
Ingin tahu model besar mana yang paling kuat dalam tugas agen dunia nyata OpenClaw?
MyToken telah mengumpulkan satu set penilaian telus yang berfokus pada kemampuan sebenar agen pengkodean AI, berdasarkan data dari laman web penilaian, dengan hanya mempertimbangkan satu dimensi utama: kejayaan (kelajuan dan kos adalah dimensi berasingan yang akan dianalisis secara berasingan kemudian). Sepenuhnya terbuka dan boleh diulang, hanya menunjukkan standard penilaian yang ketat + senarai 10 teratas kejayaan terkini.
Satu: Dimensi Penilaian: Kep Berjaya
Kriteria spesifik: Peratusan tugas yang diselesaikan secara lengkap dan tepat oleh agen AI. Setiap tugas menggunakan proses yang sangat standard:
Prompt pengguna yang tepat
Send to agent in full to simulate real user request scenario
Perilaku yang dijangka
Menerangkan cara pelaksanaan yang diterima dan titik keputusan utama
Kriteria penilaian (senarai semak)
Senaraikan senarai pemeriksaan kejayaan atomik yang boleh diperiksa satu per satu
Dua: Tiga cara penilaian
Penilaian ini utamanya menggunakan tiga kaedah penilaian.
Pemeriksaan automatik: Skrip Python secara langsung mengesahkan kandungan fail, rekod pelaksanaan, panggilan alat, dan hasil objektif lain
Pengadil model LLM besar: Claude Opus memberi skor mengikut skala terperinci (kualiti kandungan, kesesuaian, kelengkapan, dll)
Mod campuran: Pemeriksaan objektif automatik + penilaian kualitatif oleh LLM sebagai hakim
Semua definisi tugas, Prompt, dan logik penilaian dibuka kepada umum untuk tujuan pengesahan semula.
Tiga, tugas yang digunakan untuk penilaian
Ujian piawai ini merangkumi 23 kategori tugas yang berbeza, mencakupi interaksi asas, operasi fail/ kod, penciptaan kandungan, analisis penyelidikan, pemanggilan alat sistem, pemertahanan memori, dan banyak lagi dimensi, yang sangat rapat dengan skenario penggunaan harian pembangun terhadap OpenClaw:
Pemeriksaan Kewajaran (automasi) — Menangani arahan mudah dan membalas salam dengan betul
Penciptaan Acara Kalender (otomatisasi) — Penghasil fail kalender ICS standard dalam bahasa semula jadi
Penyelidikan Harga Saham (automasi) — Mencari harga saham secara langsung dan menghasilkan laporan berformat
Blog Post Writing (LLM Judge) — Tulis satu blog post berstruktur dalam Markdown sebanyak kira-kira 500 patah perkataan
Penciptaan Skrip Cuaca (automasi) — Menulis skrip API cuaca Python dengan penanganan ralat
Ringkasan Dokumen (Pengadil LLM) — Ringkasan ringkas tiga bahagian bagi tema utama
Penyelidikan Konferensi Teknologi (Pengadil LLM) — Mengumpul dan menyusun maklumat 5 konferensi teknologi sebenar (nama, tarikh, tempat, pautan)
Penyusunan E-mel Profesional (Pengadil LLM) — Menolak mesyuarat dengan sopan dan mencadangkan alternatif
Pengambilan Memori dari Konteks (automasi) — mengekstrak secara tepat tarikh, ahli, teknologi, dll daripada nota projek
Penciptaan Struktur Fail (automasi) — Menghasilkan direktori projek standard, README, .gitignore secara automatik
Alur API Langkah Berbilang (Campuran) — Baca konfigurasi → Tulis skrip panggilan → Dokumentasi penuh
Pasang Kecek ClawdHub (automasi) — Pasang dan sahkan ketersediaan daripada gudang kecek
Cari dan Pasang Kemahiran (automasi) — Cari kemahiran cuaca dan pasang dengan betul
Penghasilan Gambar AI (Campuran) — Hasilkan dan simpan gambar mengikut huraian
Manusia kan AI-Generasi Blog (Pengadil LLM) — Tukar kandungan yang kelihatan mesin kepada gaya percakapan alami
Ringkasan Penyelidikan Harian (Pengadil LLM) – Menggabungkan beberapa dokumen menjadi ringkasan harian yang lancar
Pengelasan Kotak Masuk Email (Campuran) — Analisis beberapa e-mel dan susun laporan mengikut kepentingan
Pencarian dan Ringkasan E-mel (Campuran) — Mencari e-mel arsip dan merumuskan maklumat utama
Penyelidikan Pasar yang Kompetitif (Campuran) — Analisis Pesaing di Bidang APM Perusahaan
Peng Ringkasan CSV dan Excel (Campuran) — Menganalisis fail jadual dan mengeluarkan wawasan
Ringkasan PDF ELI5 (Pengadil LLM) — Terangkan PDF teknikal dengan bahasa yang boleh difahami oleh kanak-kanak berumur 5 tahun
Pemahaman Laporan OpenClaw (automasi) — Menjawab soalan tertentu dengan tepat daripada PDF laporan penyelidikan
Kekal Pengetahuan Otak Kedua (Campuran) — Menyimpan dan mengingat semula maklumat secara lintas sesi
Empat: Kesimpulan Utama: Peringkat 10 Model Teratas Berdasarkan Kep Berjaya (%/Avg %)
Data dikemas kini hingga 7 April 2026
% Terbaik ialah kejayaan tertinggi sekali jalan, % Purata ialah purata kejayaan berulang, yang lebih mencerminkan kestabilan
Berikut adalah sepuluh model dengan kejayaan tertinggi
anthropic/claude-opus-4.6 (Anthropic) —— 93.3% / 82.0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91.9% / 91.9%
openai/gpt-5.4 (OpenAI) —— 90.5% / 81.7%
qwen/qwen3.5-27b (Qwen) —— 90.0% / 78.5%
minimax/minimax-m2.7 (MiniMax) — 89.8% / 83.2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89.5% / 78.1%
qwen/qwen3.5-397b-a17b (Qwen) —— 89.1% / 80.4%
xiaomi/mimo-v2-flash(Xiaomi)——88.8% / 70.2%
qwen/qwen3.6-plus-preview (Qwen) —— 88.6% / 84.0%
nvidia/nemotron-3-super-120b-a12b(NVIDIA)——88.6% / 75.5%
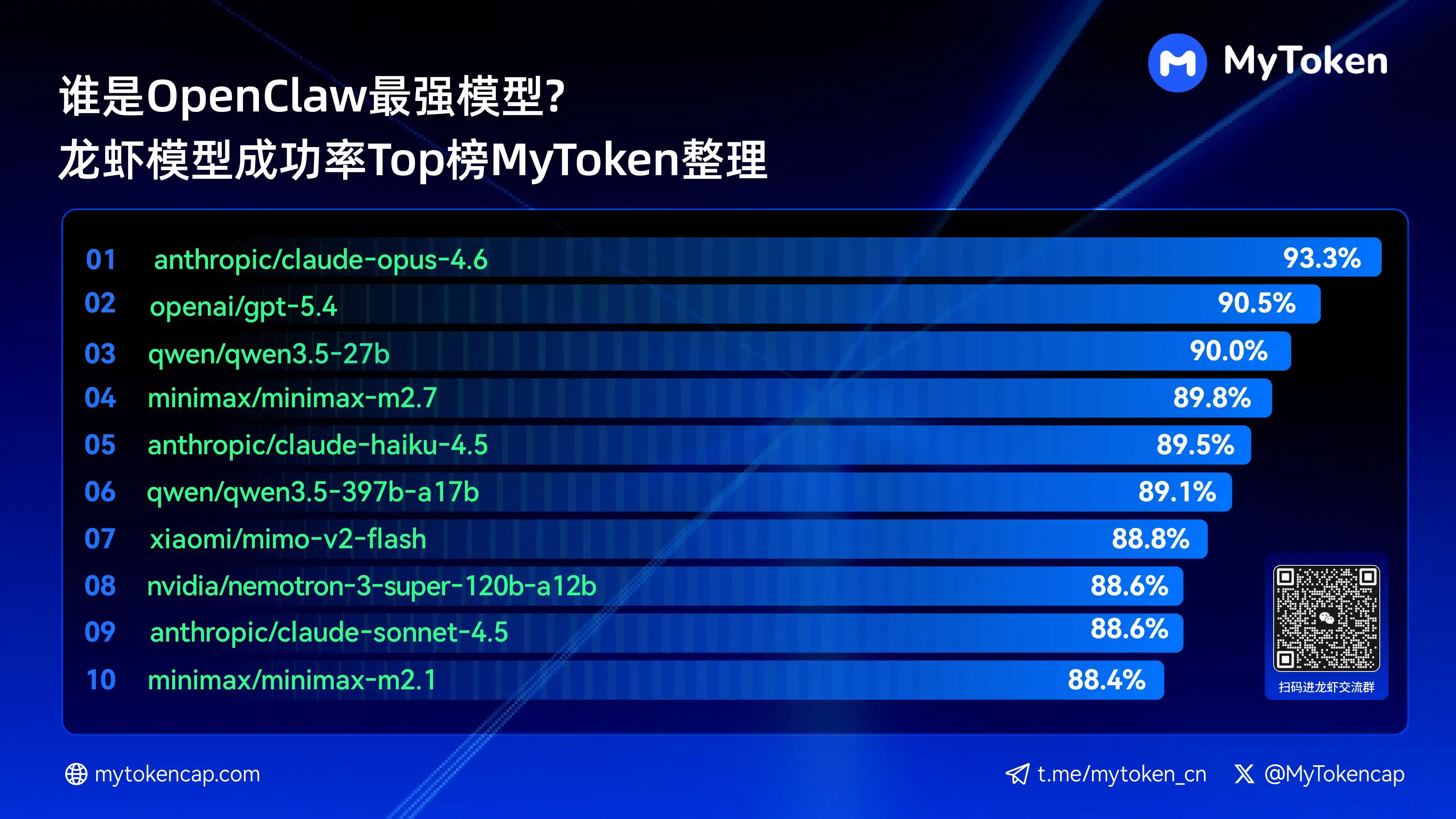
Claude Opus 4.6 kini memimpin dengan kadar kejayaan tertinggi sebanyak 93.3%, tetapi Trinity milik Arcee menunjukkan prestasi yang menonjol dalam kestabilan purata, sementara siri Qwen juga memiliki beberapa model masuk sepuluh besar, menunjukkan potensi nilai yang sangat baik. Kadar kejayaan adalah ambang asas, manakala kelajuan dan kos akan mempengaruhi pengalaman sebenar pada tahap seterusnya.
Benchmarks tugas 23 ini sepenuhnya telus, dan kami sangat menyarankan anda menguji secara praktikal mengikut skenario masing-masing. Untuk peringkat model lain, tunggu fungsi senarai peringkat agen MyToken yang akan datang.
(Data berasal daripada ujian rujukan OpenClaw proxy yang diumumkan oleh PinchBench, sedang dikemas kini secara berterusan.)