









К сожалению, в эту эпоху чем более искренне и серьезно вы работаете, тем быстрее превращаете себя в навык, который может быть заменен ИИ.
В последние два дня тенденции и медиа-каналы были заполнены упоминаниями «коллеги.skill». Когда этот инцидент продолжал развиваться на всех социальных платформах, общественное внимание почти неизбежно было захвачено крупными тревогами, связанными с «увольнениями с помощью ИИ», «эксплуатацией капиталом» и «цифровой бессмертностью работников».
Это действительно вызывает тревогу, но то, что вызывает у меня наибольшую тревогу, — это рекомендация по использованию, указанная в файле README проекта:
Качество сырья определяет качество skill: рекомендуется в первую очередь собирать его длинные статьи, написанные самостоятельно > ответы, связанные с принятием решений > повседневные сообщения.
Наиболее идеально отфильтровываемые системой и точно воспроизводимые в пикселях — это именно те, кто работает наиболее серьезно.
Это те, кто после завершения каждого проекта остается за столом и пишет отчеты об анализе; те, кто при возникновении разногласий готов потратить полчаса, чтобы набрать в чате длинное сообщение и честно проанализировать свою логику принятия решений; те, кто проявляет крайнюю ответственность и безупречно поручает все детали работы системе.
Серьезность, когда-то самая ценимая добродетель на рабочем месте, теперь стала катализатором, ускоряющим превращение работников в топливо для ИИ.
Использованные работники
Нам нужно заново понять слово: контекст.
В повседневном контексте контекст — это фон общения. Но в мире ИИ, особенно среди стремительно развивающихся ИИ-агентов, контекст — это топливо, питающее двигатель, кровь, поддерживающая пульс, и единственный якорь, позволяющий модели делать точные суждения в хаосе.
Искусственный интеллект, лишенный контекста, даже при огромном количестве параметров, — всего лишь поисковая система с амнезией. Он не узнает вас, не чувствует скрытые течения под бизнес-логикой и не может понять, какие долгие колебания и компромиссы вы пережили на сети, сплетенной из ограничений ресурсов и человеческих игр, прежде чем принять решение.
То, что «коллега.skill» вызвало столь огромную волну, объясняется тем, что он чрезвычайно холодно и точно захватил горную породу, в которой накоплено огромное количество высококачественного контекста — программное обеспечение для корпоративного сотрудничества.
За последние пять лет китайские рабочие места пережили тихую, но глубокую цифровую трансформацию. Инструменты, такие как Feishu, DingTalk и Notion, превратились в огромные корпоративные базы знаний.
На примере Feishu, ByteDance ранее публично заявляла, что ежедневно в компании генерируется огромное количество документов, и эти плотно заполненные символы точно сохраняют каждый интеллектуальный порыв, каждую оживлённую дискуссию на совещаниях и каждую тяжёлую стратегическую уступку более чем ста тысяч сотрудников.
Эта цифровая проникающая сила превосходит любую предыдущую эпоху. Когда-то знания были живыми — они скрывались в головах опытных сотрудников, рассеивались в случайных разговорах в комнате для перерывов; теперь вся человеческая мудрость и опыт насильно высушены и безжалостно оседают на холодных серверных матрицах в облаке.
В этой системе, если вы не пишете документы, ваша работа остается невидимой, и новые коллеги не могут с вами сотрудничать. Эффективная работа современных предприятий основана на ежедневном цикле «взноса» контекста каждым сотрудником в систему.
Серьезные работники с трудолюбием и добросердечием на этих холодных платформах без остатка раскрывают свои мысли. Они делают это, чтобы шестеренки команды работали более слаженно, чтобы доказать свою ценность системе и найти свое место внутри этой сложной коммерческой чудовищной машины. Они не отдают себя добровольно — они просто неуклюже и усердно следуют законам выживания в современном рабочем мире.
Но именно этот контекст, оставленный для человеческого взаимодействия, становится идеальным топливом для ИИ.
В административной панели Feishu есть функция, позволяющая суперадминистратору массово экспортировать документы и переписку членов. Это означает, что всё, что вы написали за три года, просидев бесчисленные бессонные ночи — анализ проектов и логи принятия решений — можно одним API-запросом за несколько минут упаковать в безжизненный архив.
Когда человека уменьшают до API
С ростом популярности «коллеги.skill» в разделе Issues GitHub и на различных социальных платформах начали появляться крайне неприемлемые производные продукты.
Кто-то создал «навык бывшего», чтобы накормить ИИ историей чатов в WeChat за последние годы, заставив его продолжать спорить или ласкаться с ним привычным тоном; кто-то создал «навык белого лунного света», превратив недоступное трепетание в холодную человеческую симуляцию, многократно отрабатывая тактику осторожных слов и шаг за шагом стремясь к оптимальному эмоциональному решению; кто-то создал «навык начальника с отцовской манерой», заранее пережевывая в цифровом пространстве那些 наполненные давлением слова ПУА, чтобы построить себе печальную психологическую защиту.
Сферы применения этих навыков полностью вышли за рамки повышения производительности труда. Оказывается, мы незаметно для себя уже отлично освоили холодную логику обращения с инструментами, чтобы разрушать и обезличивать живых, полноценных людей.
Немецкий философ Мартин Бубер утверждал, что основа человеческих отношений сводится к двум совершенно различным моделям: «Я и Ты» и «Я и Оно».
В встрече «я и ты» мы преодолеваем предвзятость, воспринимая друг друга как целостные и достойные существа. Эта связь открыта без остатка, полна живой, непредсказуемой энергии, и именно благодаря своей искренности она особенно хрупка; однако, как только мы попадаем в тень «я и оно», живого человека снижают до уровня объекта, который можно разобрать, проанализировать и классифицировать с помощью ярлыков. В этом крайнем утилитарном взгляде нас интересует только одно: «Какую пользу этот объект приносит мне?»
Появление продуктов, таких как «бывший.skill», означает, что инструментальная рациональность «я и оно» полностью вторглась в самую интимную эмоциональную сферу.
В настоящих отношениях люди многогранны, полны складок и постоянно меняются в ответ на противоречия и шероховатости; их реакции постоянно изменяются в зависимости от конкретной ситуации и эмоционального взаимодействия. Ваш бывший может по-разному отреагировать на одну и ту же фразу, проснувшись утром, и после ночной смены работы.
Но когда вы перерабатываете человека в навык, вы отбрасываете лишь ту функциональную оболочку, которая в определённых отношениях оказалась для вас «полезной» и «эффективной». Тот, кто когда-то был живым, с собственными радостями и печалями, в этой жестокой очистке полностью лишается души и превращается в «интерфейс функции», который вы можете подключать и отключать по своему усмотрению.
Нужно признать, что ИИ не придумал эту пугающую холодность. Еще до появления ИИ мы давно привыкли навешивать ярлыки на других и точно взвешивать «эмоциональную ценность» и «сетевую значимость» каждого отношения. Например, на свиданиях мы превращаем характеристики людей в таблицы; на работе мы классифицируем коллег как «тех, кто работает», и «тех, кто ленится». ИИ лишь сделал эту скрытую, межличностную функциональность полностью явной.
Человек был сплющен, остался только срез «а как это мне поможет».
Электронная патина
В 1958 году венгеро-британский философ Майкл Полани опубликовал книгу «Личностное знание». В ней он ввел проницательное понятие — скрытое знание.
Поланий сказал известное утверждение: «Мы знаем больше, чем можем выразить».
Он привёл пример обучения езде на велосипеде. Опытный велосипедист, скользящий по ветру, идеально сохраняет равновесие при каждом наклоне под действием силы тяжести, но не может точно описать ту тонкую интуицию тела, которую он ощущает в тот момент, с помощью сухих физических формул или бледных слов. Он знает, как ездить, но не может это объяснить. Такое знание, которое невозможно закодировать или выразить словами, называется скрытым знанием.
В рабочей среде полно такой скрытой информации. Опытный инженер, анализируя сбой в системе, может сразу определить проблему по логам, но ему сложно описать в документации эту «интуицию», выработанную на тысячах проб и ошибок; отличный продавец в ходе переговоров внезапно замолкает — это молчание, создающее давление и идеально подобранный момент, невозможно зафиксировать ни в одном руководстве по продажам; опытный HR-специалист во время собеседования, заметив лишь полсекунды, когда кандидат избегает зрительного контакта, может почувствовать несоответствия в резюме.
«Коллега.skill» может извлекать только явные знания, которые уже были записаны или сказаны. Он может извлечь ваши аналитические документы, но не может захватить ваши колебания во время их написания; он может скопировать ваши ответы по принятию решений, но не может воспроизвести интуицию, стоявшую за этими решениями.
Система выделяет только тень человека.
Если бы история закончилась здесь, это было бы просто еще одним неудачным подражанием технологии человеческой природе.
Но когда человек превращается в навык, этот навык не остается статичным. Он используется для ответа на письма, написания новых документов и принятия новых решений. То есть эти тени, созданные ИИ, начинают порождать новые контексты.
А эти контексты, сгенерированные ИИ, будут сохранены в Feishu и DingTalk и станут обучающими материалами для следующего цикла дистилляции.
Еще в 2023 году исследовательские команды Оксфордского и Кембриджского университетов совместно опубликовали статью о «крахе модели». Исследование показало, что при итеративном обучении ИИ-моделей на данных, сгенерированных другими ИИ, распределение данных становится все уже и уже. Редкие, маргинальные, но чрезвычайно реальные человеческие черты быстро стираются. Лишь после нескольких поколений синтетических данных модель полностью забывает о длинных хвостах сложных реальных человеческих данных и начинает генерировать исключительно посредственные и однородные результаты.
В 2024 году журнал «Nature» также опубликовал исследовательскую статью, указывающую, что обучение будущих поколений моделей машинного обучения на наборах данных, сгенерированных с помощью ИИ, серьезно загрязнит их выводы.
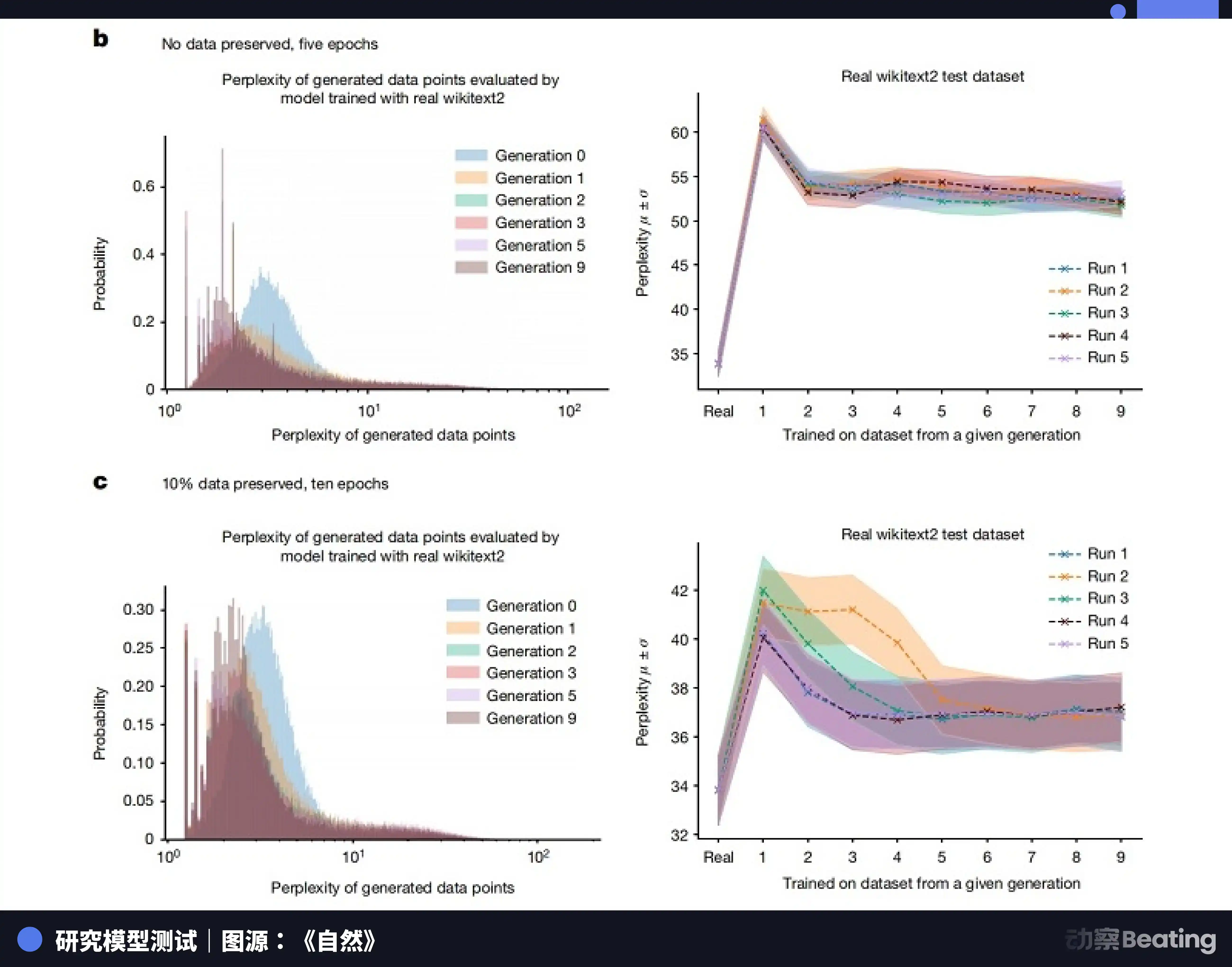
Это как те мемы, которые распространяются в интернете: изначально это был чёткий скриншот, который бесчисленное количество раз пересылали, сжимали и снова пересылали. Каждый раз при передаче терялась часть пикселей и добавлялся шум. В итоге изображение становилось размытым и покрывалось электронной патиной.
Когда истинный человеческий контекст, содержащий скрытые знания, исчерпан, и система может обучаться только на затертых тенях, что останется в конце?
Кто стирает наши следы
Остается только правильная пустая болтовня.
Когда река знаний иссякает в бесконечном жевании и пережевывании ИИ самим собой, всё, что система выдыхает и вдыхает, станет чрезвычайно стандартным, чрезвычайно безопасным, но безнадёжно пустым. Вы увидите бесчисленное количество идеально структурированных еженедельных отчётов, бесчисленное количество безупречных писем, но в них не будет ни единого дыхания живого человека, ни единого по-настоящему ценного прозрения.
Это крупное поражение знаний произошло не потому, что человеческий мозг стал глупее; настоящая трагедия в том, что мы передали право мыслить и ответственность за сохранение контекста нашему собственному отражению.
Несколько дней спустя после всплеска популярности «colleague.skill» на GitHub появился проект под названием «anti-distill».
Автор этого проекта не пытался атаковать крупные модели и не писал никаких грандиозных манифестов. Он просто предоставил небольшой инструмент, помогающий сотрудникам автоматически генерировать в Feishu или DingTalk длинные тексты, которые выглядят правдоподобно, но на самом деле полны логического шума.
Его цель проста: спрятать свои ключевые знания до того, как система их извлечет. Поскольку система любит извлекать «длинные тексты, написанные самостоятельно», давайте накормим ее кучей бессмысленного мусора.
Этот проект не стал таким же хитом, как «Colleague.skill», он даже кажется незначительным и беспомощным. Использовать магию против магии — это всё равно что крутиться в рамках правил игры, заданных капиталом и технологиями. Он не может изменить общую тенденцию к всё большей зависимости от ИИ и всё большему игнорированию реальных людей.
Но это не мешает этому проекту стать наиболее трагически поэтичной и глубоко аллегорической сценой всего этого абсурдного спектакля.
Мы прилагаем огромные усилия, чтобы оставить следы в системе, составлять подробную документацию, принимать продуманные решения, пытаясь доказать в этой огромной современной корпоративной машине, что мы когда-то существовали и были ценными. Но мы не знаем, что эти крайне серьезные следы в конечном итоге станут ластиком, стирающим нас.
Но, с другой стороны, это не обязательно полная тупиковая ситуация.
Потому что то, что стирает этот ластик, — это всегда лишь «прошлое тебя». Навык, упакованный в файл, независимо от того, насколько изощренна его логика извлечения, по сути, является лишь статичным снимком. Он зафиксирован на ту самую секунду экспорта и может лишь бесконечно вращаться в заданных процессах и логике, питаясь устаревшими данными. У него нет инстинкта столкновения с неизвестной хаотичностью и тем более способности к саморазвитию через реальные неудачи в реальном мире.
Когда мы отпускаем те высоко стандартизированные и устоявшиеся опыты, мы освобождаем свои руки. Пока мы продолжаем выходить за пределы, разрушать и перестраивать свои когнитивные границы, тень, застрявшая в облаках, всегда будет следовать за нашими спинами.
Человек — это потоковый алгоритм.