









Penyesuaian harga oleh DeepSeek ini, dengan penurunan tajam nonlinier, secara paksa membawa industri ke sebuah era biaya baru.
Penulis artikel, sumber: 0x9999in1, ME News
TL;DR
- Harga menembus batas bawah: Pada akhir April 2026, DeepSeek menurunkan harga output model V4-Pro menjadi 0,878 dolar per juta token melalui kombinasi diskon terbatas waktu dan penurunan harga cache, sementara harga input dengan cache hit turun lebih jauh menjadi 0,0037 dolar (sekitar 0,025 yuan Cina), secara resmi menghancurkan patokan harga industri model besar.
- Harga di Tiongkok dan AS mengalami "kesenjangan": Dibandingkan produsen terkemuka global, biaya total pemanggilan API DeepSeek-V4-Pro hanya sekitar satu-tigapuluh dari OpenAI GPT-5.5 dan Anthropic Claude Opus 4.7, menciptakan selisih biaya yang sangat signifikan.
- Tekanan kompetisi domestik: Di bawah penetapan harga agresif DeepSeek, model-model utama domestik seperti Zhipu GLM 5.1 dan Moonshot Kimi K2.6 menghadapi tekanan besar dalam komersialisasi, yang mungkin terpaksa mengikuti penurunan harga, sehingga mempercepat kecepatan penyaringan industri.
- “Cache hit” menjadi inti ekonomi: DeepSeek menurunkan harga cache hit menjadi sepertiga dari harga aslinya, strategi ini secara fundamental sangat menguntungkan untuk skenario pemrosesan teks panjang, RAG (Retrieval-Augmented Generation), dan interaksi berulang berkelanjutan dari Agent.
- Kesimpulan analisis think tank: Model dasar sedang mempercepat "infrastrukturisasi seperti listrik dan air", dan fokus persaingan masa depan akan beralih sepenuhnya dari persaingan ukuran parameter model tunggal menuju kemampuan optimasi biaya inferensi dan penguasaan ekosistem pengembang.
Pendahuluan: Titik singularitas biaya komputasi model besar
Perkembangan teknologi sering kali disertai dengan penurunan biaya secara eksponensial, yang merupakan jalan tak terhindarkan bagi setiap teknologi disruptif menuju adopsi luas. Pada 25 hingga 26 April 2026, industri AI menyaksikan momen yang sangat bersejarah: produsen model besar terkemuka, DeepSeek, melepaskan dua "bom dalam" berturut-turut. Pertama, mereka mengumumkan diskon ekspres 2,5% untuk API model DeepSeek-V4-Pro; kemudian mengumumkan bahwa harga untuk input cache hit dalam seluruh rangkaian layanan API langsung turun menjadi 1/10 dari harga sebelumnya.
Setelah dua siklus strategi penyesuaian harga berturut-turut, harga input cache hit untuk DeepSeek-V4-Flash telah turun menjadi 0,0029 dolar AS (sekitar 0,02 yuan Cina) per juta token sebelum 5 Mei 2026, sementara harga input cache hit untuk DeepSeek-V4-Pro yang menjadi pembanding tingkat global teratas hanya sebesar 0,0037 dolar AS (sekitar 0,025 yuan Cina).
Sebelumnya, industri secara umum memprediksi biaya inferensi model besar akan turun sekitar 50% per tahun, tetapi penyesuaian harga kali ini oleh DeepSeek menyebabkan penurunan tajam non-linear yang secara paksa membawa industri ke era biaya baru. Kami percaya ini bukan sekadar aktivitas pemasaran sederhana atau "perang harga" jangka pendek, melainkan hasil tak terhindarkan dari optimasi arsitektur algoritma dasar (seperti mekanisme perhatian jarang, evolusi ekstrem arsitektur MoE) serta peningkatan kemampuan rekayasa klaster komputasi. Laporan ini akan menganalisis secara mendalam guncangan industri yang disebabkan oleh penurunan harga DeepSeek berdasarkan data harga terbaru di seluruh industri, serta membandingkan secara horizontal daya saing komersial model besar utama global, untuk memberikan peta jalan evolusi industri yang jelas bagi para pengambil keputusan.
Fenomena utama: Tembusnya batas sistem harga seri DeepSeek-V4
Untuk memahami sejauh mana penurunan harga ini mengguncang, kita harus menganalisis tiga dimensi inti biaya API model besar: harga input (tidak tercakup cache), harga input (tercakup cache), dan harga output. Model penagihan sebelumnya sering hanya membedakan antara input dan output, tetapi seiring kedewasaan teknologi konteks panjang (Long-Context), "tingkat keberhasilan cache (Cache Hit)" sedang menjadi variabel kunci yang membentuk ulang ekonomi API.
Analisis Strategi Penetapan Harga: Penjumlahan Diskon dan Leverage Cache
Berdasarkan data terbaru yang dirilis, DeepSeek mengadopsi strategi tiga langkah: penurunan harga dasar, diskon terbatas waktu, dan leverage kasp.
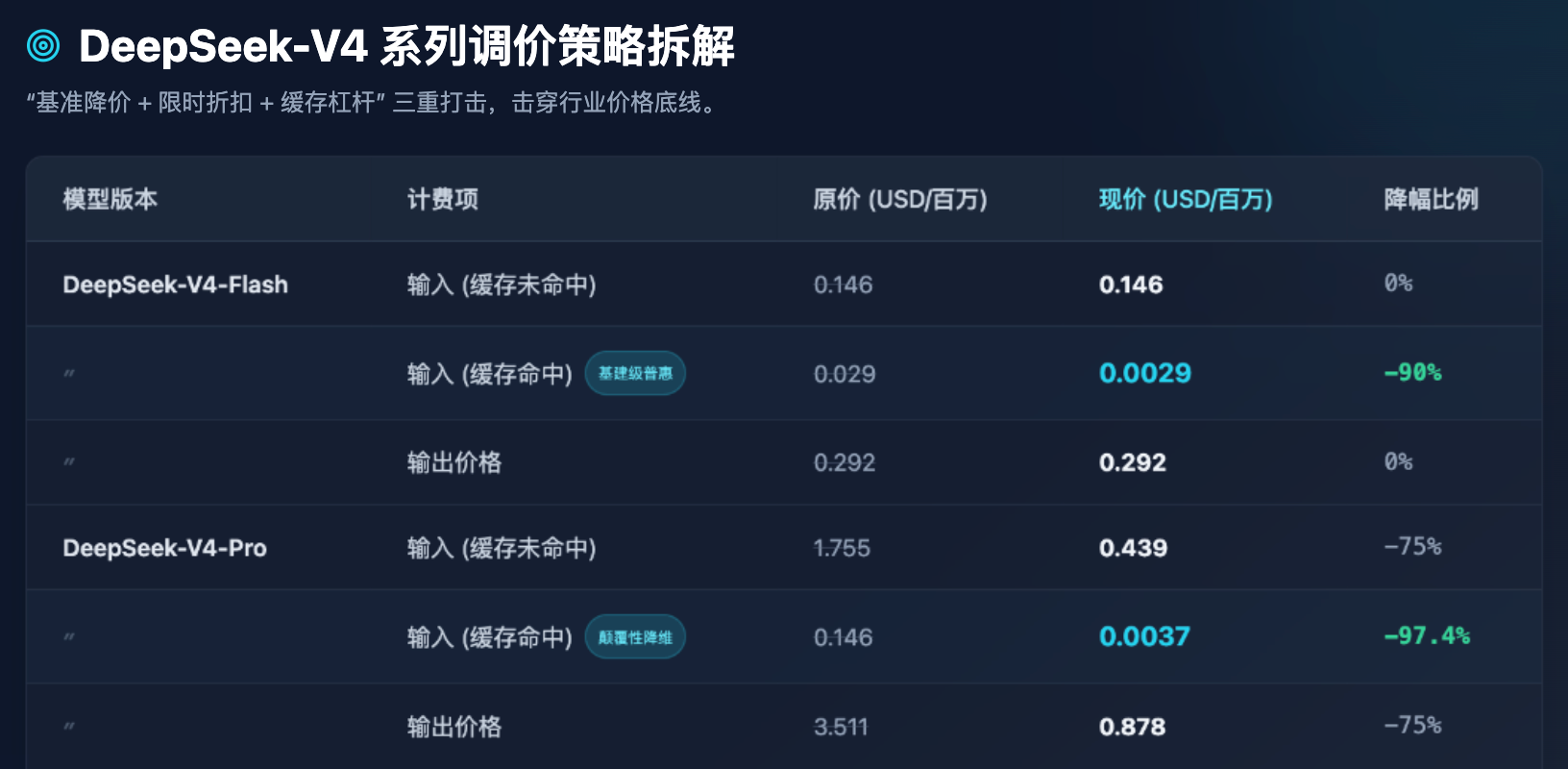
Tabel 1: Perbandingan harga API terbaru seri DeepSeek-V4 sebelum dan sesudah penyesuaian (satuan: dolar per juta Token)
Dari Tabel 1, kita dapat menyimpulkan beberapa pengamatan industri yang sangat jelas:
Pertama, popularisasi model Flash telah mencapai batas bawah. Untuk model Flash yang menonjolkan kinerja tinggi dan latensi rendah, harga output tetap pada $0,292 per juta Token, yang sudah sangat mendekati batas bawah biaya keras daya komputasi server. DeepSeek tidak terus-menerus mempermainkan harga dasar Flash, tetapi dengan cerdik menurunkan harga "cache hit" sebesar 90%. Ini berarti, dalam menangani sejumlah besar prompt sistem (System Prompt) yang berulang atau pertanyaan-dokumen tetap, biaya model Flash hampir dapat diabaikan.
Kedua, penurunan harga model Pro. Sebagai model unggulan yang sejajar dengan kelompok teratas global (seperti level GPT-5), harga output V4-Pro turun drastis dari $3,511 menjadi $0,878. Lebih ekstrem lagi, harga input cache hit yang awalnya $0,146, setelah digabungkan dengan diskon sementara 25% dan penurunan harga 1/10, langsung turun menjadi $0,0037. Ini adalah angka yang sangat menakutkan—artinya biaya memanggil kecerdasan teratas dunia telah ditekan hingga tingkat yang memungkinkan perusahaan menengah-kecil bahkan pengembang perorangan untuk memanggilnya secara frekuensi tinggi tanpa ragu.
Ketiga, mendorong pengembang untuk mengoptimalkan teknik Prompt. Dengan menetapkan harga yang dipicu cache sebagai sepersekian dari harga yang tidak dipicu cache (misalnya, dalam model Pro: $0,0037 vs $0,439, perbedaan sekitar 118 kali), ini bukan hanya strategi penetapan harga, tetapi juga cara untuk membimbing ekosistem teknis melalui pendekatan bisnis. DeepSeek secara jelas memberi tahu pengembang: selama arsitektur Anda dirancang dengan baik (misalnya, konteks panjang tetap di depan, pertanyaan singkat yang berubah di belakang), Anda dapat menikmati daya komputasi input hampir gratis.
Perbandingan horizontal: Perbedaan tajam dalam penetapan harga model besar global dan lokal
Hanya membandingkan penurunan harga DeepSeek secara vertikal tidak cukup untuk melihat gambaran lengkap; ketika kita menempatkannya dalam kerangka pasar model besar global tahun 2026, perbedaan tajam yang diciptakan oleh strategi penetapan harga ini benar-benar membuat merinding.
Berdasarkan OpenRouter dan informasi publik dari berbagai pihak, kami telah menyusun data harga API terbaru untuk 9 model besar domestik dan internasional yang paling representatif di pasar saat ini.

Tabel 2: Perbandingan Harga API Model Besar Global 2026 (dalam dolar AS per juta Token)
Melawan raksasa global: Menghancurkan mitos "kecerdasan tinggi dan premi tinggi"
Dalam narasi AI selama dua tahun terakhir, OpenAI dan Anthropic telah mempertahankan kesepakatan implisit: model paling cerdas seharusnya menikmati marjin keuntungan tertinggi. Saat ini, harga output GPT-5.5 dan Claude Opus 4.7 masing-masing mencapai $30 dan $25 per juta Token. Dua raksasa Silicon Valley ini berusaha mempertahankan pajak komputasi tinggi mereka dengan memonopoli kemampuan inferensi paling unggul.
Namun, kemunculan DeepSeek-V4-Pro dan harga outputnya sebesar 0,878 dolar AS langsung menembus lapisan kertas jendela ini. Misalkan V4-Pro mampu mencapai atau mendekati tingkat GPT-5.5 dalam berbagai pengujian benchmark inti dan pengalaman nyata, maka perbedaan harga output sebesar 34 kali lipat antara keduanya akan menghancurkan sepenuhnya logika premium para raksasa luar negeri di pasar B2B.
「ME News智库」 memperkirakan, bagi perusahaan ekspor yang sangat bergantung pada konten yang dihasilkan AI, jika mengonsumsi 1 miliar token output per bulan, biaya tetap menggunakan GPT-5.5 adalah $30.000; sementara beralih ke DeepSeek-V4-Pro, biaya ini akan turun drastis menjadi $878. Perbedaan biaya pada skala ini cukup untuk memengaruhi kelangsungan hidup sebuah perusahaan rintisan. Ini menunjukkan bahwa perusahaan AI Tiongkok telah menempuh jalur yang sama sekali berbeda dari Silicon Valley, yang menekankan baik “estetika kekerasan” maupun optimasi teknik ekstrem dalam pelatihan model dasar dan optimasi klaster inferensi.
Menghadapi pesaing domestik: Mempercepat pembersihan besar-besaran industri
Jika DeepSeek merupakan serangan turun tingkat terhadap raksasa luar negeri, maka bagi pesaing domestik, ini adalah permainan nol-sum yang kejam.
Dari Tabel 2, terlihat bahwa produsen terkemuka domestik seperti Zhipu (GLM 5.1, output $4,40) dan Moonshot (Kimi K2.6, output $4,00) berada dalam posisi yang membingungkan dalam hal penetapan harga. Harga-harga ini beberapa bulan lalu dianggap “wajar dan bernilai tinggi”, tetapi di hadapan DeepSeek-V4-Pro (output $0,878), mereka langsung kehilangan semua lini pertahanan harga. Bahkan Alibaba Cloud, yang selama ini dikenal karena sifat open-source dan harga rendahnya (Qwen3.6 Plus, output $1,96), tampaknya tidak lagi “murah”.
Di medan pertempuran model Flash ringan, pertarungan juga sengit. Step 3.5 Flash dari Jiepao Xingchen memiliki input serendah $0,028 dan output hanya $0,299, sangat ketat dibandingkan DeepSeek-V4-Flash (output $0,292). Ini menunjukkan bahwa di bidang model ringan, tekanan terhadap biaya komputasi telah mencapai tingkat nano, dan semua pihak terbang tepat di garis biaya.
Secara keseluruhan, DeepSeek sebenarnya menggunakan kemampuan tingkat Pro untuk menyerang harga pesaing domestik versi Plus bahkan versi standar; sementara menggunakan harga tingkat Flash untuk menangkap seluruh volume lalu lintas panjang dengan kepadatan nilai rendah. Taktik “pengapit dua sisi” ini secara signifikan mempersempit ruang hidup perusahaan model besar lainnya, dan kompetisi eliminasi model AI domestik akan dipercepat setelah penurunan harga ini.
Deep Dive: Teknologi dan Logika Bisnis di Balik Harga Terendah
Harga rendah yang tidak didukung oleh fundamental tidak berkelanjutan. DeepSeek berani menerapkan strategi penurunan harga yang begitu tegas pada tahun 2026 karena didukung oleh dasar teknis yang kuat dan ambisi bisnis yang sangat besar.
Teknis logika: Dari "kekuatan besar, batu terbang" hingga "arsitektur yang menang"
Penurunan tajam harga pada dasarnya adalah pelepasan manfaat dari evolusi arsitektur teknis.
- Manfaat mendalam dari arsitektur MoE (Mixture of Experts): Berbeda dengan model padat besar awal dari OpenAI, model canggih saat ini secara umum menggunakan arsitektur MoE yang sangat dioptimalkan. DeepSeek sangat mungkin lebih mengurangi rasio parameter aktif dalam arsitektur V4. Ini berarti meskipun jumlah parameter total besar, hanya sebagian kecil "ahli" yang diaktifkan setiap kali inferensi, sehingga secara signifikan mengurangi beban komputasi (FLOPs) dan bandwidth memori grafis untuk setiap panggilan.
- Terobosan revolusioner dalam manajemen KV Cache: Fitur utama penyesuaian harga ini adalah "penurunan cache input menjadi 1/10". Dalam arsitektur Transformer, hambatan terbesar dalam inferensi teks panjang bukanlah komputasi, melainkan penggunaan VRAM besar oleh KV Cache yang menyimpan informasi konteks. DeepSeek jelas telah mengimplementasikan teknologi pooling KV Cache berskala global dan lintas permintaan pada level sistem (misalnya, versi peningkatan teknologi RadixAttention). Ketika banyak permintaan simultan pengguna berisi pengaturan sistem atau basis pengetahuan latar belakang yang sama, model tidak perlu menghitung ulang Token-token ini, tetapi langsung membacanya dari memori atau bahkan dari pool VRAM terdistribusi. Ini membuat biaya marjinal dari "input teks panjang" mendekati nol.
Business logic: Trade profit for space, reshape the ecological moat
「ME News智库」 percaya bahwa strategi diskon terbatas dan harga dasar DeepSeek memiliki tujuan bisnis yang jelas dan tegas:
Pertama, hancurkan sepenuhnya ekosistem "fine-tuning berbungkus", memaksa munculnya aplikasi native AI. Ketika biaya pemanggilan model dasar terkuat mendekati gratis, para pengusaha tidak lagi memiliki makna ekonomi untuk menghabiskan biaya besar dalam melatih atau menyesuaikan model kecil industri mereka sendiri. DeepSeek melalui harga rendah berusaha menarik seluruh pengembang AI di masyarakat ke dalam ekosistem API-nya, menjadikannya seperti "listrik, air, dan gas dasar di era AI" seperti Amazon AWS atau Microsoft Azure.
Selanjutnya, fajar ledakan Agent (agen). Aplikasi Agentic yang sebenarnya memerlukan model untuk melakukan banyak pemikiran mandiri, refleksi, perencanaan, dan pemanggilan siklus berulang (Loop). Dalam proses ini, akan terjadi konsumsi Token implisit dalam jumlah besar. Biaya API yang mahal adalah hambatan terbesar dalam penerapan Agent. DeepSeek dengan menurunkan harga keberhasilan cache menjadi 0,0037 dolar, sebenarnya memberikan kelayakan ekonomi bagi "membiarkan AI berjalan sepuluh ribu putaran". Siapa yang menyediakan biaya percobaan dan kesalahan paling murah, dialah yang akan melahirkan superaplikasi berbasis AI paling hebat.
Dampak dan analisis tren industri: Dari "perang model" ke "perang ekosistem"
Untuk secara lebih intuitif menunjukkan dampak perubahan harga terhadap keputusan perusahaan, kami melakukan simulasi biaya aplikasi tingkat perusahaan.
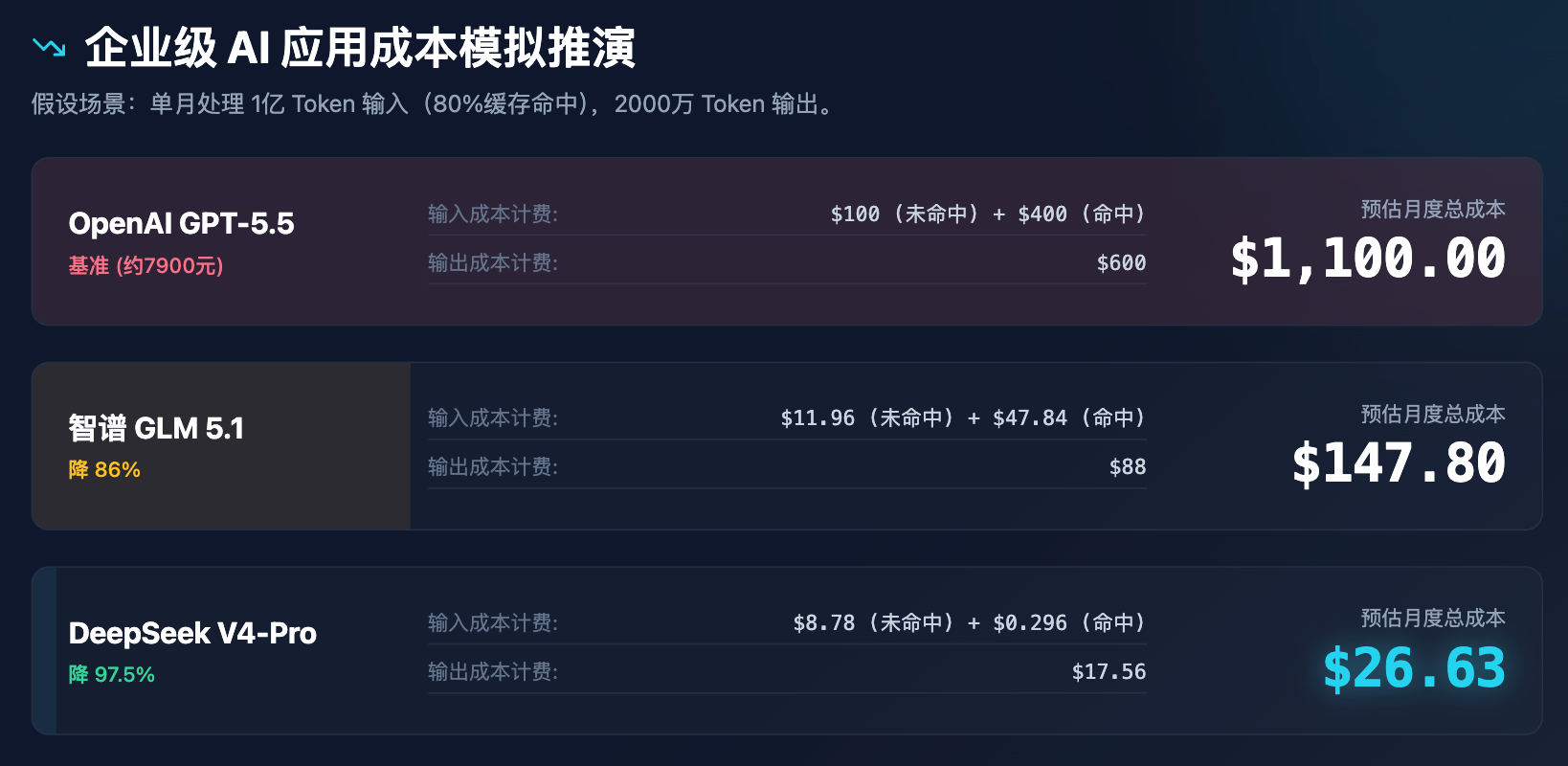
Tabel 3: Analisis simulasi biaya aplikasi AI tingkat perusahaan (asumsi pemrosesan 100 juta token masukan dan 20 juta token keluar per bulan)
Melalui simulasi di atas, jelas terlihat bahwa penetapan harga DeepSeek tidak hanya diskon, tetapi juga merekonstruksi model biaya. Dengan biaya kurang dari $30 per bulan, semua kebutuhan bantuan layanan pelanggan, analisis dokumen, dan pemeriksaan kode untuk perusahaan menengah dapat dipenuhi, yang pasti akan memicu serangkaian reaksi berantai:
- Perubahan mendasar dalam logika investasi AI: modal akan sepenuhnya kehilangan minat terhadap "menciptakan ulang model besar umum". Kecuali untuk sejumlah sangat kecil entitas negara atau raksasa internet, pintu untuk model dasar besar umum telah dilas rapat. Investasi masa depan akan mengalir secara menyeluruh ke lapisan aplikasi (Application Layer) dan middleware infrastruktur (router infrastruktur, AI gateway, dll.).
- Strategi routing multi-model (LLM Routing) menjadi standar: perusahaan tidak lagi bergantung pada satu model tunggal. Sistem akan secara otomatis mendistribusikan tugas berdasarkan tingkat kompleksitasnya. Misalnya, 90% pembersihan data harian dan klasifikasi sederhana diselesaikan dengan biaya sangat rendah oleh DeepSeek-V4-Flash atau Step 3.5 Flash; 10% logika kompleks dan pembuatan laporan eksekutif memanfaatkan DeepSeek-V4-Pro atau memanggil GPT-5.5 sesuai kebutuhan.
- Aplikasi teks panjang mencapai titik balik komersial sejati: sebelumnya, meskipun terdengar menarik untuk “mengunggah laporan keuangan ratusan ribu kata agar diringkas AI”, biaya API yang sering mencapai beberapa dolar membuat perusahaan B2B enggan menggunakannya. Dengan penurunan harga cache input hingga level 0,02 yuan RMB per juta token, “membaca seluruh dokumen perpustakaan dan berinteraksi secara real-time” akan menjadi fitur standar di semua perangkat lunak OA dan ERP perusahaan.
Kesimpulan dan Rekomendasi Strategis
Badai penurunan harga pada April 2026 menandai berakhirnya era romantis klasik industri model besar, di mana para pemain berlomba-lomba memperlihatkan parameter dan skor, dan memasuki era industri yang keras, di mana yang dipertaruhkan adalah biaya, daya komputasi, dan ekosistem. DeepSeek melalui strategi penetapan harga yang menekan secara ekstrem tidak hanya menunjukkan kepada dunia keahlian mendalam perusahaan AI Tiongkok dalam rekayasa model, tetapi juga secara aktif meledakkan gelembung premium berlebihan pada daya komputasi AI.
Untuk ini, "ME News Think Tank" memiliki tiga saran:
- Untuk pengembang lapisan aplikasi: Tinggalkan ketakutan terhadap biaya pemanggilan model besar. Segera hentikan pembangunan dan fine-tuning model dasar di bawah seratus miliar parameter, dan arahkan semua sumber daya pengembangan ke pengalaman produk, adaptasi sisi endpoint, pembangunan hambatan data eksklusif, serta penyempurnaan alur kerja Agent. Manfaatkan manfaat "kekuatan komputasi cerdas murah" ini untuk cepat merebut pasar.
- Untuk CIO/CTO perusahaan tradisional: Tinjau ulang strategi AI perusahaan. Proyek-proyek seperti pertanyaan-jawab pengetahuan, layanan pelanggan otomatis, dan code Copilot yang sebelumnya ditunda karena pertimbangan biaya kini telah memiliki ROI (return on investment) yang sangat tinggi di harga API saat ini. Disarankan untuk mengadopsi platform LLMOps yang matang dan membangun gateway AI perusahaan agar dapat secara fleksibel mengintegrasikan model-model paling hemat biaya saat ini.
- Untuk pesaing model dasar: harus meninggalkan strategi mengikuti. Di hadapan perang harga, either melalui optimasi sinergis chip-kerangka yang lebih ekstrem untuk menekan biaya lebih rendah, atau membangun hambatan teknis yang tak tergantikan di bidang diferensiasi seperti kecerdasan tubuh, multimodal native (generasi video/3D), dan penalaran logis kuat di industri vertikal. Model bahasa besar murni yang biasa-biasa saja sudah tidak memiliki jalan keluar.
Model besar bukan lagi dewa yang dipuja di laboratorium, ia sedang turun dari takhta dengan kecepatan belum pernah terjadi sebelumnya, berubah menjadi arus besar yang menggerakkan kecerdasan segala sesuatu. Dan semua ini baru saja dimulai.
Sumber kutipan:
- OpenRouter. (2026). Database Perbandingan Harga API.
- Pengumuman Resmi DeepSeek. (2026, 25 April). Program Diskon Terbatas untuk API DeepSeek-V4-Pro.
- Pengumuman Resmi DeepSeek. (2026, 26 April). Daya Komputasi Terjangkau di Era Model Besar: Skema Penyesuaian Harga Cache API Global.