









DeepSeek V4 наконец-то запущен. Это момент, которого ждали почти пять месяцев. Основная модель MoE с 1 трлн параметров + версия Flash с 285 млрд параметров, полная версия Pro с 1,6 трлн параметров следует вслед за ними, полностью открыта на GitHub по лицензии Apache 2.0, веса и код развертывания выпущены одновременно.
Как только модель появилась, финансовые рынки дали свой ответ тремя взаимосвязанными, но независимыми способами.
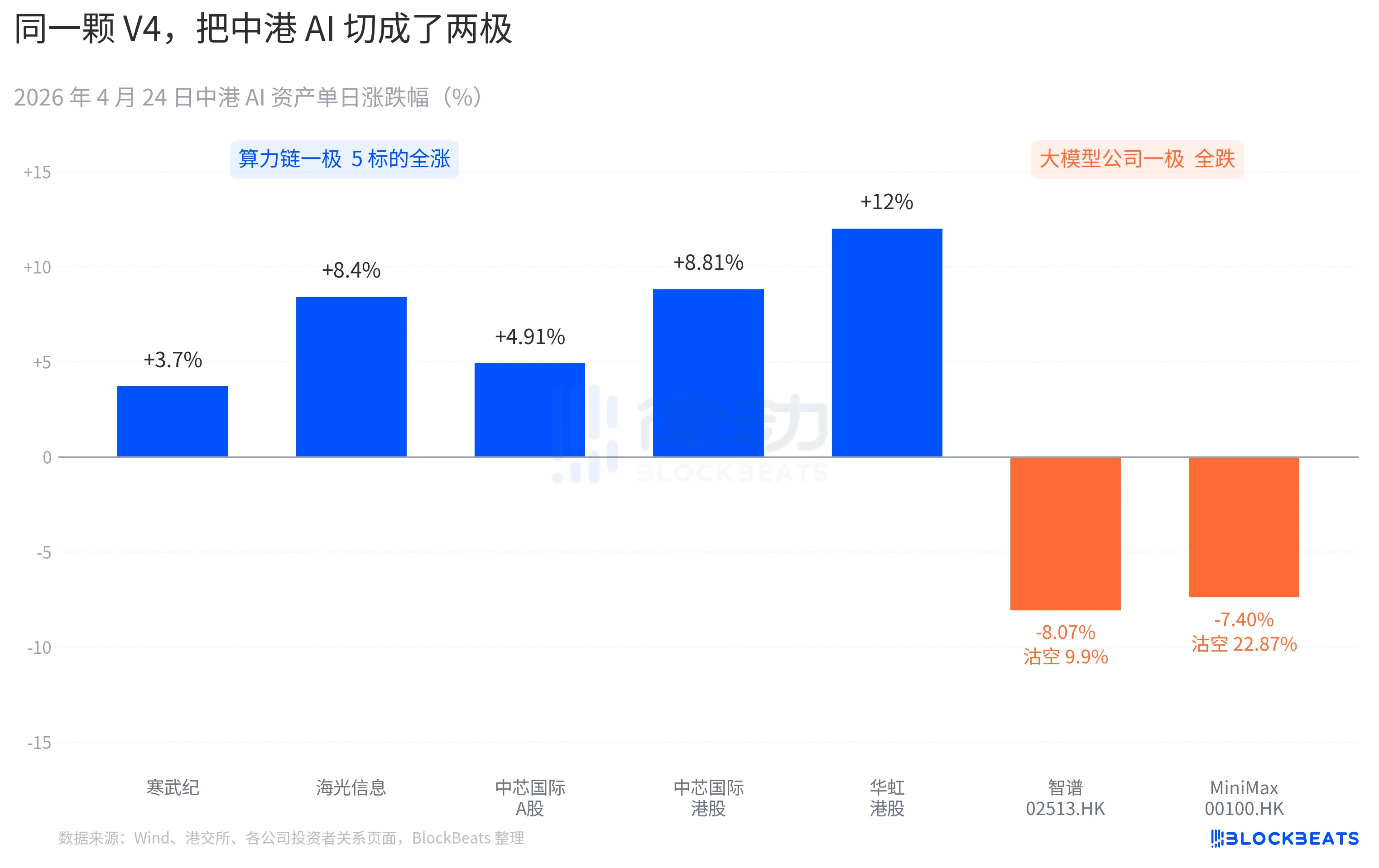
Разные реакции рынка капитала
Почти все акции цепочки вычислительных мощностей A-рынка показали резкий рост. Cambricon продемонстрировала 11 ростовых дней подряд, суточный рост составил 3,7%, а совокупный рост за месяц превысил 60%. Hightech Information достигла предела роста в 10% в ходе торгов и закрылась с ростом на 8,4%. SMIC на A-рынке вырос на 4,91%, на гонконгском рынке — на 8,81%. Hua Hong на гонконгском рынке поднялась до +18%, закрылась с ростом на 12%. ETF GBT на основе полупроводниковых акций научно-технического рынка привлек 2,4 млрд юаней за один день, и ее объем достиг исторического максимума.
У этой компании-разработчика крупных языковых моделей на гонконгском рынке другой цвет. Zhipu (02513.HK) упала на 8,07%, доля шортов — 9,9%. MiniMax (00100.HK) упала на 7,40%, доля шортов взлетела до 22,87%. Это самый высокий однодневный показатель шортов за последние три месяца в секторе ИИ на Гонконгской бирже. Обе компании являются представителями волны IPO в секторе ИИ на Гонконгском рынке во второй половине 2025 года, и в проспектах размещения их ключевым конкурентным преимуществом является одна и та же фраза: «собственная базовая крупная модель».
На другом конце Тихого океана реакция была столь же конкретной. Акции NVIDIA открылись 24 апреля с падением на 1,8%, в ходе торгов упали до -2,6%, а к закрытию закрепились на уровне открытия. Блумберг в своем рыночном обзоре сравнил эту коррекцию с «моментом DeepSeek» 27 января. Разница в том, что в январе произошел панический отток — за один день капитализация сократилась на 600 миллиардов долларов. На этот раз это скорее переназначение цен с умеренным объемом, но четким направлением. В исследовательских отчетах институциональных покупателей появилось новое выражение: «Спрос на ИИ-выводы в Китае начинает отделяться от спроса на ИИ-выводы в Северной Америке».
Сложив эти три графика друг на друга, вы получите первый приговор рынка, написанный в течение 24 часов после запуска V4. После победы открытого исходного кода деньги начали заново распределяться: больше не сама модель определяет цену, а то, на каком оборудовании она запущена и в какую цепочку поставок она встроена.
30 дней, 11 новых моделей, V4 подогревает сообщество с открытым исходным кодом
Временное окно выпуска V4 само по себе является одной из причин усиления этой реакции.
Откатимся на последние 30 дней. С 26 марта по 24 апреля по всему миру было выпущено или обновлено как минимум 11 крупных моделей с заметным влиянием, в список вошли почти все основные игроки: Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonshot Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, а также DeepSeek V4, выпущенный 23 апреля в полночь.
В среднем новый модель появляется каждые 2,7 дня. Это скорость, с которой даже управляющие фондами не успевают прочитать пресс-релизы. Но если просмотреть китайско-гонконгские K-линии AI-активов за последние 30 дней, то единственным именем, оставившим устойчивый след на графике, является одно. 8 апреля GPT-5.5 спровоцировал рост NVIDIA на 4,2% за один день, после чего акции достигли пика. Затем, 23–24 апреля, DeepSeek V4 стимулировал непрерывный скачок в цепочке вычислительных мощностей в Китае и Гонконге.
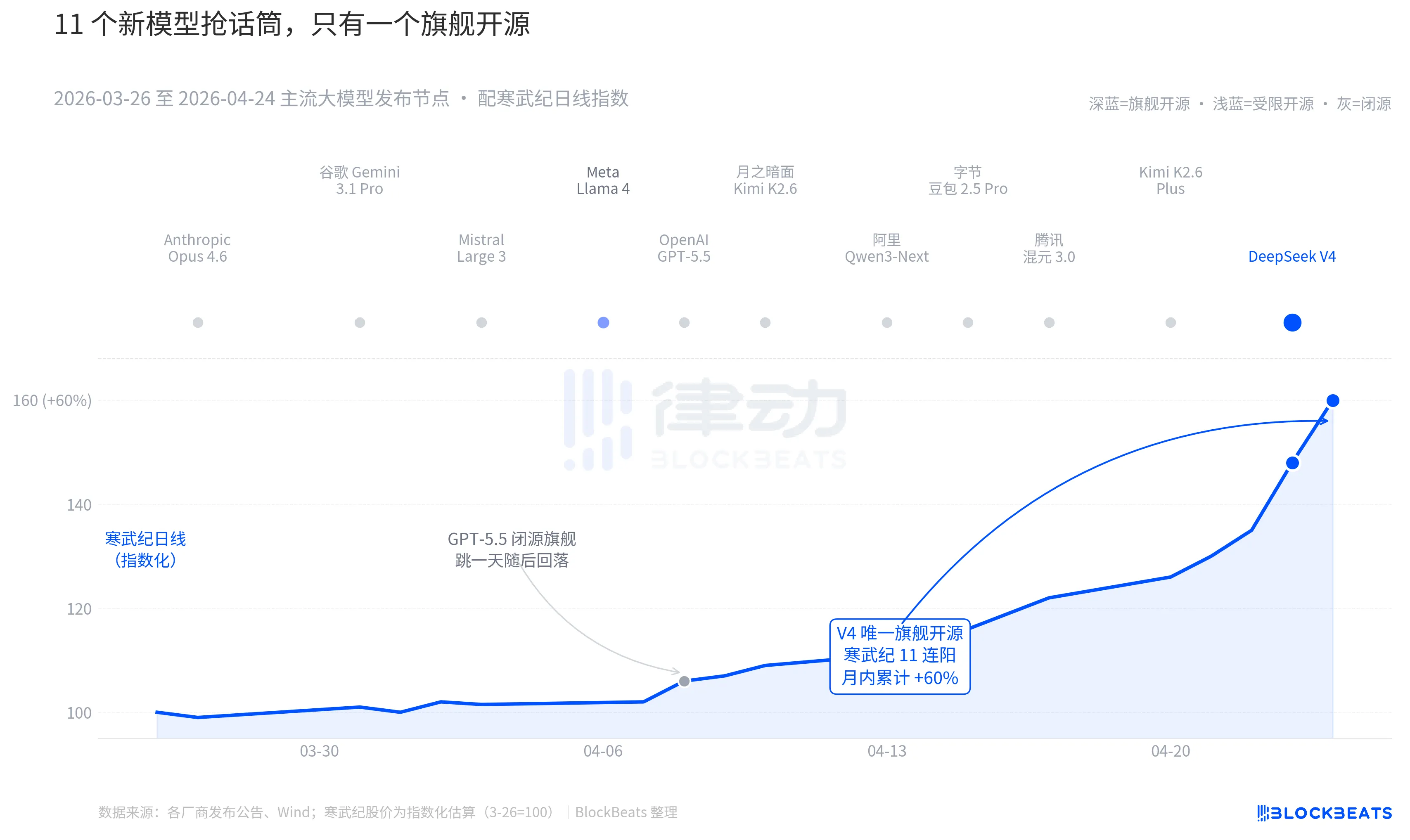
Разница заключается не в самих возможностях моделей. Разрыв между этими 11 моделями в рейтинге LMArena в большинстве случаев не превышает 50 баллов и находится в узком диапазоне «одного и того же уровня». Разница возникает из-за совокупности двух факторов.
Первое — это открытый исходный код. Среди первых десяти моделей только Llama 4 был открыт, однако его лицензия на веса содержала длинный список ограничений для коммерческого использования, и сообщество разработчиков в Европе и США отнеслось к нему холодно: уже на третий день после запуска на OpenRouter он выпал из десятки лучших. Протокол V4 — Apache 2.0: веса без ограничений, свободное коммерческое использование и одновременная публикация кода для инференса. Это первая флагманская открытая модель за последние полгода, которая одновременно оказала давление на закрытые модели по трем параметрам: производительности, цене и открытости.
Второе — это момент. На фоне непрерывного усиления усилий закрытых команд, открытая модель всё чаще оказывается под давлением. Opus 4.6 поднял SWE-Bench для задач по коду до нового уровня, а GPT-5.5 установил цену в 1,25 доллара за миллион токенов как новую нижнюю планку. Дискуссия о том, сможет ли открытая модель догнать закрытую, длится в Силиконовой долине уже два года. V4, достигнув предварительной оценки в 90 миллионов активных пользователей за месяц, приостановил эту дискуссию.
По словам одного из крупнейших отечественных управляющих фондами на презентации: «До V4 мы применяли дисконт к оценке открытых больших моделей, после V4 этот дисконт начал превращаться в премию».
DeepSeek сменила таблицу ценообразования цепочки поставок вычислительных мощностей
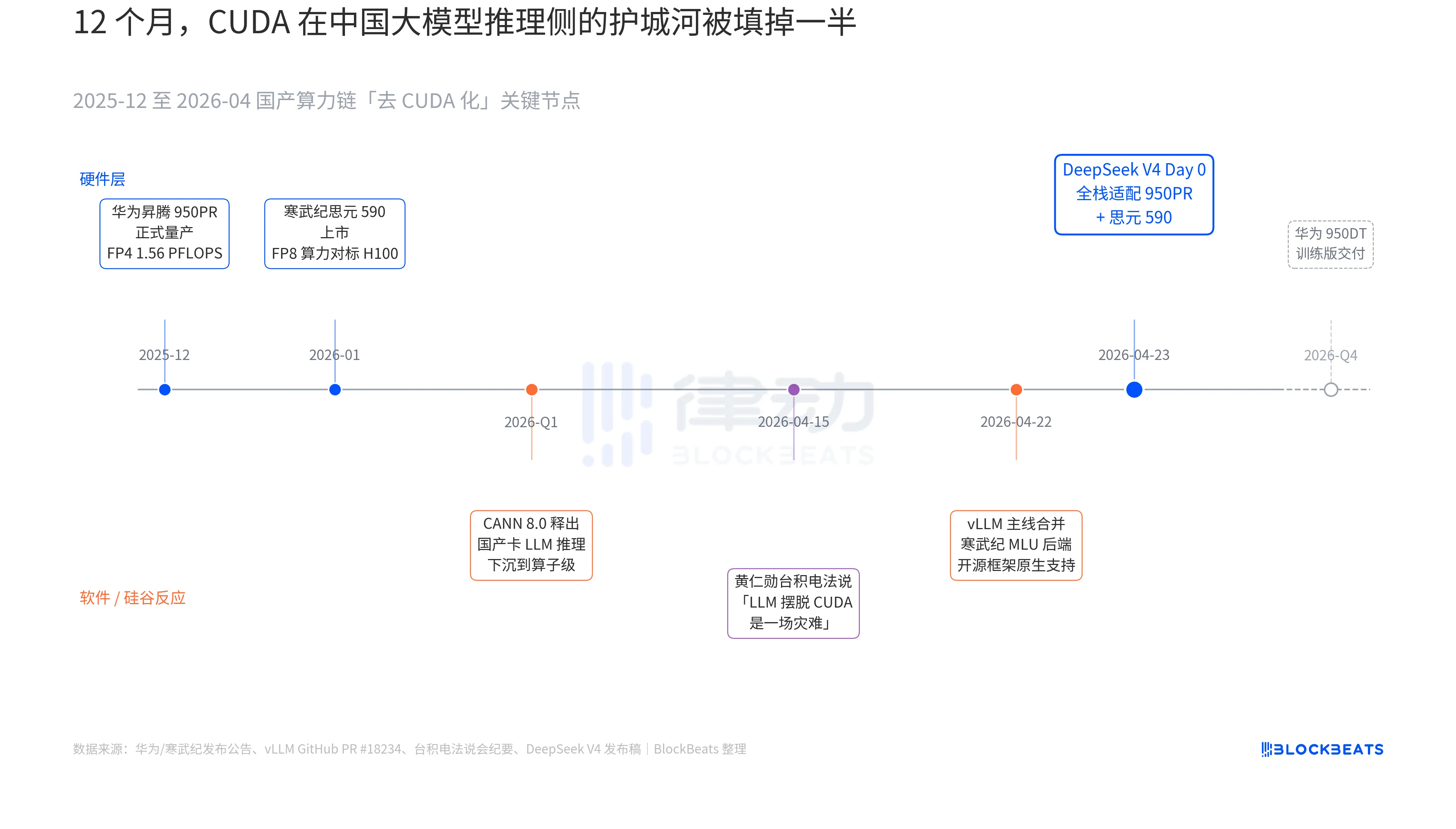
В официальных документах китайских крупных моделей ранее никогда не встречалась такая строка в релизных заметках V4: «На День 0 полностью адаптировано для каменных мифов MLU590 и Huawei Ascend 950PR, код развертывания одновременно открыт». Чтобы понять значение этой строки, нужно соединить три параллельные скрытые линии, развивавшиеся в течение последних 12 месяцев. Эти три линии относятся к аппаратному обеспечению, программному обеспечению и реакции Силиконовой долины.
Первая скрытая линия — на стороне чипа. Чип Huawei Ascend 950PR официально вышел на массовое производство в декабре 2025 года, обеспечивая вычислительную мощность FP4 1,56 PFLOPS и объем HBM 112 ГБ — это первый раз, когда китайский ИИ-чип по ключевым техническим параметрам сопоставим с серией NVIDIA B. При выполнении задач инференса MoE с параметрами 1 Т, пропускная способность одной карты повышается в 2,87 раза по сравнению с H20. Соответствующее программное обеспечение CANN 8.0 оптимизирует фреймворки инференса LLM на уровне операторов; открытые DeepSeek бенчмарки показывают, что конечная задержка инференса V4 на суперузле Ascend (8 карт 950PR) на 35% ниже, чем у кластера H100 аналогичного масштаба. Данные по чипу Cambricon MLU590 еще более агрессивны: вычислительная мощность FP8 на одном чипе сопоставима с H100, а цена — менее половины.
Вторая скрытая линия — на стороне программного обеспечения. 22 апреля vLLM объединил PR с бэкендом MLU от Cambricon, впервые обеспечив нативную поддержку китайских GPU, не являющихся продуктами NVIDIA, в открытой фреймворке для вывода. DCU от Hygon идет другим путем через экосистему ROCm, но способен полностью запустить слой маршрутизации MoE V4. Это означает, что развертывание V4 больше не «возможно только на одной конкретной китайской карте», а «может осуществляться на выбор между несколькими китайскими картами». Зависимость экосистемы от единого поставщика преодолена — это ключевой переломный момент для production.
Третья скрытая нить исходит из Силиконовой долины. 15 апреля Хуан Ренъюнь на отчетной презентации TSMC был допрошен аналитиками о прогрессе китайских собственных вычислительных мощностей; его ответ был холодным и конкретным: «Если они действительно смогут освободить LLM от CUDA, это будет для нас катастрофой (a disaster)». Девять дней спустя DeepSeek дал ответ одним объявлением Day 0.
За последние три года эти четыре слова — «отечественная замена» — были использованы настолько часто, что потеряли смысл. Но после утра 24 апреля впервые появились конкретные данные, которые можно оценить на капитальных рынках: пропускная способность одной карты, задержка конец-в-конец при выводе, стоимость вывода, готовый к коммерческому развертыванию код — тихо и незаметно вывели эту долгую словесную битву за порог производства.
Логика 11-дневного роста акций Cambricon скрыта здесь. Она больше не является просто «акцией китайского GPU», а стала «поставщиком инфраструктуры для вывода DeepSeek V4». Та же логика объясняет 12%-й рост акций Hua Hong на гонконгской бирже — она производит 7-нм эквивалентную технологию для 950PR. Каждый токен V4, запущенный на китайском Ascend, означает, что часть мощностей, которые ранее поступали бы NVIDIA и TSMC, теперь частично остаются в районе реки Жемчужная.
Следующий шаг уже подготовлен. В дорожной карте Huawei планируется поставка 950DT (обучающая версия) в четвертом квартале 2026 года, с целью достижения «полноценного обучения стека на кластере из 10 000 процессоров для модели V5 или эквивалентного уровня». Если этот путь окажется реализуемым, конкурентное преимущество CUDA в области обучения крупных моделей в Китае снизится с «необходимого» до «опционального».
Источник:律动 BlockBeats