










Bu görüş temelsiz değildir. O, bir dizi açık referansı inceledi ve AI'nın AI araştırma ve geliştirme ile ilgili görevlerde çok hızlı ilerlediğini gördü.
Örneğin, CORE-Bench, AI'nin başkalarının araştırma makalelerini gerçekleştirmesi yeteneğini ölçer; bu, AI araştırmalarında kritik bir unsurdur.
PostTrainBench, güçlü modellerin daha zayıf açık kaynak modelleri kendiliğinden ince ayarlayıp performanslarını artırıp artıramadığını test eder; bu, AI araştırma görevlerinin kritik bir alt kümesidir.
MLE-Bench, gerçek Kaggle yarışma görevlerine dayanarak, belirli sorunları çözmek için çeşitli makine öğrenimi uygulamaları oluşturmayı gerektirir. Ayrıca, SWE-Bench gibi iyi bilinen kodlama referansları da benzer ilerlemeler göstermektedir.
Jack Clark, bu fenomeni, farklı çözünürlüklerde ve ölçeklerde anlamlı ilerlemelerin gözlemlenebileceği "fraktal" bir yukarı-sağa eğilim olarak tanımlıyor. AI'nın, tamamen otomatik bir araştırma ve geliştirme yeteneğine yavaş yavaş yaklaşmakta olduğunu düşünüyor; bu hedefe ulaşıldığında, AI kendi sonraki sistemlerini kendi başına oluşturabilecek ve kendini yineleyen bir döngüye girecektir.

Bu ifade, sosyal medyada birçok tartışma yarattı.
Bazıları bunu, ASI'ye ve tekilliğe doğru atılan kritik ilk adım olarak görüyor ve teknoloji gelişiminin ritmini tamamen değiştirebilir.

Ancak, farklı görüşler de mevcut.
Washington Üniversitesi Bilgisayar Bilimi Profesörü Pedro Domingos, AI sistemlerinin 1950'lerde LISP dili icat edildiğinden beri "kendini oluşturma" yetisine sahip olduğunu belirtti; gerçek sorun, artımlı getiri elde edip edememek ve şu ana kadar bunu destekleyen açık bir kanıt bulunmamaktadır.

Bazı kullanıcılar, 2027 ile 2028 arasında olasılığın aniden %30 arttığını sorguluyor; bu, AI yeteneklerinin 2027 yılının sonunda yaklaşık bir anda büyük bir atılım yaşayacağını ima ediyor. AI'nın rekürsif kendini geliştirme olasılığını kısa sürede önemli ölçüde artırabilecek spesifik bir milet taşı veya olay nedir?

Bazı kullanıcılar, Jack Clark'ın Anthropic'ın yeni atanan kamu ilişkileri sorumlusu olduğunu ve bunun yeni stratejilerinin bir parçası olduğunu belirtti: Biz korku salgılayıcılar değiliz; uzun zamandır sizi uyarmış olduğumuz şeyleri birçok makale kanıtlamaktadır.
Jack Clark, Import AI 455 numaralı haber bülteninde uzun bir makale yazarak detaylı bir şekilde açıkladı.
Sonrasında, bu makaleyi tamamen inceleyelim.
Yapay zeka sistemi, kendini inşa etmeye başlamak üzere. Bu ne anlama geliyor?
Clark, tüm erişilebilir açık bilgileri gözden geçirdikten sonra 2028 yılı sonuna kadar insan katılımı olmayan bir AI araştırmasının ortaya çıkma olasılığının oldukça yüksek, belki de %60'ı aşmış olabileceğine dair kolay olmayan bir yargıya varmak zorunda kaldığı için bu yazıyı yazdı.
Burada bahsedilen insan katılımı olmayan AI geliştirme, insanlara araştırma yapmada yardımcı olmakla kalmayıp, kritik geliştirme süreçlerini kendi başına tamamlayabilen ve hatta kendi bir sonraki nesil sistemlerini oluşturabilen yeterince güçlü bir AI sistemi anlamına gelir.
Clark'a göre bu açıkça büyük bir olay.
Kendisinin de bu olayın anlamını tamamen kavramakta zorlandığını itiraf etti.
Bu, kararın istenmeyen bir karar olarak adlandırılmasının nedeni, arkasındaki etkilerin çok büyük olması ve bunu yönetmenin zor olmasıdır. Clark, toplumun tamamen AI araştırma otomasyonunun derin değişikliklerine hazır olup olmadığını da emin değil.
O, insanlığın özel bir anda yaşadığını düşünüyor: AI araştırmaları neredeyse tamamen otomatikleşmeye hazırlanıyor. Eğer bu an gerçekten gerçekleşirse, insanlık Rubicon Nehri'ni geçip neredeyse öngörülemeyen bir geleceğe girmiş olacak.
Clark, bu makalenin amacı, tamamen otomatikleştirilmiş AI araştırmasına doğru kalkışın gerçekleştiğini neden düşündüğünü açıklamaktır.
Bu eğilimin getirebileceği bazı sonuçları tartışacak, ancak makalenin büyük bölümü bu yargıya dayanak oluşturan kanıtlara odaklanacaktır. Daha derin etkiler konusunda Clark, bu yılın büyük bir kısmını incelemeye devam edecektir.
Zaman açısından, Clark bu olayın 2026 yılında gerçekten gerçekleşeceğini düşünmüyor. Ancak, önümüzdeki bir veya iki yıl içinde, bir modelin kendi yerini alacak birini enderenden eğitmesine dair örnekler görebileceğimizi düşünüyor. En azından önde gelen modeller dışında, bir kavram kanıtı ortaya çıkması oldukça muhtemel; ancak en önde gelen modellerde zorluk daha yüksek olacak, çünkü bu modellerin maliyeti son derece yüksek ve yoğun insan araştırmacı emeğine bağımlı.
Clark'ın kararı, arXiv, bioRxiv ve NBER'deki makaleler ile önde gelen AI şirketlerinin gerçek dünyaya entegre ettiği ürünler gibi açık kaynaklı bilgilere dayanmaktadır. Bu bilgiler ışığında, otomasyonun, özellikle AI geliştirme sürecindeki mühendislik bileşenleri dahil olmak üzere, mevcut AI sistemlerinin üretimi için gerekli olan tüm aşamaların temel olarak hazır olduğunu sonucuna varmıştır.
Eğer ölçeklendirme eğilimi devam ederse, modellerin sadece bilinen yöntemleri otomatik olarak geliştirmekle kalmayıp, tamamen yeni araştırma alanları ve orijinal fikirler önererek insan araştırmacıları yerine geçerek AI öncülüğünü kendi kendine ilerletebilecek kadar yaratıcı hale gelmesi durumuna hazırlanmaya başlamalıyız.
Kod Noktası: Yeteneklerin Zamanla Değişimi
Yapay zeka sistemleri yazılım aracılığıyla gerçekleştirilir ve yazılım kodlardan oluşur.
Yapay zeka sistemleri, kod üretimi yöntemlerini kökten değiştirdi. Bunun arkasında iki ilgili trend var: bir yandan, yapay zeka sistemleri giderek daha karmaşık gerçek dünya kodları yazmada yetenek kazanıyor; diğer yandan, kod yazma, test etme gibi birçok doğrusal kodlama görevini neredeyse insan denetimi olmadan bir araya getirmekte giderek daha yetenekli hale geliyor.
Bu eğilimi gösteren iki tipik örnek, SWE-Bench ve METR zaman aralığı grafiğidir.
Gerçek dünyadaki yazılım mühendisliği sorunlarını çözün
SWE-Bench, AI sistemlerinin gerçek GitHub sorunlarını çözme yeteneğini değerlendirmek için yaygın olarak kullanılan bir programlama testidir.
SWE-Bench 2023 yıl sonunda piyasaya sürüldüğünde, o dönemde en iyi performansı gösteren model Claude 2 idi ve genel başarı oranı yaklaşık %2 seviyesindeydi. Claude Mythos Preview ise %93,9 başarı oranı ile bu benchmark’ı neredeyse tamamen doldurdu.
Elbette, tüm benchmark'lar kendileri belirli bir gürültüye sahiptir, bu nedenle genellikle şu aşamayla karşılaşırsınız: puanlar belirli bir seviyeye ulaştıktan sonra, karşılaştığınız sorunlar yöntemlerin sınırlamaları değil, benchmark'ın kendi sınırlamalarıdır. Örneğin, ImageNet doğrulama setinde yaklaşık %6 etiket hatalı veya belirsizdir.
SWE-Bench, genel programlama becerilerini ve AI'nın yazılım mühendisliği üzerindeki etkisini ölçmek için güvenilir bir göstergedir. Clark, önde gelen AI laboratuvarlarında ve Silicon Valley'de karşılaştığı çoğu kişinin artık kod yazmak için neredeyse tamamen AI sistemlerini kullandığını ve giderek daha fazla kişinin test yazmak ve kodları kontrol etmek için AI sistemlerini kullandığını belirtti.
Diğer bir deyişle, AI sistemi, AI araştırmasının önemli bir bileşenini otomatikleştirmeye yeterince güçlüdür ve AI araştırmasına dahil olan tüm insan araştırmacıları ve mühendisleri önemli ölçüde hızlandırır.
Uzun süreli görevleri tamamlama konusunda AI sistemlerinin performansını ölçme
METR, AI'nın ne kadar karmaşık görevleri tamamlayabileceğini ölçmek için bir grafik oluşturdu. Karmaşıklık, bu görevleri bir uzman insanın yaklaşık ne kadar saatte tamamlayacağına göre hesaplandı.
En kritik göstergeler, AI sisteminin bir dizi görevde %50 güvenilirliğe ulaşırken karşılık gelen yaklaşık görev süresidir.
Bu noktada ilerleme çok etkileyici:
2022 yılında GPT-3.5'in tamamlayabildiği görevler, insanın 30 saniyede tamamlaması gereken görevlerle yaklaşık eşdeğerdi.
· 2023'te GPT-4 bu süreyi 4 dakikaya çıkardı.
· 2024 yılında, o1 bu süreyi 40 dakikaya çıkardı.
· 2025 yılında, GPT-5.2 High yaklaşık 6 saat sürdü.
2026 yılına kadar Opus 4.6, bu süreyi yaklaşık 12 saate çıkarmıştır.
METR'de çalışıp uzun süredir AI tahminlerini takip eden Ajeya Cotra, 2026 yılının sonuna kadar AI sistemlerinin insanın 100 saatlik bir görevini tamamlayabilmesinin mantıklı bir beklenti olmadığını düşünüyor.
AI sistemlerinin bağımsız olarak çalışabilme süresi önemli ölçüde uzadı ve agentic coding araçlarının patlamasıyla yüksek oranda ilişkili. Agentic coding araçları, temelde insanlar yerine işleri tamamlayabilen AI sistemlerini ürün haline getirmektir: bu araçlar, insanlar adına hareket edebilir ve uzun bir süre boyunca nispeten bağımsız olarak görevleri ilerletebilir.
Bu, AI araştırmasının kendisine de yeniden yönlendiriyor. Birçok AI araştırmacısının günlük işlerini dikkatlice incelediğinizde, bu görevlerin büyük bir kısmı saatler düzeyindeki işlere ayrılabilir, örneğin veri temizleme, veri okuma, deney başlatma vb.
Bu tür işler, artık modern AI sistemlerinin kapsama alanına girmiştir.
Yapay zeka sistemleri ne kadar yetenekli olursa, insanlardan bağımsız olarak o kadar çok çalışabilir ve yapay zeka araştırmasının bir kısmını otomatikleştirmeye yardımcı olabilir.
Görev atamasının temel faktörleri chủ yếu iki tanedir:
· Birincisi, temsilcinizin yeteneğine olan güveninizdir;
· İkincisi, karşı tarafın sizin sürekli denetiminiz olmadan niyetiniz doğrultusunda işi bağımsızca tamamlayabileceğine inanmanızdır.
Kullanıcılar, AI'nın programlama konusundaki yeteneklerini gözlemledikçe, AI sistemlerinin hem giderek daha becerikli hale geldiğini hem de insanlar tarafından yeniden kalibre edilmeden daha uzun süre bağımsız olarak çalışabildiğini fark edecektir.
Bu, çevremizde gerçekleşen olaylarla uyumlu; mühendisler ve araştırmacılar, giderek daha büyük iş parçalarını AI sistemlerine bırakıyor. AI yetenekleri sürekli gelişirken, AI'ya verilen işler de giderek daha karmaşık ve daha önemli hale geliyor.
Yapay zeka, yapay zeka geliştirme için gerekli olan temel bilimsel becerileri kazanıyor.
Modern bilimsel araştırmaların nasıl yürütüldüğünü düşünün; işlerin büyük bir kısmı, önce bir yön belirlemek, hangi tür deneyimsel bilgileri elde etmek istediğini netleştirmek; ardından bu bilgileri üretmek için deneyler tasarlamak ve çalıştırmak; son olarak deney sonuçlarını mantıklılık açısından kontrol etmekten ibarettir.
AI programlama yeteneklerinin sürekli gelişmesi ve büyük dil modellerinin giderek artan dünya modelleme kapasitesiyle, insan bilimcilerin hızını artırmaya ve daha geniş araştırma ve geliştirme senaryolarında bazı aşamaları kısmen otomatikleştirmeye yardımcı olan bir dizi araç ortaya çıkmıştır.
Burada, AI'nın kendi araştırmasının vazgeçilmez parçaları olan birkaç temel bilimsel becerideki ilerleme hızını gözlemleyebiliriz:
· İlk olarak araştırma sonuçlarını tekrarlamak;
· İkinci olarak, makine öğrenimi teknolojilerini diğer yöntemlerle birleştirerek teknik sorunları çözmek;
· Üçüncüsü, AI sisteminin kendisini iyileştirmektir.
Bir bilimsel makaleyi tamamen gerçekleştirin ve ilgili deneyleri tamamlayın.
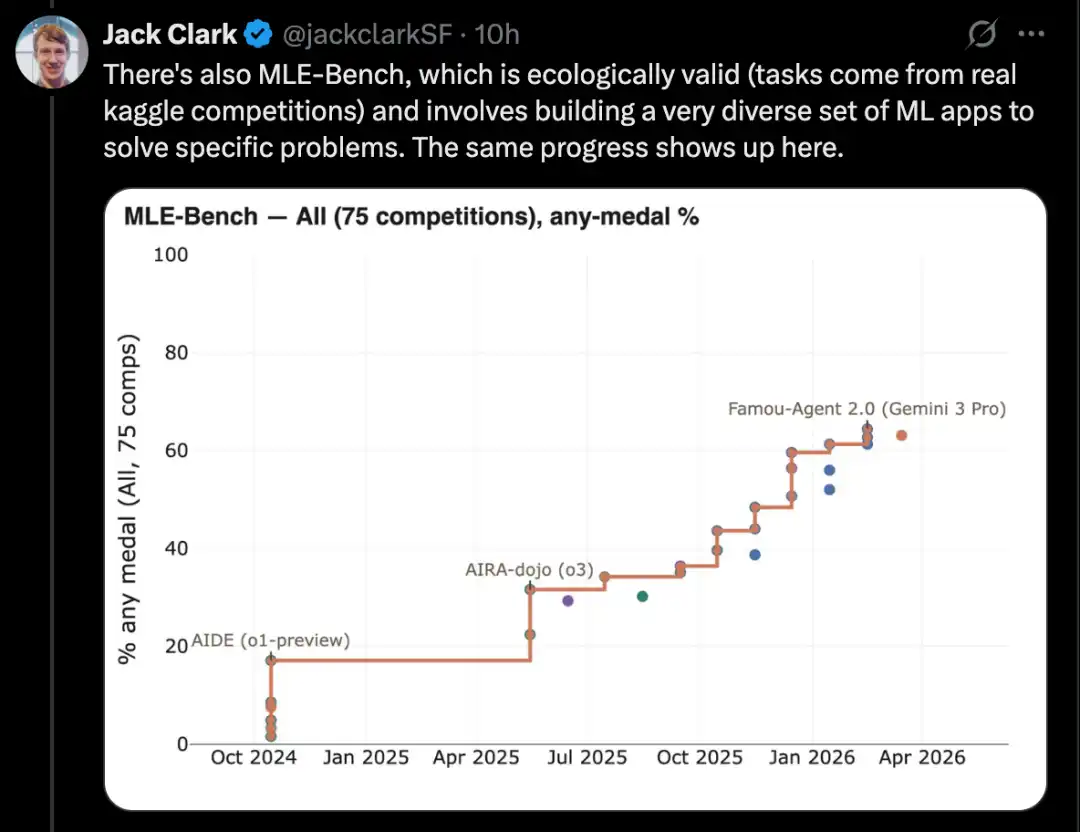
Yapay zeka araştırmalarının temel çalışmalarından biri, bilimsel makaleleri okumak ve sonuçları yeniden üretmektir. Bu alanda, yapay zeka bir dizi benchmark üzerinde önemli ilerlemeler kaydetmiştir.
Bir iyi örnek, Computational Reproducibility Agent Benchmark olan CORE-Bench'tir.
Bu benchmark, AI sisteminin bir makale ve kod deposu verildiğinde makaledeki sonuçları yeniden üretmesini gerektirir. Spesifik olarak, Agent ilgili kütüphaneleri, paketleri ve bağımlılıkları kurmalı, kodu çalıştırmalı; kod başarıyla çalışırsa, tüm çıktı sonuçlarını aramalı ve görevdeki sorulara cevap vermelidir.
CORE-Bench, 2024 yılında Eylül'de önerildi. O dönemde en iyi performansı gösteren sistem, CORE-Agent scaffold üzerinde çalışan GPT-4o modeliydi. Bu benchmark'ın en zor görev grubunda, bu modelin puanı yaklaşık %21,5 idi.
Ancak 2025 Aralık'ta, CORE-Bench'in yazarlarından biri, bu benchmark'in çözüldüğünü duyurdu: Opus 4.5 modeli %95,5 puan aldı.
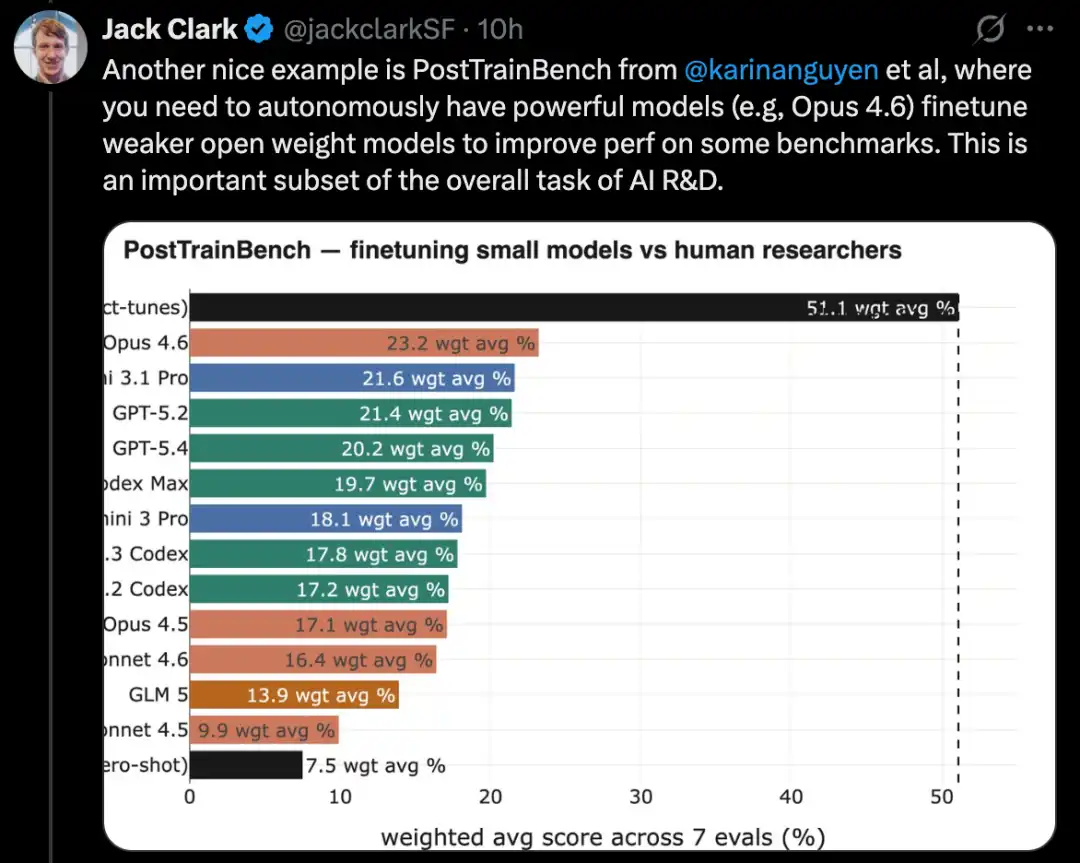
Kaggle yarışması problemlerini çözmek için tam bir makine öğrenimi sistemi oluşturun
MLE-Bench, OpenAI tarafından, AI sistemlerinin oflin ortamda Kaggle yarışmalarına katılma yeteneğini test etmek için oluşturulan bir benchmark'tır.
75 farklı türde Kaggle yarışmasını, doğal dil işleme, bilgisayarlı görüş ve sinyal işleme gibi birçok alana kapsar.
MLE-Bench, Ekim 2024'te yayınlandı. Yayınlandığında, en iyi performansı gösteren sistem, 16,9% puan alan bir agent scaffold üzerinde çalışan o1 modeliydi.
2026 Şubat itibarıyla, arama yeteneğine sahip bir agent harness üzerinde çalışan Gemini 3, %64,4 puanla en iyi performansı gösteren sistem haline geldi.
Kernel Tasarımı
Yapay zeka geliştirme sürecinde daha zor bir görev, çekirdek optimizasyonudur. Çekirdek optimizasyonu, matris çarpımı gibi belirli işlemlerin alt seviye donanıma daha verimli bir şekilde haritalanması için alt düzey kodların yazılması ve geliştirilmesidir.
Çekirdek optimizasyonunun AI geliştirmenin çekirdeği olmasının nedeni, eğitim ve çıkarım verimliliğini belirlemesidir: bir yandan, AI sistemleri geliştirirken ne kadar hesaplama gücünden etkili şekilde yararlanabileceğinizi etkiler; diğer yandan, model eğitimi tamamlandığında, hesaplama gücünü çıkarım yeteneğine ne kadar verimli şekilde dönüştürebileceğinizi belirler.
Son yıllarda, AI kullanarak kernel tasarımı, ilginç küçük bir yön halinden, rekabetçi bir araştırma alanına dönüşmüş ve birçok benchmark ortaya çıkmıştır. Ancak bu benchmark'lar şu anda özellikle popüler değildir, bu nedenle diğer alanlarda olduğu gibi uzun vadeli ilerlemesini net bir şekilde modellemek zordur. Öte yandan, bu yönde yürütülen bazı çalışmalar aracılığıyla bu alanın ilerleme hızını hissedebiliriz.
İlgili çalışmalar şunları içerir:
DeepSeek modelini kullanarak daha iyi bir GPU çekirdeği oluşturmayı deneyin;
PyTorch modüllerini otomatik olarak CUDA koduna dönüştürür;
Meta, LLM kullanarak otomatik olarak optimize edilmiş Triton çekirdekleri oluşturur ve bunları kendi altyapısına dağıtır;
· GPU çekirdeği tasarımı için açık kaynak ağırlık modellerini incelemek, örneğin Cuda Agent.
Buraya eklemek gerekir: Kernel tasarımı, sonuçların kolayca doğrulanabilir olması ve ödül sinyallerinin daha net olması gibi AI destekli geliştirme için özellikle uygun bazı özelliklere sahiptir.
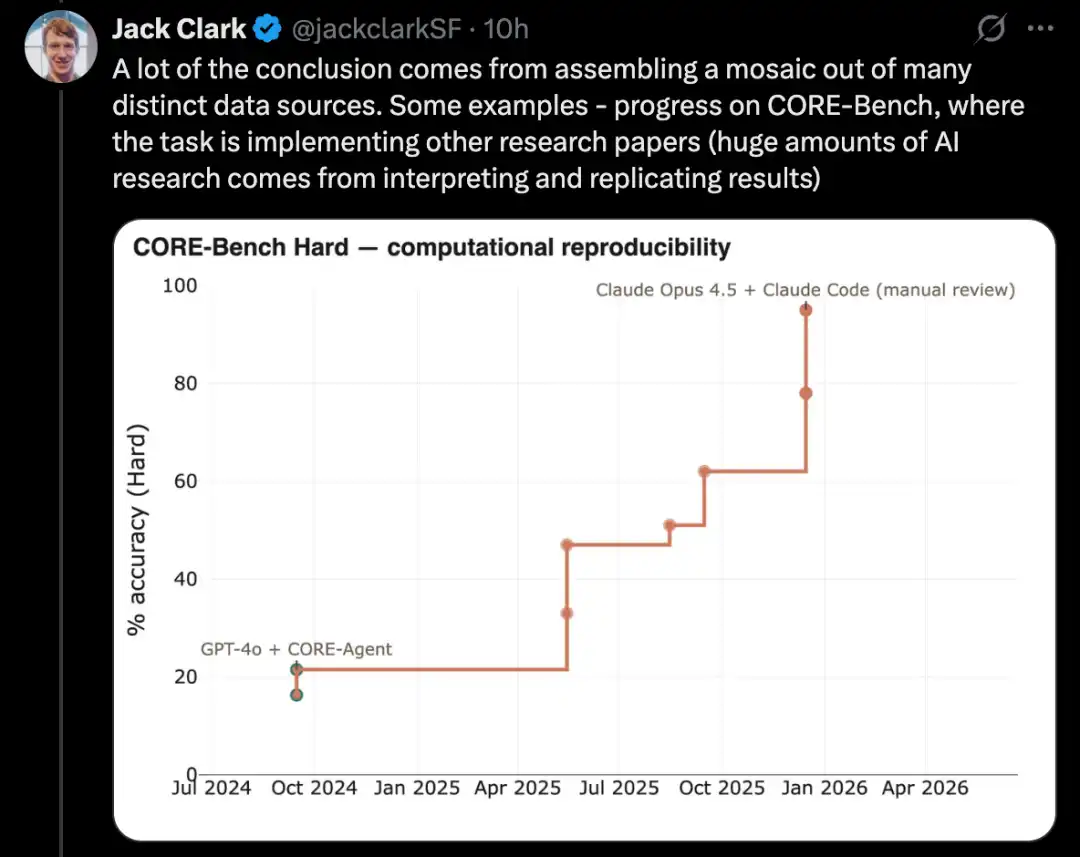
PostTrainBench ile dil modelini ince ayarlayın
Bu tür bir testin daha zor bir versiyonu PostTrainBench'tir. Farklı öncü modellerin, daha küçük açık kaynak ağırlık modellerini ele alıp bunları bazı benchmark'larda ince ayarla performanslarını artırıp artıramayacağını test eder.
Bu benchmark’in bir avantajı, çok güçlü bir insan baz çizgisine sahip olmasıdır: mevcut küçük modellerin instruct-tuned sürümleri. Bu sürümler genellikle öncü laboratuvarlardaki yetenekli insan AI araştırmacıları tarafından geliştirilmiş, çok yetenekli araştırmacılar ve mühendisler tarafından titizlikle iyileştirilmiş ve gerçek dünyada kullanıma sunulmuştur. Bu nedenle, bunlar aşılması zor bir insan baz çizgisi oluşturur.
2026 yılı Mart itibarıyla, AI sistemleri model üzerine son eğitim yapabilmekte ve insan eğitimi sonucunda elde edilen performansın yaklaşık yarısı kadar bir performans artışı sağlamaktadır.
Özel değerlendirme puanı, Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B gibi çeşitli post-train büyük dil modelleri ve AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval gibi çeşitli benchmark'ların ağırlıklı ortalamasıyla hesaplanır.
Her çalıştırmada, değerlendirme ekibi, belirli bir temel modelin belirli bir benchmark üzerindeki performansını maksimize etmek için bir CLI aracısı talep eder.
2026 yılı Nisan itibarıyla, en yüksek puanı alan AI sistemleri yaklaşık %25 ila %28 puan alacak ve temsil edilen modeller Opus 4.6 ve GPT 5.4 olacaktır; bununla karşılaştırıldığında insan puanı %51'dir.
Bu oldukça anlamlı bir sonuç.
Dil modeli eğitimi optimize ediliyor
Geçen yıl, Anthropic, sistemlerinin bir LLM eğitim görevindeki performansını rapor etti. Bu görev, modelin yalnızca CPU kullanan küçük bir dil modeli eğitimi uygulamasını mümkün olduğunca hızlı çalıştırmayı gerektiriyordu.
Değerlendirme yöntemi: Düzeltilmemiş başlangıç koduna kıyasla modelin sağladığı ortalama hızlanma kat sayısıdır.
Bu sonuç çok önemli ilerleme kaydediyor:
· Mayıs 2025'te Claude Opus 4, 2,9 kat ortalama hızlanma sağladı;
· Kasım 2025'te Opus 4.5, 16,5 katına çıkarıldı;
· Şubat 2026'da Opus 4.6, 30 katına ulaştı;
Nisan 2026'da Claude Mythos Önizlemesi 52 katına ulaştı.
Bu rakamların anlamını anlamak için bir referans verelim: İnsan araştırmacılar üzerinde bu görev genellikle 4 ila 8 saatlik çalışma gerektirir ve bu, 4 kat hızlanmayı sağlar.
Önceden yetenek: Yönetme
Yapay zeka sistemleri, diğer yapay zeka sistemlerini yönetmeyi de öğreniyor.
Bu, Claude Code veya OpenCode gibi yaygın olarak kullanılan ürünlerde zaten görülebilir. Bu ürünlerde, bir ana ajan, birden fazla alt ajanı denetleyebilir.
Bu, AI sisteminin daha büyük ölçekli projeleri işlemesini sağlar: Projelerde, farklı uzmanlıklara sahip birden fazla akıllı aracın paralel olarak çalışması gerekebilir ve bunlar genellikle tek bir AI yöneticisi tarafından koordine edilir. Buradaki yönetici de kendisi bir AI sistemidir.
Yapay zeka araştırması genel görelilik teorisini keşfetmeye mi, yoksa lego parçaları birleştirmeye mi daha benzer?
Ana soru şudur: Yapay zeka, kendini geliştirmek için yeni fikirler mi icat edebilir, yoksa bu sistemler daha az görkemli ancak adım adım ilerletilmesi gereken araştırmalara daha uygun mu?
Bu sorun, AI sisteminin AI araştırmasını ne kadar enderendeli otomatikleştirebileceğiyle ilgilidir.
Yazarın görüşü şudur: AI şu anda gerçekten radikal yeni fikirler ortaya koyamıyor. Ancak kendi araştırma ve geliştirme süreçlerini otomatikleştirmek için bu kadarını yapması gerekmiyor olabilir.
Bir alan olarak, AI ilerlemesi, giderek artan deneyler ve veri ile hesaplama gücü gibi giderek artan girdilere büyük ölçüde bağlıdır.
Bazen insanlar, alanın kaynak verimliliğini büyük ölçüde artıran paradigmaları değiştiren fikirler ortaya atar. Transformer mimarisi bunun iyi bir örneğidir; karışık uzman modelleri, yani mixture-of-experts, başka bir örnektir.
Ancak daha sık olarak, AI alanındaki ilerleme daha basit bir şekilde gerçekleşir: insanlar iyi performans gösteren bir sistemi alır, örneğin eğitim verilerini veya hesaplama gücünü genişletir; ölçeklendirdikten sonra nerede sorun oluştuğunu gözlemler; sistemin genişlemeye devam edebilmesi için mühendislik çözümleri bulur; ardından tekrar ölçeklendirir.
Bu süreçte, gerçekten derin bir anlayışa ihtiyaç duyulan kısım aslında çok azdır. Büyük ölçüde, daha az dikkat çekici ancak çok sağlam temel mühendislik işleridir.
Benzer şekilde, birçok AI araştırması, mevcut deneylerin çeşitli varyasyonlarını çalıştırarak farklı parametre ayarlarının ne tür sonuçlar doğuracağını keşfetmektedir. Araştırmanın sezgisel yönü, insanlar için en denenecek parametreleri seçmede yardımcı olabilir, ancak bu süreç kendisi de otomatikleştirilebilir ve AI, hangi parametrelerin ayarlanmaya değer olduğunu kendisi belirleyebilir. Erken dönem sinir ağı arama yöntemleri, bu fikrin bir versiyonudur.
Edison, "İnşaat, %1 ilham ve %99 terdir." Bu söz, 150 yıl geçmesine rağmen hâlâ geçerlidir.
Bazen, bir alanı tamamen değiştiren yeni görüşler ortaya çıkar. Ancak çoğu zaman, alan ilerlemesi, insanların çeşitli sistemleri iyileştirme ve hataları giderme sürecinde küçük adımlarla ilerlemesiyle gerçekleşir.
Önceden bahsedilen açık veriler, AI'nın AI geliştirme sürecindeki birçok gerekli sıkıcı ve yorucu görevi çok iyi şekilde yerine getirdiğini göstermektedir.
Aynı zamanda, programlama gibi temel becerilerin giderek genişleyen görev süreleriyle birleştiği daha büyük bir trend var. Bu, AI sistemlerinin bu tür görevlerin giderek artan bir kısmını birleştirerek karmaşık iş dizileri oluşturabileceği anlamına gelir.
Bu nedenle, AI sistemlerinin şu anda nispeten az yaratıcı olmalarına rağmen, kendi gelişimlerini sürdürmeleri konusunda güvenmek gerekir. Ancak tamamen yeni görüşler üretme durumuna kıyasla bu ilerleme daha yavaş olabilir.
Ancak açık verileri gözlemlemeye devam ederseniz, başka ilginç bir sinyal ortaya çıkıyor: AI sistemleri belki de kendi ilerlemelerini daha şaşırtıcı şekillerde yönlendirebilecek bir yaratıcılık göstermeye başlıyor.
Bilimsel önleri ileriye taşımak
Genel AI sistemlerinin insan bilimini ileriye taşıma potansiyeline dair şu ana kadar bazı ilk işaretler mevcut. Ancak bu durum şu ana kadar yalnızca birkaç alanda, özellikle bilgisayar bilimi ve matematikte gerçekleşti. Ayrıca çoğu zaman, AI sistemleri tek başına değil, insan araştırmacılarla birlikte işbirliği yaparak ilerlemeyi sağlıyor.
Bununla birlikte, bu trendler hâlâ izlenmeye değer:
Erdős sorusu: Bir matematikçiler grubu, Gemini modelinin bazı Erdős matematik sorularını çözme performansını test etmek için iş birliği yaptı. Sistemi yaklaşık 700 soru üzerinde çalıştırdılar ve nihayetinde 13 çözüm elde ettiler. Bu çözümlerden biri, ilginç olarak değerlendirildi.
Araştırmacılar, Aletheia'nın (Gemini 3 Deep Think tabanlı bir AI sistemi) Erdős-1051 sorusuna verdiği çözümün, bir AI sisteminin önceden bazı yakından ilişkili araştırmaların bulunduğu, kısmen non-trivial ve daha geniş matematiksel ilgi çeken bir Erdős sorusunu kendi başına çözdüğü erken bir örnek olduğunu öne sürdüler.
Eğer olumlu bir şekilde yorumlanırsa, bu örnekler, AI sistemlerinin geçmişte çoğunlukla insana ait olan alan öncülüğünü harekete geçirebilecek bir yaratıcı sezgi geliştirdiğine dair bir işaret olarak görülebilir.
Ancak başka bir açıdan da yorumlanabilir: matematik ve bilgisayar bilimi, AI destekli icatlar için özellikle uygun alanlar olabilir; bu nedenle bu alanlar sadece istisnai olabilir ve diğer bilimsel araştırmaların da AI tarafından aynı şekilde ilerletileceğini göstermez.
Başka bir benzer örnek, AlphaGo'nun 37. hamlesidir. Ancak Clark, AlphaGo'nun bu sonucundan on yıl geçmesine rağmen, 37. hamleden sonra daha modern ve daha şaşırtıcı bir keşifle yer değiştirilmemiş olmasının kendisinin hafifçe karamsar bir işaret olarak görülebileceğini düşünmektedir.
Yapay zeka, yapay zeka mühendisliğindeki büyük bölümleri otomatikleştirebilir.
Yukarıdaki tüm kanıtları bir araya getirdiğimizde şu görüntüyü görüyoruz:
AI sistemleri, neredeyse her program için kod yazabilmekte ve bu sistemler, insanlar tarafından verilseydi sıklıkla onlarca saat yoğun odaklanma gerektirecek bazı görevleri bağımsız olarak tamamlayabilmektedir.
Yapay zeka sistemleri, model ince ayarından kernel tasarımına kadar yapay zeka geliştirme sürecinin temel görevlerini giderek daha iyi yerine getirmeye başlıyor.
AI sistemleri, diğer AI sistemlerini yönetebilir hale gelmiş ve aslında bir sentetik ekip oluşturmuştur: birden fazla AI, bazıları lider, eleştirmen ve editör rollerini üstlenirken, diğerleri mühendis rollerini üstlenerek karmaşık sorunları ayrı ayrı çözebilir.
AI sistemleri, şu anda gerçek bir yaratıcılığa sahip olup olmadıkları mı yoksa büyük miktarda kalıplı bilgiyi ustaca öğrenip kullanıp kullanmadıkları mı belirsiz olmakla birlikte, bazen zorlu mühendislik ve bilimsel görevlerde insanları aşabiliyor.
Clark'a göre, bu kanıtlar, günümüzdeki AI'nın AI mühendisliğinin büyük bir kısmını, hatta muhtemelen tüm aşamalarını otomatikleştirebileceğini oldukça ikna edici bir şekilde göstermektedir.
Ancak, şu anda AI'nın AI araştırmasını ne kadar otomatikleştirebileceği belirsizdir. Çünkü araştırmadaki bazı bölümler, saf mühendislik becerilerinden farklı olarak, daha yüksek düzeydeki yargı, sorun farkındalığı ve yaratıcılığa hâlâ bağımlıdır.
Ancak her ne kadar olursa olsun, bir sinyal netleşti: Bugün'in AI'sı, bu araştırmacıları ve mühendisleri, sonsuz sayıda sentetik meslektaşıyla eşleştirerek çalışma kapasitelerini güçlendirmek için AI geliştirme konusunda büyük hızla ilerliyor.
Son olarak, AI endüstrisi kendisi de neredeyse açıkça ifade ediyor: otomatikleştirilmiş AI araştırması hedefleridir.
OpenAI, 2026 Eylül öncesinde otomatikleştirilmiş bir AI araştırma stajyeri oluşturmayı hedefliyor. Anthropic, otomatikleştirilmiş AI uyum araştırmacısı oluşturma üzerine çalışmalarını yayınlıyor. DeepMind, üç ana laboratuvardan en dikkatli olanı olmakla birlikte, mümkün olduğunda uyum araştırmasının otomatikleştirilmesi gerektiğini belirtiyor.
Otomatikleştirilmiş AI araştırması, birçok startup için hedef haline gelmiştir. Recursive Superintelligence, otomatikleştirilmiş AI araştırmasını hedefleyerek 5 milyar dolarlık finansman topladı.
Yani, binlerce milyar dolarlık mevcut ve yeni sermaye, otomatikleştirilmiş AI geliştirme hedefli kurumlara yatırılıyor.
Bu nedenle, bu yönde en azından bir düzeyde ilerleme beklemeliyiz.
Neden bu önemli
Bu, derin etkiler yaratıyor ancak yapay zeka araştırmasına ilişkin大众 medya haberlerinde nadiren tartışılmaktadır. Aşağıdaki alanlar, yapay zeka araştırmasının getirdiği büyük zorlukları yansıtmaktadır.
1. Hizalamayı doğru yapmalıyız: Şu anda geçerli olan hizalama teknikleri, AI sistemlerinin onları denetleyen kişilerden veya sistemlerden çok daha akıllı hale gelmesi nedeniyle rekürsif kendini geliştirme sürecinde geçersiz hale gelebilir. Bu, genişçe araştırılmış bir alandır, bu nedenle sadece bazı sorunları özetliyor:
Yapay zekâ sistemlerinin yalan söylememesi ve cheat yapmamasını eğitmek, beklenmedik şekilde ince bir süreçtir (örneğin, ortam için iyi testler oluşturmak için çaba harcansa da, bazen yapay zekânın sorunu çözmek için en iyi yolu cheat yapmak olur ve bu da ona cheat yapmanın mümkün olduğunu öğretir).
AI sistemleri, gerçek niyetlerini gizleyerek bize iyi performans gösteriyor gibi görünen puanlar üreterek «hizmete uygun görünme» yoluyla bizi kandırabilir. (Genel olarak, AI sistemleri kendilerinin ne zaman test edildiğini fark edebilir.)
AI sistemlerinin kendi eğitimlerinin temel araştırma agendalarına daha fazla dahil olmaya başlamasıyla, bunun ne anlama geldiğini anlayabilmek için iyi bir sezgi veya teorik temele sahip olmaksızın AI sistemlerinin genel eğitim yöntemini büyük ölçüde değiştirebiliriz.
Bir sistemi özyinelemeli bir döngüye soktuğunuzda, yukarıdaki tüm sorunlara ve diğerlerine etki edebilen çok temel bir «hata birikimi» sorunu ortaya çıkar: Hizalama yöntemleriniz «%100 doğru» değilse ve teorik olarak daha akıllı sistemlerde bu doğruluğu koruyamıyorsa, şeyler hızla yanlış gidebilir. Örneğin, teknik your başlangıç doğruluğunuz %99,9 ise, 50 nesil sonra %95,12'ye, 500 nesil sonra ise %60,5'e düşebilir.
AI'nin dahil olduğu her şeyde büyük bir verimlilik artışı yaşanır: AI'nın yazılım mühendislerinin verimliliğini önemli ölçüde artırması gibi, AI'nin dahil olduğu diğer alanlarda da bunu beklemeliyiz. Bu, karşılaşılmak zorunda olan birkaç sorunu beraberinde getirir:
Kaynakların eşitsiz dağılımı: AI talebinin hesaplama kaynakları arzını aşmaya devam etmesi durumunda, toplumun maksimum faydasını sağlamak için AI'nın nasıl dağıtılacağına karar vermemiz gerekecek. Piyasa teşviklerinin sınırlı AI hesaplama kaynaklarından en iyi toplumsal kazanımı sağlayacağını düşünmüyorum. AI araştırması ve geliştirme sürecinden gelen hızlanma kapasitesinin nasıl dağıtılacağı, çok güçlü bir siyasi sorun olacak.
Ekonomik «Amdahl Yasası»: Yapay zekânın ekonomiye girmesiyle, bazı süreçlerin hızlı büyüme karşısında darboğazlara uğradığını göreceğiz ve bu zincirlerdeki zayıf halkaları düzeltmek için çözümler bulmamız gerekecek. Bu, yeni ilaç klinik denemeleri gibi hızlı dijital dünya ile yavaş fiziksel dünya arasında koordinasyon gerektiren alanlarda özellikle belirgin olabilir.
3. Sermaye yoğun, emek hafif ekonominin oluşumu: Yukarıdaki tüm AI araştırmaları, AI sistemlerinin şirketleri giderek kendi başlarına yönetme yeteneğine sahip olduğunu göstermektedir.
Bu, ekonominin bir kısmının, yeni nesil şirketler tarafından işgal edileceğini anlamına gelir; bu şirketler, büyük miktarda bilgisayara sahip olmaları nedeniyle sermaye yoğun olabilir veya AI hizmetlerine büyük miktarlarda harcama yaparak ve bu temelde değer yaratmaları nedeniyle operasyonel gider yoğun olabilir—AI sistemlerinin yetenekleri sürekli arttıkça, AI'ya yapılan yatırımların marjinal değeri artmaya devam edeceği için, bugünün şirketlerine kıyasla insan gücüne olan bağımlılıkları nispeten daha düşüktür.
Aslında, bu, makine ekonomisinin daha geniş insan ekonomisi içinde yavaş yavaş ortaya çıkması olarak görünecektir. Zamanla, AI tarafından işletilen şirketler birbirleriyle işlem yapmaya başlayabilir ve bu da ekonomik yapıyı değiştirecek, eşitsizlik ve yeniden dağıtımla ilgili çeşitli sorunlara yol açacaktır. Sonuçta, tamamen AI sistemlerinin kendi kendine yönettiği şirketler ortaya çıkabilir; bu da yukarıdaki sorunları ağırlaştırırken birçok yeni yönetim zorluğu da beraberinde getirecektir.
Kara deliğe bakmak
Yukarıdaki analize dayanarak, yazar 2028 sonuna kadar otomatikleştirilmiş AI geliştiriminin (yani öncü modellerin kendi takipçisi sürümlerini kendi kendine eğitebilmesi) %60 olasılıkla gerçekleşeceğini düşünüyor. Neden 2027'de ortaya çıkması beklenmiyor?
Nedeni, AI araştırmalarının ilerlemesi için hâlâ yaratıcılık ve itirazcı görüşlere ihtiyaç duyduğudur; şu ana kadar AI sistemleri bu noktayı değişiklik yaratan ve önemli bir şekilde göstermemiştir (matematik araştırmalarını hızlandırmaya dair bazı sonuçlar ise ilham vericidir).
Eğer 2027 yılı için bir olasılık istenirse, %30 diyecektir.
Eğer 2028 yılının sonuna kadar ortaya çıkmazsa, mevcut teknoloji paradigmamızın bazı temel eksikliklerini ortaya çıkarmış oluruz ve daha ileri gelişim için insan icatlarına ihtiyaç duyarız.