









El modelo es el cerebro de OpenClaw y afecta directamente el rendimiento.
Autor del artículo: Zhang Haining
Fuente del texto: Notas de Henry
Recientemente he probado varias formas de instalar y desplegar OpenClaw: servidores físicos, servidores en la nube, máquinas virtuales, contenedores, modelos nacionales e internacionales, redes, etc. En general, es bastante complejo y requiere considerar muchos factores. Planeo escribir un artículo de síntesis. Este sirve como preludio, y primero hablaré sobre un aspecto muy importante: la elección del modelo.
El modelo es el cerebro de OpenClaw y afecta directamente el rendimiento. Actualmente, se consensua que los modelos extranjeros son ligeramente más inteligentes que los nacionales, pero requieren acceso a Internet con herramientas de circumventación, tienen un costo más elevado y necesitan métodos de pago extranjeros; un pequeño error puede llevar al bloqueo de la cuenta. Aunque existen estaciones de transbordo que ofrecen servicios más económicos, al pertenecer a un sector gris, presentan factores de incertidumbre. Por lo tanto, los usuarios que buscan estabilidad en el servicio suelen optar por modelos nacionales.
Este artículo compara el uso y los precios de diversos modelos en el país, y ofrece algunas recomendaciones para referencia.
Después de que OpenClaw, el marco de agentes de IA de código abierto, se volvió extremadamente popular en el país, generó una revolución en la productividad, pero también facturas impactantes.
El modo de funcionamiento de OpenClaw es completamente distinto al de las IA conversacionales tradicionales en navegadores o aplicaciones. Tras recibir una instrucción del usuario, la herramienta activa de forma autónoma decenas e incluso cientos de llamadas al modelo, lee archivos, genera código y realiza depuración y ejecución, consumiendo Token durante todo el proceso.
Una tarea de desarrollo full-stack de complejidad media, con llamadas al modelo que podrían oscilar entre 10 y 40 rondas; si se utiliza el modelo insignia que admite 200K de contexto, el costo por tarea alcanza fácilmente decenas de yuanes.
📊 Cálculo del costo real
Como ejemplo de una tarea de complejidad media: OpenClaw inicia aproximadamente 30 rondas de conversación, con una entrada promedio de 20,000 tokens por ronda y una salida de 2,000 tokens por ronda, utilizando un modelo principal (aproximadamente 0.005 yuanes por mil tokens de entrada, 0.02 yuanes por mil tokens de salida):
Costo por tarea única ≈ 30 × (20.000 × 0,005 ÷ 1000 + 2.000 × 0,02 ÷ 1000) = 30 × (0,1 + 0,04) = 4,2 yuanes
Los desarrolladores intensivos completan entre 5 y 10 tareas diarias, con un costo mensual de entre 630 y 1,260 yuanes. Esta estimación se basa en el uso de modelos de gama media; si se eligen modelos de gama alta, los costos se duplicarán.
En este contexto, los principales proveedores de nube y empresas de modelos grandes del país entraron de forma intensa entre finales de 2025 y marzo de 2026, lanzando paquetes de suscripción "Coding Plan" que reemplazan el cobro por Token por una tarifa fija mensual. El punto de partida de esta guerra de precios fue el GLM Coding Plan lanzado por Zhipu AI a finales de 2025, seguido por el ingreso agresivo de Alibaba Cloud Bailian con una entrada extremadamente baja de "7.9 yuanes el primer mes", y Tencent Cloud completó la última pieza del rompecabezas el 5 de marzo de 2026.
Este artículo proporcionará un análisis sistemático de los planes de codificación de las seis principales plataformas nacionales, comparando dos líneas principales: proveedores de nube (Alibaba Cloud Bailian, Volcano Engine de ByteDance, Tencent Cloud) y fabricantes de modelos (Zhipu GLM, Kimi de Moonshot AI, MiniMax), para ofrecer una referencia a los usuarios de OpenClaw.
OpenClaw necesita comprar el Coding Plan. Sí, exactamente el mismo modelo de uso que los programadores aplican con IDEs como Cursor, Trae, etc., porque OpenClaw y Cursor son esencialmente agentes inteligentes. Si no compras el Coding Plan (en el extranjero comúnmente llamado API), tu dinero solo se podrá usar para acceder a modelos grandes a través del navegador.
(Los modelos extranjeros no se discuten en este artículo)
Proveedor de nube
Tres grandes proveedores de nube: la competencia en la tienda de modelos
La lógica central de la estrategia de los proveedores de nube es "agregar plataformas": empaquetar múltiples modelos de lenguaje abiertos como Qwen, GLM, Kimi y MiniMax en un mismo paquete, permitiendo a los desarrolladores cambiar libremente entre ellos con una sola clave de API, sin necesidad de recargar en varias plataformas por separado. Estos paquetes se miden en "solicitudes por unidad", no en Prompts (indicaciones), lo que en números parece mayor, pero debe considerarse junto con la conversión real.
Los tres proveedores de nube tienen los siguientes detalles:



Fabricantes de modelos grandes
Tres grandes proveedores de modelos: la elección especializada en profundidad
A diferencia de la "tienda de modelos" de los proveedores de nube, el plan de Coding de los fabricantes de modelos sigue un enfoque de "tienda especializada": solo ofrece sus propios modelos, pero con optimizaciones profundas y un diseño más refinado de las capacidades y los límites del modelo. Estos paquetes suelen utilizar "Prompts" como unidad de medición, donde 1 Prompt ≈ 15 llamadas al modelo (según el cálculo de MiniMax), por lo que los números parecen mucho más pequeños, pero cada uno soporta una mayor cantidad de conversaciones.



Tabla de comparación de datos clave de cada plataforma
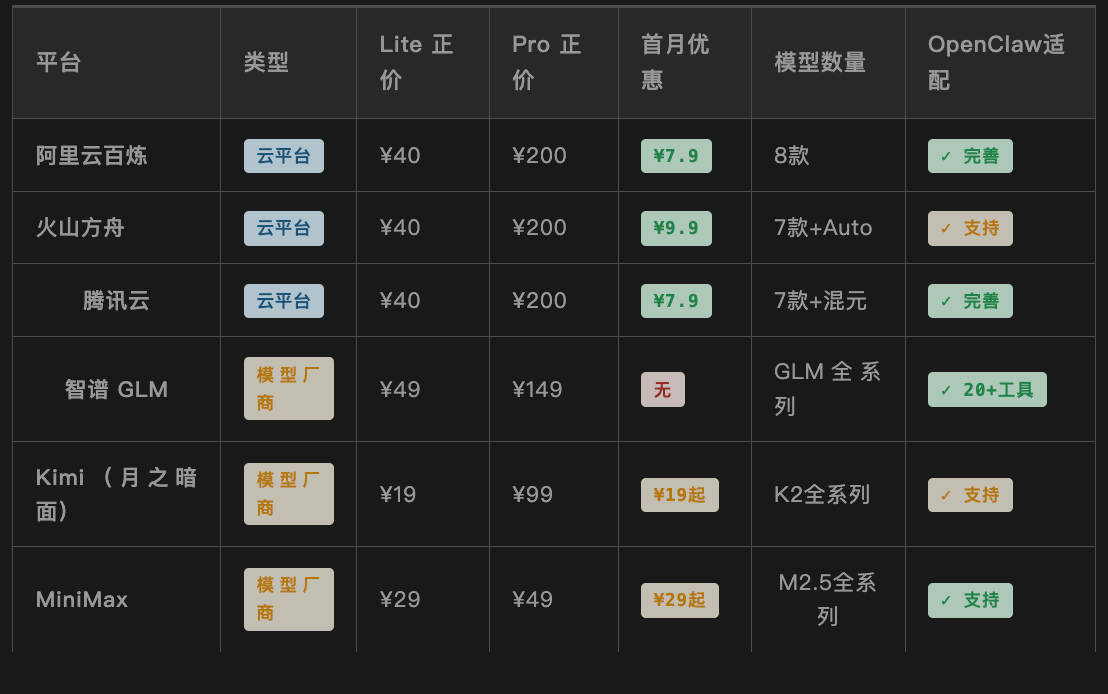
Nota: Los precios se basan en el precio oficial de marzo de 2026. El descuento del primer mes es exclusivo para nuevos usuarios; consulte la página de pedido para detalles. La calificación de compatibilidad de OpenClaw se basa en la completitud de la documentación oficial y el feedback de la comunidad.
Guía para evitar trampas
Desglose de la forma de facturación: la verdad detrás de los números
El mayor obstáculo de información en el mercado radica en que cada plataforma utiliza unidades de medición completamente diferentes, por lo que comparar números directamente carece de sentido. Esta sección revisa los tres puntos clave de facturación para ayudarte a tomar una decisión realista antes de comprar.
1. Las unidades de medida no son consistentes
Actualmente coexisten dos sistemas en el mercado: los proveedores de nube (Alibaba Cloud, Volcano, Tencent) miden en "solicitudes por segundo"; los proveedores de modelos (Zhipu, MiniMax) miden en "Prompts". La relación de conversión clave es: 1 Prompt ≈ 15 llamadas al modelo.
La facturación se realiza por ronda de interacción iniciada por el usuario: una pregunta, independientemente de cuántas veces se llame al modelo en segundo plano, solo consume una unidad. El modelo de facturación por cantidad es el tradicional de proveedores de nube, que se basa en el número de llamadas a la API; si una pregunta del usuario desencadena múltiples llamadas al modelo, se cobran múltiples cargos. El primero es más favorable para agentes como OpenClaw, que realizan llamadas frecuentes en segundo plano, ya que permite predecir los costos; el segundo cobra estrictamente según el número real de solicitudes, lo que puede generar facturas inesperadas debido a llamadas internas.
Ambos métodos son adecuados para los usuarios ocasionales de OpenClaw, ya que no se cuentan los tokens, sino solo las veces, y hay un límite mensual, lo que elimina la ansiedad relacionada con los tokens.
2. Ejemplos de conversión
El plan Pro de Alibaba Cloud BAILIAN ofrece 90,000 solicitudes mensuales, equivalentes a aproximadamente 6,000 prompts.
El paquete智谱 GLM Lite ofrece aproximadamente 120 prompts cada 5 horas, lo que equivale a aproximadamente 1,800 solicitudes.
Por lo tanto, "90,000" y "120" no son números directamente comparables.
3. La ventana deslizante / 5 horas es el verdadero cuello de botella
Casi todas las plataformas imponen un límite de "5 horas por período", y este número es el indicador clave que determina si puedes desarrollar de forma continua e intensiva, no el límite total mensual. La ventana de 5 horas sigue un mecanismo de recuperación deslizante (no un período natural fijo): si comienzas a usarlo a las 14:00 y agotas el límite a las 15:00, deberás esperar hasta las 19:00 para que se restablezca el primer lote de cuota. Es muy fácil alcanzar el límite durante las horas pico de la tarde, al desarrollar de forma continua durante 2 a 3 horas.
4. Reglas ocultas de reducción de peso de智谱 GLM-5
El plan de codificación de智谱 GLM tiene una regla exclusiva: durante las horas pico (UTC+8 14:00~18:00), el número real de usos disponibles de GLM-5 es solo 1/3 del número disponible fuera de las horas pico. Actualmente, ninguna otra plataforma tiene esta regla; por lo tanto, presta especial atención a tus horarios principales de uso al realizar la compra.
5. No se admiten reembolsos ni cancelaciones
Todos los servicios anteriores especifican claramente que no se admiten reembolsos ni cancelaciones tras la suscripción; asegúrese de confirmar sus necesidades antes de comprar. Se recomienda a los nuevos usuarios que prueben primero el plan de bajo costo del primer mes y no adquieran el plan anual de una sola vez.
Guía de compras exclusiva para usuarios de OpenClaw
OpenClaw, como un marco de agente autónomo, tiene requisitos especiales superiores a los de un plugin de IDE común para el Plan de Codificación: tolerancia a llamadas de alta concurrencia, capacidad estable de procesamiento de contexto prolongado y compatibilidad nativa con el protocolo de Anthropic (ya que OpenClaw está diseñado sobre la base del protocolo Claude). A continuación se proporcionan recomendaciones específicas clasificadas por escenario de uso.
🌱 Tipo de prueba para principiantes
Recomendado: Alibaba Cloud BAILIAN Lite primer mes por ¥7.9 (ya no disponible) o Tencent Cloud primer mes por 7.9 yuanes
Primera vez que usas Coding Plan y quieres experimentar el proceso completo de OpenClaw con el menor costo posible. La diversidad de modelos de Bailian (8 modelos) te permite experimentar horizontalmente Qwen, GLM-5 y Kimi en un solo paquete, ayudándote a establecer rápidamente un juicio intuitivo. Actualmente, Alibaba Cloud solo ofrece el paquete Pro de 200 yuanes/mes, mientras que Tencent Cloud aún tiene paquetes Lite de 7.9 yuanes y 40 yuanes; sin embargo, los usuarios reales indican que la disponibilidad se agota en segundos, por lo que probablemente solo el paquete de 200 yuanes/mes sea más fácil de obtener.
💼 Desarrollador diario
Recomendado: MiniMax Plus ¥49/mes
Tiene tareas de programación fijas diarias, pero no requiere uso continuo e intensivo. El plan Starter de MiniMax, con su respuesta ultrarrápida (101 tokens/s) y sin límite semanal, es el más adecuado para un ritmo de desarrollo fragmentado pero frecuente.
⚡Tipo continuo intensivo
Recomendado: Tencent Cloud o Alibaba Cloud Pro ¥200/mes
Desarrollo continuo de más de 6 horas diarias, requiriendo el manejo de grandes bases de código y flujos de trabajo de Agent complejos. El límite mensual de 90,000 solicitudes y 6,000 solicitudes por ventana de 5 horas de Tencent/Bailian Pro ofrece la mejor combinación de relación costo-rendimiento y estabilidad en plataformas en la nube.
🎨 Frontend / multimodal
Recomendado: Kimi Moderato ¥99/mes
Se necesita con frecuencia ingresar capturas de pantalla de diseños y bocetos de UI a la IA para analizarlos y generar código. Kimi-K2.5 es el único paquete original en el mercado de Coding Plan que admite entrada multimodal por captura de pantalla, ideal para escenarios de frontend y Vibe Coding.
🔬 Ingeniería compleja
Recomendado: ZhiPu GLM Pro ¥149/mes
Escenarios que requieren capacidades de modelos de primer nivel, como el procesamiento de proyectos monolíticos grandes, la programación compleja de agentes y las pruebas automatizadas de alta concurrencia. La escala de 754 mil millones de parámetros de GLM-5 es la más grande entre los modelos de código abierto en China, con capacidad de código cercana a Claude Opus, y los costos a largo plazo pueden reducirse aún más con un paquete anual al 30 % de descuento.
Resumen
Estrategia de compra
El mercado nacional de Coding Plan para 2026 ha entrado en una fase de competencia intensa. Los beneficiarios directos de la guerra de precios son los desarrolladores y los usuarios: por menos de 10 yuanes en el primer mes, puedes probar múltiples modelos de primera línea, algo que era impensable hace un año.
Sin embargo, la reducción del umbral del paquete no significa que la dificultad de elección disminuya: las diferencias en las unidades de medida, las reglas ocultas de límites y la tendencia al aumento de precios son variables que deben considerarse cuidadosamente.
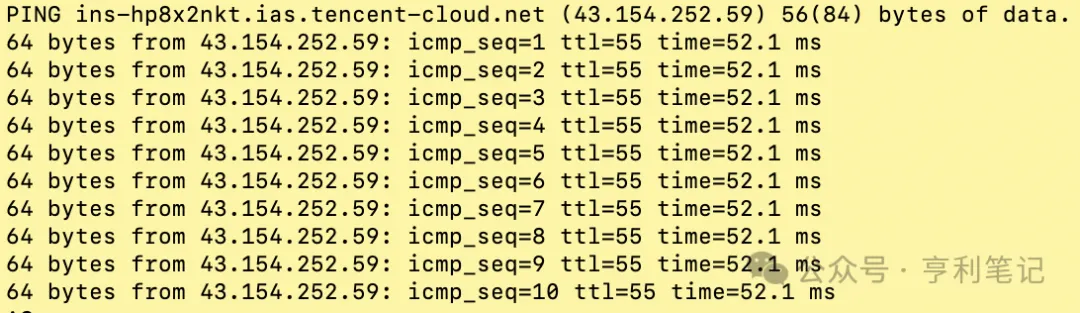
También es importante verificar qué servicio de modelo grande tiene menor latencia desde la máquina de OpenClaw. El método más sencillo es usar el comando ping en la máquina de OpenClaw para verificar la latencia de red y la tasa de pérdida de paquetes.
Por ejemplo, esto es para verificar la red entre el host OpenClaw y los puntos de conexión de Tencent Cloud; preste atención a si hay pérdida de paquetes en icmp_seq y si la latencia time es baja:
$ ping api.lkeap.cloud.tencent.com
Según el análisis anterior, resumimos lo siguiente:

📌 Última sugerencia
Los datos de este artículo están actualizados hasta finales de marzo de 2026. Dado que las políticas de precios de las plataformas se ajustan con frecuencia (por ejemplo, Zhipu ya ha aumentado sus precios y Alibaba Cloud Bailian Lite ha dejado de ofrecer nuevas compras), asegúrese de verificar siempre las últimas notificaciones oficiales de cada plataforma antes de realizar una compra. Los paquetes no son reembolsables; se recomienda comenzar con el paquete de precio reducido del primer mes para validar la compatibilidad de las herramientas y sus hábitos de uso antes de planificar a largo plazo.
La próxima vez, hablaremos sobre los diversos puntos de equilibrio a tener en cuenta al implementar OpenClaw.