









Penulis:Tina, DongmeiInfoQ
1. Setelah hampir tiga tahun, Musk kembali merilis algoritma rekomendasi X secara open source.
Baru saja, tim insinyur X memposting pengumuman di X bahwa mereka secara resmi mengosifikasikan algoritma rekomendasi X. Menurut pengenalan mereka, perpustakaan open source ini mencakup sistem rekomendasi inti yang mendukung aliran informasi "Rekomendasi untuk Anda" di X. Sistem ini menggabungkan konten dalam jaringan (dari akun yang diikuti pengguna) dengan konten luar jaringan (ditemukan melalui pencarian berbasis machine learning), dan menggunakan model Transformer berbasis Grok untuk menilai semua konten. Dengan kata lain, algoritma ini menggunakan arsitektur Transformer yang sama dengan Grok.
Alamat sumber terbuka: https://x.com/XEng/status/2013471689087086804
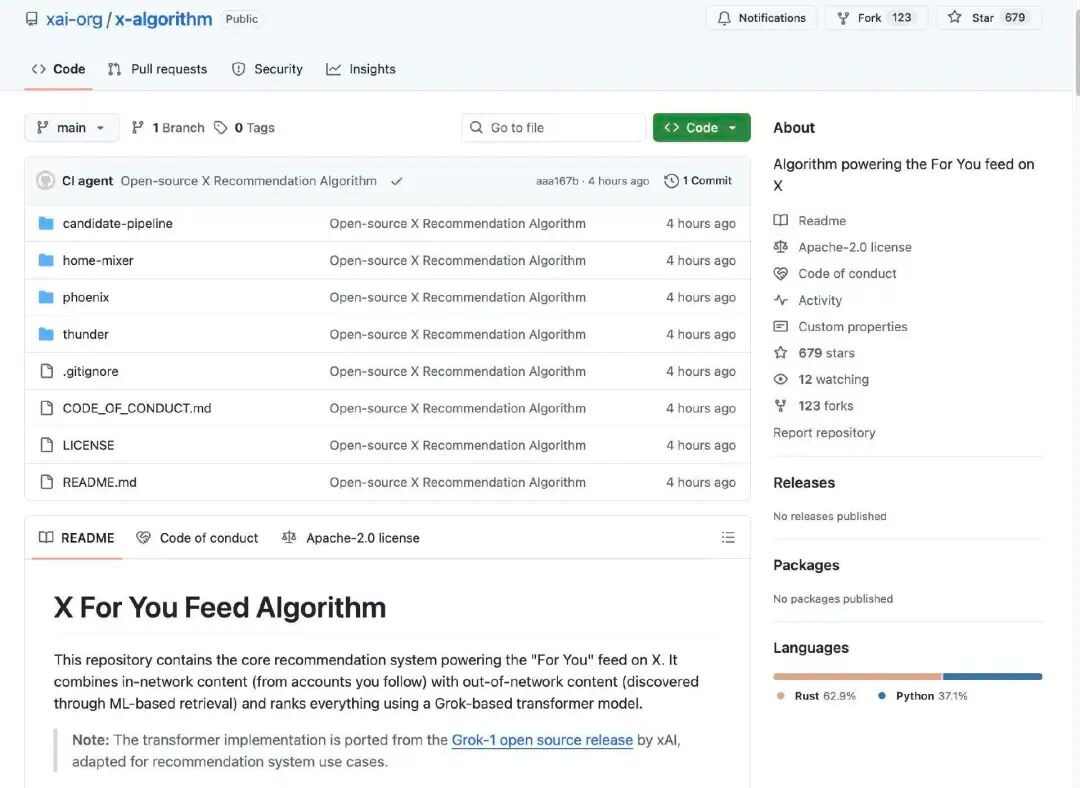
Algoritma rekomendasi X bertugas menghasilkan apa yang akan dilihat pengguna di halaman utama.Konten "Rekomendasi untuk Anda" (For You Feed)Ia mendapatkan posting kandidat dari dua sumber utama:
Akun yang Anda ikuti (In-Network / Thunder)
Posting lain yang ditemukan di platform (Out-of-Network / Phoenix)
Konten-konten kandidat ini kemudian diolah secara seragam, difilter, dan diurutkan berdasarkan tingkat relevansinya.
Lalu, bagaimana struktur inti dan logika eksekusi algoritma tersebut?
Algoritma terlebih dahulu mengumpulkan konten kandidat dari dua sumber berikut:
Isi yang Diperhatikan: Postingan dari akun yang secara aktif Anda ikuti.
Konten non-ikuti: Postingan yang mungkin menarik bagi Anda yang diambil dari seluruh kumpulan konten oleh sistem.
Tujuan tahap ini adalah "mencari posting yang mungkin relevan."
Sistem secara otomatis menghapus konten berkualitas rendah, duplikat, melanggar aturan, atau tidak pantas. Contoh:
Konten akun yang diblokir
Topik yang jelas tidak menarik minat pengguna
Posting ilegal, usang, atau tidak valid
Dengan demikian memastikan bahwa hanya konten kandidat yang bernilai yang diproses saat pengurutan akhir.
Inti dari algoritma yang dibuka sumber codenya kali ini adalah sistem menggunakan model Transformer berbasis Grok (mirip dengan model bahasa besar / jaringan pembelajaran dalam) untuk memberi skor pada setiap posting kandidat. Model Transformer memprediksi probabilitas setiap jenis tindakan berdasarkan perilaku sebelumnya dari pengguna (seperti menyukai, membalas, membagikan, mengklik, dll.). Pada akhirnya, probabilitas-probabilitas tindakan ini dikombinasikan dengan bobot tertentu menjadi skor komprehensif. Postingan dengan skor yang lebih tinggi lebih mungkin direkomendasikan kepada pengguna.
Desain ini secara dasar menghilangkan praktik lama mengekstrak fitur secara manual, beralih ke pendekatan pembelajaran ujung-ke-ujung (end-to-end) untuk memprediksi minat pengguna.
Ini bukan pertama kalinya Musk membuka sumber daya algoritma rekomendasi X.
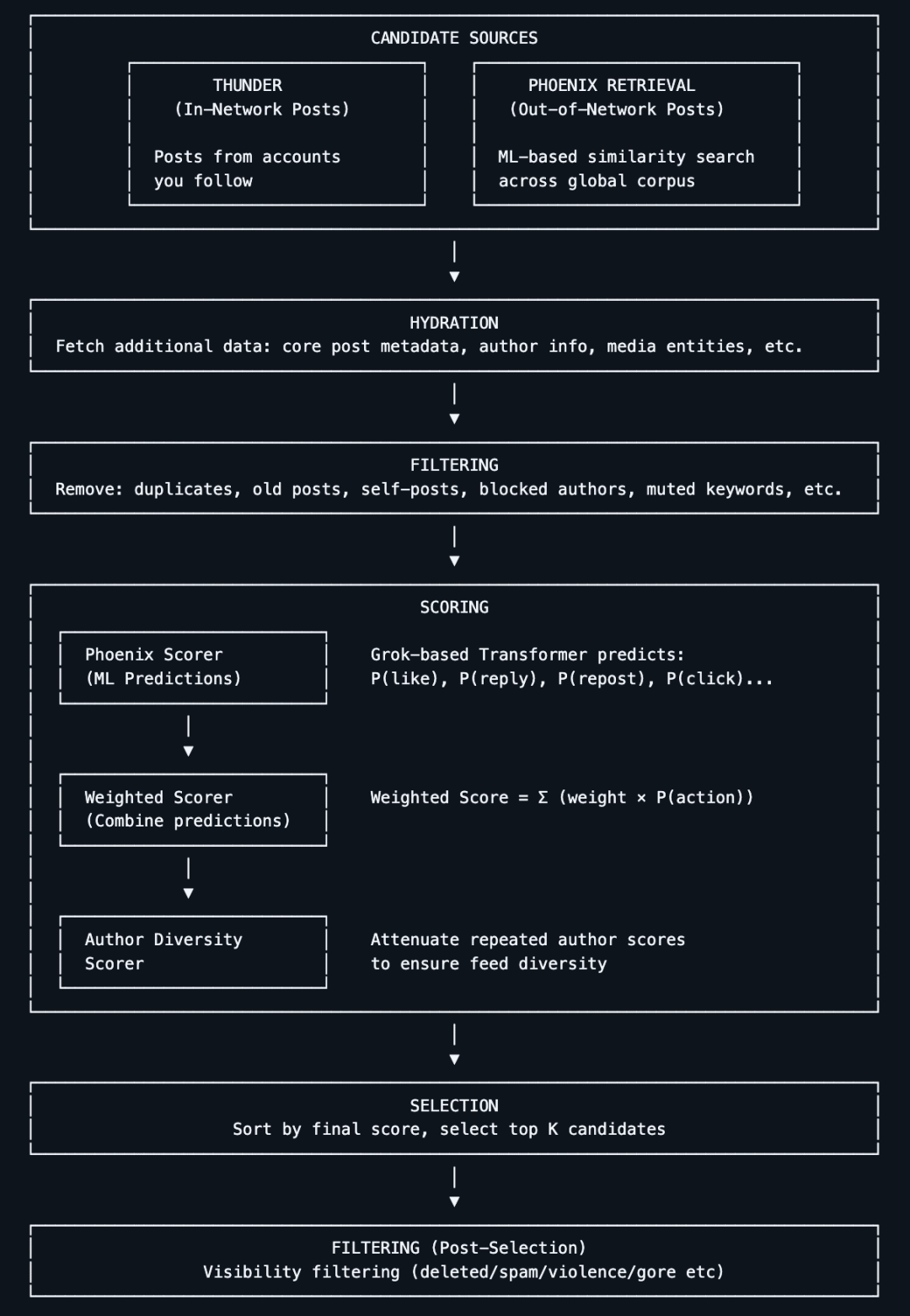
Sejak 31 Maret 2023, seperti yang dijanjikan oleh Musk ketika membeli Twitter, ia secara resmi mengumumkan kode sumber Twitter, termasuk algoritma yang digunakan untuk merekomendasikan tweet di timeline pengguna.Pada hari proyek open source, proyek ini telah mendapatkan 10k+ bintang di GitHub.
Pada saat itu, Musk menyatakan di Twitter bahwa peluncuran ini adalah"Sebagian besar algoritma rekomendasi"algoritma lainnya juga akan segera diungkapkan secara bertahap. Ia juga menyampaikan harapannya bahwa "pemangku kepentingan pihak ketiga yang independen dapat menentukan dengan akurasi yang wajar konten apa yang mungkin ditampilkan Twitter kepada pengguna."
Dalam diskusi Space mengenai peluncuran algoritma, dia mengatakan bahwa rencana open source ini bertujuan untuk membuat Twitter menjadi "sistem paling transparan di internet", dan agar Twitter sekuat proyek open source paling terkenal dan sukses, Linux. "Tujuan umumnya adalah agar pengguna yang terus mendukung Twitter dapat menikmati platform ini sebanyak mungkin."
Saat ini telah hampir tiga tahun sejak Musk pertama kali merilis algoritma X secara open source. Sebagai seorang KOL super di kalangan teknologi, Musk jauh hari sebelumnya telah melakukan promosi yang cukup untuk peluncuran open source kali ini.
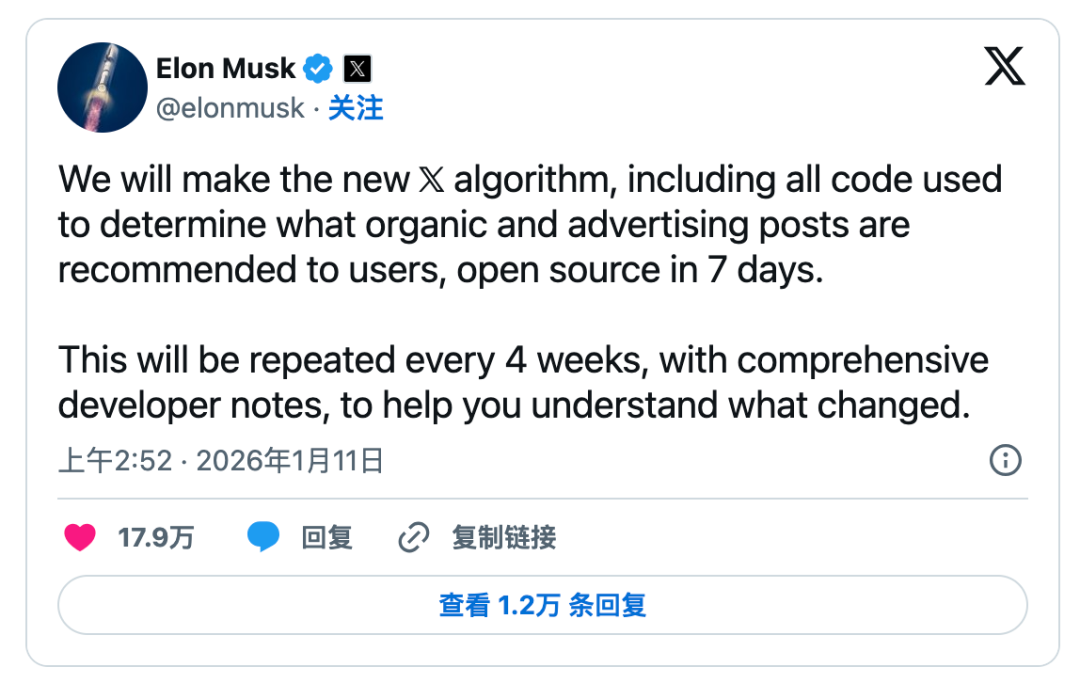
Pada 11 Januari, Musk mengunggah cuitan di X bahwa dalam 7 hari ke depan, algoritma X baru (termasuk seluruh kode yang digunakan untuk menentukan konten pencarian alami dan iklan apa yang akan direkomendasikan kepada pengguna) akan dijadikan open source.
Proses ini akan diulang setiap 4 minggu, lengkap dengan penjelasan rinci untuk pengembang, untuk membantu pengguna memahami perubahan apa saja yang terjadi.
Hari ini, janjinya terpenuhi lagi.
2. Mengapa Musk ingin open source?
Ketika Elon Musk kembali menyebutkan "sumber terbuka", reaksi pertama dari masyarakat bukanlah idealisme teknis, melainkan tekanan nyata.
Dalam setahun terakhir, X telah beberapa kali terlibat kontroversi karena mekanisme distribusi kontennya. Platform ini sering dikritik karena algoritmanya yang dianggap memanjakan dan memperkuat pandangan kanan. Tendensi ini tidak dianggap sebagai kasus terisolasi, melainkan dianggap bersifat sistematis. Sebuah laporan penelitian yang dirilis tahun lalu menunjukkan bahwa sistem rekomendasi X menunjukkan bias politik yang jelas dalam penyebaran konten.
Sementara itu, beberapa kasus ekstrem lebih lanjut memperbesar keraguan dari pihak luar. Tahun lalu, sebuah video yang belum ditinjau yang terkait dengan insiden penusukan aktivis sayap kanan Amerika Serikat, Charlie Kirk, menyebar dengan cepat di platform X, memicu kegaduhan opini publik. Para kritikus mengatakan bahwa ini tidak hanya mengungkap kegagalan mekanisme peninjauan platform, tetapi juga kembali menyoroti bagaimana algoritma memperbesar atau justru mengabaikan konten tertentu. Kekuatan terselubung.
Dalam konteks ini, tiba-tiba Elon Musk menekankan transparansi algoritma, sulit dijelaskan secara sederhana sebagai keputusan teknis murni.

3. Bagaimana pendapat netizen?
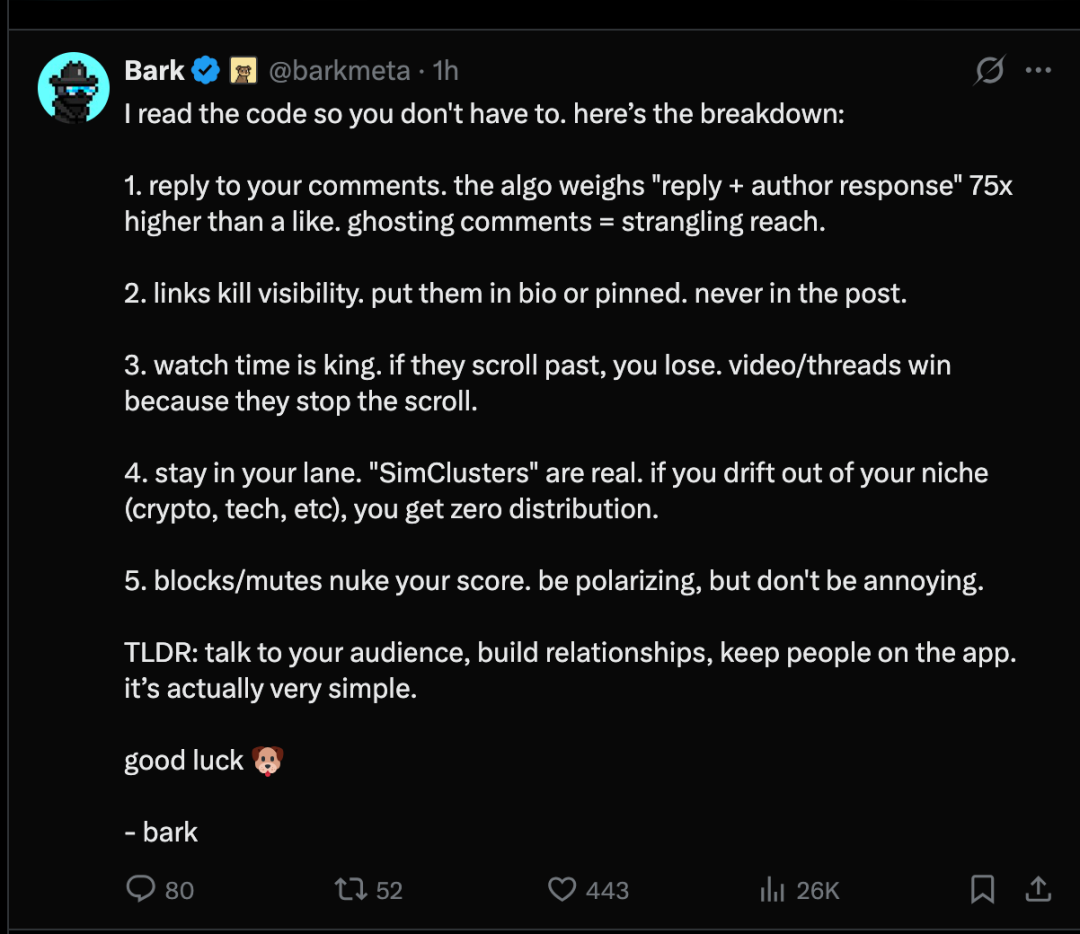
Setelah algoritma rekomendasi X dibuka sumber terbukanya, di platform X, pengguna membuat 5 kesimpulan berikut tentang mekanisme algoritma rekomendasi:
- Balas komentarmuAlgoritma memberi bobot 75 kali lebih tinggi pada "balasan + tanggapan penulis" dibandingkan suka. Tidak merespons komentar akan sangat memengaruhi tingkat eksposur.
- Tautan akan mengurangi tingkat eksposur.Tautan sebaiknya ditempatkan di profil pribadi atau di unggahan yang dipasang di bagian atas, jangan sekali-kali ditempatkan di dalam isi unggahan.
- Durasi menonton sangat pentingJika mereka menggeser layar dan melewati, maka kau tidak akan menarik perhatian mereka. Video/post yang mendapat perhatian tinggi karena mampu membuat pengguna berhenti.
- Pertahankan bidangmu"Simulasi klaster" itu nyata ada. Jika kamu menyimpang dari segmen pasar kamu (kripto, teknologi, dll.), kamu tidak akan mendapatkan saluran distribusi apa pun.
- Memblokir / Diam-diam akan secara signifikan menurunkan skor AndaHarus kontroversial, tetapi jangan sampai menjengkelkan.
Singkatnya: berkomunikasi dengan audiens Anda, bangun hubungan, dan pertahankan pengguna di dalam aplikasi. Sebenarnya sangat sederhana.
Beberapa pengguna internet juga menemukan bahwa meskipun arsitekturnya open source, masih ada beberapa konten yang belum di-open source-kan. Pengguna tersebut menyatakan bahwa peluncuran kali ini pada dasarnya adalah sebuah kerangka kerja (framework), tanpa mesin (engine). Spesifiknya, apa saja yang masih kurang?
Parameter bobot tidak tersedia - Kode memastikan "penambahan poin untuk perilaku positif" dan "pengurangan poin untuk perilaku negatif", tetapi berbeda dengan versi 2023, nilai spesifiknya telah dihapus.
Sembunyikan bobot model - Tidak termasuk parameter internal dan perhitungan model itu sendiri.
Data pelatihan yang belum diumumkan - Kami tidak tahu apa-apa mengenai data yang digunakan untuk melatih model, cara pengambilan sampel perilaku pengguna, serta bagaimana membangun sampel "baik" dan sampel "buruk".
Bagi pengguna X pada umumnya, pengembangan algoritma X menjadi open source tidak akan berdampak besar. Namun, transparansi yang lebih tinggi dapat menjelaskan mengapa beberapa postingan mendapat eksposur sementara yang lain tidak, serta memungkinkan peneliti untuk mempelajari cara platform menentukan peringkat konten.
4. Mengapa sistem rekomendasi menjadi medan pertandingan yang penting?
Dalam sebagian besar diskusi teknis,Sistem RekomendasiBiasanya dianggap sebagai bagian dari rekayasa belakang, rendah hati, kompleks, dan jarang berada di bawah sorotan. Namun, jika kita benar-benar menguraikan cara perusahaan raksasa internet beroperasi secara komersial, kita akan menemukan bahwa sistem rekomendasi bukanlah modul pinggiran, melainkan "infrastruktur" yang mendasari seluruh model bisnis tersebut. Karena alasan ini, sistem rekomendasi dapat disebut sebagai "makhluk besar yang diam" di industri internet.
Data publik telah berulang kali memverifikasi hal ini. Amazon pernah mengungkapkan bahwa sekitar 35% dari pembelian di platform mereka langsung berasal dari sistem rekomendasi; Netflix bahkan lebih ekstrem, sekitar 80% dari waktu menonton didorong oleh algoritma rekomendasi; situasi di YouTube juga mirip, sekitar 70% dari waktu menonton berasal dari sistem rekomendasi, terutama pada aliran informasi (feed). Sebagai untuk Meta, meskipun mereka tidak pernah memberikan proporsi yang jelas, tim teknis mereka pernah menyebutkan bahwa sekitar 80% dari kapasitas komputasi kluster internal perusahaan digunakan untuk tugas-tugas rekomendasi.
Apa arti dari angka-angka ini?Jika sistem rekomendasi dihilangkan dari produk-produk ini, hampir setara dengan mengangkat fondasi bangunan.Ambil contoh Meta, penayangan iklan, durasi penggunaan pengguna, dan konversi bisnis hampir semuanya bergantung pada sistem rekomendasi. Sistem rekomendasi tidak hanya menentukan apa yang dilihat pengguna, tetapi juga secara langsung menentukan cara platform memperoleh keuntungan.
Namun, sistem yang menentukan hidup dan mati ini justru dalam jangka panjang menghadapi masalah kompleksitas teknik yang sangat tinggi.
Dalam arsitektur sistem rekomendasi tradisional, sangat sulit untuk menutupi semua skenario dengan satu model yang seragam. Sistem produksi nyata biasanya sangat terfragmentasi. Ambil contoh perusahaan seperti Meta, LinkedIn, dan Netflix, biasanya di balik rantai rekomendasi lengkap, terdapat 30 model khusus atau bahkan lebih yang berjalan secara bersamaan: model pemanggilan (recall), model penyortiran kasar (coarse ranking), model penyortiran halus (fine ranking), model penyusunan ulang (re-ranking), masing-masing dioptimalkan untuk fungsi tujuan dan indikator bisnis yang berbeda. Di balik setiap model, biasanya terdapat satu atau lebih tim yang bertanggung jawab atas rekayasa fitur (feature engineering), pelatihan, penyetelan parameter, peluncuran, dan iterasi berkelanjutan.
Biaya dari pola ini jelas terlihat: kompleksitas teknis yang tinggi, biaya pemeliharaan yang besar, serta kesulitan dalam kolaborasi lintas tugas. Setelah seseorang mengajukan pertanyaan "apakah satu model bisa digunakan untuk menyelesaikan beberapa masalah rekomendasi", hal ini berarti penurunan orde kompleksitas bagi seluruh sistem. Ini adalah tujuan jangka panjang yang selama ini sangat diinginkan tetapi sulit dicapai oleh industri.
Munculnya model bahasa besar memberikan jalur baru yang mungkin bagi sistem rekomendasi.
LLM telah terbukti dalam praktik bahwa ia dapat menjadi model umum yang sangat kuat: kemampuannya untuk berpindah antara tugas-tugas berbeda sangat baik, dan kinerjanya terus meningkat seiring dengan peningkatan skala data dan daya komputasi. Sebaliknya, model rekomendasi tradisional biasanya bersifat "khusus tugas", sehingga sulit untuk berbagi kemampuan di antara berbagai skenario.
Yang lebih penting lagi, model tunggal tidak hanya menyederhanakan aspek teknis, tetapi juga membawa potensi "pembelajaran silang". Ketika model yang sama memproses beberapa tugas rekomendasi sekaligus, sinyal dari tugas-tugas yang berbeda dapat saling melengkapi. Seiring bertambahnya skala data, model menjadi lebih mudah berkembang secara keseluruhan. Ini adalah karakteristik yang selama ini sangat diinginkan dalam sistem rekomendasi, tetapi sulit dicapai melalui pendekatan tradisional.
Apa yang diubah oleh LLM? Sebenarnya, yang diubah adalah dari rekayasa fitur menuju kemampuan memahami.
Secara metodologis, perubahan terbesar yang dibawa LLM (Large Language Model) pada sistem rekomendasi terjadi pada tahap inti "fitur engineering".
Di sistem rekomendasi tradisional, para insinyur harus terlebih dahulu secara manual membangun sejumlah besar sinyal: riwayat klik pengguna, durasi tampil, preferensi pengguna serupa, tag konten, dan lain sebagainya. Setelah itu, mereka secara eksplisit memberi tahu model "harap membuat keputusan berdasarkan fitur-fitur ini". Model itu sendiri tidak memahami makna semantik dari sinyal-sinyal tersebut, hanya belajar hubungan pemetaan di ruang numerik.
Setelah model bahasa diperkenalkan, alur ini menjadi sangat abstrak. Anda tidak lagi perlu menentukan satu per satu "perhatikan sinyal ini, abaikan sinyal itu", tetapi Anda dapat langsung menggambarkan masalah itu sendiri kepada model: ini adalah seorang pengguna, ini adalah konten; pengguna ini sebelumnya menyukai konten serupa, pengguna lain juga memberikan umpan balik positif terhadap konten ini—sekarang tolong tentukan, apakah konten ini sebaiknya direkomendasikan kepada pengguna ini?
Model bahasa itu sendiri sudah memiliki kemampuan memahami. Ia dapat menilai sendiri informasi mana yang merupakan sinyal penting dan bagaimana menggabungkan sinyal-sinyal tersebut untuk mengambil keputusan. Dalam arti tertentu, model ini bukan hanya menjalankan aturan rekomendasi, tetapi juga "memahami hal rekomendasi itu sendiri".
Sumber kemampuan ini terletak pada fakta bahwa LLM telah terpapar pada data yang sangat besar dan beragam selama tahap pelatihan, sehingga lebih mudah menangkap pola-pola halus namun penting. Sebaliknya, sistem rekomendasi tradisional harus bergantung pada insinyur untuk secara eksplisit menjabarkan pola-pola tersebut, dan begitu ada yang terlewat, model tidak akan mampu mengenali pola tersebut.
Dari sudut pandang backend, perubahan ini tidak terlalu asing. Seperti saat kamu bertanya kepada GPT, ia akan menghasilkan jawaban berdasarkan konteks informasi yang ada. Demikian pula, saat kamu bertanya kepadanya, "Apakah saya akan tertarik dengan konten ini?", ia juga dapat membuat penilaian berdasarkan informasi yang sudah ada. Dalam tingkat tertentu, model bahasa itu sendiri sebenarnya sudah secara alami memiliki kemampuan "rekomendasi".