










Imagina este escenario:
Le pediste a un agente de IA que te ayudara a arreglar un error en el código. Abrió el proyecto, leyó 20 archivos, hizo algunos cambios, ejecutó las pruebas, no pasaron, volvió a modificar, volvió a ejecutar, aún así no pasaron... Después de más de una docena de intentos, finalmente—todavía no lo arregló.
Apagaste la computadora y suspiraste aliviado. Luego recibiste la factura de la API.
Los números anteriores podrían dejarte sin aliento: en la API oficial externa, los agentes de IA que reparan errores de forma autónoma suelen gastar más de un millón de tokens por tarea no reparada, con costos que pueden oscilar entre diez y cien dólares.
En abril de 2026, un artículo de investigación publicado conjuntamente por Stanford, MIT, la Universidad de Michigan y otras instituciones abrió por primera vez de manera sistemática el "caja negra" del consumo en tareas de código por parte de los AI Agent: ¿dónde se gasta el dinero, si vale la pena y si se puede predecir con anticipación; las respuestas fueron sorprendentes.
Descubrimiento uno: La velocidad con la que el agente gasta dinero al escribir código es 1000 veces mayor que la de una conversación de IA común.
Quizás piensen que gastar dinero para que una IA escriba código por ustedes cuesta lo mismo que gastar para que una IA discuta código con ustedes.
El artículo presenta una comparación que muestra:
El consumo de tokens para la tarea de codificación agente es aproximadamente 1000 veces mayor que para tareas comunes de preguntas y respuestas de código o razonamiento de código.
Diferencia de tres órdenes de magnitud.
¿Por qué ocurre esto? El artículo señala un hecho: el dinero no se gasta en "escribir código", sino en "leer código".
Aquí, "leer" no se refiere a que los humanos lean el código, sino que el Agente, durante su funcionamiento, necesita alimentar constantemente al modelo con todo el contexto del proyecto, el historial de operaciones, la información de errores y el contenido de los archivos. Cada nueva ronda de conversación hace que este contexto se vuelva más largo; y el modelo se factura según el número de tokens: cuantos más le des, más tendrás que pagar.
Por ejemplo: es como contratar a un técnico que, antes de mover cada llave, exige que le leas desde el principio los planos de todo el edificio: el costo de leer los planos es mucho mayor que el de apretar los tornillos.
El papel resume este fenómeno en una sola frase: el costo del Agente es impulsado por el crecimiento exponencial de los tokens de entrada, no por los tokens de salida.
Descubrimiento dos: el mismo error, ejecutado dos veces, puede costar el doble, y cuanto más caro es el error, menos estable es.
Lo que es más frustrante es la aleatoriedad.
Los investigadores hicieron que el mismo agente ejecutara la misma tarea cuatro veces y descubrieron:
- Entre diferentes tareas, la tarea más costosa quema aproximadamente 7 millones de tokens más que la más económica (Figura 2a)
- En múltiples ejecuciones del mismo modelo y la misma tarea, la más cara fue aproximadamente el doble de la más barata (Figura 2b)
- Y si se compara el mismo task entre modelos, el consumo máximo y mínimo pueden diferir hasta 30 veces.
El último número es especialmente relevante: significa que la diferencia de costo entre elegir el modelo correcto y el incorrecto no es solo "un poco más caro", sino "un orden de magnitud más caro".
Lo que duele más es que gastar más no significa hacerlo mejor.
El estudio encontró una curva en forma de "U invertida":
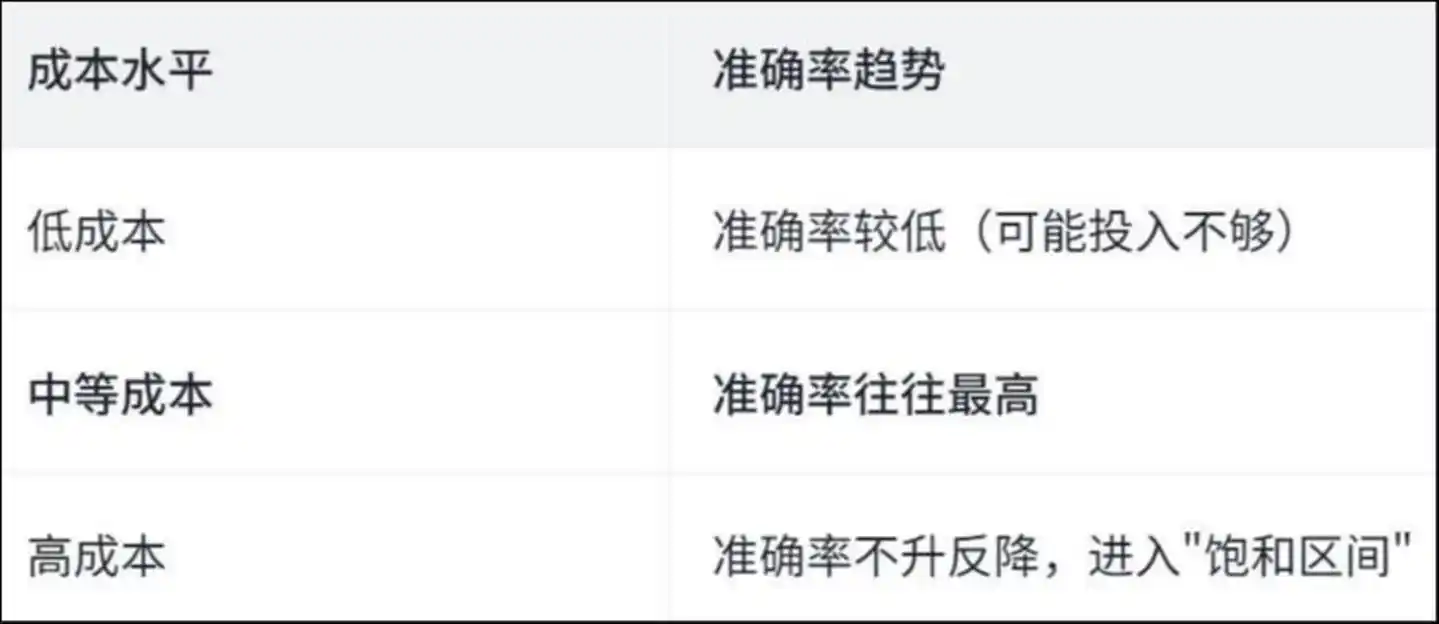
Tendencia de precisión de niveles de costo: bajo costo, precisión baja (posiblemente inversión insuficiente); costo medio, precisión generalmente más alta; alto costo, precisión no aumenta, sino que disminuye, entrando en la "zona de saturación"
¿Por qué sucede esto? El artículo proporciona la respuesta mediante el análisis de las operaciones específicas del Agente:
En un entorno de alto costo, los Agentes dedican gran parte de su tiempo a "tareas repetitivas".
Los estudios revelan que, en operaciones de alto costo, aproximadamente el 50% de las acciones de visualización y modificación de archivos son repetitivas: es decir, el agente lee una y otra vez el mismo archivo y modifica una y otra vez la misma línea de código, como una persona dando vueltas en una habitación, más vueltas se da, más se vuelve confundida, y más confundida está, más vueltas da.
El dinero no se gastó en resolver el problema, sino en perderse.
Descubrimiento tres: La eficiencia energética varía enormemente entre modelos: GPT-5 es el más eficiente, algunos modelos consumen hasta 1,5 millones de tokens más
Se evaluó el rendimiento de 8 modelos grandes de vanguardia en Agentes utilizando el estándar de la industria SWE-bench Verified (500 issues reales de GitHub). En términos de dólares, los modelos con mayor eficiencia de tokens pueden gastar decenas de dólares más por tarea. En aplicaciones empresariales, donde se ejecutan cientos de tareas al día, esta diferencia se traduce en dinero real.
Un descubrimiento aún más interesante es que la eficiencia del token es una "característica inherente" del modelo, no una consecuencia de la tarea.
Los investigadores separaron las tareas que todos los modelos resolvieron con éxito (230) y las tareas que todos los modelos fallaron (100) para compararlas, y descubrieron que el ranking relativo de los modelos casi no cambió.
Esto indica que algunos modelos son inherentemente “habladores”, independientemente de la dificultad de la tarea.
Otro hallazgo reflexivo: el modelo carece de "conciencia de stop loss".
Cuando se enfrenta a tareas difíciles que ningún modelo puede resolver, un agente ideal debería renunciar lo antes posible en lugar de seguir gastando dinero. Pero en la realidad, los modelos consumen más tokens en tareas fallidas: no "se rinden", sino que continúan explorando, reintentando y releyendo el contexto, como un automóvil sin luz de advertencia de combustible que sigue conduciendo hasta quedarse sin gasolina.
Descubrimiento cuatro: Lo que los humanos consideran difícil, el agente no necesariamente lo considera costoso: la percepción de la dificultad está completamente desalineada.
Podrías pensar: al menos puedo estimar el costo según la dificultad de la tarea, ¿verdad?
Se consultaron expertos humanos para calificar la dificultad de 500 tareas y luego se comparó con el consumo real de tokens del agente—
Resultado: Solo existe una correlación débil entre ambos.
En palabras sencillas: una tarea que los humanos encuentran extremadamente difícil puede ser resuelta fácilmente y sin mucho costo por un agente; en cambio, una tarea que los humanos consideran trivial puede hacer que un agente gaste una fortuna y se pregunte si está hecho para esto.
Porque la dificultad que ven las personas y la que ve la IA no es en absoluto lo mismo:
- Lo que ve el ser humano es: complejidad lógica, dificultad algorítmica, umbral de comprensión del negocio
- El agente observa: qué tan grande es el proyecto, cuántos archivos hay que leer, qué tan larga es la ruta de exploración y si se modificará repetidamente el mismo archivo.
Un error que un humano experto considera que se puede arreglar cambiando solo una línea puede requerir que el agente primero comprenda la estructura de todo el código para localizar esa línea; simplemente “leer” consume una gran cantidad de tokens. Por otro lado, un problema algorítmico que un humano encuentra confuso puede ser exactamente lo que el agente conoce como solución estándar, resolviéndolo rápidamente.
Esto lleva a una realidad incómoda: los desarrolladores casi no pueden predecir el costo de ejecución de un Agente por intuición.
Descubrimiento cinco: ni siquiera el modelo puede calcular con precisión cuánto le costará.
Si los humanos no pueden predecirlo, ¿por qué no dejar que la IA lo prediga por sí misma?
Los investigadores diseñaron un experimento ingenioso: hacer que el agente primero "inspecte" el repositorio de código antes de comenzar realmente a corregir el error, y luego estime cuántos tokens necesitará, sin ejecutar realmente la corrección.
How did it turn out?
Todos los modelos, derrotados por completo.
El mejor rendimiento fue el de Claude Sonnet-4.5, con una correlación de predicción de los tokens de salida de 0.39 (sobre un máximo de 1.0). La mayoría de los modelos tuvieron una correlación de predicción entre 0.05 y 0.34, siendo Gemini-3-Pro el más bajo, con solo 0.04: prácticamente equivalente a adivinar al azar.
Lo más sorprendente es que todos los modelos subestimaron sistemáticamente su consumo de tokens. En el gráfico de dispersión de la Figura 11, casi todos los puntos de datos se encuentran por debajo de la “línea de predicción perfecta”: los modelos creen que “no gastarán tanto”, pero en realidad gastan más. Además, este sesgo de subestimación es aún más pronunciado cuando no se proporcionan ejemplos.
Lo más irónico es que hacer la predicción también cuesta dinero.
El costo de las predicciones de Claude Sonnet-3.7 y Sonnet-4 puede superar incluso el doble del costo de la tarea en sí. Es decir, hacer que primero "hagan una estimación" cuesta más que realizar directamente el trabajo.
La conclusión del artículo es directa:
En esta etapa, los modelos avanzados no pueden predecir con precisión su propio consumo de tokens. Hacer clic en "Ejecutar Agente" es como abrir una caja sorpresa: hasta que llega la factura, no sabes cuánto gastaste.
Detrás de esta “cuenta confusa” se esconde un problema mayor de la industria
Al leer esto, es posible que te preguntes: ¿qué significan estos hallazgos para las empresas?
El modelo de precios de "suscripción mensual" está siendo fisurado por Agent
El artículo señala que los modelos de suscripción como ChatGPT Plus son viables porque el consumo de tokens en conversaciones normales es relativamente controlable y predecible. Sin embargo, las tareas de Agentes rompen por completo este supuesto: una sola tarea puede consumir una cantidad masiva de tokens si el agente entra en un bucle.
Esto significa que el modelo de precios por suscripción pura puede no ser sostenible para los escenarios de Agent, y el pago por uso (Pay-as-you-go) seguirá siendo la opción más realista durante un largo período. Pero el problema con el pago por uso es que el consumo en sí mismo es impredecible.
2. La eficiencia del token debe convertirse en el "tercer indicador" para seleccionar modelos
Tradicionalmente, las empresas evalúan modelos en dos dimensiones: capacidad (si pueden hacerlo) y velocidad (lo rápido que lo hacen). Este artículo presenta una tercera dimensión igualmente importante: eficiencia energética (cuánto se necesita gastar para lograrlo).
Un modelo ligeramente menos potente pero 3 veces más eficiente puede tener mayor valor económico en escenarios de escalabilidad que un modelo "más fuerte pero más costoso".
3. El agente necesita el "indicador de combustible" y el "freno"
El artículo menciona una dirección futura digna de atención: políticas de uso de herramientas conscientes del presupuesto. En términos sencillos, significa equipar al agente con un "indicador de combustible": cuando el consumo de tokens se acerque al presupuesto, se le obliga a detener la exploración ineficaz en lugar de seguir gastando hasta agotar los recursos.
Actualmente, casi todos los marcos de Agent principales carecen de este mecanismo.
El "problema de gasto de dinero" del agente no es un error, sino un dolor inevitable de la industria
El artículo revela no un defecto de un modelo en particular, sino un desafío estructural de todo el paradigma de Agentes: cuando la IA evoluciona de “una pregunta, una respuesta” a “planificación autónoma, ejecución en múltiples pasos y depuración repetida”, la imprevisibilidad del consumo de tokens es casi inevitable.
La buena noticia es que, por primera vez, alguien ha sistematizado y analizado este lío financiero. Con estos datos, los desarrolladores pueden elegir modelos, establecer presupuestos y diseñar mecanismos de stop-loss de manera más informada; los fabricantes de modelos también tienen una nueva dirección de optimización: no solo hacerlos más potentes, sino también más eficientes.
Después de todo, antes de que los agentes de IA ingresen realmente a los entornos de producción de múltiples industrias, gastar cada yuan de manera inteligente es más importante que escribir cada línea de código de manera elegante. (Este artículo se publicó originalmente en la app Titanium Media, autor | Silicon Valley Tech News, editor | Zhao Hongyu)
Nota: Este artículo se basa en el artículo preimpreso publicado en arXiv el 24 de abril de 2026, titulado *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei). Los autores pertenecen a instituciones como la Universidad de Virginia, Stanford, MIT, la Universidad de Michigan, entre otras. Esta investigación aún no ha sido sometida a revisión por pares.