










Penulis asli: KarenZ, Foresight News
Pada 20 Maret 2026, ada percakapan yang tidak biasa di podcast All-In Ventures.
Pengusaha modal ventura Chamath Palihapitiya melemparkan topik kepada CEO NVIDIA, Jensen Huang, mengatakan bahwa sebuah proyek di Bittensor telah "mencapai pencapaian teknis yang cukup gila" dengan melatih model bahasa besar di internet menggunakan daya komputasi terdistribusi, sepenuhnya terdesentralisasi tanpa partisipasi pusat data terpusat.
Huang Renxun tidak menghindari hal ini. Ia membandingkannya dengan "versi modern Folding@home", proyek terdistribusi yang pada tahun 2000-an memungkinkan pengguna biasa menyumbangkan daya komputasi yang menganggur untuk bersama-sama mengatasi tantangan pelipatan protein.
Empat hari sebelumnya, pada 16 Maret, Jack Clark, salah satu pendiri Anthropic, juga secara luas menyoroti dan mengutip terobosan ini dalam laporan kemajuan penelitian AI: Subnet Bittensor Templar (SN3) berhasil menyelesaikan pelatihan terdistribusi untuk model besar 72 miliar parameter (Covenant 72B), dengan kinerja yang sebanding dengan LLaMA-2 yang dirilis Meta pada 2023.
Jack Clark memberi judul bab ini "Menghadapi Politik Ekonomi AI Melalui Pelatihan Terdistribusi", dan dalam analisisnya menekankan bahwa ini adalah teknologi yang layak untuk terus dipantau—ia membayangkan masa depan di mana AI di perangkat secara luas mengadopsi model yang dilatih secara terdesentralisasi, sementara AI cloud terus menjalankan model besar eksklusif.
Reaksi pasar sedikit tertunda tetapi sangat tajam: SN3 naik lebih dari 440% dalam sebulan terakhir, lebih dari 340% dalam dua minggu terakhir, dengan kapitalisasi pasar mencapai $130 juta. Narasi subnetwork meledak, yang secara langsung menciptakan tekanan pembelian terhadap TAO. Oleh karena itu, TAO naik cepat, sempat mencapai $377, berlipat ganda dalam sebulan terakhir, dengan FDV mencapai sekitar $7,5 miliar.
Pertanyaannya: Apa yang sebenarnya dilakukan SN3? Mengapa ia didorong ke sorotan? Bagaimana narasi nilai pelatihan terdistribusi dan AI terdesentralisasi akan berkembang?
Model 72B itu
Untuk menjawab pertanyaan ini, perlu melihat hasil yang diberikan oleh SN3.
Pada 10 Maret 2026, tim Covenant AI merilis laporan teknis di arXiv, secara resmi mengumumkan bahwa Covenant-72B telah selesai dilatih. Ini adalah model bahasa besar dengan 72 miliar parameter, yang dilatih pada korpus sekitar 1,1 triliun token menggunakan lebih dari 70 node independen (sekitar 20 node disinkronkan per putaran, masing-masing node dilengkapi dengan 8 unit B200).
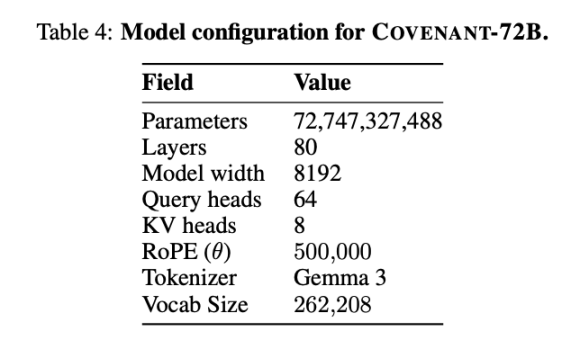
Templar memberikan beberapa data terkait benchmark, dengan LLaMA-2-70B sebagai model besar yang dirilis Meta pada tahun 2023. Seperti yang dikatakan oleh salah satu pendiri Anthropic, Jack Clark, Covenant-72B mungkin sudah ketinggalan zaman jika dibandingkan dengan tahun 2026. Skor 67,1 dari Covenant-72B di MMLU kira-kira sebanding dengan LLaMA-2-70B yang dirilis Meta pada tahun 2023 (65,6 poin).
Sementara model terdepan tahun 2026—baik seri GPT, Claude, maupun Gemini—sudah dilatih pada ratusan ribu GPU dengan jumlah parameter jauh melebihi 100 miliar, kesenjangan dalam kemampuan inferensi, coding, dan matematika adalah masalah orde, bukan persentase. Kesenjangan nyata ini seharusnya tidak tenggelam oleh suasana pasar.
Namun, jika diukur berdasarkan asumsi "dilatih menggunakan daya komputasi terdistribusi di internet terbuka", maknanya sama sekali berbeda.
Bandingkan: INTELLECT-1 (dikembangkan oleh tim Prime Intellect, 10 miliar parameter) mendapatkan skor MMLU 32,7, sementara proyek pelatihan terdistribusi lainnya, Psyche Consilience (40 miliar parameter), yang dilakukan di antara peserta daftar putih, mendapatkan skor 24,2. Covenant-72B, dengan ukuran 72 miliar dan skor MMLU 67,1, merupakan angka yang menonjol di lintasan pelatihan terdesentralisasi.
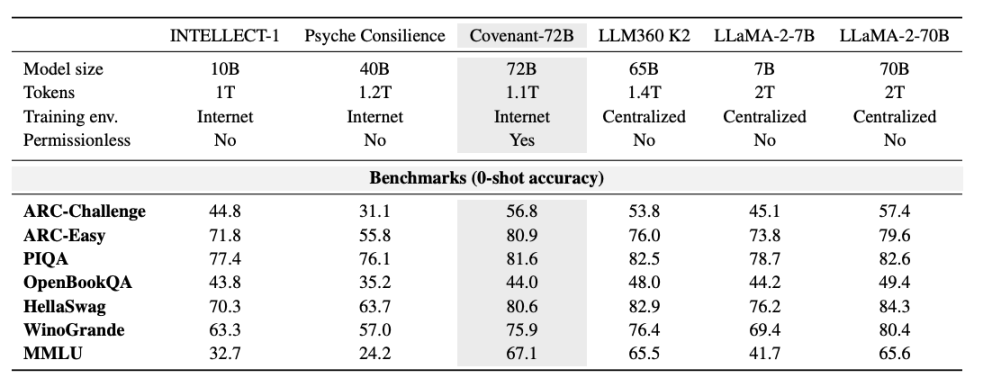
Yang lebih penting lagi, pelatihan ini bersifat "tanpa izin". Siapa pun dapat terhubung dan menjadi node peserta tanpa tinjauan sebelumnya atau daftar putih. Lebih dari 70 node independen berpartisipasi dalam pembaruan model, menyumbangkan daya komputasi dari seluruh dunia.
Apa yang dikatakan Huang Renxun, dan apa yang tidak dikatakan
Mengembalikan detail percakapan podcast tersebut dapat membantu memperbaiki interpretasi publik terhadap «dukungan» ini.
Chamath Palihapitiya menyajikan pencapaian teknis Bittensor dalam percakapan kepada Huang Renxun, menggambarkannya sebagai pelatihan model Llama menggunakan daya komputasi terdistribusi, dengan proses yang "sepenuhnya terdistribusi sekaligus mempertahankan status". Tanggapan Huang Renxun membandingkannya dengan "versi modern dari Folding@home", dan ia mengembangkan diskusi mengenai kebutuhan akan keberadaan paralel antara model open-source dan propietary.
Perlu dicatat bahwa Huang Renxun tidak secara langsung menyebutkan token Bittensor atau implikasi investasi apa pun, serta tidak membahas lebih lanjut tentang pelatihan AI terdesentralisasi.
Memahami subnet Bittensor dan SN3
Untuk memahami tembusan SN3, pertama-tama perlu memahami cara kerja Bittensor dan sub-jaringannya. Secara sederhana, Bittensor dapat dilihat sebagai blockchain dan platform AI, sementara setiap sub-jaringan setara dengan "lini produksi AI" independen, masing-masing memiliki tugas inti yang jelas dan merancang mekanisme insentif, bekerja sama membentuk ekosistem AI terdesentralisasi.
Proses operasionalnya jelas dan terdesentralisasi: pemilik subnet menentukan tujuan subnet dan menulis model insentif; penambang menyediakan daya komputasi di dalam subnet dan menyelesaikan tugas terkait AI (seperti inferensi, pelatihan, penyimpanan, dll.); validator memberi skor terhadap kontribusi penambang dan mengunggah skor tersebut ke lapisan konsensus Bittensor; akhirnya, algoritma konsensus Yuma Bittensor akan mendistribusikan imbalan yang sesuai kepada peserta subnet berdasarkan total insentif yang terakumulasi di setiap subnet.
Saat ini terdapat 128 subnetwork di Bittensor yang mencakup berbagai tugas AI seperti inferensi, layanan cloud AI tanpa server, gambar, pelabelan data, pembelajaran penguatan, penyimpanan, dan komputasi.
SN3 adalah salah satu subnetnya. Ia tidak membuat lapisan aplikasi, tidak menyewa API model besar yang sudah ada, tetapi langsung menargetkan salah satu tahap inti paling mahal dan paling tertutup dalam seluruh rantai industri AI: pelatihan awal model besar itu sendiri.
SN3 ingin memanfaatkan jaringan Bittensor untuk mengoordinasikan pelatihan terdistribusi sumber daya komputasi heterogen, membuktikan bahwa model dasar yang kuat dapat dilatih tanpa memerlukan klaster superkomputer terpusat yang mahal, melalui pelatihan model besar terdistribusi berbasis insentif. Daya tarik utamanya terletak pada "pemerataan" — menghancurkan monopoli sumber daya dalam pelatihan terpusat, memungkinkan individu biasa atau lembaga menengah-kecil untuk berpartisipasi dalam pelatihan model besar, sekaligus mengurangi biaya pelatihan dengan memanfaatkan daya komputasi terdistribusi.
Kekuatan utama yang mendorong pengembangan SN3 adalah Templar, dengan tim peneliti di belakangnya yaitu Covenant Labs. Tim ini juga mengoperasikan dua subnetwork lainnya: Basilica (SN39, fokus pada layanan komputasi) dan Grail (SN81, fokus pada pelatihan lanjutan RL dan evaluasi model). Ketiga subnetwork ini membentuk integrasi vertikal yang mencakup seluruh proses dari pra-pelatihan hingga optimasi alignment model besar, membangun ekosistem lengkap untuk pelatihan model besar terdesentralisasi.
Secara khusus, penambang menyumbangkan sumber daya komputasi dengan mengunggah pembaruan gradien (arah dan tingkat penyesuaian parameter model) ke jaringan; validator mengevaluasi kualitas kontribusi masing-masing penambang dan memberikan skor on-chain berdasarkan tingkat perbaikan kesalahan. Hasilnya menentukan bobot hadiah, yang dialokasikan secara otomatis tanpa perlu mempercayai pihak ketiga mana pun.
Kunci desain mekanisme insentif adalah hadiah secara langsung terkait dengan "seberapa besar kontribusi Anda membuat model menjadi lebih baik", bukan sekadar kehadiran daya komputasi. Ini secara mendasar menyelesaikan masalah terberat dalam skenario terdesentralisasi: bagaimana mencegah penambang malas.
Bagaimana Covenant-72B menyelesaikan masalah efisiensi komunikasi dan kecocokan insentif?
Mengkoordinasikan puluhan node yang saling tidak percaya, dengan perangkat keras yang berbeda-beda dan kualitas jaringan yang tidak merata untuk melatih model yang sama, menimbulkan dua tantangan: pertama, efisiensi komunikasi, solusi pelatihan terdistribusi standar memerlukan koneksi berbandwidth tinggi dan latensi rendah antar node; kedua, kesesuaian insentif, bagaimana mencegah node jahat mengirimkan gradien yang salah? Bagaimana memastikan setiap peserta benar-benar melatih model, bukan menyalin hasil orang lain?
SN3 menyelesaikan kedua masalah ini dengan dua komponen inti: SparseLoCo dan Gauntlet.
SparseLoCo menyelesaikan masalah efisiensi komunikasi. Pelatihan terdistribusi tradisional mensyaratkan sinkronisasi gradien penuh pada setiap langkah, yang menghasilkan volume data yang sangat besar. Solusi yang digunakan SparseLoCo adalah: setiap node menjalankan 30 langkah optimasi internal (AdamW) secara lokal, lalu mengompresi "pseudo-gradien" yang dihasilkan sebelum mengunggahnya ke node lain. Metode kompresi mencakup sparsifikasi Top-k (hanya mempertahankan komponen gradien paling kritis), umpan balik kesalahan (menyimpan bagian yang dibuang dan mengakumulasikannya ke putaran berikutnya), serta kuantisasi 2-bit. Rasio kompresi akhir melebihi 146 kali.
Dengan kata lain, hal yang sebelumnya memerlukan transmisi 100 MB, sekarang cukup dengan kurang dari 1 MB.
Ini memungkinkan sistem mempertahankan pemanfaatan komputasi sekitar 94,5% di bawah batas bandwidth internet biasa (hingga 110 Mbps upload, 500 Mbps download)—20 node, masing-masing dengan 8 B200, dan setiap siklus komunikasi hanya memakan waktu 70 detik.
Gauntlet menyelesaikan masalah incentive compatibility. Ia berjalan di blockchain Bittensor (Subnet 3) dan bertanggung jawab untuk memverifikasi kualitas pseudo-gradien yang dikirimkan setiap node. Caranya: menguji sejumlah kecil data untuk mengukur "seberapa besar penurunan kerugian model setelah menggunakan gradien dari node ini", hasilnya disebut LossScore. Sistem juga memeriksa apakah node tersebut benar-benar melatih model menggunakan data yang dialokasikan kepadanya—jika sebuah node menunjukkan peningkatan kerugian yang lebih baik pada data acak dibandingkan pada data yang dialokasikan, ia akan menerima skor negatif.
Pada akhirnya, hanya gradien dari node dengan skor tertinggi yang dipilih untuk agregasi setiap putaran, sementara node lainnya dikeluarkan dari putaran tersebut. Peserta tambahan akan menggantikan yang tereliminasi secara sewaktu-waktu untuk menjaga stabilitas sistem. Selama seluruh proses pelatihan, rata-rata 16,9 node per putaran memiliki gradiennya dimasukkan ke dalam agregasi, dengan lebih dari 70 ID node unik yang telah berpartisipasi secara kumulatif.
Narratif nilai AI terdesentralisasi sedang mengalami perubahan mendasar
Dari sudut pandang teknis dan industri, arah yang diwakili oleh Covenant-72B memiliki beberapa makna nyata.
Pertama, menghancurkan asumsi bahwa "pelatihan terdistribusi hanya cocok untuk model kecil". Meskipun masih jauh dari model terdepan, hal ini membuktikan skalabilitas arah ini.
Kedua, partisipasi tanpa izin adalah nyata dan dapat diwujudkan. Hal ini diremehkan. Proyek pelatihan terdistribusi sebelumnya bergantung pada daftar putih—hanya peserta yang telah diverifikasi yang dapat menyumbangkan daya komputasi. Dalam pelatihan SN3 ini, siapa pun yang memiliki daya komputasi yang cukup dapat terhubung, dan mekanisme verifikasi bertanggung jawab untuk menyaring kontribusi jahat. Ini merupakan langkah nyata menuju "desentralisasi sejati".
Ketiga, mekanisme dTAO dari Bittensor memungkinkan penemuan nilai pasar untuk sub-jaringan. dTAO memungkinkan setiap sub-jaringan mengeluarkan token Alpha sendiri, memungkinkan pasar menentukan melalui mekanisme AMM mana sub-jaringan yang mendapatkan lebih banyak emisi TAO. Ini memberikan mekanisme penangkapan nilai yang kasar namun efektif bagi sub-jaringan seperti SN3 yang telah menghasilkan pencapaian konkret. Tentu saja, mekanisme ini juga rentan terhadap gangguan narasi dan emosi, karena kualitas hasil pelatihan LLM sulit dievaluasi secara independen oleh peserta pasar biasa.
Keempat, implikasi politik-ekonomi dari pelatihan AI terdesentralisasi. Jack Clark dalam Import AI mengangkat masalah ini ke tingkat "siapa yang memiliki masa depan AI". Saat ini, pelatihan model mutakhir dikuasai oleh sejumlah kecil lembaga yang memiliki pusat data berskala besar, yang bukan hanya masalah bisnis, tetapi juga masalah struktur kekuasaan. Jika pelatihan terdistribusi terus mencapai kemajuan teknis, hal ini berpotensi menciptakan ekosistem pengembangan yang benar-benar terdesentralisasi untuk beberapa jenis model (seperti model mutakhir skala kecil di bidang tertentu). Tentu saja, prospek ini saat ini masih jauh.
Ringkasan: Sebuah tonggak nyata, serta sejumlah masalah nyata
Huang Renxun mengatakan ini seperti "Folding@home versi modern." Folding@home memberikan kontribusi nyata di bidang simulasi molekuler, tetapi tidak mengancam posisi inti riset dan pengembangan perusahaan farmasi besar. Analogi ini sangat akurat.
SN3 telah menjalankan protokol dan memvalidasi arah yang layak untuk pelatihan terdistribusi. Namun dari sudut pandang teknis dan industri, di balik hasil yang diberikan oleh SN3 ini, masih ada sejumlah masalah yang jarang ada yang bersedia diskusikan secara serius:
MMLU sendiri juga merupakan indikator yang kontroversial di kalangan akademis, dengan risiko kebocoran soal dan jawaban benchmark publik ke dalam dataset pelatihan. Yang lebih penting adalah pemilihan baseline perbandingan: model LLaMA-2-70B dan LLM360 K2 yang menjadi acuan dalam paper tersebut adalah model lama dari tahun 2023 hingga 2024, sementara skor 65 hingga 70 pada periode yang sama dianggap sebagai tingkat menengah-kebawah dan pemula ketika dibandingkan dengan Grok atau Doubao, dan dianggap sangat tertinggal menurut Claude. Jika ditempatkan pada daftar dinamis atau benchmark generasi baru yang dirancang untuk tahan terhadap kontaminasi, kesimpulannya mungkin akan lebih jujur.
Yang lebih penting lagi, data berkualitas tinggi yang menentukan batas kemampuan model—data percakapan, kode, derivasi matematis, dan literatur ilmiah—kemungkinan besar berada di tangan berbagai perusahaan, lembaga penerbit, dan database akademik. Kekuatan komputasi telah didemokratisasi, tetapi sisi data tetap berstruktur oligopoli, dan kontradiksi ini belum pernah dibahas.
Terkait keamanan, partisipasi tanpa izin berarti Anda tidak tahu siapa di balik lebih dari 70 node tersebut, maupun data apa yang mereka gunakan untuk melatih. Gauntlet dapat menyaring gradien yang jelas-jelas tidak wajar, tetapi tidak dapat mencegah keracunan data yang halus—jika sebuah node secara sistematis melatih lebih banyak iterasi pada jenis konten berbahaya tertentu, perubahan gradien yang dihasilkan cukup halus untuk lolos dari pemeriksaan skor kerugian, namun menyebabkan pergeseran akumulatif pada perilaku model. Pertanyaan akhirnya adalah: dalam skenario dengan persyaratan kepatuhan dan keamanan tinggi seperti keuangan, perawatan kesehatan, dan hukum, apa risiko yang ditimbulkan dengan menggunakan model yang dilatih oleh sejumlah kecil node anonim dengan sumber data yang tidak dapat dilacak sepenuhnya?
Masih ada masalah struktural yang perlu diungkapkan secara langsung: Covenant-72B sendiri bersifat open source dengan lisensi Apache 2.0 dan tidak menggunakan token SN3. Memegang token SN3 berarti Anda berbagi dalam pendapatan emisi yang dihasilkan dari produksi model baru berkelanjutan dari subnet ini, bukan pendapatan langsung dari penggunaan model tersebut. Nilai rantai ini bergantung pada produksi pelatihan yang berkelanjutan dan kesehatan mekanisme emisi jaringan Bittensor secara keseluruhan. Jika pelatihan di masa depan terhenti, atau kualitas hasil pelatihan baru tidak memenuhi harapan, logika penilaian token akan melemah.
Mencantumkan masalah-masalah ini bukan untuk menyangkal makna Covenant-72B. Fakta bahwa ia membuktikan sesuatu yang sebelumnya dianggap tidak mungkin dapat dicapai, tidak akan hilang. Tetapi, berhasil melakukannya, dan apa artinya hal itu, adalah dua hal yang berbeda.
Token SN3 naik 440% dalam sebulan terakhir. Jarak yang tercipta mungkin bukan sekadar hiperbola, melainkan kecepatan narasi yang selalu lebih cepat daripada kecepatan realitas. Apakah jarak ini akhirnya akan diisi oleh realitas atau diserap oleh koreksi pasar, tergantung pada apa yang benar-benar diserahkan oleh tim Covenant AI ke depan.
Yang perlu diperhatikan adalah bahwa Grayscale telah mengajukan permohonan ETF TAO pada Januari 2026, yang menunjukkan sinyal masuknya modal institusional ke jalur ini. Selain itu, pada Desember 2025, Bittensor memangkas emisi harian TAO menjadi setengahnya, sehingga pengetatan struktural di sisi pasokan masih berlanjut.
Tautan referensi:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95