










Автор: Max, который всегда в пути, 01Founder
Если бы нужно было составить промежуточный итог для OpenAI за 2025 год, многие, вероятно, описали бы его как скучный или даже несколько пассивный.
За последние более чем год они последовательно реализовали логическую цепочку, плотно выпустив модели для вывода от o3pro до o4mini, а также представив новые базовые модели, такие как GPT-4.5 и GPT-5.
Но в области визуального создания, где обычные пользователи наиболее ярко это ощущают и где最容易形成自发传播, их присутствие постепенно ослабевает.
После первоначального шока от появления Sora, OpenAI, похоже, вступила в длительный период молчания в этой области.
В это время другие игроки за столом тоже не сидели сложа руки.
В открытой экосистеме модели, такие как Flux, полностью сняли барьеры для создания высококачественных изображений локально;
На коммерческом фронте помимо старых конкурентов, удерживающих высокие эстетические барьеры, появились новые участники, такие как Nano-banana, обладающие встроенными функциями поиска в интернете.
Напротив, ранее основная модель генерации изображений OpenAI GPT-Image-1.5 уже выглядит устаревшей:
Качество изображения плохое, макет жесткий, и он часто сбоит при работе со сложным текстом.
Постепенно в отрасли сформировался консенсус:
OpenAI столкнулась с техническим барьером в области визуальной генерации и теперь испытывает трудности под давлением различных конкурентов.
До нескольких недель назад поворотный момент появился очень скрытным образом.
На известной платформе слепого тестирования крупных моделей LM Arena незаметно появилась таинственная图像-модель под кодовым именем Duct Tape.
Участники слепого тестирования быстро поняли, что что-то не так:
Эта модель не только чрезвычайно точно управляет экстремальными соотношениями сторон, но и безупречно генерирует макеты плакатов с большим количеством текста на разных языках, причем, похоже, перед созданием изображения происходит некий скрытый процесс логического планирования.
Все технические сообщества сразу начали гадать, какая компания тайно запустила этот ход, но представители OpenAI сохраняли молчание.
В эту ночь ботинок наконец-то упал.
Без долгих презентаций и масштабной маркетинговой подготовки OpenAI официально назвала модель с кодовым именем «Клейкая лента» ChatGPT GPT-Image-2 и полностью запустила её на рынке.
Также была опубликована таблица рейтинга текст-в-изображение, вызывающая ощущение удушья.
GPT-Image-2 с рекордным результатом 1512 сразу занял первое место, опередив второго места (Nano-banana-2 с функцией поиска в интернете) на целых 242 балла.
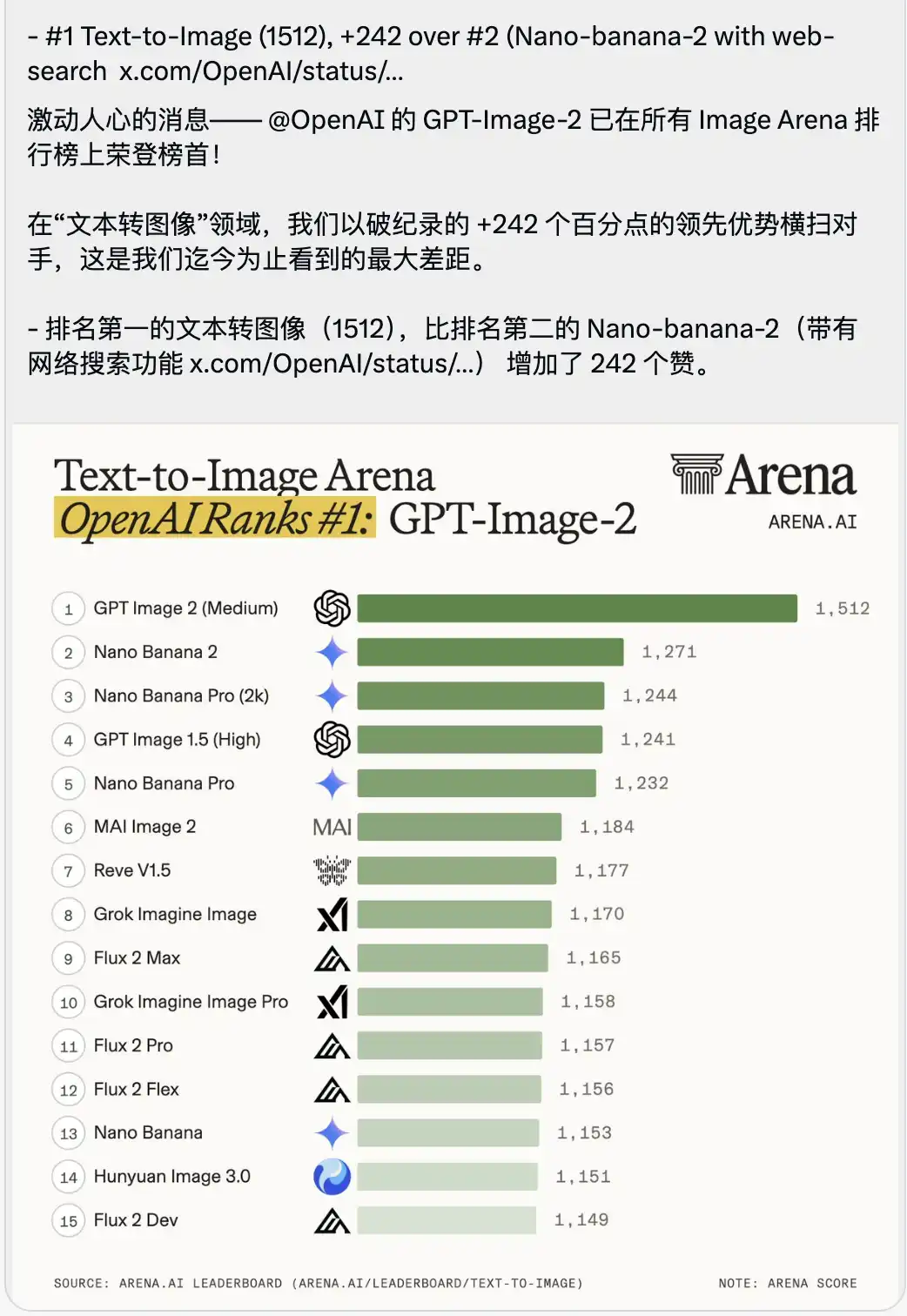
В контексте оценки больших моделей люди часто широко освещают превосходство на десятые или единицы, так как результаты ведущих моделей очень близки.
Разрыв в 242 очка — беспрецедентный в истории арены.
Это совсем не небольшая версия обновления, это грубое подавление поколения.
Я потратил большую часть дня, внимательно изучив все его предельные возможности и последнюю документацию API.
Единственное ощущение:
OpenAI остается той же OpenAI.
Когда он решил отвоевать потерянные позиции, он сделал это, полностью перевернув старый игровой стол.
Перед этой моделью работы по визуальному дизайну, которые мы считали, что еще потребуют двух-трех лет, прежде чем будут полностью заменены ИИ, сегодня, по сути, подошли к концу.
ЧАСТЬ 01. Генерация изображений от модели до визуального агента
Чтобы понять, почему GPT-Image-2 показывает такие огромные различия в результатах, нужно отказаться от устоявшихся представлений о моделях генерации изображений по тексту.
Раньше, когда мы использовали ИИ для рисования, это было похоже на покупку слепых коробок: вводили несколько ключевых слов и ждали, пока он соберет пиксели в нужное изображение.
Но GPT-Image-2 больше похож на агент с встроенным визуальным движком.
Самое очевидное изменение — это то, что в его механизме напрямую выделены две совершенно разные модели.
Один из них — мгновенный режим (Instant Mode), доступный для всех пользователей.
Этот режим ориентирован на мгновенную реакцию и бесшовную интеграцию в рабочие и жизненные процессы.
Например, вы отправляете ему команду с телефона, и он за несколько секунд предоставляет вам структурированное изображение.
Его базовые возможности визуального понимания чрезвычайно сильны, но он в основном решает частые, одноразовые задачи визуального преобразования.
А режим мышления (Thinking Mode), доступный для платных пользователей.
Даже прежде чем начать отображать хоть один пиксель, оно сначала проходит через длительный процесс логических рассуждений и поиска в интернете, длящийся более десяти секунд.
Эта модель именно решает чрезвычайно ключевую, но чрезвычайно сложную задачу:
Модель впервые действительно узнала, что именно ей нужно рисовать.
Приведем самый наглядный пример.
Введите в чат:
Создайте плакат, найдите в интернете отзывы о таинственной модели Duct Tape и добавьте QR-код ChatGPT.

Если использовать старую модель, она вообще не поймет, что написали пользователи, и просто нарисует плакат с бессмысленными символами, а QR-код будет фальшивым изображением, которое нельзя просканировать.
Но в режиме мышления его рабочий процесс выглядит так:
Он сначала приостановит рисование, запустит инструмент поиска в интернете и соберет реальные отзывы пользователей с Reddit, Threads или LinkedIn;
Затем он начал планировать макет плаката, белые пространства и иерархию шрифтов;
Наконец, он генерирует настоящий, рабочий QR-код, который можно отсканировать для перехода, и отображает всю картинку.

Это уже не просто рисование, а фактически комплексная работа по самостоятельному проведению исследований, планированию, извлечению текстов и дизайну макетов.
Здесь необходимо сделать параллельное сравнение.
Все, кто следит за сообществом крупных моделей, знают, что генеративные модели с возможностью подключения к интернету и поиска не были впервые созданы OpenAI.
Второй в рейтинге Nano-banana уже обладал этим механизмом.
Но при практическом использовании Nano-banana вы обнаружите, что он кажется несколько неуклюжим во многих местах.
Мысли Nano-banana часто представляют собой механическое соединение логики.
Например, если вы попросите его найти тренды отрасли для создания плаката, он действительно найдет, но обычно просто механически вырывает предложения из Википедии и насильно вставляет их на изображение.
Когда возникает необходимость интерпретировать абстрактные бизнес-требования, он легко теряется.

Это ощущение, как будто у вас есть стажёр, который понимает, что ему говорят, но完全没有 опыта работы — он знает, как выполнять задачи, но совершенно не понимает стратегию.
Но производительность GPT-Image-2 в этой области можно описать только как преувеличенную.
Его размышления — это не формальность, а настоящее понимание культурного контекста и коммерческих намерений.
During testing, I entered a minimal Chinese instruction: Help me create a screenshot of Musk live-streaming on TikTok to sell Doubao.
Если использовать старые модели генерации изображений, они, скорее всего, нарисуют белого человека, похожего на Маска, с баоцзы в руке, с нечетким фоном и даже не знающим, как выглядит Douyin.
Но в режиме мышления результаты GPT-Image-2 вызывают некоторое беспокойство.
Он не просто скомпоновал элементы, а самостоятельно применил понимание китайского интернета, чтобы сгенерировать скриншот интерфейса стрима на Douyin, точный до пикселя.
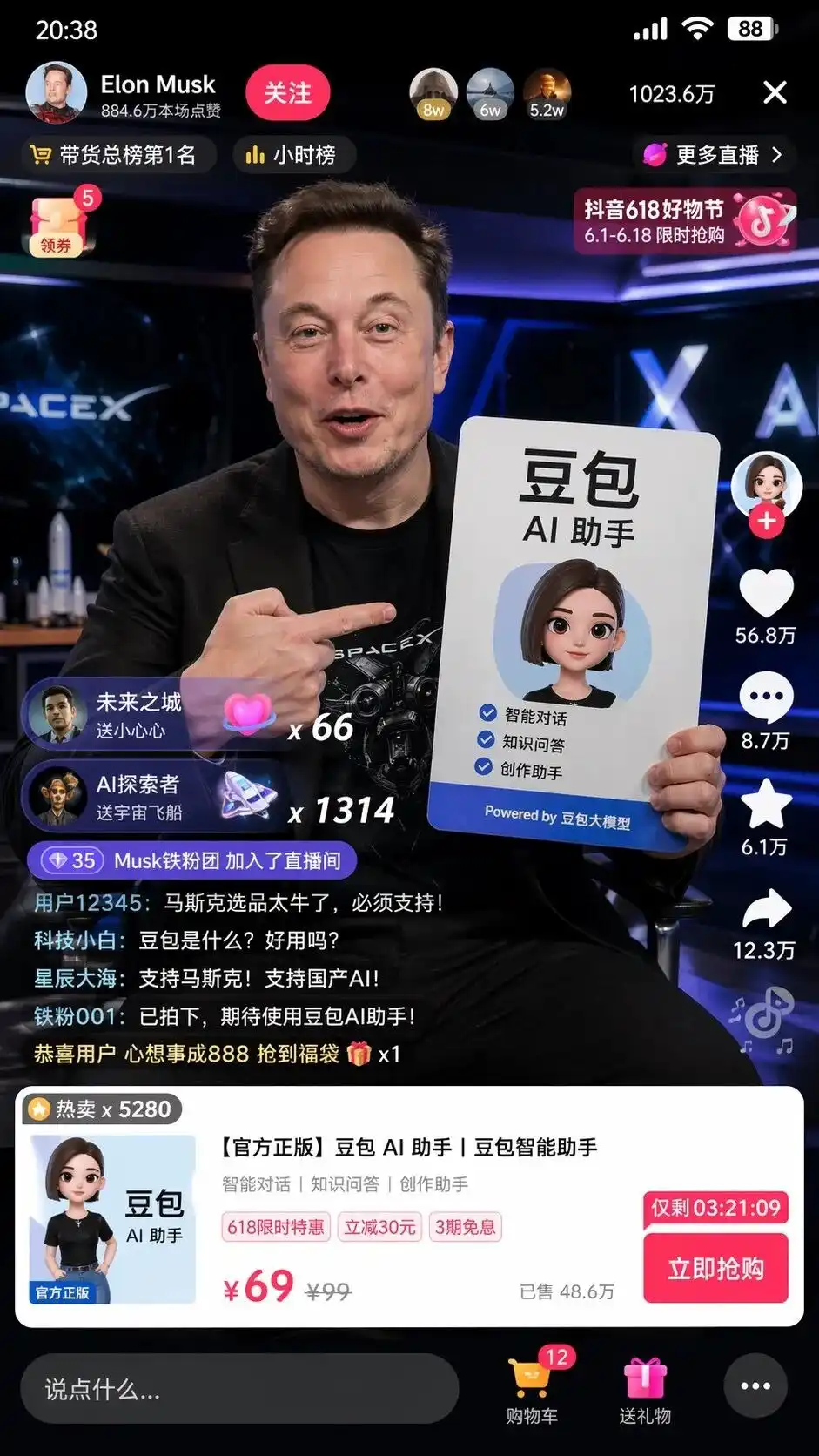
На экране не только реалистичный Маск держит плакат с рекламой помощника AI DouBao с идеальным форматированием, но и еще более пугающие детали, которых не было в подсказке:
Кнопка подписки в левом верхнем углу, рейтинг по часам, 10,236,000 онлайн-пользователей в правом верхнем углу, стандартная карточка товара, появляющаяся внизу, а также указанная зачеркнутая цена 99, специальная цена 69 и кнопка «Купить сейчас» с обратным отсчетом.
Самое жуткое — это прокручивающиеся в левом нижнем углу чрезвычайно реалистичные комментарии пользователей:
Технический новичок: Что такое Добао? Удобно ли пользоваться?
Звёзды и океаны: Поддерживаем Маска! Поддерживаем отечественный ИИ!
Никто не говорил ему, что писать в чате, как должен выглядеть интерфейс товара и какую устанавливать цену.
Это полный дизайн пользовательского интерфейса и маркетинговый план, сгенерированный моделью после анализа меток «продвижение товаров на Douyin» и «большая модель DouBao».
В этот момент оценочные критерии больших моделей в генерации изображений перешли от простого вопроса «можно ли нарисовать красиво» к пониманию стратегии и логики композиции.
ЧАСТЬ 02. Практическая проверка ключевых возможностей
Чтобы проверить его пределы, я протестировал его на нескольких частых и сложных сценариях в соответствии со стандартами коммерческого дизайна.
Оказалось, что уровень детализации, с которым он решает проблемы, доходит до жуткого.
Первый сценарий: визуальное понимание и бизнес-цикл (одевание модели)
В традиционной электронной коммерции или планировании моды стоимость реализации от идеи до визуализации на модели чрезвычайно высока.
Вам нужно найти модель, взять одежду напрокат, организовать студию и провести постобработку.
Позже появился ИИ, и люди начали обучать модели LoRA для фиксации черт лица персонажей, но это все еще требует десятков изображений и значительных затрат на обучение.
В GPT-Image-2 этот процесс был максимально сжат.
Я загрузил свое обычное селфи, сообщил ему, что в следующем месяце еду в отпуск на остров, и попросил помочь подобрать несколько комплектов одежды.
Сначала он предоставил мне 8 каталогов летней одежды в совершенно разных стилях, оформленных как профессиональный电商-lookbook, где рядом с каждой单品 даже есть правильные текстовые подписи.
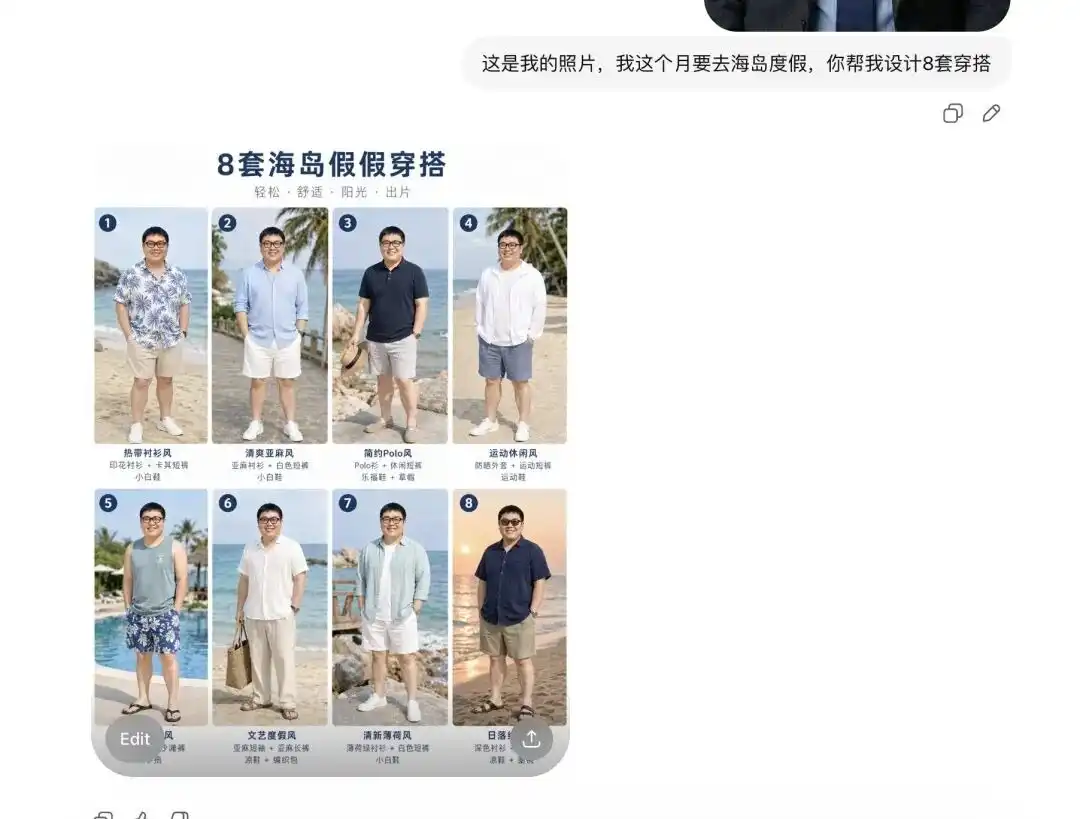
Более того, в этот момент он точно проанализировал мои черты лица и пропорции тела.
Когда я сказал ей, что хочу увидеть, как выглядит первый комплект на мне, и попросил несколько детальных снимков с разных углов, она сразу извлекла человека с моего селфи, надела на него летнюю одежду и вывела изображения с бокового, полуповерхностного и других ракурсов.

Этот поворот очень плавный. Это означает, что барьер для первоначальной визуализации одежды или аутсорсинга работы с моделями полностью устранён.
Второй сценарий: решение вопросов согласованности и непрерывности повествования (генерация комикса одним предложением)
Все, кто пробовал генерировать изображения с помощью ИИ, знают, что легко заставить ИИ нарисовать красивое изображение, но сложно заставить его нарисовать десять изображений одного и того же человека с последовательными движениями и ракурсами.
Это и есть так называемая проблема согласованности (Consistency).
Но в этом практическом тесте я столкнулся с случаем, крайне противоречащим прошлому опыту.
Можно загрузить только одну фотографию с другом из вчера и ввести очень простую подсказку:
Превратите нас в главных героев, нарисуйте три трёхстраничные японские манги, сюжет придумайте вы
Через несколько секунд он сразу вывел три страницы черно-белых комиксов со стандартными сценариями.
Самое страшное, что эти два персонажа, созданных на основе реальных людей, находятся в разных кадрах на трех страницах.

Как ближние планы, так и дальние планы с бегом, а также силуэты — даже черты лиц, детали прически и складки на одежде — полностью сохраняют идеальную согласованность.
Еще более впечатляет то, что сюжет комикса полностью логичен, и даже текст в речевых пузырях образует целостную повествовательную структуру.

Способность обеспечивать согласованность во времени и пространстве свидетельствует о том, что она вышла за рамки генерации отдельных изображений и обладает режиссерскими способностями для создания непрерывного повествования.
Третий сценарий: преодоление последнего барьера в рендеринге текста (многоязычная верстка)
Если согласованность решила проблему повествования, то точное отображение многоязычного текста действительно загнало графических дизайнеров в угол.
Раньше, как только в изображении появлялся хоть какой-то текст, крупные модели начинали рисовать каракули.
Поскольку модель понимает текст в виде токенов (семантических блоков), а генерирует изображения в виде пикселей, эти два элемента ранее были разобщены.
GPT-Image-2 полностью решил эту проблему.
Я создал обложку французского модного журнала, составил меню японского ресторана с полным набором хираганы и иероглифов, а также попробовал разметку с чрезвычайно высокой плотностью русских комментариев.

Результат — один этап, без опечаток.
Самое отчаянное — это то, что он не только правильно написал буквы, но и умеет соответствовать культурным вкусам и дизайну шрифтов в зависимости от языка.
Например, китайские иероглифы в японских листовках используют очень аутентичные японские ретро-шрифты, а расположение хираганы соответствует традиционной вертикальной форме чтения на японском языке.
Дизайн макета когда-то был монополией графических дизайнеров.
Настройка интервалов между буквами, определение приоритетов и достижение визуального баланса между текстом и фоном требуют много практики.
Но когда ИИ может обрабатывать столько языков без ошибок и обладает продвинутым чувством типографики, повседневные плакаты, буклеты и рекламные объявления в ленте больше не требуют ручного выравнивания по направляющим.
Четвертая сцена: искаженное соотношение сторон и экстремальный микроконтроль (надпись на зерне риса)
Наконец, чтобы проверить, насколько велика его подчиняемость, я дал ему несколько очень сложных команд.
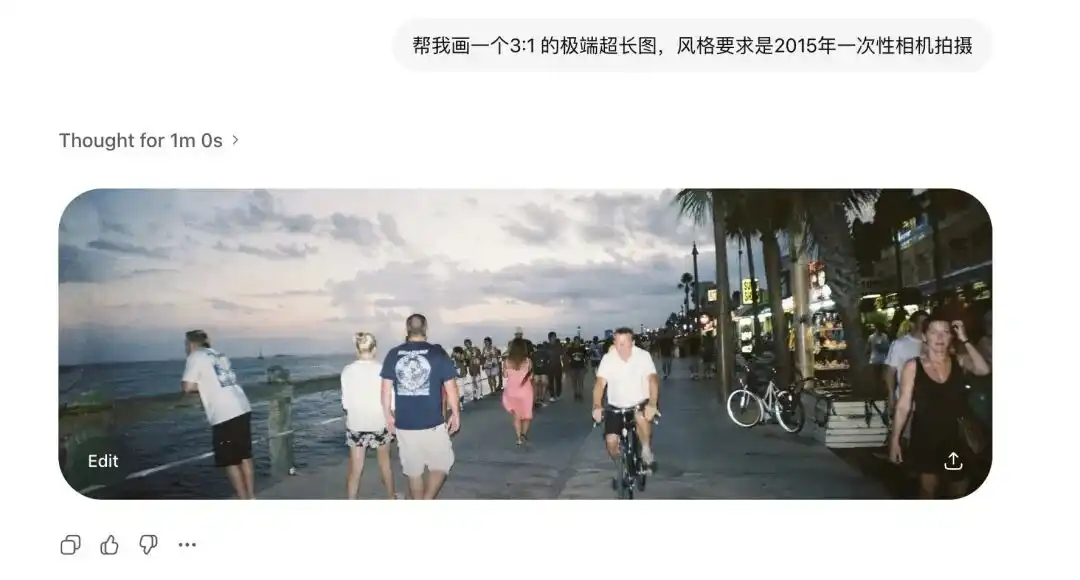
Я сначала протестировал его экстремальные соотношения сторон.
Традиционные диффузионные модели крайне чувствительны к нестандартным пропорциям.
Раньше, если немного растянуть изображение, на нем появлялись две головы.
Но я попросил Images 2.0 сгенерировать сверхширокие изображения с соотношением сторон 3:1 и вертикальные изображения с соотношением сторон 1:3 — они не только не испортились, но и сгенерировали 360-градусные панорамные изображения с замкнутой логикой, где начало и конец соединяются.
После добавления записи о фотографиях, сделанных одноразовой камерой 2015 года, даже искажения старых объективов и некачественное отражение вспышки на стене воспроизведены совершенно четко.
Еще одним более ярким примером его микроконтроля является немного безумный тест с рисовым зерном, продемонстрированный официальными лицами на презентации.
Исследователи использовали экспериментальный 4K API, который пока находится в закрытом тестировании; они не использовали никаких уточнений, таких как макросъёмка или 8K сверхвысокая чёткость, а дали лишь одну крайне абстрактную простую инструкцию:
Куча риса. На одной отдельной зернышке этой кучи риса написано GPT Image 2.
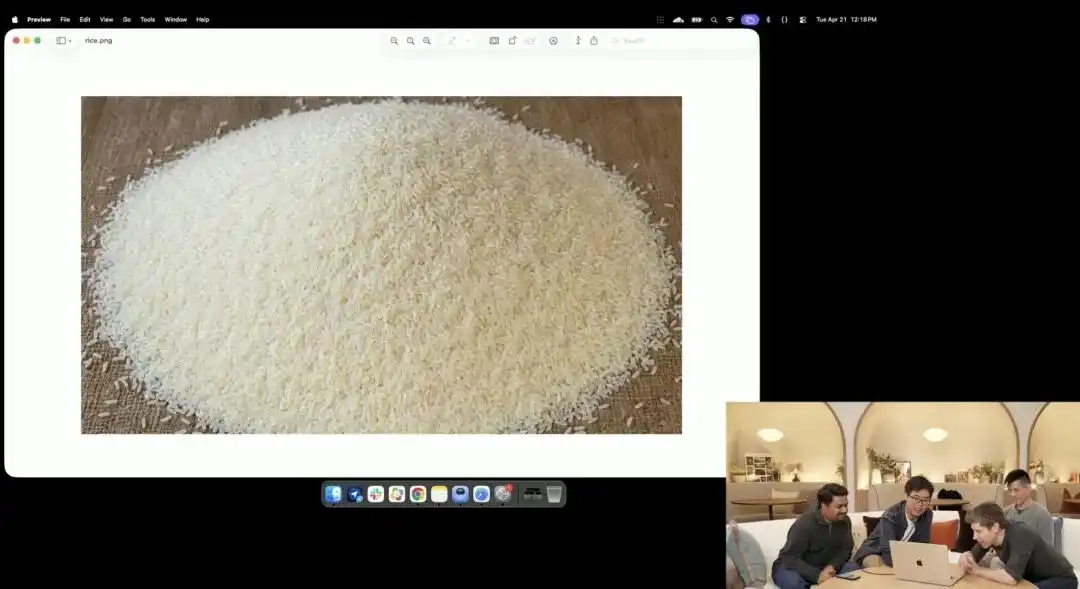
Когда изображение увеличено десятки раз на экране и даже появляются пиксельные зерна, вы действительно сможете найти ту крошечную частицу, на которой выгравирована надпись, среди кучи риса.
The texture of this grain of rice still conforms to the laws of physics, and the text is precisely embedded along the subtle curves of the grain.
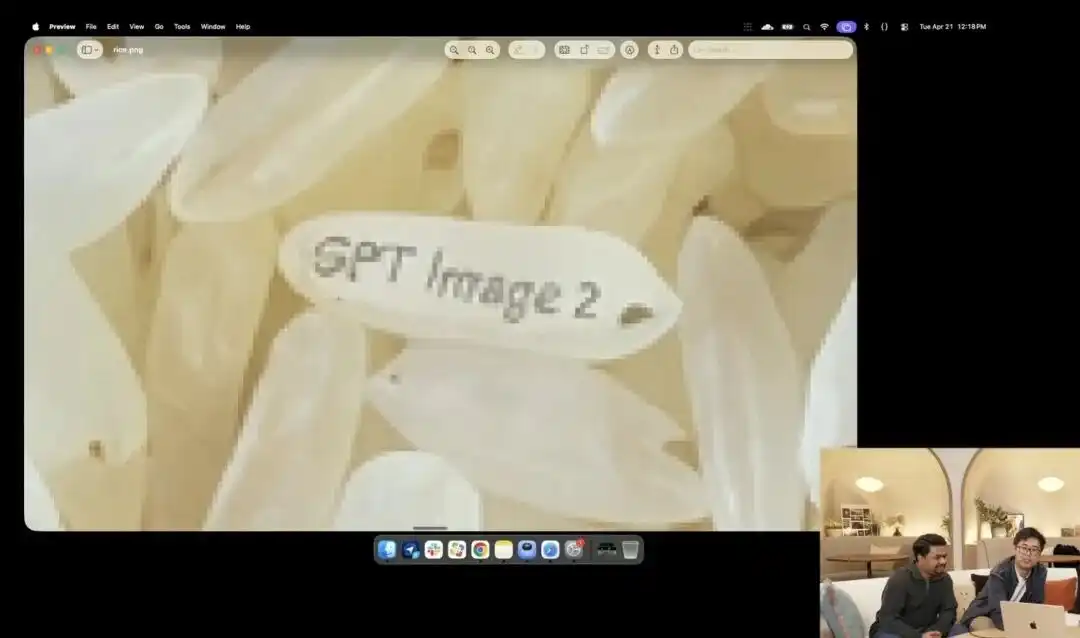
Все оставшиеся действия — вызов макро-взгляда, расчет глубины резкости, поиск физических координат зерна в латентном пространстве и нанесение текста — полностью автоматически сгенерированы и выполнены крупной моделью в режиме мышления.
Этот пример наглядно демонстрирует, что модель понимает пространственное положение с точностью до пикселя.
Это означает, что в дальнейшем в реальной работе вы сможете точно изменять любые мелкие детали в макете, точно указывая, что нужно изменить, а не как раньше, когда при попытке изменить воротник вся картинка менялась целиком.
ЧАСТЬ.03 Некоторые технические детали
Такая экстремальная контрольная сила и стратегический интеллект не могут быть достигнуты просто за счет слепого наращивания вычислительной мощности.
Чтобы выяснить, что именно лежит в основе, я провел несколько тестовых запросов для GPT-Image-2.
Выяснилось очень интересное обстоятельство.
Хотя в официальной документации указано, что общая база знаний GPT-Image-2 была обновлена до декабря 2025 года, в моих реальных тестах.
Дата окончания обучающих данных для режима мгновенного ответа (Instant Mode) по-прежнему является концом мая 2024 года;

А режим мышления (Thinking Mode), требующий длительного размышления, имеет базу знаний, устаревшую примерно до июня 2024 года (но может получать актуальную дату через онлайн-подключение в реальном времени).

Следуя этим двум временным точкам, можно проследить основу GPT-Image-2.
Сначала рассмотрим режим в реальном времени, ориентированный на частую генерацию изображений.
Срок действия мая 2024 года означает, что он, скорее всего, напрямую использует o4-mini или является легкой версией из семейства GPT-5 (GPT-5 mini или даже сверхмалопараметрической версией GPT-5 nano).
Как раз потому, что этот легковесный базовый слой уже обладает отличными способностями к планированию пространства и пониманию сложных команд, генерация изображений на верхнем уровне может сохранять стабильность и не выходить из-под контроля.
А основа того чрезвычайно умного, ориентированного на бизнес-стратегии мышления не может быть базовой моделью GPT-5.
Поскольку база знаний GPT-5 была обновлена до сентября 2024 года.
Режим мышления, скорее всего, подключен к постоянно обновляемой в фоновом режиме модели серии O (например, o4 или обновленной o3).
Большая модель сначала использует специальный механизм длительного размышления серии O, чтобы точно рассчитать в латентном пространстве бизнес-логику, психологию аудитории и координаты верстки, а затем передает данные визуальному модулю для финальной пиксельной рендеризации.
Конечно, существует и другой возможный путь:
В рамках крайне точного механизма распределения вычислительных ресурсов внутри OpenAI, быстрый режим может напрямую использовать GPT-5 nano для базовой обработки, тогда как режим размышления задействует немного более мощный GPT-5 mini в сочетании с внешними инструментами.
Но независимо от того, какая комбинация базовой платформы используется, если вы внимательно следите за экосистемой API OpenAI, вы заметите, что ее базовая логика генерации давно уже не на одном уровне с Midjourney.
ЧАСТЬ 04. Ценообразование, которое больше всего интересует пользователей
Но вместо того чтобы угадывать базовую цену, для разработчиков и компаний, которые действительно планируют интегрировать её в свои рабочие процессы, более важной является крайне реалистичная и контринтуитивная таблица цен на API.
Раньше DALL-E 3 взимал плату за изображение (например, 0,04 доллара за изображение).
Но с первого поколения GPT-Image-1 OpenAI полностью перешла на модель оплаты по токенам.
GPT-Image-2 в этом случае также соответствует этим стандартам, и даже предлагает увеличенные возможности по более низкой цене.
Согласно недавно опубликованному прайс-листу от официального источника, цена за миллион токенов следующая.
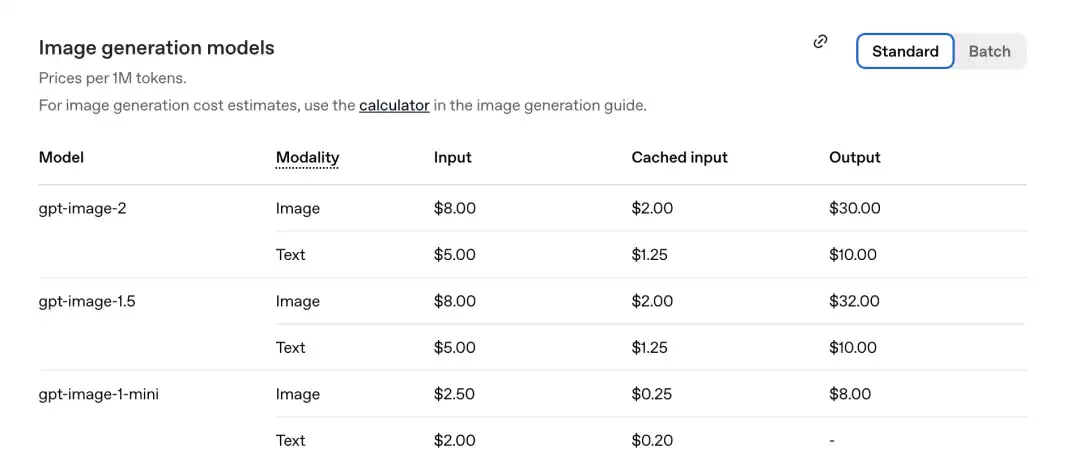
GPT-Image-2 Изображение: вход 8,00, кэшированные входы (Cached inputs) 2,00, выход 30,00 $
По сравнению с предыдущим поколением gpt-image-1.5: стоимость составляет $32.00.
Новая модель теперь дешевле.
Давайте проведем расчет.
В предыдущих моделях для генерации изображения высокого качества требовалось примерно 1000–1500 выходных токенов.
С учетом цены в 30 долларов за миллион выведенных токенов, фактическая стоимость генерации одного изображения составляет примерно от 0,03 до 0,045 доллара (около 2–3 юаней).
Если вам не нужен мгновенный ответ, а вы используете официальный режим API Batch (пакетная обработка), эта цена снова снизится вдвое (до $15,00).
В итоге создание одной картинки стоит всего более 10 центов.
Эта цена уже достаточно выгодна, но настоящим козырем является кэшированный ввод (Cached inputs) в таблице цен.
Раньше, когда вы рисовали комиксы или создавали серию плакатов, каждый раз при повторной генерации вам приходилось заново загружать множество опорных изображений персонажей, предысторию и длинные промпты — стоимость ввода была очень высокой.
Но в текущей модели оплаты по токенам, когда вы запрашиваете одновременную генерацию восьми последовательных комиксов, визуальные элементы первого изображения напрямую кэшируются как контекст.
Со второго изображения стоимость ввода изображений резко упала с $8,00 до $2,00 (то есть взимается только 25% от суммы).
Это означает, что при проведении масштабного коммерческого пакетного создания изображений или при необходимости высокой согласованности персонажей при последовательном создании его предельные затраты резко снижаются.
Чем умнее модель и чем больше она рисует, тем ниже средняя стоимость на изображение.
Эта индустриальная логика выставления счетов — то, что действительно загонит художников на конвейере в угол.
ЧАСТЬ 05. Раскрытие команды за кулисами
Наконец, мы снова обратим внимание на внутреннюю визуальную мечту OpenAI, которая демонстрировалась на прямой трансляции презентации — многие функции, которые раньше казались нереальными, теперь полностью объяснимы.
Например, как именно он решает проблемы сложного многоязычного форматирования и китайских иероглифов.
Это невозможно без старшего ученого в команде Габриэля Го.

В академической среде он наиболее известен как ключевой автор инновационной мультимодальной модели CLIP.
CLIP заложил основу для понимания современным ИИ того, как человеческий язык и пиксели изображений соотносятся друг с другом.
Со своим лидером в области межмодального семантического сопоставления GPT-Image-2 больше не угадывает форму текста, а действительно пишет на уровне пикселей.
Например, как он может понимать трехмерные пространственные отношения, создавать экстремальные панорамные изображения с соотношением сторон 360 градусов и воспринимать микроскопическое освещение на зерне риса?
Это благодаря другому ключевому члену команды Алексу Ю.

До присоединения к OpenAI он был сооснователем и бывшим техническим директором стартапа Luma AI, известного в области генерации 3D-контента, а также ведущим ученым, специализирующимся на нейронной рендеринге 3D (например, NeRF).
С ним GPT-Image-2 уже вышел за рамки традиционной 2D-пиксельной растяжки.
Скорее всего, сначала в уме создается трехмерная сцена, расставляется освещение, а затем генерируется точный 2D-срез.
Как удалось добиться такой ужасающей согласованности многостраничной комиксной истории.
Это соответствует молодой паре из команды, только что окончившей Массачусетский технологический институт (MIT CSAIL):
Боюань Чэнь (слева) и Кихан Сонг (справа).
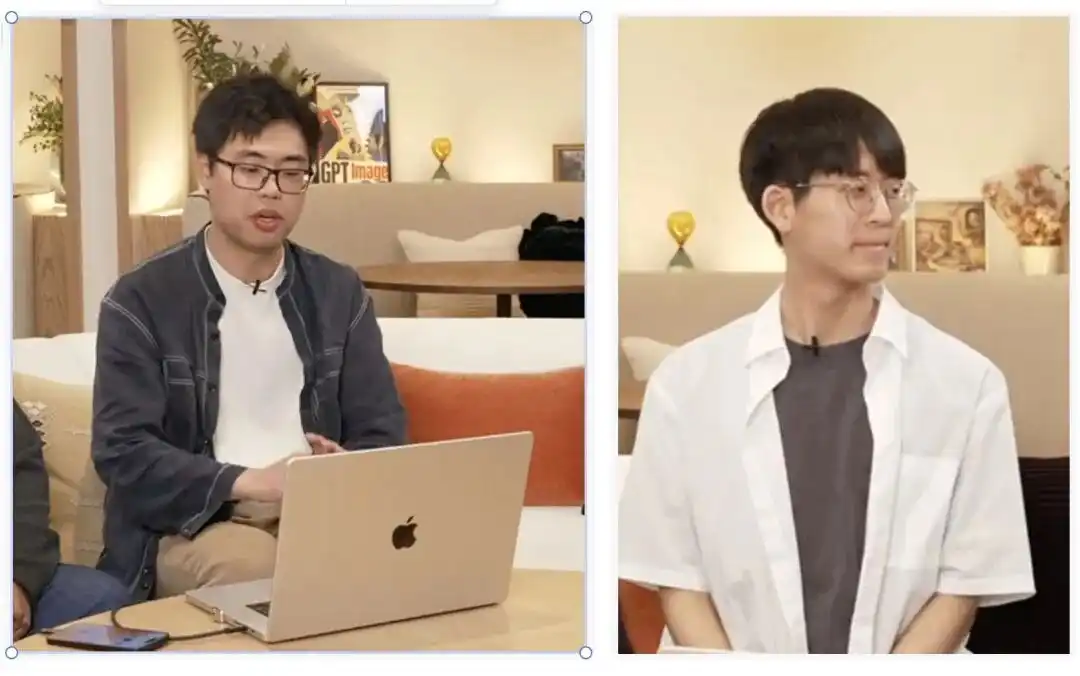
Их основное направление в академической среде — это мировые модели (World Models) и встроенная интеллектуальность.
Научить машину понимать, как функционирует физический мир, и обеспечить полную сохранность характеристик персонажей без искажений в разных кадрах во времени и пространстве — именно эта задача была предметом постоянных усилий этих двух ученых.
Наконец, добавьте Нитханта Кудидже (слева, ключевой автор моделей O-series для вывода), который постоянно работает над интеграцией крупных моделей вывода с базовой логикой визуализации, и Кэндзи Хату (справа, бывший исследователь Google, выпускник лаборатории визуализации Стэнфорда).

Когда эта группа людей объединяется, базовая логическая аргументация, 3D-рендеринг, идеальное выравнивание текста и изображений, а также законы физического мира естественным образом объединяются в одной модели.
ЧАСТЬ 06 Границы GPT-Image-2
У любой модели есть границы.
Официальные лица также признали, что они все еще испытывают трудности при столкновении с некоторыми экстремальными ситуациями.
Например, инструкции по оригами, требующие точного физического переворота, головоломка кубик Рубика или чрезвычайно плотные детали, подобные мельчайшим песчинкам, всё же достигают пределов его возможностей.
Но в контексте коммерческого применения это уже крайне незначительный недостаток.
Для всей индустрии дизайна нам не нужно разжигать тревогу — это вовсе не означает гибель эстетики.
Люди с вкусом, коммерческой проницательностью и пониманием стратегии все еще могут создавать с его помощью отличные вещи.
Но объективным фактом является то, что конкурентное преимущество дизайнера как профессии было существенно разрушено.
Раньше люди зарабатывали на жизнь, заучивая сочетания клавиш в дизайнерских программах, умением точно выравнивать шрифты по горизонтали и вертикали, знанием особенностей верстки для разных языков, а также умением тонкой ретуши и вырезания изображений.
Но в будущем это будет сложнее, потому что навыки, которые раньше можно было открыто продавать и торговать, теперь превратились в базовые команды, доступные бесплатно по одному запросу.
После периода затишья OpenAI снова доказала, кто на этой игре действительно держит козыри, используя крайне спокойный, но чрезвычайно мощный подход.
Старая цепочка инструментов для исполнения разрушается, и вопрос, стоящий перед отраслью, уже не в том, заменит ли нас ИИ, а в том, как нам адаптироваться к этой совершенно новой производственной линии.