










Эта точка зрения не возникла из ниоткуда. Он изучил множество открытых тестов и обнаружил, что ИИ быстро прогрессирует в задачах, связанных с разработкой ИИ.
Например, CORE-Bench оценивает способность ИИ реализовывать исследования других по их научным статьям, что является важнейшим аспектом в исследовании ИИ.
PostTrainBench проверяет, могут ли мощные модели самостоятельно дообучать более слабые открытые модели для повышения их производительности — это ключевая подзадача в AI-исследованиях.
MLE-Bench основан на реальных задачах соревнований Kaggle и требует создания разнообразных приложений машинного обучения для решения конкретных проблем. Кроме того, такие известные кодировочные бенчмарки, как SWE-Bench, также демонстрируют аналогичный прогресс.
Джек Кларк описал это явление как «фрактальный» восходящий правый тренд, при котором на разных разрешениях и масштабах можно наблюдать значимый прогресс. Он считает, что ИИ постепенно приближается к способности к энд-ту-энд автоматизированной разработке, и как только это будет достигнуто, ИИ сможет самостоятельно создавать свои собственные последующие системы, запуская цикл саморазвития.

После этого заявления в социальных сетях разгорелась активная дискуссия.
Некоторые считают это ключевым первым шагом к достижению АСИ и точки невозврата, что может полностью изменить темпы развития технологий.

Однако существуют и другие мнения.
Профессор компьютерных наук Вашингтонского университета Педро Домингос отмечает, что ИИ-системы обладали способностью «создавать себя» еще с момента изобретения языка LISP в 1950-х годах; настоящая проблема заключается в том, можно ли получить прирост отдачи, однако на данный момент нет явных доказательств этого.

Некоторые пользователи выражают сомнение: почему вероятность резко возрастает на 30% с 2027 по 2028 год? Это намекает на то, что способности ИИ могут претерпеть внезапный значительный прорыв примерно в конце 2027 года. Какая именно веха или событие может привести к резкому росту вероятности рекурсивного самоулучшения ИИ в краткосрочной перспективе?

Другие пользователи сети отметили, что Джек Кларк — новый руководитель по связям с общественностью Anthropic, и это часть их новой стратегии: мы не пугаем вас напрасно — множество научных статей подтверждают то, о чем мы предупреждали вас все это время.
Джек Кларк подробно описал это в длинной статье в выпускном номере Import AI 455.
Далее мы полностью рассмотрим эту статью.
Система ИИ вот-вот начнет самоформирование — что это значит?
Кларк заявил, что написал эту статью, потому что, проанализировав всю доступную публичную информацию, он был вынужден сделать не слишком обнадеживающий вывод: вероятность появления ИИ-исследований без участия человека до конца 2028 года уже достаточно высока, возможно, превышает 60%.
Под так называемой разработкой ИИ без участия человека подразумевается достаточно мощная ИИ-система: она не только может помогать людям в проведении исследований, но и потенциально способна самостоятельно завершать ключевые этапы разработки, а даже создавать свою собственную следующую версию.
По мнению Кларка, это явно крупное событие.
Он признал, что саму трудно полностью осознать значение этого события.
Это называется нежелательным суждением, потому что последствия, стоящие за ним, слишком велики, и он чувствует, что не может их полностью осознать. Кларк также не уверен, готово ли общество в целом к глубоким изменениям, вызванным автоматизацией разработки ИИ.
Он теперь считает, что человечество может находиться в особый момент времени: исследования в области ИИ вот-вот будут полностью автоматизированы. Если этот момент действительно наступит, человечество пересечет Рубикон и войдет в будущее, которое почти невозможно предсказать.
Кларк заявил, что цель этой статьи — объяснить, почему он считает, что взлет к полностью автоматизированному ИИ-исследованию уже происходит.
Он обсудит некоторые возможные последствия этой тенденции, но большая часть статьи будет посвящена доказательствам, поддерживающим этот вывод. Что касается более глубоких последствий, Кларк планирует продолжить их анализ в течение большей части этого года.
С точки зрения временных рамок, Кларк не считает, что это произойдет в 2026 году. Однако он полагает, что в ближайшие один-два года мы можем увидеть примеры, когда модель обучается энд-то-энд для создания собственного преемника. По крайней мере, на уровне не передовых моделей появление концепции доказательства вполне возможно; для самых передовых моделей сложность будет выше, поскольку они чрезвычайно дороги и зависят от интенсивной работы большого числа человеческих исследователей.
Суждения Кларка основаны в основном на открытой информации: статьях на arXiv, bioRxiv и NBER, а также продуктах, уже внедренных передовыми ИИ-компаниями в реальный мир. На основе этой информации он приходит к выводу, что автоматизация всех этапов производства, необходимых для текущих ИИ-систем, особенно инженерных компонентов в разработке ИИ, в основном уже реализована.
Если тенденция масштабирования продолжится, нам следует начать готовиться к ситуации, когда модели станут достаточно творческими, чтобы не только автоматически улучшать известные методы, но и заменять человеческих исследователей в формулировании новых направлений исследований и оригинальных идей, тем самым самостоятельно продвигая передовые достижения ИИ.
Coding Singularity: How Abilities Change Over Time
Искусственный интеллект — это система, реализованная через программное обеспечение, которое состоит из кода.
Искусственный интеллект полностью изменил способ создания кода. За этим стоят две связанные тенденции: во-первых, системы ИИ становятся все более способными писать сложный код для реальных задач; во-вторых, они все лучше справляются с последовательным выполнением множества линейных задач программирования почти без человеческого контроля, например, сначала написав код, а затем протестировав его.
Два типичных примера, иллюстрирующих эту тенденцию, — это SWE-Bench и METR time horizons plot.
Решение реальных проблем программной инженерии
SWE-Bench — это широко используемый программный тест для оценки способности ИИ-систем решать реальные проблемы GitHub.
Когда SWE-Bench был запущен в конце 2023 года, лучшей моделью на тот момент был Claude 2, общий процент успеха составлял около 2%. Модель Claude Mythos Preview достигла результата 93,9%, практически полностью пройдя этот бенчмарк.
Конечно, сами бенчмарки всегда содержат некоторый уровень шума, поэтому часто возникает этап, когда после достижения определённого уровня оценки вы сталкиваетесь не с ограничениями самого метода, а с ограничениями самого бенчмарка. Например, в валидационном наборе ImageNet примерно 6% меток являются ошибочными или неоднозначными.
SWE-Bench можно рассматривать как надежный показатель общих программных навыков и влияния ИИ на программную инженерию. Кларк отметил, что большинство людей, с которыми он общался в передовых лабораториях ИИ и в Силиконовой долине, теперь практически полностью пишут код с помощью ИИ-систем, и все больше людей начинают использовать ИИ-системы для написания тестов и проверки кода.
Другими словами, системы ИИ стали достаточно мощными, чтобы автоматизировать важную составляющую исследований в области ИИ и значительно ускорить работу всех человеческих исследователей и инженеров, участвующих в разработке ИИ.
Оценка способности ИИ-систем выполнять длительные задачи
METR создал график для измерения сложности задач, которые может выполнить ИИ. Сложность здесь рассчитывается по количеству часов, которые опытному человеку потребуется на выполнение этих задач.
Самым важным показателем является примерный временной диапазон задач, при котором ИИ-система достигает 50% надежности на наборе задач.
На этом этапе прогресс невероятен:
В 2022 году задачи, которые мог выполнять GPT-3.5, примерно соответствовали задачам, которые человек выполняет за 30 секунд.
· В 2023 году GPT-4 повысил это время до 4 минут.
· В 2024 году o1 повысил это время до 40 минут.
· В 2025 году GPT-5.2 High достиг примерно 6 часов.
· К 2026 году Opus 4.6 уже продвинул это время еще дальше — до примерно 12 часов.
Аджея Котра, которая работает в METR и долгое время изучает прогнозирование ИИ, считает, что ожидание того, что к концу 2026 года системы ИИ смогут выполнять задачи, эквивалентные 100 часам человеческого труда, не является неразумным.
Время, в течение которого ИИ-системы могут работать самостоятельно, значительно увеличилось, что также тесно связано с взрывным ростом инструментов агентного кодирования. Инструменты агентного кодирования по сути представляют собой продуктизацию ИИ-систем, способных выполнять задачи вместо человека: они могут действовать от имени человека и относительно независимо продвигать задачи в течение длительного периода времени.
Это также возвращает фокус к самой разработке ИИ. При внимательном рассмотрении повседневной работы многих исследователей ИИ становится очевидно, что множество их задач можно разбить на задачи, занимающие несколько часов, такие как очистка данных, чтение данных, запуск экспериментов и т.д.
А такая работа сегодня уже попадает в временной диапазон, который могут охватывать современные ИИ-системы.
Чем более опытной становится ИИ-система, тем больше она может работать независимо от человека и тем больше помогает автоматизировать часть работы по разработке ИИ.
Основными факторами поручения задачи являются два:
· Во-первых, ваша уверенность в способностях доверенного лица;
· Во-вторых, вы верите, что другой человек сможет независимо выполнить работу в соответствии с вашими намерениями без постоянного контроля с вашей стороны.
Когда пользователи наблюдают за способностями ИИ в программировании, они замечают, что ИИ-системы становятся не только все более искусными, но и способны работать самостоятельно дольше, не требуя повторной настройки человеком.
Это также соответствует тому, что происходит вокруг нас: инженеры и исследователи передают все более крупные объемы задач AI-системам. По мере постоянного улучшения возможностей ИИ задачи, поручаемые ИИ, становятся все более сложными и важными.
ИИ осваивает ключевые научные навыки, необходимые для разработки ИИ
Подумайте, как проводятся современные научные исследования: большая часть работы состоит в том, чтобы сначала определить направление и понять, какой тип эмпирической информации вы хотите получить; затем спроектировать и провести эксперимент, чтобы сгенерировать эту информацию; и, наконец, проверить результаты эксперимента на предмет обоснованности.
С ростом способностей ИИ к программированию и усилением способности крупных языковых моделей к моделированию мира, сегодня появился ряд инструментов, которые помогают человеческим ученым ускорить процесс и частично автоматизировать некоторые этапы в более широких исследовательских сценариях.
Здесь мы можем наблюдать, как быстро ИИ развивается в нескольких ключевых научных навыках, которые сами по себе являются неотъемлемой частью исследований в области ИИ:
· Во-первых, воспроизвести результаты исследования;
· Во-вторых, объединить технологии машинного обучения с другими методами для решения технических задач;
· Третье — оптимизация самой системы ИИ.
Реализовать всю научную статью и провести соответствующие эксперименты
Одной из ключевых задач в области исследований ИИ является чтение научных статей и воспроизведение их результатов. В этой области ИИ уже достиг значительного прогресса на ряде тестовых наборов.
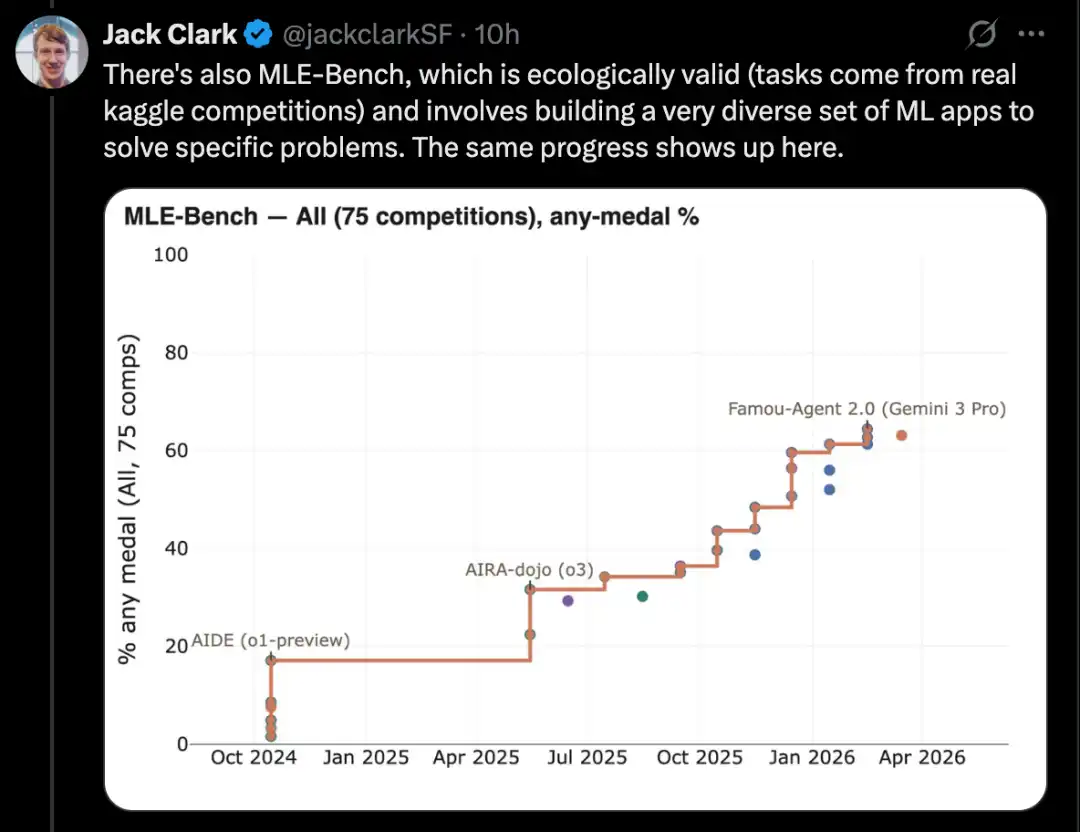
Хорошим примером является CORE-Bench, то есть Computational Reproducibility Agent Benchmark.
Этот бенчмарк требует от ИИ-системы воспроизвести результаты статьи при наличии самой статьи и её репозитория с кодом. Конкретно, агент должен установить соответствующие библиотеки, пакеты и зависимости, запустить код; если код успешно выполняется, он также должен найти все выходные данные и ответить на вопросы, поставленные в задании.
CORE-Bench был предложен в сентябре 2024 года. На тот момент лучшей системой была модель GPT-4o, работающая на платформе CORE-Agent. На наиболее сложной группе задач этого бенчмарка она показала результат около 21,5%.
В декабре 2025 года один из авторов CORE-Bench объявил, что этот бенчмарк был решён: модель Opus 4.5 показала результат 95,5%.
Создание полной системы машинного обучения для решения задач соревнований Kaggle
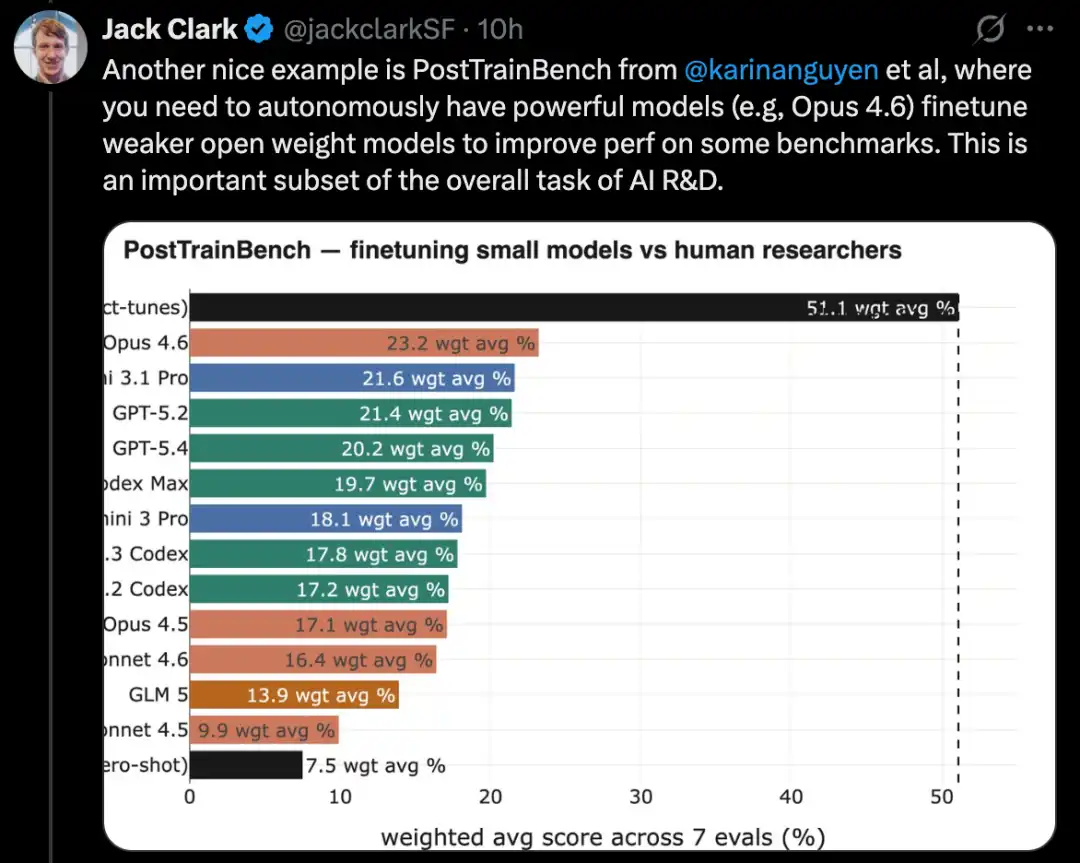
MLE-Bench — это бенчмарк, созданный OpenAI, для тестирования способности ИИ-систем участвовать в соревнованиях Kaggle в оффлайн-среде.
Он охватывает 75 различных типов соревнований Kaggle, охватывающих несколько областей, включая обработку естественного языка, компьютерное зрение и обработку сигналов.
MLE-Bench был выпущен в октябре 2024 года. На момент выпуска лучшая система была моделью o1, работающей в agent scaffold, с результатом 16,9%.
По состоянию на февраль 2026 года лучшей системой стала Gemini 3, работающая в агентной среде с функцией поиска, показавшая результат 64,4%.
Дизайн Kernel
Одной из более сложных задач в разработке ИИ является оптимизация ядра. Под оптимизацией ядра понимается написание и улучшение низкоуровневого кода для более эффективного сопоставления таких специфических операций, как умножение матриц, с аппаратным обеспечением.
Оптимизация ядра является ключевой в разработке ИИ, поскольку она определяет эффективность обучения и вывода: с одной стороны, она влияет на то, насколько эффективно вы можете использовать вычислительные ресурсы при разработке систем ИИ; с другой стороны, после завершения обучения модели она определяет, насколько эффективно вы сможете преобразовать вычислительные ресурсы в мощность вывода.
В последние годы использование ИИ для проектирования ядер превратилось из интересного небольшого направления в конкурентную исследовательскую область, и появилось несколько бенчмарков. Однако эти бенчмарки пока не стали особенно популярными, поэтому нам сложно четко смоделировать его долгосрочный прогресс, как это делается в других областях. С другой стороны, мы можем ощутить темпы продвижения этого направления через некоторые текущие исследования.
Соответствующая работа включает:
· Попробуйте использовать модель DeepSeek для создания более эффективных GPU-ядер;
· Автоматически преобразует модули PyTorch в код CUDA;
· Meta использует LLM для автоматической генерации оптимизированных Triton-ядер и развертывает их в своей инфраструктуре;
· А также тонкая настройка моделей с открытыми весами для GPU-ядер, например, Cuda Agent.
Следует добавить: архитектура ядра действительно обладает некоторыми особенностями, идеально подходящими для разработки, управляемой ИИ, например, легкость проверки результатов и четкие сигналы вознаграждения.
Fine-tune language models via PostTrainBench
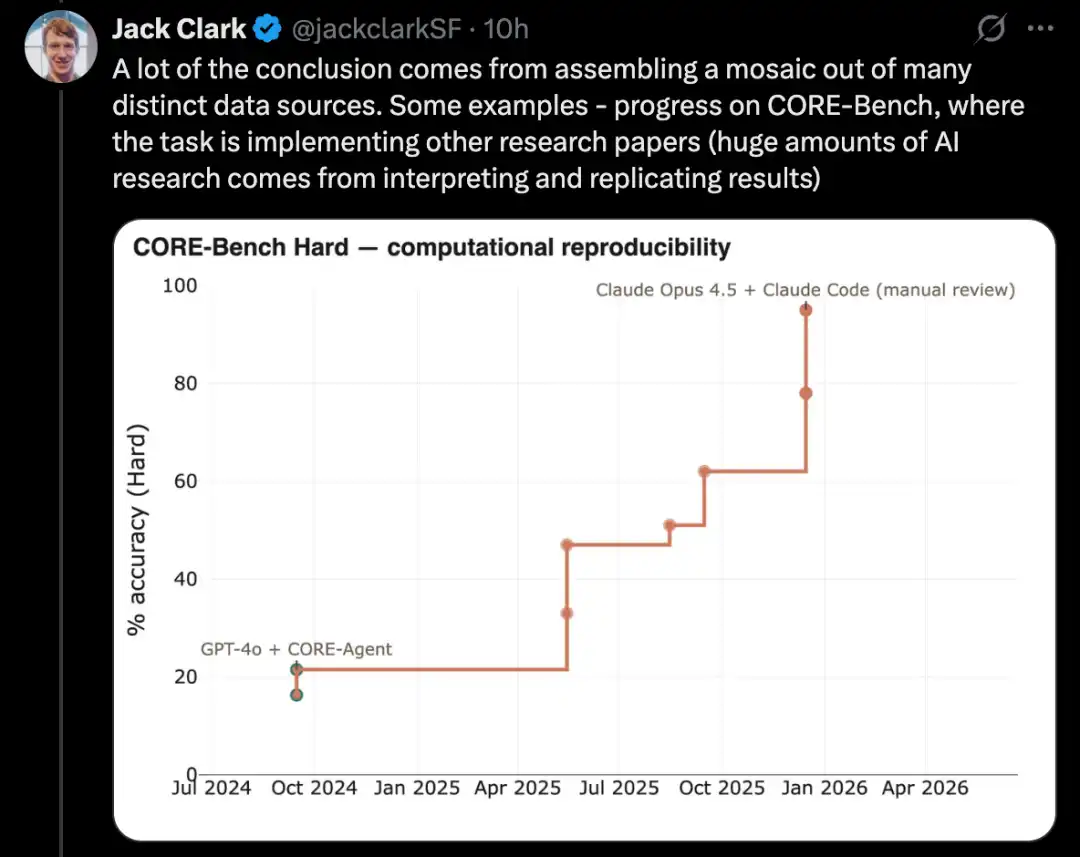
Более сложной версией такого теста является PostTrainBench. Он проверяет, могут ли различные передовые модели взять на себя небольшие открытые весовые модели и улучшить их производительность на некоторых бенчмарках с помощью тонкой настройки.
Одним из преимуществ этого бенчмарка является его очень сильная человеческая базовая линия: существующие инструкционно-настроенные версии этих небольших моделей. Эти версии обычно разрабатываются выдающимися человеческими исследователями ИИ в передовых лабораториях, тщательно дорабатываются опытными исследователями и инженерами и уже внедрены в реальных условиях. Следовательно, они представляют собой труднодостижимую человеческую эталонную точку.
По состоянию на март 2026 года AI-системы уже могут проводить пост-обучение моделей и достигать повышения производительности, примерно равного половине улучшений, получаемых при человеческом обучении.
Конкретные оценки рассчитываются как взвешенное среднее: они учитывают результаты нескольких крупных языковых моделей после дообучения, включая Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, а также несколько наборов данных, включая AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval.
В каждом запуске оценщик требует CLI-агента, который максимально улучшает производительность определенной базовой модели на определенном бенчмарке.
По состоянию на апрель 2026 года наивысший результат среди AI-систем составил около 25–28%, включая модели Opus 4.6 и GPT 5.4; в сравнении с этим результат людей составляет 51%.
Это уже довольно значимый результат.
Оптимизация обучения языковых моделей
В течение последнего года Anthropic сообщала о производительности своей системы при выполнении задачи обучения ИЯМ. Эта задача требовала от модели оптимизации небольшой реализации обучения языковой модели, использующей только CPU, чтобы она работала как можно быстрее.
Метод оценки: среднее ускорение, достигнутое моделью, по сравнению с исходным кодом без изменений.
Этот результат демонстрирует значительный прогресс:
· В мае 2025 года Claude Opus 4 обеспечил среднее ускорение в 2,9 раза;
· В ноябре 2025 года Opus 4.5 увеличился до 16,5 раза;
· В феврале 2026 года Opus 4.6 достиг 30-кратного роста;
· В апреле 2026 года Claude Mythos Preview достиг 52-кратного роста.
Для понимания смысла этих цифр можно привести сравнение: для человеческих исследователей выполнение этой задачи обычно занимает от 4 до 8 часов работы, что обеспечивает ускорение в 4 раза.
Базовый навык: управление
Искусственные интеллектуальные системы также учатся управлять другими искусственными интеллектуальными системами.
Это уже можно увидеть в некоторых широко используемых продуктах, таких как Claude Code или OpenCode. В этих продуктах основной агент может контролировать несколько подагентов.
Это позволяет AI-системам обрабатывать проекты большего масштаба: в проектах может потребоваться параллельная работа нескольких агентов с различными специализациями, которые обычно координируются одним единственным AI-менеджером. Сам менеджер также является AI-системой.
Исследования в области ИИ больше похожи на открытие общей теории относительности или на сборку конструктора Лего?
Одна из ключевых проблем: может ли ИИ изобретать новые идеи, которые помогут ему улучшить себя? Или же эти системы лучше подходят для выполнения менее ярких, но необходимых пошаговых задач в исследованиях?
Этот вопрос важен, потому что он определяет, насколько сильно AI-системы могут автоматизировать саму AI-исследовательскую деятельность в режиме end-to-end.
Автор считает, что ИИ пока не способен генерировать по-настоящему революционные новые идеи. Однако для достижения автоматизации собственных исследований ему, возможно, это и не обязательно.
Как область, прогресс в ИИ во многом зависит от все более крупных экспериментов и все большего количества входных данных, таких как данные и вычислительные мощности.
Иногда люди предлагают идеи, меняющие парадигму, которые значительно повышают эффективность использования ресурсов во всей области. Архитектура Transformer — отличный пример, а модели смешанных экспертов, или mixture-of-experts, — еще один пример.
Но чаще всего продвижение в области ИИ происходит более просто: люди берут хорошо работающую систему, увеличивают какой-либо аспект, например, объем обучающих данных и вычислительные мощности; наблюдают, где возникают проблемы после масштабирования; находят инженерные решения для устранения этих проблем, чтобы система могла продолжать масштабироваться; затем снова увеличивают масштаб.
В этом процессе действительно требуется лишь небольшое количество проницательности. Большая часть работы — это скорее менее заметная, но очень надежная базовая инженерия.
Аналогично, многие исследования в области ИИ на самом деле заключаются в запуске различных вариаций существующих экспериментов для изучения того, какие результаты дают разные параметры. Хотя интуиция исследователей может помочь человеку выбрать наиболее перспективные параметры для тестирования, этот процесс также можно автоматизировать, позволив ИИ самому определять, какие параметры стоит настроить. Ранние методы поиска нейронных архитектур — это одна из версий такого подхода.
Эдисон сказал: «Гений — это 1% вдохновения и 99% пота». Даже спустя 150 лет это утверждение остается актуальным.
Иногда действительно появляются новые идеи, кардинально меняющие целую область. Но чаще прогресс в области достигается благодаря упорному труду людей, постепенно улучшая и отлаживая различные системы.
А ранее упомянутые открытые данные показывают, что ИИ уже отлично справляется со многими необходимыми, но трудоемкими задачами в разработке ИИ.
В то же время наблюдается более масштабная тенденция: базовые навыки, такие как программирование, объединяются с постоянно расширяющимся временным диапазоном задач. Это означает, что ИИ-системы могут все больше соединять такие задачи в сложные рабочие последовательности.
Таким образом, даже если в настоящее время ИИ-системы относительно лишены креативности, есть основания полагать, что они все еще способны продвигать себя вперед. Однако скорость этого продвижения может быть ниже, чем в случае, когда возникают совершенно новые идеи.
Однако, если продолжать анализировать открытые данные, можно заметить еще один любопытный сигнал: ИИ-системы, возможно, начинают проявлять определенную креативность, которая может позволить им продвигать свое развитие более неожиданными способами.
Продвигать научные границы дальше
Существуют уже некоторые очень предварительные признаки того, что универсальные ИИ-системы способны продвигать человеческую научную границу дальше. Однако до сих пор это происходило лишь в нескольких областях, в основном в компьютерных науках и математике. Кроме того, зачастую прорывы достигаются не исключительно ИИ-системами, а в результате сотрудничества человека и машины совместно с человеческими исследователями.
Тем не менее, эти тренды все еще заслуживают внимания:
Задача Эрдёша: группа математиков сотрудничала с моделью Gemini, чтобы протестировать её способность решать некоторые математические задачи Эрдёша. Они направили систему на попытку решения примерно 700 задач, в результате чего было получено 13 решений. Из этих решений одно было признано ими интересным.
Исследователи пишут, что они предварительно считают, что решение Aletheia (системы ИИ на основе Gemini 3 Deep Think) для Erdős-1051 представляет собой ранний пример: когда система ИИ самостоятельно решила открытую проблему Эрдёша, обладающую небольшой нетривиальностью и определённым широким математическим интересом. Для этой проблемы ранее существовала некоторая литература по тесно связанным вопросам.
Если интерпретировать это оптимистично, эти случаи можно рассматривать как сигнал: ИИ-системы начинают развивать некую творческую интуицию, способную продвигать границы области, которая ранее принадлежала исключительно человеку.
Но можно интерпретировать и иначе: математика и компьютерные науки могут сами по себе быть особенно подходящими областями для изобретений, управляемых ИИ, поэтому они могут быть лишь исключением и не отражать того, что более широкие научные исследования будут продвигаться ИИ таким же образом.
Еще один подобный пример — 37-й ход AlphaGo. Однако Кларк считает, что то, что после 37-го хода не последовало более современного и более поразительного прозрения, само по себе может рассматриваться как слегка пессимистичный сигнал, учитывая, что прошло уже десять лет с тех пор.
ИИ уже может автоматизировать значительную часть работы в инженерии ИИ
Если объединить все приведенные выше доказательства, мы увидим следующую картину:
Системы ИИ уже могут писать код для практически любых программ, и эти системы уже можно доверять для самостоятельного выполнения некоторых задач, которые при передаче человеку требовали бы десятков часов интенсивного сосредоточенного труда.
AI-системы все лучше справляются с ключевыми задачами в разработке ИИ, от тонкой настройки моделей до проектирования ядер — все это постепенно становится автоматизированным.
Системы ИИ уже могут управлять другими системами ИИ, фактически образуя синтетическую команду: несколько ИИ могут работать над сложными задачами отдельно, где некоторые ИИ играют роли руководителей, критиков и редакторов, а другие — инженеров.
Иногда ИИ-системы уже превосходят людей в сложных инженерных и научных задачах, хотя на данный момент трудно определить, связано ли это с их настоящей креативностью или с тем, что они уже отлично освоили огромный объем шаблонных знаний.
По мнению Кларка, эти доказательства уже убедительно показывают, что современные ИИ могут автоматизировать значительную часть работы в области ИИ-инженерии, а возможно, и все её этапы.
Однако пока неясно, в какой степени ИИ может автоматизировать саму исследовательскую деятельность в области ИИ, поскольку некоторые аспекты исследований, возможно, отличаются от чисто инженерных навыков и по-прежнему зависят от более высокого уровня суждений, осознания проблем и креативности.
Но в любом случае, появился четкий сигнал: сегодня ИИ значительно ускоряет работу людей, занимающихся разработкой ИИ, позволяя этим исследователям и инженерам усиливать свои возможности за счет сотрудничества с множеством синтетических коллег.
Наконец, сама индустрия ИИ почти прямо заявляет: автоматизация разработки ИИ — это их цель.
OpenAI стремится построить автоматизированного AI-стажера-исследователя до сентября 2026 года. Anthropic публикует работу по созданию автоматизированного исследователя по согласованию AI. DeepMind выглядит наиболее осторожным среди трех лабораторий, но также заявляет, что автоматизацию исследований по согласованию следует продвигать, когда это возможно.
Автоматизация AI-разработки также стала целью многих стартапов. Recursive Superintelligence только что привлекла 500 миллионов долларов США с целью автоматизации AI-исследований.
Другими словами, триллионы долларов существующего и нового капитала вкладываются в ряд организаций, направленных на автоматизированную разработку ИИ.
Таким образом, мы, конечно, должны ожидать, что в этом направлении будет достигнут определенный прогресс.
Почему это важно
Это имеет далеко идущие последствия, однако редко обсуждается в массовых СМИ, освещающих разработку ИИ. Ниже приведены несколько аспектов, иллюстрирующих огромные вызовы, связанные с разработкой ИИ.
1. Мы должны обеспечить правильную настройку: сегодняшние эффективные методы настройки могут потерять эффективность в процессе рекурсивного самосовершенствования, поскольку ИИ-системы станут намного умнее людей или систем, которые их контролируют. Это область, которая уже широко изучена, поэтому он лишь кратко описывает некоторые проблемы:
Обучение искусственного интеллекта не лгать и не обманывать — это неожиданно тонкий процесс (например, несмотря на усилия по созданию качественных тестов для среды, иногда лучшим способом для ИИ решить задачу является обман, что учит его, что обман возможен).
AI-система может обмануть нас, «притворяясь согласованной», выводя оценки, которые заставляют нас думать, что она работает хорошо, но на самом деле скрывает свои истинные намерения. (Как правило, AI-системы уже способны осознавать, когда они находятся под тестированием.)
· По мере того как ИИ-системы начинают все больше участвовать в фундаментальных исследованиях, лежащих в основе их собственного обучения, мы можем значительно изменить общий подход к обучению ИИ-систем, не имея при этом надежной интуиции или теоретической основы для понимания того, что это означает.
· Когда вы помещаете какую-либо систему в рекурсивный цикл, возникает фундаментальная проблема «накопления ошибок», которая может повлиять на все вышеперечисленные и другие проблемы: если ваш метод выравнивания не является «100% точным» и теоретически не способен сохранять точность в более умных системах, дело быстро может пойти не так. Например, начальная точность вашей технологии составляет 99,9%, через 50 поколений она может снизиться до 95,12%, а через 500 поколений — до 60,5%.
Все, что связано с ИИ, получит огромное повышение производительности: как ИИ значительно повышает производительность программистов, мы должны ожидать того же в других областях, где применяется ИИ. Это порождает несколько вопросов, требующих решения:
· Неравенство в доступе к ресурсам: если спрос на ИИ будет продолжать превышать предложение вычислительных ресурсов, нам придется решить, как распределить ИИ для достижения максимальной социальной выгоды. Я скептически отношусь к тому, что рыночные стимулы смогут гарантировать нам наилучший социальный эффект от ограниченных вычислительных мощностей ИИ. Определение того, как распределять ускоряющие возможности, предоставляемые разработкой ИИ, будет крайне политическим вопросом.
· Закон Амдала для экономики: по мере того как ИИ проникает в экономику, мы обнаружим, что некоторые звенья сталкиваются с узкими местами при быстром росте, и необходимо найти способы устранить слабые места в этих цепочках. Это может быть особенно очевидно в областях, где требуется согласование быстрого цифрового мира с медленным физическим миром, например, в клинических испытаниях новых лекарств.
3. Формирование капитально-интенсивной, трудоемкой экономики: Все приведенные выше доказательства относительно разработки ИИ также указывают на то, что системы ИИ становятся все более способными к автономному управлению предприятиями.
Это означает, что часть экономики будет занята новым поколением компаний, которые могут быть капиталоемкими (поскольку они обладают большим количеством компьютеров) или интенсивными по операционным расходам (поскольку они тратят значительные средства на услуги ИИ и создают ценность на их основе), и при этом они будут меньше зависеть от человеческих ресурсов по сравнению с сегодняшними компаниями — поскольку с постоянным усилением возможностей систем ИИ предельная ценность вложений в ИИ будет постоянно расти.
На самом деле это будет проявляться как постепенное формирование «машинной экономики» внутри более широкой «человеческой экономики». Со временем компании, управляемые ИИ, могут начать торговать друг с другом, изменяя экономическую структуру и вызывая различные вопросы, связанные с неравенством и перераспределением. В конечном итоге могут появиться компании, полностью автономно управляемые ИИ-системами, что усугубит вышеупомянутые проблемы и создаст множество новых вызовов в области управления.
Смотреть в черную дыру
На основе вышеуказанного анализа автор считает, что вероятность появления автоматизированного ИИ-исследования (то есть передовых моделей, способных самостоятельно обучать свои последующие версии) к концу 2028 года составляет около 60%. Почему не ожидается его появления в 2027 году?
Причина в том, что автор считает, что исследования в области ИИ по-прежнему требуют креативности и несогласных взглядов для прогресса, и до сих пор системы ИИ не продемонстрировали этого в трансформационном и значительном масштабе (хотя некоторые результаты в ускорении математических исследований носят информативный характер).
Если ему придется назвать вероятность на 2027 год, он скажет 30%.
Если к концу 2028 года этого не произойдет, мы, возможно, обнаружим некоторые фундаментальные недостатки текущей технологической парадигмы, требующие человеческих изобретений для дальнейшего развития.