










原文作者:Jtsong.eth (Ø,G)(@Jtsong2)
近期加密投資研究智庫 @MessariCrypto 發表了一篇關於0G的綜合深度研究報告,本文是中文精華總結版:
【重點摘要】
隨著 2026 年去中心化人工智能(DeAI)賽道的爆發,零重力 以顛覆性的技術架構,徹底解決了 Web3 無法承載大規模 AI 模型的歷史難題。其核心殺手锏可歸納為:
極速效能引擎(50 Gbps 吞吐量)透過邏輯解耦與多級並行分片,0G 實現了相比於傳統 DA 層(如以太坊、Celestia)超過 60萬倍 的性能突破,成為全球唯一能支援 DeepSeek V3 等超大規模模型即時分發的協議。
dAIOS 模組化架構首創「結算、存儲、數據可用性(DA)、計算」四層協同的操作系統範式,打破傳統區塊鏈的「存儲赤字」與「計算滯後」,實現 AI 數據流與執行流的高效閉環。
AI 原生可信環境(TEE + PoRA)0G 通過可信執行環境(TEE)與隨機訪問證明(PoRA)的深度整合,不但解決了海量數據的「熱存儲」需求,更建立了一個無需信任、保障私隱的人工智能推理與訓練環境,實現從「賬本」到「數碼生命基礎」的飛躍。
第一章 宏觀背景:AI 與 Web3 的「解耦與重構」
在人工智慧邁入大模型時代的背景下,數據、演算法與算力已成為核心生產要素。然而,現有的傳統區塊鏈基礎設施(如以太坊、Solana)在承載人工智慧應用時,正面臨嚴峻的「效能不匹配」問題。
1. 傳統區塊鏈的局限性:吞吐量與儲存的瓶頸
傳統的 Layer 1 區塊鏈設計初衷是處理金融帳本交易,而非承載 TB 級別的人工智能訓練數據集或高頻的模型推理任務。
儲存赤字以太坊等區塊鏈的數據存儲成本極高,且缺乏對非結構化大數據(如模型權重文件、視頻數據集)的原生支持。
吞吐量瓶頸以太坊的資料可用性(DA)頻寬僅約 80KB/s,即使經過 EIP-4844 升級,也遠遠無法滿足大型語言模型(LLM)實時推理所需的 GB 級吞吐需求。
計算滯後AI推理需要極低的延遲(毫秒級),而區塊鏈的共識機制通常以秒為單位,導致「鏈上AI」在現有架構下幾乎不可行。
2. 0G 的核心使命:打破「數據牆」
現時人工智慧行業被中心化巨頭壟斷,形成了事實上的「數據牆(Data Wall)」,導致數據私隱受限制、模型輸出無法驗證,而且租用成本高昂。零重力 的出現,標誌著 AI 與 Web3 的深度重構。它不再僅僅將區塊鏈視作一個存儲哈希值的賬本,而是透過模組化架構將 AI 所需的「數據流、存儲流、計算流」進行解耦。0G 的核心使命是打破中心化黑箱,通過去中心化技術讓 AI 資產(數據和模型)成為主權可擁有的公共商品。
在理解了這種宏觀錯位後,我們需要深入剖析 0G 如何透過一套嚴謹的四層架構,逐一解決這些零散的痛點。
第二章 核心架構:模組化 0G Stack 的四層協同
0G 不只是單一的區塊鏈,而是被定義為 dAIOS(去中心化人工智能作業系統)這個概念的核心在於,它為AI開發者提供了一個類似操作系統的完整協議堆疊,通過四層架構的深度協同,實現了性能的指數級躍升。
1. dAIOS 的四層架構解析
0G Stack 通過將執行、共識、存儲與計算分離,確保每一層都能獨立擴展:

2. 0G 鏡鏈:以 CometBFT 為基礎的效能底層
作為 dAIOS 的神經中樞,0G 鏡鏈 採用了高度優化的 CometBFT 共識機制。其創新之處在於將執行層與共識層分離,並通過流水線並行處理(Pipelining)和 ABCI 模組化設計,大幅縮減區塊生產的等待時間。 效能指標根據最新基準測試,0G Chain 在單一分片下可實現 11,000+ 每秒交易量 的吞吐量,並具備亞秒級(Sub-second)的最終確認性。這種極高性能確保了在大規模 AI 代理(AI Agents)高頻互動時,鏈上結算不會成為瓶頸。
3. 0G 儲存與 0G DA 的解耦協同
0G 的技術護城河在於其「雙通道」設計,將數據發佈與永久存儲分離:
0G DA專注於 Blob 數據的快速廣播與採樣驗證。它支援單一 Blob 最高約 32.5 MB,透過擦除碼(Erasure Coding)技術,即使部分節點離線,也能確保數據可用。
0G 儲存空間透過「日誌層(Log Layer)」處理不可變數據,透過「鍵值層(KV Layer)」處理動態狀態。
這種四層協同架構為高性能 DA 層提供了成長的土壤,接下來我們將深入探討 0G 核心引擎中最具震撼力的部分——高性能 DA 技術。
第三章 高效能 DA 層(0G DA)的技術深潛
在 2026 年的去中心化人工智慧生態中,數據可用性(DA)不僅僅是「發布證明」,更必須承載 PB 級人工智慧權重文件與訓練集的即時管道。
3.1 邏輯解耦與物理協同:「雙通道」架構的世代演進
0G DA 的核心優越性源於其獨特的「雙通道」架構:將數據發佈(Data Publishing)與數據存儲(Data Storage)在邏輯上徹底解耦,但在物理節點層面實現高效協同。
邏輯解耦與傳統 DA 層將數據發佈與長期存儲混為一談不同,0G DA 僅負責驗證數據塊在短時間內的可訪問性,而將海量數據的持久化交由 0G Storage 處理。
物理協同:儲存節點使用情況隨機訪問證明(PoRA)確保數據真實存在,而 DA 節點則通過基於分片的共識網絡確保透明度,實現了「即發即驗、存驗一體」。
3.2 性能指標:規模領先的數據對決
0G DA 在吞吐量上的突破,直接定義了去中心化 AI 操作系統的性能邊界。下表展示了 0G 與主流 DA 方案的技術參數對比:
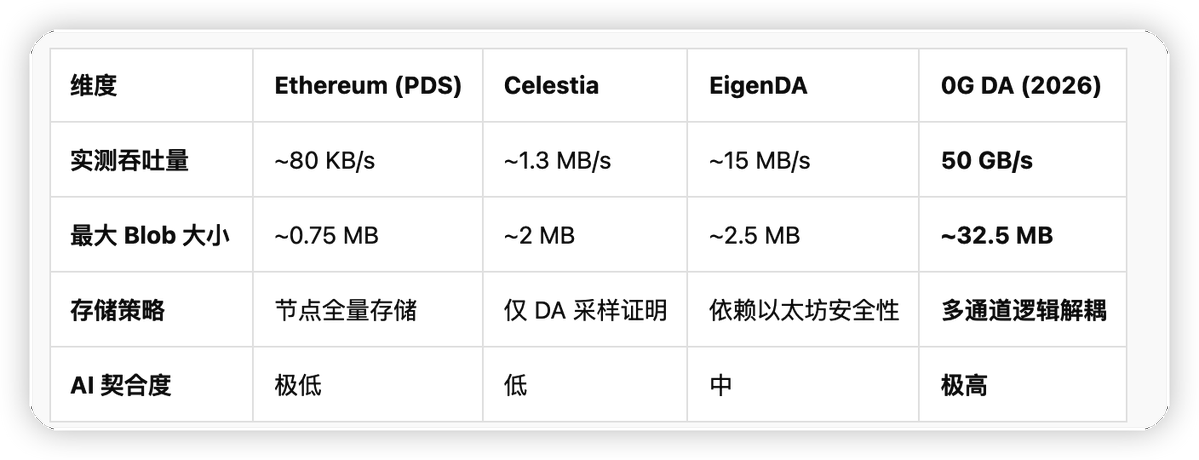
3.3 實時可用性的技術基礎:糾刪碼與多共識分片
為了支援龐大的 AI 數據,0G 引入了擦除編碼(Erasure Coding)與多重共識分片(Multi-sharding):
優化Erasure Code即使網絡中大量節點離線,通過增加冗餘證明,仍可透過採樣極小的數據片段來恢復完整資訊。
多共識分片:0G 摒棄了單條鏈處理所有 DA 的線性邏輯。透過橫向擴展共識網絡,使總吞吐量隨節點數量增加而線性增長在 2026 年的實測中,支撐了每秒數萬次的 Blob 驗證請求,確保了 AI 訓練流程的連續性。
單單擁有高速數據通道是不夠的,AI 還需要一個低延遲的「大腦存儲」和保障私隱的「運行空間」,這就引出了 AI 專用優化層。
第四章 AI 專用優化與安全算力增強
4.1 解決 AI 代理(AI Agents)的延誤焦慮
對實時執行策略的AI代理而言,數據讀取延遲是決定其存亡的關鍵。
冷熱數據分離架構0G 儲存 內部劃分為不變日誌層(Log Layer)與可變狀態層(KV Layer)熱數據存於高性能 KV 層,支援亞秒級隨機存取。
高效益索引協議透過分布式哈希表(DHT)與專用的元數據索引節點,AI 代理能夠在毫秒級別內定位所需的模型參數。
4.2 TEE 增強:構建無需信任的人工智慧的最後一塊拼圖
0G 於 2026 年全面推出 TEE(可信執行環境) 安全升級。
計算私隱化模型權重與用戶輸入在 TEE 內部的「隔離區」處理。即使節點運營商亦無法窺視運算過程。
結果可驗證性由 TEE 產生的遠程靜默證明(Remote Attestation)會與計算結果一同提交至 0G Chain,確保結果由特定的未篡改模型產生。
4.3 實現願景:從儲存到操作系統的躍進
AI代理不再只是孤立的腳本,而是擁有主權身份(iNFT 標準)受保護記憶(0G 儲存)與可驗證邏輯(TEE Compute)的數碼生命實體。這種閉環消除了雲廠商對 AI 的壟斷,標誌著去中心化 AI 進入大規模商業應用時代。
然而,要承載這些「數字生命」,底層的分布式存儲必須經歷一場從「冷」到「熱」的性能革命。
第五章 分散式存儲層的創新——從「冷存檔」到「熱性能」的範式革命
0G Storage 的核心創新在於打破了傳統分布式存儲在性能上的束縛。
1. 雙層架構:Log Layer 與 KV Layer 的解耦
日誌層(流數據處理)專為非結構化數據(如訓練日誌、數據集)而設計。通過只追加寫入(Append-only)模式,確保海量數據在分布式節點之間實現毫秒級同步。
KV Layer(索引與狀態管理)針對結構化數據,提供高性能索引支援。在調用模型參數權重(Weights)時,將響應延遲壓低至毫秒級。
2. PoRA(隨機存取證明):抵禦 Sybil 攻擊與驗證體系
為了確保存儲的真實性,0G 引入了 PoRA(隨機訪問證明)。
反女巫攻擊PoRA 將採礦難度與實際佔用的物理存儲空間直接掛鉤。
可驗證性:允許網絡對節點進行隨機「抽查」,確保數據不僅被儲存,而且處於「隨時可用」的熱活躍狀態。
3. 性能突破:秒級檢索的工程實現
0G 通過將擦除編碼與高頻寬 DA 通道結合,實現了從「分鐘級」到「秒級」的檢索跨越。這種「熱儲存」能力,性能足以媲美中心化雲服務。
這種存儲性能的飛躍,為支撐百億級參數的模型提供了堅實的去中心化基礎。
第六章 AI 原生支援——百億級參數模型的去中心化基礎
1. AI 對齊節點:AI 工作流程的守護者
AI 對齊節點 監控存儲節點與服務節點之間的協作。通過對訓練任務真實性驗證,確保 AI 模型運行不偏離預設邏輯。
2. 支援大規模並行 I/O
處理擁有數十億甚至數千億參數的模型(例如 Llama 3 或 DeepSeek-V3)需要極高的並行 I/O。0G 通過數據切片與多共識分片技術,允許數千個節點同時處理大規模數據集的讀取。
3. 檢查點(Checkpoints)與高頻寬 DA 的協同
故障復原:0G 可以迅速將百GB級的檢查點文件持久化。
無感復原得益於 50 Gbps 吞吐上限,新節點可以即時從 DA 層同步最新的檢查點快照,解決了去中心化大模型訓練難以長期維持的痛點。
除了技術細節之外,我們必須把視野擴展至整個行業,看看 0G 是如何席捲現有市場的。
第七章 競爭格局——0G 的維度碾壓與差異化優勢
7.1 主流 DA 方案的橫向測評
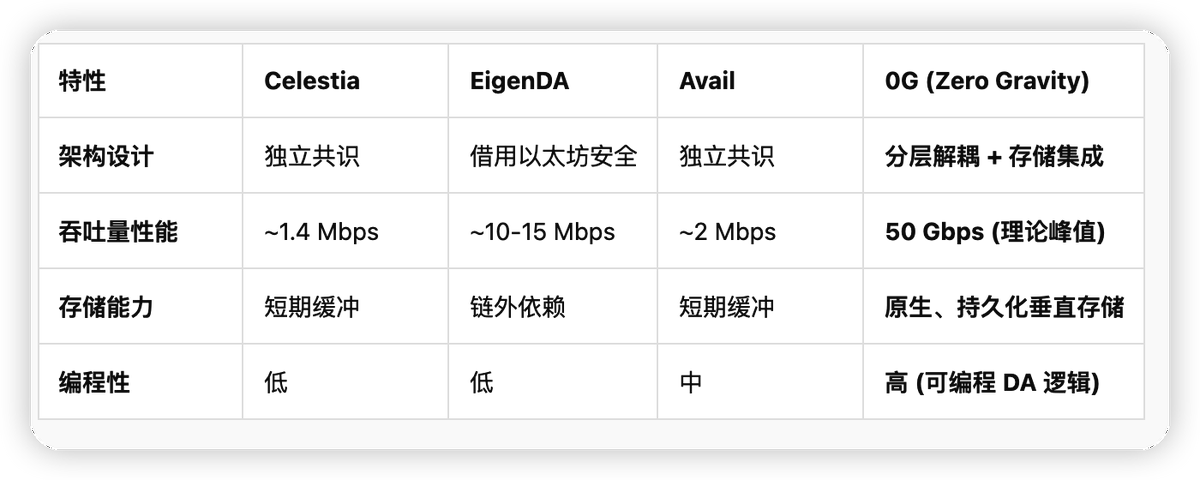
7.2 核心競爭力:可編程 DA 與垂直整合存儲
消除傳輸瓶頸原生融合存儲層,使 AI 節點可直接從 DA 層提取歷史數據。
50Gbps 的吞吐量突破:比競爭對手快幾個數量級,支援即時推理。
可編程性(Programmable DA)允許開發者自訂數據分佈策略,動態調整數據冗餘度。
這種維度的碾壓預示著一個龐大經濟體的崛起,而代幣經濟學則是推動這體系的燃料。
第八章 2026 年生態展望與代幣經濟學
隨著 2025 年主網的穩定運行,2026 年將成為 0G 生態爆發的關鍵節點。
8.1 $0G 代幣:多維價值捕獲路徑
資源支付(工作代幣):接觸高性能 DA 及存儲空間的唯一媒介。
安全抵押(Staking)驗證者和儲存提供者必須质押 $0G,以獲取網絡收益紅利。
優先次序分配在繁忙時期,令牌持有量決定計算任務的優先次序。
8.2 2026 年生態激勵與挑戰
0G計劃啟動 「重力基金會 2026」 專項基金,重點扶持 DeAI 推理框架與數據眾籌平台。儘管技術領先,但 0G 仍面臨節點硬體門檻高、生態冷啟動及合規性等挑戰。