
自學習 AI 執行個體與傳統機器學習模型及現有的基於 LLM 的執行個體有何不同?
2026/05/02 15:21:02
介紹
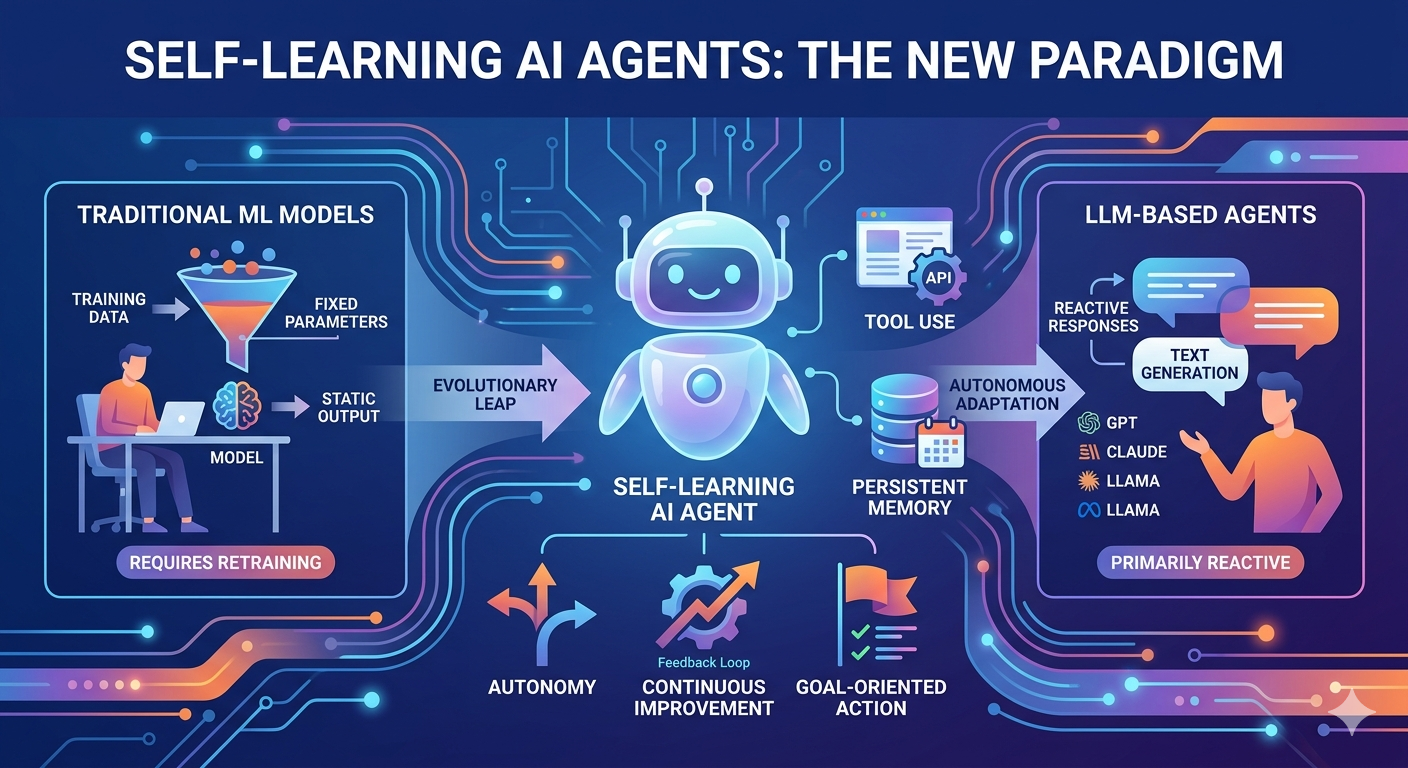
人工智慧領域正經歷一場深刻的變革。儘管傳統的機器學習模型主導了過去十年,而大型語言模型自2022年以來吸引了全球的關注,但一種新的範式正在出現,徹底改變了人工智慧系統的運作方式。自學習AI agents代表了下一階段的進化躍遷,它們在自主性、適應性推理和持續改進方面的結合,使其與其前身及當前基於LLM的系統有著顯著區別。理解這些差異對於任何希望在快速演變的人工智慧生態中把握方向的人來說都是至關重要的。
什麼是自學習 AI 代理?
自學習 AI 代理是能夠感知環境、分析資訊、制定決策並執行行動以達成特定目標的自主計算實體。與需要在每一步都依賴人類提示的傳統 AI 系統不同,自學習代理只需給予一個高層次目標,便能獨立決定如何實現該目標。這些代理結合了感知、推理、學習與行動能力,模擬以往僅見於生物系統的智能行為。
自學習 AI 代理的關鍵特徵包括自主性、反應性、主動性和社交能力。自主性使代理能夠在無需持續人為干預的情況下獨立運作。反應性使它們能夠感知環境變化並作出適當回應。主動性意味著它們不僅僅對刺激作出反應,還會透過規劃積極追求目標。社交能力則允許它們在多代理系統中與其他代理協作,以完成複雜任務。
根據微軟2025年的人工智慧預測,由人工智慧驅動的代理正獲得更高的自主性,以執行更多任務,從而提升多個領域的生活品質。關鍵區別在於這些代理如何處理目標:大型語言模型需要詳細且精心撰寫的提示才能產生高品質輸出,而人工智慧代理只需一個目標,便能獨立思考並執行必要的行動。
傳統機器學習模型:結構與限制
傳統的機器學習模型代表了一種與人工智慧根本不同的方法。這些模型通常在特定的數據集上進行訓練,以執行狹窄且定義明確的任務,例如分類、回歸或聚類。一旦部署,它們將在固定的參數內運行,若無明確的重新訓練,則無法根據新經驗修改其行為。
傳統機器學習模型的架構以從歷史資料中進行統計學習為核心。模型在訓練期間學習模式,並在推論時將這些學到的模式應用於新輸入。這種方法在具有明確模式和一致輸入的任務中表現極佳,例如垃圾郵件檢測、圖像分類或推薦系統。然而,這些模型的靜態特性在動態且不可預測的環境中會造成顯著限制。
傳統的機器學習模型需要工程師手動定義特徵、選擇演算法並調節超參數。當資料分佈發生變化或任務需求改變時,模型的表現可能下降,並需要重新訓練。部署後,學習過程基本上處於凍結狀態,意味著這些系統無法從經驗中學習或在沒有明確干預的情況下適應新情況。
安全與合規團隊通常使用傳統的機器學習來識別結構化數據中的模式,但這些系統在面對需要情境理解或多步推理的任務時會遇到困難。它們缺乏規劃、推理因果關係,或將複雜問題分解為較小且可管理的子任務的能力。
基於 LLM 的代理:現有功能與限制
目前的 LLM-based agents 相較於傳統機器學習有顯著進步。這些系統基於擁有數十億參數的大型語言模型,能夠理解自然語言、生成類似人類的文本,並執行過去 AI 無法完成的推理任務。OpenAI、Anthropic 和 Google 等公司已開發出越來越強大的模型,成為今日許多 AI 應用程式的基礎。
基於 LLM 的代理在自然語言理解和生成方面表現出色。它們能夠進行有意義的對話、總結文件、編寫代碼並解釋複雜的概念。例如,OpenAI 的 o1 模型展現了先進的推理能力,使其能夠在回答難題前,使用類似人類分析的邏輯步驟來解決複雜問題。
然而,目前大多數基於 LLM 的代理本質上是反應式系統。它們會回應使用者的提示,但不會主動追求目標或在現實世界中執行行動。當你與聊天機器人互動時,系統會根據你的輸入和其訓練資料生成回應,但若沒有持續的人工指導,它不會獨立採取步驟以達成更廣泛的目標。
基於大語言模型的代理在需要跨多個步驟持續努力、與外部工具整合或根據反饋進行調整的任務中,其限制便會顯現。雖然這些模型能在單一交易所內推理問題,但它們通常缺乏在互動中維持狀態、在外部系統中執行操作或從決策結果中學習的能力。
關鍵差異:自學型 AI 代理 vs 傳統機器學習
自學型 AI 代理與傳統機器學習模型之間的差異涵蓋架構、能力與運作哲學。理解這些區別有助於釐清為何許多專家將代理視為 AI 發展的下一前沿。
-
學習與適應
傳統的機器學習模型在固定的訓練階段中學習,之後便靜態運作。基於歷史交易數據訓練的詐騙檢測模型,除非重新訓練,否則將無限期套用相同的模式。相反,自學習代理能從與環境的互動中持續學習。它們觀察自身行動的結果,分析哪些有效、哪些無效,並相應地調整策略。
-
自主性與目標導向行為
傳統的機器學習模型是人類用來完成特定任務的工具。它們不會獨立追求目標,僅根據學習到的模式處理輸入並產生輸出。自我學習代理是以目標為導向的系統,能夠接收高層次目標,並確定實現這些目標的最佳行動方案。它們會將複雜目標分解為子任務,執行這些子任務,並根據進展調整策略。
-
工具使用與環境互動
自學習代理可與外部工具、API 和軟體系統進行介面。它們可以瀏覽網際網路、操作檔案、執行程式碼,並與資料庫互動。傳統的機器學習模型通常無法做到這一點;它們僅限於在其自身計算圖內接收的輸入和產生的輸出。
-
情境理解與規劃
雖然傳統的機器學習在結構化數據的模式識別上表現出色,但自學習代理在理解上下文和規劃多步解決方案方面展現出更優異的能力。一個被賦予規劃旅行目標的代理,將會研究目的地、比較價格、檢查可用性並預訂安排——這些行為是靜態分類模型無法實現的。
關鍵差異:自學型 AI 代理與基於 LLM 的代理
自學型 AI 代理與現有基於 LLM 的代理之間的區別雖細微,卻至關重要。兩者都可能以大型語言模型作為核心組件,但它們的架構和運作模式有顯著差異。
-
被動運作與主動運作
目前大多數基於 LLM 的代理都是反應式系統,會根據提示生成回應。用戶提出問題,模型便提供答案。然而,自學型代理可以主動運作。給定一個目標後,它們會主動蒐集資訊、制定計畫並執行行動,無需在每個步驟都等待人類輸入。
-
狀態管理與記憶體
傳統的 LLM 將每場對話視為無狀態,儘管某些實現方式會加入上下文視窗。自學習代理則整合了複雜的記憶系統,能在跨會話中維持資訊、追蹤目標進度,並從過往經驗中學習。這種持久記憶使代理能夠基於先前的工作進行累積,而非在每次互動時從頭開始。
-
工具整合與動作執行
基於大語言模型的代理主要生成文字,即使該文字代表程式碼或指令。自學習代理則設計為實際執行這些指令並與外部系統互動。OpenAI 的 Operator 和 Claude 的 Computer Use 代表了這方面的初步進展,使 AI 能夠控制瀏覽器、命令列介面和軟體應用程式。
-
動態工作流程適應
當基於 LLM 的代理遇到障礙時,通常會失敗或產生錯誤訊息。自學習代理能夠識別其初始方法是否無效,分析原因,並動態調整策略。這種迭代與適應的能力對於處理複雜的現實世界任務至關重要,因為這些任務很少能完全按照計劃進行。
自學習代理的架構
要了解自學代理的獨特之處,需檢視其底層架構。這些系統結合了多個組件,共同實現自主和適應性行為。
-
規劃與推理引擎
自學習代理的核心是一個推理引擎,通常由大型語言模型驅動,能夠將複雜目標分解為可執行的步驟。此引擎使代理能夠規劃、推理因果關係,並評估潛在行動的結果。微軟的研究表明,訓練方法與代理能力可能產生協同效應,更優化的模型能促成更有效的代理。
-
Memory Systems
自我學習代理維護多種類型的記憶:用於當前任務的短期工作記憶、用於持久知識的長期記憶,以及用於過去經驗的情境記憶。這些記憶系統使代理能夠從反饋中學習、記住成功的策略,並避免重複錯誤。這些記憶系統的複雜性將真正的自我學習代理與較簡單的反應式系統區分開來。
-
工具使用與 API 整合
代理具備調用外部工具、存取資料庫、瀏覽網頁及與軟體應用程式互動的能力。此工具使用功能將代理的範圍擴展至純文字生成之外,實現真實世界的操作。代理可根據任務選擇合適的工具,執行工具調用,並將結果融入其推理過程。
-
反饋與學習機制
自我學習代理最顯著的特點可能是其從經驗中學習的能力。當代理嘗試一項任務時,它可以評估結果、識別問題所在,並調整未來的策略。這種學習可以通過多種機制實現,包括強化學習、自我反思和迭代優化。
實際應用與影響
自學習 AI 代理的獨特功能正在推動各行業的新應用。微軟報告指出,近 70% 的《財富》500 強員工已使用 Microsoft 365 Copilot 代理來處理重複的日常任務,例如在 Teams 會議中過濾郵件和記錄會議筆記。
在供應鏈管理中,代理可根據歷史數據和實時資訊預測庫存需求變化,調整採購和生產計劃,以避免缺貨或庫存過多的情況。在醫療保健領域,代理可通過處理大量醫學文獻和病患記錄,分析病患案例,提供診斷建議,並協助制定治療計劃。
影響遠不止於效率的提升。自學習代理正在改變知識工作的執行方式。與人類學習使用 AI 工具不同,這一範式正轉向 AI 代理學習更有效地協助人類。這代表了人與 AI 關係的根本性變化,從人類操作工具轉變為人類監督並與自主代理協作。
組織如何為代理時代做好準備?
希望利用自學型 AI 代理的組織,應首先識別高價值的使用情境,在這些情境中,代理的功能相較於傳統方法能帶來顯著優勢。涉及多步驟流程、外部系統整合或動態環境的任務,是部署代理的首選對象。
技術基礎設施必須進化以支援代理運作。這包括穩健的 API 整合、安全的工具存取,以及能夠追蹤代理表現並偵測問題的監控系統。組織還應建立治理框架,明確定義代理自主性的適當界限,同時確保符合相關法規。
隨著這些系統日益普及,在全公司範圍內提升對代理技術的認知變得至關重要。員工需要了解代理的運作方式、如何提供有效的指導,以及如何評估和優化代理的輸出。這一轉變不僅需要技術投入,還需要文化上的適應。
結論
自我學習的 AI 代理代表了人工智慧能力的根本性進步。與傳統的靜態且專注於特定任務的機器學習模型不同,代理能夠自適應、規劃並自主執行複雜的工作流程。與現有的基於 LLM 的系統相比,代理增加了主動操作、持久記憶,以及透過工具整合實現現實世界操作的能力。
從反應式 AI 轉向自主代理,標誌著一場與從狹義 AI 轉向通用語言理解相當的範式轉變。理解這些差異並據此做好準備的組織,將最能掌握自學習代理的變革潛力。代理時代並非即將到來——它已經來臨,正在重塑工作的執行方式以及 AI 能夠達成的成就。
常見問題
AI 代理與傳統機器學習模型的主要差異是什麼?
傳統的機器學習模型在訓練期間學習模式,並靜態地將其應用於新輸入,需重新訓練才能適應。自學習 AI 代理可從經驗中持續學習、適應新情況,並在無需持續人為干預或重新訓練的情況下自主運作。
自學習 AI 個體能否取代現有的基於 LLM 的聊天機器人?
AI 動作代理與大型語言模型具有不同的用途,通常互為補充而非競爭關係。大型語言模型擅長語言理解與生成,而動作代理則增添自主性、行動能力與適應性學習。許多動作代理實際上以大型語言模型作為其推理引擎,並額外加入規劃、記憶與工具使用等層級。
自學習 AI 執行個體是否比傳統機器學習模型需要更多的計算資源?
自學習代理由於其複雜性、持續狀態管理以及通常較大的底層模型,通常需要更多的計算資源。然而,在許多應用中,自主運行帶來的效率提升和減少對人工監督的需求,可以抵消這些成本。
自學習代理如何處理錯誤和失敗?
自學習代理能夠識別其方法是否無效,分析失敗原因,並動態調整策略。這種迭代優化能力使它們比靜態系統更能應對不可預測的情況,但強大的錯誤處理和人工監督仍至關重要。
自學型 AI 代理是否適合商業使用?
在適當設計並設有合理防護措施的情況下,自學習代理可安全地部署於商業環境中。組織應為代理的自主性設定明確邊界,建立監控系統,並對關鍵決策保持人工監督。關鍵在於平衡代理能力與適當的治理框架。
免責聲明: 本頁面經由 AI 技術(GPT 提供支持)翻譯,旨在方便您的閱讀。欲獲取最準確資訊,請以原始英文版本為準。