










Источник: CoinW Research Institute
Краткое содержание
Gradients — это децентрализованная сеть обучения ИИ (SN56), построенная на Bittensor, чья суть заключается в преобразовании сложных технических процессов обучения моделей в сетевое сотрудничество, управляемое рынком, с помощью механизмов, таких как «публикация задач, конкуренция майнеров, проверка и отбор». В архитектуре она объединяет AutoML и распределенные вычислительные ресурсы, создавая рынок обучения, основанный на стимулирующих механизмах, что не только снижает барьеры для использования ИИ, но и повышает эффективность использования вычислительной мощности. С точки зрения экосистемы и данных, Gradients уже завершила создание базовой сети, однако текущие веса стимулов и приток капитала остаются относительно ограниченными. Gradients дополняет инфраструктуру обучения в экосистеме TAO и исследует новую парадигму «оптимизации ИИ, управляемой рынком», имея потенциал в долгосрочной перспективе стать важным входным слоем для децентрализованного обучения ИИ.
1. Начнем с Web2 AutoML: текущее состояние и ограничения обучения ИИ
1.1 Что такое AutoML
В традиционном понимании обучение модели ИИ — это задача с высоким порогом входа: инженеры должны обрабатывать данные, выбирать модель, многократно настраивать параметры и оценивать результаты — весь процесс сложен и трудоемок. Появление AutoML (автоматизированного машинного обучения) по сути заключается в «упаковке» этих трудоемких шагов в автоматизированный процесс. Можно представить его как «инструмент для автоматического создания моделей»: пользователю достаточно предоставить данные и указать цель системы — например, классификацию, прогнозирование или распознавание — а все остальные этапы, включая выбор модели, настройку параметров и обучение с оптимизацией, выполняются системой автоматически. Это превращает ИИ из инструмента лишь для немногих профессиональных инженеров в доступную способность для обычных разработчиков и даже предприятий — важный шаг на пути к массовому распространению ИИ.
1.2 Основные ограничения традиционного AutoML
В настоящее время основные реализации AutoML сосредоточены на платформах облачных провайдеров, таких как Google Vertex AI и AWS SageMaker, которые предлагают «обучение ИИ как услугу». Хотя Web2 AutoML значительно снизил барьеры для использования ИИ, его базовые модели все еще имеют явные ограничения. Во-первых, это централизация: вычислительные мощности, ценообразование и правила полностью контролируются платформами, что делает пользователей сильно зависимыми от одного поставщика и лишает их переговорной силы. Во-вторых, стоимость высока и не прозрачна: ресурсы GPU, необходимые для обучения ИИ, в основном находятся в руках облачных провайдеров, а механизмы ценообразования лишены рыночной конкуренции. Еще важнее то, что эффективность оптимизации имеет предел. Традиционный AutoML по сути остается «системой, которая помогает вам найти оптимальное решение» — независимо от того, насколько сложна эта система, она по-прежнему представляет собой оптимизацию в рамках единой технологической траектории. Ее пространство для поиска ограничено, и она трудоемко одновременно пробует совершенно разные подходы. Таким образом, современное обучение ИИ на базе Web2 представляет собой «закрытую систему», в которой обучение, оптимизация и управление ресурсами модели происходят в среде, контролируемой одной платформой. Хотя эта модель эффективна, с ростом спроса ее границы постепенно становятся очевидными.
2. Градиенты: перестройка обучения ИИ с помощью «сети»
2.1 Gradients — это децентрализованная платформа AutoML
В предыдущем разделе мы упоминали, что основная проблема традиционного Web2 AutoML заключается в «закрытой системе»: обучение моделей зависит от платформы, пути оптимизации ограничены, а поток ресурсов ограничен. Gradients представляет собой переосмысление этой модели. Gradients возник из децентрализованного сообщества инженеров, инициированного WanderingWeights, и построен на сети Bittensor как подсеть, работающая на Subnet 56. В отличие от традиционных платформ, она не предоставляет централизованных услуг, а разбивает процесс обучения и передает его на выполнение открытой сети. Пользователю необходимо только определить цель задачи — например, тип модели и данные — остальные этапы, включая выполнение обучения, оптимизацию параметров и отбор результатов, автоматически выполняются сетью. В такой модели обучение ИИ превращается из сложного инженерного процесса в простой процесс «постановки задачи и получения результата», становясь больше похожим на универсальную способность, а не на технологическую работу с высоким порогом входа.
2.2 От закрытой системы к открытому сотрудничеству: какие проблемы решает Gradients
Суть изменения в Gradients заключается в преобразовании ранее замкнутого процесса обучения внутри единой платформы в открытый сетевой процесс сотрудничества. Задачи обучения больше не выполняются одной системой, а распределяются между несколькими участниками для параллельных попыток, после чего наилучшие результаты отбираются с помощью единой механизма оценки. Такая структура во-первых, снижает зависимость от централизованных сервисов, обеспечивая обучение на распределенных вычислительных ресурсах; во-вторых, разрозненные GPU-ресурсы интегрируются в одну сеть, формируя в условиях конкуренции более рыночный подход к распределению ресурсов. Еще важнее то, что оптимизация модели больше не ограничивается одним путем, а постоянно приближается к более совершенным решениям благодаря параллельному исследованию множества методов, тем самым повышая общий потенциал оптимизации.
2.3 Существенные изменения: от инструмента к «рынку обучения»
В традиционных AutoML платформы скорее являются инструментами, помогающими пользователям находить оптимальные решения с помощью внутренних алгоритмов. В Gradients этот процесс больше похож на постоянно функционирующий «рынок»: пользователи публикуют запросы, различные участники конкурируют за одну и ту же задачу, а результаты отбираются с помощью механизма оценки. Таким образом, производительность модели больше не зависит от возможностей одной системы, а формируется за счет постоянной конкуренции и итераций среди множества участников. AutoML превращается из относительно закрытой технической задачи оптимизации в динамический процесс, управляемый стимулами, позволяя масштабировать возможности оптимизации по мере роста числа участников. Это изменение придает обучению ИИ черты саморазвития, подобные рыночным.
2.4 Роль в экосистеме TAO: уровень инфраструктуры для обучения ИИ
В архитектуре подсетей Bittensor различные Subnet выполняют разные функции, такие как вывод, обработка данных и обучение, а Gradients находится на уровне обучения. Он отвечает за преобразование распределенных вычислительных мощностей в реальные результаты моделей и с помощью механизмов распределения задач и оценки обеспечивает непрерывное управление и оптимизацию этих ресурсов. Одновременно он связывает предложение вычислительных мощностей с потребностью в моделях, превращая обучение из простого процесса потребления ресурсов в организуемый и оптимизируемый процесс сетевого взаимодействия. В этой системе Gradients выступает в роли центрального звена, преобразующего распределенные ресурсы в пригодные для использования AI-возможности и поддерживающего развитие приложений верхнего уровня.
3. Основная архитектура: как происходит обучение ИИ в сети
В предыдущем разделе мы упоминали, что Gradients изменил процесс обучения ИИ с «выполнения внутри платформы» на «совместное выполнение через сеть». Как именно работает эта сеть? Основная цель этого раздела — наглядно разобрать этот процесс.
3.1 Распределённое обучение: как одна задача выполняется несколькими участниками
Представьте Gradients как постоянно работающую «сеть совместного обучения». После отправки пользователем задачи на обучение она не передаётся одному системе для выполнения, а одновременно распределяется между несколькими участниками сети. Эти участники, используя одни и те же данные и цели, пытаются применить различные методы обучения и в установленный срок отправляют результаты. Затем система проводит унифицированную оценку всех результатов и отбирает наилучшее решение. В итоге лучшие результаты получают вознаграждение, а остальные отсеиваются. Для пользователя этот процесс требует лишь инициализации одной задачи, что эквивалентно одновременному «вызову» нескольких различных подходов к оптимизации с автоматическим выбором наилучшего решения. Ключевая идея здесь — не в мощи отдельного узла, а в параллельном экспериментировании множества участников и автоматическом отборе, позволяющем постепенно приближаться к оптимальному результату.
В этой сети существует три основных участника: пользователи, майнеры и валидаторы. Пользователи формулируют требования к обучению; майнеры предоставляют вычислительные мощности и пробуют различные методы обучения; валидаторы оценивают результаты и отбирают оптимальные модели. Такое разделение труда позволяет процессу обучения работать непрерывно и постоянно отбирать более эффективные решения. В целом, это формирует кооперативную сеть, управляемую «спросом, предложением и оценкой».
3.2 Автоматизированное машинное обучение, ориентированное на рынок
Как видно из предыдущего разбора механизма, Gradients не просто переносит AutoML на блокчейн, а изменяет фундаментальную логику оптимизации моделей за счет введения многостороннего участия и стимулирующих механизмов. В традиционном AutoML оптимальное решение ищется单一ной системой в рамках ограниченных путей, тогда как в Gradients этот процесс расширяется на всю сеть: различные участники постоянно пробуют разные подходы к одной и той же задаче и постоянно отбирают и итерируют их через единую оценку. Это превращает оптимизацию модели из одноразового вычислительного процесса в динамический процесс, способный к многократному развитию. В рамках такой системы лучшие результаты получают более высокую награду, что постоянно привлекает участников к улучшению своих стратегий и способствует постоянному повышению общей эффективности.
4. Механизмы стимулирования и конкуренции: как обучение ИИ формирует «положительный цикл»
4.1 Механизм стимулирования (на основе TAO): от тренировочных действий к доходу
Ключом к долгосрочной работе Gradients является механизм стимулирования, который опирается на нативную систему вознаграждений Bittensor. В ней TAO является нативным токеном сети Bittensor и служит «носителем ценности» во всей сети: он используется для вознаграждения участников, предоставляющих вычислительные мощности и вносящих вклад в модели, а также участвует в распределении весов подсетей через стейкинг и другие механизмы, влияя на то, как ресурсы перемещаются между различными подсетями.
Главная сеть Bittensor постоянно генерирует новые стимулы Emission в виде TAO (сейчас примерно 3600 TAO в день), которые распределяются между различными подсетями по определённым правилам. Количество TAO, которое получает каждая подсеть, зависит от её «производительности» в сети — например, уровня активности, качества вклада и уровня финансовой поддержки. Для подсети, в которой находится Gradients, эта распределённая часть TAO снова распределяется внутри между участниками. Основным критерием распределения является качество внесённого модели: чем лучше модель, тем больше дохода получает её автор.
Подробно: майнеры отправляют результаты обучения, а валидаторы отвечают за тестирование и оценку этих результатов. Система рассчитывает «вес вклада» каждого участника на основе оценок, а затем распределяет вознаграждения в соответствии с этим весом. Модели с лучшей производительностью (например, с более высокой обобщающей способностью и более стабильными результатами) получают более высокую прибыль, а валидаторы, чьи оценки более точны и лучше отражают реальное качество, также получают более высокие стимулы. Такая система напрямую связывает «лучшую работу» с «большим заработком», стимулируя участников постоянно улучшать модели.
4.2 Конкуренция между подсетями: не только внутренняя конкуренция, но и внешний рейтинг
Помимо внутренней конкуренции в подсети, Gradients сталкивается с «горизонтальной конкуренцией» по всему сети Bittensor. Поскольку распределение TAO динамично, различные подсети конкурируют за более высокий вес. Только те подсети, которые постоянно генерируют высококачественные результаты и привлекают больше участников, получают большую долю вознаграждения. Таким образом, стимулы для Gradients зависят не только от внутренней производительности моделей, но и от их относительной конкурентоспособности во всей экосистеме. Вся система образует многоуровневый цикл: внутри подсети происходит конкуренция между моделями; между подсетями — конкуренция за общую производительность. В конечном итоге вложения вычислительных мощностей, эффективность моделей и экономическая отдача связаны вместе, образуя устойчивый механизм обратной связи.
4.3 Градиенты 5.0: от конкуренции к «турнирному механизму»
На основе ранних непрерывных соревнований Gradients эволюционировали в более структурированный механизм, известный как «турнирное обучение». Его можно представить как периодический турнир: на каждом этапе обучения задается временной интервал, несколько участников соревнуются в выполнении одной и той же задачи, и посредством нескольких раундов отбора постепенно исключаются менее эффективные решения, пока не будет выбрана оптимальная. Этот подход подчеркивает поэтапное сравнение и централизованную оценку. Важным изменением стало то, что майнеры больше не отправляют напрямую результаты обучения, а представляют «методы обучения» (код), которые затем единообразно выполняются проверяющими узлами. Это повышает справедливость, исключая влияние различных вычислительных сред, а также лучше защищает конфиденциальность данных и процесса обучения. Кроме того, победившие методы часто сохраняются и становятся переиспользуемыми решениями, подобно накоплению «наилучших практик». В долгосрочной перспективе такой механизм не только отбирает оптимальные модели, но и формирует постоянно развивающуюся библиотеку методов обучения.
5. Текущее состояние экосистемы
5.1 Структура участников: коллаборативная сеть, состоящая из спроса, предложения и оценки
Экосистема Gradients состоит из трех ключевых ролей: пользователи (сторона спроса), майнеры (сторона предложения) и валидаторы (сторона оценки). Пользователи в основном включают разработчиков ИИ, малый и средний бизнес, а также создателей Web3 — эти группы обычно обладают определенной технической базой, но не имеют достаточной вычислительной мощности или полных возможностей для обучения моделей, поэтому предпочитают использовать Gradients для создания моделей с меньшими затратами. Майнеры предоставляют вычислительную мощность GPU и участвуют в конкуренции за задачи обучения, их основной мотивацией является получение дохода в TAO. Валидаторы отвечают за оценку и ранжирование результатов обучения, играя ключевую роль в обеспечении качества моделей и эффективной работы механизма.
С точки зрения более детализированного пользовательского профиля, реальная аудитория Gradients демонстрирует явную «полуразработческую» характеристику: она отличается как от ведущих лабораторий ИИ, так и от обычных пользователей без технической подготовки, сосредоточившись в основном на разработчиках с определенными инженерными навыками и пользователях Web3. Это также отражается в структуре сообщества: текущая экосистема в основном англоязычная, основная аудитория сосредоточена среди разработчиков в Северной Америке и Европе, при этом охватывая также часть майнеров в Юго-Восточной Азии и глобальных поставщиков GPU. В целом она близка к технически ориентированному сообществу разработчиков.
5.2 Текущее состояние экосистемы
На 12 мая цена альфа-токена Gradients составляла около 0,0255 TAO, количество адресов с токенами — около 4 890, майнеров — 243, валидаторов — 12, доля эмиссии — 1,61%. При этом в ликвидности TAO составляет 2,19%, а Alpha — 97,81%. С точки зрения цены и количества держателей, Gradients уже имеет определенную базу пользователей и внимание, но в целом находится на ранней стадии распространения. Для сравнения, у ведущего проекта TAO-экосистемы Chutes цена альфа-токена составляла 0,0877 TAO, а количество адресов с токенами — 13 409.
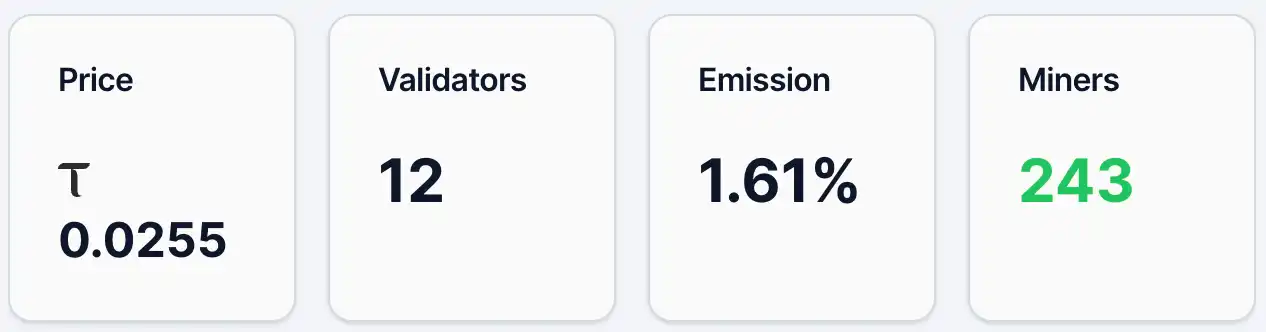
Рисунок 1. Данные градиентов.
Источник:https://bittensormarketcap.com/subnets/56
Затем следует механизм эмиссии. В системе Bittensor эмиссия обозначает текущий вес распределения новых наград между подсетями в рамках всей сети. Сеть Bittensor непрерывно создает новые TAO, которые распределяются между подсетями пропорционально их весам. Текущий показатель 1,61% для Gradients означает, что она получает лишь небольшую долю от общих новых наград сети. Этот показатель по сути отражает «результат голосования» рынка, выраженный через потоки капитала (например, стейкинг). Таким образом, уровень в 1,61% обычно указывает на относительно ограниченную рыночную признанность и приток капитала, но одновременно оставляет пространство для потенциального роста веса в будущем. С точки зрения структуры капитала (ликвидные пулы), доля TAO составляет всего 2,19%, в то время как Alpha достигает 97,81%, что свидетельствует о ограниченном притоке внешних средств и преобладании внутреннего предложения подсети. Цена чувствительна к новым вливаниям капитала — при увеличении притока TAO возможен более выраженный эффект ускорения.
6. Конкурентная среда и преимущества/недостатки
6.1 Отраслевая ориентация: инфраструктура для обучения децентрализованного AutoML
Gradients занимает нишу «инфраструктура для обучения ИИ + децентрализованная AutoML». Он стремится освободить обучение моделей от централизованных платформ и обеспечить более эффективное использование ресурсов и оптимизацию моделей с помощью сетевых механизмов. В рамках экосистемы Web2 эта ниша уже относительно зрелая, типичными представителями которой являются Google Vertex AI и AWS SageMaker. Эти платформы предоставляют разработчикам комплексные услуги по обучению и развертыванию моделей с использованием облачных вычислений, но по своей сути остаются централизованными архитектурами. В отличие от них, отличие Gradients заключается не в «большем количестве функций», а в иной базовой логике: он превращает обучение из «платформенной услуги» в «сетевое сотрудничество» и использует конкурентный механизм для отбора оптимальных результатов, делая его более похожим на рыночно функционирующую систему обучения.
6.2 Поперечное сравнение: различия между Web2 и Web3 AutoML
С более широкой точки зрения, различие между Web2 и Web3 в направлении AutoML по сути является сравнением двух разных парадигм. Модель Web2 акцентирует эффективность и стабильность, обеспечивая контролируемый и зрелый опыт обслуживания за счет централизации ресурсов и инженерной оптимизации; в то время как модель Web3 больше ориентирована на открытость и стимулирование, позволяя моделированию эволюционировать в условиях конкуренции за счет привлечения множества участников. Конкретно, Web2 AutoML больше похож на «мощный инструмент»: пользователь передает задачу платформе, а система самостоятельно находит оптимальное решение; в то время как Web3 AutoML, представленный Gradients, скорее напоминает «открытый рынок», где пользователи публикуют свои требования, а различные участники предлагают решения, после чего результаты отбираются с помощью механизма оценки. Прямое следствие этого различия заключается в том, что первая модель более стабильна и контролируема, но имеет ограниченные пути оптимизации; вторая же предлагает больший потенциал для исследований и более высокий потенциальный предел, однако все еще нуждается в улучшении стабильности и зрелости.
6.3 Дифференциация Gradients в Web3
В текущем секторе Web3 AI большинство проектов сосредоточены на уровне вывода или AI Agent, тогда как проекты, ориентированные на «инфраструктуру обучения», относительно редки. Некоторые проекты пытаются объединить вычислительные сети или сети данных для предоставления возможностей обучения, но в целом большинство остаются на уровне управления ресурсами или рынка вычислительных мощностей. Отличие Gradients заключается в том, что он не просто предоставляет согласование вычислительных мощностей, а продвигается дальше — к самому «механизму оптимизации модели», внедряя систему оценки и конкуренции, что позволяет процессу обучения постоянно развиваться. Это означает, что он решает не только вопрос «откуда берутся вычислительные мощности», но и «как использовать эти мощности более эффективно». С точки зрения позиционирования, Gradients ближе к сети, ориентированной на результат обучения, а не просто к рынку вычислительных мощностей или инструментальной платформе — именно это является ключевым отличием от большинства проектов Web3 AI.
6.4 Ключевые преимущества: повышение эффективности за счет механизма
В целом, преимущества Gradients в основном проявляются в их архитектуре. Во-первых, благодаря абстракции задач, они снижают порог входа, позволяя пользователям получать результаты моделей без глубокого участия в сложных процессах обучения, что расширяет потенциальную аудиторию. Во-вторых, на уровне ресурсов внедрение распределенных вычислений освобождает обучение от зависимости от одного облачного провайдера, теоретически позволяя сформировать более гибкую структуру затрат за счет конкуренции. Еще важнее изменение подхода к оптимизации. Благодаря параллельному исследованию несколькими участниками и использованию механизма отбора, Gradients предлагают альтернативу традиционной однопутевой оптимизации, позволяя моделям достигать более высокой производительности за более короткое время. Эта модель «оптимизации, движимой конкуренцией», является их главным преимуществом.
6.5 Потенциальные вызовы
Качество модели может иметь проблемы с стабильностью. Распределенное обучение зависит от участия нескольких сторон; хотя это может повысить потенциал, оно также может вызывать колебания результатов, и в плане управляемости по сравнению с централизованными системами существует определенная неопределенность. Во-вторых, возникают вопросы доверия на корпоративном уровне. Для корпоративных пользователей безопасность данных и проверяемость процесса обучения имеют решающее значение, и в распределенной среде обеспечение того, чтобы данные не использовались неправомерно, а результаты могли быть аудированы, остается ключевым испытанием. Наконец, существует зависимость от токеномики. Функционирование Gradients сильно зависит от механизма стимулирования; если привлекательность дохода от TAO снизится, это может повлиять на участие майнеров и общую активность сети. Следовательно, его долгосрочная устойчивость в определенной степени зависит от того, сможет ли экономическая модель сформировать устойчивый положительный цикл.
7. Перспективы на будущее: Может ли децентрализованная AutoML существовать?
На текущем этапе Gradients всё ещё находится на ранней стадии, и его успешная реализация в будущем зависит от нескольких ключевых факторов. Самым важным является способность постоянно привлекать реальные потребности в обучении, а не только участие, стимулируемое вознаграждениями; далее — качество моделей: способна ли децентрализованная модель стабильно генерировать пригодные или даже более качественные результаты; а также — способна ли экономическая модель сформировать положительный цикл, обеспечивая долгосрочное равновесие между предложением вычислительных мощностей и доходами.
В более широком отраслевом контексте обучение ИИ разделяется на два направления. Одно — это модель Web2, доминируемая ведущими технологическими компаниями, которые за счет централизованных ресурсов и инженерных возможностей постоянно улучшают производительность моделей, что обеспечивает стабильность и зрелость; другое — это веб-3-направление, представленное Gradients, которое с помощью открытой сети и стимулирующих механизмов позволяет большему числу участников совместно участвовать в оптимизации моделей, постоянно повышая потолок в условиях конкуренции. Первое — это «создание более мощных систем», а второе — скорее «построение саморазвивающейся сети».
С этой точки зрения исследование Gradients представляет собой новую возможность: обучение ИИ больше не является исключительно технической проблемой, а представляет собой сочетание «вычислительных мощностей + данных + рыночных механизмов». Если эта модель окажется жизнеспособной, она может стать входной точкой для децентрализованного обучения ИИ и сыграть ключевую роль в экосистеме Bittensor. Конечно, этому направлению еще нужно время для проверки, но оно уже предлагает AutoML альтернативный путь развития, отличный от традиционного.
Ссылка
1. Документация Bittensor:https://docs.learnbittensor.org
2. Сайт Gradients:https://www.gradients.io/
3. Градиенты:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats:https://taostats.io/subnets/56/chart