










Представьте эту ситуацию:
Вы попросили AI-агента исправить баг в коде. Он открыл проект, прочитал 20 файлов, внес изменения, запустил тесты — не прошли, снова изменил, снова запустил — всё ещё не прошли… После десятков попыток — всё ещё не исправил.
Вы выключили компьютер и облегченно вздохнули. Затем получили счет за API.
Приведённые цифры могут заставить вас вздрогнуть — автономное исправление ошибок AI-агентом через официальный API за рубежом часто требует расхода более миллиона токенов за одну нерешённую задачу, что может стоить от десятков до более чем ста долларов.
В апреле 2026 года совместно опубликованное исследование Стэнфордского, Массачусетского технологического и Мичиганского университетов впервые систематически раскрыло «черный ящик» расходов AI-агентов в кодовых задачах — куда именно тратятся деньги, оправданы ли эти расходы и можно ли их предсказать заранее. Ответы оказались шокирующими.
Открытие 1: Скорость расходов на написание кода агентом в 1000 раз выше, чем у обычного AI-диалога.
Возможно, вы думаете, что траты на то, чтобы заставить ИИ писать код для вас, и на то, чтобы ИИ обсуждал с вами код, должны быть примерно одинаковыми.
Приведенное в статье сравнение показывает:
Потребление токенов для агентных задач кодирования составляет примерно в 1000 раз больше, чем для обычных задач кодирования и логического анализа кода.
Разница составляет целых три порядка величины.
Почему так происходит? В статье отмечается факт: деньги тратятся не на написание кода, а на чтение кода.
Здесь «чтение» не означает, что человек читает код, а указывает на то, что агент в процессе работы должен постоянно «кормить» модель всем контекстом проекта, историей операций, сообщениями об ошибках и содержимым файлов. Каждый новый цикл диалога делает этот контекст длиннее на один цикл; а модель оплачивается по количеству токенов — чем больше вы подаете, тем больше платите.
Например, это как нанять слесаря, который перед каждым движением гаечного ключа требует, чтобы вы прочитали ему вслух все чертежи здания с самого начала — стоимость чтения чертежей намного выше, чем стоимость поворота винта.
Статья суммирует это явление одним предложением: затраты на агента обусловлены экспоненциальным ростом входящих токенов, а не выходящих.
Второе наблюдение: один и тот же баг, запущенный дважды, может стоить вдвое больше — причем чем дороже баг, тем нестабильнее он работает.
Еще более беспокоящим является случайность.
Исследователи запустили один и тот же агент на одной и той же задаче четыре раза и обнаружили:
- Между различными задачами самая дорогая задача сжигает примерно на 7 миллионов токенов больше, чем самая дешевая (Рисунок 2a)
- В нескольких запусках одной и той же модели на одной и той же задаче самая дорогая операция примерно в два раза дороже самой дешевой (Рисунок 2b)
- А если сравнивать один и тот же запрос между разными моделями, разница между максимальным и минимальным потреблением может достигать 30 раз.
Особое внимание стоит уделить последней цифре: это означает, что разница в стоимости между правильной и неправильной моделью — это не «немного дороже», а «на порядок дороже».
Еще более болезненно то, что большие расходы не означают лучшую работу.
Исследование обнаружило «обратную U-образную» кривую:
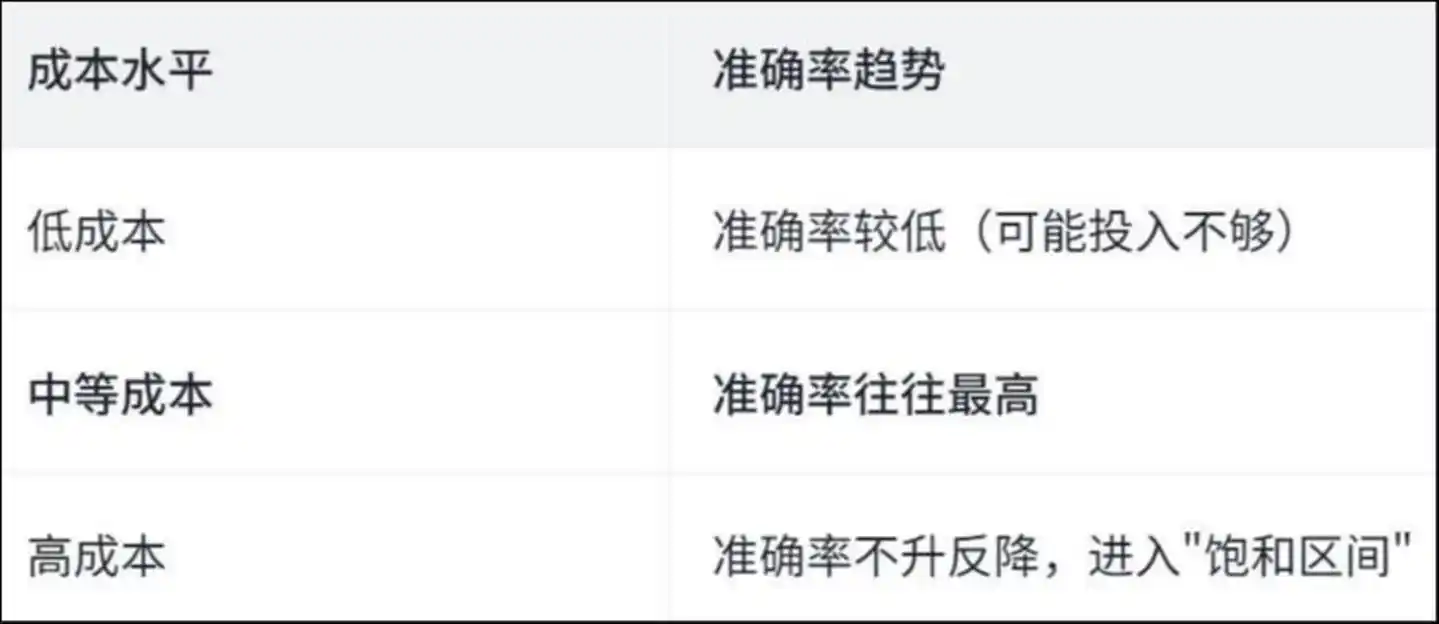
Уровень затрат Точность тренда Низкие затраты Низкая точность (возможно, недостаточно инвестиций) Средние затраты Часто максимальная точность Высокие затраты Точность не растет, а снижается, входя в «интервал насыщения»
Почему так происходит? Статья дает ответ, проанализировав конкретные действия агента —
В условиях высоких затрат агент тратит большое количество времени на «повторяющуюся работу».
Исследование показало, что при высоких затратах примерно 50% операций просмотра и изменения файлов являются дублирующими — то есть агент многократно читает один и тот же файл и многократно изменяет одну и ту же строку кода, как человек, бегающий по кругу в комнате, всё больше кружась и теряя ориентацию.
Деньги потрачены не на решение проблемы, а на то, чтобы заблудиться.
Открытие три: «энергоэффективность» между моделями сильно различается — GPT-5 наиболее экономичен, некоторые модели расходуют на 1,5 миллиона токенов больше
На стандарте SWE-bench Verified (500 реальных проблем GitHub), который является отраслевым стандартом, было протестировано представление 8 передовых крупных моделей в роли агентов. При пересчете в доллары, модели с высокой эффективностью токенов могут позволить себе на десятки долларов больше на каждую задачу. В корпоративном применении — при выполнении сотен задач в день — эта разница превращается в реальные деньги.
Еще один интересный вывод: эффективность токена — это «врожденная черта» модели, а не результат задачи.
Исследователи выделили задачи, которые все модели успешно решили (230 задач), и задачи, которые все модели не смогли решить (100 задач), и обнаружили, что относительный рейтинг моделей практически не изменился.
Это означает: некоторые модели по своей природе «болтливы» и это мало связано со сложностью задачи.
Еще один заставляющий задуматься вывод: модель не обладает «осознанием стоп-лосса».
При столкновении с трудными задачами, которые не могут быть решены ни одной моделью, идеальный агент должен как можно раньше отказаться, а не продолжать тратить деньги. Но на практике модели обычно расходуют больше токенов на неудачные задачи — они не «сдаются», а продолжают исследовать, повторять попытки и перечитывать контекст, как автомобиль без индикатора низкого уровня топлива, который едет до поломки.
Открытие 4: То, что людям кажется сложным, агенту не обязательно кажется дорогим — восприятие сложности полностью смещено
Вы можете подумать: хотя бы я могу оценить стоимость в зависимости от сложности задачи?
Для оценки сложности 500 задач были привлечены человеческие эксперты, после чего результаты были сопоставлены с фактическим потреблением токенов агентом—
Результат: между ними существует лишь слабая корреляция.
Простыми словами: задача, которая людям кажется невероятно сложной, агент может выполнить легко и недорого; а задача, которая людям кажется простой, агент может сделать так, что он начнёт сомневаться в себе.
Потому что сложность, которую видят люди и ИИ, совершенно разная:
- Человек смотрит на: сложность логики, сложность алгоритмов, порог понимания бизнеса
- Агент смотрит: насколько велик проект, сколько файлов нужно прочитать, насколько длинен путь исследования и будут ли повторно изменяться одни и те же файлы.
Та ошибка, которую человек-эксперт считает «достаточно исправить одну строку», агенту может потребоваться сначала разобраться со всей структурой кодовой базы, чтобы найти эту строку — одни только «чтение» потребует огромного количества токенов. А алгоритмическая задача, которую человек считает «логически запутанной», агенту может быть знакома как стандартное решение, и он быстро справится с ней.
Это приводит к неловкой реальности: разработчикам почти невозможно интуитивно оценить стоимость выполнения агента.
Открытие пять: даже модель не может точно рассчитать, сколько она будет стоить
Если человек не может точно предсказать, почему бы не дать это сделать ИИ самому?
Исследователи разработали тонкий эксперимент: заставили агента сначала «проверить» репозиторий кода, а затем оценить, сколько токенов ему потребуется — но не выполнять фактическое исправление.
Каков результат?
All models, completely wiped out.
Наилучший результат — корреляция предсказаний Claude Sonnet-4.5 по выходным токенам: 0,39 (максимум — 1,0). У большинства моделей корреляция предсказаний составляет всего от 0,05 до 0,34; у Gemini-3-Pro она самая низкая — всего 0,04 — что практически равно случайным догадкам.
Еще более странно: все модели систематически недооценивали потребление своих токенов. На диаграмме рассеяния на рисунке 11 почти все точки находятся ниже «линии идеального прогноза» — модели считали, что «не потратят столько», но на самом деле потратили больше. И эта недооценка становится еще более выраженной, когда примеры не предоставляются.
Более иронично то, что сами прогнозы тоже стоят денег.
Прогнозирование стоимости для Claude Sonnet-3.7 и Sonnet-4 превышает стоимость самой задачи более чем в два раза. То есть заставить их сначала «оценить цену» дороже, чем сразу приступить к работе.
Выводы статьи прямолинейны:
На текущем этапе передовые модели не могут точно предсказать свое потребление токенов. Нажатие кнопки «Запустить агента» похоже на открытие «слепого ящика» — вы узнаете, сколько потратили, только когда придет счет.
За этой «путаной бухгалтерией» скрывается более серьезная отраслевая проблема
Дочитав до этого момента, вы можете задаться вопросом: что это значит для бизнеса?
Модель ценообразования «подписка на месяц» начинает трескаться под давлением агентов
Статья указывает, что подписочные модели, такие как ChatGPT Plus, работают, потому что потребление токенов в обычных диалогах относительно контролируемо и предсказуемо. Однако задачи агентов полностью нарушают это предположение — одна задача может привести к огромным расходам токенов из-за зацикливания агента.
Это означает, что чистая подписочная модель ценообразования может быть неприемлемой для сценариев с Agent, и почасовая оплата (Pay-as-you-go) останется наиболее реалистичным вариантом в течение длительного времени. Однако проблема почасовой оплаты заключается в том, что объем использования сам по себе непредсказуем.
2. Эффективность токена должна стать «третьим критерием» при выборе модели
Традиционно компании оценивают модели по двум измерениям: способность (способны ли они это сделать) и скорость (насколько быстро они это делают). Эта статья предлагает третье равнозначно важное измерение: энергоэффективность (сколько ресурсов нужно затратить, чтобы это сделать).
Модель, которая немного слабее, но в три раза эффективнее, может иметь большую экономическую ценность в масштабируемых сценариях, чем «самая сильная, но самая дорогая» модель.
3. Агенту необходимы «уровень топлива» и «тормоз»
В статье упоминается перспективное направление будущего — политики использования инструментов с учетом бюджета. Проще говоря, это как установить для агента «указатель уровня топлива»: когда расход токенов приближается к лимиту, он должен быть принудительно остановлен, чтобы избежать бесполезных попыток и не тратить ресурсы до конца.
В настоящее время большинство основных фреймворков Agent не обладают таким механизмом.
Проблема «сжигания денег» агента — это не ошибка, а неизбежная боль отрасли
Этот документ раскрывает не недостаток какой-либо модели, а структурные вызовы всего парадигмы агентов — когда ИИ эволюционирует от «вопрос-ответ» к «автономному планированию, многошаговому выполнению и повторной отладке», непредсказуемость потребления токенов становится почти неизбежной.
Хорошей новостью является то, что впервые кто-то систематически выявил и проанализировал эту путаницу. С этими данными разработчики могут более осознанно выбирать модели, устанавливать бюджеты и проектировать механизмы стоп-лосса; производители моделей получили новое направление для оптимизации — не только делать модели более мощными, но и более экономичными.
В конце концов, прежде чем AI-агенты действительно войдут в производственные среды множества отраслей, разумное расходование каждого рубля важнее, чем красиво написанный код. (Эта статья впервые опубликована в приложении Titanium Media, автор | Silicon Valley Tech news, редактор | Чжао Хуньюй)
Примечание: Этот текст основан на препринте статьи, опубликованной 24 апреля 2026 года на arXiv: *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei). Авторы принадлежат к таким учреждениям, как Университет Вирджинии, Стэнфордский университет, MIT, Университет Мичигана. Исследование еще не прошло рецензирование.