
Quel modèle de grande taille est véritablement le meilleur sur les tâches d'agents OpenClaw en monde réel ?
MyToken a élaboré, sur la base de données de sites d'évaluation, un benchmark transparent axé exclusivement sur la mesure des capacités réelles des agents d'encodage IA, en se concentrant uniquement sur le taux de réussite (la vitesse et le coût étant des dimensions indépendantes, analysées ultérieurement). Entièrement ouvert et reproductible, il présente uniquement des critères d'évaluation rigoureux et le classement des 10 meilleurs taux de réussite récents.
I. Critères d'évaluation : Taux de réussite
Critère spécifique : Pourcentage de tâches accomplies de manière complète et précise par les agents IA. Chaque tâche suit un processus hautement standardisé :
Prompt utilisateur précis
Envoyer à l'agent l'intégralité pour simuler un scénario de demande utilisateur réel
Comportement attendu
Les méthodes acceptables et les points clés de décision sont indiqués.
Critères d'évaluation (checklist)
Liste des critères d'acceptation atomisés vérifiables point par point
Deuxièmement, trois méthodes d'évaluation
Cette évaluation utilise principalement trois méthodes d'évaluation.
Vérification automatisée : Le script Python vérifie directement le contenu des fichiers, les enregistrements d'exécution, les appels d'outils et autres résultats objectifs.
Juge de modèle LLM : Claude Opus attribue des notes selon une échelle détaillée (qualité du contenu, pertinence, intégralité, etc.)
Mode hybride : vérification objective automatisée + évaluation qualitative par un juge LLM
Toutes les définitions de tâches, les prompts et les logiques d'évaluation sont publiés pour permettre la reprise et la vérification.
Trois. Tâches à évaluer
Ce benchmark couvre 23 catégories de tâches différentes, incluant des interactions de base, des opérations sur des fichiers/code, la création de contenu, l'analyse de recherche, l'appel d'outils système, la persistance de la mémoire, et d'autres dimensions, offrant une forte similitude avec les scénarios d'utilisation quotidiens des développeurs avec OpenClaw :
Vérification de la cohérence (automatisée) — traiter les commandes simples et répondre correctement aux salutations
Création d'événement de calendrier (automatisation) — génération de fichiers de calendrier ICS standards à partir de langage naturel
Recherche de cours boursier (automatisée) — Requête en temps réel des cours et génération de rapports formatés
Blog Post Writing (LLM Judge) — Write a structured Markdown blog post of approximately 500 words
Création de script météo (automatisation) — Écrire un script Python pour l'API météo avec gestion des erreurs
Résumé de document (jugement LLM) — Résumé concis en trois parties sur le thème central
Recherche sur les conférences technologiques (juge LLM) — Recueil et organisation des informations de 5 conférences technologiques réelles (nom, date, lieu, lien)
Rédaction d’un e-mail professionnel (jugement LLM) — Refuser poliment la réunion et proposer une alternative
Récupération de mémoire à partir du contexte (automatisée) — Extraction précise de dates, de membres, de stack technique, etc. à partir des notes de projet
Création de la structure de fichiers (automatisation) — génération automatique du répertoire de projet standard, du README et du .gitignore
Workflow API en plusieurs étapes (hybride) — lire la configuration → écrire le script d'appel → documenter complètement
Installez la compétence ClawdHub (automatisation) — installez-la à partir du dépôt de compétences et vérifiez sa disponibilité
Rechercher et installer une compétence (automatisation) — rechercher et installer correctement une compétence liée à la météo
Génération d'images IA (mixte) — Générez et enregistrez des images selon la description
Humaniser les blogs générés par l’IA (jugement LLM) — transformer un contenu trop machine en langage naturel et conversationnel
Résumé quotidien de recherche (juge LLM) — Synthèse cohérente de plusieurs documents
Tri des e-mails de la boîte de réception (mixte) — Analyser plusieurs e-mails et établir un rapport classé par urgence
Recherche et synthèse d’e-mails (mixte) — Rechercher les e-mails archivés et extraire les informations clés
Recherche de marché compétitive (mixte) — Analyse des concurrents dans le domaine des APM d'entreprise
Résumé CSV et Excel (mixte) — Analyser les fichiers de tableaux et générer des insights
Résumé PDF ELI5 (jugement LLM) — Expliquez les PDF techniques avec des mots compréhensibles pour un enfant de 5 ans
Compréhension du rapport OpenClaw (automatisation) — Répondre précisément à des questions spécifiques à partir de rapports d'étude au format PDF
Persistence des connaissances du Second Brain (hybride) — Stockage inter-sessions et rappel précis des informations
Quatre : Conclusion principale : Classement des 10 meilleurs modèles par taux de réussite (Meilleur % / Moyenne %)
Les données sont mises à jour au 7 avril 2026
Le % le plus élevé correspond au taux de réussite le plus élevé sur une seule opération, tandis que le % moyen représente le taux de réussite moyen sur plusieurs opérations, reflétant mieux la stabilité.
Voici les dix modèles avec le taux de réussite le plus élevé
anthropic/claude-opus-4.6 (Anthropic) —— 93,3 % / 82,0 %
arcee-ai/trinity-large-thinking (Arcee AI) — 91,9 % / 91,9 %
openai/gpt-5.4 (OpenAI) — 90,5 % / 81,7 %
qwen/qwen3.5-27b (Qwen) — 90,0 % / 78,5 %
minimax/minimax-m2.7 (MiniMax) — 89,8 % / 83,2 %
anthropic/claude-haiku-4.5 (Anthropic) —— 89,5 % / 78,1 %
qwen/qwen3.5-397b-a17b (Qwen) — 89,1 % / 80,4 %
xiaomi/mimo-v2-flash (Xiaomi) —— 88,8 % / 70,2 %
qwen/qwen3.6-plus-preview (Qwen) — 88,6 % / 84,0 %
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88,6 % / 75,5 %
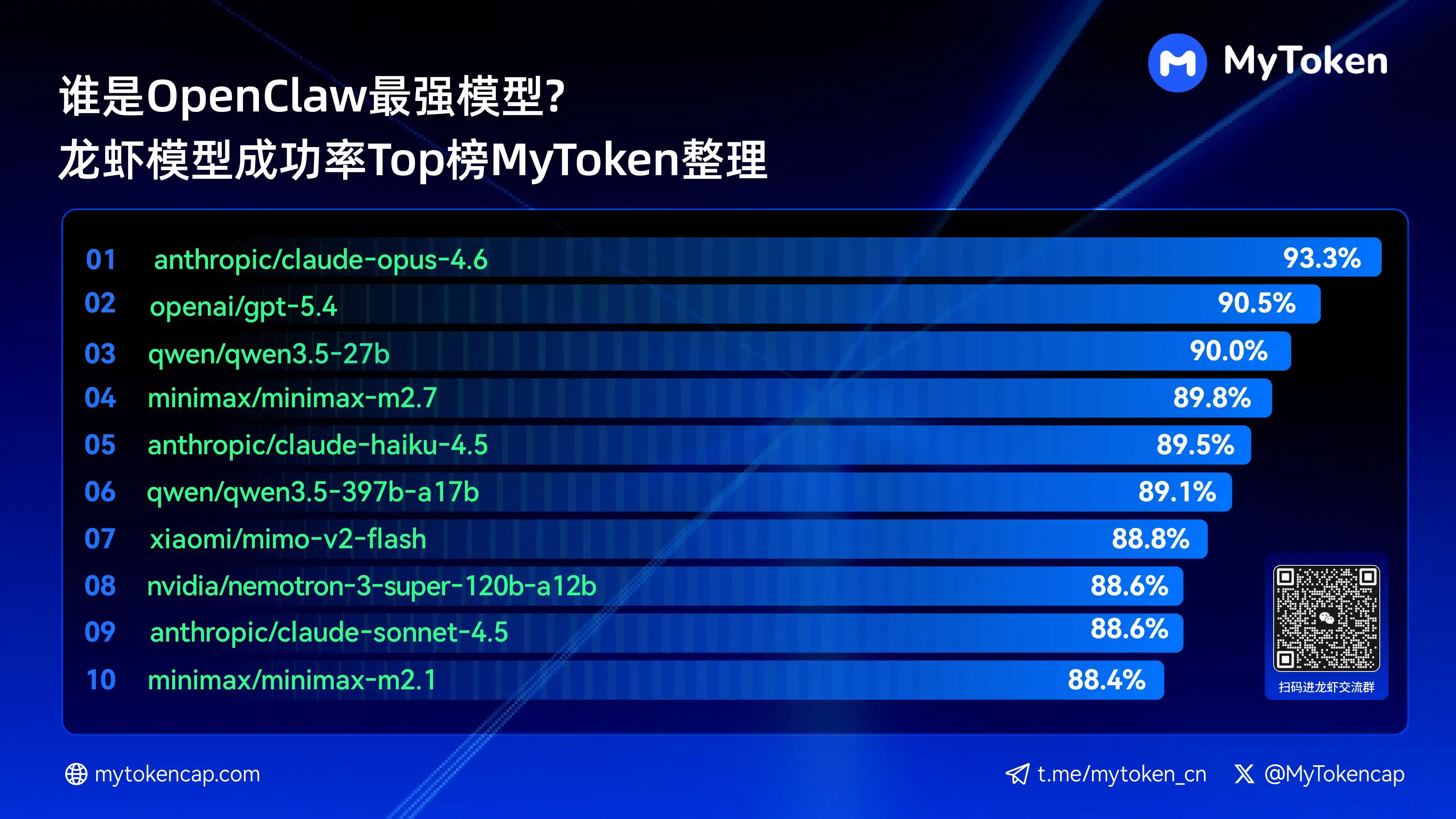
Claude Opus 4.6 mène actuellement avec un taux de réussite maximal de 93,3 %, mais Trinity d'Arcee se distingue par sa stabilité moyenne remarquable, tandis que plusieurs modèles de la série Qwen figurent parmi les dix premiers, démontrant un fort potentiel de rapport qualité-prix. Le taux de réussite constitue un seuil de base ; la vitesse et le coût influenceront ultérieurement l'expérience réelle.
Ce benchmark de 23 tâches est entièrement transparent ; nous recommandons vivement à chacun de l'tester selon son propre contexte. Pour plus de classements d'autres modèles, veuillez attendre la fonctionnalité prochaine de classement des agents de MyToken.
(Les données proviennent du benchmark OpenClaw publié par PinchBench, en mise à jour continue.)