
ตัวแทน AI ที่เรียนรู้ด้วยตนเองแตกต่างจากโมเดลการเรียนรู้ของเครื่องแบบดั้งเดิมและตัวแทนที่ใช้ LLM ปัจจุบันอย่างไร
2026/05/02 15:21:02
คำนำ
ทัศนียภาพของปัญญาประดิษฐ์กำลังผ่านการเปลี่ยนแปลงอย่างลึกซึ้ง ขณะที่แบบจำลองการเรียนรู้ของเครื่องแบบดั้งเดิมครองพื้นที่ในทศวรรษที่ผ่านมา และแบบจำลองภาษาขนาดใหญ่ดึงดูดความสนใจของโลกตั้งแต่ปี 2022 รูปแบบใหม่กำลังเกิดขึ้นซึ่งเปลี่ยนแปลงวิธีการทำงานของระบบปัญญาประดิษฐ์อย่างพื้นฐาน ตัวแทนปัญญาประดิษฐ์ที่เรียนรู้ด้วยตนเอง แสดงถึงก้าววิวัฒนาการถัดไป โดยรวมความเป็นอิสระ การให้เหตุผลแบบปรับตัว และการพัฒนาอย่างต่อเนื่องในลักษณะที่แยกแยะออกจากบรรพบุรุษและระบบปัจจุบันที่อิงตาม LLM อย่างชัดเจน การเข้าใจความแตกต่างเหล่านี้เป็นสิ่งจำเป็นสำหรับผู้ที่ต้องการนำทางในระบบนิเวศปัญญาประดิษฐ์ที่เปลี่ยนแปลงอย่างรวดเร็ว
ตัวแทน AI ที่เรียนรู้ด้วยตัวเองคืออะไร
ตัวแทน AI ที่เรียนรู้ด้วยตนเองเป็นหน่วยการคำนวณอิสระที่สามารถรับรู้สภาพแวดล้อม วิเคราะห์ข้อมูล กำหนดการตัดสินใจ และดำเนินการเพื่อให้บรรลุเป้าหมายเฉพาะเจาะจง ต่างจากระบบ AI แบบดั้งเดิมที่ต้องการคำสั่งจากมนุษย์ในทุกขั้นตอน ตัวแทนที่เรียนรู้ด้วยตนเองสามารถกำหนดเป้าหมายระดับสูงแล้วจะตัดสินใจเองว่าจะบรรลุเป้าหมายนั้นอย่างไร ตัวแทนเหล่านี้รวมความสามารถในการรับรู้ การให้เหตุผล การเรียนรู้ และการกระทำ เพื่อจำลองพฤติกรรมอัจฉริยะที่เคยพบได้เฉพาะในระบบชีวภาพ
ลักษณะสำคัญของตัวแทน AI ที่เรียนรู้ด้วยตนเอง ได้แก่ ความเป็นอิสระ ความไวต่อสิ่งเร้า ความริเริ่ม และความสามารถทางสังคม ความเป็นอิสระช่วยให้ตัวแทนสามารถทำงานได้อย่างอิสระโดยไม่ต้องมีการแทรกแซงจากมนุษย์อย่างต่อเนื่อง ความไวต่อสิ่งเร้าช่วยให้พวกเขาสามารถรับรู้การเปลี่ยนแปลงของสภาพแวดล้อมและตอบสนองอย่างเหมาะสม ความริเริ่มหมายความว่าพวกเขาไม่ได้แค่ตอบสนองต่อสิ่งเร้า แต่ยังมุ่งเน้นไปที่การบรรลุเป้าหมายผ่านการวางแผนอย่างกระตือรือร้น ความสามารถทางสังคมอนุญาตให้พวกเขาทำงานร่วมกับตัวแทนอื่นๆ ในระบบตัวแทนหลายตัวเพื่อ hoàn thànhงานที่ซับซ้อน
ตามการพยากรณ์ปัญญาประดิษฐ์ของไมโครซอฟต์ในปี 2025 ตัวแทนที่ขับเคลื่อนด้วยปัญญาประดิษฐ์กำลังได้รับความเป็นอิสระมากขึ้นในการดำเนินงานที่หลากหลาย จึงช่วยยกระดับคุณภาพชีวิตในหลายด้าน ความแตกต่างหลักอยู่ที่วิธีการที่ตัวแทนเหล่านี้จัดการเป้าหมาย: ในขณะที่โมเดลภาษาขนาดใหญ่ต้องการคำสั่งที่ละเอียดและร่างขึ้นอย่างดีเพื่อผลลัพธ์คุณภาพสูง ตัวแทนปัญญาประดิษฐ์ต้องการเพียงเป้าหมายเท่านั้น และจะคิดและดำเนินการตามขั้นตอนที่จำเป็นด้วยตนเอง
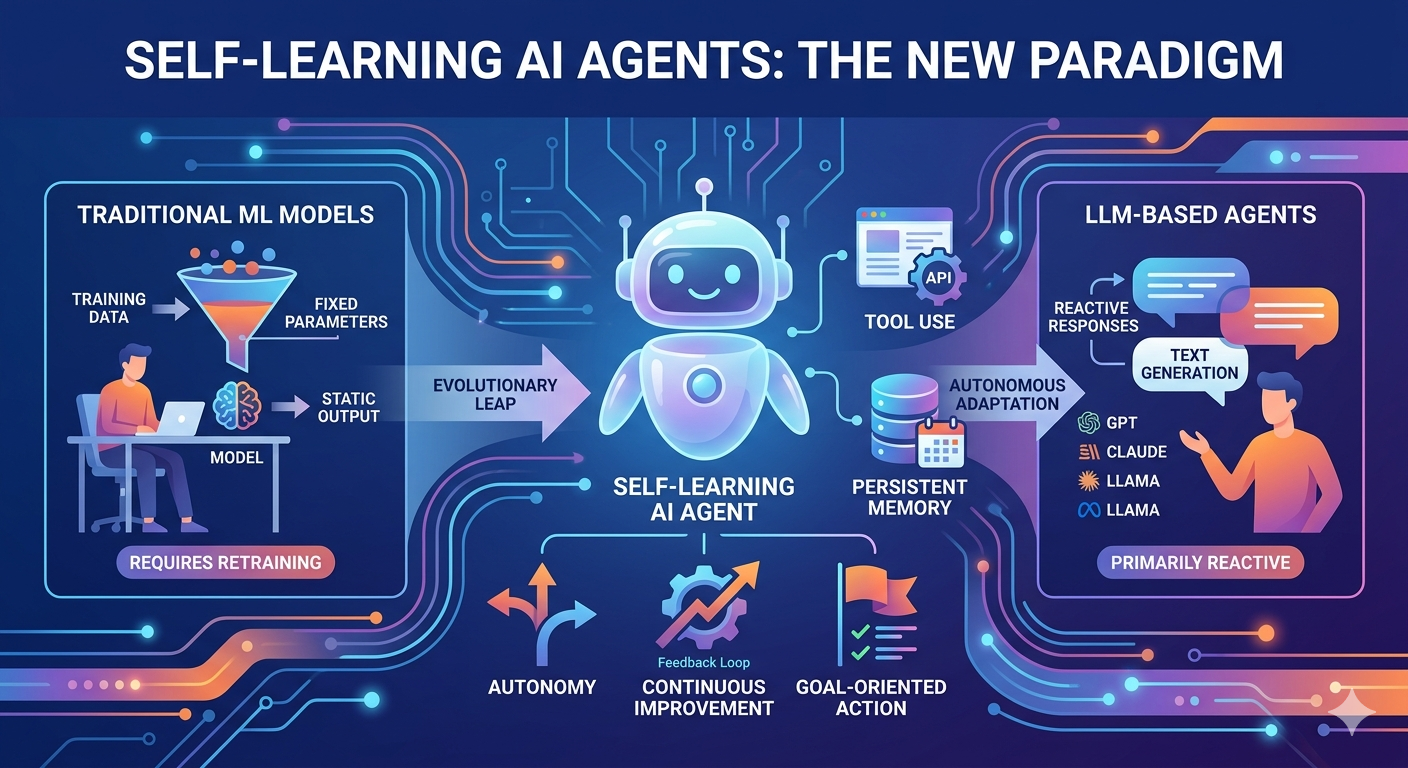
แบบจำลองการเรียนรู้ของเครื่องแบบดั้งเดิม: โครงสร้างและข้อจำกัด
แบบจำลองการเรียนรู้ของเครื่องแบบดั้งเดิมแสดงถึงวิธีการที่แตกต่างอย่างสิ้นเชิงจากปัญญาประดิษฐ์ แบบจำลองเหล่านี้มักจะได้รับการฝึกฝนบนชุดข้อมูลเฉพาะเพื่อทำการทำงานที่แคบและกำหนดไว้อย่างชัดเจน เช่น การจำแนกประเภท การถดถอย หรือการจัดกลุ่ม เมื่อถูกนำไปใช้งานแล้ว พวกมันจะทำงานภายในพารามิเตอร์ที่คงที่และไม่สามารถปรับเปลี่ยนพฤติกรรมของตนเองตามประสบการณ์ใหม่ได้ หากไม่มีการฝึกฝนใหม่อย่างชัดเจน
สถาปัตยกรรมของโมเดล ML แบบดั้งเดิมเน้นที่การเรียนรู้ทางสถิติจากข้อมูลในอดีต โมเดลจะเรียนรู้รูปแบบระหว่างการฝึกฝนและนำรูปแบบที่เรียนรู้มาใช้กับข้อมูลใหม่ในช่วงการอนุมาน วิธีการนี้ทำงานได้ดีเยี่ยมสำหรับงานที่มีรูปแบบชัดเจนและข้อมูลนำเข้าคงที่ เช่น การตรวจจับสแปม การจำแนกภาพ หรือระบบแนะนำ อย่างไรก็ตาม ลักษณะคงที่ของโมเดลเหล่านี้สร้างข้อจำกัดที่สำคัญในสภาพแวดล้อมที่เปลี่ยนแปลงและไม่สามารถคาดเดาได้
แบบจำลอง ML แบบดั้งเดิมต้องการวิศวกรมนุษย์ในการกำหนดคุณลักษณะ เลือกอัลกอริธึม และปรับค่าไฮเปอร์พารามิเตอร์ เมื่อการกระจายข้อมูลเปลี่ยนแปลงหรือข้อกำหนดของงานเปลี่ยนแปลง แบบจำลองอาจมีประสิทธิภาพลดลงและต้องการการฝึกใหม่ กระบวนการเรียนรู้จะถูกตรึงไว้หลังจากการนำไปใช้งาน หมายความว่าระบบที่เหล่านี้ไม่สามารถพัฒนาได้จากประสบการณ์หรือปรับตัวเข้ากับสถานการณ์ใหม่ๆ ได้โดยไม่มีการแทรกแซงอย่างชัดเจน
ทีมด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบมักใช้การเรียนรู้ของเครื่องแบบดั้งเดิมในการรับรู้รูปแบบจากข้อมูลที่มีโครงสร้าง แต่ระบบเหล่านี้มีข้อจำกัดเมื่อเผชิญกับงานที่ต้องการความเข้าใจในบริบทหรือการให้เหตุผลหลายขั้นตอน พวกมันขาดความสามารถในการวางแผน การวิเคราะห์ความสัมพันธ์เชิงเหตุและผล หรือการแยกปัญหาที่ซับซ้อนออกเป็นงานย่อยที่จัดการได้ง่ายกว่า
ตัวแทนที่ใช้ LLM: ความสามารถปัจจุบันและข้อจำกัด
ตัวแทนที่ใช้ LLM-based agents ในปัจจุบันถือเป็นความก้าวหน้าครั้งใหญ่เหนือการเรียนรู้ของเครื่องแบบดั้งเดิม ระบบเหล่านี้สร้างขึ้นจากโมเดลภาษาขนาดใหญ่ที่มีพารามิเตอร์หลายพันล้านตัว ซึ่งสามารถเข้าใจภาษาธรรมชาติ สร้างข้อความที่คล้ายมนุษย์ และดำเนินการงานเชิงเหตุผลที่ก่อนหน้านี้ AI ไม่สามารถทำได้ บริษัทต่างๆ เช่น OpenAI, Anthropic และ Google ได้พัฒนาโมเดลที่มีความสามารถสูงขึ้นเรื่อยๆ ซึ่งเป็นรากฐานสำหรับแอปพลิเคชัน AI จำนวนมากในปัจจุบัน
ตัวแทนที่ใช้ LLM โดดเด่นในการเข้าใจและสร้างภาษาธรรมชาติ พวกเขาสามารถมีบทสนทนาที่มีความหมาย สรุปเอกสาร เขียนโค้ด และอธิบายแนวคิดที่ซับซ้อน ตัวแบบ o1 ของ OpenAI ตัวอย่างเช่น แสดงความสามารถในการให้เหตุผลขั้นสูง ซึ่งช่วยให้มันสามารถแก้ปัญหาที่ซับซ้อนได้โดยใช้ขั้นตอนเชิงตรรกะที่คล้ายกับการวิเคราะห์ของมนุษย์ก่อนตอบคำถามที่ยาก
อย่างไรก็ตาม ตัวแทนที่ใช้ LLM ปัจจุบันส่วนใหญ่เป็นระบบเชิงรับโดยพื้นฐาน พวกมันตอบสนองต่อคำสั่งของผู้ใช้ แต่ไม่ได้ดำเนินการอย่างรุกเพื่อให้บรรลุเป้าหมายหรือดำเนินการในโลกจริง เมื่อคุณมีปฏิสัมพันธ์กับแชทบอท ระบบจะสร้างคำตอบจากข้อมูลที่คุณป้อนและข้อมูลการฝึกอบรมของมัน แต่ไม่ได้ดำเนินการอย่างอิสระเพื่อบรรลุเป้าหมายที่กว้างขึ้นโดยไม่มีการแนะนำจากมนุษย์อย่างต่อเนื่อง
ข้อจำกัดของตัวแทนที่ใช้ LLM จะชัดเจนเมื่อภารกิจต้องการความพยายามอย่างต่อเนื่องข้ามหลายขั้นตอน การรวมเข้ากับเครื่องมือภายนอก หรือการปรับตัวตามข้อเสนอแนะ แม้ว่าโมเดลเหล่านี้จะสามารถวิเคราะห์ปัญหาได้ภายในแพลตฟอร์มแลกเปลี่ยนเดียว แต่มักขาดความสามารถในการรักษาสถานะข้ามการโต้ตอบ การดำเนินการในระบบภายนอก หรือการเรียนรู้จากผลลัพธ์ของการตัดสินใจของตน
ความแตกต่างหลัก: ตัวแทน AI ที่เรียนรู้ด้วยตนเอง เทียบกับ ML แบบดั้งเดิม
ความแตกต่างระหว่างตัวแทน AI ที่เรียนรู้ด้วยตนเองกับแบบจำลองการเรียนรู้ของเครื่องแบบดั้งเดิมครอบคลุมถึงสถาปัตยกรรม ความสามารถ และปรัชญาการดำเนินงาน การเข้าใจความแตกต่างเหล่านี้ช่วยให้ชัดเจนว่าทำไมผู้เชี่ยวชาญจำนวนมากจึงมองว่าตัวแทนเป็นขอบเขตถัดไปของการพัฒนา AI
-
การเรียนรู้และการปรับตัว
แบบจำลอง ML แบบดั้งเดิมเรียนรู้ในช่วงการฝึกที่กำหนดไว้แล้วจึงทำงานแบบคงที่ แบบจำลองตรวจจับการฉ้อโกงที่ฝึกจากข้อมูลธุรกรรมในอดีตจะใช้รูปแบบเดิมๆ ไปตลอดเวลาเว้นแต่จะมีการฝึกใหม่ ในทางตรงกันข้าม ตัวแทนที่เรียนรู้ด้วยตนเองสามารถเรียนรู้อย่างต่อเนื่องจากปฏิสัมพันธ์กับสภาพแวดล้อมของตน พวกเขาสังเกตผลลัพธ์ของการกระทำของตน วิเคราะห์ว่าอะไรใช้งานได้และอะไรไม่ได้ และปรับกลยุทธ์ของตนตามนั้น
-
ความเป็นอิสระและพฤติกรรมที่มุ่งเป้าหมาย
แบบจำลอง ML แบบดั้งเดิมเป็นเครื่องมือที่มนุษย์ใช้เพื่อทำภารกิจเฉพาะเจาะจง พวกเขาไม่ได้ตั้งเป้าหมายด้วยตนเอง; พวกเขาแค่ประมวลผลข้อมูลนำเข้าและสร้างผลลัพธ์ตามรูปแบบที่เรียนรู้มา ตัวแทนที่เรียนรู้ด้วยตนเองเป็นระบบที่มุ่งเป้าหมายซึ่งสามารถรับเป้าหมายระดับสูงและกำหนดวิธีการที่ดีที่สุดในการบรรลุเป้าหมายเหล่านั้น พวกเขาแบ่งเป้าหมายที่ซับซ้อนออกเป็นงานย่อย ดำเนินการงานย่อยเหล่านั้น และปรับวิธีการตามความคืบหน้า
-
การใช้เครื่องมือและการโต้ตอบกับสิ่งแวดล้อม
ตัวแทนที่เรียนรู้ด้วยตนเองสามารถเชื่อมต่อกับเครื่องมือภายนอก API และระบบซอฟต์แวร์ได้ พวกเขาสามารถท่องอินเทอร์เน็ต จัดการไฟล์ รันโค้ด และโต้ตอบกับฐานข้อมูล โมเดลการเรียนรู้ของเครื่องแบบดั้งเดิมมักไม่สามารถทำสิ่งเหล่านี้ได้; พวกมันถูกจำกัดเฉพาะกับข้อมูลนำเข้าที่ได้รับและผลลัพธ์ที่สร้างขึ้นภายในกราฟการคำนวณของตนเอง
-
การเข้าใจบริบทและการวางแผน
ในขณะที่การเรียนรู้ของเครื่องแบบดั้งเดิมมีจุดแข็งในการรับรู้รูปแบบในข้อมูลที่มีโครงสร้าง ตัวแทนที่เรียนรู้ด้วยตนเองแสดงความสามารถที่เหนือกว่าในการเข้าใจบริบทและการวางแผนโซลูชันหลายขั้นตอน ตัวแทนที่ได้รับเป้าหมายในการวางแผนการเดินทางจะทำการวิจัยจุดหมายปลายทาง เปรียบเทียบราคา ตรวจสอบความพร้อม และจองการจัดการ—พฤติกรรมที่โมเดลการจำแนกประเภทแบบคงที่ไม่สามารถทำได้
ความแตกต่างหลัก: ตัวแทน AI ที่เรียนรู้ด้วยตนเอง vs ตัวแทนที่ใช้ LLM
ความแตกต่างระหว่างตัวแทน AI ที่เรียนรู้ด้วยตนเองกับตัวแทนที่ใช้ LLM ปัจจุบันนั้นละเอียดอ่อนแต่มีผลอย่างมีนัยสำคัญ ทั้งสองประเภทอาจใช้โมเดลภาษาขนาดใหญ่เป็นส่วนประกอบหลัก แต่สถาปัตยกรรมและโหมดการดำเนินงานของพวกมันแตกต่างกันอย่างมาก
-
การดำเนินการแบบตอบสนอง vs การดำเนินการแบบรุก
ตัวแทนที่ใช้โมเดล LLM รุ่นล่าสุดส่วนใหญ่เป็นระบบเชิงรับที่สร้างคำตอบตอบกลับคำสั่ง ผู้ใช้ถามคำถาม และโมเดลจะให้คำตอบ อย่างไรก็ตาม ตัวแทนที่เรียนรู้ด้วยตนเองสามารถทำงานเชิงรุกได้ เมื่อมีเป้าหมาย พวกเขาจะดำเนินการเองเพื่อรวบรวมข้อมูล วางแผน และดำเนินการโดยไม่ต้องรอคำสั่งจากมนุษย์ในแต่ละขั้นตอน
-
การจัดการสถานะและหน่วยความจำ
LLM แบบดั้งเดิมจะจัดการการสนทนาแต่ละครั้งเป็นแบบไม่มีสถานะ แม้ว่าการใช้งานบางแบบจะเพิ่มหน้าต่างบริบท ตัวแทนที่เรียนรู้ด้วยตนเองมีระบบความจำที่ซับซ้อนซึ่งเก็บข้อมูลข้ามเซสชัน ติดตามความคืบหน้าไปสู่เป้าหมาย และสามารถเรียนรู้จากประสบการณ์ในอดีต ความจำที่คงอยู่นี้ช่วยให้ตัวแทนสามารถสร้างต่อจากงานที่ผ่านมาแทนที่จะเริ่มต้นใหม่ทุกครั้งที่มีการโต้ตอบ
-
การผสานรวมเครื่องมือและการดำเนินการ
ตัวแทนที่ใช้ LLM ส่วนใหญ่สร้างข้อความ แม้แต่เมื่อข้อความนั้นแทนโค้ดหรือคำสั่ง ตัวแทนที่เรียนรู้ด้วยตนเองออกแบบมาเพื่อดำเนินการคำสั่งเหล่านั้นจริงๆ และโต้ตอบกับระบบภายนอก OpenAI's Operator และ Claude's Computer Use แสดงถึงก้าวแรกในทิศทางนี้ ทำให้ AI สามารถควบคุมเบราว์เซอร์ อินเทอร์เฟซบรรทัดคำสั่ง และแอปพลิเคชันซอฟต์แวร์
-
การปรับตัวของกระบวนการทำงานแบบไดนามิก
เมื่อตัวแทนที่ใช้ LLM พบอุปสรรค มักจะล้มเหลวหรือแสดงข้อความข้อผิดพลาด ตัวแทนที่เรียนรู้ด้วยตนเองสามารถรับรู้ได้ว่าแนวทางเริ่มต้นของมันไม่ได้ผล วิเคราะห์สาเหตุ และปรับกลยุทธ์แบบไดนามิก ความสามารถในการวนซ้ำและปรับตัวนี้มีความสำคัญอย่างยิ่งต่อการจัดการงานที่ซับซ้อนในโลกแห่งความเป็นจริง ซึ่งแทบไม่เคยดำเนินไปตามแผนที่วางไว้อย่างสมบูรณ์
สถาปัตยกรรมของตัวแทนที่เรียนรู้ด้วยตนเอง
การเข้าใจสิ่งที่ทำให้ตัวแทนการเรียนรู้ด้วยตนเองแตกต่างออกไป ต้องพิจารณาสถาปัตยกรรมพื้นฐานของพวกมัน ระบบเหล่านี้รวมองค์ประกอบหลายส่วนที่ทำงานร่วมกันเพื่อให้เกิดพฤติกรรมอัตโนมัติและปรับตัวได้
-
เครื่องมือวางแผนและวิเคราะห์เหตุผล
แกนหลักของตัวแทนที่เรียนรู้ด้วยตนเองคือเครื่องจักรการให้เหตุผล ซึ่งมักขับเคลื่อนด้วยโมเดลภาษาขนาดใหญ่ ที่สามารถแยกเป้าหมายที่ซับซ้อนออกเป็นขั้นตอนที่สามารถดำเนินการได้ เครื่องจักรนี้ช่วยให้ตัวแทนสามารถวางแผน วิเคราะห์ความสัมพันธ์เชิงเหตุและผล และประเมินผลลัพธ์ของพฤติกรรมที่เป็นไปได้ การวิจัยของไมโครซอฟท์ชี้ให้เห็นว่า วิธีการฝึกฝนและความสามารถของตัวแทนอาจสร้างผลกระทบเชิงสัมพันธ์ โดยโมเดลที่ดีขึ้นจะช่วยให้ตัวแทนมีประสิทธิภาพมากยิ่งขึ้น
-
ระบบหน่วยความจำ
ตัวแทนที่เรียนรู้ด้วยตนเองมีหน่วยความจำหลายประเภท: หน่วยความจำระยะสั้นสำหรับงานปัจจุบัน หน่วยความจำระยะยาวสำหรับความรู้ที่คงอยู่ และหน่วยความจำแบบเหตุการณ์สำหรับประสบการณ์ในอดีต ระบบหน่วยความจำเหล่านี้ช่วยให้ตัวแทนสามารถเรียนรู้จากข้อเสนอแนะ จดจำกลยุทธ์ที่ประสบความสำเร็จ และหลีกเลี่ยงการซ้ำผิดพลาด ความซับซ้อนของระบบหน่วยความจำเหล่านี้เป็นสิ่งที่แยกแยะตัวแทนที่เรียนรู้ด้วยตนเองอย่างแท้จริงออกจากระบบตอบสนองแบบง่าย
-
การใช้งานเครื่องมือและการผสานรวม API
ตัวแทนได้รับความสามารถในการเรียกใช้เครื่องมือภายนอก เข้าถึงฐานข้อมูล ท่องเว็บ และโต้ตอบกับแอปพลิเคชันซอฟต์แวร์ ความสามารถในการใช้เครื่องมือนี้ขยายขอบเขตของตัวแทนให้ vượtพ้นการสร้างข้อความเพียงอย่างเดียวไปสู่การกระทำในโลกจริง ตัวแทนสามารถเลือกเครื่องมือที่เหมาะสมตามงาน ดำเนินการเรียกใช้เครื่องมือ และรวมผลลัพธ์เข้ากับการวิเคราะห์ของมัน
-
ข้อเสนอแนะและกลไกการเรียนรู้
คุณลักษณะที่โดดเด่นที่สุดของตัวแทนที่เรียนรู้ด้วยตนเองคือความสามารถในการเรียนรู้จากประสบการณ์ เมื่อตัวแทนพยายามทำภารกิจหนึ่งๆ มันสามารถประเมินผลลัพธ์ ระบุสิ่งที่ผิดพลาด และปรับวิธีการสำหรับการพยายามครั้งต่อไป การเรียนรู้นี้สามารถเกิดขึ้นผ่านกลไกต่างๆ รวมถึงการเรียนรู้แบบเสริมแรง การสะท้อนตนเอง และการปรับปรุงแบบวนซ้ำ
การประยุกต์ใช้งานจริงและผลกระทบ
ความสามารถพิเศษของตัวแทน AI ที่เรียนรู้ด้วยตนเองกำลังเปิดโอกาสให้เกิดแอปพลิเคชันใหม่ๆ ข้ามอุตสาหกรรม ไมโครซอฟท์รายงานว่าเกือบ 70% ของพนักงานในบริษัท Fortune 500 ใช้ตัวแทน Microsoft 365 Copilot ในการจัดการงานประจำวันที่ซ้ำซาก เช่น การกรองอีเมลและการจดบันทึกการประชุมระหว่างการประชุมผ่าน Teams
ในการจัดการห่วงโซ่อุปทาน ตัวแทนสามารถคาดการณ์การเปลี่ยนแปลงความต้องการสินค้าคงคลังจากข้อมูลในอดีตและข้อมูลแบบเรียลไทม์ พร้อมปรับแผนการจัดซื้อและการผลิตเพื่อหลีกเลี่ยงสถานการณ์สินค้าหมดหรือสินค้าล้นคลัง ในด้านการดูแลสุขภาพ ตัวแทนสามารถวิเคราะห์กรณีผู้ป่วย ให้คำแนะนำในการวินิจฉัย และช่วยในการวางแผนการรักษาโดยประมวลผลข้อมูลทางการแพทย์และบันทึกผู้ป่วยจำนวนมาก
ผลกระทบยังขยายเกินกว่าการเพิ่มประสิทธิภาพ เพียงอย่างเดียว ตัวแทนที่เรียนรู้ด้วยตนเองกำลังเปลี่ยนแปลงวิธีการดำเนินงานของงานที่ต้องใช้ความรู้ แทนที่มนุษย์จะเรียนรู้วิธีใช้เครื่องมือ AI รูปแบบกำลังเปลี่ยนไปสู่ตัวแทน AI ที่เรียนรู้เพื่อช่วยเหลือมนุษย์ได้อย่างมีประสิทธิภาพมากขึ้น นี่คือการเปลี่ยนแปลงพื้นฐานในความสัมพันธ์ระหว่างมนุษย์กับ AI ที่เคลื่อนจากมนุษย์ที่ใช้งานเครื่องมือ สู่การที่มนุษย์กำกับดูแลและร่วมมือกับตัวแทนอัตโนมัติ
องค์กรสามารถเตรียมตัวสำหรับยุคตัวแทนได้อย่างไร?
องค์กรที่ต้องการใช้เลเวอเรจตัวแทน AI ที่เรียนรู้ด้วยตนเองควรเริ่มต้นด้วยการระบุกรณีการใช้งานที่มีมูลค่าสูง ซึ่งความสามารถของตัวแทนสามารถให้ข้อได้เปรียบอย่างมากเมื่อเทียบกับวิธีการแบบดั้งเดิม งานที่เกี่ยวข้องกับกระบวนการหลายขั้นตอน การรวมระบบภายนอก หรือสภาพแวดล้อมที่เปลี่ยนแปลงได้ เป็นตัวเลือกที่เหมาะสมที่สุดสำหรับการใช้งานตัวแทน
โครงสร้างพื้นฐานทางเทคนิคต้องพัฒนาให้รองรับการดำเนินงานของตัวแทน ซึ่งรวมถึงการบูรณาการ API ที่มั่นคง การเข้าถึงเครื่องมืออย่างปลอดภัย และระบบการตรวจสอบที่สามารถติดตามประสิทธิภาพของตัวแทนและตรวจจับปัญหา องค์กรควรจัดตั้งกรอบการกำกับดูแลที่กำหนดขอบเขตที่เหมาะสมสำหรับความเป็นอิสระของตัวแทน ในขณะเดียวกันก็รับประกันการปฏิบัติตามกฎระเบียบที่เกี่ยวข้อง
การลงทุนในความรู้ความเข้าใจเกี่ยวกับตัวแทนภายในองค์กรกลายเป็นสิ่งจำเป็นเมื่อระบบเหล่านี้มีความแพร่หลายมากขึ้น พนักงานจำเป็นต้องเข้าใจว่าตัวแทนทำงานอย่างไร วิธีให้คำแนะนำที่มีประสิทธิภาพ และวิธีประเมินและปรับปรุงผลลัพธ์ของตัวแทน การเปลี่ยนแปลงนี้ต้องการไม่เพียงแต่การลงทุนด้านเทคนิค แต่ยังรวมถึงการปรับตัวด้านวัฒนธรรม
สรุป
ตัวแทน AI ที่เรียนรู้ด้วยตนเองเป็นความก้าวหน้าพื้นฐานในความสามารถของปัญญาประดิษฐ์ ต่างจากโมเดลการเรียนรู้ของเครื่องแบบดั้งเดิมที่เป็นแบบคงที่และเฉพาะงาน ตัวแทนสามารถปรับตัว วางแผน และดำเนินการไหล่ของงานที่ซับซ้อนได้อย่างอิสระ เมื่อเทียบกับระบบปัจจุบันที่ใช้ LLM ตัวแทนเพิ่มความสามารถในการดำเนินการเชิงรุก หน่วยความจำถาวร และความสามารถในการดำเนินการในโลกจริงผ่านการผสานรวมเครื่องมือ
การเปลี่ยนผ่านจาก AI แบบตอบสนอง เป็นตัวแทนอัตโนมัติ ถือเป็นการเปลี่ยนแปลงรูปแบบที่เทียบเท่ากับการเปลี่ยนจาก AI แบบจำกัดไปสู่การเข้าใจภาษาทั่วไป องค์กรที่เข้าใจความแตกต่างเหล่านี้และเตรียมตัวให้เหมาะสม จะอยู่ในตำแหน่งที่ดีที่สุดในการใช้ศักยภาพอันเปลี่ยนแปลงของตัวแทนที่เรียนรู้ด้วยตนเอง ยุคของตัวแทนไม่ได้กำลังจะมา—มันอยู่ที่นี่แล้ว กำลังเปลี่ยนแปลงวิธีการทำงานและสิ่งที่ AI สามารถบรรลุได้
คำถามที่พบบ่อย
ความแตกต่างหลักระหว่างตัวแทน AI กับแบบจำลองการเรียนรู้ของเครื่องแบบดั้งเดิมคืออะไร
แบบจำลอง ML แบบดั้งเดิมเรียนรู้รูปแบบระหว่างการฝึกฝนและใช้รูปแบบเหล่านั้นอย่างคงที่กับข้อมูลใหม่ ซึ่งต้องมีการฝึกฝนใหม่เพื่อปรับตัว ขณะที่ตัวแทน AI ที่เรียนรู้ด้วยตนเองสามารถเรียนรู้อย่างต่อเนื่องจากประสบการณ์ ปรับตัวเข้ากับสถานการณ์ใหม่ และทำงานด้วยตนเองโดยไม่ต้องพึ่งการแทรกแซงหรือการฝึกฝนใหม่จากมนุษย์อย่างสม่ำเสมอ
เอเจนต์ปัญญาประดิษฐ์ที่เรียนรู้ด้วยตัวเองสามารถแทนที่แชทบอทที่ใช้ LLM ปัจจุบันได้หรือไม่
ตัวแทน AI และ LLM มีจุดประสงค์ที่ต่างกันและมักเสริมกันมากกว่าแข่งขันกัน LLM โดดเด่นในการเข้าใจและสร้างภาษา ส่วนตัวแทนเพิ่มความสามารถในการทำงานอย่างอิสระ การกระทำ และการเรียนรู้แบบปรับตัว ตัวแทนจำนวนมากใช้ LLM เป็นเครื่องจักรในการให้เหตุผลพร้อมเพิ่มชั้นสำหรับการวางแผน ความจำ และการใช้เครื่องมือ
เอเจนต์ปัญญาประดิษฐ์ที่เรียนรู้ด้วยตัวเองต้องการทรัพยากรการประมวลผลมากกว่าโมเดลการเรียนรู้ของเครื่องแบบดั้งเดิมหรือไม่
เอเจนต์ที่เรียนรู้ด้วยตัวเองมักต้องการทรัพยากรการคำนวณมากขึ้นเนื่องจากความซับซ้อน การจัดการสถานะอย่างต่อเนื่อง และมักมีโมเดลพื้นฐานที่ใหญ่กว่า อย่างไรก็ตาม ประโยชน์ด้านประสิทธิภาพจากการดำเนินการอย่างอิสระและการลดความจำเป็นในการดูแลจากมนุษย์สามารถชดเชยต้นทุนเหล่านี้ได้ในหลายแอปพลิเคชัน
ตัวแทนที่เรียนรู้ด้วยตัวเองจัดการกับข้อผิดพลาดและความล้มเหลวอย่างไร
ตัวแทนที่เรียนรู้ด้วยตนเองสามารถรับรู้ได้ว่าเมื่อวิธีการของพวกมันไม่ได้ผล วิเคราะห์สาเหตุของความล้มเหลว และปรับกลยุทธ์อย่างยืดหยุ่น ความสามารถในการปรับปรุงแบบวนซ้ำนี้ช่วยให้พวกมันจัดการกับสถานการณ์ที่ไม่สามารถคาดเดาได้ได้ดีกว่าระบบคงที่ แม้ว่าการจัดการข้อผิดพลาดอย่างแข็งแกร่งและการกำกับดูแลจากมนุษย์ยังคงมีความสำคัญ
เอไอที่เรียนรู้ด้วยตัวเองปลอดภัยสำหรับการใช้งานทางธุรกิจหรือไม่
เมื่อออกแบบอย่างเหมาะสมพร้อมมาตรการป้องกันที่เหมาะสม ตัวแทนที่เรียนรู้ด้วยตนเองสามารถนำไปใช้งานในสภาพแวดล้อมทางธุรกิจได้อย่างปลอดภัย องค์กรควรกำหนดขอบเขตที่ชัดเจนสำหรับความเป็นอิสระของตัวแทน สร้างระบบการตรวจสอบ และรักษาการกำกับดูแลโดยมนุษย์สำหรับการตัดสินใจที่สำคัญ กุญแจสำคัญคือการสมดุลระหว่างความสามารถของตัวแทนกับกรอบการกำกับดูแลที่เหมาะสม
คำปฏิเสธความรับผิดชอบ: หน้านี้แปลโดยใช้เทคโนโลยี AI (ขับเคลื่อนโดย GPT) เพื่อความสะดวกของคุณ สำหรับข้อมูลที่ถูกต้องที่สุด โปรดดูต้นฉบับภาษาอังกฤษ