










Yazar: KarenZ, Foresight News
20 Mart 2026'da, All-In Yatırım Podcast'inde olağan dışı bir diyalog yer aldı.
Yatırım uzmanı Chamath Palihapitiya, konuşmayı NVIDIA CEO'su Jensen Huang'a devretti ve Bittensor'da, dağıtılmış hesaplama gücüyle互联网 üzerinde tamamen merkezi olmayan bir şekilde, hiçbir merkezi veri merkezi katkısı olmadan büyük bir dil modeli eğitilen bir proje "oldukça çılgın bir teknik başarı" tamamladığını söyledi.
Huang Renxun kaçmadı. Bu olayı, 2000'lerde normal kullanıcıların boşta kalan hesaplama gücünü katkıda bulunarak protein katlanma sorununa ortak olarak karşı koyan dağıtık proje olan Folding@home'un modern bir versiyonuna karşı koydu.
Dört gün önce, 16 Mart'ta Anthropic ortak kurucusu Jack Clark, bir AI araştırma ilerlemesi raporunda bu başarıyı büyük ölçüde vurguladı ve aktarıldı: Bittensor ekosisteminin alt ağı Templar (SN3), 72 milyar parametrelik büyük model (Covenant 72B) için dağıtılmış eğitimini tamamladı ve model performansı, Meta'nın 2023'te yayınladığı LLaMA-2 ile karşılaştırılabilir.
Jack Clark, bu bölümü "Dağıtılmış Eğitimle AI Politik Ekonomisini Zorlamak" olarak adlandırdı ve analizinde bunun sürekli izlenmesi değerli bir teknoloji olduğunu vurguladı; cihaz üzerindeki AI'nın, merkezi olmayan eğitimle üretilen modelleri yaygın şekilde benimseyeceği ve bulut AI'nın ise özel büyük modelleri çalıştırmaya devam edeceği bir gelecek hayal edebiliyor.
Piyasa tepkisi hafif gecikmiş ancak çok şiddetli olmuştur: SN3, geçen ay %440'tan fazla, geçen iki haftada %340'tan fazla artmış ve piyasa değeri 130 milyon dolaara ulaşmıştır. Alt ağ hikayesi patlaması, doğrudan TAO'ya yönelik satın alma baskısına dönüşecektir. Bu nedenle TAO hızla yükselmeye başlamış, bir süre 377 dolar seviyesine ulaşmış, geçen ay iki katına çıkmış ve FDV'si yaklaşık 7,5 milyar dolara ulaşmıştır.
Sorular ortaya çıktı: SN3 tam olarak ne yaptı? Neden ışık altında bırakıldı? Dağıtık eğitim ve merkeziyetsiz AI'nın değer hikayesi nasıl gelişecektir?
O 72B modeli
Bu soruyu yanıtlamak için SN3'ün sunduğu sonuçlara dikkatle bakmak gerekir.
10 Mart 2026 tarihinde Covenant AI ekibi, arXiv üzerinde bir teknik rapor yayınlamak suretiyle Covenant-72B'nin eğitimini tamamladığını resmen duyurdu. Bu, 72 milyar parametreli büyük bir dil modelidir ve yaklaşık 1,1 trilyon token'lık bir veri seti üzerinde, her turda yaklaşık 20 düğümün senkronize olduğu 70'ten fazla bağımsız düğüm peer (her düğümde 8 adet B200) kullanılarak ön eğitim tamamlandı.
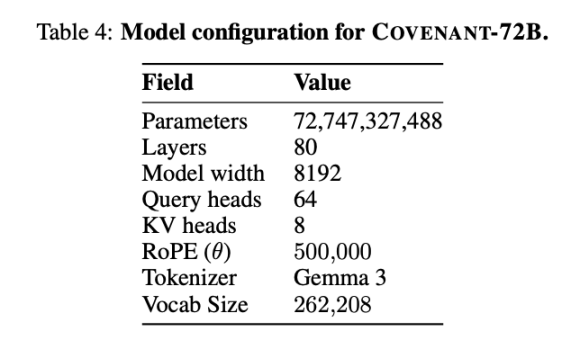
Templar, temel testler açısından bazı veriler sundu; tabii ki karşılaştırılan LLaMA-2-70B, Meta'nın 2023 yılında yayınladığı büyük modeldir. Anthropic ortak kurucusu Jack Clark'ın söylediğine göre, Covenant-72B 2026 yılında biraz eski kalabilir. Covenant-72B'nin MMLU'da elde ettiği 67,1 puan, Meta'nın 2023 yılında yayınladığı LLaMA-2-70B (65,6 puan) ile yaklaşık olarak karşılaştırılabilir.
2026 yılına ait ön plana çıkan modeller—GPT serisi, Claude veya Gemini—zaten yüz binlerce GPU üzerinde 100 milyardan çok parametreyle eğitildi; çıkarım, kodlama ve matematik yeteneklerindeki fark yüzde değil, sayısal bir düzeyde. Bu gerçek fark, piyasa duygularıyla bastırılmamalı.
Ancak "açık internet üzerindeki dağıtılmış hesaplama gücüyle eğitilmiş" varsayımına göre anlam tamamen farklılaşır.
Bir karşılaştırma yapalım: Aynı merkeziyetsiz eğitim yöntemiyle geliştirilen INTELLECT-1 (Prime Intellect ekibi, 10 milyar parametre) MMLU puanı 32,7; diğer bir dağıtılmış eğitim projesi olan Psyche Consilience (40 milyar parametre), beyaz listeli katılımcılarda 24,2 puan aldı. Covenant-72B, 72 milyar parametre ölçeği ve 67,1 MMLU puanıyla merkeziyetsiz eğitim alanında dikkat çekici bir rakam.
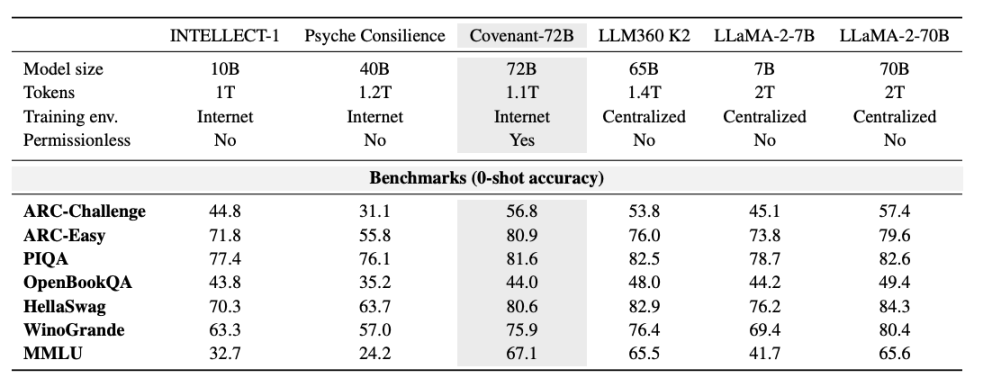
Daha da önemlisi, bu eğitim «izin gerektirmeyen» bir süreçtir. Herkes, önceden onay veya beyaz liste gerektirmeden katılım düğümü olarak bağlanabilir. Model güncellemesine, dünya çapında bağlantı kurarak 70'ten fazla bağımsız düğüm katılmıştır.
Huang Renxun ne dedi, ne dedi
Bu podcast diyaloğunun ayrıntılarını geri yüklemek, bu "destek" olayının dış dünyada nasıl yorumlandığını düzeltmeye yardımcı olur.
Chamath Palihapitiya, diyalogda Bittensor'un teknik başarılarını Huang Renxun'a sunarak, dağıtık hesaplama gücüyle bir Llama modelinin eğitildiğini ve sürecin "tamamen dağıtık, aynı anda durumu koruyan" olduğunu açıkladı. Huang Renxun'un yanıtı, bunu "modern Folding@home" olarak nitelendirmek ve açık kaynak ile özel modellerin paralel olarak var olmasının gerekçesini tartışmaktı.
Dikkat edilmesi gereken nokta, Huang Renxun'un Bittensor'un token'ını veya herhangi bir yatırım anlamını doğrudan bahsetmemesi ve merkeziyetsiz AI eğitimi hakkında daha fazla konuşmamasıdır.
Bittensor alt ağlarını ve SN3'i anlayın
SN3'ün patlamasını anlamak için önce Bittensor ve alt ağlarının çalışma mantığını anlamalısınız. Basitçe söylemek gerekirse, Bittensor, bir AI halka zinciri ve platformu olarak görülebilir; her alt ağ ise kendi özgün görevini, teşvik mekanizmasını tasarlayan bağımsız bir "AI üretim hattı" gibidir ve bunlar birlikte merkeziyetsiz bir AI ekosistemi oluşturur.
İşleyişi net ve merkeziyetsizdir: Alt ağ sahipleri alt ağ hedeflerini tanımlar ve teşvik modellerini yazar; madenciler alt ağda hesaplama gücü sağlar ve çıkarım, eğitim, depolama gibi AI ile ilgili görevleri tamamlar; doğrulayıcılar madencilerin katkılarını puanlar ve bu puanları Bittensor uzlaşım katmanına yükler; nihayetinde, Bittensor'un Yuma uzlaşım algoritması, her alt ağda birikmiş ödüllere göre alt ağ katılımcılarına ilgili getirileri dağıtır.
Bittensor'da şu anda 128 alt ağı bulunuyor ve bu ağlar çıkarım, sunucusuz AI bulut hizmetleri, görüntü, veri etiketleme, pekiştirmeli öğrenme, depolama, hesaplama gibi çeşitli AI görevlerini kapsıyor.
SN3, bunlardan bir alt ağıdır. Uygulama katmanı kabuğu oluşturmaz, mevcut büyük modellerin API'lerini kiralamaz, aksine AI endüstri zincirinin en pahalı ve en kapalı çekirdek bileşenlerinden birine doğrudan odaklanır: büyük modellerin ön eğitimine.
SN3, Bittensor ağı üzerinden heterojen hesaplama kaynaklarının dağıtılmış eğitimini koordine etmeyi amaçlıyor ve teşvik temelli dağıtılmış büyük model eğitimiy-le, pahalı merkezi süper bilgisayar kümelerine gerek kalmadan güçlü temel modellerin eğitilebileceğini kanıtlıyor. Temel çekicilik, "eşitlik" — merkezi eğitimi sağlayan kaynak monopollerini kırarak, sıradan bireylerin veya küçük ve orta ölçekli kurumların büyük model eğitimi sürecine katılmasını sağlıyor ve dağıtılmış hesaplama gücüyle eğitim maliyetlerini düşürüyor.
SN3'ü geliştiren temel güç Templar'dır ve arka planda yer alan araştırma ekibi Covenant Labs'tır. Bu ekip, Basilica (SN39, hesaplama hizmetlerine odaklanan) ve Grail (SN81, RL sonrası eğitme ve model değerlendirmeye odaklanan) olmak üzere iki başka alt ağı da işletmektedir. Üç alt ağ, büyük modellerin ön eğitimden hizmete uygun hale getirme ve optimizasyona kadar olan tüm sürecini dikey olarak kapsayarak, merkeziyetsiz büyük model eğitimi için tam bir ekosistem oluşturur.
Özellikle, madenci kaynakları katkıda bulunarak gradyan güncellemelerini (model parametrelerinin düzenleme yönü ve şiddeti) ağa yükler; doğrulayıcılar, her madencinin katkı kalitesini değerlendirir ve hata iyileşme miktarına göre zincir üzerinde puan verir. Sonuçlar, herhangi bir üçüncü tarafı güvenmeye gerek kalmadan otomatik olarak ödül ağırlıklarını belirler.
Teşvik mekanizmasının temel amacı, ödülün yalnızca hesaplama gücü katılımı değil, "katkılarınızın modeli ne kadar iyileştirdiği" ile doğrudan ilişkilendirilmesidir. Bu, merkeziyetsiz senaryolardaki en zor sorunu temelden çözer: madencielerin işten kaçmasını nasıl önleriz.
Covenant-72B, iletişim verimliliğini ve teşvik uyumluluğunu nasıl çözer?
Birbirine güvenmeyen, donanımları farklı ve ağ kalitesi değişken onlarca düğümün aynı modeli birlikte eğitmesi, iki zorlukla karşılaşıyor: birincisi iletişim verimliliği, standart dağıtık eğitim çözümleri düğümler arasında yüksek bant genişliği ve düşük gecikme gerektiriyor; ikincisi teşvik uyumu, kötü niyetli düğümlerin yanlış gradyanları göndermesini nasıl engelleriz? Her katılımcının kendi sonuçlarını eğitip, başkalarının sonuçlarını kopyalamadığından nasıl emin oluruz?
SN3, bu iki sorunu SparseLoCo ve Gauntlet adlı iki temel bileşenle çözmektedir.
SparseLoCo, iletişim verimliliği sorununu çözer. Geleneksel dağıtılmış eğitimde her adımda tam gradyan senkronizasyonu gerekir ve veri miktarı çok büyüktür. SparseLoCo, her düğümün yerel olarak 30 adımlık iç optimizasyonu (AdamW) tamamladıktan sonra oluşturulan "sahte gradyanları" sıkıştırıp diğer düğümlere yüklemesini benimser. Sıkıştırma yöntemi, Top-k seyreltme (en kritik gradyan bileşenlerini koruma), hata geri bildirimi (atılan kısımların bir sonraki döngüye kadar biriktirilmesi) ve 2-bit kuantizasyonu içerir. Son sıkıştırma oranı 146 katın üzerindedir.
Yani, daha önce 100 MB aktarılması gereken bir şey, şimdi 1 MB'den azıyla yeterli.
Sistem, normal internet bant genişliği sınırları (yukarı 110 Mbps, aşağı 500 Mbps) altında, 20 düğüm, her düğümde 8 adet B200 ile her iletişim döngüsünde yalnızca 70 saniye harcayarak hesaplama kullanımını yaklaşık %94,5 seviyesinde tutuyor.
Gauntlet, teşvik uyumu sorununu çözer. Bittensor blok zinciri (Subnet 3) üzerinde çalışır ve her düğümün gönderdiği sahte gradyan kalitesini doğrular. Bu, küçük bir veri seti kullanarak "bu düğümün gradyanını kullanarak model kaybı ne kadar azaldı?" sorusunu test ederek yapılır; sonuç LossScore olarak adlandırılır. Sistem aynı zamanda düğümün kendi atanan verileriyle eğitim yaptığını da kontrol eder—bir düğümün kendi atanan verilerindeki kayıp iyileşmesi, rastgele verilerdeki iyileşmeden daha kötüyse, negatif puan alır.
Sonuç olarak, her eğitim turunda en yüksek puanı alan düğümlerin gradyanları yalnızca toplu işleme dahil edilir, diğer düğümler bu turdan elenir. Fazla katılımcılar, sistemin kararlılığını korumak için zamanla yerini alır. Tüm eğitim süreci boyunca, ortalama her turda 16,9 düğümün gradyanı toplu işleme dahil edilmiştir ve toplamda 70'ten fazla benzersiz düğüm ID'si katılmıştır.
Merkeziyetsiz AI'nın değer hikayesi temel şekilde değişiyor
Bu olayı teknik ve endüstri perspektifinden değerlendirdiğimizde, Covenant-72B'in temsil ettiği yönün birkaç gerçek anlamı vardır.
Birincisi, "dağıtık eğitim yalnızca küçük modeller için uygundur" varsayımını çürüttü. Ön uç modellerle hâlâ uzak olsa da, bu yönün ölçeklenebilirliğini kanıtladı.
İkinci olarak, izinsiz katılım gerçekçi ve uygulanabilir. Bu nokta abartılmaktadır. Önceki dağıtılmış eğitim projeleri beyaz listeye dayanıyordu—yalnızca onaylanmış katılımcılar hesaplama gücü sağlayabilirdi. SN3 eğitiminde, yeterli hesaplama gücüne sahip herkes bağlanabilir ve doğrulama mekanizması kötü niyetli katkıları filtreler. Bu, "gerçekten merkeziyetsiz" olmaya doğru somut bir adımdır.
Üçüncü olarak, Bittensor'ın dTAO mekanizması, alt ağların değerinin piyasa keşfini mümkün kılar. dTAO, her alt ağın kendi Alpha token'ını çıkarmasını ve AMM mekanizması aracılığıyla piyasaya hangi alt ağların daha fazla TAO emisyonu alacağını belirletmesini sağlar. Bu, SN3 gibi somut sonuçlar üreten alt ağlar için kaba ancak etkili bir değer yakalama mekanizması sunar. Elbette, bu mekanizma hikâyeler ve duygularla kolayca etkilenebilir; LLM eğitimi sonuçlarının kalitesi, normal piyasa katılımcıları tarafından bağımsız olarak değerlendirilmesi zordur.
Dördüncü olarak, merkeziyetsiz AI eğitiminin siyasi ekonomik anlamı. Jack Clark, Import AI'de bu sorunu "AI'nin geleceğini kimin sahipleneceği" düzeyine taşıdı. Şu anda öncü modellerin eğitimi, büyük ölçekli veri merkezlerine sahip az sayıda kurum tarafından monopolize edilmiştir; bu sadece bir ticari sorun değil, aynı zamanda bir güç yapısı sorunudur. Dağıtılmış eğitim, teknolojik ilerlemeleri sürdürebilirse, bazı model türlerinde (örneğin belirli alanlara özgü küçük ölçekli öncü modeller) gerçekten merkeziyetsiz bir geliştirme ekosistemi oluşturabilir. Ancak bu vizyon şu anda hâlâ çok uzak.
Özet: Gerçek bir milta taşı ve bir dizi gerçek sorun
Huang Renxun, bunun "modern Folding@home" gibi olduğunu söyledi. Folding@home, moleküler simülasyon alanında gerçek katkılar sağlamıştır, ancak büyük ilaç şirketlerinin temel araştırma geliştirme konumunu tehdit etmemiştir. Bu benzetme çok doğru.
SN3, protokolü çalıştırdı ve dağıtık eğitim için mümkün olan bir yönü doğruladı. Ancak teknik ve endüstri bakış açılarından bakıldığında, bu performansın ardında nadiren ciddiye alınan bir dizi sorun daha var:
MMLU, akademik dünyada kendisi de tartışmalı bir metriktir; açık referans soruları ve cevapları eğitim setine sızma riski taşır. Daha da önemlisi, karşılaştırma temelinin seçimi: Makalede karşılaştırılan LLaMA-2-70B ve LLM360 K2, 2023-2024 yılları arasında geliştirilmiş eski modellerdir; aynı aralıkta 65 ila 70 puan, Grok ve DouBao sorulduğunda orta-alt ve giriş seviyesi olarak sınıflandırılırken, Claude'a göre ciddi şekilde geride kalınmış durumdadır. Eğer bu modeller dinamik olarak güncellenen bir sıralamaya veya kirletme dirençli tasarlanmış yeni nesil referanslara yerleştirilseydi, sonuçlar daha dürüst olabilirdi.
Daha da önemlisi, modelin kapasitesini belirleyen kaliteli veriler—diyalog verileri, kod, matematiksel türetmeler, bilimsel makaleler—muhtemelen büyük şirketlerin, yayıncıların ve akademik veritabanlarının elinde. Hesaplama gücü demokratikleşti, ancak veri tarafında hâlâ oligopolik bir yapı var ve bu çelişki hiç tartışılmadı.
Güvenlik açısından, izinsiz katılım, bu 70'ten fazla düğümün arkasında kimin olduğunu ve hangi verilerle eğitildiklerini bilmeniz anlamına gelir. Gauntlet, açıkça anormal gradyanları filtreleyebilir, ancak ince veri zehirlemesine karşı koruma sağlamaz—bir düğüm, belirli bir zararlı içerik türüne yönelik olarak sistematik olarak birkaç ek eğitim döngüsü uygularsa, oluşan gradyan değişiklikleri yeterince ince olabilir ve kayıp puan taramasını geçebilir, ancak model davranışında birikimsel bir sapmaya neden olur. Sonuç olarak, finansal, tıbbi ve hukuki gibi yüksek uyumluluk ve güvenlik gerektiren senaryolarda, az sayıda anonim düğümün katılımıyla ve veri kaynakları izlenemeyen bir model kullanmak nasıl bir risk taşır?
Ayrıca, açıkça belirtmek gerekir ki: Covenant-72B, Apache 2.0 lisansı altında açık kaynaklıdır ve SN3 token'ını kullanmaz. SN3 token'ını elde tutmak, modelin kullanımından doğrudan kaynaklanan herhangi bir gelir değil, bu alt ağınn gelecekte yeni modeller üretmesiyle ortaya çıkacak emisyon gelirlerini paylaşmanız anlamına gelir. Bu değer zinciri, sürekli eğitim çıktılarına ve Bittensor ağının genel emisyon mekanizmasının sağlıklı çalışmasına dayanır. Gelecekte eğitim durursa veya yeni eğitim sonuçları beklentileri karşılamazsa, token'ın değerleme mantığı zayıflar.
Bu soruları listelemek, Covenant-72B'nin anlamını reddetmek için değil; daha önce imkânsız olduğu düşünülen bir şeyin yapılabilir olduğunu kanıtlaması gerçeği kaybolmaz. Ancak yapılması ve bunun ne anlama geldiğinin iki farklı şey olduğunu unutmayın.
SN3 token, geçen ay %440 artış kaydetti. Bu arasındaki mesafe, sadece bir spekülasyon olmayabilir; hikayenin hızının gerçekliğin hızından her zaman daha hızlı olması olabilir. Bu mesafenin nihayet gerçeklikle doldurulup doldurulmayacağı ya da piyasa tarafından düzeltilecek mi, Covenant AI ekibinin sonraki adımlarında ne sunacağına bağlıdır.
Dikkat edilmesi gereken nokta, Grayscale'in Ocak 2026'da TAO ETF başvurusu sunduğu ve bu durumun kurumsal sermayenin bu alana girmeye yöneldiğine işaret etmesidir. Ayrıca, Bittensor 2025 Aralık'ta günlük TAO emisyonunu yarıya indirdi ve arz tarafındaki yapısal daralma hâlâ devam etmektedir.
Referans bağlantısı:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95