









Minggu lalu, ketika Anthropic meluncurkan Mythos Preview, reaksi komunitas keamanan dapat digambarkan dengan satu kata: terkejut.
Sebuah model AI secara mandiri menemukan kerentanan eksekusi kode jarak jauh yang telah tersembunyi selama 17 tahun di FreeBSD, mengidentifikasi kelemahan protokol TCP di OpenBSD yang tidak diperhatikan selama 27 tahun, serta secara independen menulis kode serangan yang berfungsi. Anthropic kemudian mengumumkan Project Glasswing, membentuk konsorsium bersama sejumlah perusahaan teknologi yang berkomitmen menyediakan kredit senilai seratus juta dolar AS untuk memperbaiki kerentanan keamanan perangkat lunak sumber terbuka.
Serangkaian operasi ini sangat memicu industri, Mythos ternyata bisa sekuat ini, manusia benar-benar akan selesai... tunggu dulu, tidak secepat itu.
Model murah juga bisa menemukan kerentanan yang sama
AISLE adalah perusahaan rintisan yang berfokus pada keamanan AI. Sejak pertengahan 2025, mereka telah menggunakan sistem AI untuk menemukan kerentanan dan memperbaiki patch pada perangkat lunak sumber terbuka, serta telah mengidentifikasi dan memperbaiki lebih dari 180 kerentanan keamanan yang diakui oleh komunitas sumber terbuka, termasuk beberapa masalah tersembunyi yang telah ada selama lebih dari 25 tahun.
Setelah Mythos dirilis, mereka melakukan hal yang tajam: menggunakan kerentanan yang ditunjukkan oleh Mythos untuk dijalankan pada sejumlah model kecil yang jauh lebih murah. Kerentanan ini disebut sebagai 'zero-day vulnerabilities', berisiko sangat tinggi; begitu ditemukan, tim keamanan hampir tidak memiliki waktu untuk bereaksi.
Hasilnya sangat mengejutkan.
Kerentanan inti yang ditemukan oleh Mythos dan disembunyikan selama 17 tahun juga digunakan oleh Anthropic untuk "menunjukkan kekuatan" saat peluncuran. AISLE menguji 8 model, dan semua berhasil ditemukan, termasuk model dengan parameter kecil dan biaya hanya $0,11 per juta token—harga ini sekitar puluhan kali lebih murah daripada Mythos. Di antaranya, DeepSeek R1 dapat dikatakan paling akurat, sesuai dengan tata letak stack aktual dalam dokumen eksploitasi yang telah dirilis.
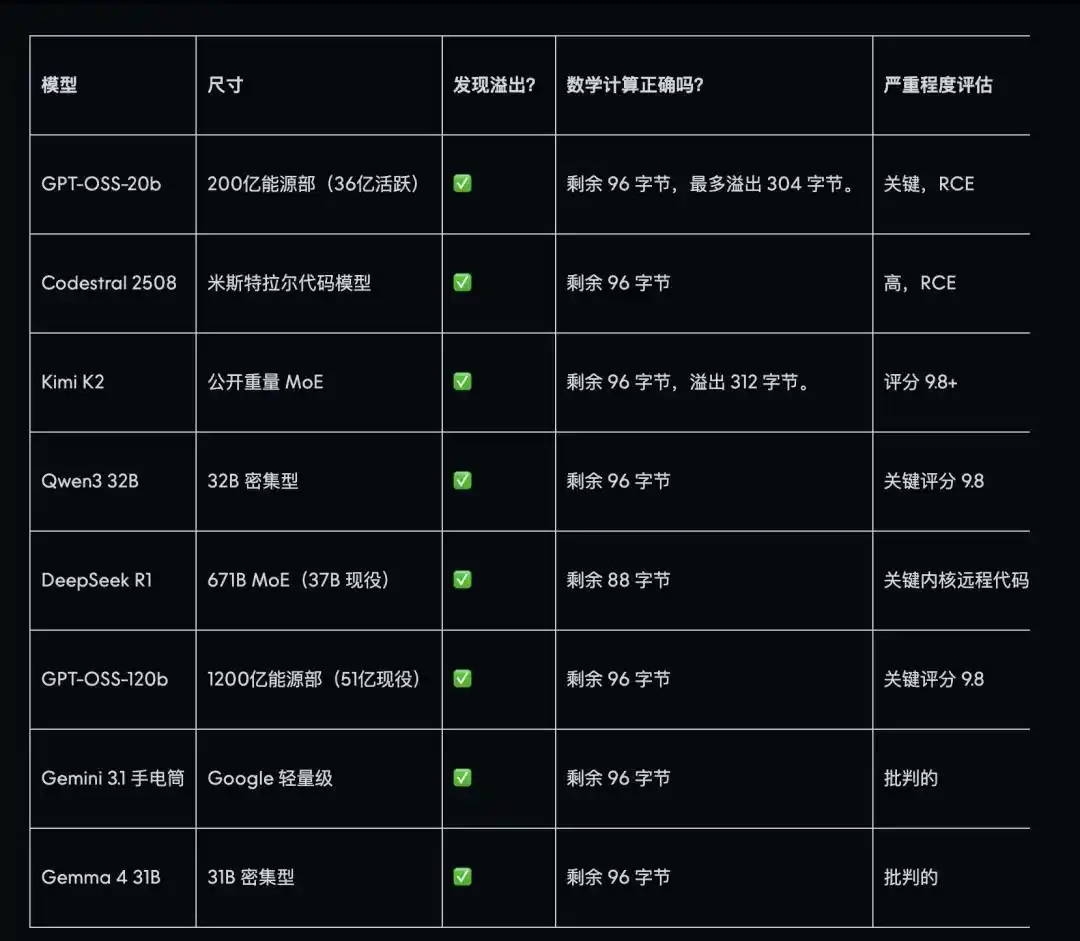
Sebagian besar model tidak hanya menemukan kerentanan, tetapi juga secara tepat menilai bahwa kerentanan tersebut dapat dieksploitasi dari jarak jauh, serta memberikan penilaian tingkat bahaya.
Lubang lain yang telah tersembunyi selama 27 tahun lebih sulit dan memerlukan pemahaman terhadap prinsip matematika yang lebih mendalam. GPT-OSS-120b berhasil mereproduksi seluruh jalur serangan sekaligus mengusulkan perbaikan yang hampir identik dengan solusi perbaikan yang sebenarnya diterapkan oleh A社. Kimi K2 juga tampil sangat baik, dan dalam membangun kerangka lanjutan untuk lubang ini, hanya memerlukan tiga panggilan API sederhana, tanpa infrastruktur agen apa pun, untuk mengamati hasil yang sangat mirip dengan logika serangan yang dijelaskan dalam pengumuman Mythos.
Namun yang paling menarik bukanlah siapa yang menjawab benar, melainkan siapa yang menjawab salah: model termahal menjawab salah pertanyaan paling sederhana.
AISLE mengeluarkan soal yang sangat dasar, sekitar setara dengan "ujian kelulusan sekolah dasar" di industri keamanan: sepotong kode tampak memiliki kerentanan keamanan, tetapi setelah diperiksa lebih teliti, data bermasalah dibuang di tengah proses, sehingga sebenarnya tidak menimbulkan bahaya.
Seperti senjata yang tampak sangat berbahaya, tetapi pelurunya telah dilepas di tengah jalan, ini adalah "pura-pura" yang sekarang tidak berbahaya, tetapi dirancang dengan buruk.

Sebagian besar model mutakhir termahal dan terkuat menjawab salah, Claude Sonnet 4.5 percaya diri memberikan jawaban yang salah, seri GPT-4.1 dan GPT-5.4 juga tidak luput dari kesalahan. Sementara itu, DeepSeek R1 berhasil mengidentifikasi dengan benar dalam keempat uji coba, dan GPT-OSS-20b serta OpenAI o3 juga mampu membedakannya.
Keamanan tidak bisa dicapai dalam sekejap
Temuan-temuan ini membuat AISLE mengusulkan sebuah konsep: batas bergigi.
Kemampuan keamanan AI tidak semakin kuat semakin besar modelnya, melainkan tidak merata, peringkatnya bisa berubah total di berbagai tugas. Model yang sama bisa mendapatkan nilai sempurna dalam satu tes, tetapi segera setelahnya dengan percaya diri menyatakan "kode tidak bermasalah" dalam tes lain. Model lain tampil terbaik dalam tugas kompleks, tetapi justru membuat kesalahan paling dasar dalam soal dasar.
Tidak ada "AI keamanan terbaik", batasan kemampuan bersifat bergigi.
Seperti tes-tes ini, bukan berarti Mythos tidak kuat. Dalam eksperimen yang mereka lakukan, model kecil diberi kode yang terkait dengan kerentanan, yang dipisahkan dan diberikan secara terpisah kepada model-model kecil, seolah-olah mengatakan, "Lihat di sini, apakah ada masalah?" Ini seperti mencontek sedikit.
Keunggulan Mythos terletak pada otonominya sepenuhnya, ia dapat secara otomatis menemukan area yang layak diperiksa lebih dalam dari ratusan ribu file, mengajukan hipotesis, memverifikasi masalah, dan menulis kode serangan, semuanya secara otomatis.

Namun, AISLE berpendapat bahwa nilai "otomatis penuh" ini terutama berasal dari desain teknik, bukan dari kecerdasan model itu sendiri.
Misalnya, proses mencari kerentanan dengan AI dapat dibagi menjadi beberapa langkah: pertama, memindai seluruh kode untuk menemukan area yang mencurigakan, lalu memeriksa lebih dalam apakah benar-benar ada kerentanan, selanjutnya menilai tingkat keparahannya, dan terakhir membuat patch untuk memperbaikinya. Tingkat kesulitan antar langkah-langkah ini sangat berbeda.
Langkah "mengidentifikasi masalah" sudah dapat diatasi oleh model murah. Yang benar-benar sulit adalah bagaimana menghubungkan langkah-langkah ini menjadi alur kerja yang andal: membuat AI menemukan lokasi yang tepat, menghilangkan false positive, merumuskan strategi, dan melaksanakannya.
Membangun keamanan AI memerlukan beberapa hal: kecerdasan AI, biaya operasional, kecepatan operasional, serta keahlian keamanan yang tertanam dalam seluruh sistem dan tim. Anthropic telah menguasai aspek pertama dengan sangat baik, tetapi pengalaman AISLE menunjukkan bahwa aspek-aspek lainnya juga sama pentingnya, bahkan terkadang lebih penting. Sistem AISLE sendiri menggunakan banyak model dari berbagai penyedia, dan model terbaik berubah-ubah tergantung pada tugasnya; teknisi utama OpenSSL menilai mereka sebagai "laporan berkualitas tinggi dan kolaborasi yang konstruktif".

Pembangunan kepercayaan ini tidak terlalu bergantung pada model mana yang digunakan, hasil terbaik mereka tidak berasal dari model Anthropic.
Sebuah kesimpulan praktis adalah: karena model murah sudah cukup efektif dalam langkah “mencari masalah”, Anda tidak perlu secara hati-hati mengarahkan model mahal ke beberapa lokasi mencurigakan. Anda bisa mengirim sekelompok model murah untuk memeriksa semua sudut. Seribu detektif yang cukup baik yang memeriksa setiap ruangan mungkin lebih efisien daripada satu detektif jenius yang mencari satu per satu.
Meskipun promosi Anthropic tidak salah, ia memiliki tingkat misinformasi tertentu dengan mencampurkan langkah-langkah ini, sehingga membuat orang percaya bahwa setiap langkah memerlukan AI paling canggih, padahal kenyataannya tidak demikian.
Mythos memang membuktikan bahwa "AI secara mandiri mencari kerentanan" itu nyata, dan tingkat otonominya bisa sangat tinggi. Namun, menyiratkan bahwa hanya model selevel Mythos yang mampu melakukannya adalah menyampaikan separuh cerita saja; parit pertahanan bukan ada pada model, tetapi pada sistem.
Makna ini bagi seluruh industri mungkin lebih besar daripada Mythos itu sendiri. Ketika kunci keamanan yang tepat bukanlah memiliki AI terkuat, melainkan bagaimana mengorganisasi AI menjadi alur kerja yang andal, maka keamanan AI tidak lagi menjadi wilayah eksklusif satu perusahaan. Ini akan menjadi sebuah ekosistem, di mana banyak tim menggunakan kombinasi AI yang berbeda dan keahlian berbeda untuk melakukan hal yang sama.
Ini mungkin hal yang baik, membuat perangkat lunak di seluruh dunia lebih aman, dan seharusnya tidak hanya mengandalkan satu model dari satu perusahaan.
Artikel ini berasal dari akun WeChat "APPSO", penulis: APPSO yang menemukan produk masa depan