









Artigo de: Zack Pokorny
Tradução: Chopper, Foresight News
A implementação de agentes de IA na blockchain não tem sido tranquila; embora a blockchain possua características programáveis e sem permissão, ela carece de abstrações semânticas e camadas de coordenação adaptadas a agentes. A instituição de pesquisa cripto Galaxy publicou um relatório destacando que agentes na blockchain enfrentam quatro atritos estruturais: descoberta de oportunidades, verificação confiável, leitura de dados e fluxos de execução. A infraestrutura atual ainda é projetada em torno da interação humana, dificultando a gestão autônoma de ativos e a execução de estratégias por IA, o que constitui os principais gargalos para a adoção em escala de agentes na blockchain. A seguir, a tradução completa do relatório:
As aplicações e capacidades dos agentes de IA já começaram a evoluir. Eles agora iniciam tarefas de forma autônoma e são desenvolvidos para detentar e configurar capital, bem como descobrir estratégias de negociação e rendimento. Embora essa transformação experimental ainda esteja em estágio muito inicial, ela difere radicalmente do modelo anterior, no qual os agentes eram principalmente ferramentas sociais e de análise.
A blockchain está se tornando o campo de testes natural para essa evolução. A blockchain é sem permissão, composta, possui um ecossistema de aplicativos de código aberto, oferece acesso igualitário aos dados a todos os participantes e todos os ativos na cadeia são programáveis por padrão.
Isso levanta uma questão estrutural: se a blockchain é programável e sem permissão, por que os agentes autônomos ainda enfrentam atritos? A resposta não está na viabilidade da execução, mas no quanto de carga semântica e de coordenação existe acima da execução. A blockchain garante a correção das transições de estado, mas geralmente não fornece abstrações nativas do protocolo, como para interpretação econômica, identidade normativa ou coordenação em nível de objetivo.
Parte da fricção decorre de falhas na arquitetura de sistemas sem permissão, e parte reflete o estado atual das ferramentas, gestão de conteúdo e infraestrutura de mercado. Na verdade, muitas funções de nível superior ainda dependem de software e fluxos de trabalho que exigem intervenção humana para serem construídos.
Arquitetura de blockchain e agentes de IA
O design da blockchain gira em torno de consenso e execução determinística, e não de interpretação semântica. Ele expõe ao exterior primitivos de baixo nível, como slots de armazenamento, logs de eventos e trajetórias de chamadas, e não objetos econômicos padronizados. Portanto, conceitos abstratos como posições, rendimentos, coeficiente de saúde e profundidade de liquidez geralmente precisam ser recriados off-chain por indexadores, camadas de análise de dados, interfaces front-end e APIs, transformando o estado específico de cada protocolo em formas mais utilizáveis.
Muitos processos principais de finanças descentralizadas, especialmente aqueles voltados para varejistas e decisões subjetivas, ainda giram em torno do modelo em que os usuários interagem por meio de interfaces front-end e assinam transações individuais. Esse modelo centrado na interface do usuário se expandiu com a popularização dos varejistas, mesmo que uma grande parte das atividades na cadeia já seja impulsionada por máquinas. O modelo dominante atual de interação com varejistas continua sendo: intenção → interface do usuário → transação → confirmação. Operações programáticas seguem um caminho diferente, mas também apresentam suas próprias limitações: os desenvolvedores selecionam contratos e conjuntos de ativos durante a fase de construção e, em seguida, executam algoritmos dentro desse intervalo fixo. Nenhum desses dois modelos é capaz de se adaptar a sistemas que precisam descobrir, avaliar e combinar operações dinamicamente em tempo de execução, com base em objetivos em constante mudança.
Quando uma infraestrutura otimizada para verificação de transações é utilizada por sistemas que precisam interpretar simultaneamente o estado econômico, avaliar crédito e otimizar comportamentos em torno de objetivos claros, atritos começam a surgir. Essas lacunas derivam em parte das características de design sem permissão e heterogêneo da blockchain, e em parte do fato de que as ferramentas de interação ainda são construídas em torno de revisão humana e intermediários front-end.
Comparação entre o fluxo de comportamento de agentes e estratégias de algoritmos tradicionais
Antes de explorar a lacuna entre a infraestrutura de blockchain e os sistemas de agentes, é necessário esclarecer: qual é a diferença entre fluxos de comportamento com maior inteligência autônoma e os sistemas algorítmicos tradicionais na cadeia.
A diferença entre eles não reside no grau de automação, complexidade, configuração parametrizada ou até mesmo na capacidade de adaptação dinâmica. Sistemas algorítmicos tradicionais podem ser altamente parametrizados, capazes de descobrir automaticamente novos contratos e novos tokens, alocar fundos entre vários tipos de estratégias e reequilibrar com base no desempenho. A verdadeira diferença está na capacidade do sistema de lidar com cenários não previstos durante a fase de construção.
Sistemas algorítmicos tradicionais, por mais complexos que sejam, executam apenas lógicas pré-definidas em padrões pré-definidos. Eles exigem interpretadores de interface pré-definidos para cada tipo de protocolo, lógicas de avaliação pré-definidas para mapear o estado do contrato em significados econômicos, regras explícitas de julgamento de crédito e padronização, além de regras codificadas diretamente para cada ramo de decisão. Quando surgem situações que não correspondem aos padrões pré-definidos, o sistema ou ignora ou simplesmente falha. Ele não consegue raciocinar sobre cenários desconhecidos, apenas verificar se o cenário atual corresponde a um modelo conhecido.
Assim como este dispositivo mecânico chamado "Pato de Digestão", capaz de imitar comportamentos biológicos, mas todos os movimentos são pré-programados.
Um algoritmo tradicional que varre o mercado de empréstimos DeFi pode identificar novos contratos implantados que emitem eventos familiares ou correspondem a padrões de fábrica conhecidos. No entanto, se surgir um novo componente de empréstimo com uma interface desconhecida, o sistema não consegue avaliá-lo. É necessário que um humano inspecione o contrato, compreenda seu mecanismo de funcionamento, determine se representa uma oportunidade explorável e escreva a lógica de integração. Apenas após isso, o algoritmo pode interagir com ele. O humano é responsável por interpretar, e o algoritmo, por executar. Sistemas de agentes baseados em modelos fundamentais alteram esse limite, permitindo:
- Interpretar metas vagas ou mal definidas. Instruções como “maximizar o retorno, mas evitar riscos excessivos” exigem interpretação semântica. O que constitui risco excessivo? Como equilibrar retorno e risco? Algoritmos tradicionais precisam definir previamente esses critérios com precisão. Já os agentes inteligentes conseguem interpretar a intenção, tomar decisões e aprimorar sua compreensão com base no feedback.
- Capaz de generalizar e se adaptar a interfaces desconhecidas. O agente pode ler código de contrato desconhecido, interpretar documentação ou examinar interfaces binárias de aplicativos nunca antes encontrados e inferir a função econômica do sistema. Não é necessário pré-construir parsers para cada tipo de protocolo. Embora essa capacidade ainda não esteja plenamente desenvolvida e o agente possa mal interpretar o que vê, ele consegue tentar interagir com sistemas que não foram previstos durante a fase de construção.
- Raciocinar na presença de incerteza quanto à confiança e normatividade. Quando os sinais de crédito são ambíguos ou incompletos, o modelo base pode ponderar probabilisticamente os sinais, em vez de aplicar regras binárias simples. Este contrato inteligente é padronizado? Com base nas evidências disponíveis, este token é legítimo? Algoritmos tradicionais ou seguem regras ou não têm solução; já os agentes podem raciocinar sobre o nível de confiança.
- Explique o erro e faça os ajustes. Quando ocorrem situações inesperadas, o agente pode raciocinar sobre a causa raiz e decidir como responder. Em contraste, algoritmos tradicionais apenas executam módulos de captura de exceções, encaminhando apenas as informações de erro sem interpretação.
Essas capacidades existem atualmente, mas não são perfeitas. Modelos básicos podem gerar ilusões, mal interpretar conteúdo e tomar decisões erradas com aparência de certeza. Em ambientes adversariais e envolvendo capital (ou seja, onde o código pode controlar ou receber ativos), "tentar interagir com sistemas não previstos" pode significar perda de fundos. A ideia central deste artigo não é que agentes já possam executar essas funções de forma confiável, mas que eles conseguem tentar de maneiras que sistemas tradicionais não conseguem, e que a infraestrutura futura poderá tornar essas tentativas mais seguras e confiáveis.
Essa diferença deve ser vista mais como um contínuo do que como um limite categorial absoluto. Alguns sistemas tradicionais incorporam formas de raciocínio aprendido, e alguns agentes também podem depender de regras codificadas em caminhos críticos. Essa distinção é direcional, não absolutamente binária. Os sistemas de agentes transferem mais interpretação, avaliação e trabalho adaptativo para o raciocínio em tempo de execução, em vez de regras pré-definidas na fase de construção. Esse ponto é crucial para a discussão sobre fricções, pois os sistemas de agentes buscam realizar exatamente o que os algoritmos tradicionais evitam completamente. Os algoritmos tradicionais evitam a descoberta de fricções ao permitir que humanos filtrem conjuntos de contratos na fase de construção; evitam fricções de controle por meio de listas brancas mantidas por operadores; evitam fricções de dados usando解析器 pré-construídos para protocolos conhecidos; e evitam fricções de execução operando dentro de limites de segurança pré-definidos. Os humanos realizam antecipadamente o trabalho semântico, de crédito e de estratégia, enquanto os algoritmos executam dentro dos limites estabelecidos. Os fluxos de comportamento de agentes on-chain iniciais talvez sigam esse modelo, mas o valor central dos agentes reside em transferir a descoberta, a avaliação de crédito e a estratégia para o raciocínio em tempo de execução, e não para pré-definições na fase de construção.
Eles tentam descobrir e avaliar oportunidades desconhecidas, raciocinar sobre padronização sem regras codificadas, interpretar estados heterogêneos sem解析器 pré-definidos e executar restrições estratégicas em objetivos possivelmente ambíguos. A existência de atrito não se deve ao fato de os agentes estarem fazendo a mesma coisa que os algoritmos, mas com maior dificuldade; sim, ao fato de estarem tentando coisas completamente diferentes: operar em um espaço de comportamento aberto e dinamicamente interpretado, e não em um sistema fechado e previamente integrado.
Atrito
Do ponto de vista estrutural, essa contradição não decorre de falhas no consenso da blockchain, mas sim do modo como a pilha de interação ao redor dela foi projetada.
A blockchain garante transformações de estado determinísticas, consenso sobre o estado final e finalidade. Ela não tenta codificar no nível do protocolo interpretações de significado econômico, verificação de intenções ou rastreamento de objetivos. Essas responsabilidades historicamente são assumidas por interfaces front-end, carteiras, indexadores e outras camadas colaborativas off-chain, onde sempre é necessária intervenção humana.
Mesmo para participantes experientes, o modelo de interação atual reflete esse design. Investidores individuais interpretam o estado por meio de painéis, selecionam ações por meio da interface do usuário e assinam transações por meio de carteiras, validando informalmente os resultados. As instituições de negociação algorítmica automatizam a execução, mas ainda dependem de operadores humanos para filtrar conjuntos de protocolos, verificar anomalias e atualizar a lógica de integração quando as interfaces mudam. Em ambos os cenários, o protocolo é responsável apenas por garantir a corretude da execução, enquanto a interpretação de intenções, o tratamento de anomalias e a adaptação a novas oportunidades são realizados por humanos.
Os sistemas de agentes comprimem e até eliminam essa divisão de trabalho. Eles devem reestruturar programaticamente estados com significado econômico, avaliar o progresso em direção aos objetivos e validar os resultados da execução, em vez de simplesmente confirmar a inclusão da transação na blockchain. Na blockchain, essas responsabilidades são particularmente proeminentes, pois os agentes operam em ambientes abertos, adversários e em rápida mutação, onde novos contratos, ativos e caminhos de execução podem surgir sem revisão centralizada. O protocolo garante apenas a execução correta das transações, mas não garante que o estado econômico seja facilmente interpretável, que os contratos sejam padronizados, que os caminhos de execução estejam alinhados com a intenção do usuário ou que oportunidades relevantes possam ser descobertas programaticamente.
A seguir, será analisado passo a passo, conforme as fases do ciclo de execução do agente, tais atritos: identificação de contratos e oportunidades existentes, verificação de sua legalidade, obtenção de estados com significado econômico e execução de operações em torno do objetivo.
Descobrir atrito
A geração de atrito ocorre porque o espaço de comportamento da finança descentralizada se expande livremente em um ambiente sem permissão, enquanto a relevância e a legitimidade são filtradas pelos seres humanos por meio das camadas sociais, de mercado e de ferramentas na cadeia. Novos protocolos emergem por meio de anúncios, mas também passam por camadas de filtragem, como integração de interfaces, listagem de tokens, plataformas de análise de dados e formação de liquidez. Conforme o tempo passa, esses sinais frequentemente acabam formando um critério viável para distinguir quais partes do espaço de comportamento possuem valor econômico e confiabilidade suficiente, embora esse consenso possa ser informal, desigual e parcialmente dependente de terceiros e filtragem manual.
É possível fornecer aos agentes dados filtrados e sinais de confiança, mas eles próprios não possuem os atalhos intuitivos que os humanos usam para interpretar esses sinais. Do ponto de vista na cadeia, todos os contratos implantados têm a mesma visibilidade. Protocolos legítimos, forks maliciosos, implantações de teste e projetos abandonados existem todos na forma de bytecode chamável. A blockchain em si não codifica quais contratos são importantes ou seguros.
Portanto, o agente deve construir seu próprio mecanismo de descoberta: escanear eventos de implantação, identificar padrões de interface, rastrear contratos fábrica (contratos que podem programaticamente implantar outros contratos) e monitorar a formação de liquidez para determinar quais contratos devem ser incluídos no escopo de decisão. Esse processo não é apenas encontrar contratos, mas também avaliar se eles devem entrar no espaço de ação do agente.
Identificar os candidatos é apenas o primeiro passo. Após a triagem inicial, os contratos devem passar pelo processo de verificação de padronização e autenticidade descrito na próxima seção. O agente deve primeiro confirmar que o contrato descoberto corresponde ao que afirma ser, antes de incluí-lo no espaço de decisão.
Descobrir atrito não se refere à detecção de novas ações implantadas. Sistemas algorítmicos maduros já conseguem realizar isso dentro de suas próprias estratégias. Buscadores que monitoram eventos do contrato Uniswap Factory e incorporam automaticamente novos pares de liquidez estão executando descoberta dinâmica. O atrito surge em dois níveis superiores: determinar se o contrato descoberto é legítimo e se está relacionado a objetivos abertos, e não apenas correspondendo a tipos de estratégia pré-definidos.
A lógica de descoberta do buscador está intimamente ligada à sua estratégia. Ele sabe quais padrões de interface procurar, pois a estratégia já foi definida. Já o agente que executa instruções mais amplas, como “configurar as melhores oportunidades ajustadas ao risco”, não pode depender apenas de filtros derivados da estratégia. Ele deve avaliar novas oportunidades em relação ao próprio objetivo, o que exige interpretar interfaces desconhecidas, inferir funções econômicas e determinar se essa oportunidade deve ser incluída no espaço de decisão. Isso é, em certa medida, um problema de autonomia geral, mas a blockchain agrava esse problema.
Controle da fricção
A geração de atrito na camada de controle ocorre porque a verificação de identidade e legitimidade geralmente é realizada fora do protocolo, dependendo combinadamente de seleção, governança, documentação, interfaces e julgamento operacional. Em muitos fluxos de trabalho atuais, os seres humanos ainda desempenham um papel crucial na etapa de verificação. A blockchain garante execução determinística e finalidade, mas não garante que o chamador esteja interagindo com o contrato pretendido. Essa verificação de intenção é externalizada para contextos sociais, sites e seleção humana.
No processo atual, os humanos utilizam a camada de confiança da página web como um meio informal de verificação. Eles acessam o domínio oficial (geralmente encontrado por meio de plataformas agregadoras como a DeFiLlama ou contas de redes sociais certificadas pelo projeto) e consideram esse site como o veículo padrão que mapeia o conceito humano para o endereço do contrato. Em seguida, a interface frontal estabelece um padrão confiável viável, identificando claramente quais endereços são oficiais, qual identificador de token deve ser usado e quais entradas são seguras.

O Mecanismo Turco de 1789 era uma máquina de xadrez que parecia operar de forma autônoma, mas na verdade dependia de um operador humano oculto.
Agentes não conseguem, por padrão, interpretar identidades de marca, sinais sociais de autenticação ou "oficialidade" no contexto social. É possível fornecer a eles dados filtrados derivados desses sinais, mas para transformá-los em suposições de confiança máquina duradouras e utilizáveis, é necessário um registro explícito, uma política ou lógica de validação. É possível configurar agentes com listas brancas filtradas, endereços autenticados e políticas de confiança fornecidas por operadores. O problema não é que o contexto social seja totalmente inacessível, mas que manter essas medidas de proteção em um espaço de comportamento em expansão dinâmica tem um custo operacional extremamente alto, e quando essas medidas estão ausentes ou incompletas, os agentes carecem dos mecanismos alternativos de validação que os humanos utilizam por padrão.
O sistema impulsionado por agentes on-chain já apresentou consequências reais decorrentes de julgamentos de confiança fracos. No caso do influenciador de criptomoedas Orangie, supostamente um agente depositou fundos em um contrato de armadilha. Em outro caso, o agente chamado Lobstar Wilde, devido a falhas de estado ou contexto, incorretamente interpretou o status do endereço e transferiu um grande saldo de tokens para um "pedinte" online. Esses casos não são argumentos centrais, mas são suficientes para ilustrar como erros na avaliação de confiança, interpretação de estado e estratégias de execução podem levar diretamente à perda de fundos.
O problema não é que os contratos sejam difíceis de encontrar, mas sim que a blockchain geralmente não possui um conceito nativo de “este é o contrato oficial deste aplicativo”. Essa ausência é, em certa medida, uma característica dos sistemas sem permissão, e não um erro de design, mas ainda assim cria desafios de coordenação para sistemas autônomos. Esse problema decorre parcialmente da arquitetura aberta com identidades padrão fracas e parcialmente da imaturidade dos registros, padrões e mecanismos de distribuição de confiança. Um agente que tenta interagir com o Aave v3 deve determinar quais endereços são endereços padrão, bem como se esses endereços são imutáveis, podem ser atualizados por meio de proxy ou estão atualmente em estado pendente de alteração de governança.
Os humanos resolvem esse problema por meio de documentos, interfaces front-end e mídias sociais. Os agentes devem determinar verificando os seguintes itens:
- Modelo de agente e pontos-chave de implementação
- Permissões de administração e lock de tempo
- Módulo de atualização de parâmetros de controle de governança
- Bytecode / ABI correspondente entre implantações conhecidas
Na ausência de um registro padrão, a "oficialidade" torna-se uma questão de inferência. Isso significa que os agentes não podem considerar endereços de contratos como configurações estáticas. Eles devem manter uma lista branca filtrada validada continuamente, ou recalcular a padronização em tempo real por meio de proxies e monitoramento de governança, ou assumir o risco de interagir com contratos obsoletos, comprometidos ou falsificados. Em software e infraestrutura de mercado tradicionais, a identidade dos serviços é geralmente ancorada por namespaces, credenciais e controles de acesso mantidos por instituições. Em contraste, na cadeia, um contrato pode ser chamado e funcionar corretamente, mas, do ponto de vista do chamador, não possui padronização econômica ou comercial.
A autenticidade do token e os metadados são o mesmo problema. Os tokens parecem ser autoexplicativos, mas os metadados do token não são autoritativos; são apenas dados em bytes retornados pelo código. Um exemplo clássico é o Wrapped Ether (WETH). O código do contrato WETH, amplamente utilizado, define claramente o nome, o símbolo e a precisão.
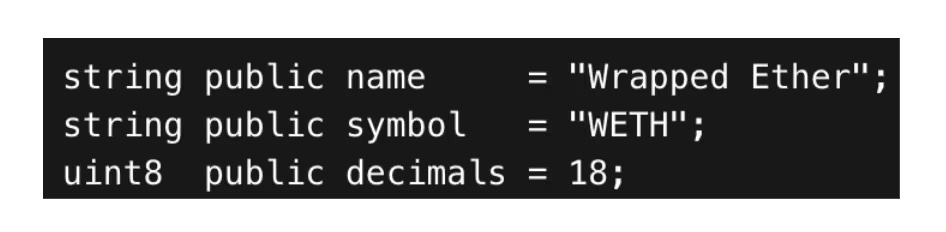
Isso parece ser um identificador de identidade, mas não é. Qualquer contrato pode ser configurado:
- symbol() = WETH
- decimais() = 18
- name() = Wrapped Ether
E implementar a mesma interface do padrão de token ERC-20. name(), symbol() e decimals() são apenas funções de leitura públicas que retornam qualquer conteúdo definido pelo deployer. Na verdade, na Ethereum, existem cerca de 200 tokens com o nome "Wrapped Ether", símbolo "WETH" e precisão de 18 casas decimais. Sem consultar o CoinGecko ou o Etherscan, você consegue identificar qual "WETH" é a versão padrão?
O agente enfrenta exatamente essa situação. A blockchain não verifica unicidade, não consulta nenhum registro para validação e não impõe nenhuma restrição. Hoje, você pode implantar 500 contratos, todos retornando os mesmos metadados. Existem alguns métodos tentativos de verificação na cadeia (por exemplo, verificar se o saldo Ethereum corresponde à oferta total, consultar a profundidade de liquidez em exchanges descentralizadas principais, validar se é aceito como garantia em protocolos de empréstimo), mas nenhum deles fornece prova absoluta. Cada método depende ou de suposições de limiar ou de verificação recursiva da padronização de outros contratos.

Assim como encontrar a rota "verdadeira" em um labirinto exige orientação externa, não há sinais padrão nativos na cadeia.
É por isso que as listas e registros de tokens existem como camadas de filtragem off-chain. Eles fornecem uma maneira de mapear o conceito de 「WETH」 para um endereço específico, o que explica por que carteiras e interfaces front-end mantêm listas brancas ou dependem de plataformas agregadoras confiáveis. Para agentes, o problema central não é apenas a baixa confiabilidade dos metadados, mas o fato de que identidades padrão geralmente são estabelecidas em níveis sociais ou institucionais, e não nativamente pelo protocolo. Identificadores on-chain confiáveis são endereços de contratos; no entanto, mapear intenções humanas, como 「trocar por USDC」, para os endereços corretos ainda depende fortemente de filtragem, registros, listas brancas ou outras camadas de confiança não nativas ao protocolo.
Fricção de dados
Agentes que otimizam a alocação entre protocolos de finanças descentralizadas precisam padronizar cada oportunidade como um objeto econômico: rendimento, profundidade de liquidez, parâmetros de risco, estrutura de taxas, fontes de oráculo, entre outros. De certa forma, trata-se de um problema comum de integração de sistemas. No entanto, na blockchain, a heterogeneidade dos protocolos, exposição direta ao capital, concatenação de estados de múltiplas chamadas e a ausência de um modelo econômico unificado subjacente agravam ainda mais essa carga — elementos essenciais para comparar oportunidades, simular alocações e monitorar riscos.
As blockchains geralmente não expõem objetos econômicos padronizados no nível do protocolo. Elas expõem slots de armazenamento, logs de eventos e saídas de funções, dos quais os objetos econômicos precisam ser inferidos ou reconstruídos. O protocolo garante apenas que as chamadas de contrato retornem os valores de estado corretos, mas não garante que esses valores possam ser claramente mapeados para conceitos econômicos legíveis, nem que os mesmos conceitos econômicos possam ser recuperados por meio de uma interface consistente entre protocolos.
Portanto, conceitos abstratos como mercado, posição e coeficiente de saúde não são primitivos do protocolo. Eles são reconstituídos off-chain por indexadores, plataformas de análise de dados, interfaces front-end e APIs, transformando o estado heterogêneo do protocolo em abstrações utilizáveis. Os usuários humanos geralmente veem apenas essa camada padronizada. Agentes também podem usar essa camada, mas acabam herdando modelos, atrasos e suposições de terceiros; caso contrário, precisam reconstituir essas abstrações por conta própria.
Esse problema torna-se cada vez mais evidente em diversos protocolos. Os preços das cotas do tesouro, as taxas de colateralização dos mercados de empréstimos, a profundidade da liquidez dos pools de trocas descentralizadas e as taxas de recompensa dos contratos de staking são componentes fundamentais com significado econômico, mas não possuem interfaces padronizadas para exposição. Cada tipo de protocolo possui seus próprios métodos de obtenção, estruturas e convenções de unidades. Mesmo dentro da mesma categoria, as implementações variam.
Mercado de empréstimos: buscar casos típicos fragmentados
O mercado de empréstimos reflete claramente esse problema. Seus conceitos econômicos são universais e aproximadamente uniformes, como liquidez de oferta e empréstimo, taxas de juros, taxa de colateral, limite de crédito e limiar de liquidação, mas os caminhos para acessá-los variam.
No Aave v3, a enumeração de mercado e a obtenção do estado da reserva são dois passos independentes. O fluxo típico é o seguinte:
Listar ativos de reserva por meio do seguinte método, retornando a matriz de endereços de tokens.

Para cada ativo, obtenha os dados básicos de liquidez e taxa de juros por meio de outro snippet de código,

Este método retorna, em uma única chamada, uma estrutura contendo o total de liquidez, o índice de juros e as bandeiras de configuração, por exemplo:
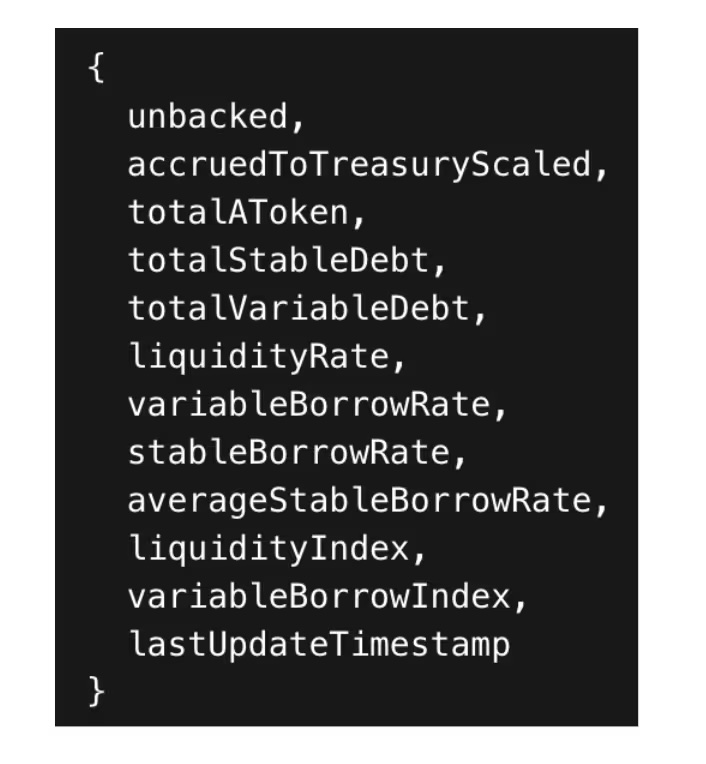
Em comparação, no Compound v3, cada implantação corresponde a um único mercado (USDC, USDT, ETH, etc.) e não possui uma estrutura de reserva unificada. Em vez disso, é necessário reunir snapshots do mercado por meio de múltiplas chamadas de função:
- Utilização básica
- Total
- Taxa de juros
- Configuração de ativos colaterais
- Parâmetros de configuração global
Cada chamada retorna apenas um subconjunto diferente do estado econômico. O "mercado" não é um objeto de primeiro nível, mas sim uma estrutura inferida montada pelo chamador.
Do ponto de vista do agente, ambos os protocolos são mercados de empréstimo; no entanto, do ponto de vista da integração, são sistemas de obtenção com estruturas completamente diferentes. Não existe um modelo compartilhado unificado. Em vez disso, os agentes devem utilizar métodos distintos de enumeração de ativos para cada protocolo, combinando estados por meio de múltiplas chamadas.
Fragmentação traz riscos de latência e consistência
Além da inconsistência estrutural, essa fragmentação introduz riscos de latência e consistência. Como o estado econômico não é exposto como um único objeto de mercado atômico, os agentes devem reconstruir instantâneos por meio de múltiplas chamadas remotas de procedimento entre vários contratos. Cada chamada adicional aumenta a latência, o risco de limitação e a probabilidade de inconsistência entre blocos. Em ambientes voláteis, quando o cálculo da taxa de oferta for concluído, a taxa já pode ter mudado; sem bloqueio explícito do bloco, os parâmetros de configuração podem corresponder a alturas de bloco diferentes da quantidade total de liquidez. Os usuários dependem de camadas de cache UI e backends agregados para mitigar indiretamente esses problemas. Agentes que operam diretamente nas interfaces RPC originais devem gerenciar explicitamente sincronização, loteamento e consistência temporal. Portanto, a recuperação não padronizada não apenas causa inconvenientes na integração, mas também limita desempenho, sincronização e correção.
Devido à ausência de um esquema padronizado para a recuperação de dados econômicos, mesmo que os protocolos implementem primitivos financeiros quase idênticos, sua exposição de estado depende das especificidades e da composição dos contratos. Essas diferenças estruturais são componentes centrais da fricção de dados.
Possível incompatibilidade no fluxo de dados
O acesso ao estado econômico na blockchain é intrinsicamente um modelo de puxar, mesmo que os sinais de execução possam ser transmitidos em fluxo. Sistemas externos consultam os nós para obter o estado desejado, em vez de receber atualizações contínuas e estruturadas. Esse modelo reflete a função central da blockchain: validação sob demanda, em vez de manter uma visão contínua do estado ao nível da aplicação.
Push primitives exist. WebSocket subscriptions can stream new blocks and event logs in real time, but these do not include the stored state that carries most of the economic significance, unless the protocol explicitly chooses to redundantly publish them. Agents cannot directly subscribe on-chain to borrow market utilization, pool reserves, or position health factors. These values are stored in contract storage, and most protocols do not provide native mechanisms to push this information downstream to consumers. The current optimal pattern is to subscribe to new block headers and re-query on each block. Logs can only indicate that state may have changed, but they do not encode the final economic state; reconstructing this state still requires explicit reads and historical state access.
O sistema de agentes pode se beneficiar de um fluxo reverso. Em vez de consultar centenas de contratos em busca de mudanças de estado, os agentes podem receber atualizações de estado estruturadas e pré-calculadas, enviadas diretamente para o ambiente de execução. A arquitetura push reduz consultas redundantes, diminui a latência entre mudanças de estado e a percepção do agente, e permite que camadas intermediárias empacotem o estado em atualizações semanticamente claras, em vez de exigir que os agentes interpretem o significado a partir do armazenamento bruto.
Essa inversão não é fácil. Ela exige infraestrutura de assinatura, lógica para filtrar relevância e padrões para transformar alterações de armazenamento em eventos econômicos executáveis por agentes. Mas à medida que os agentes se tornam participantes contínuos, em vez de consultores intermitentes, o custo da ineficiência do modelo de pull torna-se cada vez mais elevado. Talvez seja mais adequado considerar a infraestrutura como destinada a agentes como consumidores contínuos, e não como clientes intermitentes, alinhando-se melhor ao modo como os sistemas autônomos operam.
Se a infraestrutura push é realmente superior ainda é uma questão em aberto. Grandes volumes de alterações de estado criam desafios de filtragem, e os agentes ainda precisam determinar quais alterações são relevantes, reintroduzindo, em outro nível, a semântica pull. O problema não está na arquitetura pull em si, mas no fato de que a arquitetura atual não considera consumidores de máquina persistentes; à medida que o uso de agentes cresce, pode valer a pena explorar outros modelos alternativos.
Executar atrito
A geração de fricção ocorre porque muitas camadas de interação atuais empacotam a conversão de intenções, a revisão de transações e a verificação de resultados em fluxos de trabalho projetados em torno da interface do usuário, carteiras e supervisão operacional. Em cenários envolvendo investidores individuais e decisões subjetivas, esse controle geralmente é realizado por humanos. Para sistemas autônomos, essas funções devem ser formalizadas e codificadas diretamente. Embora a blockchain garanta execução determinística com base na lógica do contrato, ela não garante que as transações estejam alinhadas com a intenção do usuário, respeitem restrições de risco ou alcancem resultados econômicos esperados. Nos fluxos atuais, a interface do usuário e os humanos preenchem essa lacuna.
Sequência de operações combinadas na interface do usuário (troca, autorização, depósito, empréstimo), a carteira fornece o nó final de “revisar e enviar”, onde o usuário ou operador geralmente toma uma decisão estratégica informal na última etapa. Eles frequentemente avaliam se a transação é segura e se os resultados da cotação são aceitáveis, mesmo com informações incompletas. Se a transação falhar ou ocorrer um resultado inesperado, o usuário tentará novamente, ajustará o deslizamento, alterará o caminho ou simplesmente desistirá da operação. O sistema de agentes remove o ser humano desse ciclo de execução. Isso significa que o sistema deve substituir as três funções humanas por meios nativos da máquina:
- Integração de intenções. Objetivos humanos, como “transferir meus stablecoins para o local de retorno otimizado ajustado ao risco”, devem ser integrados em planos de ação específicos: escolher qual protocolo, qual mercado, qual caminho de token, qual escala e quais autorizações, bem como a ordem de execução. Para humanos, esse processo é realizado implicitamente por meio da interface do usuário; para agentes inteligentes, deve ser implementado de forma formalizada.
- Execução da estratégia. Clicar em "Enviar transação" não é apenas uma assinatura, mas também uma verificação implícita de que a transação atende às restrições: tolerância a slippage, limite de alavancagem, coeficiente mínimo de saúde, contrato na lista branca ou "contratos upgradeáveis proibidos". O agente deve codificar as restrições estratégicas explícitas como regras verificáveis por máquina:
- O sistema de execução deve verificar se o gráfico de chamadas proposto atende a essas regras antes da transmissão.
- Verificação dos resultados. A transação na blockchain não equivale à conclusão da tarefa. Mesmo com execução bem-sucedida da transação, o objetivo pode não ter sido atingido: o slippage pode ter excedido o limite tolerável, o tamanho da posição-alvo pode não ter sido alcançado devido a limites de quota, ou as taxas podem ter mudado entre a simulação e a execução na blockchain. Humanos verificam informalmente por meio da interface do usuário após o fato. Agentes inteligentes devem avaliar programaticamente as pós-condições.
Isso introduz a necessidade de verificação completa, e não apenas a simples inclusão da transação. A arquitetura centrada em intenções pode resolver parcialmente esse problema, transferindo a maior parte da carga de "como" executar dos agentes para solucionadores especializados. Ao transmitir intenções assinadas em vez de dados de chamada brutos, os agentes podem especificar restrições baseadas em resultados que os solucionadores ou mecanismos de nível de protocolo devem satisfazer para que a execução seja aceitável.
Fluxo de trabalho em várias etapas e modos de falha
A maioria das operações executadas na finança descentralizada é intrinsicamente multietapa. Um ajuste de rendimento pode exigir autorização → conversão → depósito → empréstimo → staking. Algumas etapas podem ser transações independentes, enquanto outras podem ser agrupadas por meio de contratos de multi-chamada ou roteamento. Humanos toleram parcialidades e retornam à interface do usuário para continuar o processo. Agentes exigem orquestração de fluxo determinística: se qualquer etapa falhar, o agente deve decidir se repetirá, redirecionará, fará rollback ou pausará.
Isso gerou novos modos de falha amplamente ocultos nos processos humanos:
- Desvio de estado entre a decisão e a execução na cadeia. Entre simulação e execução, as taxas de juros, a utilização ou a liquidez podem mudar. Humanos aceitam essa variabilidade; agentes devem definir faixas aceitáveis e aplicá-las.
- Execução não atômica e parcial. Algumas operações podem ser executadas em várias transações ou gerar resultados parciais. O agente deve rastrear o estado intermediário e confirmar que o estado final está alinhado com o objetivo.
- Limite de autorização e risco de aprovação. Humanos assinam automaticamente autorizações por meio da interface do usuário; agentes inteligentes devem raciocinar sobre o escopo da autorização (limite, usuário, prazo) como parte da política de segurança, e não apenas como um passo da interface do usuário.
- Escolha de caminho e custos de execução implícitos. Humanos dependem de contratos de roteamento e configurações padrão da interface do usuário. Agentes devem incorporar slippage, risco de valor extraível máximo, custos de gas e impacto de preço na função objetivo.
Executar: Problema de controle nativo da máquina
O argumento central sobre a fricção de execução é que a camada de interação da finança descentralizada utiliza assinaturas de carteiras humanas como plano de controle final. Essa etapa carrega a verificação atual de intenção, tolerância ao risco e julgamentos informais de “se é razoável”. Ao remover o ser humano, a execução torna-se um problema de controle: os agentes devem traduzir objetivos em padrões de comportamento, executar automaticamente restrições de estratégia e validar resultados sob incerteza. Esse desafio existe em muitos sistemas autônomos, mas o ambiente de blockchain é particularmente rigoroso: a execução envolve diretamente capital, contratos desconhecidos combináveis e expõe-se a mudanças de estado adversárias. Humanos tomam decisões por meio de heurísticas e corrigem erros por tentativa e erro. Agentes devem realizar o mesmo trabalho programaticamente à velocidade da máquina, geralmente em espaços de comportamento dinâmicos e em constante mudança. Portanto, a afirmação de que “os agentes apenas precisam enviar transações” subestima a dificuldade. Enviar transações é a parte mais simples.
Conclusão
O design original da blockchain não foi criado para fornecer nativamente a camada semântica e de coordenação necessárias aos agentes. Seu objetivo é garantir execução determinística e consenso sobre transições de estado em ambientes adversos. A camada de interação construída sobre essa base evoluiu em torno do modelo em que usuários humanos interpretam o estado por meio de interfaces, selecionam ações por meio de interfaces front-end e validam resultados por meio de revisão humana.
Os sistemas de agentes revolucionaram essa arquitetura. Eles removem os analistas humanos, aprovadores e validadores do ciclo, exigindo que essas funções sejam implementadas nativamente por máquinas. Essa transformação expõe atritos estruturais em quatro dimensões: descoberta, avaliação de crédito, obtenção de dados e processos de execução. Esses atritos surgem não porque a execução seja inviável, mas porque a infraestrutura ao redor da blockchain, na maioria dos casos, ainda assume a presença de intervenção humana entre a interpretação do estado e a submissão da transação.
Para preencher essas lacunas, é provável que seja necessário construir novas infraestruturas em múltiplas camadas de tecnologia: normalizar o estado econômico entre protocolos em middleware legível por máquina; serviços de indexação ou extensões de chamada remota para primitivas semânticas como posições, coeficientes de saúde e conjuntos de oportunidades; um registro que forneça mapeamento padrão de contratos e verificação de autenticidade de tokens; e um framework de execução que codifique restrições de estratégia, processe fluxos de trabalho em múltiplos passos e valide programaticamente a conclusão de objetivos. Algumas lacunas decorrem das características estruturais de sistemas sem permissão: implantação aberta, identidade padrão fraca e interfaces heterogêneas. Outras dependem das ferramentas, padrões e design de incentivos atuais; à medida que a escala de uso dos agentes aumenta e os protocolos competem para otimizar a integração com sistemas autônomos, essas lacunas tendem a se reduzir.
À medida que sistemas autônomos começam a gerenciar capital, executar estratégias e interagir diretamente com aplicações on-chain, as suposições arquiteturais da camada de interação atual se tornarão cada vez mais evidentes. A maior parte da fricção descrita neste artigo reflete o fato de que as ferramentas e modelos de interação blockchain evoluíram em torno de fluxos de trabalho com intermediários humanos; parte da fricção decorre da abertura, heterogeneidade e ambiente adversarial dos sistemas sem permissão; e outra parte é um problema comum enfrentado por sistemas autônomos em ambientes complexos.
O desafio central não é fazer com que o agente assine transações, mas sim fornecer-lhe um caminho confiável para realizar a interpretação semântica, a avaliação de crédito e a execução de estratégias, tarefas atualmente compartilhadas entre software e julgamento humano entre o estado da blockchain e o comportamento operacional.