









Автор:Тіна, ДонгмейInfoQ
1. Після майже трьох років приголомшливих змін Маск знову відкрив алгоритм рекомендацій X
Щойно інженерна команда X оприлюднила пост у X, у якому оголошено про офіційне відкриття джерельного коду алгоритму рекомендацій X. За описом, ця бібліотека відкритого коду містить ядро системи рекомендацій, яке підтримує потік інформації "Рекомендовано для вас" у X. Ця система поєднує вміст у мережі (від облікових записів, на які підписано користувача) з вмістом поза межами мережі (виявлення через пошук, заснований на машинному навчанні), а потім використовує модель Transformer на основі Grok для ранжування всього вмісту. Іншими словами, цей алгоритм використовує ту саму архітектуру Transformer, що й Grok.
Відкритий код: https://x.com/XEng/status/2013471689087086804
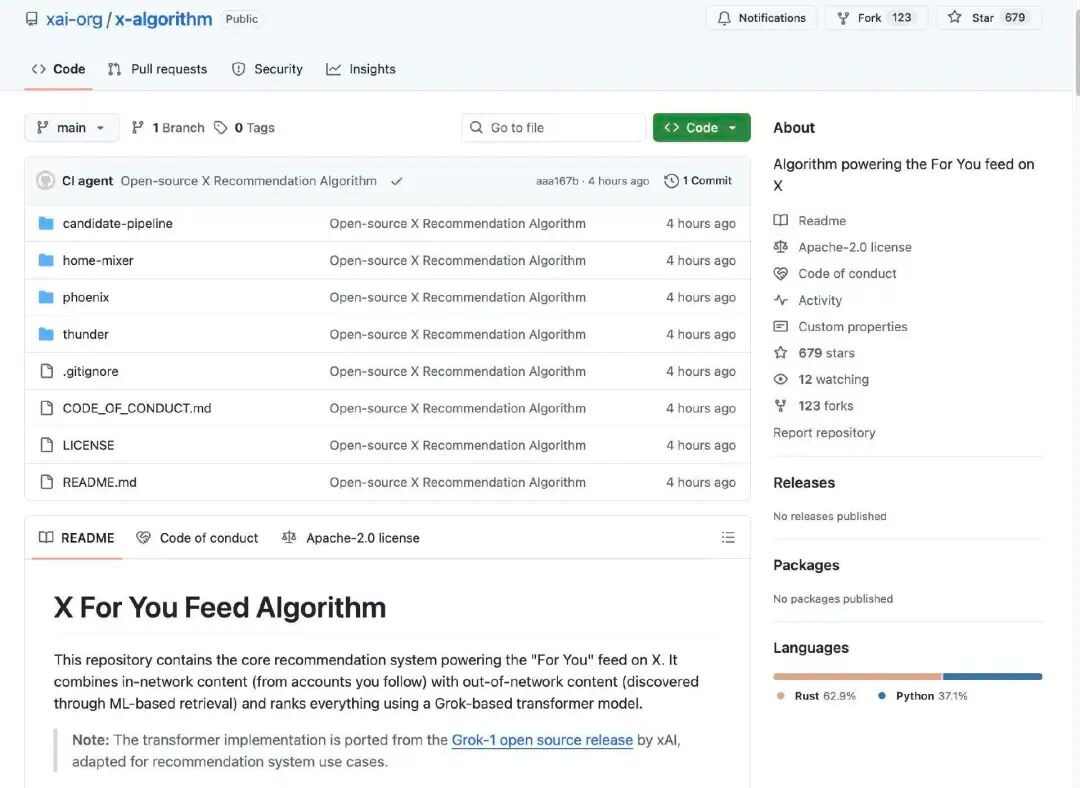
Рекомендаційний алгоритм X відповідає за те, що користувач бачить на головному екранівміст від "For You"Він отримує кандидатські дописи з двох основних джерел:
Обліковий запис, який ви стежите (In-Network / Thunder)
Інші публікації, знайдені на платформі (поза мережею / Phoenix)
Ці кандидатські вміст подають на обробку, після чого відфільтровують і впорядковують за релевантністю.
То ж таки, як виглядає ядро алгоритму та логіка його роботи?
Алгоритм спочатку отримує кандидатів на вміст з двох джерел:
Вміст, який ви стежите: публікації, які розміщують облікові записи, за якими ви стежите.
Нецензурний вміст: пости, що можуть Вас зацікавити, вибрані з усього контенту системою.
Метою цього етапу є «виявлення пов'язаних дописів».
Система автоматично видаляє низькоякісний, повторюваний, порушувальний або непідходящий вміст. Наприклад:
Вмикнути зміст облікового запису
Теми, які явно не цікавлять користувача
Незаконні, застарілі або недійсні дописи
Таким чином забезпечується те, що при кінцевому впорядкуванні оброблятиметься лише корисний контент.
Ядром алгоритму, відкритого для використання, є використання системою моделі Transformer на основі Grok (аналогічно до великих мовних моделей / глибоких нейронних мереж), яка оцінює кожен кандидатський пост. Модель Transformer передбачає ймовірність кожного типу дії на основі історії поведінки користувача (лайки, відповіді, репости, кліки тощо). Нарешті, ці ймовірності дії комбінуються з вагами, утворюючи загальний бал. Пости з вищим балом мають більші шанси бути рекомендованими користувачу.
Це забезпечує зміну традиційного підходу, коли використовувалися ручні ознаки, на передбачення інтересів користувача за допомогою навчання з кінця до кінця.
Це не перший випадок, коли Маск відкрив алгоритм рекомендацій X.
31 березня 2023 року, як і обіцяв Маск під час купівлі Twitter, він офіційно відкрив частину вихідного коду Twitter, включаючи алгоритм рекомендації твітів у лінії часу користувачаВідкриття проекту відбулося в день, коли він отримав 10 000+ зірок на GitHub.
У той же час, Маск заявив у Twitter, що це випуск"Більшість алгоритмів рекомендацій"Решта алгоритмів також будуть відкриті по черзі. Він також зазначив, що сподівається, що «незалежні треті сторони зможуть визначити з прийнятною точністю, що Twitter може показувати користувачам».
У дискусії в Space про публікацію алгоритму він сказав, що цей план відкритого коду має зробити Twitter "найпрозорішою системою в Інтернеті" і зробити його таким же стійким, як найвідоміший і найуспішніший проект з відкритим кодом Linux. "Загальна мета — забезпечити максимально можливе задоволення користувачів, які продовжують підтримувати Twitter," — сказав він.
Сьогодні минуло майже три роки з тих пір, як Маск вперше відкрив алгоритм X. Як супер-інфлюенсер у технічному співтоваристві, Маск давно зробив достатньо пропаганди для цього відкриття.
11 січня Маск написав у X, що він відкриє джерельний код нового алгоритму X (включаючи всі коди, які визначають, який зміст природного пошуку та рекламу рекомендувати користувачам) через 7 днів.
Цей процес повторюватиметься кожні 4 тижні з детальними поясненнями для розробників, щоб допомогти користувачам зрозуміти, що змінилося.
Сьогодні він знову виконав своє обіцяання.
2. Чому Маск вирішив зробити відкритим вихідний код?
Коли Ілон Маск знову згадує "відкрите джерело", перша реакція з боку зовнішнього світу — це не технічний ідеалізм, а реальний тиск.
Протягом минулий рік X неодноразово потрапляв у скандали через свій механізм розподілу контенту. Платформу широко критикували за те, що її алгоритми переважають і підтримують праворадикальні погляди, і ця тенденція не є окремим випадком, а вважається системною. У звіті, опублікованому минулого року, зазначалося, що система рекомендацій X демонструє помітний новий зміст у поширенні політичного контенту.
У той же міру, деякі екстремальні випадки ще більше підсилили зовнішні сумніви. Рік тому невідфільтроване відео, яке стосувалося вбивства американського правого активіста Чарлі Керка, швидко поширилося на платформі X, викликавши хвилю громадської реакції. Критики вважають, що це не тільки відкрило неефективність механізмів модерації платформи, але й знову підкреслило, як алгоритми вирішують, що посилювати, а що ні. Приховане впливове становище.
У такому контексті раптове підкреслення Маском прозорості алгоритмів важко просто трактувати як чисто технічне рішення.

3. Що про це думають користувачі мережі?
Після того як алгоритм рекомендацій X був відкритий, на платформі X користувачі зробили наступні 5 висновків щодо механізму алгоритму рекомендацій:
- Відповісти на ваш коментарАлгоритм надає вагу «відповідь + відповідь автора» у 75 разів більше, ніж лайкам. Не відповідати на коментарі може суттєво вплинути на охоплення.
- Посилання зменшують відомістьПосилання потрібно розміщувати в особистому профілі або в закріпленому дописі, але ні в якому разі не в основному тексті допису.
- Тривалість перегляду є найважливішоюЯкщо вони прокотять екран, то ви не зможете захопити їх увагу. Відео/пости отримують високий рівень уваги, тому що вони зупиняють користувачів.
- Залишайся в межах свого фаху«Симуляція класу» дійсно існує. Якщо ви відхиляєтесь від вашої ниші (криптовалюти, технології тощо), то не отримаєте жодних каналів розподілу.
- Заглушка / мовчання значно знизить ваші балиЦе має бути спричинююче суперечки, але не образливе.
Коротко: спілкуйтесь зі своєю аудиторією, будуєте зв’язки, залучайте користувачів до додатку. Насправді це дуже просто.
Користувачі мережі також помітили, що, хоча архітектура є відкритою, деякі змістовні частини все ще не відкриті. Цей користувач висловив думку, що цей реліз, по суті, є лише фреймворком без двигуна. А конкретно, чого бракує?
Відсутній параметр ваги — Код підтверджує нарахування балів за позитивні дії та зняття балів за негативні дії, але, на відміну від версії 2023 року, конкретні значення були вилучені.
Приховати ваги моделі - Не включає внутрішні параметри та обчислення самого моделі.
Непублічні тренувальні дані - Нічого не відомо про вибірку даних для навчання моделі, спосіб збору даних про поведінку користувачів, а також про те, як формується «хороші» і «погані» зразки.
Для звичайних користувачів X відкритий код алгоритму не вплине на них особливо сильно. Однак більша прозорість може пояснити, чому деякі публікації отримують увагу, а інші ні, і дозволить дослідникам вивчати, як платформа ранжує контент.
4. Чому рекомендаційна система є об'єктом боротьби?
У більшості технічних дискусій,Рекомендаційна системаЧасто вважається частиною інженерії, що працює в тіні, складною, але рідко потрапляє в центр уваги. Але якщо дійсно зрозуміти, як працює бізнесовий механізм інтернет-гігантів, виявляється, що система рекомендацій не є периферійним модулем, а є «інфраструктурним існуванням», що підтримує весь бізнес-модель. Саме тому її можна назвати «тихою гіпою» інтернет-індустрії.
Відкриті дані багаторазово це підтвердили. Amazon розповіла, що приблизно 35% покупок на її платформі безпосередньо здійснюються через систему рекомендацій; Netflix ще більш агресивний, приблизно 80% часу перегляду визначається алгоритмом рекомендацій; у YouTube ситуація аналогічна, приблизно 70% переглядів здійснюється через систему рекомендацій, особливо через потік (feed). Що стосується Meta, хоча вони ніколи не наводили точних даних, але технічна команда зазначала, що приблизно 80% обчислювальних ресурсів внутрішніх обчислювальних кластерів компанії використовується для виконання завдань, пов'язаних із рекомендаціями.
Що означають ці цифри?Якщо видалити систему рекомендацій з цих продуктів, це майже еквівалентно видаленню фундаменту.Взявши, наприклад, Meta, розміщення реклами, тривалість перебування користувачів, комерційні перетворення майже повністю ґрунтуються на системі рекомендацій. Рекомендаційна система не тільки визначає, що бачить користувач, але й безпосередньо визначає, як платформа заробляє гроші.
Однак саме така система, що вирішує питання життя і смерті, довгий час стикатиметься з проблемою надзвичайно високої інженерної складності.
У традиційній архітектурі систем рекомендацій важко використовувати єдину модель, яка б відповідала всім сценаріям. У реальних виробничих системах відбувається висока фрагментація. Наприклад, у компаній типу Meta, LinkedIn, Netflix повна ланцюжок рекомендацій зазвичай виконується одночасно більше 30 спеціалізованих моделей: моделі відбору, моделі грубого ранжування, моделі точного ранжування, моделі переранжування, кожна з яких оптимізується під різні цільові функції та показники бізнесу. Зазвичай за кожну модель відповідає один або навіть кілька команд, які займаються інженерією ознак, навчанням, налаштуванням гіперпараметрів, впровадженням у виробництво та постійними ітераціями.
Вартість цього підходу очевидна: складність інженерії, високі витрати на обслуговування, складність співпраці між завданнями. Як тільки хтось ставить запитання "Чи можна використовувати один модель для вирішення кількох задач рекомендацій", це означає зменшення складності на порядок для всієї системи. Це саме те, чого довгий час прагнув індустрія, але що було важко досягти.
Поява великих мовних моделей відкрила новий шлях для рекомендаційних систем.
LLM вже довели на практиці, що вони можуть стати дуже потужними загальними моделями: вони добре переносяться між різноманітними завданнями, а їхня продуктивність може продовжувати підвищуватися з розширенням масштабу даних та обчислювальних ресурсів. Навпаки, традиційні рекомендаційні моделі зазвичай є «напрямленими на конкретні завдання», і їх дуже складно використовувати для обміну здібностями між кількома сценаріями.
Ще важливіше, що єдиний великий модель не тільки спрощує інженерію, але й має потенціал «перехресного навчання». Коли одна модель одночасно вирішує кілька задач рекомендацій, сигнали між різними задачами можуть взаємно доповнювати один одного, і з ростом масштабу даних модель легше еволюціонує в цілому. Саме така властивість довгий час була бажаною для рекомендаційних систем, але важко досяжною традиційними методами.
Що змінив LLM? Насправді він змінив все від інженерії ознак до здатності до розуміння.
З точки зору методології найбільш значиме вплив LLM на рекомендаційні системи відбувається на етапі «інженерії ознак», який є центральним елементом.
У традиційних системах рекомендацій інженери повинні вручну створювати велику кількість сигналів: історію кліків користувача, тривалість перебування, вподобання схожих користувачів, мітки вмісту тощо, а потім чітко говорити моделі: «Будь ласка, приймай рішення на основі цих ознак». Сами моделі не розуміють семантики цих сигналів, вони лише вчаться встановлювати відповідності в числовому просторі.
Після введення мовних моделей цей процес став високо абстрактним. Тепер вам більше не потрібно вказувати окремо "оберіть цей сигнал, ігноруйте той сигнал", замість цього ви можете просто описати саму проблему моделі: це користувач, це вміст; цей користувач раніше полюбляв подібний вміст, інші користувачі також дали позитивну відповідь на цей вміст — зараз, будь ласка, визначте, чи цей вміст слід рекомендувати цьому користувачу.
Сама мовна модель вже має здатність розуміння, вона може самостійно визначати, які дані є важливими сигналами, і яким чином їх об'єднувати для прийняття рішень. У певному сенсі, вона не просто виконує рекомендаційні правила, але й "розуміє саме поняття рекомендацій".
Джо сила полягає в тому, що LLM у процесі навчання зустрічалися з величезним і різноманітним обсягом даних, що дозволяє їм легше вловлювати тонкі, але важливі закономірності. Навпаки, традиційні системи рекомендацій змушені залежати від того, щоб інженери явно перерахували ці закономірності, і якщо якась пропущена, модель не зможе її вловити.
З точки зору бекенду, така зміна не є чимось новим. Як ви задаєте запит GPT, і він генерує відповідь на основі контексту, так само, коли ви запитуєте його: «Чи зацікавить мене цей вміст?» — він може прийняти рішення на основі наявної інформації. У певній мірі мовні моделі мають вроджену здатність «рекомендувати».