









Autor:Tina, Dong Mei, InfoQ
1. Após quase três anos, Musk volta a tornar open source o algoritmo de recomendação do X
Apenas agora, a equipa de engenharia da X publicou um anúncio na X, revelando que tornou oficialmente open source o algoritmo de recomendação da X. Segundo a apresentação, esta biblioteca open source inclui o sistema de recomendação central que suporta o feed de "Recomendações para si" na X. Este sistema combina conteúdo dentro da rede (proveniente de contas seguidas pelos utilizadores) com conteúdo fora da rede (descoberto através de buscas baseadas em aprendizagem automática) e utiliza um modelo Transformer baseado no Grok para ranquear todo o conteúdo. Isto significa que o algoritmo utiliza a mesma arquitetura Transformer do Grok.
Endereço de código aberto: https://x.com/XEng/status/2013471689087086804
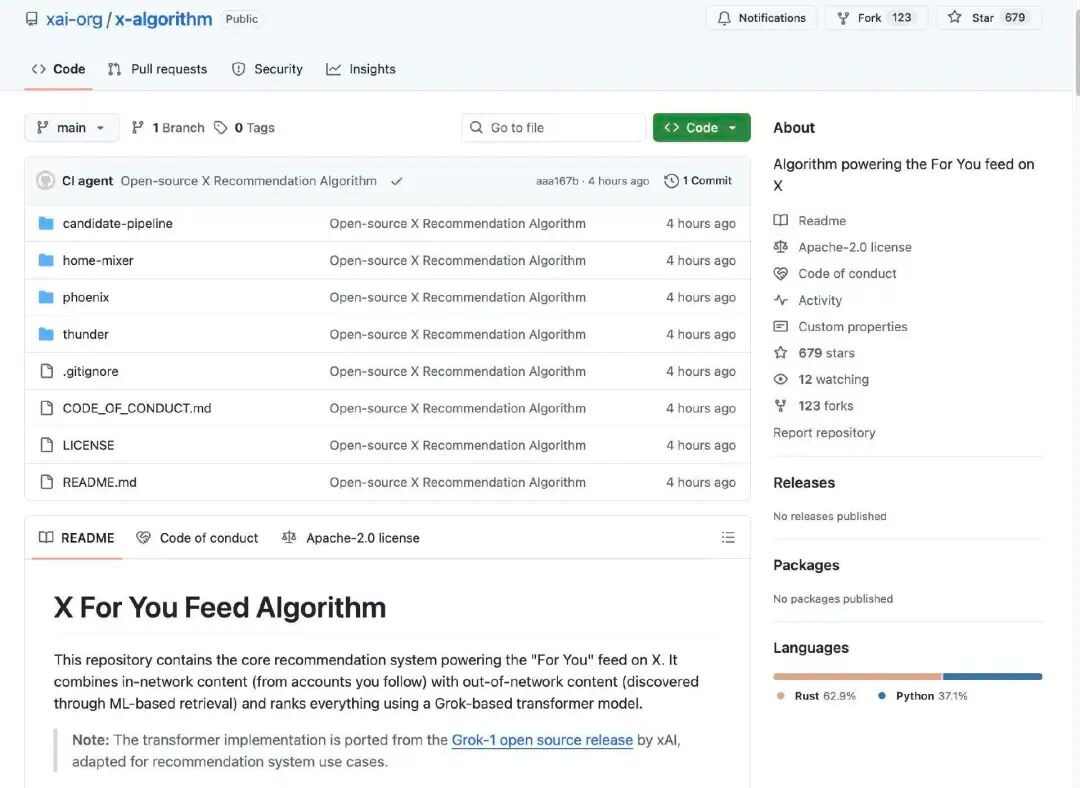
O algoritmo de recomendação do X é responsável por gerar o que os utilizadores veem na página principal.Conteúdo da secção "Para Ti". Ela obtém os posts candidatos de duas fontes principais:
A conta que segue (In-Network / Thunder)
Outras publicações encontradas na plataforma (Fora da Rede / Fênix)
Estes conteúdos candidatos são posteriormente processados de forma uniforme, filtrados e ordenados por relevância.
Então, qual é a arquitetura central e a lógica de funcionamento do algoritmo?
O algoritmo começa por capturar conteúdo candidato de duas fontes:
Conteúdo a seguir: publicações de contas que você segue ativamente.
Conteúdo não seguido: publicações que podem interessar-lhe, seleccionadas pelo sistema a partir de toda a base de dados de conteúdo.
O objetivo desta fase é "encontrar mensagens que possam estar relacionadas".
O sistema remove automaticamente conteúdos de baixa qualidade, repetidos, ilegais ou inadequados. Por exemplo:
Conteúdo de contas bloqueadas
Assuntos claramente desinteressantes para o utilizador
Posts ilegais, desatualizados ou inválidos
Isto garante que apenas o conteúdo candidato valioso seja processado no final da classificação.
O núcleo do algoritmo divulgado open-source é o uso, pelo sistema, de um modelo Transformer baseado em Grok (similar a modelos de linguagem de grande escala ou redes de aprendizagem profunda) para atribuir uma pontuação a cada postagem candidata. O modelo Transformer prevê a probabilidade de cada tipo de comportamento com base na história de interações do utilizador (como curtidas, respostas, partilhas, cliques, etc.). Finalmente, estas probabilidades de comportamento são combinadas de forma ponderada para formar uma pontuação global. As publicações com pontuações mais elevadas são mais propensas a serem recomendadas ao utilizador.
Este design praticamente elimina a abordagem tradicional de extracção manual de características, substituindo-a por um método de aprendizagem de ponta a ponta para prever os interesses dos utilizadores.
Este não é o primeiro algoritmo de recomendação do X a ser tornado open-source por Musk.
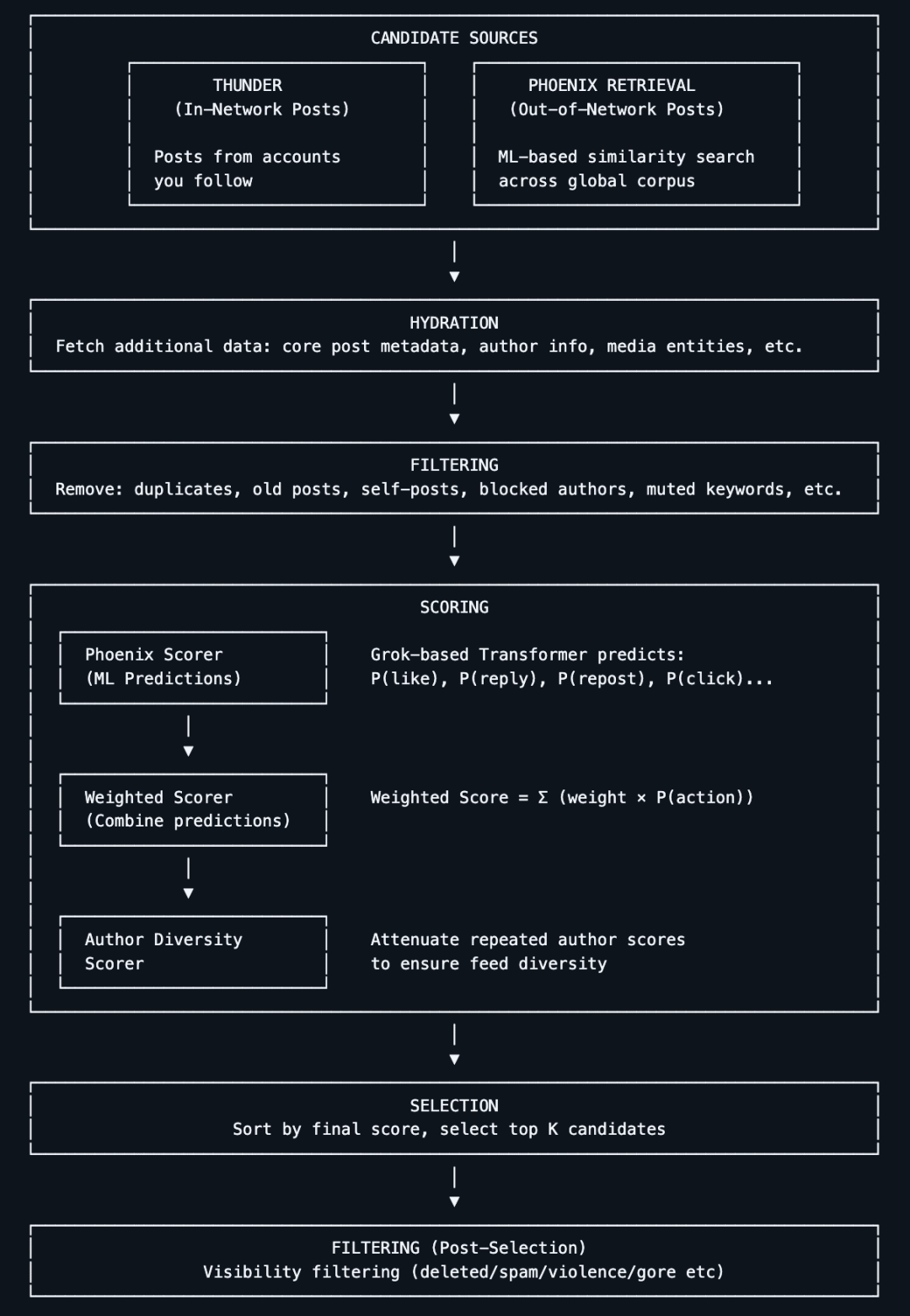
Em 31 de março de 2023, como prometido quando adquiriu o Twitter, Musk tornou oficialmente open source parte do código-fonte do Twitter, incluindo o algoritmo que recomenda tweets nas linhas do tempo dos utilizadores.No dia em que foi lançado como open source, o projeto já tinha recebido mais de 10k estrelas no GitHub.
Na altura, Musk disse no Twitter que este lançamento era"Algoritmos de recomendação", os restantes algoritmos também serão gradualmente divulgados. Ele também referiu que espera que "terceiros independentes possam determinar com uma precisão razoável o conteúdo que o Twitter pode mostrar aos utilizadores".
Na discussão do Space sobre a publicação do algoritmo, ele disse que este plano de código aberto visa tornar o Twitter "o sistema mais transparente na Internet" e torná-lo tão robusto quanto o Linux, o projeto de código aberto mais conhecido e bem-sucedido. "O objetivo geral é permitir que os utilizadores que continuam a apoiar o Twitter desfrutem ao máximo deste serviço."
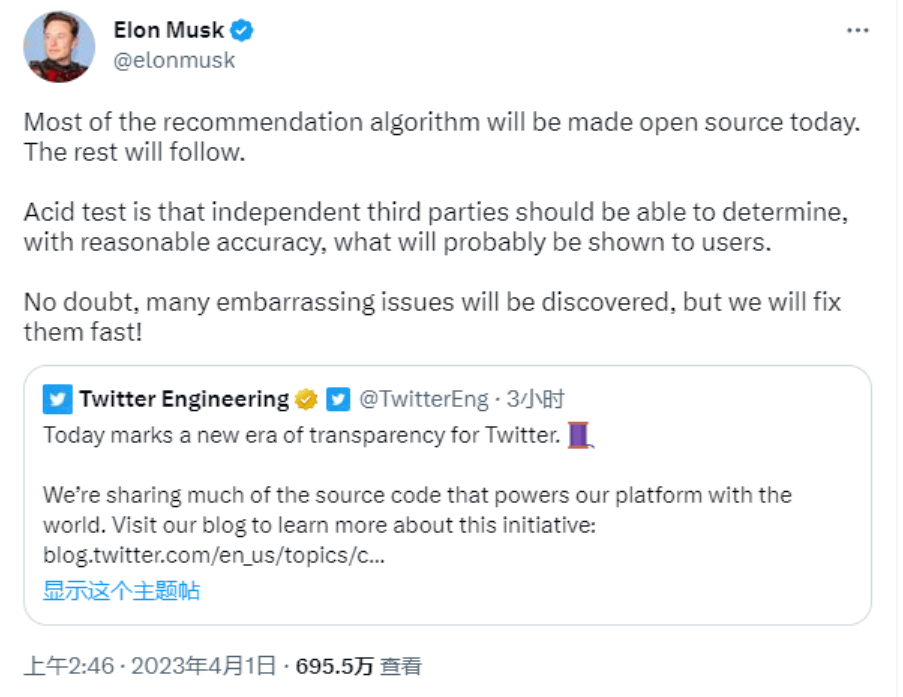
Já passaram mais de três anos desde que Musk tornou o algoritmo X open-source pela primeira vez. E como um super KOL do círculo tecnológico, Musk já fez uma campanha de divulgação suficiente para esta open-source.
No dia 11 de janeiro, Musk publicou no X que iria tornar open source o novo algoritmo do X (incluindo todo o código usado para determinar quais conteúdos de pesquisa natural e anúncios seriam recomendados aos utilizadores) dentro de 7 dias.
Este processo repetir-se-á a cada 4 semanas, acompanhado de instruções detalhadas para os desenvolvedores, ajudando os utilizadores a compreender quais as alterações que ocorreram.
Hoje, a sua promessa cumpriu-se novamente.
2. Por que Musk quer open-source?
Quando Elon Musk menciona novamente "código aberto", a primeira reação do público não é o idealismo técnico, mas sim a pressão real.
Nos últimos 12 meses, o X tem estado repetidamente envolvido em controvérsias devido ao seu mecanismo de distribuição de conteúdo. A plataforma tem sido amplamente criticada por favorecer e promover, ao nível algorítmico, pontos de vista de direita. Esta tendência não é considerada isolada, mas sim sistémica. Um estudo publicado no ano passado destacou, por exemplo, que o sistema de recomendações do X apresenta claramente um novo viés na propagação de conteúdo político.
Ao mesmo tempo, alguns casos extremos agravaram ainda mais as dúvidas externas. No ano passado, um vídeo não verificado envolvendo o ativista de direita norte-americano Charlie Kirk, que supostamente mostrava a sua morte, espalhou-se rapidamente na plataforma X, causando uma forte reação pública. Os críticos acreditam que isso não apenas revelou a ineficácia dos mecanismos de moderação da plataforma, mas também destacou novamente como os algoritmos decidem "o que ampliar e o que não ampliar". Poder tácito.
Neste contexto, o fato de Musk subitamente enfatizar a transparência algorítmica é difícil de ser interpretado simplesmente como uma decisão técnica pura.

3. O que os internautas pensam disso?
Após o algoritmo de recomendação do X ser open-source, na plataforma X, os utilizadores fizeram as seguintes cinco resumos sobre o mecanismo do algoritmo de recomendação:
- Responda ao seu comentárioO algoritmo dá um peso 75 vezes maior a "respostas + respostas dos autores" em comparação com curtidas. Não responder a comentários afeta significativamente a taxa de exposição.
- Os links reduzem a taxa de exposição.Coloque o link na sua biografia pessoal ou na publicação em destaque, nunca no corpo principal da publicação.
- O tempo de visualização é crucial.Se eles deslizarem a tela e passarem, você não conseguirá atrair a sua atenção. Vídeos/postagens conseguem alta atenção porque conseguem fazer os utilizadores pararem.
- Permanece no teu campo."Clusteres de simulação" são reais. Se você se afastar do seu nicho (criptomoedas, tecnologia, etc.), não conseguirá obter nenhum canal de distribuição.
- Bloquear/ignorar vai reduzir significativamente a tua pontuação.Seja controverso, mas não desagradável.
Em resumo: comunique-se com seu público, construa relações e mantenha os utilizadores dentro da aplicação. Na verdade, é bastante simples.
Alguns utilizadores da Internet também descobriram que, apesar da arquitetura ser open-source, ainda há alguns conteúdos que não foram abertos. Este utilizador afirmou que este lançamento, essencialmente, é apenas um quadro conceptual, sem incluir o motor. O que exatamente falta?
Falta o parâmetro de peso. - O código confirma a atribuição de pontos por comportamentos positivos e a dedução de pontos por comportamentos negativos, mas, diferentemente da versão de 2023, os valores específicos foram removidos.
Ocultar pesos do modelo - Não inclui os parâmetros internos e cálculos do próprio modelo.
Dados de treino não divulgados - Não temos qualquer conhecimento sobre os dados utilizados para treinar o modelo, a forma como os comportamentos dos utilizadores foram amostrados, nem como foram construídos os exemplos "bons" e "maus".
Para utilizadores comuns de X, o facto de o algoritmo ser de código aberto não terá grande impacto. No entanto, uma maior transparência pode explicar por que alguns posts recebem visibilidade e outros não, permitindo também que os investigadores estudem como a plataforma classifica o conteúdo.
4. Por que é que os sistemas de recomendação são um campo de batalha essencial?
Na maioria das discussões técnicas,Sistema de recomendaçãoMuitas vezes é visto como parte da engenharia de fundos, discreto e complexo, mas raramente sob os holofotes. No entanto, se analisarmos cuidadosamente o modo como os gigantes da internet gerem os seus negócios, descobriremos que o sistema de recomendação não é apenas um módulo periférico, mas sim uma "infraestrutura essencial" que suporta todo o modelo de negócio. Por isso, pode ser chamado de "monstrinho silencioso" da indústria da internet.
Dados públicos já confirmaram repetidamente este ponto. A Amazon revelou que cerca de 35% das compras na sua plataforma ocorrem diretamente a partir do sistema de recomendação; o Netflix é ainda mais radical, com aproximadamente 80% do tempo de visualização impulsionado pelo algoritmo de recomendação; o YouTube encontra-se numa situação semelhante, com cerca de 70% do tempo de visualização a resultar do sistema de recomendação, especialmente no feed de conteúdo. Quanto à Meta, embora nunca tenha fornecido uma percentagem exata, a sua equipa técnica mencionou que cerca de 80% dos ciclos de computação nos clusters de computação internos da empresa são utilizados para tarefas relacionadas com recomendações.
O que estes números significam?Se removermos o sistema de recomendação destes produtos, será quase como tirar as bases do chão.Tomando como exemplo a Meta, a colocação de anúncios, o tempo que os utilizadores passam na plataforma e as conversões comerciais baseiam-se quase que totalmente no sistema de recomendação. O sistema de recomendação não apenas determina o que os utilizadores "vêm", mas também decide diretamente "como a plataforma ganha dinheiro".
No entanto, é precisamente um sistema que decide entre a vida e a morte que tem enfrentado há muito tempo problemas de uma complexidade extrema em termos de engenharia.
Na arquitetura tradicional de sistemas de recomendação, é difícil cobrir todos os cenários com um único modelo unificado. Os sistemas produtivos reais são frequentemente altamente fragmentados. Tomando como exemplo empresas como a Meta, LinkedIn e Netflix, por trás de uma cadeia completa de recomendações, normalmente estão em execução simultaneamente mais de 30 modelos especializados: modelos de recuperação, modelos de classificação grosseira, modelos de classificação fina, modelos de reordenação, cada um otimizado para diferentes funções objetivo e métricas de negócio. Por trás de cada modelo, normalmente existe um ou mais equipas responsáveis pela engenharia de características, treino, ajuste de parâmetros, implementação e iteração contínua.
O custo deste modelo é evidente: complexidade de engenharia, custos elevados de manutenção e dificuldade de cooperação entre tarefas. Assim que alguém propõe a ideia de "Será que um único modelo pode resolver múltiplos problemas de recomendação?", isso significa, para todo o sistema, uma redução de ordem de magnitude na complexidade. Este é exatamente o objetivo que a indústria tem desejado há muito tempo, mas que tem sido difícil de atingir.
A emergência de modelos de linguagem de grande escala fornece um novo caminho possível para sistemas de recomendação.
Os modelos LLM já demonstraram, na prática, poderem tornar-se modelos genéricos extremamente poderosos: possuem uma forte capacidade de transferência entre diferentes tarefas e o seu desempenho pode continuar a melhorar com a expansão da escala dos dados e do poder computacional. Por contraste, os modelos tradicionais de recomendação são frequentemente "personalizados para tarefas específicas", tendo grande dificuldade em partilhar capacidades entre múltiplos cenários.
Mais importante ainda, um único modelo grande traz não apenas simplificação no engenhamento, mas também o potencial de "aprendizagem cruzada". Quando o mesmo modelo processa simultaneamente múltiplas tarefas de recomendação, os sinais entre diferentes tarefas podem se complementar mutuamente, e, à medida que a escala dos dados aumenta, o modelo evolui mais facilmente como um todo. Esta é exatamente a característica que os sistemas de recomendação desejaram por muito tempo, mas que foi difícil de ser alcançada por meios tradicionais.
O que o LLM mudou? Na verdade, mudou desde a engenharia de características até à capacidade de compreensão.
Do ponto de vista metodológico, a maior mudança introduzida pelos LLM nos sistemas de recomendação ocorre na etapa central do "engenharia de características".
Nos sistemas de recomendação tradicionais, os engenheiros têm de construir previamente uma grande quantidade de sinais, como histórico de cliques do utilizador, duração do tempo de permanência, preferências de utilizadores semelhantes, etiquetas de conteúdo, etc., e depois indicar claramente ao modelo "por favor, baseie-se nestas características para tomar decisões". O próprio modelo não compreende o significado destes sinais, limitando-se a aprender relações de mapeamento no espaço numérico.
Após a introdução dos modelos linguísticos, este processo foi altamente abstraído. Não é necessário especificar individualmente "preste atenção a este sinal, ignore aquele sinal", mas sim descrever directamente ao modelo o problema em si: este é um utilizador, este é um conteúdo; este utilizador gostou anteriormente de conteúdos semelhantes, outros utilizadores também deram feedback positivo sobre este conteúdo — agora, por favor avalie se este conteúdo deveria ser recomendado a este utilizador.
Os modelos linguísticos em si já possuem a capacidade de compreensão, podendo julgar por si mesmos quais informações são sinais importantes e como integrar esses sinais para tomar decisões. De certo modo, eles não apenas executam regras de recomendação, mas também "compreendem o ato de recomendar".
A origem desta capacidade reside no facto de que os LLMs tiveram contacto, durante a fase de treino, com uma quantidade massiva e diversificada de dados, o que lhes permite capturar mais facilmente padrões sutilmente importantes. Por contraste, os sistemas de recomendação tradicionais têm de depender de engenheiros para enumerar explicitamente estes padrões, e, assim que algum seja omitido, o modelo não consegue detetá-lo.
Do ponto de vista do backend, essa mudança não é algo novo. Assim como tu fazes uma pergunta ao GPT e ele gera uma resposta com base no contexto, da mesma forma, quando tu lhe perguntas "serei eu interessado por este conteúdo", ele também pode tomar uma decisão com base nas informações existentes. Em certo sentido, os próprios modelos de linguagem já possuem, de forma natural, a capacidade de "recomendar".