










Bu senaryoyu hayal edin:
Bir AI Agent'ı bir kod hatasını düzeltmek için yardım etmeye ikna ettiniz. Agent projeyi açtı, 20 dosyayı okudu, bazı değişiklikler yaptı, testleri çalıştırdı, geçemedi, tekrar değiştirdi, tekrar çalıştırdı, yine geçemedi... Onlarca tur döndü, nihayetinde—hâlâ düzeltmedi.
Bilgisayarınızı kapatıp bir nefes aldınız. Sonra API faturasını aldınız.
Yukarıdaki rakamlar sizi ürkütücü bulabilir—AI Agent'in yurt dışı resmi API altında kendi kendine hata düzeltmesi yapması, düzeltilmemiş bir görevde sıklıkla milyonlarca Token tüketir ve maliyeti onlarca ila yüzlerce dolar olabilir.
Nisan 2026'da, Stanford, MIT ve Michigan Üniversitesi gibi kurumların ortaklaşa yayınladığı bir araştırma makalesi, AI Agent'ların kod görevlerindeki "tüketim siyah kutusunu" ilk kez sistematik olarak açtı—para nerede harcanıyor, harcama değerli mi, önceden tahmin edilebilir mi? Cevaplar şaşırtıcıydı.
Keşif 1: Agent'in kod yazma maliyeti, normal AI sohbetinin 1000 katı.
Herkes, AI'nın kod yazmanıza yardımcı olmasının ve AI ile kod hakkında konuşmanızın aynı miktarda para harcamanızı gerektirdiğini düşünebilir.
Verilen makale karşılaştırmayı göstermektedir:
Agentic kodlama görevlerinin token tüketimi, normal kod soru-cevap ve kod çıkarım görevlerinin yaklaşık 1000 katıdır.
Tamamen üç basamak fark var.
Neden böyle? Makale, paranın “kod yazmak” üzerine değil, “kodu okumak” üzerine harcandığı gerçeğini ortaya koyuyor.
Buradaki “okuma”, insanın kod okuması anlamına gelmez; Agent, çalışma sürecinde projenin tüm bağlamını, geçmiş işlemlerini, hata mesajlarını ve dosya içeriklerini bir anda modele “besler”. Her bir diyalog döngüsüyle bu bağlam bir adım daha uzar; model ise Token sayısıyla ücretlendirilir—daha fazla beslerseniz, daha fazla ödersiniz.
Bir örnek verelim: Bu, bir tamirciyi çağırıp, her anahtar döndürmeden önce binanın tüm planlarını ona baştan sona okumanıza benzer—planları okumak için ödediğiniz para, vidayı sıkmaktan çok daha pahalıdır.
Bu fenomeni bir cümleyle özetliyor: Agent maliyetini tetikleyen, çıktı Token'larının değil, girdi Token'larının üssel artışıdır.
İkinci Keşif: Aynı hata, iki kez çalıştırıldığında maliyet iki kat fark edebilir—ve daha pahalı hatalar daha kararsızdır.
Daha da zorlayıcı olan rastgelelik.
Araştırmacı, aynı Agent'ı aynı görevde 4 kez çalıştırdı ve şunu buldu:
- Farklı görevler arasında, en pahalı görev, en ucuz görevden yaklaşık 7 milyon token daha çok yakmaktadır (Şekil 2a).
- Aynı modelde ve aynı görevde yapılan birden fazla çalıştırma arasında en pahalı işlem, en ucuz işlemin yaklaşık iki katıdır (Şekil 2b).
- Ancak aynı görev için farklı modeller arasında karşılaştırma yapıldığında, en yüksek ve en düşük tüketim arasında hasta 30 kat fark olabilir.
Özellikle dikkat edilmesi gereken son rakam: Bu, doğru modeli seçmek ile yanlış modeli seçmek arasındaki maliyet farkının “biraz daha pahalı” değil, “bir sıralık daha pahalı” olduğu anlamına gelir.
Daha da acı verici olanı—daha çok harcamak, daha iyi yapmak anlamına gelmez.
Araştırma, bir “ters U şekli” eğrisi keşfetti:
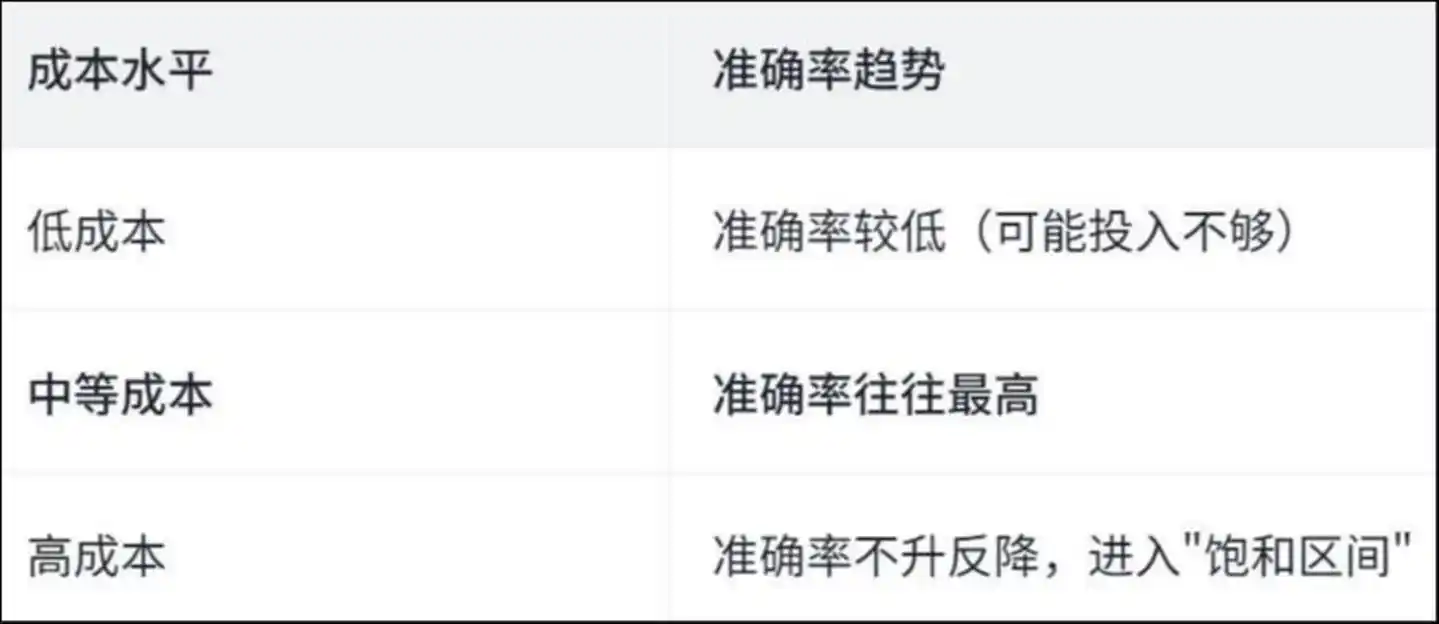
Maliyet seviyesi doğruluk eğilimi: Düşük maliyette doğruluk düşük (muhtemelen yeterli yatırım yapılmamıştır); orta maliyette doğruluk genellikle en yüksektir; yüksek maliyette doğruluk artmaz, aksine düşer ve "doyma aralığına" girer.
Neden böyle oldu? Makale, Agent'in özel işlemlerini analiz ederek cevabı veriyor—
Yüksek maliyetli operasyonlar sırasında, Agent çok fazla zamanı "tekrarlayan işlerde" harcıyor.
Araştırmalar, yüksek maliyetli işlemlerde dosya görüntüleme ve dosya düzenleme işlemlerinin yaklaşık %50'sinin tekrarlandığını gösteriyor—yani, Agent aynı dosyayı tekrar tekrar okuyor, aynı kod satırını tekrar tekrar değiştiriyor, sanki biri bir odada dairesel bir yol izliyor, ne kadar dönerse o kadar başı dönyor.
Para sorunu çözmek yerine, kaybolmaya harcandı.
Keşif 3: Modeller arasında "verimlilik oranı" büyük farklılıklar var—GPT-5 en az enerji tüketen, bazı modeller ise 1,5 milyon token daha fazla tüketiyor
SWE-bench Verified (500 gerçek GitHub sorunu) endüstri standardında, 8 ileri büyük modelin Agent performansı test edildi. Dolar cinsinden hesaplandığında, token verimliliği yüksek modeller her görevde onlarca dolarlık fark yaratıyor. Kurumsal uygulamalara getirildiğinde — günde yüzlerce görev çalıştırıldığında — bu fark gerçek para anlamına geliyor.
Daha ilginç bir bulgu, Token verimliliğinin görevden kaynaklanmayıp modelin "özgün karakteri" olmasıdır.
Araştırmacılar, tüm modellerin başarıyla çözdüğü görevleri (230) ve tüm modellerin başarısız olduğu görevleri (100) ayrı ayrı karşılaştırarak modellerin göreli sıralamasının neredeyse değişmediğini tespit etti.
Bu, bazı modellerin doğuştan "konuşkan" olduğunu ve görev zorluğuyla pek ilişkili olmadığını gösterir.
Daha derin bir düşünmeye yer veren bir bulgu daha: modelde "stop-loss bilinci" yok.
Tüm modellerin çözemeyeceği zor görevlerde, ideal bir Ajan, harcamayı sürdürmek yerine erken vazgeçmelidir. Ancak gerçeklik, modellerin başarısız görevlerde daha fazla Token tükettiğidir—onlar “pes etmez”, sadece keşfetmeye, yeniden denemeye ve bağlamı yeniden okumaya devam ederler; yakıt göstergesi olmayan bir araba gibi, tamamen bozulana kadar sürülürler.
Keşif Dört: İnsanlar için zor olan, Agent için mutlaka pahalı değildir—zorluk algısı tamamen yanlış yönlendirilmiş
Belki şöyle düşünüyorsunuz: En azından görevin zorluğuna göre maliyeti tahmin edebilirim, değil mi?
500 görevin zorluğunu değerlendirmek için insan uzmanları çağrıldı ve bunlar, Agent'in gerçek token tüketimiyle karşılaştırıldı—
Sonuç: İkisi arasında zayıf bir ilişki var.
İnsanlar için çok zor görünen görevler, Agent için belki de kolay ve düşük maliyetli olabilir; insanlar için kolay görünen görevler ise Agent için hayatın anlamını sorgulatacak kadar pahalı olabilir.
Çünkü insanlar ve AI'nın "gördüğü" zorluk tamamen farklıdır:
- İnsanlar şunları göz önünde bulundurur: mantıksal karmaşıklık, algoritma zorluğu, iş anlama engeli
- Ajan şunları göz önünde bulundurur: projenin boyutu, kaç dosyanın okunması gerektiği, keşif yolunun uzunluğu ve aynı dosyanın tekrar tekrar değiştirilip değiştirilmeyeceği.
Bir insan uzmanı "sadece bir satırı değiştir" diyorsa, Agent bu satırı bulmak için tüm kod tabanının yapısını anlamak zorunda kalabilir—sadece "okumak" bile büyük miktarda Token tüketir. Bir insan için "mantığı karmaşık" görünen bir algoritma sorunu ise, Agent'in tam olarak standart çözümü bildiği ve bunu hızla çözdüğü durumlar olabilir.
Bu, geliştiricilerin Agent'in çalışma maliyetini tahmin etmenin neredeyse imkânsız olduğu bir duruma yol açıyor.
Keşif Beş: Model bile kendi ne kadar harcayacağını tam olarak hesaplayamıyor.
İnsanlar tahmin edemiyorsa, AI'nın kendi kendine tahmin etmesini sağlamalı mıyız?
Bir araştırmacı, Agent'in gerçek hata düzeltmesini yapmadan önce kod deposunu "incelemesini" ve ne kadar Token tüketeceğini tahmin etmesini sağlayan ince bir deney tasarladı—ancak düzeltmeyi gerçekleştirmeden.
Sonuçlar nasıl?
Tüm modeller, tamamen imha edildi.
En iyi sonuç, Claude Sonnet-4.5'in çıktı Token'ları ile ilgili tahmin ilişkisi oldu — 0,39 (maksimum 1,0). Çoğu modelin tahmin ilişkisi yalnızca 0,05 ile 0,34 arasında, Gemini-3-Pro ise en düşük olan 0,04 ile neredeyse rastgele tahmin seviyesinde.
Daha da absürd olan, tüm modellerin kendi Token tüketimlerini sistematik olarak düşük tahmin etmeleridir. Şekil 11'deki saçılım grafiğinde, neredeyse tüm veri noktaları “mükemmel tahmin çizgisinin” altında yer alıyor—modeller, “o kadar çok harcamayacaklar” diye düşünüyorlar, ancak aslında daha fazlasını harcıyorlar. Bu alt tahmin eğilimi, örnek sağlanmadığında daha da şiddetli hale geliyor.
Daha da ironik olan—tahmin etmek için de para harcamak gerekir.
Claude Sonnet-3.7 ve Sonnet-4'ün tahmin maliyeti, görevin kendi maliyetinin iki katından bile fazla olabilir. Yani, bunlara önce "bir fiyat tahmini yaptırmak", doğrudan işi yapmaktan daha pahalıdır.
Tezin sonucu doğrudan şudur:
Şu anda, öncü modeller, kendi Token tüketimlerini doğru bir şekilde tahmin edemiyor. "Agent'ı Çalıştır" butonuna tıklayın, bu bir karanlık kutu açmak gibi—fatura geldiğinde ne kadar harcandığını öğrenirsiniz.
Bu “karışık hesap”ın ardında, daha büyük bir endüstri sorunu gizli.
Bunu okuduktan sonra, bu bulguların işletmeler için ne anlama geldiğini sorabilirsiniz.
"Aylık abonelik" fiyatlandırma modeli, Agent tarafından çatlaklarla açılıyor
Makale, ChatGPT Plus gibi abonelik modellerinin, normal diyalogların token tüketiminin nispeten kontrol edilebilir ve öngörülebilir olmasından dolayı işleyebilmesini açıklıyor. Ancak Agent görevleri bu varsayımı tamamen bozuyor—bir Agent döngüye girdiğinde bir görev milyonlarca token tüketebilir.
Bu, Agent senaryoları için saf abonelik fiyatlandırmasının sürdürülebilir olmayabileceğini ve ücretlendirme modelinin oldukça uzun bir süre boyunca en gerçekçi seçenek olarak kalacağını anlamına gelir. Ancak按量计费 sorunu, kullanım miktarının kendisinin önceden tahmin edilemez olmasıdır.
2. Token verimliliği, model seçiminin "üçüncü ölçütü" olmalıdır.
Geleneksel olarak şirketler, model seçerken iki boyuta bakar: yetenek (yapabilir mi) ve hız (hızlı mı yapar). Bu makale, üçüncü, eşit derecede önemli bir boyutu sunuyor: verimlilik (başarmak için ne kadar harcar).
Biraz daha zayıf ancak üç kat daha verimli bir model, ölçeklenebilir senaryolarda "en güçlü ama en pahalı" modele göre daha ekonomik değer sağlayabilir.
3. Ajan, "yakıt göstergesi" ve "fren" gerektirir.
Makale, dikkat edilmesi gereken bir gelecek yönünü belirtiyor: Bütçe bilinçli araç kullanım politikaları. Basitçe ifade edilirse, bu, Ajan'a bir "yakıt göstergesi" takmak: Token tüketimi bütçeye yaklaşırken, sonuna kadar harcamadan geçersiz araştırmaları zorunlu olarak durdurmak.
Şu anda, hemen hemen tüm ana akım Agent çerçevelerinde bu mekanizma yoktur.
Agent'in "para yakma sorunu", bir hata değil, sektörün geçmesi gereken bir acı.
Bu makale, bir modelin eksikliğini değil, AI'nın “tek soru-tek cevap”tan “kendi kendine planlama, çok adımlı yürütme, tekrarlı hata ayıklama”ya geçişinde ortaya çıkan Agent paradigmalarının yapısal zorluklarını ortaya koyuyor—Token tüketiminin öngörülemeyenliği neredeyse kaçınılmazdır.
İyi haber, bu karışık hesaplamayı ilk kez sistematik bir şekilde ortaya çıkaran biri var. Bu verilerle geliştiriciler, model seçimi, bütçe belirleme ve zarar durdurma mekanizmaları tasarımı konusunda daha bilinçli kararlar verebilecek; model sağlayıcılar ise sadece daha güçlü değil, aynı zamanda daha verimli olma yönünde yeni bir iyileştirme yönü elde edecek.
Aslında, AI Agent'ların gerçek üretim ortamlarına girmesinden önce, her satır kodun güzel yazılmasından daha önemli olan, her kuruşun açık bir şekilde harcanmasıdır. (Bu makale ilk kez Titanium Media APP'de yayınlandı, yazar | Silicon Valley Tech news, editör | Zhao Hongyu)
Not: Bu yazı, 24 Nisan 2026 tarihinde arXiv'de yayınlanan *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei) başlıklı ön baskı makalesine dayanmaktadır. Yazarlar Virginia Üniversitesi, Stanford Üniversitesi, MIT, Michigan Üniversitesi gibi kurumlardan gelmektedir. Bu araştırma henüz hakemli değerlendirme geçmemiştir.