









Saat orang biasa masih mempelajari "mantra prompt terkuat", laboratorium puncak Silicon Valley telah mengubah infrastruktur AI menjadi jalur produksi.
Penulis artikel, sumber: Sinar Zhiyuan
Apakah Anda masih terus menyesuaikan prompt di kotak obrolan ChatGPT?
Baru-baru ini, seorang pengguna X mengirimkan tweet yang dimulai dengan seruan terkejut: Templat proyek Claude Code yang digunakan secara diam-diam oleh perusahaan besar bocor!
Ini bukan lagi menulis prompt. Ini adalah infrastruktur teknik AI.

Seluruh strategi berpusat pada satu file 「CLAUDE.md」, dan prinsip intinya hanya tiga:
Setiap kali Claude membuat kesalahan → Anda menambahkan satu aturan; setiap kali Anda mengulangi diri sendiri → Anda menambahkan satu alur kerja; setiap kali ada bug → Anda menambahkan satu pengaman.

Dengan melakukan ini, pengalaman proyek dijadikan konteks jangka panjang dan batasan otomatis yang akan dibaca setiap kali dimulai.
Seluruh arsitektur, seperti struktur posisi di sebuah perusahaan AI: CLAUDE.md adalah buku panduan penerimaan, skills/ adalah SOP kerja, hooks/ adalah departemen kepatuhan, docs/ adalah anggaran dasar perusahaan, tools/ adalah tim logistik, src/ adalah departemen bisnis yang benar-benar menghasilkan karya.

Anda tidak lagi sedang berbicara dengan AI, melainkan sedang membangun AI yang memahami repositori kode Anda.
Bagian paling gila adalah, Anda hanya perlu mengonfigurasi sekali, Claude akan secara otomatis meninjau kode, merekonstruksi sesuai instruksi, menegakkan aturan arsitektur, menulis catatan rilis, menjalankan alur kerja dari keterampilan, mengingat kesalahan masa lalu, dll.
Dan semakin sering digunakan, semakin cerdas.
Sebagian besar orang membuka ChatGPT, menulis prompt, menyalin dan menempel, berulang-ulang; sedangkan dengan metode ini, Anda hanya perlu membuka terminal, menjalankan kode skill yang sudah diserahkan.
Ini seperti memiliki sekelompok rekan kerja AI di perpustakaan kode Anda sendiri.
Di balik tweet ini, terdapat sinyal kecil bahwa era ini sedang perlahan berubah, yang mungkin belum disadari oleh sebagian besar orang.
Sebuah tangkapan layar yang tidak dianggap bocor mengungkap sebuah kebenaran
Screenshot yang dibagikan oleh @ai_rohitt adalah standar rekomendasi resmi dari dokumentasi Anthropic untuk Claude Code.
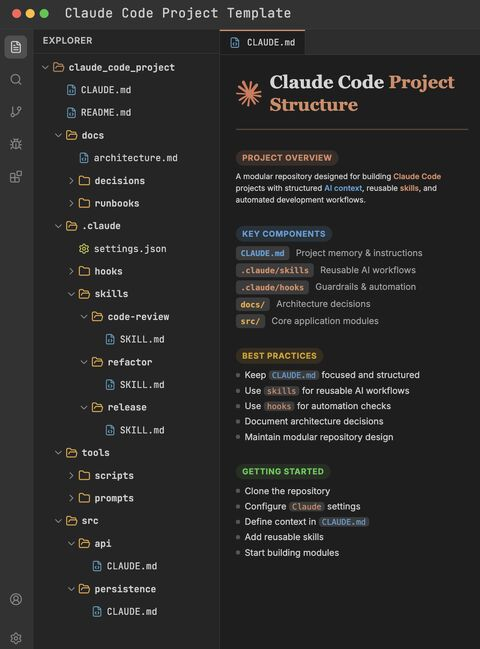
CLAUDE.md adalah file memori proyek yang secara otomatis dibaca oleh Claude Code saat memulai sesi.
.claude/skills/ dan .claude/hooks/ adalah mekanisme ekstensi yang didukung secara resmi.
Ini semua adalah praktik publik yang telah dibahas oleh komunitas selama beberapa bulan, bukan "templat internal" yang dicuri oleh siapa pun.
Namun, fakta bahwa beberapa pengembang berpengalaman secara aktif membagikannya menunjukkan bahwa hal ini mendapat pengakuan dari para pengembang yang sehari-hari menggunakan Claude.
Sebagian besar dari mereka baru menyadari dua hari ini bahwa ternyata bisa digunakan seperti ini.
Sedangkan tim puncak Silicon Valley telah menjadikan hal ini sebagai jalur produksi.
Contoh pertama adalah tim OpenAI Frontier.
Dalam eksperimen tim Frontier yang diungkapkan oleh OpenAI, sebuah beta internal yang dimulai dari repo kosong menghasilkan sekitar 1 juta baris kode dan sekitar 1.500 PR dalam waktu sekitar 5 bulan oleh Codex; tim berkembang dari 3 orang menjadi 7 orang, tanpa penulisan kode secara manual.
Ryan Lopopolo, yang memimpin tim, lebih lanjut menyebut dalam wawancara berikutnya bahwa alur kerja ini telah mendekati bentuk maksimal «0 kode manual, 0 tinjauan manual».
Dia percaya bahwa lebih baik memanfaatkan kapasitas paralel yang sangat tinggi dan biaya yang sangat rendah dari model daripada mengandalkan perhatian sinkron yang terbatas dan mahal dari manusia.
Contoh kedua adalah sistem agen otomatisasi internal Stripe bernama Minions.
Minions di dalam Stripe menghasilkan dan mendorong lebih dari 1.300 PR yang digabungkan setiap minggu, kode tersebut sepenuhnya dihasilkan oleh AI, tetapi tetap melalui tinjauan manusia.
Masih ada satu set data: 1,6% vs 98,4%, yang berasal dari sebuah makalah yang diterbitkan oleh VILA-Lab, Universitas Mohamed bin Zayed AI.

https://arxiv.org/pdf/2604.14228
Peneliti secara sistematis menganalisis 512.000 baris kode sumber TypeScript versi Claude Code v2.1.88, dan menyimpulkan bahwa hanya 1,6% yang merupakan logika keputusan AI, sedangkan 98,4% sisanya adalah infrastruktur teknis yang deterministik.
Secara spesifik, yaitu empat kategori: gateway izin, manajemen konteks, routing alat, dan pemulihan kesalahan.
Angka-angka ini bukan berarti model hanya menyumbang 1,6% kemampuan, tetapi menunjukkan bahwa sebagai produk, Claude Code memiliki sebagian besar kompleksitasnya bukan pada model itu sendiri, melainkan pada infrastruktur teknis deterministik seperti otorisasi, konteks, routing alat, dan mekanisme pemulihan.
Struktur CLAUDE.md/skills/hooks di gambar itu adalah 'infrastructure versi pemula' yang bisa dibangun oleh pengembang biasa, dan memiliki pola yang sama dengan arsitektur produksi dari OpenAI dan Stripe, hanya saja skalanya jauh lebih kecil.
Rahasia yang terungkap dari CLAUDE.md
Selama tiga tahun terakhir, semua orang bertanya, "K متkapan GPT akan menjadi lebih cerdas?" "K متkapan Claude akan merilis versi baru?"
Namun, tim yang benar-benar menjalankan pemrograman AI di lingkungan produksi, yang lebih mereka perhatikan mungkin bukan hal ini, melainkan bagaimana membuat AI mengingat kesalahan yang pernah mereka buat sebelumnya, bagaimana membuat AI melihat batasan arsitektur proyek terlebih dahulu sebelum mulai bekerja, dan bagaimana membuat AI terhenti oleh alat saat melakukan kesalahan.
CLAUDE.md adalah wadah semua ini.
Definisi resmi dari Anthropic hanya satu kalimat:
Sebuah file markdown, ditempatkan di direktori root proyek, yang secara otomatis dibaca oleh Claude Code saat awal setiap sesi.

https://code.claude.com/docs/en/memory
Terdengar sederhana, tetapi lapisan-lapisan struktur di sekitarnya adalah bagian yang benar-benar hebat.
CLAUDE.md adalah otak proyek.
Keputusan arsitektur, konvensi penamaan, persyaratan pengujian, dan semua kesalahan berulang yang pernah terjadi, semuanya ditumpuk di sini. Ini adalah "buku panduan karyawan" yang pertama kali dilihat AI setiap kali dimulai.
.claude/skills/ adalah alur kerja yang dapat digunakan kembali.
Pencipta Claude Code, Boris Cherny, berulang kali menekankan kalimat ini di komunitas: "Jika Anda melakukan sesuatu lebih dari sekali setiap hari, jadikan itu sebagai skill atau command."
Sebuah skill adalah sejumlah metodologi yang dapat dieksekusi. Code review,生成 commit message, menulis release notes, semuanya seharusnya bukan pekerjaan yang harus diketik manual setiap hari, melainkan cukup dengan memanggil skill untuk langsung menghasilkan hasilnya.
.claude/hooks/ adalah penghalang otomatis.
Ini adalah bagian paling krusial. Ia tidak bergantung pada penilaian AI sendiri, tetapi kode deterministik menghentikannya sebelum AI melakukan kesalahan. Inilah mengapa kami berani membiarkan AI berjalan tanpa pengawasan, karena batasan kesalahan telah dihentikan oleh hook.
docs/decisions/ adalah catatan keputusan arsitektur.
Buat AI tidak hanya tahu apa itu kode, tetapi juga mengapa kode seperti itu.
Ini adalah hal yang paling sering diabaikan, tetapi juga merupakan titik pengungkit terbesar dalam kolaborasi AI.
tools/ dan src/ adalah lapisan eksekusi.
Yang patut diperhatikan dari arsitektur ini bukanlah seorang pengembang yang menciptakan direktori yang rapi, melainkan semakin banyak tim independen yang mulai menyatu ke arah yang sama: memasukkan model ke dalam sebuah kerangka yang terdiri dari konteks, alat, izin, evaluasi, dan siklus umpan balik.
Sudah banyak proyek serupa yang dapat dilihat di GitHub:
awesome-claude-code-toolkit oleh rohitg00, claude-code-infrastructure-showcase oleh diet103, dan everything-claude-code oleh affaan-m, semuanya membangun lingkungan kerja terstruktur untuk Claude Code berdasarkan komponen-komponen seperti agents, skills, hooks, rules, dan MCP configs.
Ini menunjukkan bahwa alur kerja pemrograman AI yang benar-benar matang bukan hanya bergantung pada model yang lebih kuat, bukan hanya pada prompt yang lebih panjang, tetapi menempatkan model dalam sistem teknik yang dapat digunakan kembali, dapat dikendalikan, dapat dipulihkan, dan dapat diaudit.
Untuk struktur direktori spesifik, setiap implementasi tidak identik.
Eksperimen batas dari laboratorium OpenAI
Pada 11 Februari 2026, blog resmi OpenAI menerbitkan artikel: >>> Harness engineering: leveraging Codex in an agent-first world<<<

https://openai.com/index/harness-engineering/
Anthropic telah menyesuaikan kembali pendekatan arsitektur Claude Code berdasarkan konsep ini; situs Martin Fowler merangkumnya menjadi sebuah rumus: «Agent=Model+Harness.»
Kata "harness" berasal dari berkuda. Istilah ini merujuk pada seluruh peralatan tali kekang kuda, termasuk tali kekang, bit, pelana, dan kekang.
Seekor kuda bisa berlari cepat dan kuat, tetapi ia sendiri tidak tahu harus pergi ke mana: seluruh peralatan penariklah yang menentukan arahnya.
Dibandingkan dengan pemrograman AI: modelnya sendiri sangat kuat, tetapi ia tidak tahu harus pergi ke mana di dalam repositori kode Anda. Harness adalah setir + rem + navigasi yang Anda buat untuknya.
Eksperimen "1 juta baris tanpa tenaga manusia" dari tim Frontier OpenAI pada dasarnya adalah mendorong Harness hingga batas maksimal.
Praktik teknis utama mereka mencakup beberapa poin berikut.
Keterikatan kuat pada arsitektur hirarkis.
Dari Types ke Config ke Repo ke Service ke Runtime ke UI, ketergantungan mengalir satu arah dan ditegakkan oleh linter di tingkat CI. Agent menulis kode yang melanggar hubungan hierarkis? Bangun langsung gagal.
Pesan kesalahan linter itu sendiri adalah instruksi perbaikan, ini juga merupakan detail paling tidak intuitif.
Kesalahan lint proyek biasa adalah "violation detected", untuk dilihat manusia; kesalahan lint OpenAI Frontier adalah "gunakan logger.info({event: 'name', …data}) alih-alih console.log", instruksi yang dapat dibaca dan diperbaiki langsung oleh Agent.
Dokumen sebagai sumber fakta tunggal. Semua diagram arsitektur, execution plans, dan spesifikasi desain berada di dalam direktori docs/ di dalam repositori. Agent tidak memerlukan basis pengetahuan eksternal, semuanya ada di repo.
Seberapa hebat efek dari hal ini?
Model tidak berubah, tetapi LangChain menyesuaikan harness, termasuk sistem prompt, alat, middleware, dan mode inferensi, sehingga meningkatkan skor Terminal Bench 2.0 dari 52.8 menjadi 66.5.
Hal yang bisa kamu lakukan hari ini
Membangun otak proyek untuk AI
Pertanyaannya kembali ke pengembang biasa: jika paradigma telah berubah, sebagai insinyur biasa, apa yang bisa Anda lakukan hari ini?
Hal pertama, buat file CLAUDE.md di direktori utama proyek terpenting Anda.
Tidak perlu sempurna, tidak perlu panjang. Tulis aturan arsitektur tim, konvensi penamaan, persyaratan pengujian, dan lubang-lubang yang sering Anda injak—versi yang bisa dipakai bisa selesai dalam 10 menit.
Saat AI salah lagi, jangan langsung memperbaiki secara manual, tapi tanyakan pada diri sendiri: Apa yang hilang di CLAUDE.md?
Hal kedua, ubah hal-hal yang dilakukan setiap hari menjadi keterampilan.
Perhatikan kutipan terkenal dari Boris Cherny: "Jika Anda melakukan sesuatu lebih dari sekali setiap hari, jadikan itu sebagai keterampilan atau perintah."
Code review,生成 commit message, menulis release note, memperbaiki bug berulang—semua ini seharusnya menjadi keterampilan, bukan sesuatu yang harus Anda ketikkan secara manual setiap hari.
Hal ketiga, tambahkan hook di tempat-tempat yang mudah menjadi jebakan.
Hook adalah bagian paling berisiko dari 98,4%. Ia tidak bergantung pada AI untuk menjadi cerdas, tetapi bergantung pada kode deterministik untuk pemeriksaan wajib. Ini adalah proses menerjemahkan penilaian insinyur manusia menjadi batasan yang dapat dibaca mesin.
Inti masalah ini bukan pada menulis kode, tetapi pada menulis aturan.
Pernyataan Karpathy di Twitter pada Januari tahun ini yang banyak dibagikan: "Saya telah berubah dari menulis kode secara manual 80% menjadi menyerahkan 80%nya kepada Agent."
Dalam lima tahun ke depan, kurva kemampuan insinyur sedang berpindah dari "Berapa banyak baris kode yang bisa saya tulis" menjadi "Seberapa ketat lingkungan kerja yang bisa saya desain untuk AI".
Pekerjaan menulis kode sedang diambil alih oleh Agent.
Namun, merancang dunia di mana Agent dapat menulis kode yang baik tetap menjadi tugas manusia. Dan lebih sulit, lebih penting, serta lebih menarik daripada sebelumnya.