
Ingin tahu model besar mana yang paling kuat dalam tugas agen dunia nyata OpenClaw?
MyToken mengumpulkan seperangkat benchmark transparan berdasarkan evaluasi situs web untuk menilai kemampuan nyata agen pengkodean AI, hanya melihat satu dimensi inti: tingkat keberhasilan (kecepatan dan biaya termasuk dimensi independen lainnya yang akan dianalisis terpisah nanti). Sepenuhnya terbuka dan dapat direproduksi, hanya menampilkan standar evaluasi yang ketat + peringkat 10 besar tingkat keberhasilan terbaru.
Satu: Dimensi Evaluasi: Tingkat Keberhasilan
Kriteria spesifik: Persentase jumlah tugas yang diselesaikan secara lengkap dan akurat oleh agen AI. Setiap tugas menggunakan proses yang sangat terstandarisasi:
Precise user prompt
Send to agent in full to simulate real user request scenario
Perilaku yang diharapkan
Menjelaskan metode implementasi yang dapat diterima dan poin keputusan kunci
Kriteria penilaian (checklist)
Daftar kriteria keberhasilan atomisasi yang dapat diverifikasi satu per satu
Dua, tiga metode penilaian
Evaluasi ini terutama menggunakan tiga metode penilaian.
Pemeriksaan otomatis: Skrip Python secara langsung memverifikasi konten file, catatan eksekusi, pemanggilan alat, dan hasil objektif lainnya
Pengadil model LLM besar: Claude Opus memberi skor berdasarkan skala rinci (kualitas konten, kesesuaian, kelengkapan, dll.)
Mode campuran: Pemeriksaan objektif otomatis + penilaian kualitatif oleh LLM sebagai hakim
Semua definisi tugas, Prompt, dan logika penilaian dipublikasikan sepenuhnya untuk verifikasi ulang.
Tiga: Tugas untuk evaluasi
Uji coba ini mencakup 23 kategori tugas yang berbeda, mencakup berbagai aspek seperti interaksi dasar, operasi file/kode, penciptaan konten, analisis penelitian, pemanggilan alat sistem, dan persistensi memori, yang sangat mendekati skenario penggunaan sehari-hari pengembang terhadap OpenClaw:
Pengecekan Kewajaran (otomatis) — menangani perintah sederhana dan membalas salam dengan benar
Pembuatan Acara Kalender (otomatisasi) —— Generasi Naskah ICS Standar dari Bahasa Alami
Penelitian Harga Saham (otomatisasi) — Query harga saham secara real-time dan hasilkan laporan terformat
Penulisan Postingan Blog (Hakim LLM) — Tulis sebuah postingan blog berstruktur Markdown sekitar 500 kata
Pembuatan Script Cuaca (otomatisasi) — Menulis script Python API cuaca dengan penanganan kesalahan
Ringkasan Dokumen (Pengadil LLM) — Ringkasan padat tiga bagian tentang topik inti
Penelitian Konferensi Teknologi (Hakim LLM) —— Mengumpulkan dan mengatur informasi dari 5 konferensi teknologi nyata (nama, tanggal, lokasi, tautan)
Draft Email Profesional (Penilai LLM) — Menolak pertemuan dengan sopan dan mengusulkan solusi alternatif
Pengambilan Memori dari Konteks (otomatisasi) — Ekstraksi tepat tanggal, anggota, teknologi, dll. dari catatan proyek
Pembuatan Struktur File (otomatisasi) — menghasilkan direktori proyek standar, README, .gitignore secara otomatis
Alur API Multi-langkah (Hibrida) — Membaca Konfigurasi → Menulis Skrip Panggilan → Dokumentasi Lengkap
Instal Skill ClawdHub (otomatisasi) — instal dan verifikasi ketersediaan dari repositori skill
Cari dan Instal Keterampilan (otomatisasi) — Cari keterampilan cuaca dan pasang dengan benar
Generasi Gambar AI (Campuran) — Buat dan simpan gambar berdasarkan deskripsi
Humanisasi Blog yang Dihasilkan AI (Pengadil LLM) — Ubah konten yang terasa mesin menjadi bahasa sehari-hari yang alami
Ringkasan Riset Harian (Pengadil LLM) — Menggabungkan beberapa dokumen menjadi ringkasan harian yang koheren
Pengelompokan Kotak Masuk Email (Campuran) — Analisis beberapa email dan susun laporan berdasarkan tingkat kepentingan
Pencarian dan Ringkasan Email (Campuran) — Mencari email arsip dan merangkum informasi penting
Riset Pasar Kompetitif (Hibrida) — Analisis Kompetitor di Bidang APM Perusahaan
Ringkasan CSV dan Excel (campuran) — menganalisis file tabel dan menghasilkan wawasan
Ringkasan PDF ELI5 (Penilai LLM) — Jelaskan PDF teknis dengan bahasa yang bisa dimengerti anak usia 5 tahun
Pemahaman Laporan OpenClaw (otomatisasi) — menjawab pertanyaan spesifik secara akurat dari PDF laporan penelitian
Ketahanan Pengetahuan Second Brain (Hibrida) — Menyimpan dan mengingat informasi secara akurat di luar sesi
Empat: Kesimpulan Utama: Peringkat 10 Model Teratas Berdasarkan Tingkat Keberhasilan (Best %/Avg %)
Data diperbarui hingga 7 April 2026
Best % adalah tingkat keberhasilan tertinggi dalam satu kali percobaan, Avg % adalah rata-rata tingkat keberhasilan dalam beberapa percobaan, yang lebih mencerminkan stabilitas
Berikut adalah sepuluh model dengan tingkat keberhasilan tertinggi
anthropic/claude-opus-4.6 (Anthropic) —— 93,3% / 82,0%
arcee-ai/trinity-large-thinking (Arcee AI) —— 91,9% / 91,9%
openai/gpt-5.4 (OpenAI) —— 90,5% / 81,7%
qwen/qwen3.5-27b (Qwen) —— 90,0% / 78,5%
minimax/minimax-m2.7 (MiniMax) —— 89,8% / 83,2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89,5% / 78,1%
qwen/qwen3.5-397b-a17b (Qwen) —— 89,1% / 80,4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88,8% / 70,2%
qwen/qwen3.6-plus-preview (Qwen) —— 88,6% / 84,0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88,6% / 75,5%
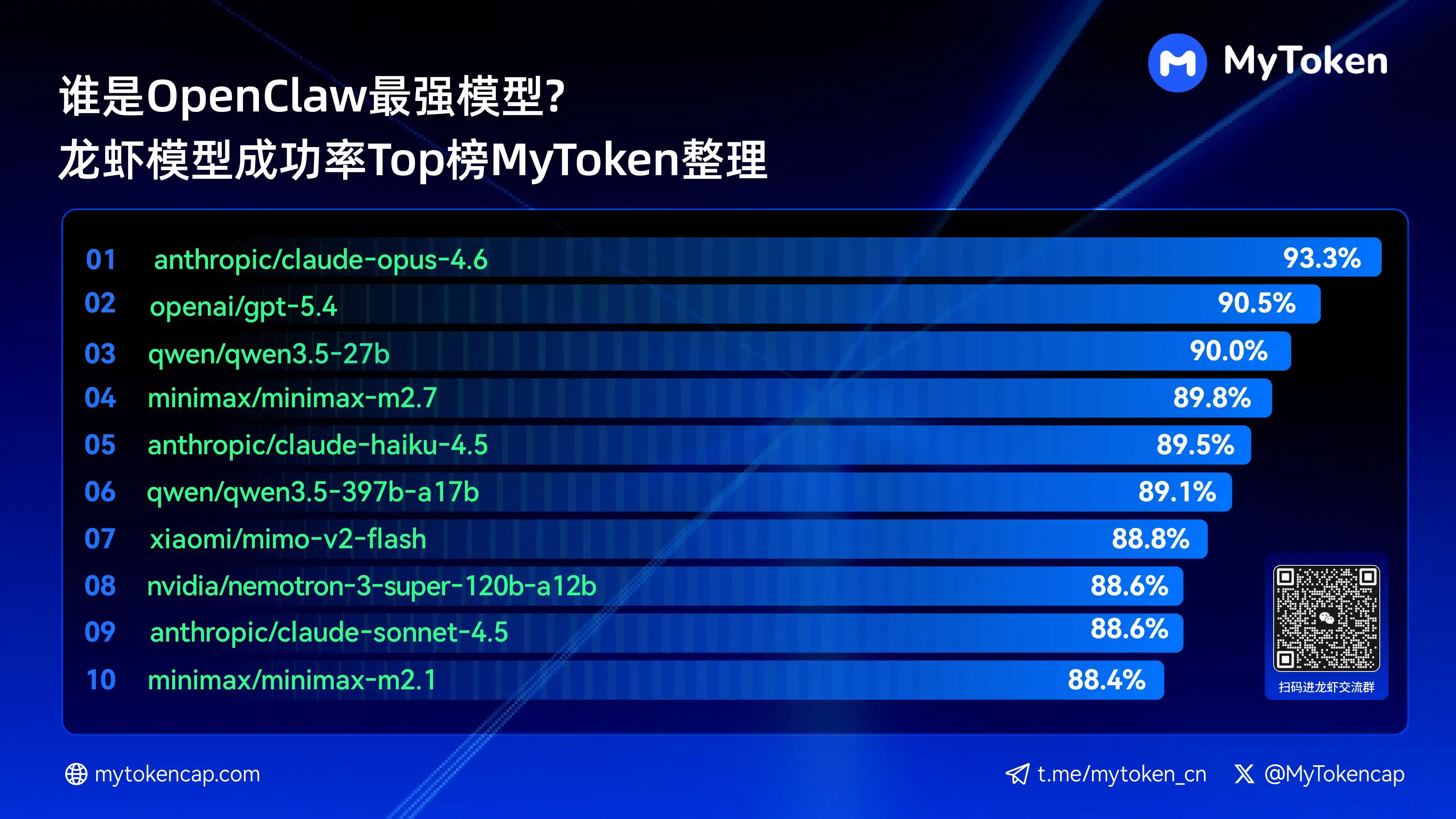
Claude Opus 4.6 saat ini memimpin dengan tingkat keberhasilan tertinggi 93,3%, tetapi Trinity dari Arcee menonjol dalam stabilitas rata-rata, sementara seri Qwen juga memiliki beberapa model masuk sepuluh besar, menunjukkan potensi nilai yang sangat baik. Tingkat keberhasilan adalah ambang dasar, namun kecepatan dan biaya akan semakin memengaruhi pengalaman nyata di masa mendatang.
Benchmarks 23 tugas ini sepenuhnya transparan, kami sangat menyarankan Anda menguji secara langsung sesuai dengan skenario Anda sendiri. Untuk peringkat model lainnya, tunggu fitur peringkat agen MyToken yang segera diluncurkan.
(Data berasal dari pengujian benchmark proxy OpenClaw yang dipublikasikan oleh PinchBench, terus diperbarui.)