
¿Quieres saber qué modelo grande es realmente el más fuerte en las tareas de agentes del mundo real de OpenClaw?
MyToken, basado en la recopilación de sitios de evaluación, ha desarrollado un conjunto de benchmarks transparentes enfocados exclusivamente en medir la capacidad práctica de los agentes de codificación de IA, considerando únicamente la tasa de éxito como dimensión central (la velocidad y el costo son dimensiones independientes que se analizarán por separado en el futuro). Totalmente abierto y reproducible, presenta únicamente estándares de evaluación rigurosos y el ranking actualizado de los 10 mejores en tasa de éxito.
I. Dimensiones de evaluación: Tasa de éxito
Criterio específico: Porcentaje de tareas completadas de forma completa y precisa por los agentes de IA. Cada tarea sigue un proceso altamente estandarizado:
Prompt de usuario preciso
Enviar al agente completo para simular un escenario de solicitud de usuario real
Comportamiento esperado
Se indican las formas aceptables de implementación y los puntos clave de decisión
Criterios de evaluación (lista de verificación)
Listar lista de verificación atomizada de éxito verificable punto por punto
II. Tres métodos de calificación
Esta evaluación utiliza principalmente tres métodos de calificación.
Verificación automatizada: El script de Python verifica directamente el contenido del archivo, los registros de ejecución, las llamadas a herramientas y otros resultados objetivos.
Juez de modelos LLM grandes: Claude Opus califica según una escala detallada (calidad del contenido, adecuación, integridad, etc.)
Modo híbrido: combinación de verificación objetiva automatizada y evaluación cualitativa con LLM como árbitro
Todas las definiciones de tareas, prompts y lógicas de evaluación se publican para permitir la verificación y repetición de pruebas.
Tres: Tareas para evaluación
Esta prueba de referencia abarca 23 categorías diferentes de tareas, cubriendo múltiples dimensiones como interacciones básicas, operaciones con archivos/código, creación de contenido, análisis de investigación, llamadas a herramientas del sistema y persistencia de memoria, acercándose altamente a los escenarios diarios de uso de OpenClaw por parte de los desarrolladores:
Verificación de cordura (automatizada): procesar instrucciones simples y responder correctamente los saludos
Creación de evento de calendario (automatización): generación de archivos de calendario ICS en lenguaje natural
Investigación de precios de acciones (automatizada): consulta en tiempo real y generación de informes formateados
Blog Post Writing (LLM Judge) — Write a structured Markdown blog post of approximately 500 words
Creación de script meteorológico (automatización): escribir un script de API meteorológica en Python con manejo de errores
Resumen de documentos (juez LLM): resumen conciso en tres párrafos del tema central
Investigación de conferencias tecnológicas (juez de LLM): recopilación de información de 5 conferencias tecnológicas reales (nombre, fecha, ubicación, enlace)
Redacción de correo profesional (juez LLM): rechazar educadamente la reunión y proponer una alternativa
Recuperación de memoria desde el contexto (automatizada): extracción precisa de fechas, miembros, pila tecnológica, etc., desde las notas del proyecto
Creación de estructura de archivos (automatización): generación automática de directorios de proyecto estándar, README y .gitignore
Flujo de trabajo de API de varios pasos (híbrido): leer la configuración → escribir el script de llamada → documentación completa
Instalar la habilidad ClawdHub (automatización): instale y verifique la disponibilidad desde el repositorio de habilidades
Buscar e instalar habilidad (automatización): buscar habilidades relacionadas con el clima e instalarlas correctamente
Generación de imágenes de IA (híbrida): genera y guarda imágenes según la descripción
Humaniza el blog generado por IA (juez de LLM): convierte el contenido con sabor a máquina en un lenguaje natural y coloquial
Resumen diario de investigación (juez LLM): síntesis coherente diaria a partir de múltiples documentos
Clasificación de la bandeja de entrada por correo electrónico (híbrida): analice múltiples correos electrónicos y genere un informe organizado por prioridad
Búsqueda y resumen de correos electrónicos (híbrido): buscar correos archivados y extraer información clave
Investigación de mercado competitiva (híbrida): análisis de competidores en el ámbito de APM empresarial
Resumen CSV y Excel (mixto): analice archivos de tabla y genere insights
Resumen en PDF ELI5 (Árbitro de LLM): Explica PDF técnicos con palabras que un niño de 5 años pueda entender
Comprensión del informe OpenClaw (automatización): responder preguntas específicas con precisión a partir de PDFs de informes de investigación
Persistencia de conocimiento de Second Brain (híbrida): almacenamiento entre sesiones y recuerdo preciso de la información
Cuatro: Conclusión principal: Clasificación de los 10 mejores modelos por tasa de éxito (% éxitos / % promedio)
Los datos se actualizan al 7 de abril de 2026
El % mejor es la tasa de éxito más alta en un solo intento; el % promedio es la tasa de éxito promedio en múltiples intentos y refleja mejor la estabilidad.
Aquí están los diez modelos con mayor tasa de éxito
anthropic/claude-opus-4.6 (Anthropic) —— 93.3% / 82.0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91,9 % / 91,9 %
openai/gpt-5.4 (OpenAI) —— 90.5% / 81.7%
qwen/qwen3.5-27b (Qwen) —— 90.0% / 78.5%
minimax/minimax-m2.7 (MiniMax) — 89.8% / 83.2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89.5% / 78.1%
qwen/qwen3.5-397b-a17b (Qwen) — 89.1% / 80.4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88.8% / 70.2%
qwen/qwen3.6-plus-preview (Qwen) — 88.6% / 84.0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88.6% / 75.5%
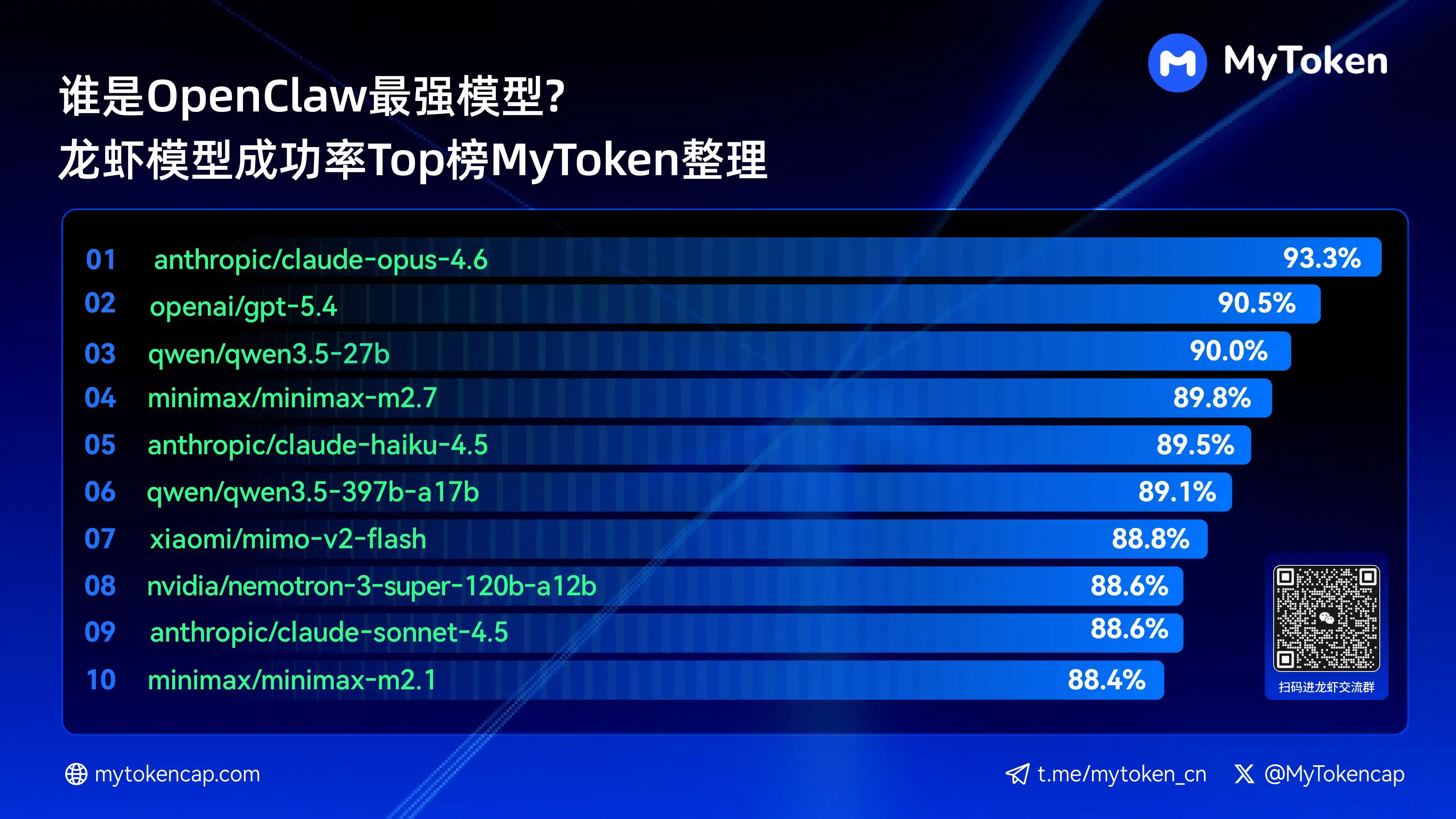
Claude Opus 4.6 lidera con una tasa de éxito máxima del 93.3%, pero Trinity de Arcee destaca en estabilidad promedio, y varias modelos de la serie Qwen también figuran entre los diez primeros, mostrando un gran potencial de relación calidad-precio. La tasa de éxito es el umbral básico; la velocidad y el costo influirán posteriormente en la experiencia real.
Esta benchmark de 23 tareas es completamente transparente; se recomienda encarecidamente que todos la prueben según su escenario real. Para más rankings de otros modelos, estén atentos a la próxima función de ranking de agentes de MyToken.
(Los datos provienen de la prueba de referencia OpenClaw publicada por PinchBench, en actualización continua.)