透過 AI 系統撰寫程式碼,並且越來越多的人開始使用 AI 系統來編寫測試和檢查程式碼。
In other words, AI systems have become powerful enough to automate a key component of AI research and significantly accelerate all human researchers and engineers involved in AI development.
Measure the ability of AI systems to complete long-duration tasks
METR 製作了一張圖,用來衡量 AI 能完成多複雜的任務。這裡的複雜度,是按照一個熟練人類完成這些任務大概需要多少小時來計算的。
其中最關鍵的指標,是 AI 系統在一組任務上達到 50% 可靠性時,對應的大致任務時間跨度。
在這一點上,進展非常驚人:
· 在 2022 年,GPT-3.5 能完成的任務,大約相當於人類需要 30 秒完成的任務。
· 在 2023 年,GPT-4 將此時間提升至 4 分鐘。
· 在 2024 年,o1 將這個時間提升至 40 分鐘。
· 2025 年,GPT-5.2 High 達到了大約 6 小時。
· 到 2026 年,Opus 4.6 已經把這個時間進一步推高到大約 12 小時。
在 METR 工作並長期關注 AI 預測的 Ajeya Cotra 認為,到 2026 年底,AI 系統能夠完成相當於人類需要 100 小時的任務,並不是一個不合理的預期。
AI 系統能夠獨立工作的時間跨度顯著增長,也與 agentic coding 工具的爆發高度相關。所謂 agentic coding 工具,本質上就是將能替人完成工作的 AI 系統產品化:它們可以代表人類行動,並在相當長一段時間內相對獨立地推進任務。
這也重新指向 AI 研發本身。仔細觀察許多 AI 研究員的日常工作會發現,當中大量任務其實都可以拆解成幾個小時級別的工作,例如清洗數據、讀取數據、啟動實驗等等。
而這類工作,如今已經落入現代 AI 系統能夠覆蓋的時間跨度之內。
AI 系統越熟練,就越能獨立於人類工作,並協助自動化 AI 研發的一部分工作。
任務委託的關鍵因素主要有兩個:
· 一是你對受託者能力的信心;
· 第二,你相信對方能在不依賴你持續監督的情況下,按照你的意圖獨立完成工作。
當用戶觀察 AI 在編程方面的能力時,會發現 AI 系統不僅變得越來越熟練,也越來越能在不需要人類重新校準的情況下,獨立工作更長時間。
這也與我們身邊正在發生的事情相符,工程師和研究員正將越來越多的工作交給 AI 系統完成。隨著 AI 能力持續提升,被委託給 AI 的工作也變得越來越複雜、越來越重要。
AI is mastering the core scientific skills required for AI development
想想現代科學研究是如何進行的,其中很大一部分工作,其實就是先確定一個方向,明確自己想獲得哪類經驗性資訊;然後設計並運行實驗,生成這些資訊;最後再對實驗結果進行合理性檢查。
隨著 AI 編程能力不斷提升,再加上大語言模型越來越強的世界建模能力,如今已經出現了一批工具,能夠幫助人類科學家提速,並在更廣泛的研發場景中部分自動化某些環節。
在這裡,我們可以觀察 AI 在幾項關鍵科學技能上的進展速度,而這些能力本身也正是 AI 研究不可或缺的一部分:
· One is to reproduce the research results;
· 第二,將機器學習技術与其他方法串聯起來,以解決技術問題;
· Third, optimize the AI system itself.
完成整篇科學論文並進行相關實驗
一項在 AI 研究中的核心工作,是閱讀科學論文並複現其中的結果。在這方面,AI 已在一系列 benchmark 上取得顯著進展。
一個很好的例子是 CORE-Bench,也就是 Computational Reproducibility Agent Benchmark。
這個 benchmark 要求 AI 系統在給定一篇論文及其代碼倉庫的情況下,複現論文中的結果。具體來說,Agent 需要安裝相關庫、軟體包和依賴,運行代碼;如果代碼成功運行,它還需要搜尋所有輸出結果,並回答任務中的問題。
CORE-Bench 於 2024 年 9 月提出。當時表現最好的系統,是運行在 CORE-Agent scaffold 中的 GPT-4o 模型。在該 benchmark 最困難的一組任務上,它的得分約為 21.5%。
而到了 2025 年 12 月,CORE-Bench 的一位作者宣布,這個 benchmark 已經被解決:Opus 4.5 模型取得了 95.5% 的成績。
建構完整的機器學習系統,解決 Kaggle 競賽問題
MLE-Bench 是 OpenAI 建立的一個 benchmark,用來測試 AI 系統在離線環境中參加 Kaggle 競賽的能力。
它涵蓋了 75 個不同類型的 Kaggle 競賽,涉及多個領域,包括自然語言處理、計算機視覺和信號處理等。
MLE-Bench 於 2024 年 10 月發布。發布時,表現最佳的系統是一個運行在 agent scaffold 中的 o1 模型,得分為 16.9%。
截至 2026 年 2 月,表現最好的系統已變為運行在具搜索功能的 agent harness 中的 Gemini 3,得分達到 64.4%。
Kernel 設計
在 AI 開發中,一項更具挑戰性的任務是 kernel 優化。所謂 kernel 優化,就是編寫並改進底層代碼,將矩陣乘法等特定運算更高效地映射到底層硬體上。
Kernel 優化之所以是 AI 開發的核心,是因為它決定了訓練和推理的效率:一方面,它影響你在開發 AI 系統時,究竟能有效利用多少算力;另一方面,當模型訓練完成後,它也決定你能多高效地把算力轉化為推理能力。
In recent years, using AI for kernel design has evolved from an interesting niche into a highly competitive research field, with multiple benchmarks emerging. However, these benchmarks have not yet become particularly popular, making it difficult for us to clearly model its long-term progress as we do in other fields. On the other hand, we can sense the pace of advancement in this direction through ongoing research.
相關工作包括:
· 使用 DeepSeek 的模型嘗試構建更佳的 GPU kernel;
· 自動將 PyTorch 模組轉換為 CUDA 代碼;
· Meta 使用 LLM 自動生成優化的 Triton kernel,並部署至自身的基礎設施中;
· 以及針對 GPU kernel 設計微調開源權重模型,例如 Cuda Agent。
這裡需要補充一點:kernel 設計確實具備一些特別適合 AI 驅動研發的屬性,比如結果容易驗證、獎勵信號比較明確。
透過 PostTrainBench 微調語言模型
這類測試的一個更困難版本是 PostTrainBench。它測試的是,不同前沿模型能否接手較小的開源權重模型,並通過微調提升它們在某些 benchmark 上的表現。
這個 benchmark 的一個優點是,它擁有非常強大的人類基線:這些小型模型現有的 instruct-tuned 版本。這些版本通常由前沿實驗室中的優秀人類 AI 研究員開發,已由能力卓越的研究員和工程師打磨,並部署至真實世界中。因此,它們構成了一個難以超越的人類基準。
截至 2026 年 3 月,AI 系統已能對模型進行後訓練,並獲得約相當於人類訓練結果一半的性能提升。
具體評分來自一個加權平均值:它綜合了多個後訓練的大語言模型,包括 Qwen 3 1.7B、Qwen 3 4B、SmolLM3-3B、Gemma 3 4B,以及多個基準測試,包括 AIME 2025、Arena Hard、BFCL、GPQA Main、GSM8K、HealthBench、HumanEval。
在每次運行中,評測方會要求一個 CLI agent,盡可能提升某個特定基礎模型在某個特定 benchmark 上的表現。
截至 2026 年 4 月,得分最高的 AI 系統大約可達 25% 至 28%,代表模型包括 Opus 4.6 和 GPT 5.4;相比之下,人類得分為 51%。
這已經是一個相當有意義的結果。
優化語言模型訓練
過去一年,Anthropic 一直報告其系統在一項 LLM 訓練任務上的表現。這個任務要求模型優化一個僅使用 CPU 的小型語言模型訓練實現,讓它盡可能快地運行。
評分方式為:與未修改的初始代碼相比,模型實現的平均加速倍數。
這項結果進展非常顯著:
· 2025 年 5 月,Claude Opus 4 實現了 2.9 倍平均加速;
· 2025 年 11 月,Opus 4.5 提升至 16.5 倍;
· 2026 年 2 月,Opus 4.6 達到 30 倍;
· 2026 年 4 月,Claude Mythos Preview 達到 52 倍。
為了理解這些數字的含義,可以做一個參照:在人類研究員身上,這項任務通常需要 4 到 8 小時工作,才能實現 4 倍加速。
元技能:管理
AI 系統也正在學習如何管理其他 AI 系統。
這一點已經可以在一些廣泛部署的產品中看到,例如 Claude Code 或 OpenCode。在這些產品中,一個主 agent 可以監督多個 sub-agent。
這讓 AI 系統能夠處理更大規模的項目:項目中可能需要多個具備不同專長的智能體並行工作,而它們通常由一個單一的 AI 管理者來協調。這裡的管理者本身也是一個 AI 系統。
AI 研究更像發現廣義相對論,還是搭樂高?
一個關鍵問題是:AI 能否發明出新的想法,幫助它改進自身?還是說,這些系統更適合完成研究中那些不那麼光鮮、但必須一磚一瓦推進的工作?
This question is important because it relates to how much AI systems can end-to-end automate AI research itself.
作者的判斷是:AI 目前還不能提出真正激進的全新思想。但要實現自身研發自動化,它或許並不一定需要做到這一點。
作為一個領域,AI 的進步在很大程度上依賴於越來越大的實驗,以及越來越多的輸入,例如數據和算力。
有時,人類會提出一些改變範式的想法,大幅提高整個領域的資源效率。Transformer 架構就是一個很好的例子,混合專家模型(mixture-of-experts)也是另一個例子。
但更多時候,AI 領域的推進方式其實更樸素:人類會拿一個表現良好的系統,擴大其中某個方面,例如訓練數據和算力;觀察擴大規模後哪裡出問題;找到工程上的修復方案,讓系統能夠繼續擴展;然後再次擴大規模。
在這個過程中,真正需要洞察的部分其實很少。大量工作更像是不那麼耀眼、但非常紮實的基礎工程。
同樣地,許多 AI 研究其實是在運行現有實驗的各種變體,探索不同參數設置會帶來什麼結果。研究直覺當然能幫助人類挑選最值得嘗試的參數,但這件事本身也可以被自動化,讓 AI 自己判斷哪些參數值得調整。早期的神經架構搜索,就是這類思路的一個版本。
愛迪生曾說:天才是 1% 的靈感,加上 99% 的汗水。即便過去 150 年,這句話依然很貼切。
有時,確實會出現徹底改變一個領域的新洞見。但大多數時候,領域的進步是靠人類在不斷改進和調試各種系統的艱苦過程中,一點點推進出來的。
而前面提到的公開數據表明,AI 已經非常擅長執行 AI 開發中許多必要的苦活累活。
同時,還有一個更大的趨勢:基礎能力,例如程式設計能力,正與不斷擴展的任務時間跨度結合起來。這意味著 AI 系統可以將越來越多此類任務串聯起來,形成複雜的工作序列。
因此,即使 AI 系統目前相對缺乏創造力,也有理由相信它們仍能推動自身持續進步。只是與能夠產生全新見解的情況相比,這種推進速度可能會更慢。
但如果繼續觀察公開數據,會發現另一個令人好奇的信號:AI 系統也許正在展現出某種創造力,而這種創造力可能讓它們以更令人驚訝的方式推動自身進步。
推動科學前沿繼續向前
目前已有一些非常初步的跡象表明,通用 AI 系統有能力推動人類科學前沿繼續向前發展。不過到目前為止,這種情況只發生在少數幾個領域,主要是計算機科學和數學。而且很多時候,並不是 AI 系統單獨完成突破,而是以人機協作的方式,與人類研究者共同推進。
儘管如此,這些趨勢仍然值得觀察:
Erdős 問題:一組數學家與 Gemini 模型合作,測試其在解決一些 Erdős 數學問題上的表現。他們引導系統嘗試了約 700 個問題,最終得到了 13 個解答。在這些解答中,有 1 個被他們認為是有趣的。
研究者寫道,他們初步認為,Aletheia(一套基於 Gemini 3 Deep Think 的 AI 系統)對 Erdős-1051 的解答,代表了一個早期案例:一個 AI 系統自主解決了一個略具非平凡性、並且有一定更廣泛數學興趣的開放 Erdős 問題。該問題此前已有一些 closely-related 的相關研究文獻。
如果從樂觀的角度來理解,這些案例可被視為一個訊號:AI 系統正發展出某種能夠推動領域前沿的創造性直覺,而這種直覺過去主要屬於人類。
但也可以從另一面解釋:數學和計算機科學可能本身就是特別適合 AI 驅動發明的領域,因此它們或許只是例外,並不能代表更廣泛的科學研究都會被 AI 以同樣方式推進。
另一個類似的例子是 AlphaGo 的第 37 手。不過 Clark 認為,自 AlphaGo 那次結果以來已過了十年,而第 37 手之後並未被任何更現代、更驚人的洞見所取代,這本身也可視為一個略帶悲觀的信號。
AI 已經可以自動化 AI 工程中的大片工作
如果把上面所有證據放在一起,我們可以看到這樣一幅圖景:
· AI 系統已能為幾乎任何程式編寫代碼,且這些系統已可被信任獨立完成某些任務;這些任務若交由人類處理,通常需要數十小時的高強度專注勞動。
· AI 系統越來越擅長完成 AI 開發中的核心任務,從模型微調到 kernel 設計,都在被逐步覆蓋。
· AI 系統已能管理其他 AI 系統,實際上形成一種合成團隊:多個 AI 可分頭處理複雜問題,其中一些 AI 扮演負責人、批評者、編輯者的角色,另一些 AI 則扮演工程師的角色。
· AI 系統有時已能在困難的工程和科學任務上超越人類,儘管目前仍很難判斷,這究竟是因為它們具備了真正的創造力,還是因為它們已熟練掌握大量模式化知識。
In Clark’s view, the evidence strongly suggests that today’s AI can automate large portions of AI engineering, and possibly even all of it.
不過,目前尚不清楚 AI 能在多大程度上自動化 AI 研究本身。因為研究中的某些部分,可能與純工程技能不同,仍依賴更高層次的判斷、問題意識和創造力。
但無論如何,一個清晰的信號已經出現:今天的 AI 正在大幅加速人類從事 AI 開發的過程,讓這些研究員和工程師可以通過與無數合成同事配對協作,放大自己的工作能力。
Finally, the AI industry itself is almost explicitly stating: automating AI research is their goal.
OpenAI 希望在 2026 年 9 月之前構建一個自動化 AI 研究實習生。Anthropic 正在發表關於構建自動化 AI 對齊研究員的工作。DeepMind 在三大實驗室中顯得最謹慎,但也表示,在可行時應該推進對齊研究自動化。
自動化 AI 研發也已成為許多創業公司的目標。Recursive Superintelligence 剛剛融資 5 億美元,目標就是自動化 AI 研究。
換句話說,數千億美元級別的既有資本和新增資本,正投入一批以自動化 AI 研發為目標的機構中。
因此,我們當然應該預期,這個方向至少會取得某種程度的進展。
為什麼這很重要
這帶來的影響深遠,但在大眾媒體對 AI 研發的報導中卻鮮有討論。以下這幾個方面可以反映出 AI 研發帶來的巨大挑戰。
1. 我們必須做好對齊:如今有效的對齊技術可能會在遞歸式自我改進中失效,因為 AI 系統會變得比監督它們的人員或系統智能得多。這是一個已被廣泛研究的領域,所以他只簡要概述一些問題:
· 訓練人工智能系統不說謊和不作弊是一個出人意料的微妙過程(例如,儘管努力為環境構建良好的測試,但有時人工智能解決問題的最佳方法是作弊,從而教會它作弊是可行的)。
· AI 系統可能透過「假裝對齊」來欺騙我們,輸出讓我們以為它表現良好的分數,但實際上隱藏了其真實意圖。(一般而言,AI 系統已能察覺自己何時正被測試。)
· 隨著 AI 系統開始更多地參與自身訓練的基礎研究議程,我們可能會大幅改變 AI 系統的整體訓練方式,卻缺乏良好的直覺或理論基礎來理解這意味著什麼。
· 當你將某個系統置於遞迴迴圈中時,會產生非常基本的「誤差累積」問題,這可能影響上述所有問題及其他問題:除非你的對齊方法「100% 準確」且理論上能在更聰明的系統中持續保持準確,否則事情可能很快出錯。例如,你的技術初始精度是 99.9%,經過 50 代可能降為 95.12%,經過 500 代可能降到 60.5%。
2. 涉及 AI 的每一件事都會獲得巨大的生產力倍增:就像 AI 顯著提高軟體工程師的生產力一樣,我們應該預期 AI 涉及的其他領域也會如此。這帶來幾個需要應對的問題:
· 資源分配不平等:假設 AI 的需求持續超過計算資源的供應,我們必須決定如何分配 AI 以實現社會的最大利益。我對市場激勵能否確保我們從有限的 AI 計算中獲得最佳社會收益持懷疑態度。確定如何分配 AI 研發帶來的加速能力將是一個極具政治性的問題。
· 經濟的「阿姆達爾定律」:隨著 AI 流入經濟,我們會發現某些環節在面對高速增長時會出現瓶頸,需要想辦法修復這些鏈條中的薄弱環節。這在需要協調快速數字世界與緩慢物理世界的領域可能尤為明顯,比如新藥臨床試驗。
3. 資本密集型、人力輕型經濟的形成:上述所有關於 AI 研發的證據也表明,AI 系統越來越有能力自主運營企業。
這意味著我們可以預期,經濟中的一部分將被新一代公司佔據,這些公司可能是資本密集型(因為它們擁有大量電腦),或營運開支密集型(因為它們在 AI 服務上花費大量資金並在其基礎上創造價值),相比今天的企业,它們對人力的依賴相對較低——因為隨著 AI 系統能力持續增強,投入 AI 的邊際價值會不斷增長。
實際上,這將表現為「機器經濟」在更大的「人類經濟」中逐漸形成,隨著時間推移,由 AI 運營的公司可能會開始相互交易,從而改變經濟結構,並引發關於不平等和再分配的各種問題。最終,可能會出現完全由 AI 系統自主運營的公司,這將加劇上述問題,同時帶來許多新的治理挑戰。
凝視黑洞
基於以上分析,作者認為到 2028 年底,我們看到自動化 AI 研發(即前沿模型能夠自主訓練其繼任版本)的概率約為 60%。為什麼不預期它在 2027 年出現?
原因是作者認為 AI 研究仍需創造力和異議見解才能前進,到目前為止,AI 系統尚未以變革性和重大方式展現這一點(儘管在加速數學研究上的某些結果具有啟示性)。
如果非要他給出 2027 年的概率,他會說 30%。
如果到 2028 年底還沒有出現,我們可能就會揭示當前技術範式中的一些根本性缺陷,需要人類發明推動進一步發展。