










Автор оригинала: KarenZ, Foresight News
20 марта 2026 года в подкасте All-In Ventures состоялся необычный разговор.
Венчурный инвестор Чамат Палихапития передал слово генеральному директору NVIDIA Хуану Ренсюню, сказав, что на Bittensor есть проект, «достигший довольно безумного технического достижения»: с помощью распределенных вычислительных ресурсов в интернете был обучен крупный языковой модель, причем процесс полностью децентрализован и не включает никаких централизованных центров обработки данных.
Хуан Ренсюнь не избегал этого вопроса. Он сравнил это с современной версией Folding@home — распределённым проектом 2000-х годов, который позволял обычным пользователям вносить свой вклад闲置 вычислительной мощностью для совместного решения проблемы складывания белков.
За четыре дня до этого, 16 марта, сооснователь Anthropic Джек Кларк в отчете о прогрессе в области ИИ также подробно описал и цитировал этот прорыв: распределенное обучение крупной модели на 72 миллиарда параметров (Covenant 72B) в подсети экосистемы Bittensor Templar (SN3) достигло производительности, сопоставимой с LLaMA-2, выпущенной Meta в 2023 году.
Джек Кларк назвал этот раздел «Бросок вызова политической экономике ИИ через распределённое обучение» и подчеркнул в своём анализе, что это технология, за которой стоит внимательно следить — он может представить будущее, в котором устройства широко используют модели, обученные децентрализованным способом, в то время как облачные ИИ-системы продолжат работать с проприетарными крупными моделями.
Реакция рынка немного запаздывает, но крайне резкая: SN3 за последний месяц вырос более чем на 440%, за последние две недели — более чем на 340%, рыночная капитализация достигла 130 миллионов долларов США. Всплеск нарратива субсети напрямую передается на покупательское давление на TAO. Поэтому TAO быстро вырос, достигнув максимума в 377 долларов США, удвоившись за последний месяц, а FDV достиг примерно 7,5 миллиарда долларов США.
Возникает вопрос: что именно сделал SN3? Почему он оказался в центре внимания? Как будет развиваться повествование о ценности распределённого обучения и децентрализованного ИИ?
Та модель с 72 млрд параметров
Чтобы ответить на этот вопрос, нужно внимательно оценить результаты SN3.
10 марта 2026 года команда Covenant AI опубликовала технический отчет на arXiv, официально объявив о завершении обучения Covenant-72B. Это языковая модель с 72 миллиардами параметров, которая была предварительно обучена на корпусе из примерно 1,1 триллиона токенов с использованием более чем 70 независимых узлов (около 20 узлов синхронизируются за цикл, каждый узел оснащен 8 GPU B200).
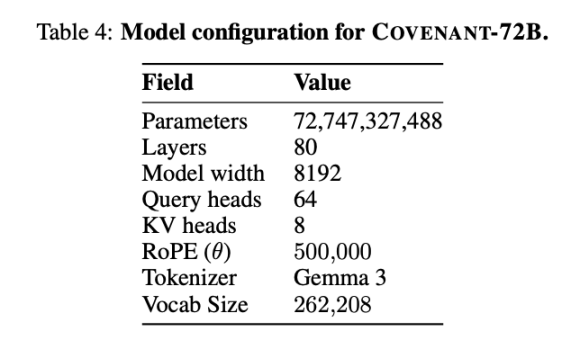
Templar предоставил некоторые данные по результатам тестирования, при этом в качестве сравнения использовалась модель LLaMA-2-70B, выпущенная Meta в 2023 году. Как отметил сооснователь Anthropic Джек Кларк, Covenant-72B к 2026 году может оказаться устаревшей. Результат Covenant-72B в MMLU — 67,1 балла — примерно соответствует результату LLaMA-2-70B, выпущенной Meta в 2023 году (65,6 балла).
А передовые модели 2026 года — будь то серия GPT, Claude или Gemini — уже прошли обучение на сотнях тысяч GPU с параметрами, значительно превышающими 100 миллиардов; разрыв в способностях к выводу, кодированию и математике — это вопрос порядка величины, а не процентов. Эту реальную разницу не следует затмевать рыночными настроениями.
Но при условии «обучения с использованием распределённых вычислительных мощностей открытого интернета» смысл становится совершенно другим.
Сравните: INTELLECT-1 (от команды Prime Intellect, 10 миллиардов параметров), обученный децентрализованно, показал результат MMLU 32,7; другой проект с распределённым обучением среди участников из белого списка — Psyche Consilience (40 миллиардов параметров) — набрал 24,2. Covenant-72B с масштабом 72 млрд параметров и результатом MMLU 67,1 — выдающийся показатель в сегменте децентрализованного обучения.
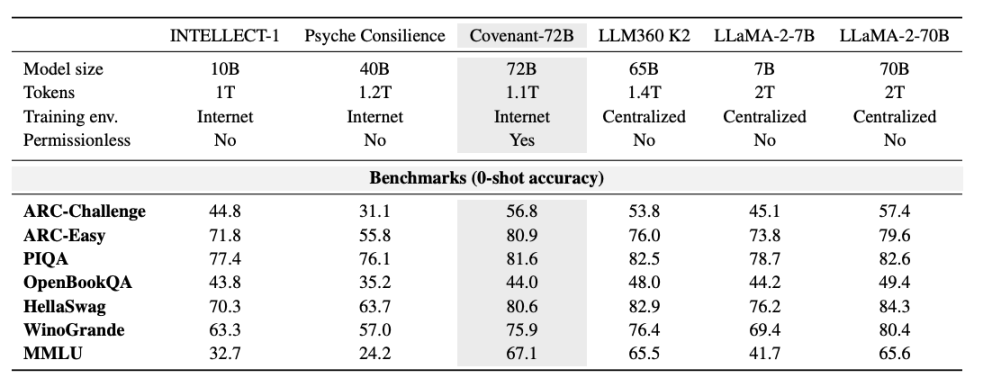
Более важно, что это обучение является «без разрешения». Любой может подключиться и стать участвующим узлом без предварительного одобрения или наличия в белом списке. Более 70 независимых узлов приняли участие в обновлении модели, подключаясь со всего мира и внося свой вклад в вычислительные мощности.
Что сказал Хуан Ренсюнь, а что не сказал
Восстановление деталей того подкаст-диалога поможет скорректировать внешнее понимание этого «одобрения».
Чамат Палихапития представил технические достижения Bittensor в беседе с Хуаном Ренсюнем, описав их как обучение модели Llama с использованием распределенных вычислительных ресурсов, при этом процесс был «полностью распределенным и сохранял состояние». Ответ Хуана Ренсюня заключался в сравнении этого с «современной версией Folding@home», после чего он подробно обсудил необходимость параллельного сосуществования открытых и проприетарных моделей.
Стоит отметить, что Хуан Ренсюнь не упомянул напрямую токен Bittensor или какие-либо инвестиционные аспекты, а также не стал подробно обсуждать децентрализованное обучение ИИ.
Понимание подсетей Bittensor и SN3
Чтобы понять прорыв SN3, сначала необходимо разобраться в логике работы Bittensor и его субсетей. Проще говоря, Bittensor можно рассматривать как блокчейн и платформу для ИИ, а каждая субсеть — как отдельная «линия по производству ИИ» со своей четко определенной задачей и системой стимулов, совместно формируя децентрализованную экосистему ИИ.
Его рабочий процесс прозрачен и децентрализован: владельцы подсетей определяют цели подсети и разрабатывают модель стимулирования; майнеры предоставляют вычислительную мощность в подсети и выполняют задачи, связанные с ИИ (такие как вывод, обучение, хранение и т.д.); валидаторы оценивают вклад майнеров и загружают оценки в консенсусный уровень Bittensor; в конечном итоге алгоритм консенсуса Yuma Bittensor распределяет соответствующие вознаграждения участникам подсети на основе накопленных наград в каждой подсети.
На Bittensor сейчас существует 128 подсетей, охватывающих различные задачи ИИ, такие как вывод, серверные AI-облачные сервисы, изображения, аннотирование данных, усиленное обучение, хранение и вычисления.
SN3 — это одна из таких подсетей. Она не создает оболочку на уровне приложений и не арендует готовые API крупных моделей, а напрямую нацелена на одну из самых дорогих и закрытых составляющих всей цепочки ИИ — предварительное обучение крупных моделей.
SN3 стремится использовать сеть Bittensor для координации распределенного обучения с использованием гетерогенных вычислительных ресурсов, доказывая, что с помощью стимулируемого распределенного обучения крупных моделей можно обучать мощные базовые модели без дорогостоящих централизованных суперкомпьютерных кластеров. Основное преимущество заключается в «равенстве» — преодолении монополии централизованного обучения на ресурсы, позволяя обычным лицам или небольшим организациям участвовать в обучении крупных моделей и одновременно снижая стоимость обучения за счет распределенных вычислительных мощностей.
Основной движущей силой развития SN3 является Templar, за которым стоит исследовательская команда Covenant Labs. Эта команда также управляет двумя другими подсетями: Basilica (SN39, ориентирована на вычислительные услуги) и Grail (SN81, ориентирована на пост-обучение RL и оценку моделей). Три подсети образуют вертикально интегрированную систему, охватывающую весь цикл от предварительного обучения до оптимизации согласования крупных моделей, создавая полную экосистему децентрализованного обучения крупных моделей.
В частности, майнеры предоставляют вычислительные ресурсы и загружают в сеть обновления градиентов (направление и интенсивность корректировки параметров модели); валидаторы оценивают качество вклада каждого майнера и присваивают им оценки в цепочке на основе степени улучшения ошибки. Результаты определяют вес вознаграждения, который автоматически распределяется без необходимости доверять каким-либо третьим сторонам.
Ключ к дизайну стимулирующей системы заключается в том, что вознаграждение напрямую связано с тем, «насколько ваш вклад улучшил модель», а не просто с вычислительной мощностью. Это фундаментально решает самую сложную проблему в децентрализованных сценариях: как предотвратить лень майнеров.
Как Covenant-72B решает проблемы эффективности связи и совместимости стимулов?
Согласованное обучение одной и той же модели десятками узлов, не доверяющих друг другу, с разным оборудованием и различным качеством сети, представляет две проблемы: во-первых, эффективность связи — стандартные схемы распределенного обучения требуют высокой пропускной способности и низкой задержки между узлами; во-вторых, совместимость стимулов — как предотвратить отправку злонамеренными узлами неверных градиентов? Как обеспечить, чтобы каждый участник действительно обучал модель, а не копировал результаты других?
SN3 решает эти две проблемы с помощью двух ключевых компонентов: SparseLoCo и Gauntlet.
SparseLoCo решает проблему эффективности связи. В традиционных распределенных тренировках на каждом шаге происходит синхронизация полных градиентов, что требует огромного объема данных. SparseLoCo использует подход, при котором каждый узел выполняет 30 внутренних шагов оптимизации (AdamW) локально, а затем сжимает и отправляет другим узлам сгенерированные «псевдоградиенты». Методы сжатия включают Top-k разреживание (сохранение только наиболее важных компонентов градиента), обратную связь по ошибке (сохранение отброшенных частей для накопления в следующем цикле) и 2-битное квантование. Итоговый коэффициент сжатия превышает 146 раз.
Другими словами, вместо передачи 100 МБ теперь достаточно менее 1 МБ.
Это позволяет системе поддерживать использование вычислительных ресурсов на уровне около 94,5% при ограничениях пропускной способности обычного интернета (восходящая 110 Мбит/с, нисходящая 500 Мбит/с) — 20 узлов, по 8 B200 на узел, время передачи данных за цикл составляет всего 70 секунд.
Gauntlet решает проблему стимулирования. Он работает на блокчейне Bittensor (Subnet 3) и отвечает за проверку качества псевдоградиентов, отправляемых каждым узлом. Конкретный метод заключается в тестировании небольшой выборкой данных: «насколько снизилась потеря модели после применения градиента этого узла» — результат называется LossScore. Кроме того, система проверяет, использует ли узел именно выделенные ему данные для обучения: если узел показывает лучшее улучшение потерь на случайных данных, чем на своих выделенных данных, он получает отрицательный балл.
В конце каждой итерации в агрегации участвуют только градиенты узлов с наивысшей оценкой, остальные узлы исключаются из этой итерации. Превышающие участники заменяются в реальном времени, обеспечивая устойчивость системы. В течение всего процесса обучения в среднем в каждой итерации в агрегацию включаются градиенты 16,9 узлов, а общее количество уникальных идентификаторов узлов, участвовавших хотя бы раз, превышает 70.
Ценность децентрализованного ИИ претерпевает фундаментальные изменения
С точки зрения технологии и отрасли, направление, представленное Covenant-72B, имеет несколько реальных значений.
Во-первых, разрушено предположение, что распределённое обучение подходит только для небольших моделей. Несмотря на то, что пока ещё далеко от передовых моделей, это подтверждает масштабируемость данного направления.
Во-вторых, участие без разрешения реально и осуществимо. Этот аспект недооценивается. Ранее проекты распределенного обучения зависели от белых списков — только одобренные участники могли вносить вычислительную мощность. В этой тренировке SN3 любой, кто обладает достаточной вычислительной мощностью, может подключиться, а механизм проверки отфильтровывает вредоносные вклады. Это конкретный шаг к «настоящему децентрализованному» подходу.
В-третьих, механизм dTAO Bittensor позволяет рыночному определению стоимости подсетей. dTAO позволяет каждой подсети выпускать собственные токены Alpha, позволяя рынку с помощью механизма AMM определять, какие подсети получат больше эмиссии TAO. Это предоставляет подсетям, таким как SN3, которые достигли конкретных результатов, грубый, но эффективный механизм захвата стоимости. Конечно, этот механизм также подвержен влиянию нарративов и эмоций, поскольку качество результатов обучения LLM трудно оценить независимо обычным участникам рынка.
Четвертое, политические и экономические последствия децентрализованного обучения ИИ. Джек Кларк в Import AI поднял этот вопрос до уровня «Кто владеет будущим ИИ?». В настоящее время обучение передовых моделей монополизировано небольшим числом организаций, обладающих крупными центрами обработки данных, что является не только коммерческой, но и проблемой структуры власти. Если распределенное обучение сможет продолжать достигать технологических успехов, оно может сформировать по-настоящему децентрализованную экосистему разработки для некоторых типов моделей (например, небольших передовых моделей в узких областях). Конечно, эта перспектива пока далека.
Итог: настоящий этап, а также множество реальных проблем
Хуан Ренсюнь сказал, что это похоже на «современную версию Folding@home». Folding@home внес реальный вклад в область молекулярного моделирования, но не угрожал основной исследовательской деятельности крупных фармацевтических компаний. Эта аналогия очень точна.
SN3 успешно реализовал протокол и подтвердил перспективное направление распределённого обучения. Однако с технической и отраслевой точек зрения за этими результатами скрываются множество проблем, о которых мало кто готов серьёзно говорить:
MMLU сам по себе является спорным показателем в академической среде, поскольку вопросы и ответы открытых эталонов подвержены риску утечки в обучающие наборы. Ещё более важным является выбор базовых моделей для сравнения: модели LLaMA-2-70B и LLM360 K2, с которыми сравнивается статья, являются устаревшими версиями 2023–2024 годов, тогда как результаты в диапазоне 65–70 баллов в тот же период считаются средними или начальным уровнем при сравнении с Grok и DouBao, а по оценке Claude — серьёзным отставанием. Если поместить их в динамически обновляемые рейтинги или на новые эталоны с защитой от загрязнения, выводы могут оказаться более честными.
Более важно то, что высококачественные данные, определяющие предел возможностей моделей — диалоги, код, математические выводы, научные публикации — скорее всего находятся в руках крупных компаний, издательств и академических баз данных. Вычислительные мощности демократизировались, но в сегменте данных сохраняется олигополистическая структура — этот противоречие никогда не обсуждалось.
Что касается безопасности, то участие без разрешения означает, что вы не знаете, кто стоит за этими более чем 70 узлами, и какими данными они обучают. Gauntlet может фильтровать очевидно аномальные градиенты, но не способен предотвратить тонкое отравление данных — если один из узлов систематически обучается несколькими дополнительными циклами на определённых вредоносных типах контента, изменения градиентов могут быть достаточно тонкими, чтобы пройти проверку по оценке потерь, но вызвать накопительное смещение в поведении модели. В конечном счёте возникает вопрос: каковы риски использования модели, обученной с участием небольшого числа анонимных узлов и с неполной прослеживаемостью источников данных, в таких высоко регулируемых и требовательных к безопасности областях, как финансы, здравоохранение и право?
Есть еще одна структурная проблема, которую стоит обозначить прямо: Covenant-72B сам по себе является открытым исходным кодом по лицензии Apache 2.0 и не использует токены SN3. Владение токенами SN3 дает право на долю в доходах от эмиссии, генерируемых в будущем за счет постоянного выпуска новых моделей этим субсетом, но не обеспечивает никакого прямого дохода от использования самой модели. Эта цепочка создания стоимости зависит от постоянного обучения и устойчивой работы общей механизмы эмиссии сети Bittensor. Если в будущем обучение остановится или качество новых результатов обучения не будет соответствовать ожиданиям, логика оценки токенов будет подорвана.
Перечисление этих вопросов не направлено на отрицание значения Covenant-72B. То, что он доказал возможность того, что раньше считалось невозможным, не исчезнет. Но то, что это сделано, и то, что это означает — это две разные вещи.
Токен SN3 вырос на 440% за последний месяц. Эта разница, возможно, не просто спекуляция, а скорость повествования всегда опережает скорость реальности. То, будет ли этот разрыв в конечном итоге заполнен реальностью или поглощен рынком, зависит от того, что действительно представит команда Covenant AI в ближайшее время.
Стоит отметить, что Grayscale подала заявку на ETF TAO в январе 2026 года, что указывает на сигнал входа институционального капитала в этот сегмент. Кроме того, в декабре 2025 года Bittensor сократил ежедневную эмиссию TAO вдвое, и структурное сокращение предложения продолжает развиваться.
Ссылка для справки:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95