









Yazar:Tina, Dongmei, InfoQ
1. Neredeyse üç yıl sonra Musk, X önerisi algoritmasını yine açık kaynak yapmaya karar verdi.
Yakında, X mühendislik ekibi, X üzerinde "tavsiye algoritmamızı resmi olarak açık kaynak yapmaktayız" başlıklı bir gönderi ile X önerme algoritmasının açık kaynak olduğunu duyurdu. Tanıtımına göre bu açık kaynak kütüphane, X'teki "için Siz" akışı için destek sağlayan temel öneri sistemini içerir. Bu sistem, kullanıcıların takip ettiği hesaplardan gelen ağ içi içerikler ile makine öğrenimi tabanlı arama yoluyla keşfedilen ağ dışı içerikleri birleştirir ve tüm içerikleri sıralamak için Grok tabanlı bir Transformer modeli kullanır. Yani bu algoritma, Grok ile aynı Transformer mimarısını kullanmaktadır.
Kaynak kod adresi: https://x.com/XEng/status/2013471689087086804
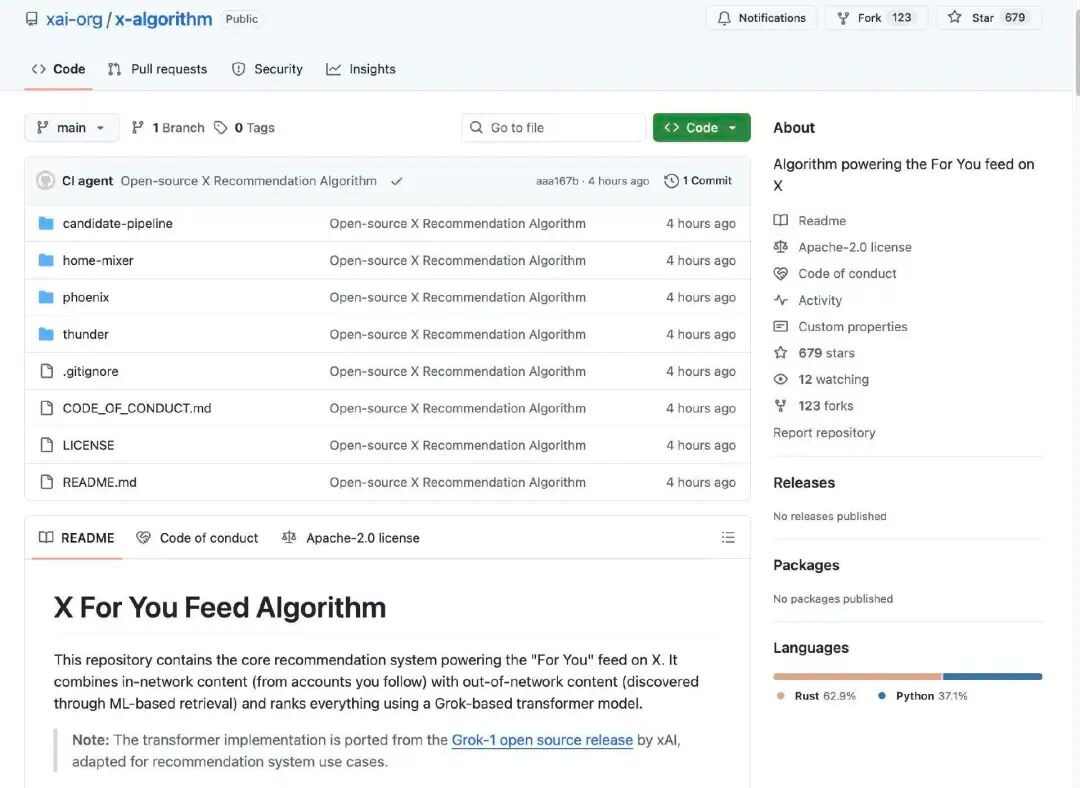
X'in öneri algoritması, kullanıcıların ana sayfada gördükleri içerikleri üretmekle sorumludur."Senin İçin" akışı içeriğiAday gönderileri iki ana kaynaktan alır:
Takip ettiğiniz hesap (Ağ İçinde / Fırtına)
Platformda bulunan diğer gönderiler (Ağ Dışı / Phoenix)
Bu aday içerikler daha sonra birleştirilir, süzülür ve ardından ilgili sıraya göre sıralanır.
Peki, algoritmanın temel mimarisi ve çalışma mantığı nasıldır?
Algoritma, aday içeriği öncelikle iki kaynaktan toplar:
Takip: Aktif olarak takip ettiğiniz hesapların gönderilerini içerir.
Takip etmeyen içerik: Sistem, tüm içerik kütüphanesinde size ilginç olabilecek gönderileri arar.
Bu aşamanın amacı, "muhtemelen ilgili olan gönderileri bulmaktır.
Sistem, düşük kaliteli, yinelenen, ihlal eden veya uygun olmayan içerikleri otomatik olarak kaldırır. Örneğin:
Engellenenin içeriği
Kullanıcının ilgisini çekmediği konuları belirginleştirmek
Yasadışı, eski veya geçersiz gönderiler
Bu sayede son sıralamada yalnızca değerli aday içerikler işlenir.
Bu keşfedi açık kaynak yapan algoritmanın merkezinde, sistem her aday gönderiye puan vermek için Grok tabanlı bir Transformer modeli (büyük dil modeli / derin öğrenme ağı benzeri) kullanır. Transformer modeli, kullanıcıların geçmiş davranışlarına (beğenme, yanıt verme, paylaşım, tıklama vb.) dayanarak her davranışın olasılığını tahmin eder. Sonunda, bu davranış olasılıkları, kullanıcıya önerilecek gönderilerin olasılığını belirleyen bir puanlama oluşturmak için ağırlıklı olarak birleştirilir.
Bu tasarım, geleneksel elle özellik çıkarma uygulamalarını temelde ortadan kaldırarak, kullanıcı ilgisini tahmin etmek için son-sona öğrenme yaklaşımını kullanmaya geçmiştir.
Bu, Musk'un X önerisi algoritmasını ilk kez açık kaynak yapmamasıdır.
31 Mart 2023'te, Twitter'ı satın alırken vaat ettiği gibi, Musk, Twitter'ın kısmi kaynak kodlarını resmen açık kaynak yapmıştır. Bu kodlar, kullanıcı akışında tweet öneren algoritmayı içerir.Proje, açık kaynak olarak paylaşıldığı gün GitHub'da 10.000'den fazla yıldız aldı.
O sırada Musk, Twitter'da bu sürümün olduğunu belirtti."Çoğu öneri algoritması"Diğer algoritmaların da zamanla açıklanacağını belirtti. Ayrıca, Twitter'ın kullanıcılara ne tür içeriklerin sunulabileceğini "bağımsız üçüncü tarafların makul bir doğrulukla belirlemesini" umduğunu ifade etti.
Twitter'in "internetin en şeffaf sistemi" haline gelmesini sağlamak ve Linux'un en bilinen ve en başarılı açık kaynak projelerinden biri olmasına benzer şekilde sağlam hale gelmesini sağlamak için açık kaynak kodlu hale getirilmesi planını açıkladığı Space tartışmasında bunu söyledi. "Genel hedeften bahsediyorum, Twitter’ı desteklemeye devam eden kullanıcıların buradan en iyi şekilde yararlanmalarını sağlamaktır."
Şu anda Musk'un X algoritmasını ilk defa açık kaynak yapmasından üç yıldan fazla bir zaman geçti. Ayrıca teknoloji dünyasının süper KOL'ü olan Musk, bu açık kaynak yapma girişimi için çok önceden yeterli tanıtımı yaptı.
11 Ocak'ta Musk, X'te yeni X algoritmasını (kullanıcılara hangi doğal arama içeriği ve reklam içeriklerinin önerileceğini belirlemek için kullanılan tüm kod dahil) 7 gün içinde açık kaynak yapacağını açıkladı.
Bu işlem her 4 hafta bir tekrar edecek ve kullanıcıların hangi değişikliklerin yapıldığını anlamasına yardımcı olacak ayrıntılı geliştirici notlarıyla birlikte sunulacak.
Bugün sözü yine tutuldu.
2. Musk neden açık kaynak yapmak istiyor?
Elon Musk "açık kaynak"ı tekrar anuma getirdiğinde, dış dünyanın ilk tepkisi teknik idealleşme değil, gerçekçi baskılar olmuştur.
Geçen yıl, X, içerik dağıtım mekanizması nedeniyle birçok tartışmaya girdi. Platform, algoritma düzeyinde sağ kanat görüşlerine önyargılı ve bu görüşlerin yayılmasına yardımcı olduğundan yaygın eleştirilere maruz kaldı. Bu eğilim, nadiren görülen bir durum değil, sistematik bir yapı olarak görülüyor. Geçen yıl yayınlanan bir araştırma raporu, X'in önerme sisteminin siyasi içeriklerin yayılmasında belirgin yeni bir eğilim gösterdiğini belirtti.
Bu arada, bazı uç durumlar, dışarıdan gelen eleştirileri daha da artırdı. Geçen yıl, Amerikalı sağ kanat aktivisti Charlie Kirk'in öldürülmesiyle ilgili, X platformunda inceleme yapılmadan yayılan bir video hızla yayıldı ve kamuoyunda büyük bir etki yarattı. Eleştirmenler, bu olayın sadece platformun inceleme mekanizmalarının başarısız olduğunu değil, aynı zamanda algoritmaların "neyi büyütmek, neyin büyümesini engellemek" konusundaki etkisini bir kez daha vurguladığını savundu. Gizli güç.
Bu arka plana sahip olmakla birlikte, Musk'un birdenbire algoritma şeffaflığını vurgulamasının sadece teknik bir karar olarak basitçe yorumlanması zordur.

3. İnternetteki kullanıcılar ne düşünüyor?
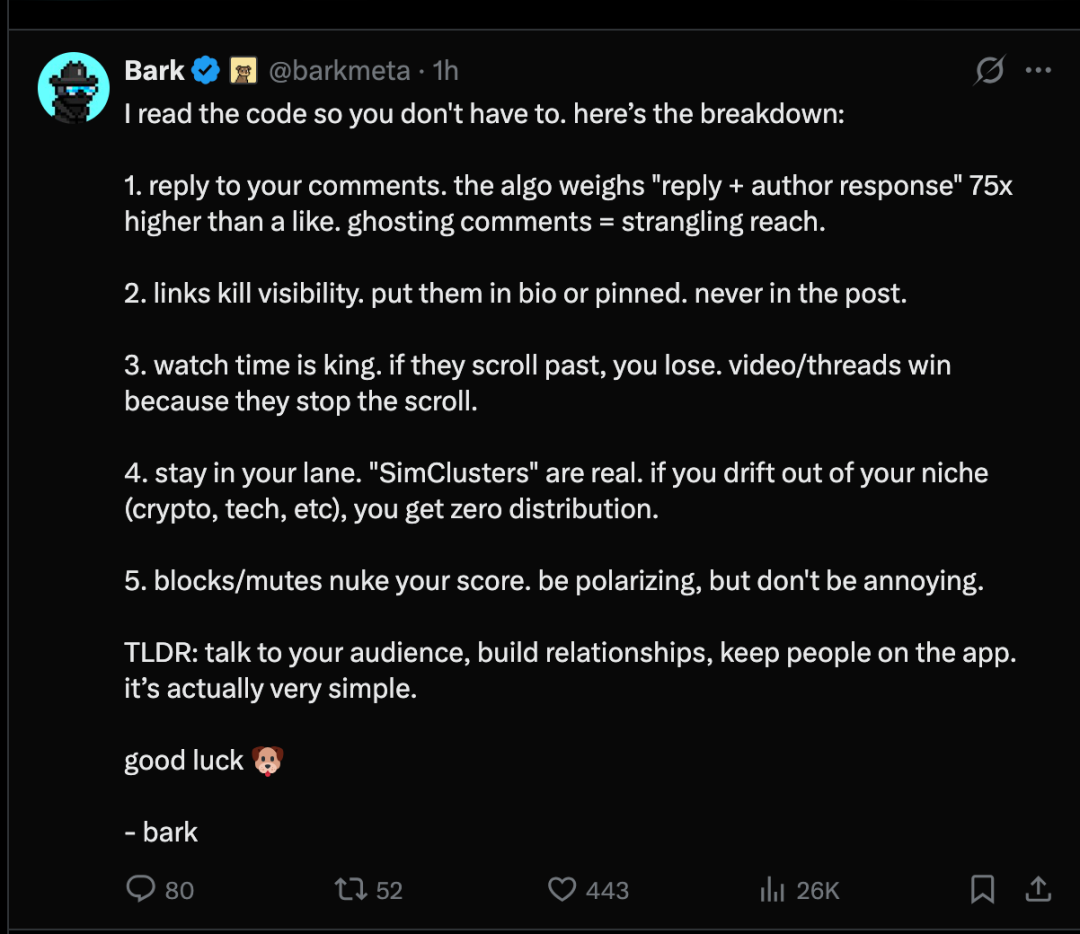
X önerme algoritması açık kaynak hale getirildikten sonra, X platformunda kullanıcılar önerme algoritması mekanizması hakkında aşağıdaki 5 noktayı özetlediler:
- Yorumunuza yanıt verinAlgoritma, "yanıt + yazar yanıtı" için beğenilere göre 75 kat fazla ağırlık verir. Yorumlara yanıt vermezseniz, görünümünüz ciddi şekilde etkilenir.
- Bağlantılar, maruziyet oranını azaltabilir.Bağlantıları, kesinlikle gönderi metninde değil, profil bilgilerinizde veya üstte sabitlenen gönderilerde yerleştirmeniz gerekir.
- İzleme süresi çok önemlidir.Eğer kaydırırlarsa onları durduramazsın. Videoların ve gönderilerin yüksek etkileşime sahip olmasının nedeni kullanıcıların durmalarını sağlamalarıdır.
- Alanında ısrar et"Simülasyon kümeleri" gerçekten var. Şifreleme, teknoloji gibi alanlardan uzaklaşırsan, hiçbir dağıtım kanalına erişemezsin.
- Engellenme / Sessiz kalma puanınızı büyük ölçüde düşürecektir.Tartışmalı olacak ama can sıkıcı olmamalı.
Kısacası: Hedef kitlenizle iletişim kurun, ilişki kurun ve kullanıcıları uygulamanızda tutun. Aslında oldukça basit.
Ağ kullanıcısı ayrıca, mimarinin açık kaynak olmasıyla birlikte bazı içeriklerin hâlâ açık kaynak olmayan şekilde kaldığını fark etti. Kullanıcı, bu yayın esasen bir çerçeve olduğunu, ancak motor olmadığını belirtti. Neler eksik?
Ağırlık parametresi eksik - Kod onayları "olumlu davranış puan ekleme" ve "olumsuz davranış puan düşürme"yi içerir ancak 2023 sürümünden farklı olarak, belirli sayısal değerler kaldırılmıştır.
Model ağırlıklarını gizle - Modelin kendi iç parametrelerini ve hesaplamalarını içermemektedir.
Gizli Eğitim Verisi - Eğitim modeli için veriler, kullanıcı davranışlarının örnekleme yöntemi ve "iyi" ve "kötü" örneklerin nasıl inşa edileceği konusunda hiçbir şey bilmiyoruz.
X algoritmi açık kaynak yapılırsa, ortalama X kullanıcısı için çok büyük bir etkisi olmayacaktır. Ancak daha yüksek şeffaflık, bazı gönderilerin neden görünürlük kazandığını ve diğerlerinin neden görmezden gelindiğini açıklamada ve araştırmacıların platformun içerikleri nasıl sıraladığını incelemesinde faydalı olabilir.
4. Neden öneri sistemi kritik bir alandır?
Çoğu teknik tartışmada,Öneri SistemiSıklıkla arka uç mühendisliğin bir parçası olarak görülür, sadece düşük profilli, karmaşık ve nadiren ışığa çıkar. Ancak gerçekten internet devlerinin ticari işleyişini inceleyecek olursak, önerme sisteminin sadece kenar bir modül olmadığını, tamamıyla ticari modeli destekleyen "altyapı düzeyinde bir varlık" olduğunu görürüz. Bu yüzden internet sektörünün "sessiz devi" olarak da adlandırılabilir.
Açık veriler bu durumu tekrar tekrar doğrulamıştır. Amazon, yaklaşık %35'lik satın alma oranının doğrudan önerilerden geldiğini açıklamıştır. Netflix ise daha da ileri gitmiş ve yaklaşık %80'lik izleme süresinin önerme algoritmaları tarafından yönlendirildiğini belirtmiştir. YouTube'da da durum benzerdir; yaklaşık %70'lik izleme süresi önerme sistemleri, özellikle akış (feed) tarafından sağlanmaktadır. Meta içinse kesin bir oran verilmemiştir ancak teknik ekibin, şirketin iç hesaplama kümelerinin yaklaşık %80'lik kısmı önerme görevlerine ayrıldığını belirttiği bilinmektedir.
Bu sayılar ne anlama gelir?Bu ürünleri bu sistemden çıkarmak, temelini çıkarmakla neredeyse aynı şeydir.Meta'ya dönersek, reklam hedeflemesi, kullanıcı tutunma süresi ve ticari dönüşümler, neredeyse tümüyle öneri sistemlerine dayanmaktadır. Öneri sistemleri yalnızca kullanıcıların "neye bakacağını" değil, aynı zamanda platformun "nasıl para kazanacağını" da doğrudan belirler.
Ancak, ömrü ve ölmeyi karar veren bu tür bir sistem uzun süredir yüksek mühendislik karmaşıklığıyla karşı karşıyadır.
Geleneksel öneri sistemleri mimarilerinde, tüm senaryoları kapsayacak şekilde tek birleşik bir modelin kullanılması zordur. Gerçek dünyadaki üretim sistemleri genellikle oldukça parçalıdır. Meta, LinkedIn ve Netflix gibi şirketleri örnek olarak ele alırsak, tam bir öneri zincirinin arkasında genellikle 30 veya daha fazla özel modelin eş zamanlı olarak çalıştığı görülür: geri çağırma modeli, kaba sıralama modeli, ince sıralama modeli, yeniden sıralama modeli. Her bir model farklı hedef fonksiyonlarına ve iş göstergelerine göre optimize edilir. Her modelin arkasında genellikle bir veya daha fazla ekip bulunur ve bu ekipler, özellik mühendisliği, eğitim, parametre ayarlaması, canlıya alma ve sürekli iterasyon gibi görevleri üstlenir.
Bu modelin maliyeti açıktır: mühendislik karmaşıklığı, yüksek bakım maliyeti ve görevler arası işbirliği zorlukları. "Bir modelin birden fazla öneri sorununu çözebilir olup olmadığı" sorulduğunda, sistemin tümü için karmaşıklığın mertebesi düşer. Bu, endüstrinin uzun süredir özlemiş ama gerçekleştirmekte zorlandığı bir hedeftir.
Büyük dil modellerinin ortaya çıkması, öneri sistemleri için yeni bir olasılık yolu sunmuştur.
LLM'lerin, uygulamada çok güçlü genel modeller olarak hizmet ettiğini, farklı görevler arasında geçiş yapma becerisine sahip olduklarını ve veri hacmi ve işlem gücü arttıkça performanslarının artmaya devam ettiğini göstermiştir. Karşılaştırmalı olarak, geleneksel öneri modelleri genellikle "görev özel"dir ve farklı senaryolar arasında yetenek paylaşımı zordur.
Daha da önemlisi, tek bir büyük modelin getirdiği sadece mühendislik basitleştirmesi değil, aynı zamanda "çapraz öğrenme" potansiyeli de var. Aynı modelin birden fazla öneri görevini aynı anda işleyebilmesi, farklı görevler arasındaki sinyallerin birbirini tamamlamasına olanak tanır. Veri ölçeği büyüdükçe modelin evrimi daha da kolaylaşır. Bu da, uzun süredir önerme sistemlerinin isteyeceği ama geleneksel yollarla zor olarak gerçekleştiremeyeceği bir özelliktir.
LLM neyi değiştirdi? Aslında özellik mühendisliği anlama kapasitesine kadar olan kısmı değiştirdi.
Yöntemolojik olarak, LLM'lerin önerme sistemlerine en büyük katkısı, "özellik mühendisliği" adı verilen temel aşamada gerçekleşir.
Geleneksel öneri sistemlerinde mühendisler, önce kullanıcı tıklama geçmişini, durma süresini, benzer kullanıcı tercihlerini, içerik etiketlerini vb. gibi birçok sinyali yapay olarak oluşturmak zorundadır. Daha sonra modeli açıkça "lütfen bu özellikleri temel alarak karar verin" demek gerekir. Model, bu sinyallerin semantik anlamını anlayamaz, sadece sayısal uzayda haritalama ilişkilerini öğrenir.
Dil modelleri eklendiğinde bu süreç yüksek derecede soyut hale geldi. Artık "bu sinyali izle, diğer sinyali görmezden gel" gibi ifadeleri tek tek belirtmek zorunda kalmıyorsunuz. Bunun yerine doğrudan modelinize sorunu tanımlayabilirsiniz: Bu bir kullanıcıdır, bu da içeriğidir; bu kullanıcı benzer içerikleri geçmişte sevmiştir, diğer kullanıcılar da bu içerikle olumlu geri bildirimde bulunmuştur - şimdi lütfen, bu içeriğin bu kullanıcıya önerilip önerilmemesi gerektiğini belirleyin.
Dil modelleri zaten anlama yeteneğine sahiptir ve hangi bilgilerin önemli sinyaller olduğunu kendi başlarına değerlendirebilir, bu sinyalleri nasıl bir araya getirerek karar vereceklerini anlayabilirler. Bu anlamda, sadece öneri kurallarını uygulamakla kalmazlar, önerileri "anlamaya" çalışırlar.
Bu yeteneğin kaynağı, LLM'lerin (Büyük Dilsel Modellerin) eğitim aşamasında çok büyük ve çok çeşitli verilerle karşılaşması ve bu sayede ince ancak önemli desenleri yakalama olasılığının daha yüksek olmasıdır. Karşılaştırıldığında, geleneksel öneri sistemleri mühendislerin bu desenleri açıkça sıralamasına bağlıdır ve bu desenlerden biri kaçırılırsa model bunu algılayamaz.
Arka uç perspektifinden bakıldığında bu değişiklik yeni değildir. GPT'e bir soru sorduğunuzda, bağlam bilgilerine dayanarak bir yanıt ürettiğini görebilirsiniz. Aynı şekilde, "Bu içeriğe ilgilenir miyim?" diye sorduğunuzda da mevcut bilgiler temelinde bir karar verebilir. Bütün bunlardan dolayı, dil modellerinin kendileri, belli bir ölçüde doğuştan "öneri" yeteneğine sahiptir.