









Autor:Tina, Dongmei, InfoQ
1. Tras casi tres años, Musk vuelve a open sourcear el algoritmo de recomendación de X
Hace un momento, el equipo de ingeniería de X publicó en X anunciando que oficialmente ha abierto el código fuente del algoritmo de recomendación de X. Según la descripción, esta biblioteca de código abierto contiene el sistema de recomendación central que respalda el feed de "Recomendaciones para ti" en X. Este sistema combina contenido dentro de la red (proveniente de cuentas que el usuario sigue) con contenido fuera de la red (descubierto mediante búsquedas basadas en aprendizaje automático), y utiliza un modelo Transformer basado en Grok para clasificar todo el contenido. Esto significa que el algoritmo utiliza la misma arquitectura Transformer que Grok.
Repositorio de código abierto: https://x.com/XEng/status/2013471689087086804
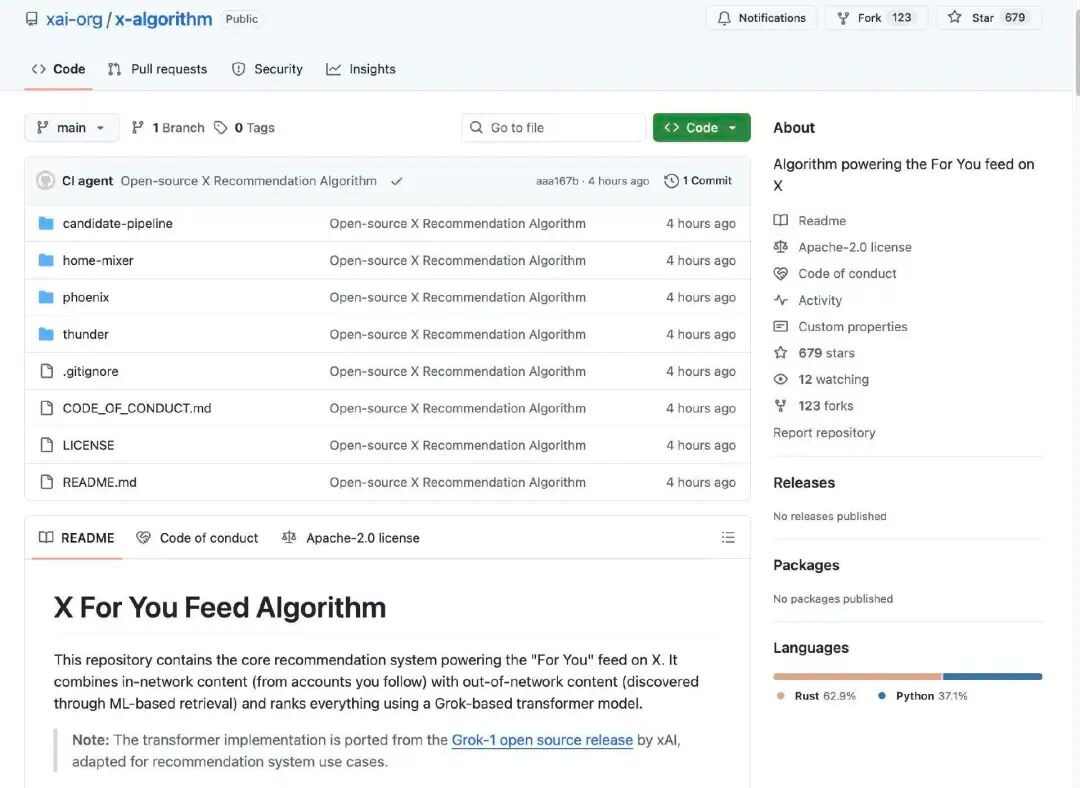
El algoritmo de recomendación de X es responsable de generar lo que los usuarios ven en la interfaz principal.Contenido de "Recomendado para ti" (For You Feed)Obtiene publicaciones candidatas de dos fuentes principales:
La cuenta a la que te suscribiste (In-Network / Thunder)
Otros mensajes encontrados en la plataforma (Fora de la red / Phoenix)
Estos contenidos candidatos se procesan posteriormente de forma uniforme, se filtran y se ordenan según su relevancia.
Entonces, ¿cuál es la arquitectura central del algoritmo y su lógica de funcionamiento?
El algoritmo primero recopila contenido candidato de dos tipos de fuentes:
Contenido de seguimiento: publicaciones de cuentas que tú has seguido activamente.
Contenido no seguido: publicaciones que podrían interesarte, recuperadas por el sistema en toda la base de contenido.
El objetivo de esta fase es "encontrar publicaciones que puedan ser relevantes".
El sistema elimina automáticamente contenido de baja calidad, duplicado, ilegal o inadecuado. Por ejemplo:
Contenido de la cuenta bloqueada
Temas que el usuario claramente no está interesado
Publicaciones ilegales, obsoletas o no válidas
Esto garantiza que al final, durante el ordenamiento, solo se procese contenido candidato valioso.
El núcleo del algoritmo liberado esta vez es que el sistema utiliza un modelo Transformer basado en Grok (similar a un modelo de lenguaje de gran tamaño o red neuronal de aprendizaje profundo) para puntuar cada publicación candidata. El modelo Transformer predice la probabilidad de cada tipo de comportamiento según la historia de interacciones del usuario (me gusta, comentarios, reenvíos, clics, etc.). Finalmente, estas probabilidades de comportamiento se combinan de forma ponderada para formar una puntuación integral, y las publicaciones con una puntuación más alta tienen más probabilidades de ser recomendadas al usuario.
Este diseño prácticamente elimina la práctica tradicional de extracción manual de características, y en su lugar utiliza un enfoque de aprendizaje de extremo a extremo para predecir los intereses del usuario.
Esta no es la primera vez que Musk hace open source el algoritmo de recomendación de X.
Ya el 31 de marzo de 2023, como prometió cuando adquirió Twitter, Musk abrió oficialmente parte del código fuente de Twitter, incluyendo el algoritmo que recomienda tweets en las líneas de tiempo de los usuarios.El día del lanzamiento como proyecto open source, el proyecto ya había obtenido más de 10.000 estrellas en GitHub.
En ese momento, Musk expresó en Twitter que este lanzamiento era"La mayoría de los algoritmos de recomendación"El resto de los algoritmos también se irán abriendo progresivamente. Además, expresó su deseo de que "terceros independientes puedan determinar con una precisión razonable el contenido que Twitter podría mostrar a los usuarios".
En la discusión de Space sobre el lanzamiento del algoritmo, dijo que el plan de código abierto busca convertir a Twitter en "el sistema más transparente de internet" y hacerlo tan robusto como el proyecto de código abierto más conocido y exitoso, Linux. "El objetivo general es que los usuarios que siguen apoyando a Twitter disfruten al máximo de esta plataforma", afirmó.
Hoy en día, han pasado más de tres años desde que Musk abrió por primera vez el algoritmo X. Y como un KOL super importante en el círculo tecnológico, Musk ya ha hecho suficiente publicidad para esta ocasión de código abierto.
El 11 de enero, Musk publicó en X que abriría el nuevo algoritmo de X (incluyendo todo el código utilizado para determinar qué contenido de búsqueda natural y qué anuncios se recomiendan a los usuarios) como código abierto dentro de 7 días.
Este proceso se repetirá cada 4 semanas y contará con instrucciones detalladas para los desarrolladores, con el fin de ayudar a los usuarios a comprender qué cambios se han producido.
Hoy, su promesa se ha cumplido nuevamente.
2. ¿Por qué Musk quiere hacer open source?
Cuando Elon Musk menciona nuevamente "código abierto", la primera reacción del público no es el idealismo tecnológico, sino la presión real.
Durante el último año, X ha estado repetidamente envuelto en controversias por su mecanismo de distribución de contenido. La plataforma ha sido ampliamente criticada por favorecer y fomentar, a nivel algorítmico, puntos de vista de la derecha. Esta tendencia no se considera un caso aislado, sino que se percibe como un patrón sistémico. Un informe publicado el año pasado señaló que el sistema de recomendación de X mostraba un sesgo político claramente nuevo y evidente en la difusión de contenido.
Mientras tanto, algunos casos extremos han intensificado aún más las dudas externas. El año pasado, un video no verificado que involucraba un intento de asesinato contra el activista conservador estadounidense Charlie Kirk se propagó rápidamente en la plataforma X, causando una conmoción pública. Los críticos consideraron que esto no solo reveló la ineficacia del sistema de moderación del contenido de la plataforma, sino que también volvió a destacar cómo los algoritmos deciden qué contenido ampliar y qué contenido no ampliar. Poder implícito.
Dado este contexto, es difícil interpretar de forma sencilla que Musk haya resaltado repentinamente la transparencia algorítmica como una decisión puramente técnica.

3. ¿Qué opinan los internautas?
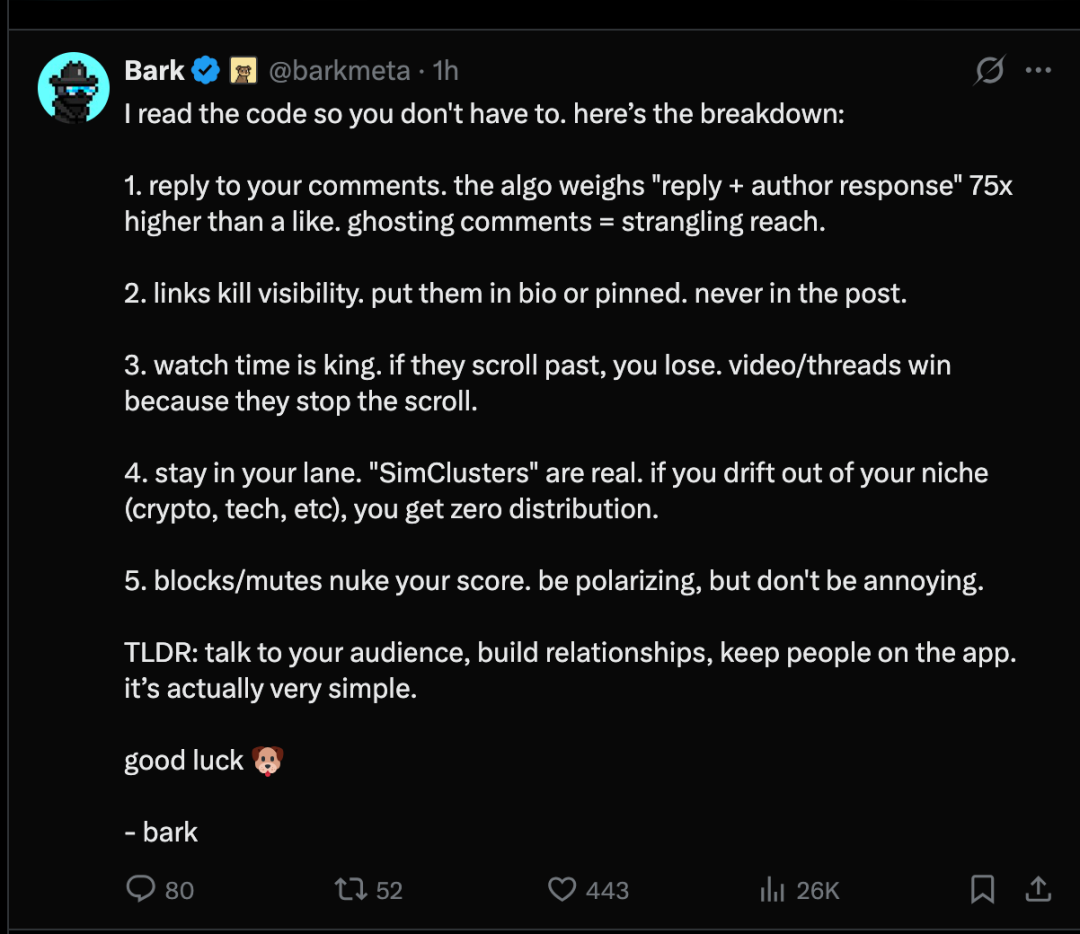
Después de que el algoritmo de recomendación de X se hiciera open source, en la plataforma X, los usuarios resumieron el mecanismo del algoritmo de recomendación en los siguientes 5 puntos:
- Responde a tu comentarioEl algoritmo da a "respuesta + respuesta del autor" un peso 75 veces mayor que el de los me gusta. No responder a los comentarios afectará significativamente la visibilidad.
- Los enlaces reducen la tasa de exposición.Coloque el enlace en su perfil personal o en un mensaje destacado, ¡nunca en el cuerpo principal del mensaje.
- La duración de la visualización es fundamental.Si deslizan la pantalla y pasan de largo, no lograrás captar su atención. Los videos o publicaciones que obtienen mucha atención son aquellos que logran detener al usuario.
- Apega a tu área de competencia."Sim Cluster" es real. Si te alejas de tu nicho (criptomonedas, tecnología, etc.), no obtendrás ningún canal de distribución.
- Bloquear / Callarse reducirá en gran medida tu puntuación.Que sea controvertido, pero no molesto.
En resumen: comunícate con tu audiencia, establece relaciones y haz que los usuarios permanezcan dentro de la aplicación. En realidad es bastante sencillo.
También hay usuarios en Internet que han descubierto que, aunque la arquitectura es de código abierto, aún hay algunos contenidos que no se han abierto. El usuario comentó que, en esencia, este lanzamiento es un marco, pero no incluye el motor. ¿Qué falta específicamente?
Falta el parámetro de peso. - El código confirma la asignación de puntos adicionales por "comportamientos positivos" y la deducción de puntos por "comportamientos negativos", pero a diferencia de la versión de 2023, los valores específicos han sido eliminados.
Ocultar pesos del modelo - No incluye los parámetros internos y cálculos del propio modelo.
Datos de entrenamiento no públicos - No sabemos nada sobre los datos utilizados para entrenar el modelo, la forma de muestreo del comportamiento de los usuarios, ni cómo se construyeron las muestras "buenas" y "malas".
Para la mayoría de los usuarios de X, el hecho de que el algoritmo de la plataforma sea de código abierto no tendría una gran influencia. Sin embargo, una mayor transparencia permitiría explicar por qué ciertos posts reciben visibilidad y otros no, y también permitiría a los investigadores estudiar cómo la plataforma clasifica el contenido.
4. ¿Por qué el sistema de recomendación es un campo de batalla crucial?
En la mayoría de los debates técnicos,Sistema de recomendaciónA menudo se considera parte de la ingeniería trasera, discreta y compleja, pero rara vez recibe la atención pública. Sin embargo, si se analiza cuidadosamente el modo en que operan las empresas tecnológicas líderes, se descubre que el sistema de recomendación no es un módulo periférico, sino una "infraestructura fundamental" que sustenta todo el modelo de negocio. Por esta razón, puede considerarse una "bestia silenciosa" del sector de internet.
Los datos públicos han confirmado repetidamente este hecho. Amazon reveló que aproximadamente el 35 % de las compras en su plataforma se generan directamente a través del sistema de recomendación. Netflix es aún más radical, ya que aproximadamente el 80 % del tiempo de visualización está impulsado por algoritmos de recomendación. La situación en YouTube es similar, con aproximadamente el 70 % del tiempo de visualización atribuido al sistema de recomendación, especialmente al feed (flujo de contenido). En cuanto a Meta, aunque nunca ha proporcionado una proporción específica, su equipo técnico mencionó que aproximadamente el 80 % de los ciclos de capacidad computacional en sus clústeres internos se utilizan para tareas relacionadas con las recomendaciones.
¿Qué significan estos números?Si se eliminara el sistema de recomendación de estos productos, sería casi equivalente a quitar los cimientos.Tomemos como ejemplo a Meta: la publicidad, el tiempo que los usuarios pasan en la plataforma y la conversión comercial dependen casi en su totalidad del sistema de recomendación. Este no solo decide qué ven los usuarios, sino que también determina directamente cómo gana dinero la plataforma.
Sin embargo, precisamente un sistema que decide entre la vida y la muerte ha enfrentado durante mucho tiempo problemas de una complejidad técnica extremadamente alta.
En la arquitectura tradicional de sistemas de recomendación, es difícil cubrir todos los escenarios con un único modelo. Los sistemas de producción reales suelen estar muy fragmentados. Tomando como ejemplo empresas como Meta, LinkedIn o Netflix, detrás de una cadena completa de recomendaciones suelen funcionar simultáneamente 30 o incluso más modelos especializados: modelos de recuperación, modelos de preclasificación, modelos de clasificación fina, modelos de reordenación, cada uno optimizado para diferentes funciones objetivo y métricas de negocio. Detrás de cada modelo, normalmente hay uno o incluso varios equipos responsables del ingeniería de características, entrenamiento, ajuste de hiperparámetros, despliegue y la iteración continua.
El costo de este modelo es evidente: complejidad en ingeniería, altos costos de mantenimiento y dificultad para la cooperación entre tareas. En cuanto alguien plantea la pregunta "¿Podría usarse un solo modelo para resolver múltiples problemas de recomendación?", esto significaría una reducción de órdenes de magnitud en la complejidad del sistema completo. Este es precisamente el objetivo que la industria ha anhelado durante mucho tiempo pero que ha sido difícil de lograr.
La aparición de los modelos de lenguaje de gran tamaño ha proporcionado un nuevo camino posible para los sistemas de recomendación.
Los modelos LLM ya han demostrado en la práctica que pueden convertirse en modelos generales extremadamente potentes: tienen una gran capacidad de transferencia entre diferentes tareas, y su rendimiento puede seguir mejorando con la expansión de la escala de datos y el poder computacional. En contraste, los modelos tradicionales de recomendación suelen ser "personalizados por tareas", y resulta difícil compartir sus capacidades entre múltiples escenarios.
Además, un modelo único no solo simplifica el proceso de ingeniería, sino que también ofrece el potencial de "aprendizaje cruzado". Cuando el mismo modelo maneja simultáneamente múltiples tareas de recomendación, las señales de las distintas tareas pueden complementarse mutuamente, y a medida que aumenta la escala de los datos, el modelo evoluciona con mayor facilidad de forma integral. Esta es precisamente una característica que los sistemas de recomendación han deseado durante mucho tiempo, pero que resulta difícil de lograr mediante métodos tradicionales.
¿Qué ha cambiado el LLM? En realidad, ha cambiado desde el ingeniería de características hasta la capacidad de comprensión.
Desde el punto de vista metodológico, el mayor cambio que los LLM (Modelos de Lenguaje de Gran Tamaño) introducen en los sistemas de recomendación ocurre en la etapa central del "procesamiento de características".
En los sistemas de recomendación tradicionales, los ingenieros deben construir manualmente una gran cantidad de señales: historial de clics del usuario, duración del tiempo de visualización, preferencias de usuarios similares, etiquetas del contenido, etc. Luego, le indican explícitamente al modelo "por favor, toma decisiones basándote en estas características". El modelo en sí mismo no entiende el significado semántico de estas señales, sino que simplemente aprende relaciones de mapeo en el espacio numérico.
Después de introducir modelos lingüísticos, este proceso se abstrae considerablemente. Ya no es necesario especificar uno por uno "mira esta señal, ignora esa señal", sino que puedes describir directamente al modelo el problema mismo: "este es un usuario, esta es una pieza de contenido; este usuario ha gustado contenido similar en el pasado, y otros usuarios también han dado retroalimentación positiva sobre este contenido—ahora, por favor, juzga si este contenido debería recomendarse a este usuario".
Los modelos de lenguaje en sí mismos ya poseen la capacidad de comprensión, pueden juzgar por sí mismos cuáles son las señales importantes y cómo sintetizar esas señales para tomar decisiones. En cierto sentido, no solo están ejecutando reglas de recomendación, sino que también "entienden la recomendación en sí".
El origen de esta capacidad radica en que los LLM han tenido contacto con grandes volúmenes de datos diversos durante la fase de entrenamiento, lo que les permite captar con mayor facilidad patrones sutiles pero importantes. En contraste, los sistemas de recomendación tradicionales deben depender de que los ingenieros enumeren explícitamente dichos patrones, y una vez que se omiten, el modelo no puede percibirlos.
Desde la perspectiva del backend, este tipo de cambio no es nada nuevo. Al igual que cuando haces una pregunta a GPT, que genera una respuesta basándose en el contexto; de manera similar, si le preguntas "¿me interesa este contenido?", también puede tomar una decisión basándose en la información existente. En cierto sentido, los modelos de lenguaje ya poseen de forma natural la capacidad de "recomendar".