









ผู้แต่ง:ทีน่า ตงเม่ย์InfoQ
1. หลังจากผ่านมาเกือบ 3 ปี เอลอน มัสก์เปิดเผยอัลกอริทึมแนะนำของ X อีกครั้ง
เมื่อไม่นานมานี้ ทีมวิศวกรของ X ได้โพสต์บน X ประกาศอย่างเป็นทางการว่าได้เปิดตัว X ระบบแนะนำอัลกอริทึมแบบโอเพนซอร์ส ตามที่อธิบายไว้ ไลบรารีโอเพนซอร์สที่เปิดตัวนี้ประกอบด้วยระบบแนะนำหลักที่ใช้สนับสนุนฟีด "แนะนำสำหรับคุณ" บน X ซึ่งรวมเนื้อหาภายในเครือข่าย (จากบัญชีที่ผู้ใช้ติดตาม) และเนื้อหาภายนอกเครือข่าย (ที่ค้นพบผ่านการค้นหาที่ใช้การเรียนรู้ของเครื่อง) เข้าด้วยกัน และใช้โมเดล Transformer ที่พัฒนาจาก Grok ในการจัดอันดับเนื้อหาทั้งหมด นั่นหมายความว่าอัลกอริทึมนี้ใช้สถาปัตยกรรม Transformer เดียวกันกับ Grok
ที่อยู่แหล่งเปิด: https://x.com/XEng/status/2013471689087086804
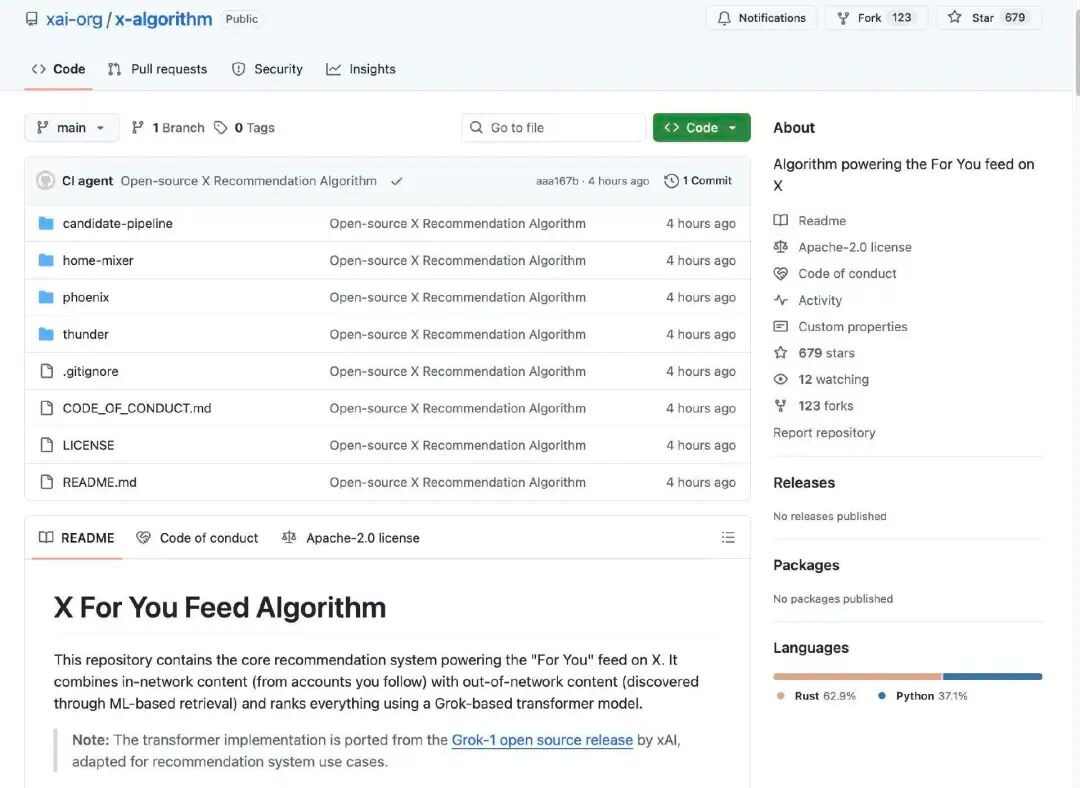
อัลกอริทึมแนะนำของ X รับผิดชอบในการสร้างเนื้อหาที่ผู้ใช้เห็นบนหน้าหลักเนื้อหาแนะนำสำหรับคุณ (For You Feed)มันได้รับโพสต์ที่เป็นไปได้จากแหล่งที่มาหลักสองแห่ง:
บัญชีที่คุณติดตาม (In-Network / Thunder)
โพสต์อื่น ๆ ที่พบบนแพลตฟอร์ม (Out-of-Network / Phoenix)
เนื้อหาที่เป็นไปได้เหล่านี้จะถูกประมวลผล ตัดกรอง และจัดลำดับตามความเกี่ยวข้องต่อไป
แล้วสถาปัตยกรรมหลักและตรรกะการทำงานของอัลกอริทึมเป็นอย่างไร?
อัลกอริทึมเริ่มต้นจากการรวบรวมเนื้อหาตัวเลือกจากแหล่งข้อมูลสองประเภท ได้แก่
เนื้อหาที่คุณติดตาม: โพสต์ที่ถูกเผยแพร่โดยบัญชีที่คุณติดตามอย่างกระตือรือร้น
เนื้อหาที่ไม่ได้ติดตาม: เนื้อหาที่ระบบค้นหาจากทั้งฐานข้อมูลที่อาจคุณสนใจ
เป้าหมายในขั้นตอนนี้คือ "ค้นหาโพสต์ที่อาจเกี่ยวข้อง"
ระบบจะลบเนื้อหาที่มีคุณภาพต่ำ ซ้ำกัน หรือไม่เหมาะสมออกโดยอัตโนมัติ ตัวอย่างเช่น:
เนื้อหาของบัญชีที่ถูกบล็อก
หัวข้อที่ผู้ใช้ชัดเจนว่าไม่สนใจ
กระทู้ที่ผิดกฎหมาย ล้าสมัย หรือไม่ถูกต้อง
การนี้ช่วยให้มั่นใจว่าเนื้อหาที่มีคุณค่าเท่านั้นที่จะถูกจัดการเมื่อเรียงลำดับสุดท้าย
อัลกอริทึมหลักของระบบในครั้งนี้คือการใช้โมเดล Transformer ที่พัฒนาบนพื้นฐานของ Grok (คล้ายกับโมเดลภาษาขนาดใหญ่ / โครงข่ายการเรียนรู้ลึก) เพื่อให้คะแนนกับโพสต์แต่ละโพสต์ที่เป็นไปได้ โมเดล Transformer จะพยากรณ์ความน่าจะเป็นของแต่ละพฤติกรรมของผู้ใช้ เช่น การกดไลก์ การตอบกลับ การแชร์ และการคลิก เป็นต้น จากประวัติการใช้งานของผู้ใช้ หลังจากนั้น ความน่าจะเป็นของแต่ละพฤติกรรมจะถูกคำนวณและรวมกันเป็นคะแนนรวม โดยโพสต์ที่มีคะแนนสูงกว่ามีแนวโน้มที่จะถูกแนะนำให้กับผู้ใช้มากกว่า
การออกแบบนี้ได้ยกเลิกการสกัดคุณลักษณะด้วยมือแบบดั้งเดิมอย่างพื้นฐาน และเปลี่ยนมาใช้การเรียนรู้แบบ End-to-End เพื่อทำนายความสนใจของผู้ใช้แทน
นี่ไม่ใช่ครั้งแรกที่มัสก์เปิดเผยอัลกอริทึมแนะนำของ X แบบโอเพนซอร์ส
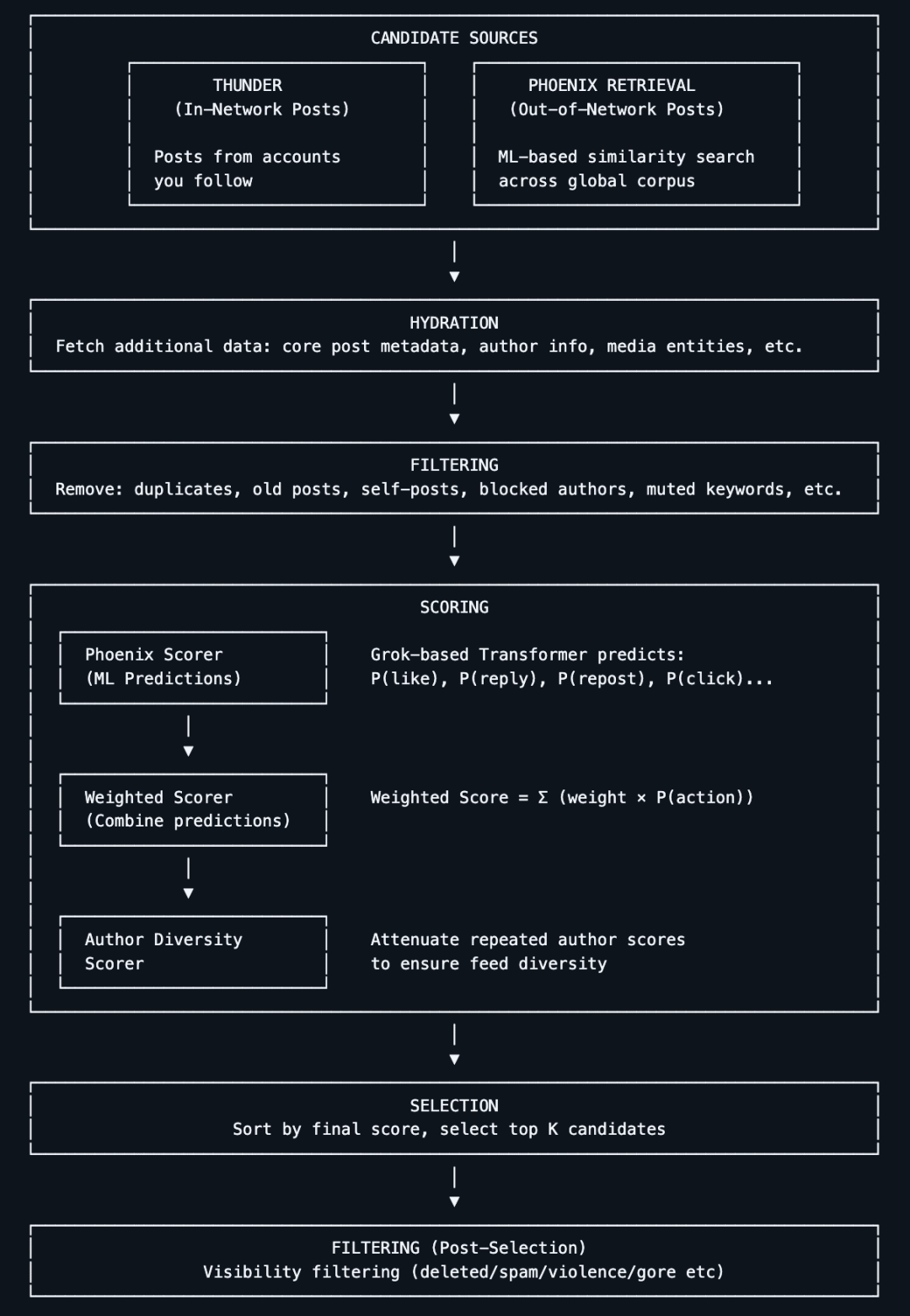
เมื่อวันที่ 31 มีนาคม ค.ศ. 2023 เอดิสัน มัสก์ ได้เปิดเผยโค้ดแหล่งที่มาของ Twitter อย่างเป็นทางการตามที่เขาสัญญาไว้ตอนซื้อ Twitter ซึ่งรวมถึงอัลกอริทึมที่ใช้ในการแนะนำทวีตในฟีดของผู้ใช้ด้วยในวันที่เปิดตัวโครงการนี้ โครงการนี้ได้รับดาว 10k+ บน GitHub
ในขณะนั้น มัสก์ได้แสดงความคิดเห็นบน Twitter ว่าการเปิดตัวครั้งนี้คือ"อัลกอริทึมแนะนำส่วนใหญ่"อัลกอริทึมอื่น ๆ จะถูกเปิดเผยทีละขั้นตอน ทั้งนี้ เขายังกล่าวอีกว่า หวังว่า "ผู้ให้บริการอิสระจากภายนอกจะสามารถระบุเนื้อหาที่ Twitter อาจแสดงให้ผู้ใช้เห็นได้อย่างแม่นยำเหมาะสม"
ในบทสนทนาผ่านทาง Space เกี่ยวกับการเปิดเผยข้อมูลของอัลกอริทึม เขากล่าวว่าแผนการเปิดตัวแหล่งข้อมูลครั้งนี้มีจุดประสงค์เพื่อให้ Twitter เป็น "ระบบที่โปร่งใสที่สุดบนอินเทอร์เน็ต" และให้มันมีความแข็งแกร่งเหมือนกับโครงการแหล่งข้อมูลเปิดที่มีชื่อเสียงและประสบความสำเร็จมากที่สุดอย่าง Linux "เป้าหมายโดยรวมคือการให้ผู้ใช้ที่ยังคงสนับสนุน Twitter ได้รับประโยชน์สูงสุดจากที่นี่"
ในตอนนี้ ผ่านมาแล้วเกือบ 3 ปีนับตั้งแต่ที่มัสก์เปิดเผยอัลกอริทึม X ครั้งแรก และด้วยสถานะของมัสก์ในฐานะ KOL ระดับซูเปอร์สตาร์ในวงการเทคโนโลยี เขาก็ได้ทำการโปรโมตการเปิดเผยแหล่งโค้ดครั้งนี้อย่างเต็มที่ตั้งแต่ต้น
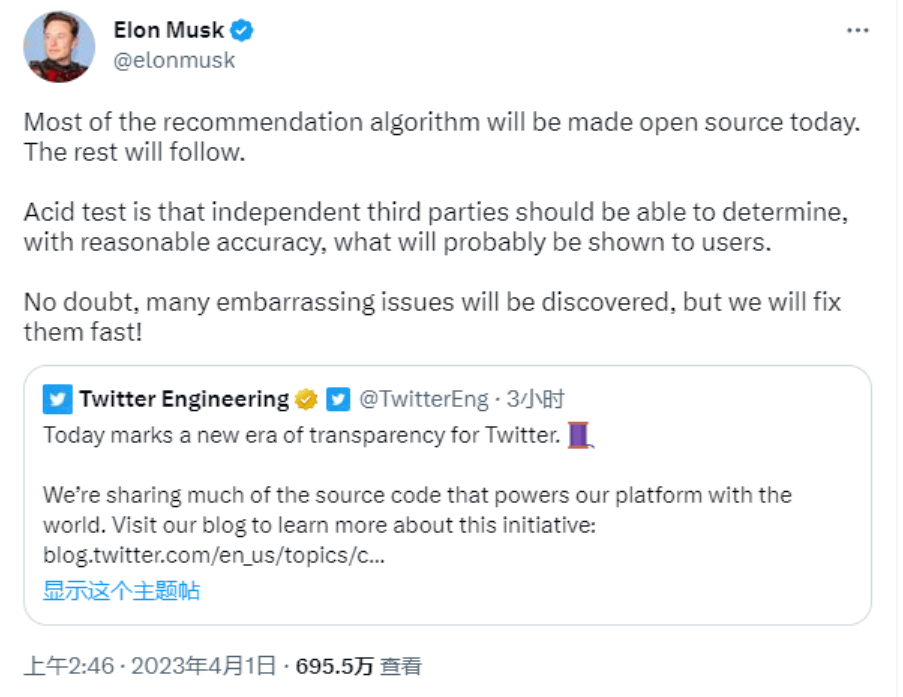
เมื่อวันที่ 11 มกราคม มัสก์ได้โพสต์บน X ว่า จะเปิดเผยโค้ดอัลกอริทึม X ใหม่ (ซึ่งรวมถึงโค้ดทั้งหมดที่ใช้ในการตัดสินใจว่าจะแนะนำเนื้อหาการค้นหาตามธรรมชาติและโฆษณาใดให้กับผู้ใช้) เป็นโอเพนซอร์สภายใน 7 วัน
ขั้นตอนนี้จะถูกทำซ้ำทุก 4 สัปดาห์ พร้อมคำอธิบายรายละเอียดสำหรับนักพัฒนา เพื่อช่วยให้ผู้ใช้เข้าใจว่ามีการเปลี่ยนแปลงอะไรบ้าง
วันนี้คำมั่นสัญญาของเขาได้รับการพิสูจน์อีกครั้ง
2. ทำไมแมสก์ถึงต้องเปิดเผยแหล่งที่มา?
เมื่ออีลอน มัสก์กล่าวถึง "โอเพนซอร์ส" อีกครั้ง ปฏิกิริยาแรกของผู้คนไม่ใช่ความอุดมคติทางเทคโนโลยี แต่เป็นความกดดันจากความเป็นจริง
ตลอดปีที่ผ่านมา X ถูกพัวพันกับข้อถกเถียงหลายครั้งเกี่ยวกับกลไกการกระจายเนื้อหา แพลตฟอร์มนี้ถูกวิจารณ์อย่างกว้างขวางว่าอัลกอริทึมของมันมีอคติและส่งเสริมมุมมองฝ่ายขวา โดยลักษณะดังกล่าวไม่ใช่กรณีศึกษาที่เกิดขึ้นแบบสุ่ม แต่ถูกมองว่าเป็นลักษณะเชิงระบบ รายงานการศึกษาที่เผยแพร่เมื่อปีที่แล้วระบุว่า ระบบแนะนำของ X แสดงให้เห็นถึงอคติใหม่ที่ชัดเจนในแง่การเผยแพร่เนื้อหาทางการเมือง
ในเวลาเดียวกัน กรณีที่รุนแรงบางกรณีได้เพิ่มความสงสัยจากภายนอกมากยิ่งขึ้น ปีที่แล้ว วิดีโอที่ยังไม่ได้รับการตรวจสอบเกี่ยวกับการลอบสังหารเชียร์ลีดเดอร์ขวาจัดชาวอเมริกัน ชาร์ลี คอก ได้แพร่กระจายอย่างรวดเร็วบนแพลตฟอร์ม X จนก่อให้เกิดความสะเทือนในสังคม นักวิจารณ์มองว่าเหตุการณ์นี้ไม่เพียงแต่เปิดเผยถึงความล้มเหลวของระบบตรวจสอบของแพลตฟอร์มเท่านั้น แต่ยังเน้นย้ำอีกครั้งถึงบทบาทของอัลกอริทึมในการ "ขยายความสำคัญของเนื้อหาใดบ้าง และไม่ขยายความสำคัญของเนื้อหาใดบ้าง" อำนาจที่ซ่อนเร้น
ในบริบทเช่นนี้ การที่แมสก์เน้นย้ำถึงความโปร่งใสของอัลกอริทึมอย่างกะทันหันนั้นยากที่จะถูกตีความอย่างง่ายดายว่าเป็นการตัดสินใจเชิงเทคนิคเพียวๆ

3. ผู้ใช้งานอินเทอร์เน็ตคิดอย่างไร?
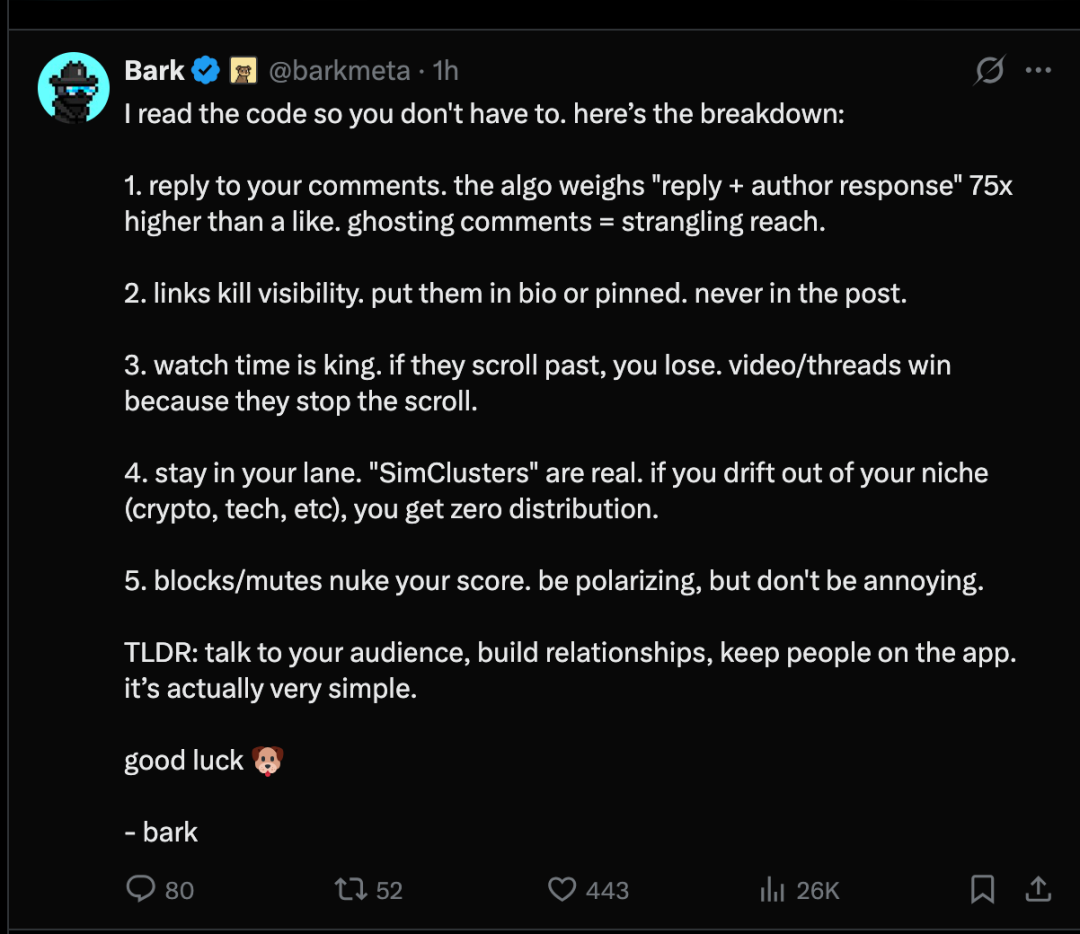
หลังจากที่ X เปิดเผยอัลกอริทึมแนะนำ บนแพลตฟอร์ม X มีผู้ใช้สรุปกลไกของอัลกอริทึมแนะนำใน 5 ข้อดังนี้:
- ตอบความคิดเห็นของคุณอัลกอริทึมให้ความสำคัญกับ "การตอบกลับ + การตอบกลับของผู้เขียน" มากกว่าการกดไลก์ถึง 75 เท่า การไม่ตอบกลับความคิดเห็นจะส่งผลต่ออัตราการมองเห็นอย่างรุนแรง
- ลิงก์จะลดอัตราการมองเห็นคุณควรใส่ลิงก์ไว้ในประวัติส่วนตัวหรือกระทู้แนะนำตัวเท่านั้น ห้ามเด็ดขาดไม่ให้ใส่ลิงก์ในเนื้อหากระทู้
- ระยะเวลาในการรับชมมีความสำคัญอย่างยิ่งหากพวกเขาเลื่อนหน้าจอผ่านไป คุณก็ไม่สามารถดึงดูดพวกเขาได้ วิดีโอ/โพสต์ที่ได้รับความสนใจสูง เพราะสามารถทำให้ผู้ใช้หยุดนิ่งได้
- ยึดมั่นในดินแดนของคุณ"คลัสเตอร์จำลอง" นั้นมีอยู่จริง หากคุณเบี่ยงเบนจากกลุ่มเป้าหมายของคุณ (เช่น คริปโตเคอเรนซี เทคโนโลยี เป็นต้น) คุณจะไม่สามารถเข้าถึงช่องทางการจัดจำหน่ายใด ๆ ได้
- การบล็อก/ไม่ตอบกลับจะทำให้คะแนนของคุณลดลงอย่างมากมีความขัดแย้ง แต่ไม่ใช่เรื่องน่ารังเกียจ
สรุปคือ: ติดต่อสื่อสารกับกลุ่มเป้าหมายของคุณ สร้างความสัมพันธ์ และทำให้ผู้ใช้อยู่ในแอปพลิเคชัน ซึ่งแท้จริงแล้วมันง่ายมาก
ผู้ใช้งานอินเทอร์เน็ตบางคนยังพบอีกว่า แม้ว่าโครงสร้างจะเปิดเผยเป็นโอเพนซอร์สแล้ว แต่ยังมีเนื้อหาบางส่วนที่ยังไม่ได้เปิดเผย ผู้ใช้งานรายหนึ่งกล่าวว่า การเปิดเผยครั้งนี้มีลักษณะเป็นเพียงกรอบการทำงาน (framework) แต่ไม่มีการเปิดเผยเครื่องมือการทำงาน (engine) อย่างแท้จริง แล้วสิ่งที่หายไปคืออะไรกันแน่?
ไม่มีพารามิเตอร์น้ำหนัก - รหัสยืนยันว่ามีการเพิ่มคะแนนสำหรับพฤติกรรมเชิงบวกและการหักคะแนนสำหรับพฤติกรรมเชิงลบ แต่แตกต่างจากเวอร์ชันปี 2023 คือ ค่าที่เฉพาะเจาะจงถูกลบออกไป
ซ่อนน้ำหนักโมเดล - ไม่รวมพารามิเตอร์ภายในและคำนวณของโมเดลเอง
ข้อมูลการฝึกอบรมที่ยังไม่เปิดเผย - เราไม่มีข้อมูลใดๆ เกี่ยวกับข้อมูลที่ใช้ในการฝึกโมเดล วิธีการเก็บตัวอย่างพฤติกรรมของผู้ใช้ รวมถึงวิธีการสร้างตัวอย่างที่ "ดี" และตัวอย่างที่ "ไม่ดี"
สำหรับผู้ใช้ทั่วไปของ X แล้ว การเปิดเผยอัลกอริทึมของ X ไม่น่าจะส่งผลใด ๆ มากนัก แต่ความโปร่งใสที่เพิ่มขึ้นนี้สามารถอธิบายได้ว่าเหตุใดโพสต์บางโพสต์จึงได้รับการโปรโมต ในขณะที่โพสต์อื่น ๆ กลับไม่มีผู้สนใจเลย และยังช่วยให้นักวิจัยสามารถศึกษาได้ว่าแพลตฟอร์มจัดอันดับเนื้อหาต่าง ๆ อย่างไร
4. ทำไมระบบแนะนำจึงเป็นพื้นที่ที่ต้องแข่งขันกัน?
ในกรณีส่วนใหญ่ของการอภิปรายเชิงเทคนิคระบบแนะนำมักถูกมองว่าเป็นส่วนหนึ่งของวิศวกรรมด้านหลัง ซึ่งเงียบขรึม ซับซ้อน แต่กลับไม่เคยอยู่ภายใต้แสงสปอตไลต์ อย่างไรก็ตาม หากมองลึกเข้าไปในวิธีการดำเนินธุรกิจของบริษัทอินเทอร์เน็ตยักษ์ใหญ่ จะพบว่าระบบแนะนำนั้นไม่ใช่เพียงแค่ส่วนประกอบรอง แต่กลับเป็น "โครงสร้างพื้นฐาน" ที่ยึดโยงทั้งรูปแบบธุรกิจไว้ ด้วยเหตุนี้ จึงสามารถเรียกมันว่าเป็น "สัตว์ร้ายเงียบ" ของอุตสาหกรรมอินเทอร์เน็ตได้อย่างเหมาะสม
ข้อมูลสาธารณะได้ยืนยันเรื่องนี้ซ้ำแล้วซ้ำอีก แอมะซอนเคยเปิดเผยว่า ประมาณ 35% ของการซื้อสินค้าบนแพลตฟอร์มของตนเกิดขึ้นโดยตรงจากระบบแนะนำสินค้า (Recommendation System) ในขณะที่เน็ตฟลิกซ์มีการใช้งานที่มากกว่านั้น โดยประมาณ 80% ของเวลาในการดูเนื้อหาถูกขับเคลื่อนโดยอัลกอริทึมแนะนำ สำหรับยูทูบก็มีลักษณะคล้ายกัน โดยประมาณ 70% ของการดูเนื้อหาเกิดขึ้นจากระบบแนะนำ โดยเฉพาะฟีดข้อมูล (feed) ส่วนเมตา (Meta) แม้จะไม่เคยเปิดเผยสัดส่วนที่ชัดเจน แต่ทีมงานด้านเทคนิคของบริษัทเคยกล่าวไว้ว่า ประมาณ 80% ของทรัพยากรการคำนวณในคลัสเตอร์การคำนวณภายในบริษัทถูกใช้เพื่อให้บริการงานที่เกี่ยวข้องกับการแนะนำสิ่งต่าง ๆ
ตัวเลขเหล่านี้หมายความว่าอย่างไร?หากไม่มีระบบแนะนำสินค้าเหล่านี้ แทบจะเทียบเท่ากับการดึงรากฐานออกจากพื้นดินเลยก็ว่าได้สำหรับ Meta แล้ว การทำโฆษณา การวัดระยะเวลาที่ผู้ใช้อยู่ในแพลตฟอร์ม และการเปลี่ยนผู้ใช้ให้เป็นลูกค้า แทบทั้งหมดขึ้นอยู่กับระบบแนะนำเนื้อหา ระบบแนะนำเนื้อหาไม่เพียงแต่กำหนดว่าผู้ใช้จะ "เห็นอะไร" แต่ยังกำหนดโดยตรงว่าแพลตฟอร์มจะ "สร้างรายได้อย่างไร"
อย่างไรก็ตาม ระบบซึ่งมีผลต่อชีวิตและความตายเช่นนี้ กลับเผชิญกับปัญหาความซับซ้อนด้านวิศวกรรมที่สูงมากเป็นเวลานาน
ในสถาปัตยกรรมระบบแนะนำแบบดั้งเดิม ยากที่จะใช้โมเดลเดียวครอบคลุมทุกสถานการณ์ ระบบผลิตในโลกจริงมักมีความแตกแยกสูง ตัวอย่างเช่นบริษัทอย่าง Meta, LinkedIn หรือ Netflix ทั่วไปแล้ว หลังจากกระบวนการแนะนำทั้งหมด มักมีโมเดลเฉพาะทางมากกว่า 30 โมเดลที่ทำงานพร้อมกัน เช่น โมเดลเรียกคืนข้อมูล (recall model), โมเดลจัดอันดับหยาบ (coarse ranking model), โมเดลจัดอันดับละเอียด (fine ranking model), โมเดลจัดลำดับใหม่ (re-ranking model) ซึ่งแต่ละโมเดลได้รับการปรับให้เหมาะสมกับฟังก์ชันเป้าหมายและตัวชี้วัดทางธุรกิจที่แตกต่างกัน ทุกโมเดลเหล่านี้มักมีทีมงานหนึ่งหรือมากกว่านั้นรับผิดชอบงานต่างๆ เช่น วิศวกรรมคุณลักษณะ (feature engineering), การฝึกโมเดล, การปรับพารามิเตอร์, การเปิดใช้งาน และการอัปเดตอย่างต่อเนื่อง
ต้นทุนของรูปแบบนี้นั้นชัดเจน: ซับซ้อนในการพัฒนา ต้นทุนการบำรุงรักษาสูง และมีความยากในการทำงานร่วมกันระหว่างงานต่างๆ ทันทีที่มีคนเสนอคำถามว่า "เราสามารถใช้โมเดลเดียวเพื่อแก้ปัญหาการแนะนำหลายอย่างได้หรือไม่" สำหรับระบบโดยรวมแล้ว หมายถึงการลดระดับความซับซ้อนลงอย่างมาก ซึ่งนี่คือเป้าหมายที่อุตสาหกรรมปรารถนาและพยายามทำมานานแต่ยังไม่สามารถบรรลุได้
การปรากฏตัวของโมเดลภาษาขนาดใหญ่ได้มอบเส้นทางที่เป็นไปได้ใหม่ให้กับระบบแนะนำ
โมเดล LLM ได้แสดงให้เห็นในทางปฏิบัติแล้วว่าสามารถเป็นโมเดลที่ทรงพลังและมีความทั่วไปสูงได้: มีความสามารถในการถ่ายโอนระหว่างงานต่างๆ ได้ดี และประสิทธิภาพของมันยังสามารถพัฒนาต่อไปได้เมื่อขยายขนาดข้อมูลและกำลังการประมวลผล อย่างไรก็ตาม เมื่อเปรียบเทียบกับโมเดลแนะนำแบบดั้งเดิม ซึ่งมักจะเป็นแบบ "ออกแบบเฉพาะงาน" และมักจะไม่สามารถแบ่งปันความสามารถระหว่างหลายสถานการณ์ได้
สิ่งที่สำคัญกว่านั้นคือ โมเดลขนาดใหญ่เดี่ยวๆ ไม่เพียงแต่ช่วยลดความซับซ้อนด้านวิศวกรรม แต่ยังมีศักยภาพในการเรียนรู้แบบ "ข้ามกัน" (cross-learning) เมื่อโมเดลเดียวกันนี้ประมวลผลงานแนะนำต่างๆ พร้อมกัน ข้อมูลจากงานที่แตกต่างกันสามารถเสริมกันได้ และเมื่อปริมาณข้อมูลเพิ่มมากขึ้น โมเดลจะพัฒนาตัวเองได้อย่างเป็นระบบมากขึ้น ซึ่งนี่คือคุณสมบัติที่ระบบแนะนำต้องการมานานแต่ยากที่จะบรรลุได้ด้วยวิธีการแบบดั้งเดิม
LLM เปลี่ยนแปลงอะไรไปบ้าง? แท้จริงแล้วมันเปลี่ยนแปลงจากงานวิศวกรรมคุณลักษณะไปสู่ความสามารถในการเข้าใจแทน
ในแง่ของวิธีการ LLM สร้างผลกระทบสูงสุดต่อระบบแนะนำที่ขั้นตอนหลักที่เรียกว่า "การวิศวกรรมคุณลักษณะ" (Feature Engineering)
ในระบบแนะนำแบบดั้งเดิม วิศวกรจำเป็นต้องสร้างสัญญาณจำนวนมากขึ้นมาด้วยตนเองก่อน เช่น ประวัติการคลิกของผู้ใช้ ระยะเวลาที่ใช้ในการดู เนื้อหาที่ผู้ใช้ที่คล้ายคลึงกันชอบ แท็กของเนื้อหา เป็นต้น จากนั้นจึงแจ้งให้โมเดลทราบอย่างชัดเจนว่า "โปรดใช้คุณสมบัติเหล่านี้ในการตัดสินใจ" โมเดลเองไม่เข้าใจความหมายของสัญญาณเหล่านี้ แต่เพียงแค่เรียนรู้ความสัมพันธ์ในการแมปในพื้นที่ตัวเลขเท่านั้น
หลังจากที่นำโมเดลภาษาเข้ามา กระบวนการนี้ก็ถูกนามธรรมขึ้นอย่างมาก คุณไม่จำเป็นต้องระบุรายละเอียดว่า "ดูสัญญาณนี้ แต่ให้ 忽略 สัญญาณนั้น" แต่คุณสามารถอธิบายปัญหาโดยตรงกับโมเดลได้: นี่คือผู้ใช้ และนี่คือเนื้อหา; ผู้ใช้คนนี้เคยชอบเนื้อหาที่คล้ายกันมาก่อน และผู้ใช้อื่นๆ ก็มีการตอบสนองเชิงบวกต่อเนื้อหานี้เช่นกัน — ตอนนี้กรุณาตัดสินว่า เนื้อหานี้ควรแนะนำให้ผู้ใช้คนนี้หรือไม่
โมเดลภาษาเองก็มีความสามารถในการเข้าใจอยู่แล้ว ซึ่งสามารถตัดสินได้ว่าข้อมูลใดเป็นสัญญาณสำคัญ และจะสามารถสังเคราะห์สัญญาณเหล่านี้อย่างไรเพื่อให้เกิดการตัดสินใจ ในแง่หนึ่ง มันไม่ได้เพียงแค่ปฏิบัติตามกฎการแนะนำเท่านั้น แต่ยัง "เข้าใจถึงเรื่องการแนะนำ" อีกด้วย
แหล่งที่มาของความสามารถนี้อยู่ที่ LLM ได้สัมผัสกับข้อมูลจำนวนมากและหลากหลายในระหว่างขั้นตอนการฝึก ทำให้สามารถจับความรูปแบบที่ละเอียดอ่อนแต่สำคัญได้ง่ายขึ้น ในทางตรงกันข้าม ระบบแนะนำแบบดั้งเดิมต้องพึ่งพาการระบุความรูปแบบเหล่านี้โดยชัดเจนจากวิศวกร และหากมีการละเลย โมเดลก็จะไม่สามารถรับรู้ได้
จากมุมมองด้านหลังแล้ว ความเปลี่ยนแปลงนี้ไม่ใช่เรื่องแปลกใหม่ ราวกับว่าคุณถาม GPT บางสิ่งบางอย่าง มันจะสร้างคำตอบขึ้นมาโดยอ้างอิงจากบริบทที่มีอยู่เช่นเดียวกัน เมื่อคุณถามมันว่า "ฉันจะสนใจเนื้อหาชิ้นนี้หรือไม่" มันก็สามารถตัดสินใจได้จากข้อมูลที่มีอยู่เช่นกัน ระดับหนึ่ง โมเดลภาษาเองก็มีความสามารถในการ "แนะนำ" อย่างเป็นธรรมชาติอยู่แล้ว