










Yazar: Her zaman yolda olan Max, 01Founder
OpenAI'nin 2025 yılı için bir aşama özeti yazmak isteyenler, büyük olasılıkla bunu sade ve hatta biraz pasif olarak tanımlayacaktır.
Geçen yılın başından beri, mantıksal çıkarım yolunu adım adım tamamladılar ve o3pro'dan o4mini'ye kadar olan çıkarım modellerini yoğun bir şekilde yayınladılar, aynı zamanda GPT-4.5 ve GPT-5 gibi tamamen yeni temel modelleri de sundular.
Ancak genel kullanıcıların en kolay fark edebileceği ve kendi kendine yayılmasını sağlayabileceği görsel üretim alanında varlıkları yavaş yavaş azalmaktadır.
Sora'nın ilk çıkışından sonra şokun geçmesinin ardından, OpenAI bu alanda uzun bir sessizlik dönemine girmiş gibi görünüyor.
Bu arada, masadaki diğer oyuncular da boş durmuyordu.
Açık kaynak ekosisteminde, Flux gibi modeller kaliteli yerel görüntü üretiminin engellerini tamamen ortadan kaldırdı;
Ticari alanda, eski rakipler sadece mükemmel estetik bir engel oluşturmakla kalmıyor, aynı zamanda Nano-banana gibi doğrudan internet arama özelliği bulunan yeni nesil oyuncular da ortaya çıkıyor.
Buna karşılık, OpenAI'nin önceki ana görsel oluşturma modeli GPT-Image-1.5 zaten eski görünüyor:
Kalite düşük, düzenlemeler sert ve karmaşık metinlerde sıklıkla çöker.
Yavaş yavaş sektörde bir uzlaşının oluştuğu:
OpenAI, görsel üretme alanında teknik bir sırıkla karşılaştı ve tüm rakiplerin kuşatmasında güçsüz kalıyor.
Birkaç hafta önce, dönüşüm çok gizli bir şekilde ortaya çıktı.
Ünlü büyük dil modeli gizli test platformu LM Arena'da, Duct Tape (bant) kod adlı gizemli bir görüntü modeli sessizce yer aldı.
Kör teste katılan kullanıcılar hemen durumun yanlış olduğunu fark etti:
Bu model, aşırı en-boy oranlarına mükemmel bir şekilde hakim olmanın yanı sıra, çok sayıda çok dilli metin içeren düzenlemeli afişleri kusursuz bir şekilde üretiyor ve görüntü üretmeden önce neredeyse gizli bir mantıksal planlama süreci var gibi görünüyor.
Bir süre boyunca çeşitli teknik topluluklar bunun hangi şirketin gizlice çıkardığı büyük bir yenilik olduğunu tahmin etti, ancak OpenAI tarafı sessizliğini korudu.
Bu sabah, sonunda ayakkabılar yere düştü.
Uzun bir sunum olmadan, yoğun bir pazarlama hazırlığı olmadan, OpenAI bu şifre adı “tape” olan modeli resmen ChatGPT GPT-Image-2 olarak adlandırdı ve piyasaya sürdü.
Aynı zamanda, biraz nefes kesici bir Text-to-Image yarışma sıralaması da duyuruldu.
GPT-Image-2, 1512 puanla doğrudan birinci sıraya yükseldi ve ikinci sırada yer alan (çevrimiçi arama özelliğine sahip) Nano-banana-2’yi 242 puanla geride bıraktı.
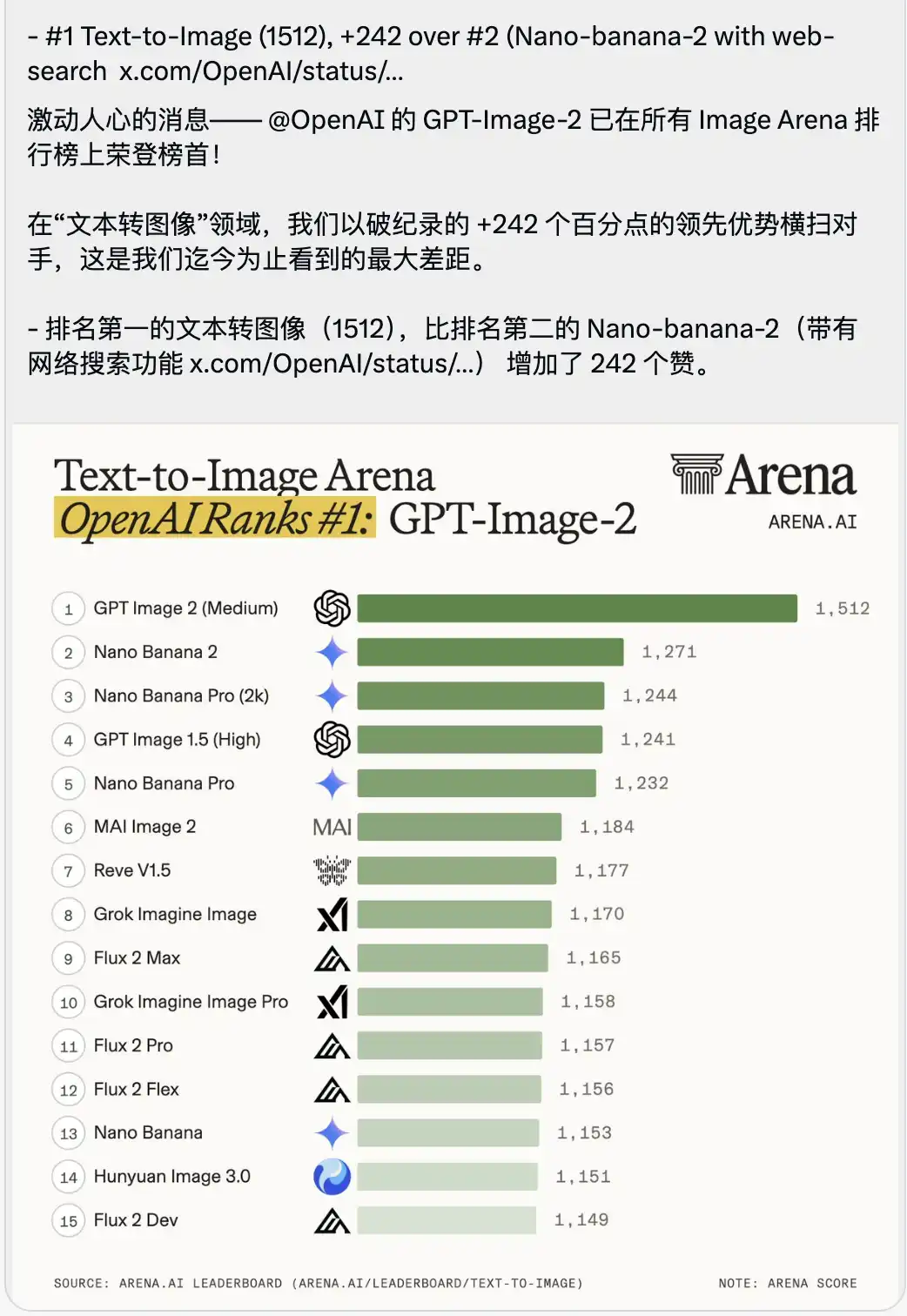
Büyük modellerin puanlama bağlamında, genellikle ondalık kesirler veya bir basamaklı sayılarla yapılan aşım büyük ölçüde vurgulanır; öncü modeller arasındaki puanlar son derece sıkı bir şekilde birbirine bağlıdır.
242 puanlık bir öncülük farkı, arena tarihinde hiç görülmemiştir.
Bu aslında küçük bir sürüm güncellemesi değil, bir hamleyle nesil farkıyla ezme.
Bir günün büyük bir kısmını, onun çeşitli sınırları ve en son API belgelerini dikkatlice incelemeye ayırdım.
Tek büyük his:
OpenAI hâlâ aynı OpenAI.
Yerini geri almaya karar verdiğinde, eski masayı doğrudan devirdi.
Bu modelin önünde, AI'nın tamamen yerini alması için hâlâ iki veya üç yıl daha gerektiğini düşündüğümüz görsel tasarım işleri bugün neredeyse sona erdi.
BÖLÜM.01 Görsel Üretim: Modelden Görsel Akıllı Ajanlara
GPT-Image-2'nin bu kadar büyük puan farkını nasıl yarattığını anlamak için, metinden görsel oluşturma modellerine ilişkin eski algıları bırakmanız gerekir.
Daha önce AI ile resim çizerken temelde karanlık kutu çekiyorduk, birkaç ipucu girip piksellerin istediğiniz şekilde dizilmesini bekliyorduk.
Ancak GPT-Image-2, görsel bir motorla entegre bir ajan gibi görünüyor.
En açık değişiklik, mekanizmasında tamamen farklı iki modu doğrudan ayırmış olmasıdır.
Bir tanesi tüm kullanıcılar için açık olan anlık moddur (Instant Mode).
Bu model, hızlı yanıt ve yaşam akışlarıyla sorunsuz entegrasyonu vurgular.
Örneğin, telefonunuzdan bir komut gönderdiğinizde, birkaç saniye içinde tam yapılandırılmış bir grafik sunar.
Alt düzey görsel anlama yeteneği çok güçlüdür, ancak ana olarak yüksek frekanslı, tek seferlik görsel dönüşüm ihtiyaçlarını çözer.
Ücretli kullanıcılar için açılan Düşünme Modu (Thinking Mode).
Bir tek piksel dahi render etmeden önce, onun onlarca saniye süren bir mantıksal çıkarım ve internet araması yapması gerekir.
Tam olarak bu model, son derece temel ancak son derece zor bir sorunu çözüyor:
Model, ilk kez gerçekten ne çizmesi gerektiğini bildi.
En açık örnek verelim.
Sohbet kutusuna girin:
İnternette Duct Tape adlı gizemli model hakkında insanların yorumlarını araştırın ve ChatGPT'nin QR kodunu ekleyin.

Eski modeli kullanırsanız,网民in ne söylediğini anlayamaz, sadece karışıksız metinlerle bir afiş çizer ve QR kodu taranamayan sahte bir görsel sunar.
Ancak düşünme modunda iş akışı şöyledir:
Öncelikle çizimi durduracak, internet arama aracını başlatacak ve Reddit, Threads veya LinkedIn üzerinde kullanıcıların gerçek yorumlarını toplayacaktır;
Ardından, afişin düzenini, boşluklarını ve yazı tipi hiyerarşisini planlamaya başladı;
Son olarak, doğrudan taranarak yönlendirilebilen gerçek ve kullanabilir bir QR kodu oluşturur ve tüm resmi render eder.

Bu artık bir çizim yapmak değil, aslında bağımsız olarak araştırmayı, planlamayı, metin çıkarmayı ve düzenlemeyi tamamen gerçekleştirmektir.
Burada bir paralel karşılaştırma yapılması gerekiyor.
Bağlantılı ve arama yeteneğine sahip görsel oluşturma modellerinin OpenAI tarafından icat edilmediğini büyük modeller topluluğu bilir.
İkinci sıradaki Nano-banana zaten bu mekanizmaya sahipti.
Ancak Nano-banana'yı gerçek hayatta kullandığınızda, bunun birçok yerde biraz aptalca olduğunu fark edeceksiniz.
Nano-banana'nın düşünceleri genellikle mekanik bir birleştirme mantığıdır.
Örneğin ona bir sektör trendini aratıp bir afiş yapmasını istesek, gerçekten arıyor ama genellikle Wikipedia’dan cümleleri sadece kopyalayıp zorla ekliyor.
Soyut ticari talepleri yorumlamayı gerektiren talimatlarla karşılaştığında kolayca şaşkına düşer.

Bu his, konuşmayı anlayan ama tamamen deneyimsiz bir stajyerin hissidir; uygulama yapmayı bilir, ancak stratejiyi tamamen anlayamaz.
Ancak GPT-Image-2'nin bu alandaki performansı, abartıyla tarif edilebilir.
Düşünmesi sadece bir formality değil, arka plandaki kültürel bağlamı ve ticari niyeti gerçekten anladı.
Test sırasında çok basit bir Çince komut girdim: Bana Elon Musk'ın Douyin'de doubao satışı yaptığı bir ekran görüntüsü çizin.
Eski bir resim modeli kullanırsanız, muhtemelen elinde bir baozi tutan,馬斯克'e benzeyen bir beyaz adam çizecek, arka plan bulanık olacak ve TikTok'un nasıl göründüğünü bile bilmiyor olacak.
Ancak düşünme modunda, GPT-Image-2'nin verdiği sonuçlar biraz korkutucu hissettiriyor.
Bu, öğeleri basitçe bir araya getirmekle kalmadı, Çin interneti hakkındaki anlayışını kendi kendine kullanarak TikTok canlı yayın arayüzünün piksel düzeyinde bir kopyasını oluşturdu.
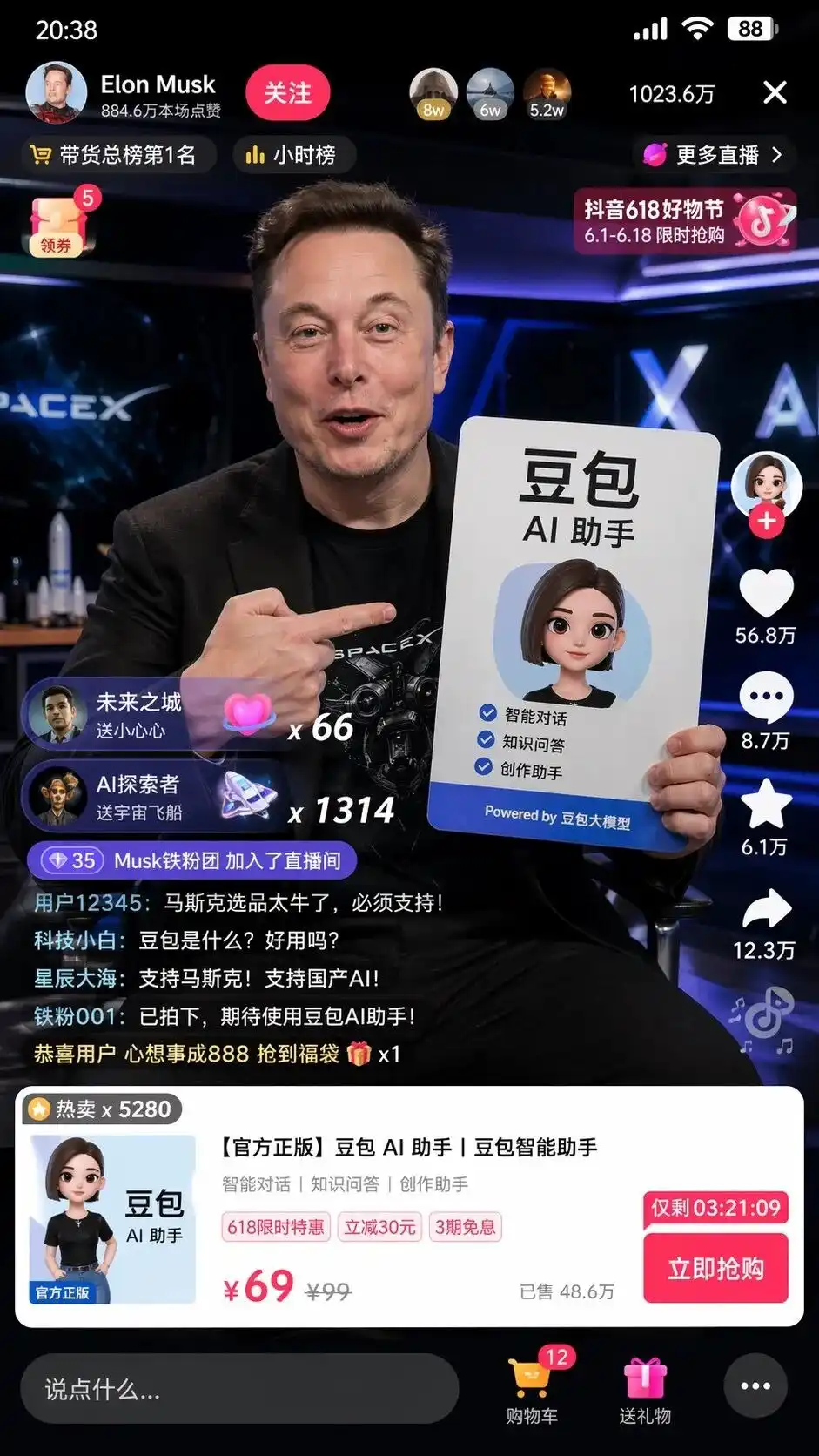
Ekran üzerinde, mükemmel bir şekilde düzenlenmiş Doudou AI asistanı reklam panosunu tutan gerçekçi bir Musk değil, aynı zamanda talimatlarda yer almayan daha korkutucu detaylar da bulunuyor:
Sol üstteki takip butonu, saatlik sıralama, sağ üstteki 10.236 milyon çevrimiçi kullanıcı, alttaki açılan standart ürün kartı ve çizgili fiyat 99, indirimli fiyat 69 ile sayaçlı Hemen Al butonu belirtilmiştir.
Sol alt köşede süren gerçekçi yorumlar en çok ürpertici:
Teknolojiye yeni başlayanlar: Dǒubāo nedir? Kullanışlı mı?
Yıldızlar ve Denizler: Musk'u destekleyin! Yerel AI'yi destekleyin!
Kimse ona yorumların ne yazılması gerektiğini, ürün arayüzünün nasıl görünmesi gerektiğini veya fiyatların nasıl belirlenmesi gerektiğini söylemedi.
Bu, Douyin ticaret ve DouBao büyük model etiketlerini analiz ettikten sonra insan beyni için tam bir ticari UI tasarımı ve operasyon planı oluşturup uygulayan bir modeldir.
Büyük modellerin görsel oluşturmada değerlendirilme kriterleri, şimdiye kadar sadece güzel çizip çizememe üzerine odaklanırken, strateji ve düzen mantığını anlama düzeyine geçiş yapmıştır.
BÖLÜM.02 Temel Yeteneklerin Gerçek Testi
Onun alt sınırını ölçmek için ticari tasarım standartlarına uygun olarak birkaç yüksek frekanslı ve karmaşık senaryo denedim.
Sonuç olarak, sorunu çözme düzeyinin korkutucu derecede detaylı olduğu ortaya çıktı.
İlk senaryo: Görsel anlama ve iş döngüsü (modelin giysileri giydirilmesi)
Geleneksel e-ticaret görsellerinde veya modaya yönelik planlamalarda, bir fikirden giyim etkisine ulaşana kadar yürütme maliyeti çok yüksektir.
Model arıyorsunuz, giysileri ödünç alıyorsunuz, stüdyo kuruyorsunuz, sonrası düzenlemeler yapıyorsunuz.
Daha sonra AI ortaya çıktığında, insanlar karakter yüzünü sabitlemek için LoRA modellerini eğitmeye başladı, ancak bu hâlâ onlarca resimlik bir malzeme ve yüksek bir öğrenme maliyeti gerektiriyordu.
GPT-Image-2'de bu süreç maksimum düzeyde sıkıştırılmıştır.
Kendimden günlük bir selfie yükledim ve gelecek ay adaya tatil yapacağımı söyledim, bana birkaç kıyafet önermesini istedim.
Önce bana tamamen farklı stillerde 8 set yazlık kıyafet kataloğu sundu, düzenlemesi profesyonel bir e-ticaret Lookbook gibi görünüyordu ve her bir ürünün yanında doğru metin etiketleri bile yer alıyordu.
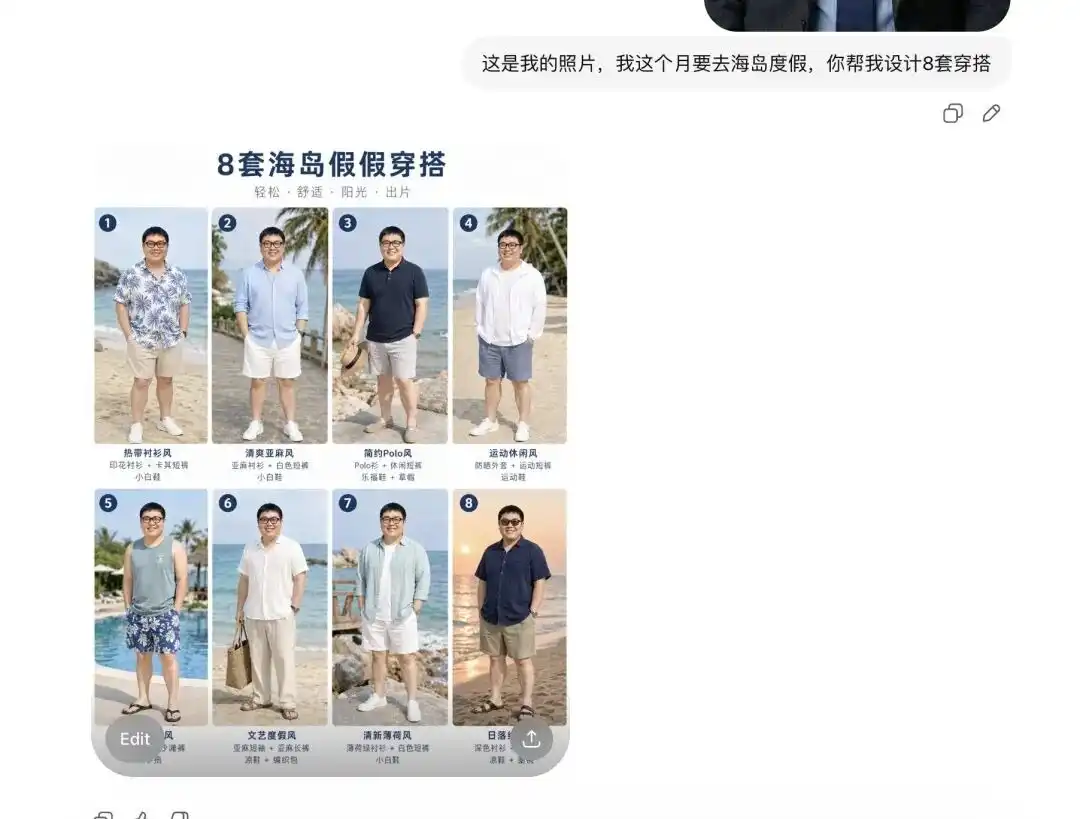
Daha da önemlisi, bu anında yüz özelliklerimi ve vücut oranlarımı tam olarak analiz etti.
İlk takımı giydirilmiş halini görmek ve farklı açıdan detaylı resimler istedim diye söylediğimde, doğrudan kendi selfi resmimdeki kişiyi çıkartıp üzerine yazılan yazıyı giydirdi ve yan, yarım vücut gibi farklı açılarda resimler üretti.

Bu dönüşüm çok sorunsuz oldu. Bu, temel giyim kombinasyonları için görselleştirme veya dışarıya verilen model deneme işlerinin rekabet avantajının tamamen ortadan kalktığı anlamına gelir.
İkinci senaryo: Tutarlılık ve sürekli hikâye çözümü (bir cümleyle komik strip üretme)
AI ile resim oluşturan herkes, AI'nın güzel bir resim çizmesinin kolay olduğunu, ancak aynı kişinin on resmini, hareket ve açı açısından tutarlı şekilde çizmesinin zor olduğunu bilir.
Bu, denilen tutarlılık (Consistency) sorunudur.
Ancak bu gerçek testte, geçmiş deneyimlere tamamen aykırı bir durum gördüm.
Dün arkadaşınla çekilmiş bir fotoğraf yükleyebilir ve çok basit bir ipucu girebilirsiniz:
İki bizi ana karakter yapın, üç sayfalık üç Japon mangası çizin, sen senaryoyu belirleyin
Birkaç saniye sonra, standart bir panel düzenine sahip siyah-beyaz bir komik kitabı üç sayfa olarak doğrudan çıktı verdi.
En korkutucu taraf, bu iki gerçek yaşamdan türetilen karikatür karakterinin üç sayfalık farklı sahnelerde yer alması.

Yakın çekim, uzak çekimde koşuş, arka görünüm veya hatta yüz özellikleri, saç detayları ve giysilerdeki katlar, tümüyle mükemmel bir tutarlılıkla korundu.
Daha da çarpıcı olan, komik serisinin hikayesinin tamamen tutarlı olması ve hatta diyalog kutularındaki metinlerin bile tam bir hikaye mantığı oluşturması.

Zaman ve mekân tutarlılığını sağlayabiliyor olması, tek bir görüntü üretmenin ötesine geçerek sürekli bir hikâye anlatma yönünde bir yönetmenlik yeteneğine sahip olduğunu gösterir.
Üçüncü senaryo: Metin işleme son engelini aşmak (çok dilli düzenlemesi)
Eğer tutarlılık hikâye sorununu çözdüyse, çok dilli metinlerin tam olarak görüntülenmesi, gerçek anlamda düzlem tasarımcılarını köşeye sıkıştırdı.
Daha önce resimde biraz metin varsa büyük model hemen garip çizgiler çizmeye başlıyordu.
Çünkü modelin anladığı metin Token'lar (anlamsal bloklar)ken, oluşturduğu görüntüler piksel noktalarıdır ve bunlar geçmişte birbirinden ayrıydı.
GPT-Image-2 bu sorunu tamamen çözdü.
Fransızca bir mod dergisi kapağı oluşturdu, tamamen hiragana ve kanji içeren bir Japon restoran menüsü yaptım ve hatta çok yoğun bir Rusça notlama denemesi yaptım.

Sonuç, tek seferde tamamlanmış ve hiçbir yazım hatası yoktur.
En umutsuz durum, sadece harfleri doğru yazmakla kalmıyor, aynı zamanda dilere göre yerel kültürel estetiği ve yazı tipi tasarımını da uyumlu hale getiriyor.
Örneğin, Japon broşüründeki kanji, çok yerel bir Japon复古 tipografisi kullanır ve hiragana düzenlemesi Japonca dikey okuma alışkanlıklarına uygundur.
Dizayn, önceki zamanlarda grafik tasarımcıların özel alanıydı.
Karakter aralıklarını ayarlamak, ana ve ikincil öğeleri ayırmak, metin ile arka plan arasında görsel denge kurmak için çok sayıda pratik gereklidir.
Ancak AI, bu kadar çok dili sıfır hata ile işleyebilir ve gelişmiş bir tipografi estetiğine sahipken, günlük afişler, broşürler ve bilgi akışı reklamları için artık elle referans çizgileri hizalamaya gerek kalmaz.
Dördüncü sahne: Deforme ekran oranı ve aşırı mikro kontrol (pirinç tanesi üzerine kazınan yazılar)
Son olarak, onun ne kadar uysal olduğunu görmek için ona çok zorlu bazı talimatlar verdim.
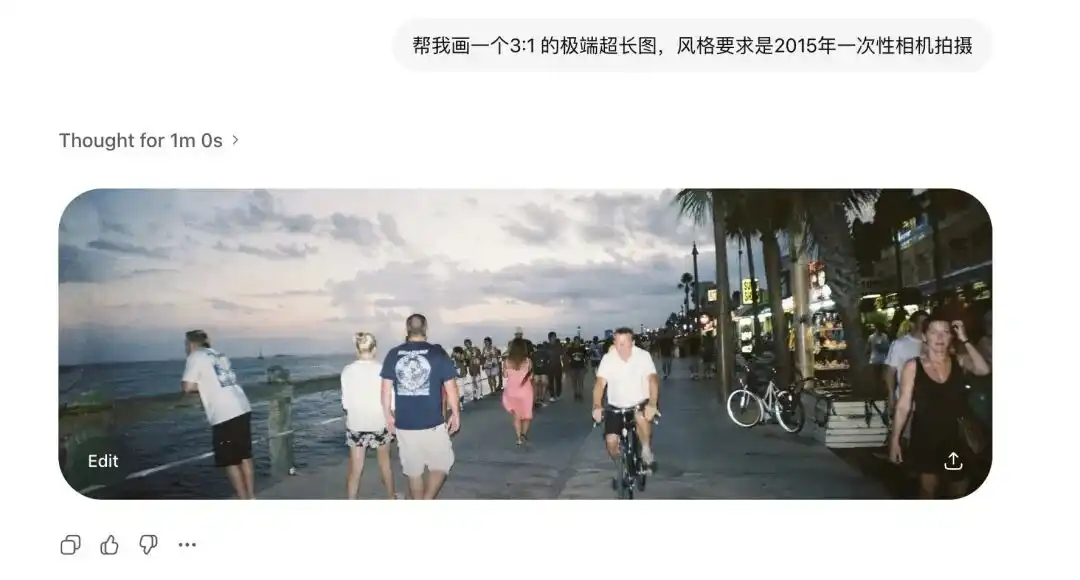
Öncelikle aşırı en-boy oranını test ettim.
Geleneksel yayılma modelleri, standart dışı oranlardan çok korkar.
Daha önce resmi biraz uzattığınızda, ekran üzerinde iki baş çıkardı.
Ancak Images 2.0'ye 3:1 genişlikte ve 1:3 boyutta dikey resimler oluşturmayı talep ettiğimde, bu resimler bozulmadı, hatta baştan sona kadar mantıksal bir döngü oluşturan 360 derece panaramik resimler üretti.
2015 yılında tek kullanımlık kamera ile çekilen maddeler eklendikten sonra, eski lenslerin bozulmaları ve flaşın duvarda yarattığı düşük kaliteli yansıma bile net bir şekilde ortaya çıkarıldı.
Ancak onun mikro kontrol gücünü daha iyi gösteren, resmi etkinlikte sergilenen biraz çılgın görünen pirinç tanesi testidir.
Araştırmacılar, halen iç testte olan deneysel 4K API'sini çağırdılar ve makro çekim, 8K ultra yüksek çözünürlük gibi herhangi bir tanımlayıcı ifade kullanmadılar; sadece son derece soyut bir basit talimat verdiler:
Bir yığın pirinç. Bu pirinç yığınının bir tanesinde GPT Image 2 yazıyor.
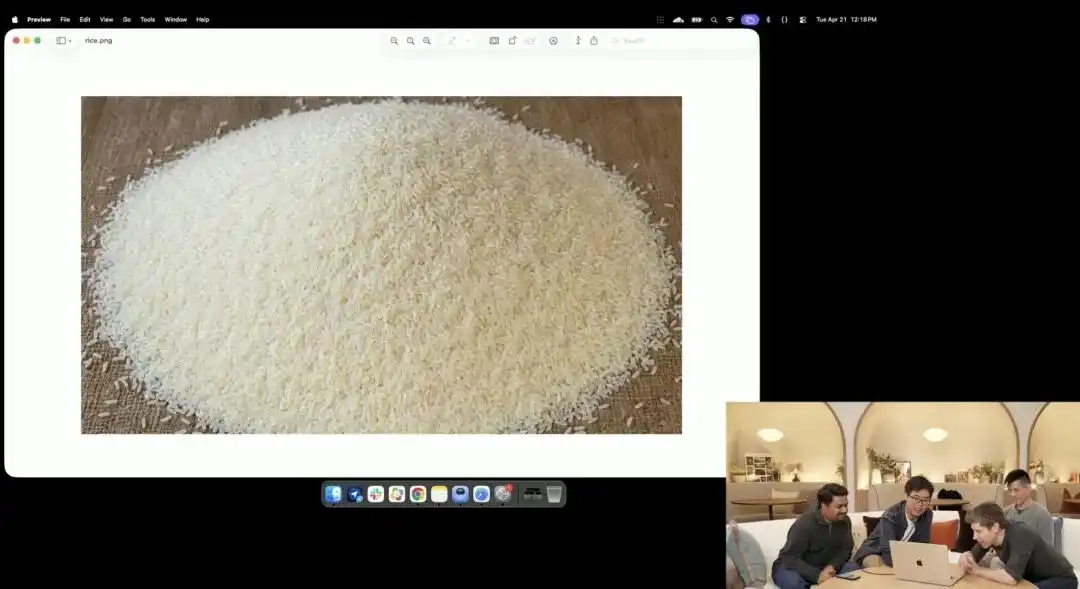
Ekran üzerinde görüntü yüzlerce kez büyütüldüğünde ve hatta piksel taneleri ortaya çıktığında, gerçekten bir çuval pirinç içinde yazılmış bir tanecik bulabilir misiniz?
Bu pirinç tanesinin dokusu hâlâ fizik yasalarına uyuyor ve metin, pirinç tanesinin küçük eğriliğine tam olarak uygun şekilde yüzeye gömülmüş.
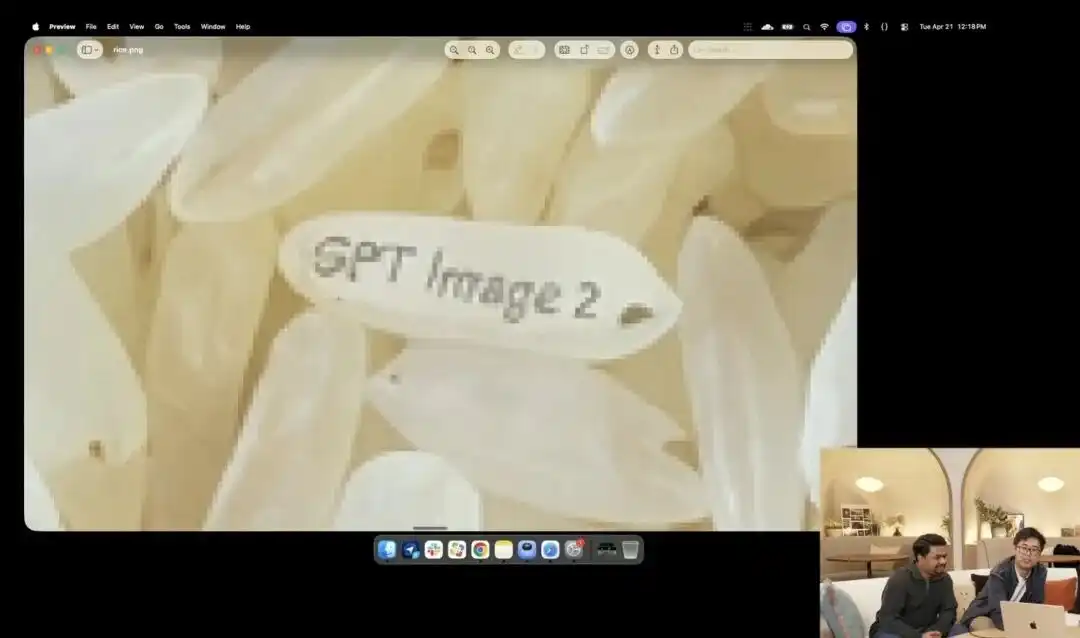
Kalan tüm işler—makro görünümü çağırma, derinlik odaklamayı hesaplama, gizli uzayda o tanecikin fiziksel koordinatını bulma ve harfleri bastırma—tümü büyük modelin düşünme modunda otomatik olarak tamamladı.
Bu örnek, modelin uzaysal konum anlayışının piksel düzeyinde cerrahi hassasiyete ulaştığını doğrudan göstermektedir.
Bu, artık gerçek işlerde tasarım dosyalarındaki herhangi bir küçük detayı hedefe yönelik olarak doğrudan değiştirebileceğiniz, eski gibi bir yaka değiştirmek isteyince tüm resmin değişmesi yerine anlamına gelir.
BÖLÜM.03 Bazı Teknik Detaylar
Bu aşırı kontrol gücü ve stratejik zeka, sadece hesaplama gücüne bağımlı olarak elde edilemez.
GPT-Image-2'nin elindeki kartların tam olarak ne olduğunu anlamak için bazı sondaj testleri gerçekleştirdim.
Çok ilginç bir nokta ortaya çıktı.
Resmi belgelerde GPT-Image-2'nin genel bilgi tabanının son tarihinin Aralık 2025'e kadar güncellendiği belirtilse de, gerçek testlerimde.
Hızlı Mod (Instant Mode) eğitim verilerinin son tarihi hâlâ 2024 yılının Mayıs ayı sonunda duruyor;

Ancak uzun düşünme modu (Thinking Mode), yerel bilgi tabanı yaklaşık olarak Haziran 2024'e kadar olan bilgileri içerir (ancak gerçek zamanlı internet bağlantısıyla güncel tarihi elde edebilir).

Bu iki zaman noktasından yola çıkarak, GPT-Image-2'nin temel yapısı görünür hale geliyor.
Öncelikle yüksek frekanslı görsel oluşturmaya odaklanan anlık modu açıklayalım.
Mayıs 2024 tarihli son teslim, doğrudan o4-mini'nin kullanıldığını veya GPT-5 ailesinden hafif bir versiyonun (GPT-5 mini veya hatta çok küçük parametreli GPT-5 nano) kullanıldığını göstermektedir.
Çünkü bu hafifletilmiş temel modeller, uzaysal planlama ve karmaşık komutları anlama yeteneğine zaten sahip olduğundan, üst düzey görüntü üretimi kararlı kalabilmektedir.
Ancak o son derece zeki ve ticari strateji anlayan düşünme modelinin temeli GPT-5 ana modeli olamaz.
Çünkü GPT-5'in temel bilgi tabanının son tarihi Eylül 2024'tür.
Düşünme modu, büyük olasılıkla arka planda sürekli olarak geliştirilen O serisi çıkarım modellerine (örneğin o4 veya güncellenmiş o3) entegre edilmiştir.
Büyük model, önce O serisine özgü uzun düşünme mekanizmasını kullanarak gizli uzayda ticari mantığı, hedef kitle psikolojisini ve düzenlemeye ait koordinatları tamamen hesaplar, ardından son piksel renderlaması için görsel modüle devredilir.
Elbette, başka bir olası yol da vardır:
OpenAI'nin içsel son derece ince hesaplama kaynakları ayarlama mekanizması altında, Hızlı Mod, temel olarak GPT-5 nano'yu doğrudan çağırabilirken, Düşünce Modu, biraz daha büyük olan GPT-5 mini'yi dış araçlarla birlikte çağırır.
Ancak hangi taban kombinasyonu olursa olsun, OpenAI'nin API ekosistemini sürekli takip edenler, temel üretme mantığının Midjourney ile tamamen farklı bir boyutta olduğunu fark eder.
BÖLÜM 04 Herkesin en çok ilgilendiği fiyatlandırma
Ancak temel tahmini yapmaktan daha önemli olan, bunu iş akışlarına entegre etmek isteyen geliştiriciler ve işletmeler için çok gerçekçi ve sezgiye aykırı bir API fiyat listesi.
DALL-E 3 önceki versiyonu görüntü başına ücretlendiriliyordu (örneğin, 0,04 dolar görüntü başına).
Ancak birinci nesil GPT-Image-1'den itibaren OpenAI, bunu tamamen token bazlı ücretlendirme modeline dönüştürdü.
Bu GPT-Image-2 de aynı standartı sürdürmekle kalmadı, aynı zamanda miktarı artırıp fiyatı düşürdü.
Resmi olarak yeni açıklanan fiyat listesine göre, her milyon Token fiyatı şöyledir.
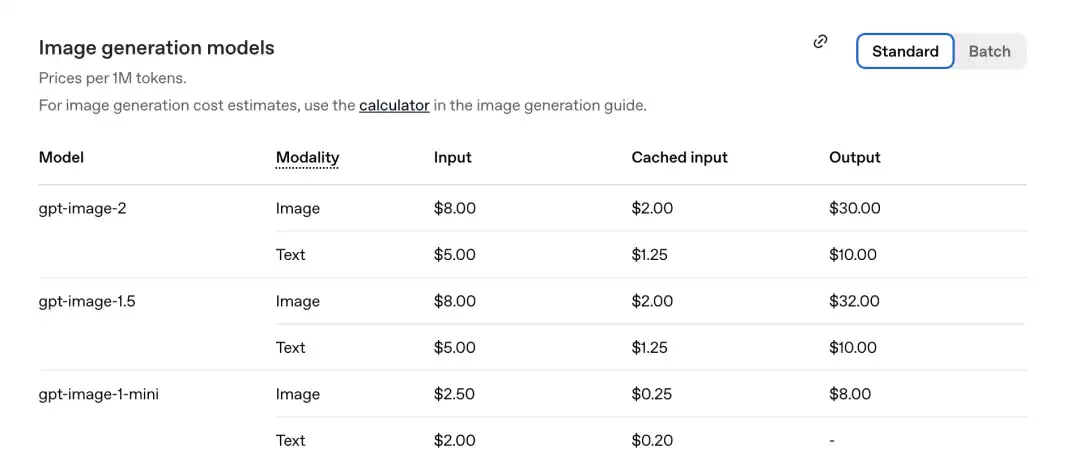
GPT-Image-2 Görüntü bölümü: Girdi 8,00, önbelleğe alınmış girdi (Cachedinputs) 2,00, çıktı $30,00.
Önceki nesil gpt-image-1.5 ile karşılaştırıldığında: çıktı $32.00.
Yeni model daha ucuz oldu.
Hadi bir hesap yapalım.
Önceki modellerde, kaliteli bir görüntü oluşturmak yaklaşık 1000 ila 1500 çıktı Token tüketiyordu.
Her milyon çıktı token için 30 dolar fiyatına göre, bir görselin üretim maliyeti yaklaşık 0,03 ile 0,045 dolar arasındadır (yaklaşık 2 ila 3 Çin yuanı).
Eğer anlık yanıt değil, resmi olarak sağlanan Batch (toplu işlem) API modunu kullanırsanız, bu fiyat doğrudan yarıya iner (çıktı $15,00'a düşer).
Bir resim oluşturmak için en az 10 kuruştan fazla maliyet çıkar.
Bu tekil fiyat zaten çok iyi bir fiyat/performans oranına sahip, ancak gerçek avantajı, fiyat tablosundaki önbelleklenmiş girdilerdir.
Daha önce komik kitaplar çizmek veya aynı serideki afiş tasarımları yaparken, her yeniden üretimde birçok karakter referans resmini, önceki özetleri ve uzun ipuçlarını tekrar yüklemeniz gerekirdi, giriş maliyeti çok yüksekti.
Ancak şu anki Token ücretlendirme modelinde, bir seferde 8 adet ardışık komik kitabı oluşturduğunuzda, ilk görselin görsel öğeleri doğrudan bağlam olarak önbelleğe alınır.
İkinci resimden itibaren, görsel girdi maliyeti doğrudan 8,00 $'dan 2,00 $'a düştü (yani sadece %25 ödeme alınıyor).
Bu, büyük ölçekli ticari toplu görsel üretimi veya yüksek karakter tutarlılığı gerektiren sürekli üretimi gerçekleştirirken marjinal maliyetinin doğrusal olarak düşeceğini anlamına gelir.
Model ne kadar akıllı ve ne kadar çok çizerse, başına düşen maliyet o kadar düşük olur.
Bu endüstriyel faturalama mantığı, gerçekten üretim hattı ressamlarını çaresiz duruma düşürecek şeydir.
BÖLÜM.05 Arka Plan Ekibi İncelemesi
Son olarak, canlı yayın etkinliğinde sunulan OpenAI iç görsel hayal ekipmanına tekrar bakalım; daha önce saçma gibi görünen birçok fonksiyon tamamen açıklanabilir hale geldi.
Örneğin, çok dilli karmaşık düzenlemeyi ve karalama sorunlarını tam olarak nasıl çözer.
Bu, ekipteki deneyimli bilim insanı Gabriel Goh sayesindedir.

Bu akademik dünyada, en ünlü kimliği, öncü çoklu modellilik modeli CLIP'in temel yazarıdır.
CLIP, insan dilini ve görsel pikseller arasındaki ilişkiyi anlamanın temelini oluşturdu.
Bu çok modlu semantik eşleme uzmanının liderliğinde, GPT-Image-2 artık metin şekillerini tahmin etmekten ziyade piksel düzeyinde gerçekten yazıyor.
Örneğin, üç boyutlu uzay ilişkilerini nasıl anlar, uç düzeyde uzunluk-genişlik oranlarında 360 derece panoramik görüntüler oluşturur ve pirinç tanesi üzerindeki mikroskobik ışık ve gölge etkilerini nasıl anlar?
Bu, diğer bir temel üyesi Alex Yu'ya borçludur.

OpenAI'ye katılmadan önce, 3D üretimi alanında önde gelen startup firması Luma AI'nın kurucu ortağı ve eski CTO'suydu ve 3D nöral rendering (NeRF vb.) konusunda uzmanlaşmış önde gelen bir akademisyendi.
O'nun varlığında, GPT-Image-2 aslında geleneksel 2D piksel boyama dışına çıkmıştır.
Muhtemelen zihninde önce üç boyutlu bir sahne oluşturup ışıkları ayarladıktan sonra size doğru bir 2D kesit render ediyor.
Nasıl yapıldı bu son derece korkutucu çok sayfalı manga tutarlılığı.
Bu, Massachusetts Institute of Technology (MIT CSAIL)’den yeni mezun olmuş genç ikiliye karşılık gelir:
Boyuan Chen (sol) ve Kiwhan Song (sağ).
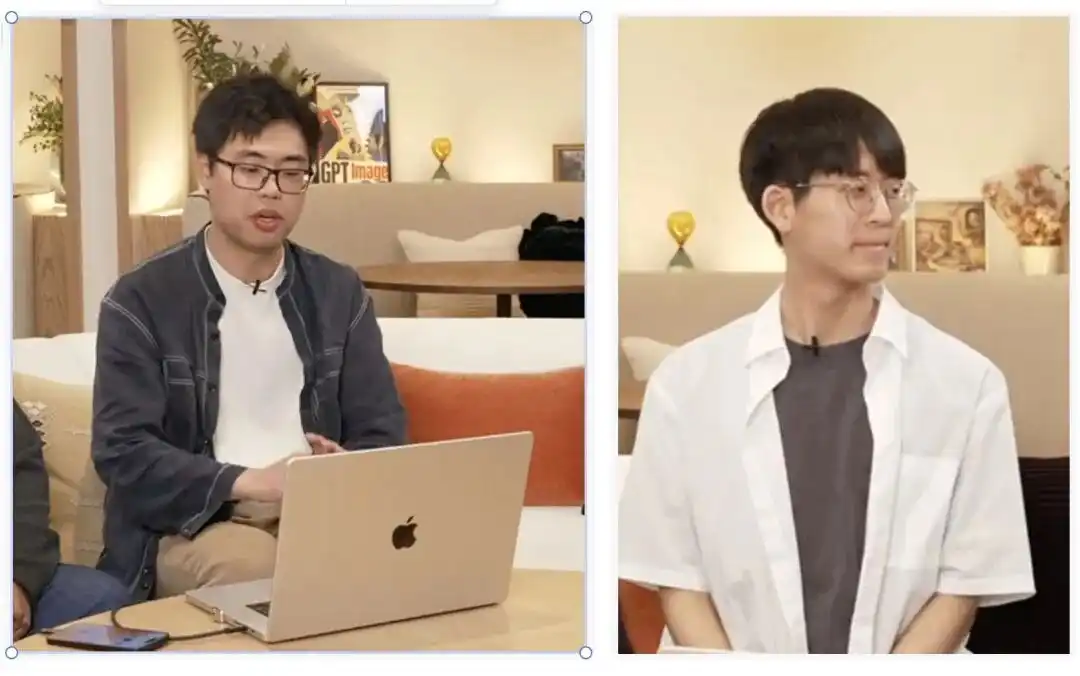
Akademik dünyada temel odak noktaları Dünya Modelleri ve Gövdeli Zeka'dır.
Makineye fiziksel dünyanın nasıl çalıştığını anlamayı öğretmek, karakterlerin farklı zamanlarda ve mekânlarda sahne geçerken özelliklerini tamamen koruyup bozulmamasını sağlamak, tam olarak bu iki akademisyenin çözmeye çalıştığı sorundur.
Son olarak, çıkarım büyük modelleri ile görsel temel mantığı birleştirmeye sürekli olarak çalışan Nithanth Kudige (sol, O serisi çıkarım modelinin önemli yazarı) ve Kenji Hata (sağ, önceki Google araştırmacısı, Stanford Görsel Laboratuvarı mezunu) eklenmiştir.

Bu insanlar bir araya geldiğinde, temel mantıksal çıkarım, 3D uzay renderi, görsel-metin mükemmel hizalama ve fiziksel dünya kuralları aynı modelde doğal olarak birleştirildi.
BÖLÜM.06 GPT-Image-2'nin Sınırı
Her modelin bir sınırı vardır.
Resmi kurum, bazı aşırı durumlarla başa çıkmakta hala zorlanıyor.
Örneğin, sıkı fiziksel uzay tersine çevirmeyi gerektiren katlama kılavuzları, rubik küpü çözme veya son derece yoğun kum taneleri gibi çok yüksek tekrarlı detaylar hala yetenek sınırlarına ulaşır.
Ancak ticari uygulamalar bağlamında bu, son derece küçük bir kusurdur.
Tasarım endüstrisi için endişe satmaya gerek yok, bu estetiğin sonunu değil.
Tadı olan, ticari bir görüşü olan ve stratejiyi anlayanlar, bunu kullanarak hâlâ harika şeyler yapabilir.
Ancak nesnel olarak gerçek olan, tasarımcının bir meslek olarak koruma duvarının temelden sarsıldığıdır.
Daha önce, tasarım yazılımlarının kısayollarını ezberleyerek, yazı tiplerini düzgünce hizalayarak, dillere göre düzenlemeyi bilerek ve ince görüntü düzenleme ile kesme işlemlerini yaparak geçimini sağlıyordu.
Ancak bundan sonra zorlaşacak, çünkü geçmişte açıkça fiyatlanıp ticaret edilebilen bu beceriler, şimdi herkesin bir cümleyle ücretsiz olarak çağırabileceği temel komutlara dönüştü.
Bir süre sessizlikten sonra, OpenAI çok sakin ama son derece etkili bir şekilde, bu masada gerçekten hangi elde asıl kartların bulunduğunu tekrar kanıtladı.
Eski yürütme araç zinciri kırılıyor ve endüstriye kalan soru, AI'nın bizi yerine geçip geçmeyeceği değil, bu tamamen yeni üretim hattına nasıl uyum sağlayacağımız.