









Автор оригинала: Дэвид, DeepTide TechFlow
20 января X выпустил новую версию рекомендательного алгоритма.
Очень интересный ответ от Маска: «Мы знаем, что алгоритм глупый и нуждается в серьёзной доработке, но по крайней мере вы можете увидеть, как мы боремся за улучшение в реальном времени. Другие социальные платформы не осмеливаются так делать».
В этих словах есть два смысла.Первое — признание того, что алгоритм имеет проблемы, и второе — использование «прозрачности» в качестве преимущества.
Это второй раз, когда X делает свой алгоритм открытым исходным кодом. Версия кода 2023 года не обновлялась три года и давно отстала от реальной системы. На этот раз всё было полностью переписано, а в ядре модель была заменена с традиционного машинного обучения на Grok transformer. Официальная версия звучит как «полное устранение ручного инженерирования признаков».
Раньше алгоритмы зависели от ручной настройки параметров инженерами, а теперь ИИ напрямую изучает историю ваших взаимодействий, чтобы решить, стоит ли рекомендовать ваш контент.
Это означает, что для создателей контента старые "законы" вроде "в какое время лучше всего публиковать посты" или "какие теги увеличивают количество подписчиков" могут перестать работать.
Мы также изучили исходный код открытых репозиториев на Github и с помощью ИИ обнаружили, что в коде действительно скрывается несколько жёстких логических конструкций, которые стоят рассмотреть.
Изменение логики алгоритма: от вручную заданных правил к автоматическому определению с помощью ИИ
Сначала ясно опишите различия между новой и старой версиями, иначе дальнейшие обсуждения будут запутанными.
В 2023 году, та версия Твиттера, которая была открыта для общественности, называлась Heavy Ranker, по сути это была традиционная машинная обработка. Инженерам приходилось вручную определять сотни «признаков»: есть ли изображение в посте, сколько у автора поста подписчиков, как давно был опубликован пост, есть ли в посте ссылка...
Потом задайте веса для каждого признака, настройте их, посмотрите, какая комбинация даст лучший результат.
Новая открытая версия называется Phoenix, у нее совершенно новая архитектура, вы можете понять это как алгоритм, который еще больше зависит от крупных моделей ИИ. Ядро использует модель трансформера Grok, и ChatGPT, и Claude используют ту же технологию.
В официальном README прямо написано: «Мы исключили каждую вручную разработанную функцию».
Все традиционные правила вручную извлекаемых характеристик контента были отменены.
А теперь, на основе чего этот алгоритм определяет, хорош ли контент или нет?
Ответ зависит от тебяПоследовательность действийВы когда-либо ставили лайки, отвечали кому-либо, заходили ли вы на какие-либо темы более чем на две минуты, какие типы аккаунтов вы блокировали. Phoenix подаёт эти действия в качестве данных в transformer, чтобы модель могла сама выявить закономерности и обобщить их.
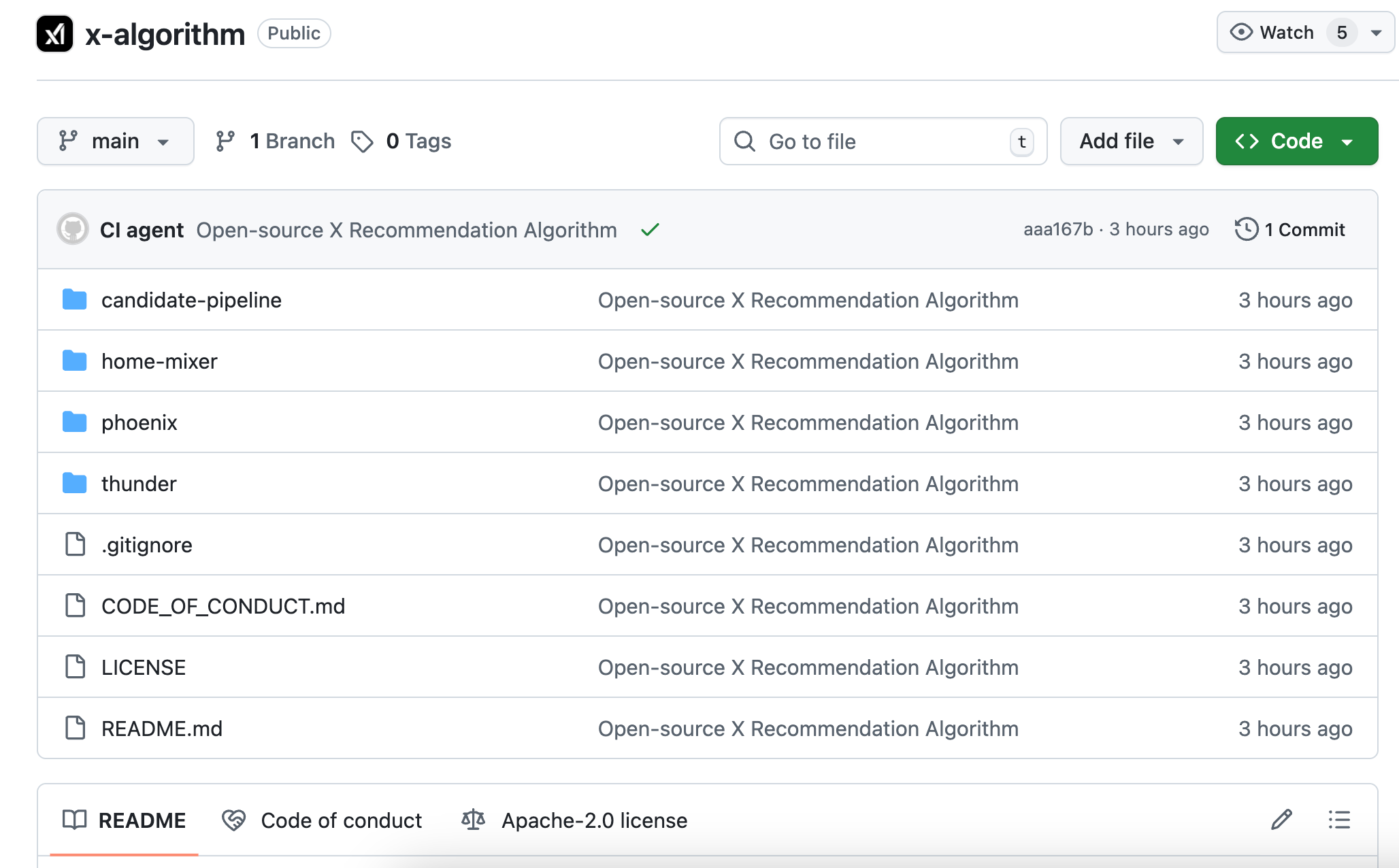
В качестве примера: старый алгоритм похож на вручную составленную таблицу оценок, где за каждую позицию ставится галочка и начисляются баллы;
Новый алгоритм подобен ИИ, просматривавшему всю вашу историю просмотров,Угадай сходуЧто ты хочешь увидеть в следующую секунду.
Для авторов это означает две вещи:
Первое: старые хитрости вроде «лучшее время для публикации» и «золотые хэштеги» стали менее значимыми.Потому что модель больше не учитывает эти фиксированные признаки, она учитывает индивидуальные предпочтения каждого пользователя.
Во-вторых, способность твоего контента распространяться всё больше зависит от того, как на него отреагируют те, кто его увидит.Эта реакция была количественно определена в виде 15-ти поведенческих прогнозов, о которых мы подробнее расскажем в следующей главе.
Алгоритм предсказывает ваши 15 реакций
После получения рекомендуемого сообщения Phoenix предскажет 15 возможных действий, которые может совершить пользователь, увидев этот контент:
- Положительное поведение: лайки, ответы, репосты, цитирование, переход к публикации, переход на страницу автора, просмотр более половины видео, раскрытие изображения, делиться, оставаться на определенное время, подписаться на автора
- Негативное поведениеНапример, нажмите «Не интересно», заблокируйте автора, отключите уведомления от автора, пожалуйтесь
Каждое действие соответствует определённой вероятности прогноза. Например, модель оценивает, что у вас есть 60% вероятности поставить лайк этой записи, 5% вероятности заблокировать автора и так далее.
А затем алгоритм делает что-то простое: умножает эти вероятности на соответствующие веса, складывает их и получает общий балл.
Формула выглядит так:
Итоговый результат = Σ (вес × P(действие))
Веса положительного поведения положительны, веса отрицательного поведения отрицательны.
Посты с высоким общим количеством баллов будут вверху, а с низким — внизу.
На самом деле, говоря простым языком, выход за рамки формул - это:
Сейчас качество контента уже не определяется самим контентом (конечно, читабельность и полезность остаются основой распространения); оно во многом зависит от того, «какую реакцию вызовет у вас этот контент». Алгоритм не заботится о качестве публикации, он учитывает только ваши действия.
Следуя этой логике, в крайних случаях публикация с низким качеством, но вызывающая непреодолимое желание ответить с сарказмом, может получить больший рейтинг, чем качественная, но не вызывающая никакой реакции публикация. Возможно, именно так устроен базовый принцип работы этой системы.
Однако в новой версии открытого исходного кода алгоритма не раскрываются конкретные числовые значения весов поведения, но они были раскрыты в версии 2023 года.
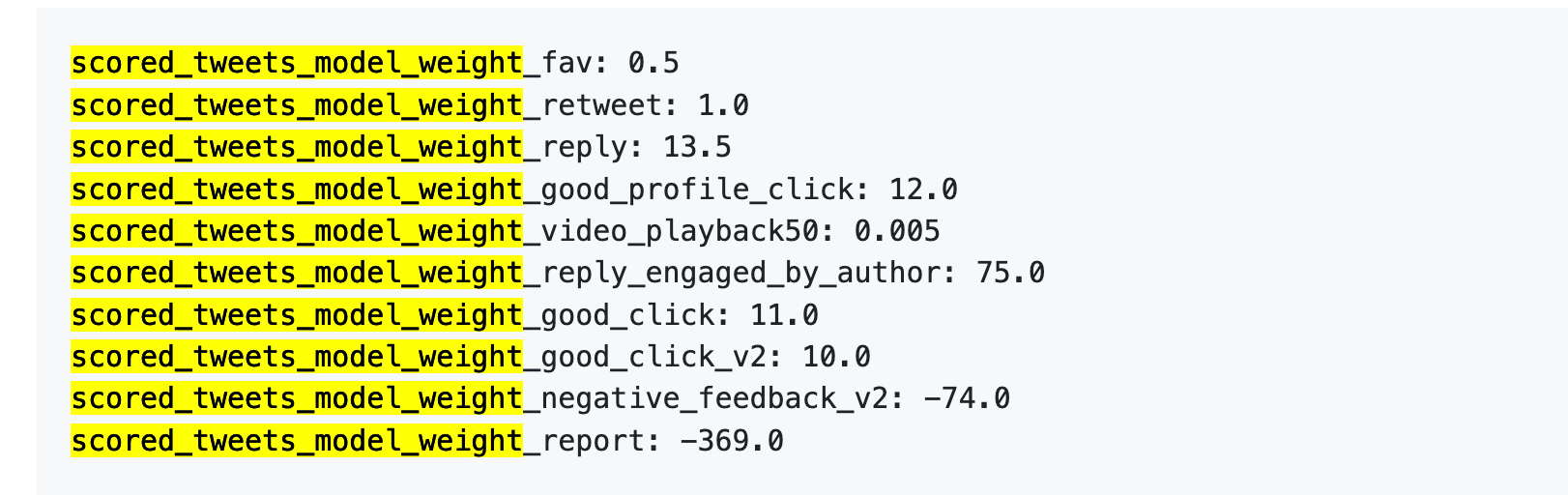
Старая ссылка: один жалоба = 738 лайков
Теперь мы можем рассмотреть данные за 2023 год, они, конечно, устаревшие, но помогут понять, насколько различается «ценность» различных действий в глазах алгоритма.
5 апреля 2023 года, X действительно публично разместила набор весовых данных на GitHub.
Прямо к цифрам:
Переведите как можно прямее:
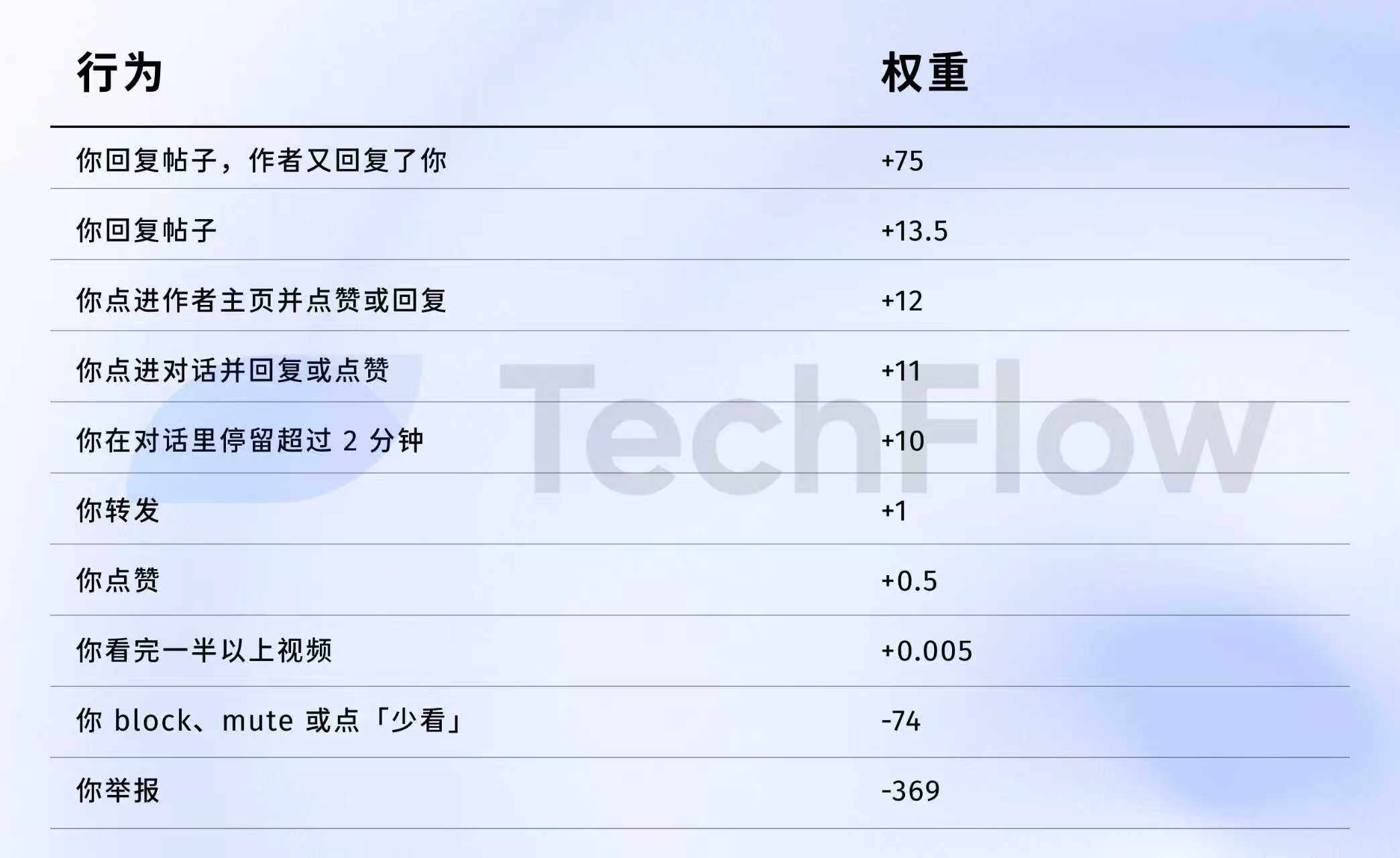
Источник данных: старая версия Репозиторий GitHub twitter/the-algorithm-ml, нажмите, чтобы посмотреть исходный алгоритм
Несколько цифр заслуживают пристального внимания.
Первое, лайки почти ничего не стоят. Вес составляет всего 0,5, что является самым низким среди всех положительных действий. С точки зрения алгоритма, ценность одного лайка примерно равна нулю.
Во-вторых, именно диалог и взаимодействие являются главным. Вес ответа «Вы ответили, автор ответил вам» равен 75, что в 150 раз больше, чем лайк. Алгоритм больше всего хочет видеть не односторонние лайки, а двусторонний диалог.
Третий, негативная обратная связь обходится очень дорого. Один блок или игнорирование (-74) может быть компенсировано 148 лайками. Одно сообщение (-369) требует 738 лайков. Более того, эти отрицательные баллы накапливаются в вашем рейтинге аккаунта и влияют на распространение всех последующих публикаций.
Четвертое, вес завершения просмотра видео слишком низкий. Только 0,005, почти можно игнорировать. Это резко контрастирует с Дуолин и TikTok, где эти две платформы рассматривают коэффициент просмотра как ключевой показатель.
В том же официальном документе также говорится: «Точные веса в файле можно изменять в любое время... С тех пор мы периодически регулировали веса для оптимизации метрик платформы».
Веса могут меняться в любое время, и они действительно менялись.
Новый вариант не раскрывает конкретные значения, но в README описан один и тот же логический фреймворк: добавление положительных баллов, вычитание отрицательных, взвешенная сумма.
Конкретные цифры могут измениться, но соотношение порядков, скорее всего, останется. Ответ на комментарий другого человека полезнее, чем получение 100 лайков. Вызывать желание заблокировать вас хуже, чем отсутствие взаимодействия.
Зная об этом, что мы, авторы, можем сделать
Изучив старый и новый алгоритмы Твиттера, я выделил несколько практических выводов.
1. Ответьте комментатору. В таблице весов «Ответ автора комментатору» имеет самый высокий балл (+75), что в 150 раз больше, чем одностороннее «лайк» от пользователя. Не нужно просить о комментариях, а если комментарий всё-таки появился, ответьте на него. Даже если вы ответите просто «Спасибо», алгоритм всё равно учтёт это.
2. Не позволяйте, чтобы вас обманули. Негативный эффект от одного блокирования может компенсироваться 148 лайками. Спорные материалы действительно легко вызывают взаимодействие, но если это взаимодействие выглядит как "Этот человек мне надоел, заблокирую", то репутационный рейтинг вашего аккаунта будет постоянно снижаться, что повлияет на распространение всех последующих публикаций. Спорный трафик - это двойной клинок, прежде чем рубить других, подумайте о себе.
3. Внешние ссылки — в раздел с комментариями.Алгоритм не хочет, чтобы пользователей перенаправляли за пределы сайта. Текст с ссылками будет учитываться хужеЭто Musk сам публично говорил. Если хочешь привлечь трафик, пиши содержание в основной текст, а ссылку кидали в первый комментарий.
4. Не флудите. В новой версии кода появился Author Diversity Scorer, который снижает вес постов от одного и того же автора, идущих подряд. Его задача — сделать поток пользователя более разнообразным, а побочный эффект — в десять раз лучше опубликовать один качественный пост, чем десять подряд.
6. Больше нет «лучшего времени для публикации». В старом алгоритме был встроен ручной признак «время публикации», но в новой версии его просто убрали. Phoenix учитывает только последовательность действий пользователя, а не время публикации записей. Стратегии вроде «лучше всего публиковать по вторникам в три часа дня» становятся всё менее значимыми.
Все вышеизложенное можно определить на уровне кода.
Некоторые дополнительные и штрафные правила взяты из открытой документации X, но не входят в репозиторий с открытым исходным кодом: сертификат Blue Tick даёт бонус, полные заглавные буквы снижают приоритет, чувствительное содержание вызывает сокращение доставки на 80%. Эти правила не были открыты, поэтому мы не будем их раскрывать подробно.
В общем итоге, этот раз открытый исходный код довольно солиден.
Полная архитектура системы, логика отбора кандидатов, процесс ранжирования и оценки, реализация различных фильтров. Код написан в основном на Rust и Python, структура понятна, README написан более подробно, чем в большинстве коммерческих проектов.
Но несколько ключевых вещей не были выпущены.
1. Весовые параметры не были опубликованы. В коде написано только, что «за позитивное поведение начисляются баллы, за негативное — списываются», но конкретно, сколько баллов добавляется за лайк, и сколько списывается за блокировку, не сказано. В версии 2023 года, по крайней мере, цифры были указаны, а в этот раз приведён только формульный шаблон.
2. Веса модели не были опубликованы. Phoenix использует Grok transformer, но сами параметры модели не раскрываются. Вы можете увидеть, как вызывается модель, но не можете увидеть, как именно производятся вычисления внутри модели.
3. Обучающие данные не были опубликованы. Ни слова не сказано о том, на каких данных обучалась модель, как производился отбор образцов поведения пользователей, как формировались положительные и отрицательные образцы.
В качестве примера, этот раз открытый исходный код эквивалентен тому, что вы говорите: «Мы используем взвешенное суммирование для расчета общей оценки», но не говорите, какие веса используются; вы говорите: «Мы используем трансформер для прогнозирования вероятности поведения», но не говорите, как выглядит трансформер внутри.
Сравнивая в плане горизонтальной прозрачности, у TikTok и Instagram даже этого нет. На этот раз X действительно раскрыла больше информации, чем другие основные платформы. Однако до «полной прозрачности» еще далеко.
Это не значит, что открытые исходные коды не имеют ценности. Для авторов и исследователей всегда лучше видеть исходный код, чем не видеть его.