









Autor original: David, DeepTide TechFlow
El 20 de enero por la tarde, X abrió al público una nueva versión de su algoritmo de recomendación.
La respuesta de Musk fue bastante interesante: "Sabemos que el algoritmo es estúpido y necesita grandes modificaciones, pero al menos puedes ver que estamos luchando en tiempo real para mejorar. Ninguna otra plataforma social se atrevería a hacer esto".
Esto tiene dos significados.Primero, admitir que el algoritmo tiene problemas, y segundo, presentar la "transparencia" como un punto de venta.
Esta es la segunda vez que X abre su algoritmo al público. La versión del código de 2023 no se ha actualizado durante tres años y lleva mucho tiempo desactualizada respecto al sistema real. En esta ocasión se ha reescrito completamente, y el modelo central ha pasado del aprendizaje automático tradicional al Grok transformer. Según la descripción oficial, esto «elimina por completo la ingeniería manual de características».
Antes, los algoritmos dependían de que los ingenieros ajustaran manualmente los parámetros, pero ahora la inteligencia artificial analiza directamente tu historial de interacciones para decidir si mostrar o no tu contenido.
Para los creadores de contenido, esto significa que la antigua "ciencia oculta" sobre "a qué hora publicar es mejor" o "qué etiquetas usar para ganar seguidores" probablemente ya no funcione.
También revisamos algunos repositorios de código abierto en Github y, con la ayuda de la IA, descubrimos que en el código realmente hay algunas lógicas complejas que valen la pena explorar.
Cambio en la lógica del algoritmo: de la definición manual a la evaluación automática mediante IA
Primero aclararemos las diferencias entre las versiones antiguas y nuevas, de lo contrario las discusiones posteriores pueden resultar confusas.
En 2023, la versión de Twitter que abrió su código se llamaba Heavy Ranker, y en esencia era aprendizaje automático tradicional. Los ingenieros tenían que definir manualmente cientos de «características»: si el tuit tiene imágenes, cuántos seguidores tiene el autor, cuánto tiempo ha pasado desde que se publicó, si hay enlaces en el tuit...
Luego se asigna un peso a cada característica, se ajusta y vuelve a ajustar para ver qué combinación da mejores resultados.
La nueva versión abierta de código esta vez se llama Phoenix, con una arquitectura completamente diferente. Puedes entenderla como un algoritmo que depende aún más de modelos de inteligencia artificial de gran tamaño. Su núcleo utiliza el modelo transformer de Grok, que comparte la misma tecnología que ChatGPT y Claude.
El documento README oficial lo expone claramente: «Hemos eliminado cada una de las características diseñadas manualmente».
Todas las reglas tradicionales que dependían de la extracción manual de características del contenido han sido eliminadas por completo.
Ahora, ¿en base a qué este algoritmo juzga si un contenido es bueno o no?
La respuesta depende de ti.Secuencia de comportamientos¿Qué has dado me gusta anteriormente, a quién has respondido, en qué publicaciones has permanecido más de dos minutos, qué tipos de cuentas has bloqueado. Phoenix alimenta estos comportamientos a un transformer, permitiendo que el modelo aprenda por sí mismo las pautas y realice resúmenes.
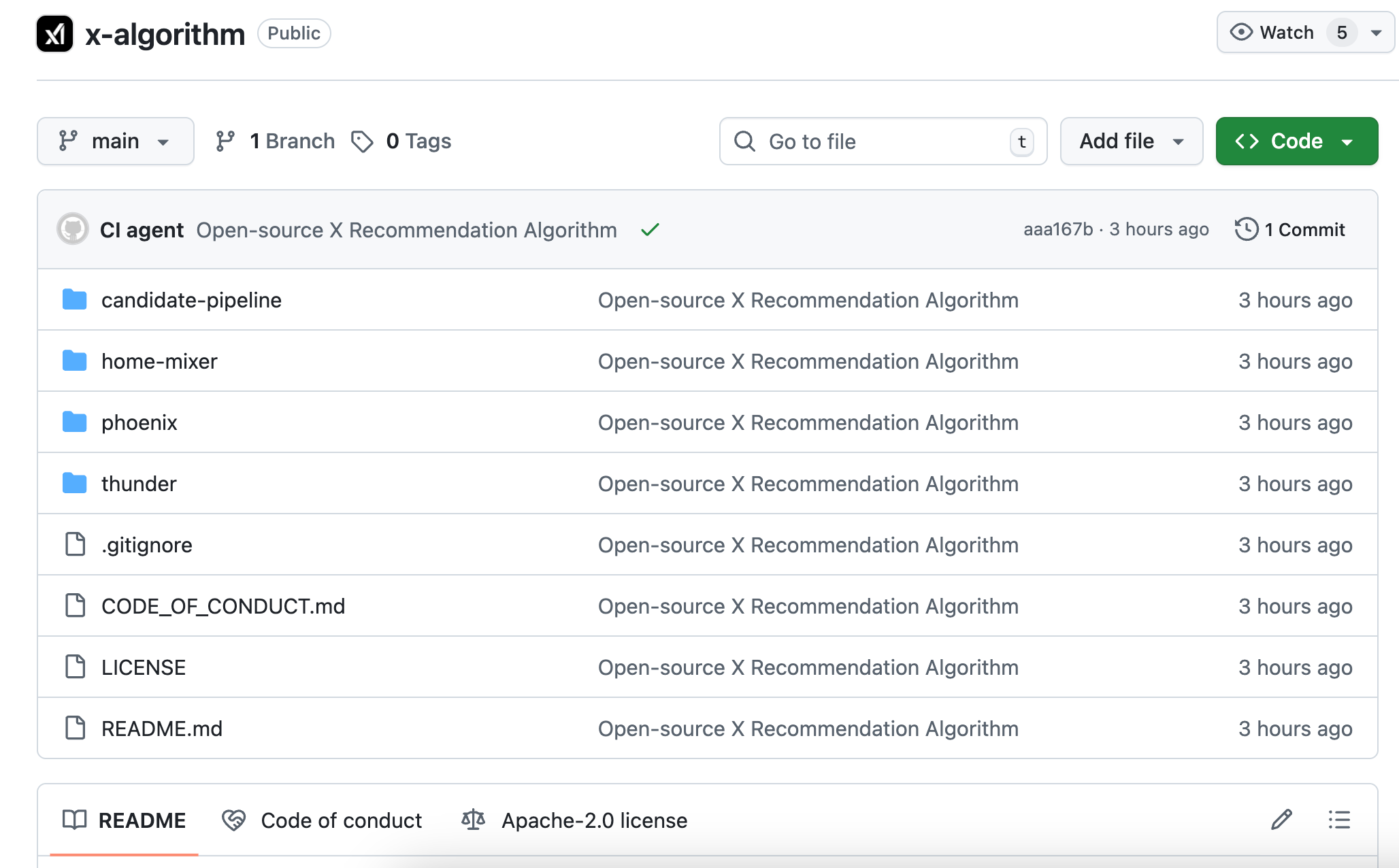
A modo de ejemplo: el algoritmo antiguo es como una tabla de puntuación elaborada manualmente, en la que se otorga una puntuación por cada casilla marcada;
El nuevo algoritmo es como una inteligencia artificial que ha visto todo tu historial de navegación,Adivina directamente¿Qué te gustaría ver en el siguiente segundo?
Para los creadores, esto significa dos cosas:
En primer lugar, las técnicas anteriores, como los "mejores momentos para publicar" o las "etiquetas doradas", tienen menos valor como referencia ahora.Dado que el modelo ya no examina estas características fijas, sino que se enfoca en las preferencias personales de cada usuario.
En segundo lugar, si tu contenido puede ser difundido o no depende cada vez más de "cómo reaccionarán las personas que lo ven".Esta reacción se ha cuantificado en 15 predicciones de comportamiento, que detallaremos en el próximo capítulo.
Algoritmos prediciendo tus 15 reacciones
Una vez que Phoenix obtiene una publicación que se va a recomendar, predecirá 15 posibles comportamientos que el usuario actual podría tener al ver este contenido:
- Comportamiento positivocomo dar me gusta, responder, reenviar, reenviar con cita, hacer clic en la publicación, hacer clic en la página principal del autor, ver más del 50 % del video, expandir imágenes, compartir, permanecer durante un tiempo determinado, seguir al autor
- Comportamiento negativo: como hacer clic en "No me interesa", bloquear al autor, silenciar al autor, denunciar
Cada acción corresponde a una probabilidad de predicción. Por ejemplo, el modelo juzga que hay un 60 % de probabilidad de que le des a "me gusta" en esta publicación, un 5 % de probabilidad de que bloques a este autor, etc.
Luego, el algoritmo hace una cosa sencilla: multiplica estas probabilidades por sus respectivos pesos, las suma y obtiene una puntuación total.
La fórmula se ve así:
Puntaje Final = Σ ( peso × P(acción) )
El peso de los comportamientos positivos es un número positivo y el peso de los comportamientos negativos es un número negativo.
Las publicaciones con puntuación total alta aparecerán en primer lugar, y las de puntuación baja se hundirán.
Salir de la fórmula, en realidad se reduce a:
Ahora mismo, si un contenido es bueno o no, ya no depende realmente de si el contenido en sí está bien escrito (aunque la legibilidad y la utilidad son la base para su difusión); sino que depende más de "qué reacción te provoca este contenido". El algoritmo no se preocupa por la calidad de la publicación en sí, solo se interesa por tus acciones.
Siguiendo esta línea de pensamiento, en situaciones extremas, una publicación vulgar pero que haga que la gente no pueda evitar responder con comentarios sarcásticos podría obtener una puntuación más alta que una publicación de alta calidad pero que nadie interactúe. Quizás esta sea la lógica subyacente del sistema.
Sin embargo, la versión de código abierto reciente no ha revelado los valores numéricos específicos de los pesos del algoritmo, pero sí se hicieron públicos en la versión de 2023.
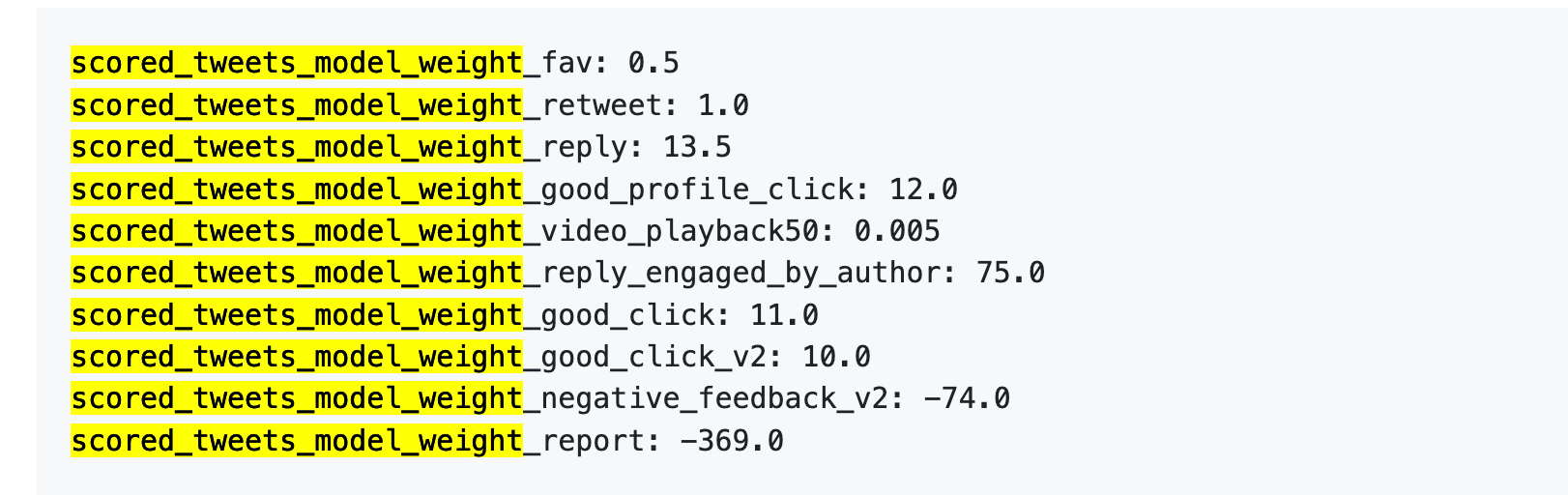
Referencia de la versión anterior: 1 denuncia = 738 me gusta
A continuación, podemos analizar los datos de 2023, aunque sean antiguos, te ayudarán a comprender cuánta "diferencia de valor" existe en los ojos del algoritmo para distintas acciones.
El 5 de abril de 2023, X realmente publicó un conjunto de datos de pesos en GitHub.
Vamos directamente con los números:
Traducción más directa:
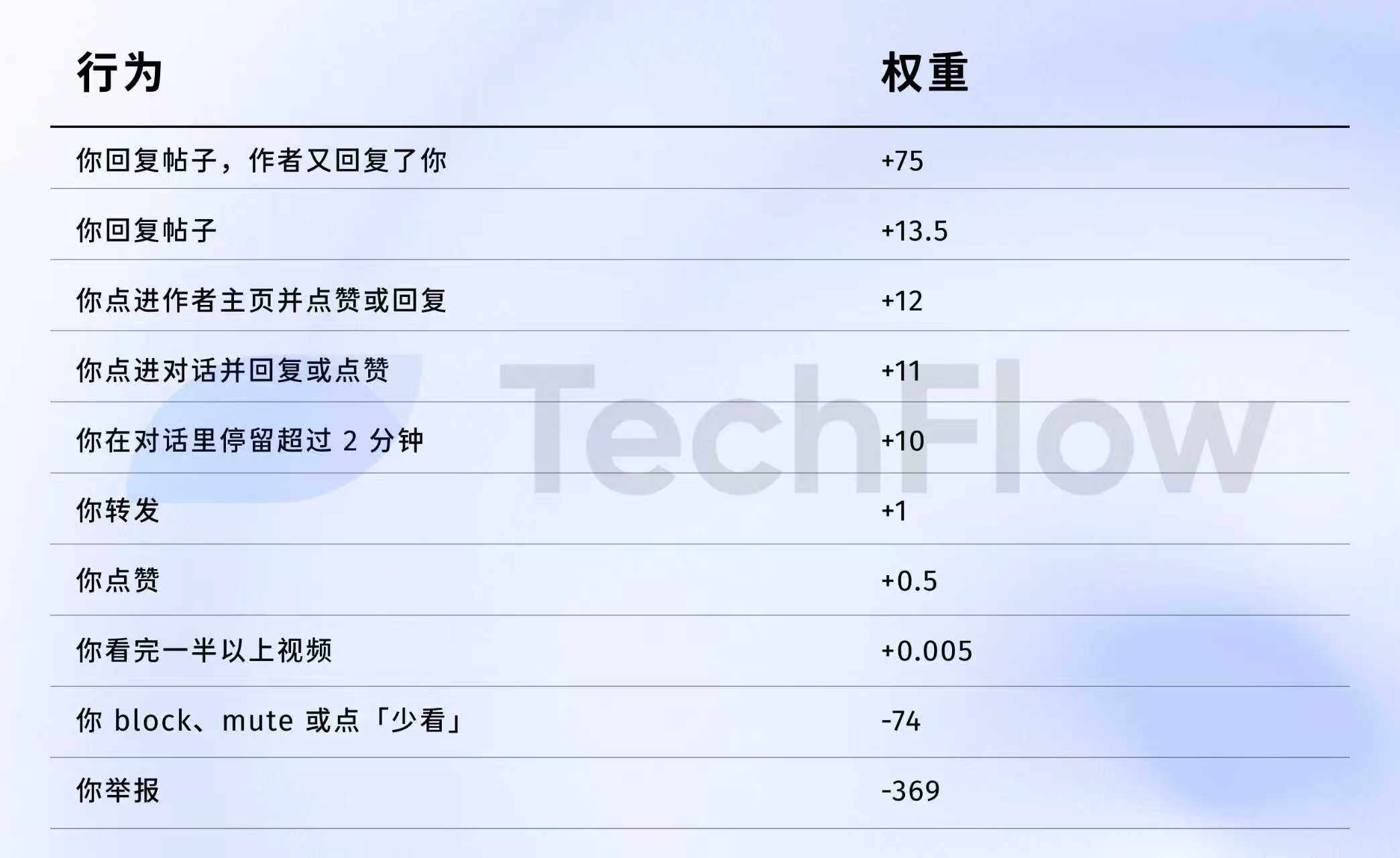
Fuente de datos: versión anterior Repositorio de GitHub twitter/the-algorithm-ml, haga clic para ver el algoritmo original
Algunos números merecen una mirada más detallada.
Primero, casi no tiene valor hacer clic en "me gusta". El peso es de solo 0.5, el más bajo entre todos los comportamientos positivos. Para el algoritmo, el valor de un me gusta es aproximadamente cero.
En segundo lugar, la interacción conversacional es lo realmente valioso. El peso de "tú respondes y el autor responde a ti" es 75, es decir, 150 veces el valor de un me gusta. Lo que más quiere ver el algoritmo no son me gustas unidireccionales, sino una conversación intercambiada.
Tercero, el costo de la retroalimentación negativa es muy alto. Un bloqueo o silenciamiento (-74) requiere 148 me gusta para compensarlo. Una denuncia (-369) requiere 738 me gusta. Además, estos puntos negativos se acumulan en la puntuación de confianza de tu cuenta y afectan la distribución de todas tus publicaciones posteriores.
Cuarto, la ponderación de la tasa de visualización completa de los videos es absurdamente baja. Solo 0.005, casi se puede ignorar. Esto contrasta claramente con Douyin y TikTok, donde esos dos plataformas consideran la tasa de visualización completa como un indicador clave.
En el mismo documento oficial también se menciona: «Los pesos exactos en el archivo pueden ajustarse en cualquier momento... Desde entonces, hemos ajustado periódicamente los pesos para optimizar las métricas de la plataforma».
Las ponderaciones pueden ajustarse en cualquier momento y de hecho se han ajustado.
La nueva versión no revela valores concretos, pero el marco lógico escrito en el README es el mismo: sumar puntos positivos, restar puntos negativos y calcular una suma ponderada.
Los números específicos pueden haber cambiado, pero con gran probabilidad las relaciones de magnitud aún están ahí. Responder a los comentarios de otros es más útil que recibir 100 me gusta. Hacer que la gente quiera bloquearte es peor que no tener interacción alguna.
Después de conocer esto, ¿qué podemos hacer los creadores?
Revisa el código de los algoritmos nuevos y antiguos de Twitter, combínalos y extrae algunas conclusiones operativas.
1. Responde a tus comentaristas. En la tabla de ponderación, "el autor responde al comentarista" es el ítem con mayor puntuación (+75), 150 veces más que un "me gusta" unilatera de un usuario. No se trata de que vayas a pedir comentarios, sino de responder cuando alguien comenta. Incluso si respondes con solo una palabra "gracias", el algoritmo lo contará.
2. No dejes que nadie se vaya sin más. Un bloqueo tiene un impacto negativo que requiere 148 me gusta para compensarlo. El contenido controvertido efectivamente genera interacción, pero si la forma de interacción es "este usuario es molesto, lo bloqueo", tu puntuación de confianza de la cuenta se verá continuamente dañada, afectando la distribución de todas tus publicaciones posteriores. El tráfico generado por el contenido controvertido es una espada de doble filo; antes de herir a otros, corta primero tu propio exceso.
3. Coloque los enlaces externos en la sección de comentarios.El algoritmo no quiere redirigir a los usuarios fuera del sitio. El contenido con enlaces será penalizado.Esto lo dijo Musk públicamente. Si quieres redirigir tráfico, escribe el contenido principal en el cuerpo del mensaje y coloca el enlace en el primer comentario.
4. No inundes la pantalla. En la nueva versión del código hay un "Author Diversity Scorer", cuya función es reducir la relevancia de las publicaciones consecutivas del mismo autor. El propósito del diseño es hacer más variado el feed del usuario, y como efecto secundario, publicar diez mensajes seguidos es menos efectivo que publicar una sola entrada de calidad.
6. Ya no existe un "mejor momento para publicar". El algoritmo anterior contaba con una característica manual llamada "hora de publicación", pero la versión nueva la eliminó sin más. Phoenix solo analiza la secuencia de comportamientos del usuario y no tiene en cuenta la hora a la que se publica una entrada. Estrategias como "publicar a las tres de la tarde del martes da mejores resultados", van perdiendo cada vez más su valor de referencia.
Lo anterior es lo que se puede leer a nivel de código.
Además, hay algunos elementos adicionales de bonificación o penalización que provienen de los documentos públicos de X, y que no están incluidos en este repositorio de código abierto: por ejemplo, los tweets con la verificación azul reciben bonificaciones, el uso de mayúsculas totalmente en un texto reduce su relevancia, y el contenido sensible puede provocar una reducción del 80 % en la tasa de llegada. Como estas reglas no se han abierto al público, no entraremos en más detalles.
En resumen, lo que se ha abierto fuente en esta ocasión es bastante sustancial.
Arquitectura del sistema completa, lógica de recuperación de contenido candidato, flujo de clasificación y puntuación, implementación de varios filtros. El código está principalmente escrito en Rust y Python, con una estructura clara y un README tan detallado como el de muchos proyectos comerciales.
Pero no se han revelado algunas cosas clave.
1. Los parámetros de peso no se han publicado. En el código solo se menciona "sumar puntos por comportamientos positivos y restar puntos por comportamientos negativos", pero no se especifica cuántos puntos se suman por un "me gusta" o cuántos puntos se restan por un bloqueo. La versión de 2023 al menos revelaba los números concretos, mientras que en esta ocasión solo se proporciona un marco de fórmula.
2. Los pesos del modelo no se han publicado. Phoenix utiliza el Grok transformer, pero no se incluyen los parámetros del propio modelo. Puedes ver cómo se llama al modelo, pero no cómo se calcula internamente el modelo.
3. Los datos de entrenamiento no se han hecho públicos. No se menciona qué datos se usaron para entrenar el modelo, cómo se muestrearon los comportamientos de los usuarios ni cómo se construyeron las muestras positivas y negativas.
Por ejemplo, esta vez, el código abierto es como si te dijera: "Calculamos la puntuación total mediante una suma ponderada", pero no te dice cuáles son los pesos; o como si te dijera: "Usamos un transformer para predecir la probabilidad de comportamiento", pero no te dice cómo es el transformer por dentro.
En comparación transversal, ni siquiera TikTok e Instagram han hecho públicos datos de este tipo. La cantidad de información que X ha decidido abrir esta vez es, efectivamente, mayor que la de otras plataformas principales. Sin embargo, aún queda camino por recorrer para alcanzar una "transparencia total".
Esto no significa que no tenga valor el software de código abierto. Para los creadores y los investigadores, ver el código siempre es mejor que no poder verlo.