










Bayangkan adegan ini:
Anda meminta AI Agent untuk memperbaiki bug kode. Ia membuka proyek, membaca 20 file, mengubah beberapa hal, menjalankan pengujian, gagal, mengubah lagi, menjalankan lagi, tetap gagal... Melakukan belasan putaran perbaikan, akhirnya—tetap tidak berhasil diperbaiki.
Anda mematikan komputer dan menghela napas lega. Kemudian menerima tagihan API.
Angka di atas mungkin membuat Anda terkejut—AI Agent yang memperbaiki bug secara mandiri di API resmi luar negeri, sering menghabiskan lebih dari satu juta Token per tugas yang tidak diperbaiki, dengan biaya mencapai puluhan hingga seratus dolar AS.
Pada April 2026, sebuah makalah penelitian yang diterbitkan bersama oleh Stanford, MIT, Universitas Michigan, dan lainnya, pertama kali secara sistematis membuka "black box" penggunaan AI Agent dalam tugas pemrograman—uang benar-benar dihabiskan di mana, apakah pengeluarannya sepadan, dan apakah bisa diprediksi sebelumnya, jawabannya mengejutkan.
Temuan satu: Kecepatan pengeluaran biaya Agent untuk menulis kode adalah 1000 kali lebih tinggi daripada percakapan AI biasa
Orang mungkin berpikir, menghabiskan uang untuk meminta AI menulis kode untukmu seharusnya sama dengan menghabiskan uang untuk berdiskusi kode dengan AI.
Paper memberikan perbandingan menunjukkan:
Penggunaan token untuk tugas encoding Agentic adalah sekitar 1000 kali lebih banyak daripada tugas tanya jawab kode dan penalaran kode biasa.
Beda seluruh tiga tingkat orde.
Mengapa hal ini terjadi? Makalah tersebut menunjukkan sebuah fakta—uang tidak dihabiskan untuk "menulis kode", melainkan untuk "membaca kode".
Di sini, "membaca" bukan berarti manusia membaca kode, melainkan Agent dalam proses kerjanya perlu terus-menerus "memberi" seluruh konteks proyek, riwayat operasi, informasi kesalahan, dan isi file ke model. Setiap sesi percakapan tambahan membuat konteks ini menjadi lebih panjang; dan model dibayar berdasarkan jumlah Token—semakin banyak yang Anda berikan, semakin banyak yang harus Anda bayar.
Sebagai perbandingan: Ini seperti mempekerjakan seorang tukang reparasi yang meminta Anda membacakan seluruh gambar bangunan dari awal sebelum ia memutar kunci pas sekali pun—biaya membaca gambar jauh lebih mahal daripada biaya memutar sekrup.
Kertas ini merangkum fenomena ini dalam satu kalimat: Biaya yang mendorong Agent adalah pertumbuhan eksponensial Token masukan, bukan Token keluaran.
Temuan dua: Bug yang sama, dijalankan dua kali, biayanya bisa berbeda dua kali lipat—dan semakin mahal bugnya, semakin tidak stabil
Yang lebih membingungkan adalah randomisasi.
Peneliti menjalankan Agent yang sama pada tugas yang sama sebanyak 4 kali, dan menemukan:
- Di antara tugas-tugas yang berbeda, tugas paling mahal membakar sekitar 7 juta Token lebih banyak daripada tugas paling murah (Gambar 2a)
- Dalam beberapa eksekusi model dan tugas yang sama, biaya tertinggi sekitar dua kali lipat biaya terendah (Gambar 2b)
- Sedangkan jika membandingkan tugas yang sama di antara berbagai model, konsumsi tertinggi dan terendah bisa berbeda hingga 30 kali lipat.
Angka terakhir sangat patut diperhatikan: ini berarti, perbedaan biaya antara memilih model yang tepat dan model yang salah, bukan hanya "sedikit lebih mahal", tetapi "lebih mahal satu orde".
Yang lebih menyakitkan—pengeluaran lebih banyak tidak berarti kinerja lebih baik.
Penelitian menemukan kurva "berbentuk U terbalik":
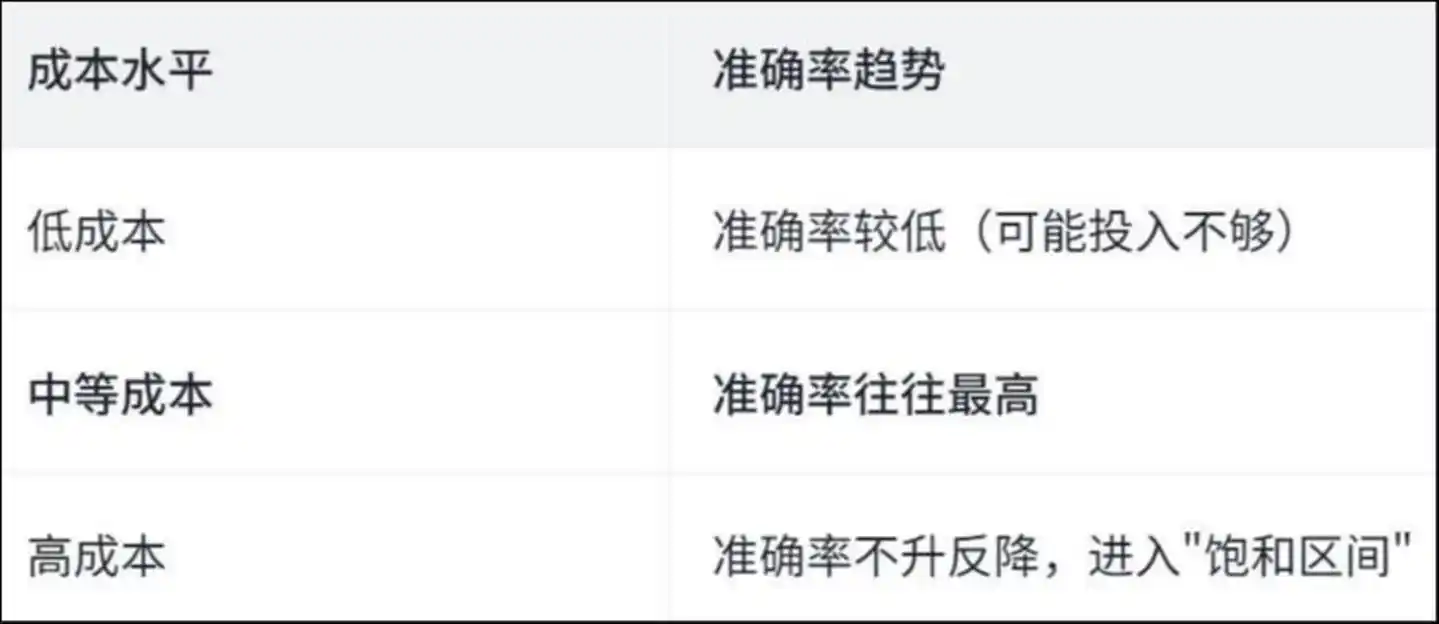
Tingkat akurasi biaya: biaya rendah memiliki akurasi lebih rendah (mungkin investasi tidak mencukupi), biaya menengah biasanya memiliki akurasi tertinggi, biaya tinggi justru menurun akurasinya, memasuki "zona jenuh"
Mengapa hal ini terjadi? Makalah memberikan jawaban dengan menganalisis operasi spesifik Agent—
Dalam operasi berbiaya tinggi, Agent menghabiskan banyak waktu pada "pekerjaan berulang".
Penelitian menemukan bahwa dalam operasi berbiaya tinggi, sekitar 50% operasi melihat dan mengubah file bersifat berulang—artinya, Agent terus-menerus membaca file yang sama dan mengubah baris kode yang sama, seperti seseorang yang berputar-putar di dalam ruangan, semakin berputar semakin pusing, semakin pusing semakin berputar.
Uang tidak dihabiskan untuk memecahkan masalah, tapi untuk "tersesat".
Temuan Tiga: Efisiensi energi antar model sangat berbeda—GPT-5 paling hemat, beberapa model menghabiskan hingga 1,5 juta token lebih banyak
Penelitian ini menguji kinerja 8 model besar terkini sebagai Agent pada SWE-bench Verified, standar industri dengan 500 masalah GitHub nyata. Dalam hal efisiensi token, model yang lebih efisien dapat menghabiskan puluhan dolar lebih banyak per tugas. Dalam penerapan tingkat perusahaan—yang menjalankan ratusan tugas per hari—perbedaan ini menjadi uang sungguhan.
Temuan yang lebih menarik adalah: efisiensi token adalah "karakter bawaan" model, bukan akibat dari tugasnya.
Peneliti membandingkan tugas yang berhasil diselesaikan oleh semua model (230 tugas) dan tugas yang gagal diselesaikan oleh semua model (100 tugas), dan menemukan bahwa peringkat relatif model hampir tidak berubah.
Ini menunjukkan: beberapa model secara alami "banyak bicara", dan tidak terlalu terkait dengan tingkat kesulitan tugas.
Temuan lain yang memikat: model kurang memiliki "kesadaran stop-loss".
Dalam menghadapi tugas sulit yang tidak dapat diselesaikan oleh semua model, agen ideal seharusnya segera menyerah, bukan terus menghabiskan uang. Namun kenyataannya, model umumnya menghabiskan lebih banyak Token pada tugas yang gagal—mereka tidak “menyerah”, melainkan terus menjelajah, mencoba ulang, dan membaca ulang konteks, seperti mobil tanpa lampu peringkat bahan bakar yang terus berjalan hingga mogok.
Temuan empat: Yang dianggap sulit oleh manusia belum tentu dianggap mahal oleh Agent—persepsi kesulitan benar-benar salah arah
Anda mungkin berpikir: Setidaknya saya bisa memperkirakan biaya berdasarkan tingkat kesulitan tugas?
Mengambil paper dan meminta ahli manusia untuk menilai tingkat kesulitan 500 tugas, lalu membandingkannya dengan konsumsi Token aktual Agent—
Result: Only a weak correlation exists between the two.
Dengan bahasa yang sederhana: tugas yang menurut manusia sangat sulit dan mahal, mungkin bisa diselesaikan Agent dengan mudah dan murah; sementara tugas yang menurut manusia mudah, justru bisa membuat Agent menghabiskan banyak sumber daya hingga sampai meragukan dirinya sendiri.
Ini karena kesulitan yang "dilihat" oleh manusia dan AI sama sekali berbeda:
- Yang dilihat manusia: kompleksitas logika, tingkat kesulitan algoritma, ambang pemahaman bisnis
- Agen melihat: seberapa besar proyeknya, berberapa banyak file yang harus dibaca, seberapa panjang jalur eksplorasi, dan apakah akan sering memodifikasi file yang sama berulang kali
Seorang ahli manusia menganggap bug yang “hanya perlu mengubah satu baris” mungkin memerlukan agen untuk terlebih dahulu memahami struktur seluruh kode basis sebelum dapat menemukan baris tersebut—hanya proses “membaca” saja sudah menghabiskan banyak token. Sementara itu, masalah algoritma yang dianggap manusia “logikanya rumit” mungkin justru diketahui agen sebagai solusi standar, dan selesai dalam sekejap.
Ini menciptakan kenyataan yang memalukan: pengembang hampir tidak mungkin memperkirakan biaya operasional Agent secara intuitif.
Temuan Lima: Bahkan modelnya sendiri tidak bisa memperkirakan berapa biaya yang akan dikeluarkan
Jika manusia tidak bisa memprediksi dengan akurat, mengapa tidak membiarkan AI memprediksi sendiri?
Peneliti merancang eksperimen yang cermat: membiarkan Agent terlebih dahulu "inspect" repositori kode sebelum mulai memperbaiki bug, lalu memperkirakan berapa banyak Token yang akan dikonsumsi—namun tidak benar-benar menjalankan perbaikan.
What was the result?
Semua model, hancur total.
Hasil terbaik adalah korelasi prediksi Claude Sonnet-4.5 terhadap token output—0,39 (skor maksimal 1,0). Sebagian besar model memiliki korelasi prediksi hanya antara 0,05 hingga 0,34, dengan Gemini-3-Pro terendah, yaitu hanya 0,04—hampir setara dengan tebakan acak.
Yang lebih parah lagi: semua model secara sistematis meremehkan konsumsi token mereka sendiri. Pada diagram sebar Gambar 11, hampir semua titik data jatuh di bawah "garis prediksi sempurna"—model merasa "tidak akan menghabiskan sebanyak itu", padahal sebenarnya menghabiskan lebih banyak. Selain itu, bias meremehkan ini menjadi lebih parah ketika tidak menyediakan contoh.
Yang lebih ironis—prediksi itu sendiri juga memerlukan biaya.
Biaya prediksi Claude Sonnet-3.7 dan Sonnet-4 bahkan bisa lebih dari dua kali biaya tugas itu sendiri. Artinya, meminta mereka untuk “memberikan perkiraan harga” lebih mahal daripada langsung mengerjakan pekerjaannya.
Kesimpulan makalahnya langsung:
Saat ini, model mutakhir tidak dapat memprediksi penggunaan Token-nya secara akurat. Klik "Jalankan Agent", seperti membuka kotak kejutan—baru tahu berapa biayanya setelah tagihan muncul.
Di balik "buku yang membingungkan" ini, tersembunyi masalah industri yang lebih besar
Setelah membaca ini, Anda mungkin bertanya: Apa arti temuan-temuan ini bagi perusahaan?
Model harga langganan bulanan sedang mengalami retakan akibat Agent
Paper tersebut menunjukkan bahwa model berlangganan seperti ChatGPT Plus layak karena konsumsi Token untuk percakapan biasa relatif terkendali dan dapat diprediksi. Namun, tugas Agent benar-benar menghancurkan asumsi ini—satu tugas bisa menghabiskan sejumlah besar Token karena Agent terjebak dalam siklus.
Ini berarti, penetapan harga berlangganan murni mungkin tidak berkelanjutan untuk skenario Agent, dan pembayaran berdasarkan penggunaan (pay-as-you-go) akan tetap menjadi pilihan paling realistis dalam jangka waktu yang cukup lama. Namun, masalah dengan pembayaran berdasarkan penggunaan adalah—penggunaannya sendiri tidak dapat diprediksi.
2. Efisiensi token harus menjadi "indikator ketiga" dalam memilih model
Secara tradisional, perusahaan memilih model berdasarkan dua dimensi: kemampuan (apakah bisa dilakukan) dan kecepatan (seberapa cepat dilakukan). Makalah ini memperkenalkan dimensi ketiga yang sama pentingnya: efisiensi energi (berapa banyak yang harus dikeluarkan untuk menyelesaikannya).
Model yang sedikit lebih lemah namun 3 kali lebih efisien mungkin memiliki nilai ekonomi lebih tinggi dalam skenario skala besar dibandingkan model "terkuat namun paling mahal".
3. Agen memerlukan "tabel bahan bakar" dan "rem"
Paper tersebut menyebutkan arah masa depan yang patut diperhatikan—kebijakan penggunaan alat yang sadar anggaran (Budget-aware tool-use policies). Secara sederhana, ini berarti memasang "pengukur bahan bakar" pada Agent: ketika konsumsi Token mendekati anggaran, paksa untuk menghentikan eksplorasi yang tidak efektif, bukan terus menghabiskan hingga habis.
Saat ini, hampir semua kerangka kerja Agent utama tidak memiliki mekanisme ini.
Masalah "pembakaran uang" agen, bukan bug, tetapi rasa sakit yang harus dilalui industri
Paper ini mengungkap bukan kelemahan dari suatu model, melainkan tantangan struktural dari seluruh paradigma Agent—ketika AI berkembang dari "satu pertanyaan, satu jawaban" menjadi "perencanaan mandiri, eksekusi multi-langkah, dan penyesuaian berulang," ketidakpastian konsumsi Token hampir merupakan hal yang tak terhindarkan.
Berita baiknya, ini adalah pertama kalinya seseorang secara sistematis mengungkap dan menghitung kekacauan ini. Dengan data ini, pengembang dapat membuat keputusan yang lebih bijak dalam memilih model, menetapkan anggaran, dan merancang mekanisme stop-loss; sementara pabrikan model memiliki arah optimasi baru—tidak hanya menjadi lebih kuat, tetapi juga lebih hemat.
Setelah semua, sebelum AI Agent benar-benar masuk ke lingkungan produksi di berbagai industri, menghabiskan setiap rupiah dengan jelas lebih penting daripada menulis setiap baris kode dengan indah. (Artikel ini pertama kali diterbitkan di aplikasi Titanium Media, penulis | Silicon Valley Tech news, editor | Zhao Hongyu)
Catatan: Artikel ini didasarkan pada makalah preprint yang diterbitkan di arXiv pada 24 April 2026 berjudul *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei). Para penulis berasal dari institusi seperti Universitas Virginia, Stanford, MIT, Universitas Michigan, dll. Penelitian ini belum melalui proses peer review.