










Penulis: Max yang selalu di jalan, 01Founder
Jika harus membuat ringkasan tahapan untuk OpenAI pada tahun 2025, banyak orang mungkin akan menggambarkannya sebagai datar bahkan agak pasif.
Dalam lebih dari satu tahun terakhir, mereka benar-benar mengikuti langkah demi langkah jalur penalaran, secara intensif meluncurkan model inferensi dari o3pro hingga o4mini, serta memperkenalkan model dasar baru seperti GPT-4.5 dan GPT-5.
Namun, di bidang generasi visual yang paling mudah dirasakan oleh pengguna biasa dan paling mudah menimbulkan penyebaran spontan, keberadaan mereka perlahan melemah.
Setelah kejutan awal peluncuran Sora, OpenAI tampaknya memasuki periode diam yang panjang di lintasan ini.
Sementara itu, pemain lain di meja tidak diam.
Di ekosistem open-source, model seperti Flux benar-benar menghancurkan hambatan untuk menghasilkan gambar berkualitas tinggi secara lokal;
Di sisi bisnis, selain pesaing lama yang menguasai batas estetika yang ekstrem, muncul pula pesaing baru seperti Nano-banana yang dilengkapi fitur pencarian online.
Sebaliknya, model generasi gambar utama OpenAI sebelumnya, GPT-Image-1.5, sudah terlihat ketinggalan zaman:
Kualitas gambar buruk, tata letak kaku, dan sering crash saat menghadapi teks kompleks.
Secara perlahan, industri membentuk sebuah konsensus:
OpenAI mengalami hambatan teknis di bidang generasi visual dan semakin kesulitan menghadapi serangan dari berbagai pesaing.
Hingga beberapa minggu lalu, titik balik muncul dengan cara yang sangat tersembunyi.
Di platform uji buta model besar terkenal LM Arena, sebuah model gambar misterius dengan kode nama Duct Tape diam-diam ikut bergabung.
Pengguna yang berpartisipasi dalam pengujian buta segera menyadari ada yang tidak beres:
Model ini tidak hanya mengendalikan rasio aspek ekstrem dengan sangat akurat, tetapi juga dapat menghasilkan poster tata letak dengan teks multibahasa dalam jumlah besar tanpa cacat, bahkan tampaknya memiliki proses perencanaan logis tak terlihat sebelum menghasilkan gambar.
Sementara itu, berbagai komunitas teknis berspekulasi tentang perusahaan mana yang secara diam-diam meluncurkan strategi besar ini, tetapi pihak OpenAI tetap bersikap diam.
Tadi malam, sepatu akhirnya jatuh.
Tanpa acara peluncuran yang panjang atau kampanye pemasaran yang masif, OpenAI secara resmi menamai model dengan kode nama "tape" sebagai ChatGPT GPT-Image-2 dan meluncurkannya secara menyeluruh ke pasar.
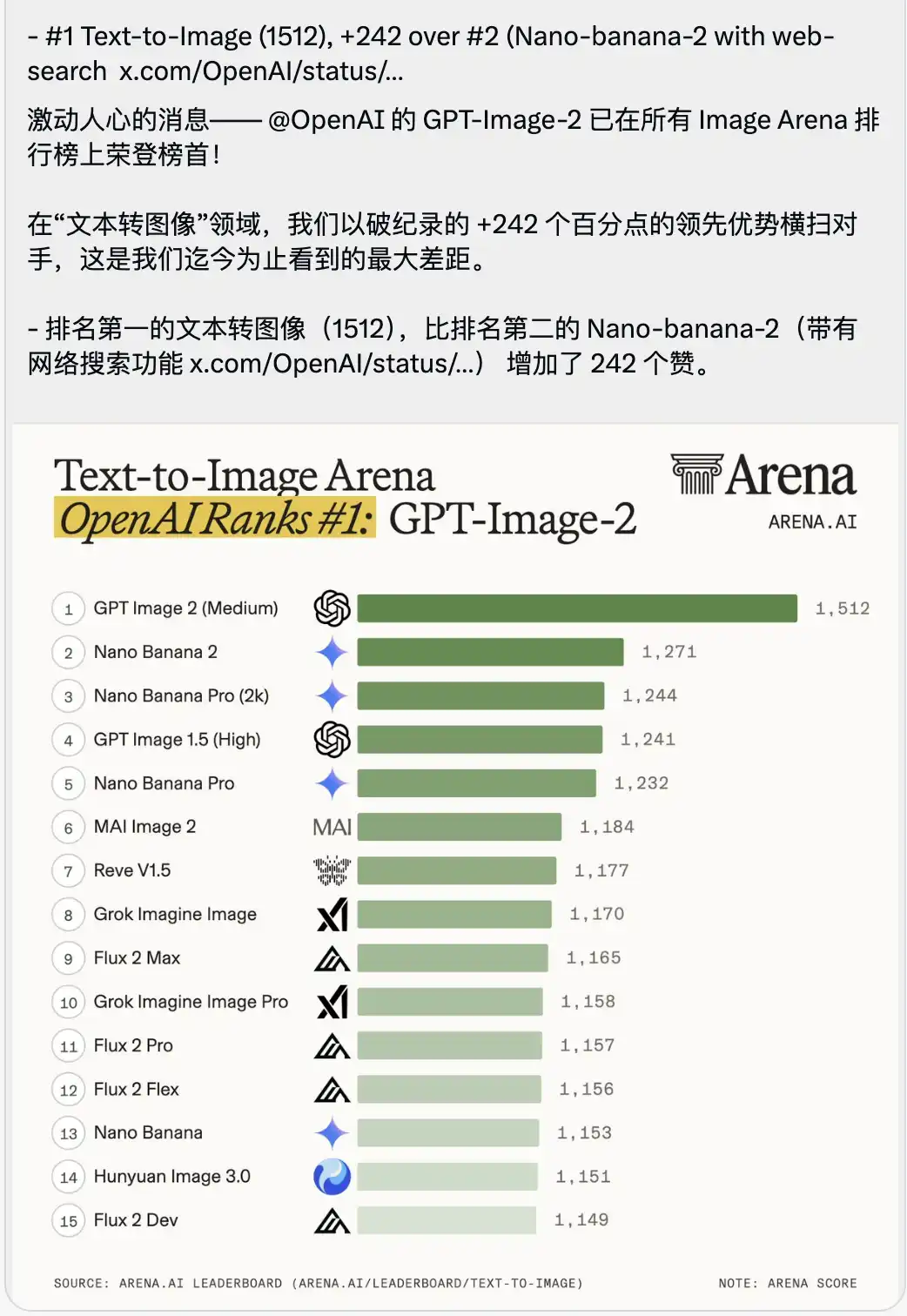
Bersamaan dengan itu, dirilis pula daftar peringkat Text-to-Image yang terasa agak menyesakkan.
GPT-Image-2 langsung menduduki peringkat pertama dengan skor sangat tinggi 1512, unggul 242 poin dari peringkat kedua (yaitu Nano-banana-2 dengan fitur pencarian daring).
Dalam konteks pengujian model besar, orang biasanya akan membahas secara besar-besaran tentang keunggulan sekecil sepersepuluh atau satuan angka, karena skor antara model teratas sangat ketat.
Sebuah keunggulan 242 poin belum pernah terjadi dalam sejarah arena.
Ini bukan sekadar pembaruan versi kecil, ini adalah penindasan generasi yang kasar.
Saya menghabiskan sebagian besar hari untuk memeriksa secara detail berbagai kemampuan ekstremnya serta dokumen API terbaru.
Satu-satunya perasaan terbesar adalah:
OpenAI tetaplah OpenAI yang sama.
Ketika ia memutuskan untuk merebut kembali wilayahnya, ia melakukannya dengan langsung melempar meja kartu lama.
Di hadapan model ini, pekerjaan desain visual yang kita kira masih membutuhkan dua hingga tiga tahun lagi untuk benar-benar digantikan oleh AI, hari ini pada dasarnya sudah mencapai akhirnya.
BAGIAN.01 Generasi Gambar dari Model ke Agen Visual
Untuk memahami mengapa GPT-Image-2 bisa menciptakan selisih skor yang begitu besar, Anda harus melepaskan pemahaman lama tentang model teks-ke-gambar.
Dulu kita menggunakan AI untuk menggambar, pada dasarnya seperti membuka kotak keberuntungan, memasukkan beberapa kata kunci, lalu menunggu ia menyusun piksel menjadi bentuk yang Anda inginkan.
Namun, GPT-Image-2 lebih seperti agen yang dilengkapi mesin visual.
Perubahan paling jelas adalah ia secara langsung membagi dua mode yang sama sekali berbeda dalam mekanismenya.
Satu mode instan (Instant Mode) yang terbuka untuk semua pengguna.
Mode ini menonjolkan respons ultra-cepat dan integrasi mulus ke dalam alur kerja sehari-hari.
Misalnya Anda mengirimkan perintah melalui ponsel, ia dapat memberikan Anda gambar dengan struktur lengkap dalam beberapa detik.
Kemampuan pemahaman visual dasarnya sangat kuat, tetapi primarily menyelesaikan kebutuhan konversi visual frekuensi tinggi dan sekali jalan.
Sementara mode berpikir (Thinking Mode) yang dibuka untuk pengguna berbayar.
Sebelum mulai merender sedikit pun satu piksel, ia akan terlebih dahulu memasuki proses penalaran logis dan pencarian daring yang berlangsung selama belasan detik.
Ini adalah pola yang menyelesaikan sebuah pernyataan yang sangat inti namun sangat sulit:
Model pertama kalinya benar-benar tahu apa yang harus digambar.
Contoh paling langsung.
Ketik di kotak obrolan:
Buatkan saya sebuah poster, cari di internet tentang ulasan orang-orang terhadap model misterius Duct Tape, dan sertakan kode QR ChatGPT.

Dengan model lama, itu sama sekali tidak tahu apa yang dikatakan netizen, hanya akan memberi Anda poster dengan kode acak dan gambar palsu yang tidak bisa dipindai.
Namun dalam mode pemikiran, alur kerjanya adalah sebagai berikut:
Ini akan terlebih dahulu menghentikan penggambaran, memulakan alat carian dalam talian, dan mengambil ulasan sebenar pengguna dari Reddit, Threads, atau LinkedIn;
Kemudian, ia mulai merancang tata letak poster, ruang kosong, dan hierarki font;
Akhirnya, ia menghasilkan kode QR yang valid dan langsung dapat dipindai untuk diarahkan, serta merender seluruh gambar.

Ini bukan lagi sekadar menggambar, ini benar-benar menyelesaikan seluruh proses secara mandiri, mulai dari riset, perencanaan, ekstraksi teks, hingga desain tata letak.
Di sini diperlukan perbandingan paralel.
Semua orang yang mengikuti komunitas model besar tahu bahwa model generasi gambar dengan kemampuan terhubung dan pencarian bukanlah ciptaan pertama OpenAI.
Peringkat kedua, Nano-banana, sudah memiliki mekanisme ini.
Namun, saat menggunakan Nano-banana secara nyata, Anda akan menemukan bahwa ia terasa agak kaku di banyak tempat.
Pemikiran Nano-banana sering kali merupakan logika penyambungan mekanis.
Misalnya Anda memintanya untuk mencari tren industri untuk membuat poster, ia memang mencarinya, tetapi biasanya hanya menyalin kalimat dari Wikipedia secara kaku dan menempelkannya secara paksa ke gambar.
Saat menghadapi instruksi yang memerlukan interpretasi permintaan bisnis abstrak, ia mudah bingung.

Rasanya seperti seorang magang yang bisa memahami perintah, tetapi tidak memiliki pengalaman kerja sama sekali, mengerti eksekusi, tetapi sama sekali tidak memahami strategi.
Namun, kinerja GPT-Image-2 dalam hal ini hanya bisa digambarkan dengan berlebihan.
Pemikirannya bukan sekadar formalitas, tetapi benar-benar memahami konteks budaya dan niat bisnis di baliknya.
Saya memasukkan perintah bahasa Tiongkok yang sangat sederhana saat pengujian: Bantu saya membuat tangkapan layar tentang Musk yang melakukan live streaming di Douyin untuk menjual Doubao.
Dengan model gambar lama, kemungkinan besar akan menghasilkan gambar seorang pria kulit putih yang mirip Musk, memegang sepotong baozi, dengan latar belakang kabur, bahkan tidak tahu seperti apa penampilan TikTok.
Namun dalam mode pemikiran, hasil dari GPT-Image-2 terasa agak mengejutkan.
Ia tidak hanya menyusun elemen-elemen secara sederhana, tetapi secara mandiri memanfaatkan pemahaman terhadap internet Tiongkok untuk menghasilkan tangkapan layar antarmuka ruang siaran Douyin yang direplikasi hingga tingkat piksel.
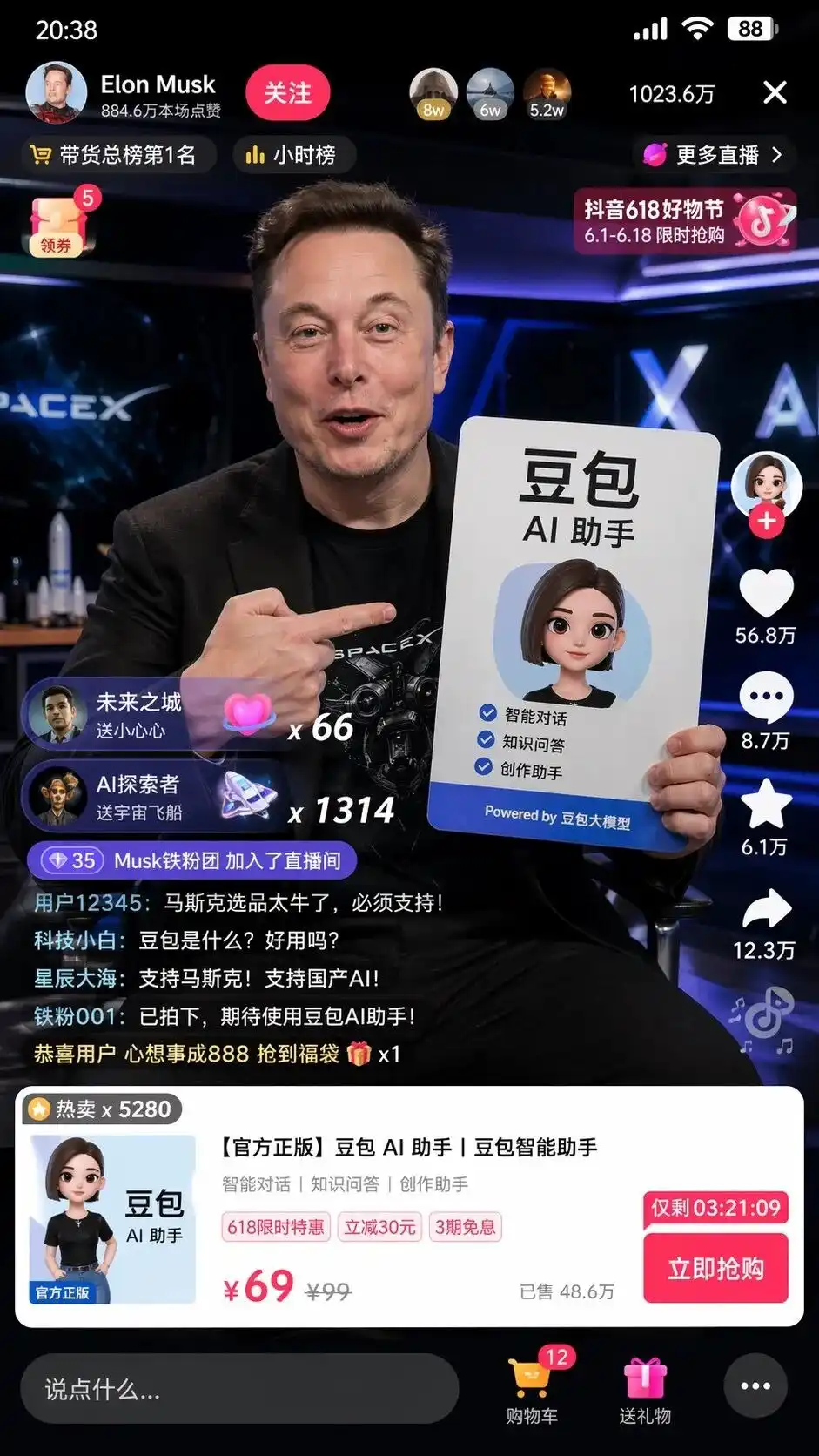
Di layar tidak hanya ada gambar Musk yang realistis memegang plakat iklan asisten AI DouBao dengan tata letak yang sempurna, tetapi juga detail-detail yang lebih menakutkan yang tidak muncul dalam prompt:
Tombol ikut di kiri atas, daftar peringkat jam, jumlah pengguna online 10,236,000 di kanan atas, kartu produk standar yang muncul di bagian bawah, bahkan menunjukkan harga garis miring 99, harga spesial 69, dan tombol beli sekarang dengan penghitung mundur.
Yang paling membuat merinding adalah komentar pengguna yang mengalir di kiri bawah dengan realisme luar biasa:
Tech newbie: What is DouBao? Is it user-friendly?
Lautan Bintang: Dukung Musk! Dukung AI lokal!
Tidak ada yang memberitahunya apa yang harus ditulis di komentar, bagaimana tampilan antarmuka produk, atau bagaimana menentukan harga.
Ini adalah desain antarmuka bisnis dan rencana operasional lengkap yang dibuat dan dieksekusi oleh model setelah menganalisis tag "perdagangan di Douyin" dan "model besar DouBao".
Dimensi evaluasi model besar dalam generasi gambar pada saat ini secara resmi telah melangkah dari sekadar mampu menghasilkan gambar yang indah, menuju pemahaman terhadap strategi dan logika tata letak.
BAGIAN.02 Uji Coba Kemampuan Inti
Untuk menguji batas bawahnya, saya mengujinya dengan beberapa skenario frekuensi tinggi dan kompleks sesuai standar desain bisnis.
Ternyata, tingkat kehalusan dalam menyelesaikan masalahnya sudah sampai pada tingkat yang menakutkan.
Adegan pertama: Pemahaman visual dan siklus bisnis (mengenakan pakaian pada model)
Dalam visual e-commerce tradisional atau perencanaan mode, biaya eksekusi antara ide hingga melihat efek pemakaian sangat tinggi.
Anda mencari model, meminjam pakaian, menyewa studio foto, dan melakukan retouching akhir.
Kemudian dengan munculnya AI, orang-orang mulai melatih model LoRA untuk mempertahankan bentuk wajah karakter, tetapi ini masih memerlukan bahan berupa puluhan gambar dan biaya pembelajaran yang cukup besar.
Dalam GPT-Image-2, proses ini telah dikompresi secara ekstrem.
Saya mencoba mengunggah satu foto self-portrait sehari-hari saya, memberitahunya bahwa saya akan pergi liburan ke pulau bulan depan, dan memintanya membantu saya memilih beberapa set pakaian.
Awalnya ia memberi saya 8 set koleksi pakaian musim panas dengan gaya yang sama sekali berbeda, tata letaknya terlihat seperti Lookbook e-commerce profesional, bahkan setiap item dilengkapi dengan label teks yang tepat.
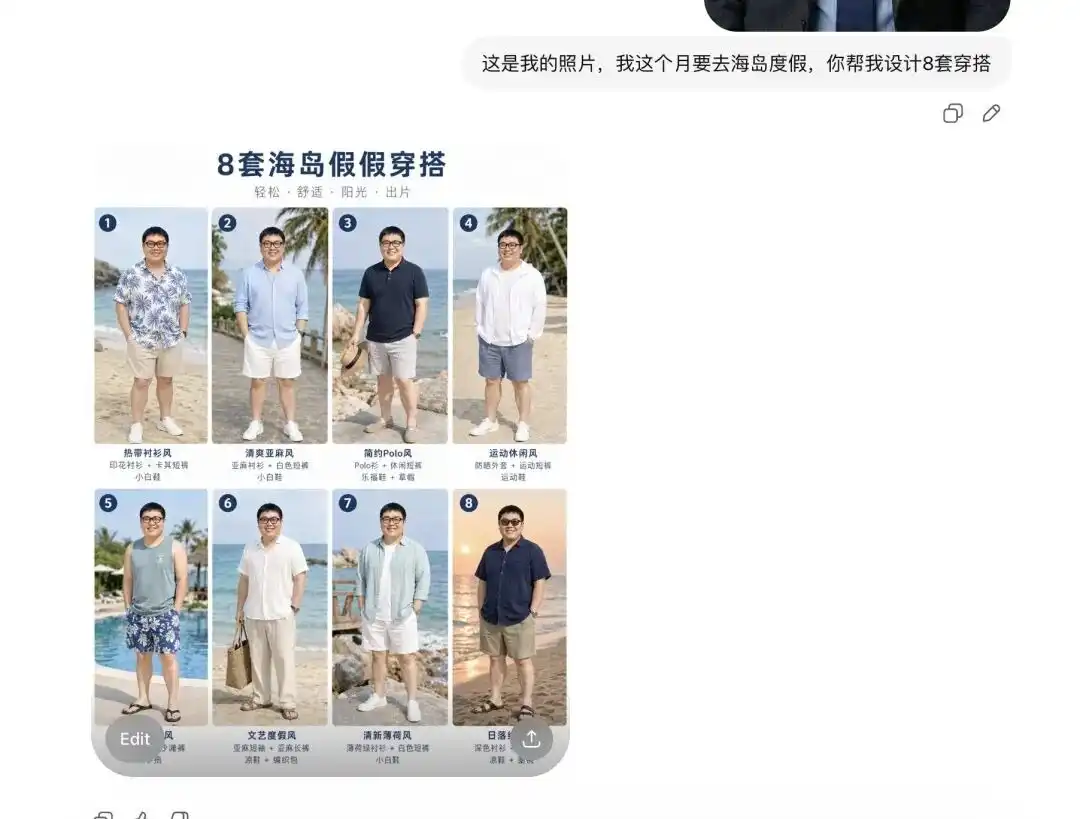
Yang lebih penting, ia telah secara akurat menganalisis fitur wajah dan proporsi tubuh saya dalam momen ini.
Ketika saya memberitahunya bahwa saya ingin melihat efek pakaian pertama yang dikenakan, serta meminta beberapa gambar detail dari berbagai sudut, ia langsung mengambil wajah saya dari foto swafoto itu, menggantinya dengan pakaian musim panas tersebut, dan menghasilkan gambar dari berbagai sudut seperti samping dan setengah badan.

Perubahan ini sangat mulus. Artinya, jalan setapak untuk rendering pakaian dasar, atau pekerjaan outsourcing yang mencari model untuk mencoba pakaian, telah benar-benar terputus.
Skenario kedua: Menyelesaikan konsistensi dan narasi berkelanjutan (membuat komik dari satu kalimat)
Semua orang yang pernah mencoba gambar AI tahu bahwa membuat AI menggambar satu gambar yang indah tidak sulit, yang sulit adalah membuatnya menggambar sepuluh gambar orang yang sama dengan gerakan dan sudut pandang yang konsisten.
Ini adalah yang disebut masalah konsistensi (Consistency).
Namun dalam pengujian nyata kali ini, saya melihat kasus yang sangat bertentangan dengan pengalaman sebelumnya.
Anda hanya perlu mengunggah satu foto bersama teman Anda kemarin, lalu masukkan petunjuk yang sangat sederhana:
Jadikan kita berdua sebagai tokoh utama, buat tiga halaman komik gaya Jepang, ceritanya terserah kamu.
Beberapa detik kemudian, ia langsung menghasilkan tiga halaman komik hitam putih dengan storyboard standar.
Yang paling menakutkan adalah, dua karakter komik yang dihasilkan berdasarkan orang nyata ini, berada di adegan berbeda dalam tiga halaman.

Baik close-up, lari dari jarak jauh, atau siluet, bahkan fitur wajah, detail rambut, dan kerutan pakaian mereka, semuanya mempertahankan konsistensi yang sempurna.
Lebih lagi, alur komiknya benar-benar koheren, bahkan teks dalam kotak dialog pun membentuk logika cerita yang utuh.

Kemampuan untuk mencapai konsistensi dalam waktu dan ruang menunjukkan bahwa ia telah melampaui ranah generasi gambar tunggal dan memiliki kemampuan sutradara untuk narasi berkelanjutan.
Skenario ketiga: Melintasi ambang terakhir dalam rendering teks (tata letak multibahasa)
Jika konsistensi menyelesaikan masalah narasi, maka rendering akurat teks multibahasa benar-benar memaksa desainer grafis ke sudut.
Dulu, hanya dengan sedikit teks dalam gambar, model besar sudah mulai menggambar sembarangan.
Karena teks yang dipahami model adalah Token (blok semantik), sedangkan gambar yang dihasilkan adalah titik piksel, keduanya sebelumnya terpisah.
GPT-Image-2 menyelesaikan masalah ini sepenuhnya.
Saya membuat sampul majalah mode berbahasa Prancis, menu restoran bahasa Jepang dengan kana hiragana dan kanji penuh, bahkan mencoba annotasi bahasa Rusia dengan kepadatan tata letak yang sangat tinggi.

Hasilnya satu kali jadi, tanpa kesalahan ejaan.
Yang paling membuat putus asa adalah, tidak hanya menulis hurufnya dengan benar, tetapi juga memahami cara menyesuaikan estetika budaya lokal dan desain font berdasarkan bahasanya.
Misalnya, karakter Tiongkok dalam brosur bahasa Jepang menggunakan huruf seni retro khas Jepang, dan tata letak hiragana sesuai dengan kebiasaan membaca vertikal bahasa Jepang.
Desain tata letak dulunya merupakan lahan milik desainer grafis.
Mengatur spacing huruf, membedakan prioritas, dan mencapai keseimbangan visual antara teks dan latar belakang memerlukan banyak latihan.
Namun ketika AI mampu menangani begitu banyak bahasa tanpa kesalahan, sekaligus dilengkapi estetika tata letak tingkat lanjut, poster harian, brosur, dan iklan aliran informasi benar-benar tidak lagi memerlukan manusia untuk secara manual mengatur garis panduan agar sejajar.
Adegan keempat: Rasio aspek terdistorsi dan kontrol mikro ekstrem (ukiran pada butir beras)
Terakhir, untuk melihat seberapa patuhnya, saya memberinya beberapa perintah yang sangat sulit.
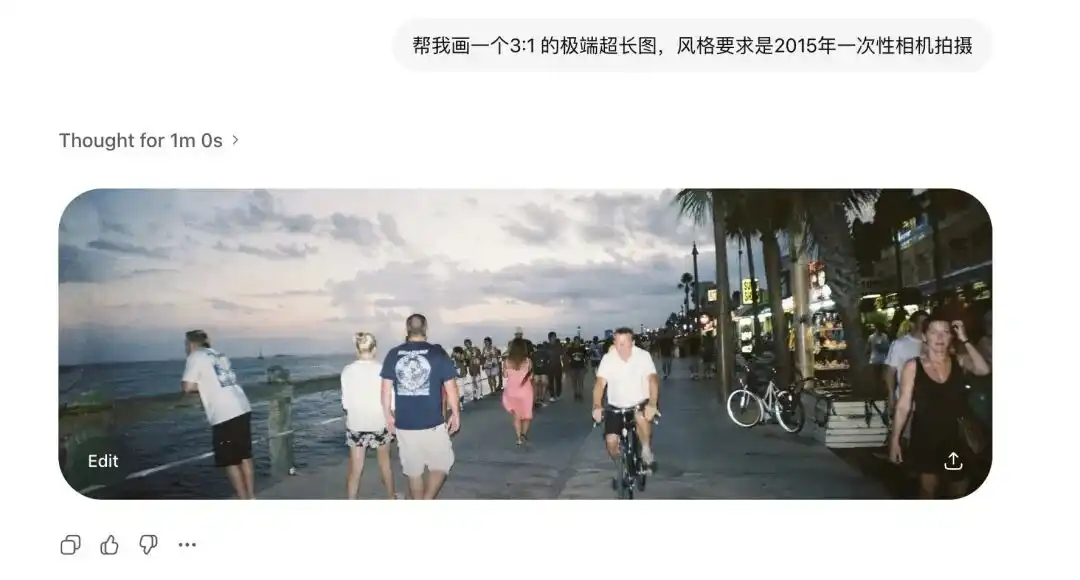
Saya pertama kali menguji rasio aspek ekstremnya.
Model difusi tradisional sangat takut terhadap rasio non-standar.
Sebelumnya, sedikit memperpanjang gambar, maka akan muncul dua kepala di dalamnya.
Namun, saya meminta Images 2.0 untuk menghasilkan gambar ultra-lebar 3:1 dan gambar vertikal panjang 1:3, dan tidak hanya tidak rusak, tetapi bahkan menghasilkan panorama 360 derajat yang saling terhubung di ujung-ujungnya dan memiliki logika tertutup.
Setelah menambahkan entri foto kamera sekali pakai tahun 2015, distorsi lensa lama dan pantulan buruk dari flash yang mengenai dinding pun direproduksi dengan jelas.
Sementara itu, yang lebih menunjukkan daya kontrol mikronya adalah pengujian butir beras yang agak gila yang ditampilkan oleh pihak resmi di acara peluncuran.
Peneliti memanggil API eksperimen 4K yang masih dalam pengujian internal, mereka tidak menggunakan kata-kata seperti fotografi makro, ultra-HD 8K, hanya memberikan satu perintah sederhana yang sangat abstrak:
Sejumlah beras. Pada satu butir beras di antara tumpukan beras tersebut tertulis GPT Image 2.
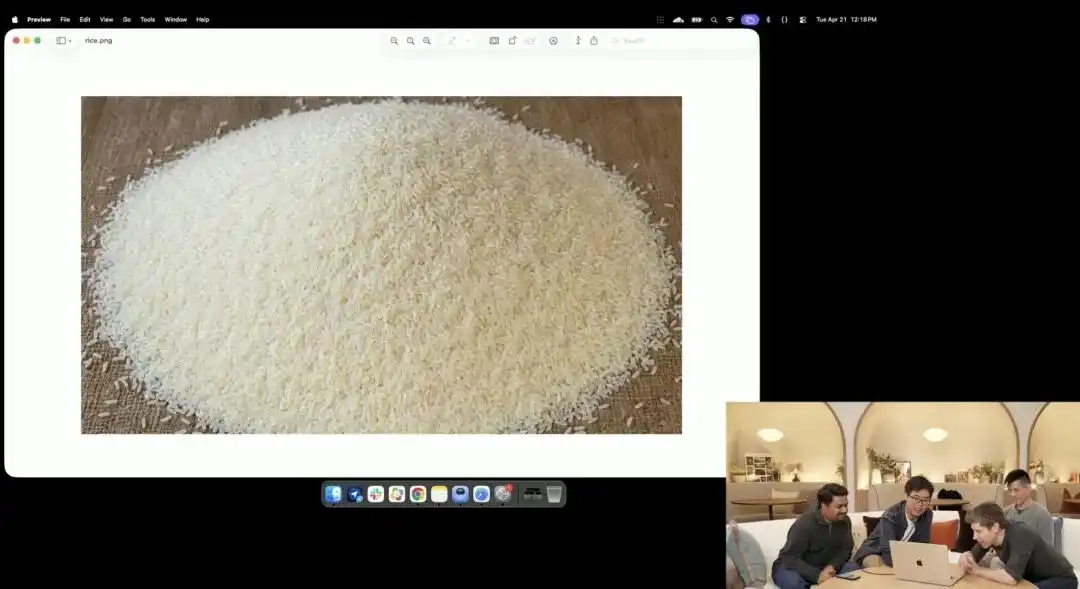
Ketika layar diperbesar puluhan kali bahkan hingga muncul butiran piksel, apakah Anda benar-benar bisa menemukan butiran mikroskopis yang memiliki tulisan di tengah sejumlah beras?
Tekstur beras ini tetap sesuai dengan hukum fisika, teks secara akurat mengikuti kelengkungan kecil butir beras di permukaannya.
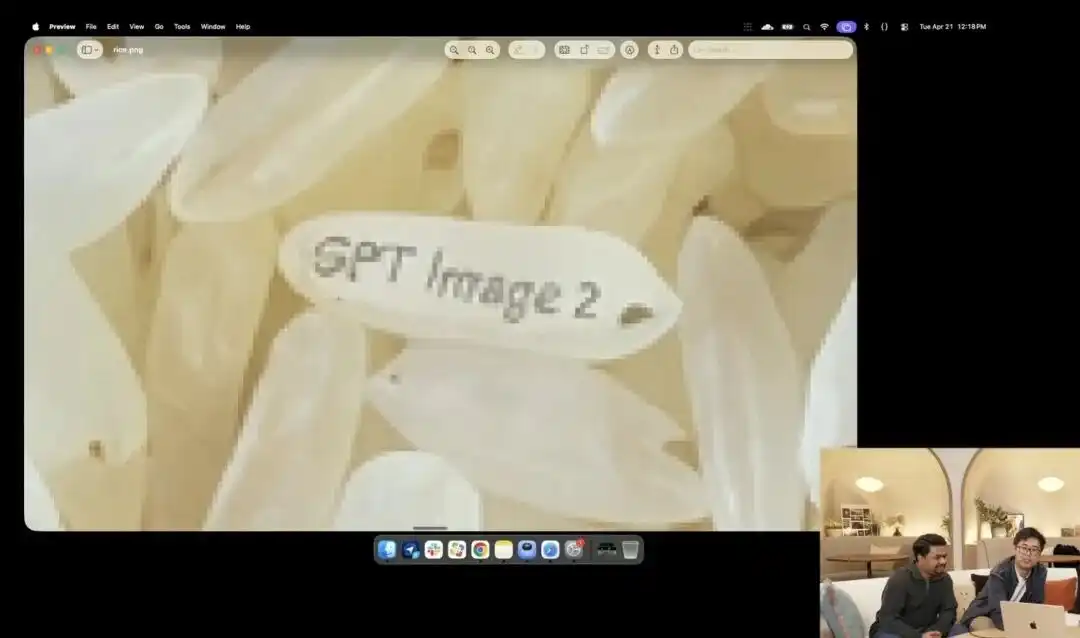
Semua pekerjaan tersisa—memanggil sudut makro, menghitung kedalaman fokus, mencari koordinat fisik butir beras di ruang laten, dan mencetak teksnya—semuanya secara otomatis diisi dan diselesaikan oleh model besar dalam mode pemikiran.
Contoh ini secara intuitif menunjukkan bahwa model memahami posisi spasial dengan presisi seakurat bedah pada tingkat piksel.
Ini berarti, di masa depan dalam pekerjaan nyata, Anda dapat secara akurat mengubah setiap bagian kecil dalam desain, tepat sasaran, bukan seperti sebelumnya, di mana saat ingin mengubah kerah, seluruh gambar ikut berubah.
BAGIAN.03 Beberapa Detail Teknis
Kekuatan ekstrem dan kecerdasan strategis semacam ini sama sekali bukan hasil hanya dengan mengerahkan daya komputasi secara membabi buta.
Untuk memahami apa sebenarnya kartu trufnya, saya melakukan beberapa pengujian probe terhadap GPT-Image-2.
Ternyata ditemukan satu poin yang sangat menarik.
Meskipun dokumen resmi menyatakan bahwa tanggal kedaluwarsa basis pengetahuan keseluruhan GPT-Image-2 diperbarui hingga Desember 2025, dalam pengujian saya sendiri.
Tanggal pelatihan untuk Mode Instan (Instant Mode) masih berhenti pada akhir Mei 2024;

Sedangkan mode pemikiran (Thinking Mode) yang memerlukan pertimbangan panjang, basis pengetahuannya secara asli sekitar Juni 2024 (tetapi dapat memperoleh tanggal saat ini secara real-time melalui koneksi internet).

Dengan menghitung dari dua titik waktu ini, tampaknya ada pola yang dapat dilihat pada dasar GPT-Image-2.
Pertama, bicarakan mode instan yang unggul dalam menghasilkan gambar frekuensi tinggi.
Batas waktu Mei 2024 berarti kemungkinan besar itu langsung menggunakan o4-mini, atau versi ringan dari keluarga GPT-5 (GPT-5 mini atau bahkan GPT-5 nano dengan parameter sangat kecil).
Karena basis ringan ini sudah memiliki kemampuan perencanaan ruang yang sangat kuat dan memahami instruksi kompleks, generasi gambar di atasnya dapat tetap stabil dan tidak kacau.
Dan pola pemikiran yang sangat cerdas dan memahami strategi bisnis tersebut tidak mungkin didasarkan pada model utama GPT-5.
Karena basis pengetahuan dasar GPT-5 berakhir pada September 2024.
Mode pemikiran kemungkinan besar terhubung ke model inferensi seri O yang terus diperbarui di latar belakang (misalnya o4, atau o3 yang diperbarui).
Model besar terlebih dahulu menggunakan mekanisme pemikiran panjang khusus seri O, menghitung secara jelas logika bisnis, psikologi audiens, dan koordinat tata letak di ruang laten, sebelum menyerahkan kepada modul visual untuk rendering piksel akhir.
Tentu, ada jalur alternatif lainnya:
Di bawah mekanisme alokasi daya komputasi yang sangat halus di dalam OpenAI, mode cepat mungkin secara langsung menggunakan GPT-5 nano sebagai cadangan, sementara mode pemikiran menggunakan GPT-5 mini yang sedikit lebih besar dikombinasikan dengan alat eksternal.
Namun, terlepas dari kombinasi dasar mana pun, jika Anda terus memperhatikan ekosistem API OpenAI, Anda akan menyadari bahwa logika generatif dasarnya sudah sama sekali tidak sejajar dengan Midjourney.
BAGIAN.04 Harga yang paling diperhatikan oleh semua orang
Namun, daripada menebak dasar, yang lebih patut diperhatikan oleh pengembang dan perusahaan yang benar-benar ingin mengintegrasikannya ke dalam alur kerja adalah tabel harga API yang sangat realistis dan kontra-intuitif.
DALL-E 3 sebelumnya dikenakan biaya per gambar (misalnya, 0,04 dolar per gambar).
Namun, sejak GPT-Image-1 generasi pertama, OpenAI telah mengubahnya sepenuhnya menjadi kerangka berbasis biaya per Token.
GPT-Image-2 kali ini tetap mempertahankan standar ini, bahkan lebih dari itu, ia juga menawarkan peningkatan fitur dengan harga lebih murah.
Menurut daftar harga yang baru saja diumumkan secara resmi, harga per juta Token adalah sebagai berikut.
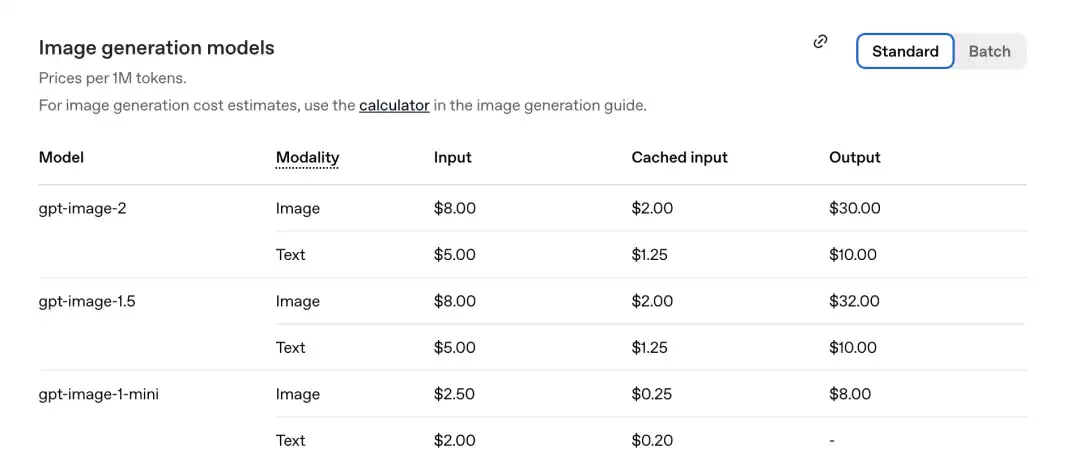
Bagian gambar GPT-Image-2: Masukkan 8.00, masukan yang di-cache (Cached inputs) 2.00, keluaran $30.00.
Dibandingkan dengan generasi sebelumnya gpt-image-1.5: outputnya adalah $32.00.
Model baru justru lebih murah.
Mari kita hitung biayanya.
Dalam model sebelumnya, menghasilkan satu gambar berkualitas tinggi memerlukan sekitar 1.000 hingga 1.500 token output.
Dengan harga $30 per juta token yang dihasilkan, biaya aktual untuk menghasilkan satu gambar berkisar antara $0,03 hingga $0,045 (sekitar Rp2 hingga Rp3).
Jika Anda tidak memerlukan respons detik-demi-detik, tetapi menggunakan mode API Batch yang disediakan resmi, harga ini akan langsung turun setengahnya (output langsung turun menjadi $15.00).
Dihitung, biaya terendah untuk menghasilkan satu gambar hanya lebih dari 10 sen.
Harga satu lembar ini sudah cukup bernilai, tetapi senjata utamanya sebenarnya terletak pada cached inputs di tabel harga.
Sebelumnya, saat membuat komik strip atau mendesain poster seri, setiap kali Anda menghasilkan ulang, Anda harus mengunggah ulang sejumlah besar gambar referensi karakter, ringkasan sebelumnya, dan petunjuk panjang, sehingga biaya input sangat tinggi.
Namun, dalam model penagihan Token saat ini, ketika Anda meminta pembuatan 8 komik berurutan sekaligus, elemen visual dari gambar pertama akan langsung disimpan sebagai konteks cache.
Mulai dari gambar kedua, biaya input gambar langsung turun dari $8,00 menjadi $2,00 (hanya mengenakan biaya 25%).
Ini berarti bahwa saat melakukan produksi massal dalam skala besar atau membutuhkan konsistensi karakter yang sangat tinggi, biaya marjinalnya akan turun secara signifikan.
Semakin cerdas model dan semakin banyak gambar yang dihasilkan, biaya rata-rata per gambar justru semakin rendah.
Logika penagihan terindustrialisasi inilah yang benar-benar akan mendorong para seniman garis produksi ke titik terakhir.
BAGIAN.05 Mengungkap Tim Di Balik Layar
Terakhir, mari kita tinjau kembali tim visual impian internal OpenAI yang tampil dalam acara peluncuran langsung ini; banyak fitur yang sebelumnya dianggap tidak masuk akal kini sepenuhnya bisa dijelaskan.
Misalnya, bagaimana tepatnya ia menyelesaikan masalah tata letak multibahasa dan tulisan tak terbaca.
Ini tidak terlepas dari ilmuwan senior di tim, Gabriel Goh.

Dalam dunia akademik, ia paling dikenal sebagai penulis utama dari model multimodal inovatif CLIP.
CLIP established the foundation for understanding how modern AI correlates human language with image pixels.
Dengan dipimpin oleh ahli pemetaan semantik multimodal ini, GPT-Image-2 tidak lagi menebak bentuk teks secara acak, tetapi benar-benar menulis pada tingkat piksel.
Misalnya, bagaimana ia bisa memahami hubungan ruang tiga dimensi, bahkan membuat panorama 360 derajat dengan rasio aspek ekstrem, serta memahami cahaya dan bayangan mikroskopis pada butiran beras.
Ini berkat anggota inti lainnya, Alex Yu.

Sebelum bergabung dengan OpenAI, ia adalah co-founder dan mantan CTO dari startup ternama di bidang generasi 3D, Luma AI, serta seorang akademisi terkemuka yang fokus pada neural rendering 3D (seperti NeRF).
Dengan kehadirannya, GPT-Image-2 sebenarnya telah melampaui pewarnaan piksel 2D tradisional.
Kemungkinan besar ia terlebih dahulu membangun adegan tiga dimensi di dalam pikiran, menata pencahayaan, lalu merender sebuah irisan 2D yang akurat untuk Anda.
Bagaimana konsistensi komik multi-halaman yang sangat menakutkan itu dicapai.
Ini merujuk pada pasangan muda dari tim yang baru saja lulus dari MIT CSAIL:
Boyuan Chen (kiri) dan Kiwhan Song (kanan).
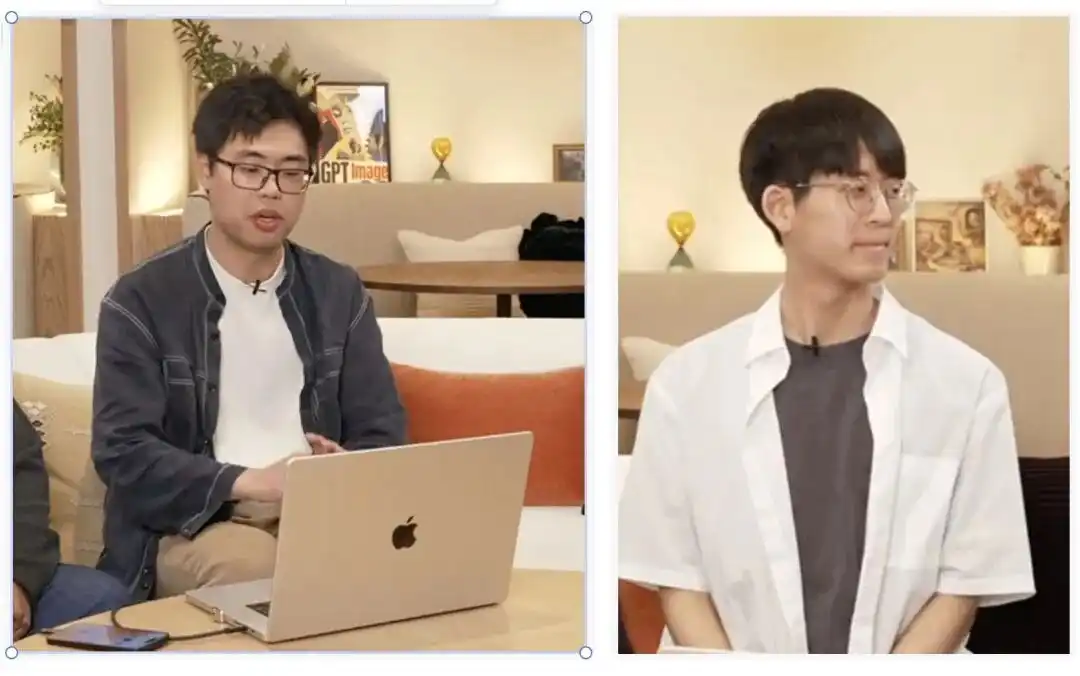
Arah utama mereka di kalangan akademis disebut World Models dan embodied intelligence.
Mengajari mesin untuk memahami bagaimana dunia fisika berfungsi, sehingga karakter tetap mempertahankan ciri-ciri yang konsisten tanpa distorsi di berbagai adegan waktu dan ruang, tepatnya adalah masalah yang terus dicoba diselesaikan oleh dua akademisi ini.
Terakhir, tambahkan Nithanth Kudige (kiri, salah satu penulis utama model inferensi seri O) yang terus berkomitmen untuk menghubungkan model inferensi besar dengan logika dasar visual, dan Kenji Hata (kanan, mantan peneliti Google, lulusan Laboratorium Visual Stanford).

Ketika sekelompok orang ini berkumpul, logika dasar, rendering ruang 3D, penyelarasan ekstrem antara teks dan gambar, serta hukum dunia fisik, secara alami disatukan dalam satu model yang sama.
BATAS GPT-Image-2
Setiap model memiliki batasan.
Pihak resmi juga mengakui bahwa mereka masih kesulitan menghadapi beberapa situasi ekstrem.
Misalnya, panduan origami yang memerlukan pembalikan ruang fisik yang ketat, menyelesaikan kubus Rubik, atau detail berulang yang sangat padat seperti butiran pasir, tetap akan menyentuh batas kemampuannya.
Namun dalam konteks aplikasi bisnis, ini sudah merupakan kecacatan yang sangat kecil.
Untuk seluruh industri desain, kita tidak perlu menimbulkan kecemasan; ini sama sekali tidak berarti kematian estetika.
Orang-orang yang memiliki selera, wawasan bisnis, dan memahami strategi tetap dapat membuat sesuatu yang luar biasa dengannya.
Namun, fakta objektifnya adalah bahwa moat profesi desainer telah secara substantif dihancurkan.
Dulu, hidup bergantung pada menghafal shortcut perangkat lunak desain, tahu cara menyelaraskan teks secara horizontal dan vertikal, tahu cara menyesuaikan tata letak berdasarkan bahasa, serta ahli dalam retouching dan pemisahan gambar yang halus.
Tetapi akan lebih sulit di masa depan, karena keterampilan yang dulu bisa dihargai dan diperdagangkan secara terbuka sekarang menjadi perintah dasar yang dapat dipanggil secara gratis dengan satu kalimat oleh siapa pun.
Setelah sekian lama tidak aktif, OpenAI benar-benar membuktikan sekali lagi bahwa di meja ini, siapa yang benar-benar memegang kartu terbaik, dengan cara yang sangat tenang namun sangat mematikan.
Rantai alat eksekusi lama sedang rusak, masalah yang tersisa bagi industri bukan lagi apakah AI akan menggantikan kita, tetapi bagaimana kita harus beradaptasi dengan lini produksi baru ini.