










Sumber: Institut Penelitian CoinW
Ringkasan
Gradients adalah subnetwork AI terdesentralisasi yang dibangun di atas Bittensor (SN56), dengan inti utama dalam mekanisme seperti "penerbitan tugas, persaingan penambang, dan verifikasi seleksi" yang mengubah proses pelatihan model dari alur teknis yang kompleks menjadi kolaborasi jaringan yang didorong pasar. Dalam arsitekturnya, Gradients menggabungkan AutoML dengan daya komputasi terdistribusi untuk membentuk pasar pelatihan yang berpusat pada insentif, tidak hanya menurunkan hambatan penggunaan AI tetapi juga meningkatkan efisiensi pemanfaatan daya komputasi. Dari segi ekosistem dan kinerja data, Gradients telah menyelesaikan pembangunan jaringan dasar, namun bobot insentif dan arus dana saat ini masih relatif terbatas. Gradients melengkapi infrastruktur pelatihan dalam ekosistem TAO serta mengeksplorasi paradigma baru "optimasi AI yang didorong pasar", dengan potensi jangka panjang untuk berkembang menjadi lapisan masuk penting dalam pelatihan AI terdesentralisasi.
1. Mulai dari Web2 AutoML: Status dan Keterbatasan Pelatihan AI
1.1 Apa itu AutoML
Dalam pemahaman tradisional, melatih model AI adalah hal yang memiliki ambang masuk tinggi, memerlukan insinyur untuk menangani data, memilih model, menyesuaikan parameter berulang kali, serta mengevaluasi hasilnya—seluruh prosesnya kompleks dan memakan waktu. Munculnya AutoML (machine learning otomatis) pada dasarnya adalah “mengotomatisasi” langkah-langkah rumit ini. Anda bisa memahaminya sebagai “alat otomatis membuat model”: pengguna hanya perlu menyediakan data dan memberi tahu sistem tujuan yang ingin dicapai, seperti klasifikasi, prediksi, atau pengenalan—seluruh proses berikutnya, termasuk pemilihan model, penyesuaian parameter, pelatihan, dan optimasi, dilakukan secara otomatis oleh sistem. Hal ini menjadikan AI dari alat hanya untuk sedikit insinyur profesional perlahan berubah menjadi kemampuan yang dapat digunakan oleh pengembang biasa bahkan perusahaan, merupakan langkah penting dalam penerapan AI secara luas.
1.2 Batasan utama AutoML tradisional
Implementasi utama AutoML saat ini terfokus pada platform penyedia cloud, seperti Google Vertex AI dan AWS SageMaker, yang menawarkan "AI Training as a Service". Meskipun AutoML Web2 secara signifikan menurunkan hambatan penggunaan AI, model dasarnya masih memiliki keterbatasan jelas. Pertama, masalah terpusat: kekuatan komputasi, penetapan harga, dan aturan sepenuhnya dikendalikan oleh platform, membuat pengguna sangat bergantung pada penyedia tunggal dan kehilangan daya tawar. Kedua, biaya tinggi dan tidak transparan; sumber daya GPU yang diperlukan untuk pelatihan AI sebagian besar dikuasai oleh penyedia cloud, dengan mekanisme harga yang kurang kompetitif secara pasar. Lebih penting lagi, efisiensi optimasi memiliki batas atas. AutoML tradisional pada dasarnya tetap merupakan "satu sistem yang membantu Anda mencari solusi terbaik", terlepas seberapa kompleks sistemnya, pada intinya tetap merupakan optimasi jalur teknologi tunggal. Ruang eksplorasinya terbatas, sehingga sulit untuk secara bersamaan mencoba berbagai pendekatan yang sama sekali berbeda. Oleh karena itu, pelatihan AI Web2 saat ini merupakan "sistem tertutup", di mana pelatihan, optimasi, dan pengaturan sumber daya model semuanya terjadi dalam lingkungan yang dikendalikan oleh satu platform. Model ini meskipun efisien, perbatasannya mulai terlihat seiring meningkatnya permintaan.
2. Gradients: Merekonstruksi pelatihan AI dengan "jaringan"
2.1 Gradients adalah: platform AutoML terdesentralisasi
Pada bab sebelumnya, kami menyebutkan bahwa masalah inti dari AutoML Web2 tradisional adalah "sistem tertutup", di mana pelatihan model bergantung pada platform, jalur optimasi terbatas, dan aliran sumber daya terhambat. Gradients merupakan rekonstruksi terhadap model ini. Gradients berasal dari komunitas insinyur terdesentralisasi yang diprakarsai oleh WanderingWeights, dibangun di atas jaringan Bittensor, dan merupakan sub-jaringan pelatihan AI yang berjalan di Subnet 56. Berbeda dengan platform tradisional, ia tidak menyediakan layanan terpusat, melainkan memecah proses pelatihan dan menyerahkannya kepada jaringan terbuka. Pengguna hanya perlu menentukan tujuan tugas, seperti jenis model dan data, sedangkan proses selanjutnya—termasuk eksekusi pelatihan, optimasi parameter, dan penyaringan hasil—diselesaikan secara otomatis oleh jaringan. Dalam model ini, pelatihan AI diabstraksikan dari proses teknis yang kompleks menjadi proses sederhana "mengirimkan permintaan, menerima hasil", sehingga lebih mirip sebagai kemampuan umum daripada pekerjaan teknis dengan ambang masuk yang sangat tinggi.
2.2 Dari Sistem Tertutup ke Kolaborasi Terbuka: Masalah Apa yang Dipecahkan oleh Gradients
Perubahan inti Gradients terletak pada peralihan proses pelatihan yang sebelumnya tertutup dalam satu platform menjadi proses jaringan kolaboratif terbuka. Tugas pelatihan tidak lagi diselesaikan oleh satu sistem tunggal, tetapi didistribusikan kepada banyak peserta untuk dicoba secara paralel, kemudian dipilih hasil terbaik melalui mekanisme evaluasi terpadu. Struktur ini pertama-tama mengurangi ketergantungan pada penyedia terpusat, sehingga pelatihan didasarkan pada daya komputasi terdistribusi; sekaligus, sumber daya GPU yang tersebar diintegrasikan ke dalam jaringan yang sama, membentuk cara alokasi sumber daya yang lebih mendekati pasar melalui kompetisi. Lebih penting lagi, optimasi model tidak lagi terbatas pada satu jalur saja, tetapi terus mendekati solusi yang lebih baik melalui eksplorasi paralel berbagai metode, sehingga meningkatkan batas atas optimasi keseluruhan.
2.3 Perubahan Esensial: Dari Alat Menjadi "Pasar Pelatihan"
Dalam AutoML tradisional, platform lebih seperti alat yang membantu pengguna menemukan solusi optimal melalui algoritma internal. Di Gradients, proses ini lebih mirip dengan "pasar" yang berjalan terus-menerus: pengguna memposting kebutuhan mereka, berbagai peserta bersaing dalam tugas yang sama, dan hasilnya disaring melalui mekanisme evaluasi. Dengan demikian, kinerja model tidak lagi bergantung pada kemampuan sistem tunggal, tetapi berasal dari persaingan dan iterasi berkelanjutan oleh banyak pihak. AutoML pun berubah dari masalah optimasi teknis yang relatif tertutup menjadi proses dinamis yang didorong oleh insentif, memungkinkan kemampuan optimasi untuk terus berkembang seiring bertambahnya peserta. Perubahan ini membuat pelatihan AI mulai memiliki ciri evolusi mandiri yang mirip pasar.
2.4 Peran dalam ekosistem TAO: Lapisan infrastruktur pelatihan AI
Dalam sistem subnet Bittensor, subnet yang berbeda menjalankan fungsi berbeda seperti inferensi, pemrosesan data, dan pelatihan, dan Gradients berada di lapisan pelatihan. Ia bertanggung jawab untuk mengubah daya komputasi terdistribusi menjadi output model nyata, serta memungkinkan sumber daya ini untuk terus dijadwalkan dan dioptimalkan melalui mekanisme distribusi tugas dan evaluasi. Sekaligus, ia menghubungkan pasokan daya komputasi dengan kebutuhan model, mengubah proses pelatihan dari sekadar konsumsi sumber daya menjadi proses kolaborasi jaringan yang dapat diorganisasi dan dioptimalkan. Dalam sistem ini, Gradients lebih seperti elemen pusat yang mengubah sumber daya terdistribusi menjadi kemampuan AI yang dapat digunakan, serta mendukung pengembangan aplikasi lapisan atas.
3. Arsitektur inti: Bagaimana pelatihan AI dilakukan dalam jaringan
Pada bab sebelumnya, kami menyebutkan bahwa Gradients mengubah pelatihan AI dari "diselesaikan di dalam platform" menjadi "diselesaikan melalui kolaborasi jaringan". Lalu, bagaimana tepatnya jaringan ini beroperasi? Inti dari bab ini adalah menjelaskan proses ini dengan cara yang lebih intuitif.
3.1 Pelatihan terdistribusi: Bagaimana satu tugas diselesaikan oleh "banyak orang"
Bayangkan Gradients sebagai "jaringan kolaboratif pelatihan" yang berjalan terus-menerus. Ketika pengguna mengirimkan tugas pelatihan, tugas tersebut tidak akan diberikan kepada satu sistem saja, tetapi akan didistribusikan secara bersamaan ke beberapa peserta dalam jaringan. Para peserta ini akan mencoba berbagai metode pelatihan yang berbeda berdasarkan data dan tujuan yang sama, lalu mengirimkan hasilnya dalam waktu yang ditentukan. Selanjutnya, sistem akan mengevaluasi semua hasil tersebut secara terpadu dan memilih solusi terbaik. Solusi yang lebih unggul akan menerima hadiah, sementara solusi lainnya akan disingkirkan. Dari sudut pandang pengguna, proses ini hanya memerlukan satu kali inisiasi tugas, seolah-olah secara bersamaan "memanggil" berbagai pendekatan optimasi yang berbeda dan secara otomatis memilih solusi terbaik. Kunci pendekatan ini bukan pada seberapa kuat satu node, tetapi pada penggunaan percobaan paralel oleh banyak orang + penyaringan otomatis, sehingga hasil terus mendekati solusi optimal.
Dalam jaringan ini, terdapat tiga jenis peserta utama: pengguna, penambang, dan validator. Pengguna bertanggung jawab untuk mengajukan permintaan pelatihan; penambang menyediakan daya komputasi dan mencoba berbagai metode pelatihan; validator bertanggung jawab untuk mengevaluasi hasil dan memilih model terbaik. Pembagian tugas ini memungkinkan proses pelatihan berjalan terus-menerus dan terus-menerus menyaring solusi yang lebih optimal. Secara keseluruhan, ini membentuk jaringan kolaboratif yang didorong oleh “permintaan, pasokan, dan evaluasi”.
3.2 AutoML yang Didorong Pasar
Dalam dekomposisi mekanisme sebelumnya, terlihat bahwa Gradients tidak sekadar memindahkan AutoML ke blockchain, tetapi mengubah logika dasar optimasi model dengan memperkenalkan partisipasi pihak banyak dan mekanisme insentif. AutoML tradisional bergantung pada sistem tunggal yang mencari solusi optimal dalam jalur terbatas, sedangkan dalam Gradients, proses ini diperluas ke seluruh jaringan: partisipan berbeda terus mencoba berbagai pendekatan untuk tugas yang sama dan secara berkelanjutan menyaring serta mengiterasi melalui evaluasi terpadu. Ini membuat optimasi model bukan lagi proses komputasi sekali jalan, melainkan proses dinamis yang dapat berkembang berulang-ulang. Dalam mekanisme ini, hasil dengan kinerja lebih baik akan memperoleh imbalan lebih tinggi, sehingga terus menarik partisipan untuk menyempurnakan strategi mereka dan mendorong peningkatan efek keseluruhan.
4. Mekanisme insentif dan kompetisi: Bagaimana pelatihan AI membentuk "siklus positif"
4.1 Mekanisme insentif (digerakkan oleh TAO): Dari perilaku pelatihan hingga pengembalian keuntungan
Kunci agar Gradients dapat beroperasi jangka panjang terletak pada mekanisme insentif di belakangnya. Hal ini bergantung pada sistem insentif asli yang disediakan oleh Bittensor. Di sini, TAO adalah token asli jaringan Bittensor, berfungsi sebagai "wadah nilai" dalam seluruh jaringan: di satu sisi digunakan untuk memberi insentif kepada peserta yang menyediakan daya komputasi dan kontribusi model, di sisi lain juga terlibat dalam alokasi bobot subnet melalui cara-cara seperti staking, memengaruhi bagaimana sumber daya mengalir di antara berbagai subnet.
Bittensor mainnet terus menghasilkan insentif Emission baru berupa TAO (saat ini jumlah harian yang sesuai sekitar 3600 TAO), dan mendistribusikannya ke berbagai subnet sesuai aturan tertentu. Jumlah TAO yang diterima setiap subnet bergantung pada "kinerja" subnet tersebut dalam jaringan secara keseluruhan, seperti tingkat aktivitas, kualitas kontribusi, dan dukungan dana. Untuk subnet tempat Gradients berada, TAO yang dialokasikan ini akan didistribusikan kembali di dalamnya kepada para peserta. Dasar utama distribusi adalah siapa yang menyumbangkan model lebih baik, maka akan mendapatkan lebih banyak imbalan.
Secara rinci, penambang mengirimkan hasil pelatihan, sedangkan validator bertanggung jawab untuk menguji dan memberi skor hasil tersebut. Sistem akan menghitung "kredit kontribusi" setiap peserta berdasarkan skor, lalu mendistribusikan reward sesuai kredit tersebut. Model yang berkinerja lebih baik (misalnya, dengan kemampuan generalisasi lebih kuat dan hasil lebih stabil) akan memperoleh penghasilan lebih tinggi, sementara validator yang memberi skor lebih akurat dan lebih mencerminkan kualitas sebenarnya juga akan mendapat insentif lebih besar. Desain ini membuat "melakukan lebih baik" secara langsung berhubungan dengan "menghasilkan lebih banyak", sehingga mendorong peserta terus mengoptimalkan model mereka.
4.2 Persaingan antar subnet: Bukan hanya persaingan internal, tetapi juga peringkat eksternal
Selain persaingan di dalam subnet, Gradients juga menghadapi "persaingan horizontal" di seluruh jaringan Bittensor. Karena alokasi TAO bersifat dinamis, subnet-subnet berbeda bersaing untuk mendapatkan bobot yang lebih tinggi. Hanya subnet yang terus menghasilkan hasil berkualitas tinggi dan menarik lebih banyak peserta yang akan memperoleh bagian insentif yang lebih besar. Oleh karena itu, insentif Gradients tidak hanya bergantung pada kinerja model internal, tetapi juga pada daya saing relatifnya di seluruh ekosistem. Seluruh sistem membentuk mekanisme umpan balik berlapis: di dalam subnet terjadi persaingan antar model; di antara subnet terjadi persaingan kinerja keseluruhan. Pada akhirnya, investasi komputasi, efektivitas model, dan imbalan ekonomi saling terkait, menciptakan mekanisme umpan balik positif yang berjalan terus-menerus.
4.3 Gradients 5.0: Dari Kompetisi ke "Mekanisme Turnamen"
Berdasarkan persaingan berkelanjutan di tahap awal, Gradients berkembang menjadi mekanisme yang lebih terstruktur, yaitu "pelatihan bertahap". Ini dapat dipahami sebagai kompetisi berkala: setiap siklus pelatihan menetapkan jendela waktu, di mana beberapa peserta bersaing dalam tugas yang sama dan secara bertahap disaring melalui beberapa putaran hingga akhirnya memilih solusi terbaik. Bentuk ini menekankan perbandingan bertahap dan evaluasi terpusat. Perubahan penting terletak pada fakta bahwa penambang tidak lagi mengirimkan hasil pelatihan secara langsung, tetapi mengirimkan "metode pelatihan" (kode), yang kemudian dieksekusi secara seragam oleh node verifikasi. Hal ini meningkatkan keadilan dengan menghindari gangguan dari lingkungan komputasi yang berbeda, sekaligus lebih baik melindungi privasi data dan proses pelatihan. Selain itu, solusi pemenang sering kali diabadikan sebagai metode yang dapat digunakan kembali, mirip dengan "praktik terbaik" yang terus berkembang. Dalam jangka panjang, mekanisme ini tidak hanya menyaring model terbaik, tetapi juga membangun perpustakaan metode pelatihan yang terus berkembang.
5. Status ekosistem
5.1 Struktur peserta: Jaringan kolaboratif yang terdiri dari permintaan, penawaran, dan evaluasi
Ekosistem Gradients terdiri dari tiga peran inti: pengguna (sisi permintaan), penambang (sisi penawaran), dan validator (sisi evaluasi). Pengguna terutama mencakup pengembang AI, UMKM, dan pembangun Web3, kelompok ini biasanya memiliki dasar teknis tertentu, tetapi kurang memiliki daya komputasi atau kemampuan pelatihan model lengkap, sehingga lebih cenderung menggunakan Gradients untuk membangun model dengan biaya lebih rendah. Penambang menyediakan daya GPU dan berpartisipasi dalam persaingan tugas pelatihan, dengan motivasi utama mereka adalah memperoleh imbalan TAO; validator bertanggung jawab untuk mengevaluasi dan mengurutkan hasil pelatihan, yang merupakan elemen kunci dalam memastikan kualitas model dan kelancaran mekanisme.
Dari segi profil pengguna yang lebih spesifik, kelompok pengguna aktif Gradients menunjukkan ciri "semi-developer": berbeda dari laboratorium AI tingkat atas, namun juga bukan pengguna umum tanpa latar belakang teknis, melainkan terutama terdiri dari pengembang dengan kemampuan teknis tertentu dan pengguna teknologi Web3. Hal ini juga tercermin dalam struktur komunitasnya, di mana ekosistem saat ini didominasi bahasa Inggris, dengan pengguna inti terutama berada di kalangan pengembang di Amerika Utara dan Eropa, serta mencakup sebagian penambang Asia Tenggara dan penyedia sumber daya GPU global. Secara keseluruhan, hal ini mendekati komunitas pengembang yang didorong oleh teknologi.
5.2 Status Operasional Ekosistem
Pada 12 Mei, harga token alpha Gradients sekitar 0,0255 TAO, dengan sekitar 4.890 alamat pemegang token, 243 penambang, dan 12 validator, dengan kontribusi Emission sebesar 1,61%. Sementara itu, dalam kolam likuiditasnya, proporsi TAO adalah 2,19% dan Alpha adalah 97,81%. Dari segi harga dan jumlah alamat pemegang, Gradients telah memiliki basis pengguna dan perhatian tertentu, tetapi secara keseluruhan masih berada pada tahap awal penyebaran. Sebagai perbandingan, proyek terkemuka di ekosistem TAO, Chutes, pada hari yang sama memiliki harga token alpha sebesar 0,0877 TAO dengan 13.409 alamat pemegang.
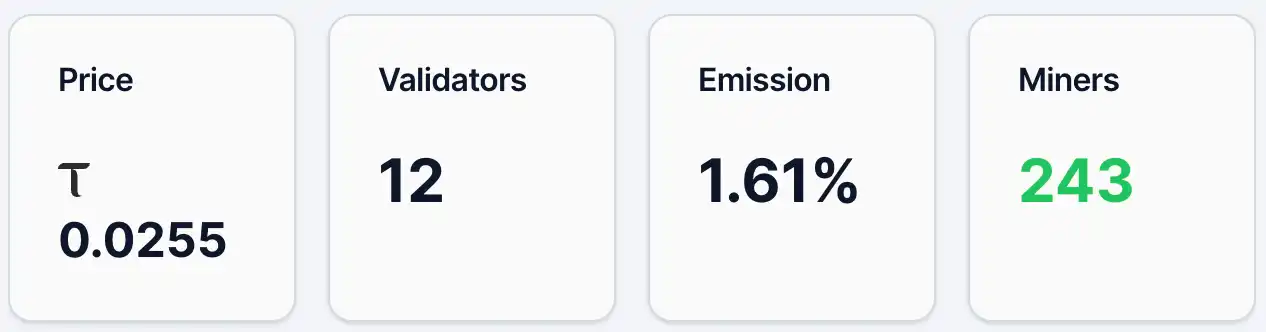
Gambar 1. Data gradien.
Sumber:https://bittensormarketcap.com/subnets/56
Selanjutnya adalah mekanisme insentif Emission. Dalam sistem Bittensor, Emission merujuk pada bobot alokasi real-time dari sub-jaringan dalam tambahan insentif jaringan secara keseluruhan. Jaringan Bittensor terus menghasilkan TAO baru dan mendistribusikannya sesuai bobot ke berbagai sub-jaringan, dan 1,61% saat ini pada Gradients berarti ia hanya menerima sebagian kecil dari total insentif baru jaringan. Indikator ini pada dasarnya mencerminkan "hasil voting" pasar melalui arus dana (seperti staking) terhadap berbagai sub-jaringan. Oleh karena itu, level 1,61% biasanya berarti tingkat penerimaan pasar dan aliran dana saat ini relatif terbatas, namun di sisi lain juga menunjukkan potensi peningkatan bobot di masa depan. Dari segi struktur dana (kolam likuiditas), persentase TAO hanya 2,19%, sementara Alpha mencapai 97,81%, yang menunjukkan bahwa aliran dana eksternal masih terbatas dan saat ini lebih didominasi oleh pasokan internal sub-jaringan. Harga sangat sensitif terhadap dana tambahan; jika lebih banyak TAO mengalir masuk, kemungkinan besar akan menghasilkan efek penggandaan yang lebih signifikan.
6. Lanskap persaingan dan kelebihan serta kekurangan
6.1 Posisi industri: Infrastruktur pelatihan AutoML terdesentralisasi
Gradients berada di segmen spesifik "infrastructure pelatihan AI + AutoML terdesentralisasi". Ia berusaha melepaskan pelatihan model dari platform terpusat dan mencapai pemanfaatan sumber daya serta optimasi model yang lebih efisien melalui mekanisme jaringan. Dalam sistem Web2, segmen ini sudah relatif matang, dengan perwakilan khas seperti Google Vertex AI dan AWS SageMaker. Platform-platform ini menyediakan layanan pelatihan dan penyebaran model all-in-one bagi pengembang melalui komputasi awan, tetapi pada dasarnya tetap merupakan arsitektur terpusat. Sebaliknya, perbedaan Gradients bukan terletak pada "fitur yang lebih banyak", melainkan pada logika dasar yang berbeda: ia mengubah pelatihan dari "layanan platform" menjadi "kolaborasi jaringan", dan memilih hasil terbaik melalui mekanisme kompetisi, sehingga lebih mendekati sistem pelatihan yang beroperasi secara pasar.
6.2 Perbandingan Horizontal: Perbedaan antara Web2 dan Web3 AutoML
Dari sudut pandang yang lebih luas, perbedaan antara Web2 dan Web3 dalam arah AutoML pada dasarnya adalah perbandingan antara dua paradigma berbeda. Model Web2 menekankan efisiensi dan stabilitas, dengan memanfaatkan sumber daya terpusat dan optimasi teknik untuk menyediakan pengalaman layanan yang terkendali dan matang; sementara model Web3 lebih menekankan keterbukaan dan mekanisme insentif, dengan memperkenalkan partisipasi banyak pihak sehingga optimasi model terus berkembang melalui persaingan. Secara spesifik, AutoML Web2 lebih seperti "sebuah alat yang kuat", di mana pengguna menyerahkan tugasnya ke platform, dan sistem secara internal mencari solusi optimal; sementara AutoML Web3 yang diwakili oleh Gradients lebih seperti "sebuah pasar terbuka", di mana pengguna mempublikasikan kebutuhan mereka, dan berbagai peserta menyediakan solusi, kemudian hasilnya disaring melalui mekanisme evaluasi. Perbedaan ini membawa dampak langsung: yang pertama lebih stabil dan terkendali, tetapi jalur optimasi terbatas; yang kedua memiliki ruang eksplorasi yang lebih luas dan potensi batas atas yang lebih tinggi, namun masih memiliki ruang untuk peningkatan dalam hal stabilitas dan kematangan.
6.3 Diferensiasi Gradients di Web3
Di jalur Web3 AI saat ini, sebagian besar proyek masih berfokus pada lapisan inferensi atau AI Agent, sementara proyek yang berfokus pada “infrastructure pelatihan” relatif sedikit. Beberapa proyek mencoba menggabungkan jaringan komputasi atau jaringan data untuk menyediakan kemampuan pelatihan, tetapi secara keseluruhan, kebanyakan masih berada pada tahap pengaturan sumber daya atau pasar komputasi. Perbedaan Gradients terletak pada fakta bahwa ia tidak hanya menyediakan pertemuan komputasi, tetapi juga melangkah lebih jauh ke dalam “mekanisme optimasi model” itu sendiri, dengan memperkenalkan sistem evaluasi dan kompetisi yang memungkinkan proses pelatihan memiliki kemampuan berkembang secara berkelanjutan. Ini berarti, ia tidak hanya menyelesaikan “dari mana asal komputasi”, tetapi juga “bagaimana menggunakan komputasi ini secara lebih efisien”. Dari sudut pandang posisi, Gradients lebih dekat menjadi jaringan yang berorientasi pada hasil pelatihan, bukan sekadar pasar komputasi atau platform alat, yang merupakan perbedaan intinya dengan sebagian besar proyek Web3 AI lainnya.
6.4 Keunggulan Utama: Peningkatan Efisiensi yang Didorong oleh Mekanisme
Secara keseluruhan, keunggulan Gradients terutama terletak pada desain mekanismenya. Pertama, ia mengurangi hambatan penggunaan melalui abstraksi tugas, memungkinkan pengguna untuk mendapatkan hasil model tanpa perlu terlibat mendalam dalam proses pelatihan yang kompleks, sehingga memperluas basis pengguna potensial. Kedua, di tingkat sumber daya, pengenalan kekuatan komputasi terdistribusi membuat pelatihan tidak lagi bergantung pada penyedia cloud tunggal, secara teori dapat membentuk struktur biaya yang lebih elastis melalui persaingan. Lebih penting lagi, perubahan dalam cara optimasi. Dengan eksplorasi paralel oleh banyak peserta dan penggabungan mekanisme penyaringan, Gradients menyediakan solusi yang berbeda dari optimasi jalur tunggal tradisional, memberi peluang bagi model untuk mencapai kinerja lebih optimal dalam waktu yang lebih singkat. Model "optimasi yang didorong oleh persaingan" ini merupakan keunggulan paling intinya.
6.5 Tantangan Potensial
Kualitas model mungkin mengalami masalah stabilitas. Pelatihan terdesentralisasi bergantung pada partisipasi pihak-pihak banyak, meskipun dapat meningkatkan batas atas, tetapi juga dapat menyebabkan fluktuasi hasil, dibandingkan sistem terpusat, terdapat ketidakpastian tertentu dalam hal kendali. Selanjutnya adalah masalah kepercayaan tingkat perusahaan. Bagi pengguna perusahaan, keamanan data dan verifiabilitas proses pelatihan sangat penting, dan bagaimana memastikan data tidak disalahgunakan serta hasil dapat diaudit dalam lingkungan terdesentralisasi tetap menjadi tantangan utama. Terakhir adalah ketergantungan pada ekonomi Token. Operasi Gradients sangat bergantung pada mekanisme insentif; jika daya tarik imbalan TAO menurun, hal ini dapat memengaruhi tingkat partisipasi penambang dan aktivitas jaringan secara keseluruhan. Oleh karena itu, keberlanjutan jangka panjangnya sebagian besar bergantung pada apakah model ekonomi mampu membentuk siklus positif yang stabil.
7. Prospek Masa Depan: Apakah AutoML terdesentralisasi dapat terwujud?
Dari tahap saat ini, Gradients masih berada di tahap awal, dan apakah masa depannya dapat benar-benar berjalan tergantung pada beberapa poin kunci. Yang paling penting adalah apakah ia dapat terus menarik permintaan pelatihan nyata, bukan hanya partisipasi yang didorong insentif; selanjutnya adalah kualitas model, apakah pendekatan terdesentralisasi dapat secara stabil menghasilkan hasil yang dapat digunakan, bahkan lebih baik; serta apakah mekanisme ekonomi dapat membentuk siklus positif, menjaga keseimbangan jangka panjang antara pasokan daya komputasi dan imbalan.
Dalam konteks industri yang lebih luas, pelatihan AI sedang memisahkan menjadi dua jalur. Satu jalur adalah model Web2, yang dipimpin oleh perusahaan teknologi terkemuka, yang terus memperkuat kinerja model melalui sumber daya dan kemampuan teknik yang terpusat, dengan keunggulan pada stabilitas dan kematangan; jalur lainnya adalah jalur Web3 yang diwakili oleh Gradients, yang memungkinkan lebih banyak partisipan untuk berkontribusi dalam optimasi model melalui jaringan terbuka dan mekanisme insentif, terus meningkatkan batas atasnya dalam persaingan. Yang pertama adalah “membangun sistem yang lebih kuat”, sementara yang kedua lebih mirip “membangun jaringan yang berevolusi secara mandiri”.
Dari sudut pandang ini, eksplorasi Gradients mewakili kemungkinan baru: pelatihan AI tidak lagi hanya menjadi masalah teknis, tetapi kombinasi dari “kekuatan komputasi + data + mekanisme pasar”. Jika model ini dapat terwujud, ia berpotensi menjadi pintu masuk pelatihan AI terdesentralisasi dan memainkan peran infrastruktur kunci dalam ekosistem Bittensor. Tentu saja, arah ini masih memerlukan waktu untuk diverifikasi, tetapi ia telah memberikan pandangan evolusi berbeda bagi AutoML yang berbeda dari jalur tradisional.
Referensi
1. Dokumentasi Bittensor:https://docs.learnbittensor.org
2. Situs Gradients:https://www.gradients.io/
3. Gradients:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats:https://taostats.io/subnets/56/chart