









Penulis asli: David, DeepTide TechFlow
Pada tanggal 20 Januari, X merilis algoritma rekomendasi versi baru secara open source.
Balasan yang dikirim Musk cukup menarik: "Kita tahu algoritma ini sangat bodoh dan masih perlu banyak perubahan, tapi setidaknya kamu bisa melihat kita berjuang secara real-time untuk memperbaikinya. Platform media sosial lain tidak berani melakukan ini."
Kalimat ini memiliki dua makna.Pertama, mengakui bahwa algoritma memiliki masalah, kedua, menjadikan "transparansi" sebagai nilai jual.
Ini adalah algoritma sumber terbuka kedua dari X. Versi kode pada 2023 tidak diperbarui selama tiga tahun, jauh berbeda dari sistem aktual. Kali ini sepenuhnya ditulis ulang, model inti beralih dari pembelajaran mesin tradisional ke Grok transformer, menurut pernyataan resmi, "secara menyeluruh menghilangkan rekayasa fitur manual."
Dulunya, algoritma mengandalkan insinyur untuk menyetel parameter secara manual, sekarang AI langsung melihat riwayat interaksi Anda untuk memutuskan apakah konten Anda akan ditampilkan atau tidak.
Bagi para kreator konten, ini berarti mitos lama seperti "pukul berapa posting terbaik" atau "menggunakan tag apa untuk menambah pengikut" mungkin tidak berlaku lagi.
Kami juga menelusuri repositori Github open source, dengan bantuan AI, kami menemukan bahwa memang ada beberapa logika keras yang tersembunyi di dalam kode, yang patut untuk diungkap.
Perubahan logika algoritma: dari definisi manual ke pengambilan keputusan otomatis oleh AI
Jelaskan dulu perbedaan versi lama dan baru, kalau tidak diskusi berikutnya akan menjadi kacau.
Pada 2023, versi yang dirilis Twitter bernama Heavy Ranker, intinya adalah pembelajaran mesin tradisional. Para insinyur harus mendefinisikan secara manual ratusan "fitur": apakah postingan ini memiliki gambar, berapa banyak pengikut penulisnya, seberapa dekat waktu posting dengan sekarang, apakah ada tautan di dalam postingan...
Kemudian beri bobot pada setiap fitur, atur dan sesuaikan, lihat kombinasi mana yang memberikan hasil terbaik.
Versi terbuka sumber kali ini disebut Phoenix, dengan arsitektur yang sama sekali berbeda. Kau bisa memahaminya sebagai algoritma yang lebih bergantung pada model AI besar. Intinya menggunakan model transformer Grok, yang menggunakan teknologi jenis yang sama dengan ChatGPT dan Claude.
Dokumen README resmi tertulis secara eksplisit: "Kami telah menghilangkan setiap fitur yang dirancang secara manual."
Semua aturan lama yang bergantung pada ekstraksi fitur konten secara manual telah dihapus tanpa ada yang tersisa.
Sekarang, algoritma ini mengandalkan apa untuk menentukan apakah suatu konten bagus atau tidak?
Jawabannya tergantung padamu.Sequences perilakuApa yang pernah kamu sukai, siapa yang pernah kamu balas, postingan apa saja yang pernah kamu tahan selama lebih dari dua menit, dan jenis akun apa saja yang pernah kamu sembunyikan. Phoenix memberi semua perilaku ini ke transformer, agar model dapat belajar sendiri menemukan pola dan membuat kesimpulan.
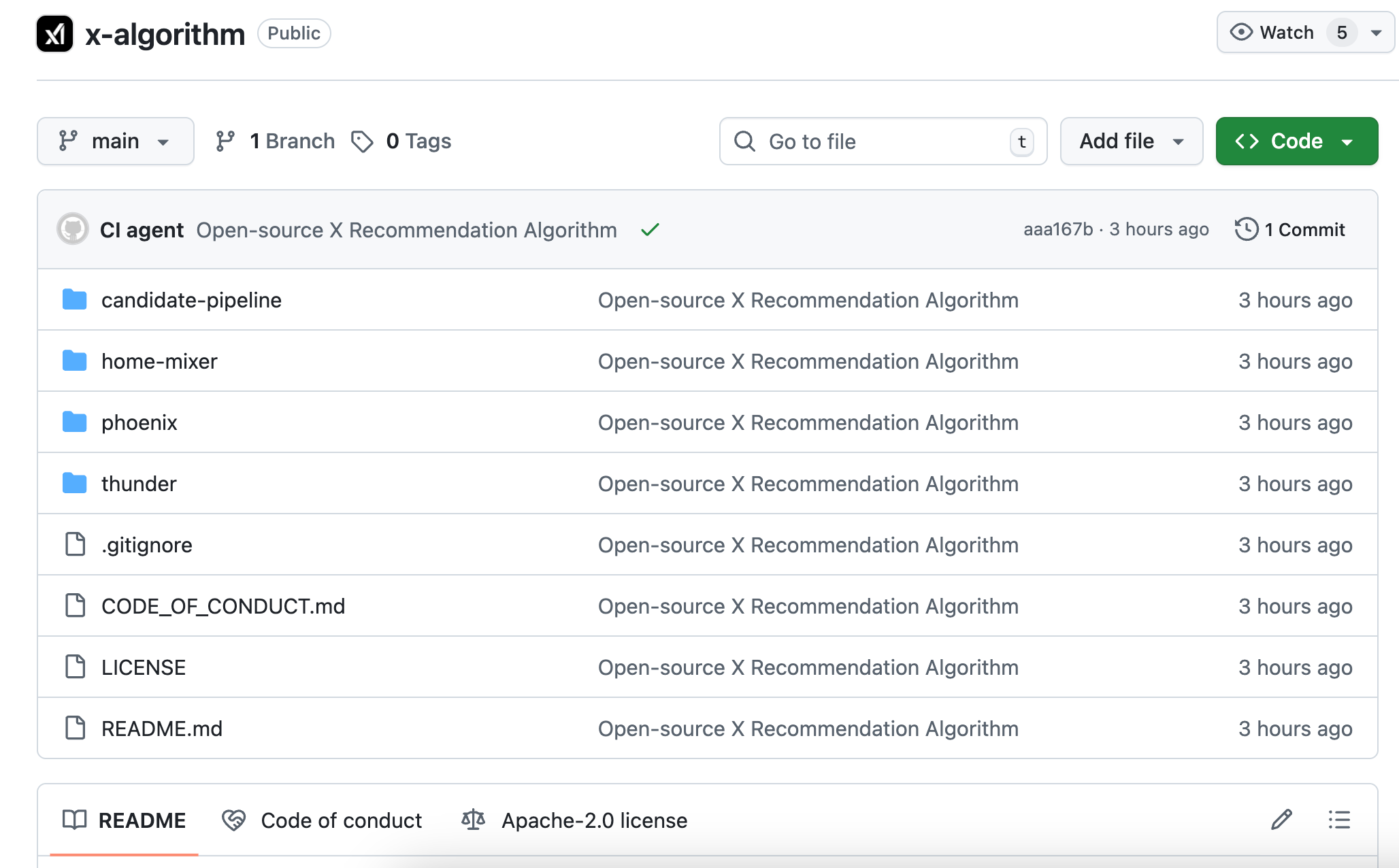
Sebagai contoh: algoritma lama seperti daftar penilaian yang dibuat secara manual, setiap item dicentang dan diberi skor;
Algoritma baru ini seperti AI yang telah melihat riwayat penjelajahan Anda,Tebak saja langsungApa yang ingin kamu tonton di detik berikutnya?
Bagi para pencipta, ini berarti dua hal:
Pertama, trik-trik seperti "waktu posting terbaik" atau "label emas" yang dulu pernah ada kini memiliki nilai referensi yang lebih rendah.Karena model tidak lagi melihat fitur tetap ini, model justru melihat preferensi pribadi setiap pengguna.
Kedua, apakah konten Anda bisa menyebar atau tidak, makin bergantung pada "bagaimana reaksi orang yang melihat konten Anda."Reaksi ini diukur dalam 15 prediksi perilaku, yang akan kita jelaskan lebih rinci di bab berikutnya.
Algoritma memprediksi 15 reaksi Anda
Setelah Phoenix mendapatkan postingan yang akan direkomendasikan, sistem akan memprediksi 15 perilaku yang mungkin dilakukan pengguna saat melihat konten tersebut:
- Perilaku positifseperti menyukai, membalas, meneruskan, meneruskan dengan menyebutkan, mengklik postingan, mengklik halaman utama penulis, menonton video lebih dari separuhnya, mengembangkan gambar, berbagi, berhenti selama jangka waktu tertentu, mengikuti penulis
- Perilaku negatif: Seperti mengklik "Tidak Tertarik", Memblokir penulis, Membisukan penulis, Melaporkan
Setiap tindakan memiliki probabilitas prediksi masing-masing. Misalnya, model menilai bahwa Anda memiliki kemungkinan 60% untuk menyukai postingan ini, 5% kemungkinan untuk memblokir penulisnya, dan seterusnya.
Kemudian algoritma melakukan sesuatu yang sederhana: mengalikan probabilitas-probabilitas ini dengan bobot masing-masing, menjumlahkannya, dan menghasilkan skor total.
Rumusnya terlihat seperti ini:
Skor Akhir = Σ (bobot × P(aksi) )
Bobot perilaku positif adalah bilangan positif, dan bobot perilaku negatif adalah bilangan negatif.
Posting dengan skor total tinggi akan berada di depan, sedangkan yang rendah akan tenggelam.
Sebenarnya, keluar dari formula itu berarti:
Sekarang ini, apakah suatu konten bagus atau tidak, tidak sepenuhnya ditentukan oleh seberapa bagus konten tersebut ditulis (tentu saja keterbacaan dan manfaat bagi orang lain adalah dasar dari penyebaran konten); melainkan lebih banyak bergantung pada "reaksi apa yang akan kamu lakukan terhadap konten ini". Algoritma tidak peduli kualitas postingan itu sendiri, yang penting adalah perilaku kamu.
Dengan cara berpikir ini, dalam situasi ekstrem, sebuah postingan vulgar yang membuat orang tidak bisa menahan diri untuk menanggapi dengan komentar mungkin akan mendapatkan skor lebih tinggi dibandingkan postingan berkualitas yang tidak ada interaksinya. Mungkin logika dasar sistem ini bekerja seperti itu.
Namun, versi algoritma open source yang baru tidak mengungkapkan nilai numerik dari bobot perilaku spesifik, tetapi versi 2023 telah mengungkapkannya.
Referensi versi lama: 1 laporan = 738 suka
Selanjutnya, kita bisa mengupas data dari tahun 2023, meskipun sudah usang, tetapi bisa membantumu memahami seberapa besar perbedaan "nilai" berbagai perilaku di mata algoritma.
Pada 5 April 2023, X memang pernah mempublikasikan kumpulan data bobot di GitHub.
Langsung ke angka:
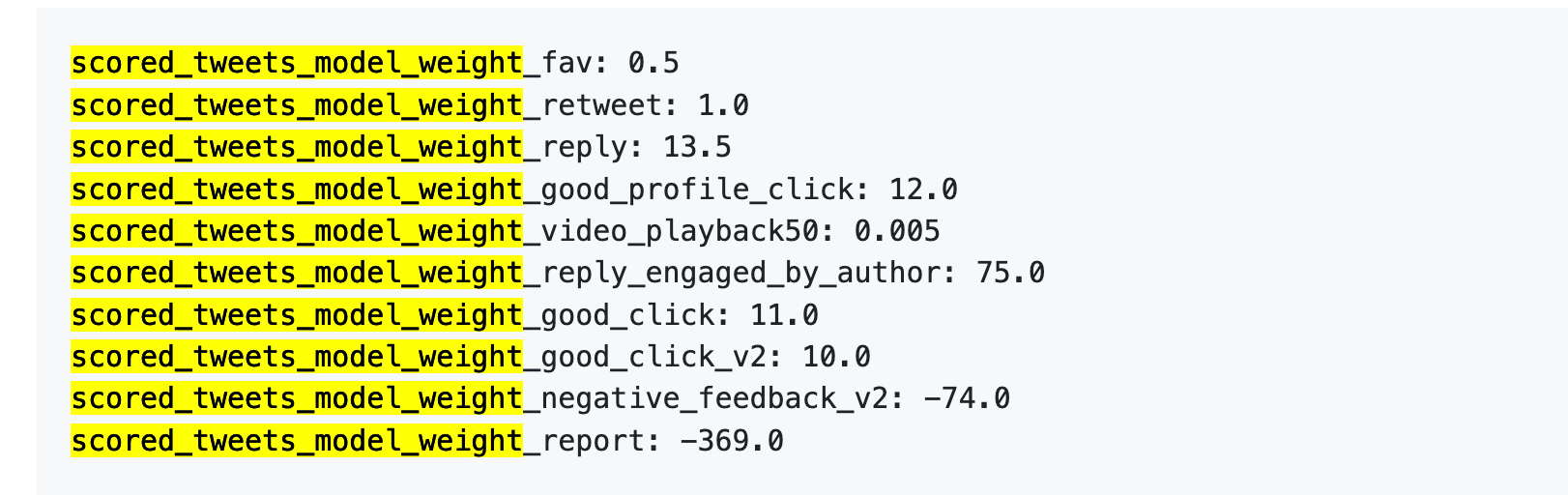
Terjemahkan lebih jelas lagi:
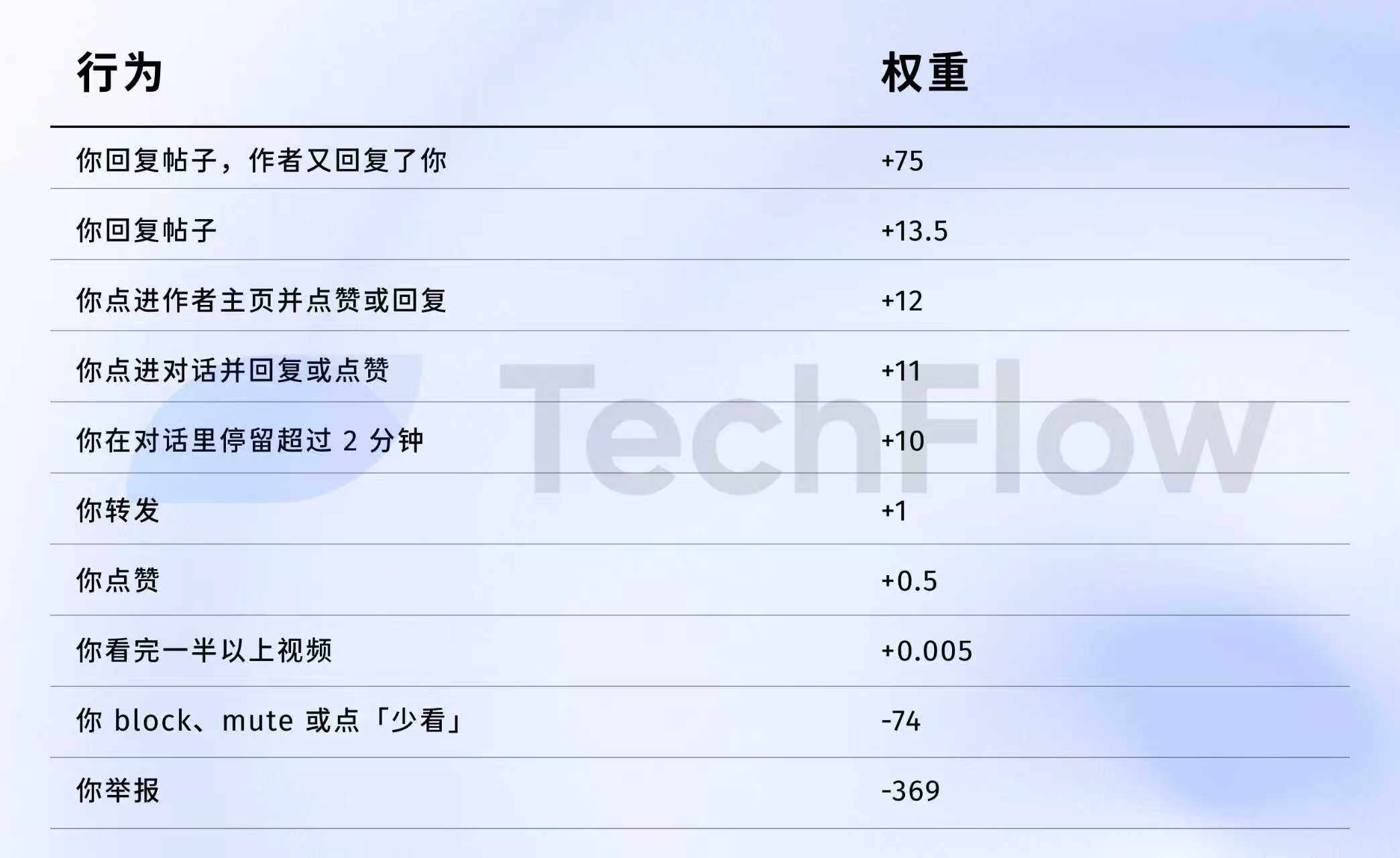
Sumber data: versi lama Repo GitHub twitter/the-algorithm-ml, klik untuk melihat algoritma aslinya
Beberapa angka patut diperhatikan secara mendalam.
Pertama, like hampir tidak bernilai apa-apa. Bobotnya hanya 0,5, yang merupakan nilai terendah di antara semua perilaku positif. Dalam pandangan algoritma, nilai dari satu kali like hampir sama dengan nol.
Kedua, interaksi dialog yang sebenarnya adalah mata uang keras. Bobot dari "kamu membalas dan penulis membalas kembali" adalah 75, yang setara dengan 150 kali dari bobot suka. Algoritma paling menginginkan dialog dua arah, bukan sekadar suka satu arah.
Ketiga, biaya umpan balik negatif sangat tinggi. Satu kali pemblokiran atau pembungkaman (-74) memerlukan 148 kali tindakan setuju untuk menetralisirnya. Satu kali pelaporan (-369) memerlukan 738 kali tindakan setuju. Selain itu, poin negatif ini akan terakumulasi ke dalam skor reputasi akun Anda, yang akan memengaruhi distribusi semua postingan berikutnya.
Keempat, bobot tingkat penonton video yang menonton hingga selesai sangat rendah. Hanya 0,005, hampir bisa diabaikan. Ini kontras tajam dengan Douyin dan TikTok, dua platform tersebut menjadikan tingkat penonton sampai selesai sebagai indikator utama.
Secara resmi dalam dokumen yang sama juga tertulis: "Bobot eksak dalam file dapat disesuaikan kapan saja... Sejak saat itu, kami secara berkala telah menyesuaikan bobot untuk mengoptimalkan metrik platform."
Bobot bisa berubah kapan saja, dan memang pernah diubah.
Versi terbaru tidak mengungkapkan angka spesifik, tetapi kerangka logika yang tertulis di README sama: penambahan poin positif, pengurangan poin negatif, dan perhitungan total dengan bobot.
Angka spesifik mungkin berubah, tetapi hubungan orde besarnya kemungkinan besar masih ada. Menjawab komentar orang lain jauh lebih bermanfaat dibandingkan mendapatkan 100 like. Membuat orang ingin memblokir Anda jauh lebih buruk dibandingkan tidak ada interaksi sama sekali.
Setelah mengetahui hal-hal ini, apa yang bisa kita lakukan sebagai pencipta?
Setelah mempelajari kode algoritma lama dan baru dari Twitter, berikut beberapa kesimpulan yang dapat diterapkan:
1. Menjawab komentarmu. Di tabel bobot, "penulis membalas komentar pengguna" adalah item dengan nilai tertinggi (+75), 150 kali lebih tinggi dari sekadar mendapatkan like dari pengguna. Ini bukan berarti kamu diminta untuk meminta komentar, tetapi jika ada yang mengomentari, balaslah. Bahkan jika hanya mengatakan "terima kasih", algoritma akan mencatatnya.
2. Jangan biarkan orang berpikir untuk pergi. Dampak negatif sekali memblokir membutuhkan 148 kali like untuk menetralisirnya. Konten kontroversial memang cenderung memicu interaksi, tetapi jika bentuk interaksinya adalah "orang ini mengganggu, blokir", nilai reputasi akun Anda akan terus terkena dampak negatif, yang akan memengaruhi distribusi semua postingan berikutnya. Lalu lintas kontroversial adalah pedang bermata dua, sebelum menghancurkan orang lain, hancurkan diri sendiri terlebih dahulu.
3. Tautan eksternal ditempatkan di bagian komentar.Algoritma tidak ingin mengalihkan pengguna ke luar situs. Konten dengan tautan akan dikurangi peringkatnya.Hal ini sendiri pernah diungkapkan secara terbuka oleh Musk. Jika ingin mengalihkan lalu lintas, tuliskan konten di dalam artikel utama, lalu letakkan tautannya di komentar pertama.
4. Jangan spam. Di versi kode terbaru terdapat Author Diversity Scorer, yang berfungsi untuk menurunkan bobot postingan yang muncul secara berurutan dari penulis yang sama. Tujuan desainnya adalah membuat feed pengguna lebih beragam, efek sampingnya adalah mengirim sepuluh postingan sekaligus tidak sebaik mengirim satu postingan berkualitas.
6. Tidak ada lagi "waktu terbaik untuk memposting". Algoritma lama memiliki fitur manual "waktu penerbitan", tetapi versi baru tiba-tiba saja menghilangkannya. Phoenix hanya memperhatikan sekuens perilaku pengguna, tanpa memperhatikan kapan postingan dibuat. Strategi-strategi seperti "efek terbaik ketika memposting pada pukul tiga sore hari Selasa" semakin kehilangan nilai referensinya.
Di atas adalah hal-hal yang bisa dibaca dari sisi kode.
Beberapa aturan tambahan dan pengurangan lainnya berasal dari dokumen resmi X, yang tidak termasuk dalam repositori open source kali ini: sertifikasi biru memberikan peningkatan, teks huruf kapital semua akan mengurangi bobot, dan konten sensitif dapat memicu pengurangan 80% dari tingkat penjangkauan. Karena aturan-aturan ini tidak di-open source-kan, maka tidak akan dijelaskan lebih lanjut.
Secara keseluruhan, hasil open source kali ini cukup memuaskan.
Arsitektur sistem yang lengkap, logika pemanggilan konten kandidat, proses peringkat dan penilaian, serta implementasi berbagai filter. Kode utamanya ditulis dalam Rust dan Python, struktur yang jelas, dan README-nya ditulis lebih rinci daripada banyak proyek komersial.
Tapi beberapa hal penting tidak diungkapkan.
1. Parameter bobot tidak diumumkan. Di dalam kode hanya tertulis "perilaku positif ditambah poin, perilaku negatif dikurangi poin," tetapi nilai spesifik untuk poin yang ditambahkan karena like, atau berapa poin yang dikurangi karena block, tidak disebutkan. Versi tahun 2023 setidaknya sudah menampilkan angka-angkanya, sedangkan kali ini hanya diberikan kerangka rumusnya saja.
2. Bobot model tidak diumumkan. Phoenix menggunakan Grok transformer, tetapi parameter dari model itu sendiri tidak disertakan. Kita bisa melihat bagaimana model dipanggil, tetapi tidak bisa melihat bagaimana perhitungan di dalam model.
3. Data pelatihan tidak diumumkan. Data apa saja yang digunakan untuk melatih model, bagaimana cara mengambil sampel perilaku pengguna, dan bagaimana cara membangun sampel positif dan negatif, semuanya tidak dijelaskan.
Sebagai analogi, kali ini open source seolah-olah mengatakan kepada kalian, "Kami menggunakan penjumlahan terboboti untuk menghitung skor total," tetapi tidak memberi tahu kalian berapa bobotnya; mengatakan kepada kalian, "Kami menggunakan transformer untuk memprediksi probabilitas perilaku," tetapi tidak memberi tahu kalian bagaimana bentuk transformer tersebut.
Secara横向比较 (perbandingan horizontal), TikTok dan Instagram bahkan belum pernah mengungkapkan informasi semacam ini. Jumlah informasi yang kali ini diungkapkan X (Twitter) memang lebih banyak dibandingkan platform utama lainnya. Namun, masih jauh dari "transparansi penuh."
Ini bukan berarti proyek sumber terbuka tidak memiliki nilai. Bagi para pencipta dan peneliti, melihat kode selalu lebih baik daripada tidak bisa melihatnya.