









Автор:Тина, Дунмэй, InfoQ
1. Прошло почти три года, Маск снова открыл исходный код алгоритма рекомендаций X
Всего что, инженерная команда X опубликовала сообщение в X, объявив о том, что официально открыла исходный код алгоритма рекомендаций X. Согласно описанию, эта библиотека с открытым исходным кодом включает в себя ядро системы рекомендаций, поддерживающей информационный поток «Рекомендации для вас» в X. Она объединяет контент внутри сети (от аккаунтов, на которых подписан пользователь) и контент вне сети (обнаруженный через поиск, основанный на машинном обучении), а также использует модель Transformer на основе Grok для ранжирования всех контентов. То есть, этот алгоритм использует ту же архитектуру Transformer, что и Grok.
Репозиторий с открытым исходным кодом: https://x.com/XEng/status/2013471689087086804
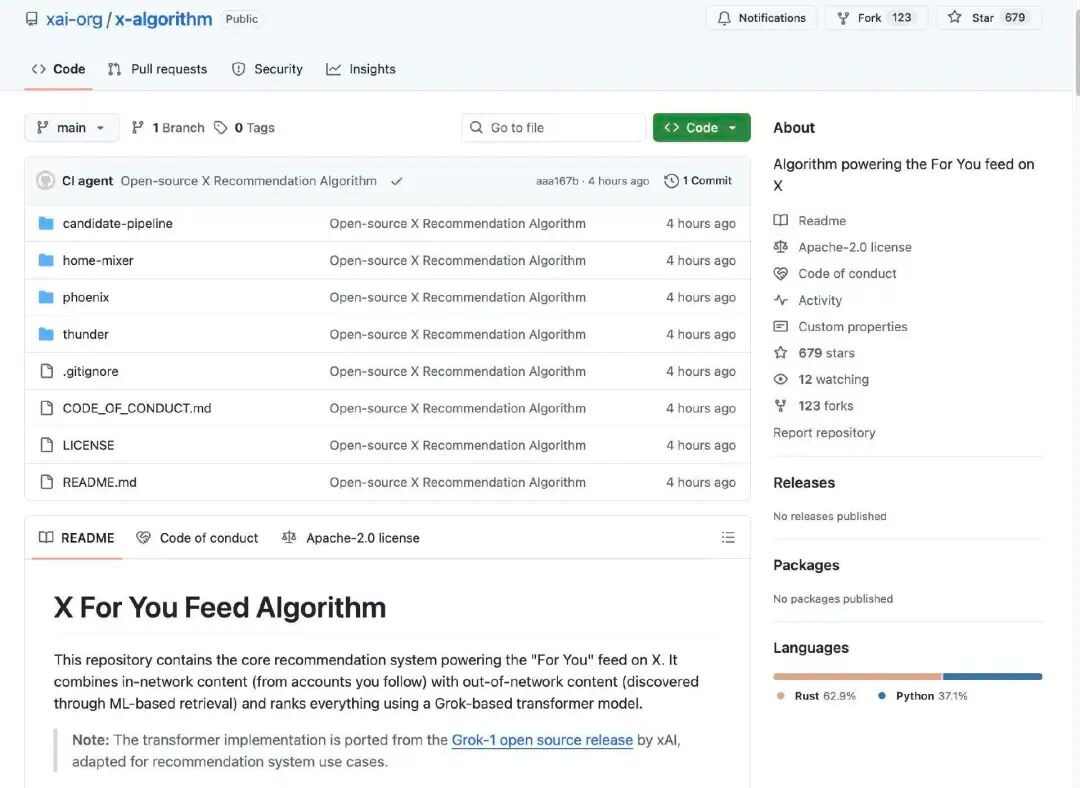
Рекомендательный алгоритм X отвечает за то, что пользователь видит на главном экранеРекомендации для вас (лента "For You")Он получает кандидатов на публикацию из двух основных источников:
Аккаунт, на который вы подписаны (In-Network / Thunder)
Другие сообщения, найденные на платформе (Out-of-Network / Phoenix)
Эти кандидаты на выбор обрабатываются, фильтруются и сортируются по релевантности.
Тогда, каковы ядро архитектуры алгоритма и его логика выполнения?
Алгоритм сначала извлекает кандидатов из двух источников:
Содержимое раздела «Внимание»: публикации, размещенные аккаунтами, которых вы сами подписались.
Неследуемое содержимое: сообщения, которые, возможно, вас заинтересуют, и которые система нашла в своём хранилище контента.
Цель этого этапа — «найти сообщения, которые могут быть связаны».
Система автоматически удаляет низкокачественный, дублирующийся, нарушительный или неподходящий контент. Например:
Содержимое заблокированного аккаунта
Темы, в которых пользователь явно не заинтересован
Незаконное, устаревшее или недействительное сообщение
Это гарантирует, что при окончательной сортировке будет обрабатываться только ценный контент.
Ядром алгоритма, открытого исходным кодом, является использование системой модели Transformer на основе Grok (аналога крупной языковой модели / глубокой нейронной сети) для выставления оценки каждому кандидату в посты. Модель Transformer предсказывает вероятность каждого действия на основе истории действий пользователя (лайки, ответы, репосты, нажатия и т.д.). В конце концов, вероятности этих действий комбинируются с весами в общий балл, и посты с более высоким баллом, скорее всего, будут рекомендованы пользователю.
Это проектирование фактически отказалось от традиционного ручного извлечения характеристик, вместо этого используя методы конечного обучения для прогнозирования интересов пользователей.
Это не первый раз, когда Маск делает алгоритм рекомендаций X открытой.
31 марта 2023 года, как и обещал Маск, когда он купил Twitter, он официально опубликовал часть исходного кода Twitter, включая алгоритм рекомендации твитов в ленте новостей пользователей.В день открытой лицензии проект получил более 10 000 звезд на GitHub.
В то время Маск заявил в Твиттере, что релиз будет следующим«Большинство рекомендательных алгоритмов»Остальные алгоритмы вскоре также будут раскрыты. Он также отметил, что надеется, что «независимые третьи стороны смогут с достаточной точностью определить, какие контент Twitter может показать пользователям».
В обсуждении в Space о публикации алгоритма он заявил, что этот план открытого исходного кода направлен на то, чтобы сделать Twitter «самой прозрачной системой в интернете», и сделать его таким же надежным, как самый известный и успешный проект с открытым исходным кодом Linux. «Общая цель — обеспечить максимальное удобство для пользователей, которые продолжают поддерживать Twitter».
С момента первого открытого исходного кода алгоритма X Маском прошло более трех лет. А как супер-блогер в технической сфере, Маск давно сделал для этого открытого исходного кода достаточную рекламу.
11 января Маск написал в X, что через 7 дней он опубликует новый алгоритм X (включая весь код, определяющий, какие естественные результаты поиска и рекламные материалы будут рекомендованы пользователям).
Этот процесс будет повторяться каждые 4 недели с подробными пояснениями для разработчиков, чтобы помочь пользователям понять, какие изменения были внесены.
Сегодня его обещание снова сбылось.
2. Почему Маск хочет сделать это открытым исходным кодом?
Когда Илон Маск снова упоминает «открытый исходный код», первая реакция со стороны не технический идеализм, а реальное давление.
В течение последнего года X неоднократно становился предметом дискуссий из-за своего механизма распространения контента. Платформа подверглась широкой критике за предвзятость алгоритмов в пользу правых взглядов и их поощрение, и эта тенденция не является случайной, а считается системной. В исследовательском отчете, опубликованном в прошлом году, было отмечено, что система рекомендаций X демонстрирует явные новые предубеждения при распространении политического контента.
В это же время некоторые крайние случаи еще больше усилили внешние сомнения. В прошлом году неотредактированное видео, связанное с убийством американского правого активиста Чарли Керка, быстро распространилось на платформе X, вызвав общественный резонанс. Критики считают, что это не только обнажило неспособность платформы выполнять проверку, но и снова подчеркнуло, как алгоритм определяет, что усиливать, а что нет. Скрытая власть.
На фоне этого заявление Маска о прозрачности алгоритмов трудно однозначно интерпретировать как исключительно техническое решение.

3. Как к этому относятся интернет-пользователи?
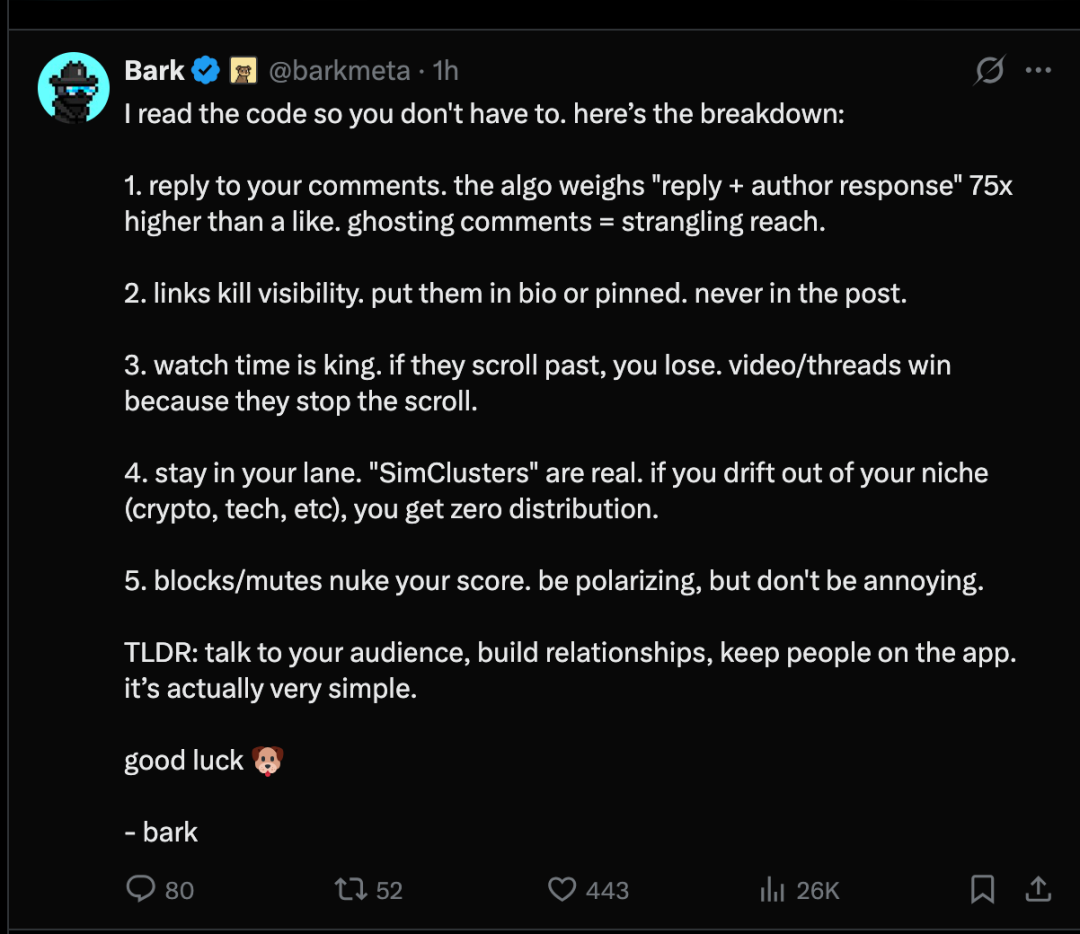
После того как алгоритм рекомендаций X стал открытым, пользователи на платформе X сделали следующие пять выводов о механизме алгоритма рекомендаций:
- Ответить на ваш комментарийАлгоритм придаёт весу «ответ + ответ автора» в 75 раз больше, чем лайкам. Не отвечать на комментарии будет серьёзно влиять на охват.
- Ссылка снизит уровень охватаСсылки нужно размещать в личном профиле или в закреплённой теме, НИ В КОЕМ СЛУЧАЕ не в самом сообщении.
- Продолжительность просмотра имеет первостепенное значениеЕсли они пролистают видео, то вы не привлечете их внимание. Видео/посты получают высокий уровень внимания, потому что заставляют пользователей остановиться.
- Соблюдайте свою сферу«Имитация кластера» существует на самом деле. Если вы выйдете за рамки своей ниши (криптовалюты, технологии и т.д.), вы не получите никаких каналов дистрибуции.
- Игнорирование / молчание сильно снизит ваш рейтингБудьте спорным, но не надоедливым.
Вкратце: взаимодействуйте со своей аудиторией, стройте отношения и удерживайте пользователей в приложении. На самом деле, это просто.
Некоторые пользователи сети также заметили, что, хотя архитектура является открытой, некоторые компоненты всё ещё не открыты. Пользователь отметил, что данная публикация по сути является фреймворком, но не движком. А что именно отсутствует?
Отсутствует параметр веса - Код подтверждает начисление баллов за «положительные действия» и списание баллов за «негативные действия», но в отличие от версии 2023 года, конкретные значения были удалены.
Скрыть веса модели - Не включает внутренние параметры и вычисления модели.
Непубличные данные для обучения - Ничего не известно о данных, использованных для обучения модели, способе отбора образцов поведения пользователей, а также о том, как были построены «хорошие» и «плохие» образцы.
Для обычных пользователей X открытость алгоритмов X не окажет существенного влияния. Однако более высокая степень прозрачности объяснит, почему одни публикации получают внимание, а другие остаются незамеченными, и позволит исследователям изучать, как платформа ранжирует контент.
4. Почему рекомендательные системы являются полем битвы?
В большинстве технических дискуссиях,Система рекомендацийЧасто воспринимается как часть инженерии, скрытой сзади, скромная и сложная, но редко находящаяся в центре внимания. Но если действительно разобрать коммерческую модель крупных интернет-гигантов, то можно обнаружить, что система рекомендаций не является периферийным модулем, а представляет собой «инфраструктурное существование», поддерживающее всю коммерческую модель. Именно поэтому её можно назвать «тихим гигантом» интернет-индустрии.
Публичные данные многократно подтверждают это. Amazon раскрыла, что около 35% покупок на ее платформе напрямую происходят благодаря системе рекомендаций. Netflix еще более радикален: около 80% времени просмотра определяется алгоритмами рекомендаций. У YouTube ситуация аналогична: около 70% просмотров приходится на рекомендательную систему, особенно на ленту (feed). Что касается Meta, то хотя компания никогда не приводила точные цифры, ее инженерная команда упоминала, что около 80% вычислительных ресурсов внутренних кластеров компании используются для задач рекомендаций.
Что означают эти цифры?Если удалить систему рекомендаций из этих продуктов, это будет почти то же самое, что вытащить фундамент.Возьмем, к примеру, Meta. Показ рекламы, время, которое пользователь проводит в приложении, коммерческое превращение — почти все строится на рекомендательной системе. Рекомендательная система определяет не только то, что пользователь «увидит», но и напрямую влияет на то, «как платформа зарабатывает деньги».
Однако именно такая система, решающая вопрос жизни и смерти, долгое время сталкивалась с проблемой чрезвычайно высокой инженерной сложности.
В традиционной архитектуре рекомендательных систем сложно охватить все сценарии с помощью одного унифицированного модели. В реальных промышленных системах всё очень фрагментировано. Например, в компаниях вроде Meta, LinkedIn и Netflix за полноценной цепочкой рекомендаций обычно одновременно работают 30 и более специализированных моделей: модели вызова, модели грубой сортировки, модели точной сортировки, модели повторной сортировки, каждая из которых оптимизируется под различные целевые функции и бизнес-метрики. За каждой моделью, как правило, стоит один или даже несколько команд, отвечающих за инженерию признаков, обучение, настройку гиперпараметров, внедрение и постоянное обновление.
Стоимость такой схемы очевидна: сложная инженерия, высокие затраты на обслуживание, сложности при координации задач. Как только кто-то предложит идею «Можно ли использовать одну модель для решения нескольких задач рекомендаций», это означает снижение сложности на порядок для всей системы. Именно этой цели давно стремится, но не может достичь индустрия.
Появление крупных языковых моделей предоставило рекомендательным системам новое возможное направление.
LLM уже доказали на практике, что могут стать чрезвычайно мощными универсальными моделями: они обладают высокой способностью к переносу между различными задачами, а их производительность продолжает улучшаться при увеличении масштаба данных и вычислительных мощностей. В то же время традиционные рекомендательные модели часто являются «задачно-ориентированными», и их сложно использовать для совместного применения в нескольких сценариях.
Важно также то, что использование одного крупного модели не только упрощает инженерную реализацию, но и открывает потенциал для «перекрестного обучения». Когда одна и та же модель одновременно решает несколько задач рекомендаций, сигналы, поступающие от разных задач, могут взаимно дополнять друг друга, а по мере роста объема данных модель легче эволюционирует в целом. Это как раз то свойство, которое системы рекомендаций давно стремились достичь, но которое оказалось труднодостижимым с помощью традиционных методов.
Что изменили LLM? Они изменили переход от инженерии признаков к способности к пониманию.
С точки зрения методологии, наибольшее влияние, которое LLM оказывает на системы рекомендаций, проявляется на этапе «инженерии признаков», являющемся ключевым звеном.
В традиционных системах рекомендаций инженеры сначала вручную создают множество сигналов: историю кликов пользователя, продолжительность остановки, предпочтения похожих пользователей, метки контента и т.д., а затем явно сообщают модели: «Пожалуйста, делайте выводы на основе этих характеристик». Сама модель не понимает семантику этих сигналов, а просто учится отображать отношения в числовом пространстве.
После внедрения языковой модели этот процесс был сильно абстрагирован. Вам больше не нужно указывать поочередно: «Обратите внимание на этот сигнал, игнорируйте тот сигнал», вместо этого вы можете просто описать саму проблему модели: это пользователь, это контент; этот пользователь раньше нравился похожий контент, другие пользователи также дали положительную реакцию на этот контент — теперь, пожалуйста, определите, должен ли этот контент быть рекомендован этому пользователю.
Сама по себе языковая модель уже обладает способностью понимания, она может сама определять, какие данные являются важными сигналами, и каким образом следует объединять эти сигналы для принятия решений. В некотором смысле, модель не просто выполняет рекомендательные правила, а «понимает рекомендацию».
Происхождение этой способности заключается в том, что LLM во время этапа обучения сталкивались с огромным количеством разнообразных данных, что делает их более способными к выявлению тонких, но важных паттернов. В сравнении с традиционными системами рекомендаций, которые должны полагаться на явное перечисление этих паттернов инженерами, модель не может их воспринимать, если они пропущены.
С точки зрения бэкенда, такие изменения не кажутся чем-то необычным. Как вы задаёте вопрос GPT, и он генерирует ответ на основе контекста, так же, как вы можете спросить его: «Меня заинтересует ли эта информация?» — и он также может сделать вывод на основе имеющихся данных. В некотором смысле, языковая модель сама по себе уже обладает врождённой способностью «рекомендовать».