









DeepSeek V4 akhirnya diluncurkan. Ini adalah momen yang telah ditunggu selama hampir lima bulan. Model utama MoE dengan 1T parameter + versi Flash dengan 285B parameter, versi Pro lengkap 1,6T segera menyusul, seluruhnya di-open source ke GitHub dengan lisensi Apache 2.0, bobot dan kode penyebaran dirilis secara bersamaan.
Ketika model tersebut muncul, pasar modal memberikan jawabannya melalui tiga cara yang saling independen namun saling terkait.
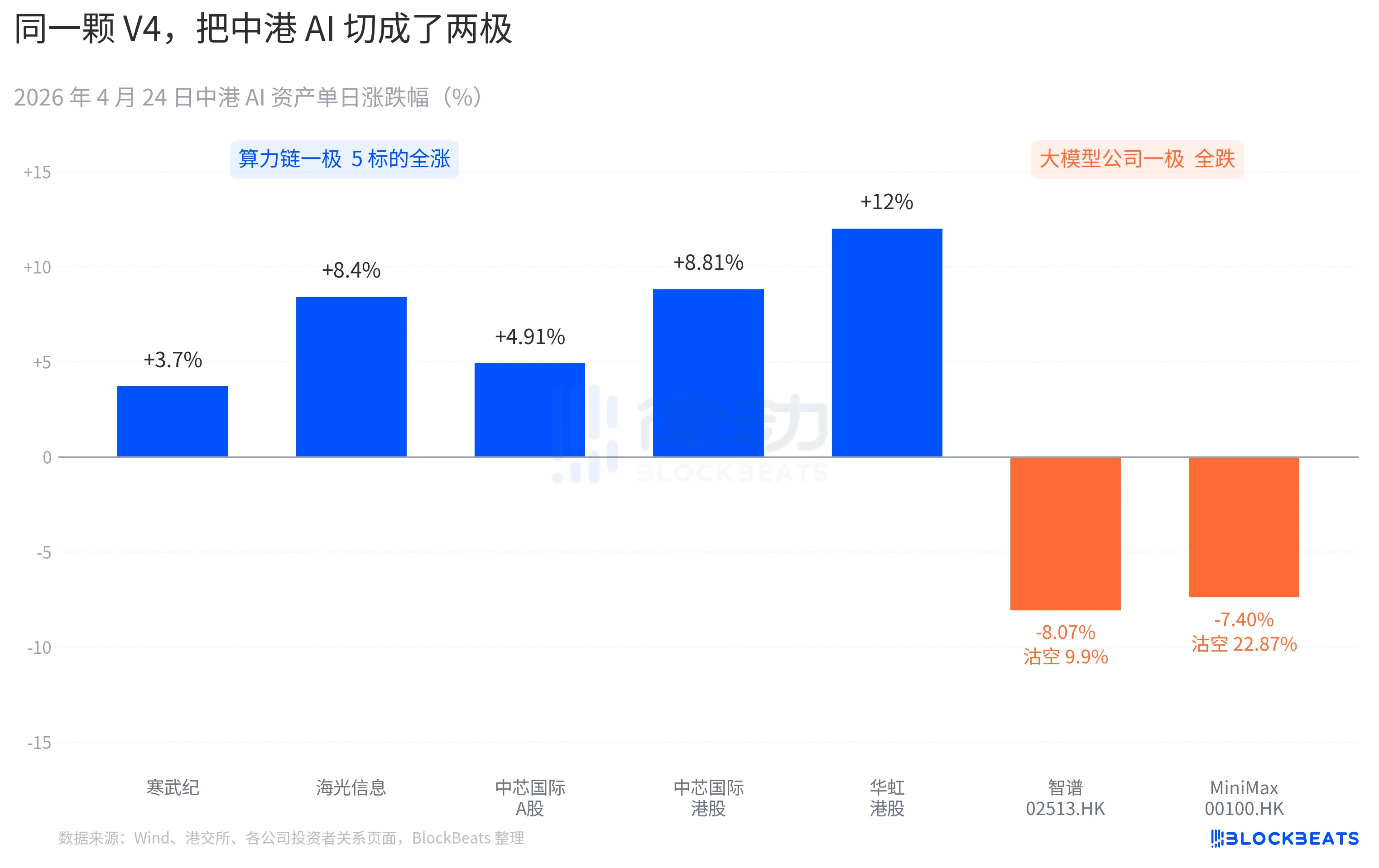
Reaksi berbeda dari pasar modal
Sebagian besar saham rantai kekuatan komputasi A melonjak. Cambricon mencatat 11 kenaikan berturut-turut, naik 3,7% dalam sehari, dengan kenaikan akumulatif bulan ini melebihi 60%. Hygon Information menyentuh batas atas 10% selama sesi, menutup pada +8,4%. SMC A-share +4,91%, saham HK +8,81%. Hua Hong HK mencapai puncak +18%, menutup pada +12%. ETF nasional chip teknologi ilmiah Guotai menyerap dana sebesar 2,4 miliar yuan dalam sehari, dengan total aset mencapai level tertinggi sepanjang sejarah.
Perusahaan model besar Hong Kong memiliki warna yang berbeda. Zhipu (02513.HK) turun 8,07%, dengan rasio short selling 9,9%. MiniMax (00100.HK) turun 7,40%, dengan rasio short selling melonjak menjadi 22,87%. Yang terakhir mencatat data short selling harian tertinggi dalam tiga bulan terakhir di sektor AI Hong Kong. Kedua perusahaan ini merupakan perwakilan dari gelombang IPO AI Hong Kong pada paruh kedua 2025, dengan kompetensi inti yang sama tertulis dalam prospektus IPO: “model dasar self-developed”.
Reaksi di sisi lain Pasifik juga spesifik. Nvidia turun 1,8% pada pembukaan 24 April, sempat jatuh hingga -2,6% selama sesi, dan menutup perdagangan datar. Evaluasi pasar Bloomberg membandingkan koreksi ini dengan "moment DeepSeek V3" pada 27 Januari. Perbedaannya, pada Januari lalu terjadi penjualan panik yang menghilangkan $600 miliar nilai pasar dalam satu hari. Kali ini lebih mirip restrukturisasi harga, dengan volume moderat tetapi arah yang jelas. Dalam catatan riset institusi pembeli muncul ungkapan baru: "Permintaan AI inferensi Tiongkok mulai terpisah dari permintaan AI inferensi di Amerika Utara."
Menumpuk ketiga pasar ini bersama-sama adalah putusan pertama yang ditulis oleh pasar dalam 24 jam setelah peluncuran V4. Setelah open source menang, uang mulai memilih sisi lagi; yang bisa menentukan harga bukan lagi modelnya sendiri, tetapi di kartu mana model tersebut berjalan dan di dalam rantai industri mana ia dipasang.
30 hari, 11 model baru, V4 menambah semangat pada komunitas open-source
Jendela waktu peluncuran V4 sendiri merupakan sebagian penyebab penguatan respons ini.
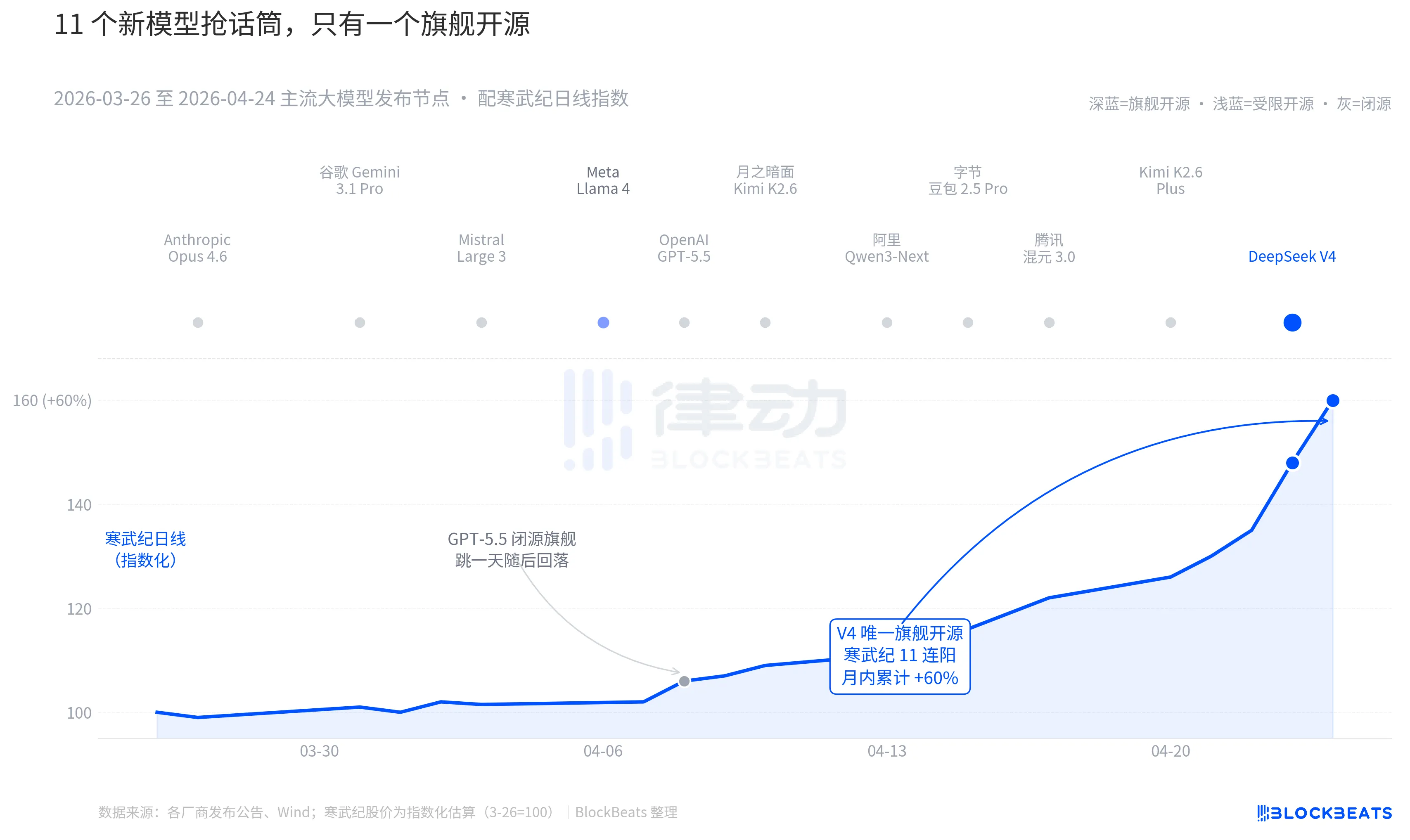
Tarik kembali kamera ke 30 hari lalu. Antara 26 Maret hingga 24 April, setidaknya 11 model besar dengan dampak signifikan dirilis atau diperbarui secara besar-besaran di seluruh dunia, mencakup hampir semua pemain utama. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonshot Kimi K2.6, Alibaba Qwen3-Next, ByteDance DouBao 2.5 Pro, Tencent HunYuan 3.0, Kimi K2.6 Plus, dan terakhir DeepSeek V4 yang dirilis pada 23 April pukul 00:00.
Rata-rata, satu model baru muncul setiap 2,7 hari. Ini adalah kecepatan yang bahkan manajer dana tidak sempat membaca rilisnya. Namun, setelah menelusuri grafik K-line aset AI Tiongkok-Hong Kong selama 30 hari ini, hanya satu nama yang meninggalkan jejak berkelanjutan di chart. GPT-5.5 pada 8 April mendorong NVIDIA naik 4,2% dalam satu hari, mencapai puncaknya sehari saja. Kemudian, DeepSeek V4 pada 23-24 April mendorong rantai komputasi Tiongkok-Hong Kong mengalami lonjakan beruntun.
Perbedaan bukan terletak pada kemampuan model itu sendiri. Selisih antara 11 model ini di peringkat LMArena, dalam banyak kasus, tidak lebih dari 50 poin, berada dalam rentang sempit yang sama. Perbedaan terletak pada akumulasi dua hal.
Yang pertama adalah open-source. Dari 10 model teratas, hanya Llama 4 yang open-source, tetapi lisensi bobot Llama 4 dilengkapi daftar panjang batasan komersial, sehingga mendapat tanggapan dingin dari komunitas pengembang Eropa dan Amerika, dan jatuh dari sepuluh besar di OpenRouter pada hari ketiga peluncuran. Protokol V4 adalah Apache 2.0, bobot tanpa hambatan, tanpa batasan komersial, dan kode inferensi dirilis secara bersamaan. Ini adalah model open-source unggulan pertama dalam enam bulan terakhir yang memberikan tekanan simultan terhadap kamp tertutup dalam tiga aspek: kinerja, harga, dan keterbukaan.
Yang kedua adalah waktu. Di tengah lanskap di mana pihak tertutup terus meluncurkan inovasi besar, narasi open-source terus ditekan. Opus 4.6 mendorong tugas kode SWE-Bench ke level baru, sementara GPT-5.5 menetapkan harga per juta token di titik anchoring bawah sebesar $1,25. Perdebatan apakah open-source bisa mengejar pihak tertutup telah berlangsung selama dua tahun di Silicon Valley. V4, dengan estimasi pengguna aktif dalam sebulan yang mencapai 90 juta, menjadi flagship open-source yang menghentikan sementara perdebatan ini.
Menurut seorang manajer dana besar domestik dalam presentasi路演, "Sebelum V4, kami memberikan diskon pada valuasi model besar open-source; setelah V4, diskon ini mulai berbalik."
DeepSeek mengganti daftar harga rantai pasokan daya komputasi.
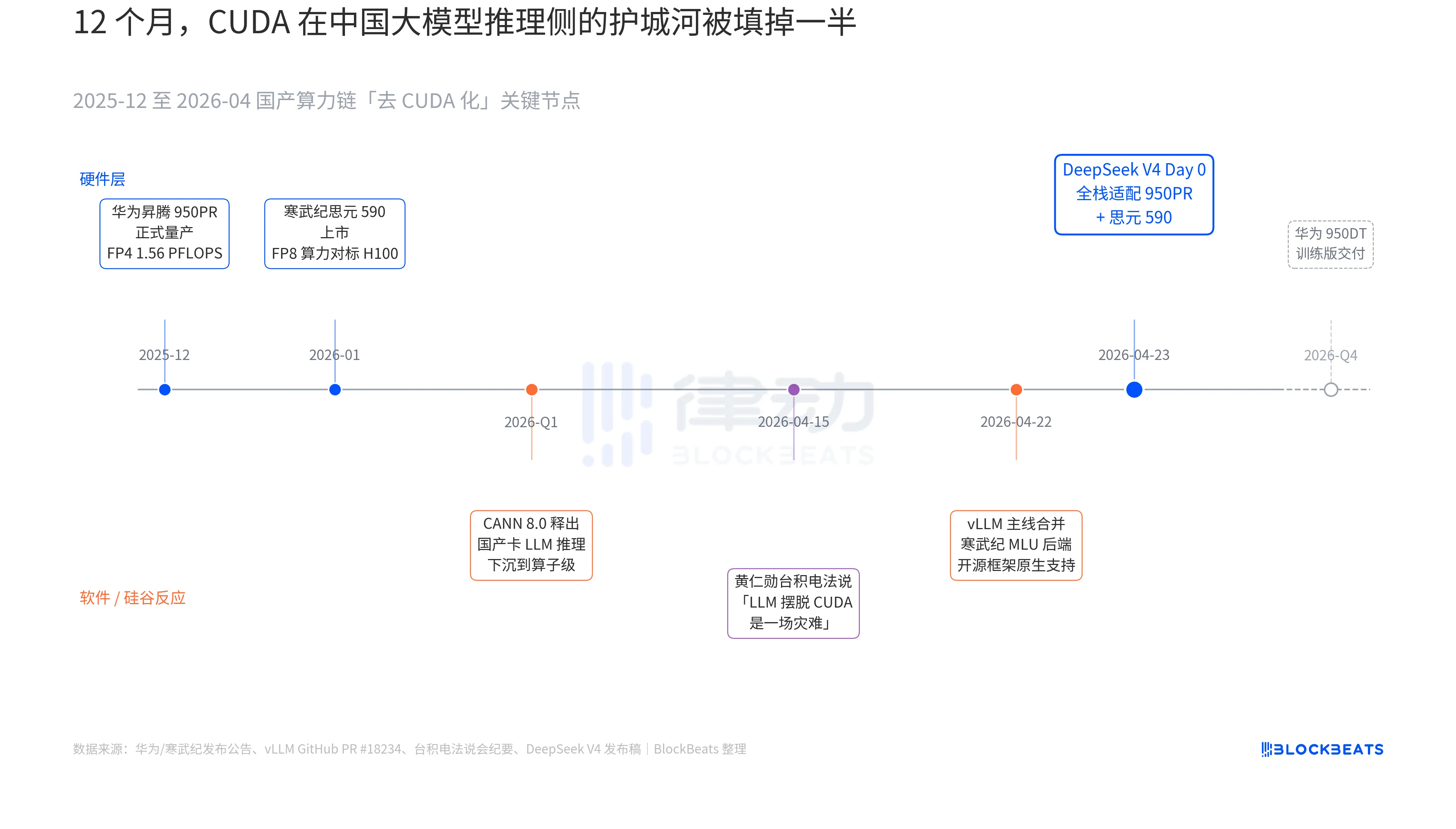
Dalam rilis V4, ada satu baris yang sebelumnya tidak pernah muncul di dokumen resmi model besar China mana pun: "Hari 0, seluruh stack disesuaikan dengan Cambricon MLU590 dan Huawei Ascend 950PR, kode deployment dibuka secara bersamaan." Makna baris ini hanya bisa dipahami jika menghubungkan tiga garis rahasia yang berjalan paralel selama 12 bulan terakhir: masing-masing terkait perangkat keras, perangkat lunak, dan reaksi dari Silicon Valley.
Garis rahasia pertama berada di sisi chip. Huawei Ascend 950PR mulai diproduksi secara massal pada Desember 2025, dengan kekuatan FP4 sebesar 1,56 PFLOPS dan kapasitas HBM 112 GB, menjadi chip AI buatan dalam negeri pertama yang secara langsung menyaingi seri B NVIDIA dalam indikator teknis. Dalam tugas inferensi MoE dengan parameter 1T seperti V4, throughput per kartu meningkat 2,87 kali dibanding H20. Stack perangkat lunak CANN 8.0 yang mendukungnya mengoptimalkan kerangka kerja inferensi LLM hingga tingkat operator; benchmark yang dirilis DeepSeek menunjukkan bahwa latensi end-to-end inferensi V4 pada super-node Ascend (8 kartu 950PR) 35% lebih rendah dibanding cluster H100 dengan skala setara. Data寒武纪思元 590 lebih agresif, dengan kekuatan FP8 per chip yang sebanding dengan H100, namun harganya kurang dari separuhnya.
Garis rahasia kedua ada di sisi perangkat lunak. Pada 22 April, vLLM menggabungkan PR backend MLU dari Cambricon, sehingga kerangka kerja inferensi open-source pertama kali mendukung secara native GPU buatan dalam negeri selain NVIDIA. DCU dari Hygon Information melewati jalur lain melalui ekosistem ROCm, tetapi mampu menjalankan lapisan routing MoE V4 secara lengkap. Ini berarti penyebaran V4 tidak lagi "hanya bisa berjalan di satu jenis kartu buatan dalam negeri", melainkan "bisa dipilih di antara beberapa jenis kartu buatan dalam negeri". Ketergantungan ekosistem terhadap pemasok tunggal telah dipecahkan—ini merupakan titik balik penting untuk produksi.
Garis rahasia ketiga berasal dari Silicon Valley. Pada 15 April, Huang Renxun dihadapkan oleh analis dalam konferensi laporan台积电 tentang kemajuan daya komputasi buatan Tiongkok, jawabannya dingin dan spesifik: "Jika mereka benar-benar bisa melepaskan LLM dari CUDA, itu akan menjadi bencana (a disaster) bagi kami." Sembilan hari kemudian, DeepSeek memberikan jawabannya melalui satu pengumuman Day 0.
Empat kata "penggantian domestik" telah terlalu sering digunakan selama tiga tahun terakhir hingga kehilangan maknanya. Namun, setelah 24 April pagi hari, untuk pertama kalinya ada data konkret yang dapat dinilai oleh pasar modal: throughput per kartu, latensi inferensi end-to-end, biaya inferensi, dan kode penyebaran yang siap komersial—dengan diam-diam mendorong perang retorika panjang ini melewati ambang produksi.
Logika di balik 11 kenaikan harga saham Kunlun bersembunyi di sini. Ia tidak lagi sekadar saham «konsep GPU domestik», tetapi «pemasok infrastruktur inferensi DeepSeek V4». Logika yang sama juga menjelaskan kenaikan 12% saham Hua Hong di pasar港股, karena ia memproduksi proses setara 7nm untuk 950PR. Setiap token V4 yang dijalankan di Ascend domestik berarti sebagian kapasitas yang sebelumnya mengalir ke NVIDIA dan TSMC sekarang terhenti sebagian di Delta Sungai Zhujiang.
Langkah selanjutnya sudah disiapkan. Dalam peta jalan Huawei, 950DT (versi pelatihan) direncanakan akan diluncurkan pada kuartal keempat 2026, dengan target «pelatihan penuh stack pada kluster 10.000 GPU untuk model V5 atau setara». Jika jalur ini berhasil dijalankan, keunggulan CUDA dalam pelatihan model besar di Tiongkok akan turun dari «diperlukan» menjadi «opsional».
Sumber: Lüdong BlockBeats