










Autor: Max, siempre en camino, 01Founder
Si se tuviera que hacer un resumen intermedio para OpenAI en 2025, muchas personas probablemente lo describirían como plano e incluso ligeramente pasivo.
Durante los últimos años, han seguido sistemáticamente el camino de razonamiento lógico, lanzando densamente modelos de inferencia desde o3pro hasta o4mini, y también han presentado nuevos modelos base como GPT-4.5 y GPT-5.
Pero en el ámbito de la generación visual, donde los usuarios comunes más lo perciben y donde más fácilmente se genera propagación espontánea, su presencia va disminuyendo.
Tras el impacto inicial de Sora, OpenAI parece haber entrado en un largo período de silencio en este sector.
Mientras tanto, los otros jugadores en la mesa no se quedaron de brazos cruzados.
En el ecosistema de código abierto, modelos como Flux han eliminado por completo las barreras para generar imágenes locales de alta calidad;
En el ámbito comercial, no solo existen rivales establecidos que mantienen barreras estéticas extremas, sino que también han surgido nuevos competidores como Nano-banana, que cuentan con funciones de búsqueda en línea integradas.
En comparación, el anterior modelo principal de generación de imágenes de OpenAI, GPT-Image-1.5, ya parece anticuado:
Además de tener una calidad de imagen pobre y un diseño rígido, a menudo se bloquea al enfrentarse a textos complejos.
Poco a poco, la industria ha llegado a un consenso:
OpenAI ha enfrentado una barrera técnica en la generación visual y, bajo la presión de diversos competidores, ya parece estar al límite.
Hasta unas pocas semanas atrás, el punto de inflexión apareció de una manera muy sutil.
En la plataforma ciega de modelos grandes conocida como LM Arena, se introdujo silenciosamente un misterioso modelo de imágenes con el código Duct Tape.
Los usuarios que participaron en la prueba ciega pronto notaron que algo no estaba bien:
Este modelo no solo controla con extrema precisión los formatos extremos, sino que también genera sin imperfecciones carteles tipográficos con gran cantidad de texto en múltiples idiomas, e incluso parece haber un proceso de planificación lógica invisible antes de generar la imagen.
Durante un tiempo, diversas comunidades técnicas especularon sobre qué empresa había lanzado en secreto esta gran novedad, pero OpenAI mantuvo silencio.
Esta madrugada, finalmente se ha cumplido.
Sin largos lanzamientos ni campañas de marketing masivas, OpenAI ha nombrado oficialmente el modelo codificado como "cinta" ChatGPT GPT-Image-2 y lo ha lanzado plenamente al mercado.
Acompañando esto, se publicó una tabla de clasificación del campo de batalla Text-to-Image que resulta algo asfixiante.
GPT-Image-2 obtuvo una puntuación récord de 1512 y se ubicó directamente en el primer lugar, liderando al segundo lugar (el Nano-banana-2 con función de búsqueda en línea) por 242 puntos.
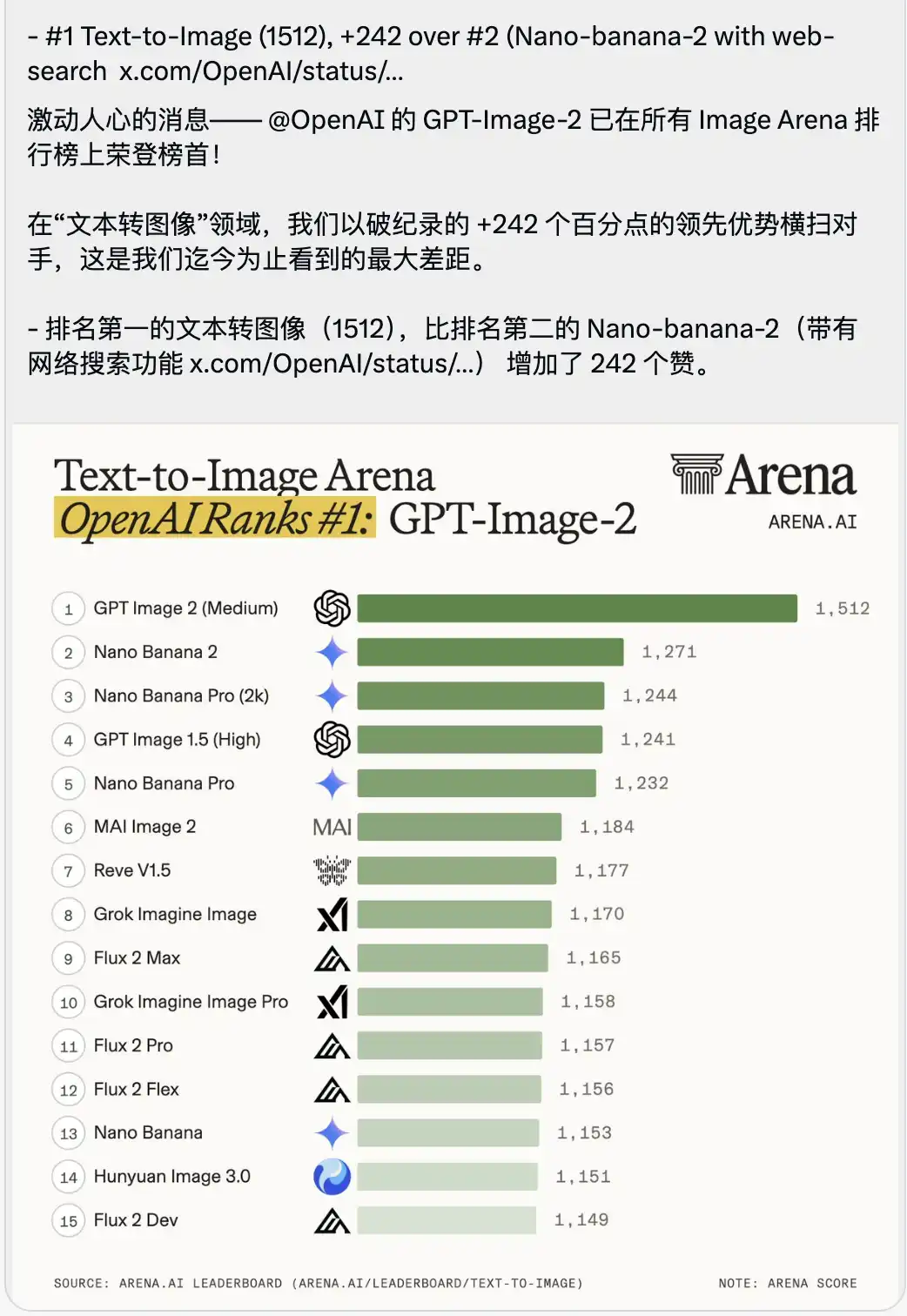
En el contexto de las pruebas de modelos grandes, las personas suelen destacar enormemente las ventajas de décimas o unidades, ya que los puntajes entre los modelos líderes están extremadamente ajustados.
Una ventaja de 242 puntos es sin precedentes en la historia del arena.
Esto no es simplemente una pequeña actualización de versión, es una abrumadora superioridad generacional.
Pasé gran parte del día revisando detenidamente sus diversas capacidades límite y la documentación más reciente de la API.
La sensación más grande es solo una:
OpenAI sigue siendo el mismo OpenAI.
Cuando decidió recuperar lo perdido, lo hizo volcando directamente la mesa anterior.
Ante este modelo, los trabajos de diseño visual que creíamos que aún necesitaban dos o tres años para ser reemplazados completamente por la IA, hoy en día prácticamente han llegado a su fin.
PART.01 Generación de imágenes, del modelo al agente visual
Para entender por qué GPT-Image-2 logra una diferencia tan extrema en los puntajes, primero debes descartar las percepciones tradicionales sobre los modelos de texto a imagen.
Antes, al usar IA para generar imágenes, era esencialmente abrir una caja sorpresa: introducías algunas palabras clave y esperabas que organizara los píxeles según lo que deseabas.
Pero GPT-Image-2 es más como un agente con un motor visual integrado.
El cambio más obvio es que, en su mecanismo, distingue directamente dos modos completamente diferentes.
Uno es el modo instantáneo (Instant Mode), disponible para todos los usuarios.
Este modelo se centra en una respuesta ultrarrápida y en la integración sin interrupciones con flujos de trabajo y vida diaria.
Por ejemplo, si le envías una instrucción desde tu teléfono, en cuestión de segundos te generará una imagen con una estructura completa.
Su capacidad subyacente de comprensión visual es muy fuerte, pero principalmente aborda necesidades de conversión visual frecuentes y únicas.
Y el modo de pensamiento (Thinking Mode) disponible para usuarios de pago.
Antes de comenzar a renderizar siquiera un píxel, entrará en un proceso de razonamiento lógico y búsqueda en línea que dura más de diez segundos.
Justo este patrón resuelve una proposición extremadamente central pero también extremadamente difícil:
El modelo supo por primera vez qué dibujar.
Por ejemplo, el caso más directo.
Escribe en el cuadro de diálogo:
Haz un cartel; busca en línea las opiniones sobre el misterioso modelo Duct Tape y incluye el código QR de ChatGPT.

Con el modelo anterior, simplemente no sabía lo que decía el usuario en línea y solo te generaba un cartel con caracteres aleatorios y un código QR falso que no se podía escanear.
Pero en modo pensamiento, su flujo de trabajo es así:
Primero pausará el dibujo, iniciará una herramienta de búsqueda en línea para rastrear las reseñas reales de los usuarios en Reddit, Threads o LinkedIn;
Luego, comenzó a planificar el diseño del cartel, los espacios en blanco y la jerarquía tipográfica;
Finalmente, genera un código QR real y funcional que se puede escanear para redirigir directamente, y renderiza la imagen completa.

Esto ya no es solo dibujar, sino que realmente implica realizar de forma autónoma toda la tarea: investigación, planificación, extracción de textos y diseño de maquetas.
Aquí se necesita hacer una comparación paralela.
Todos los que siguen el círculo de modelos grandes saben que los modelos de generación de imágenes con capacidad de conexión y búsqueda no fueron creados por primera vez por OpenAI.
El Nano-banana en segundo lugar en el ranking ya tenía este mecanismo.
Pero al usar Nano-banana en la práctica, descubrirás que parece un poco torpe en muchos lugares.
Los pensamientos de Nano-banana suelen ser una lógica mecánica de ensamblaje.
Por ejemplo, si le pides que busque una tendencia de la industria para hacer un cartel, realmente lo busca, pero generalmente solo copia frases rígidas de Wikipedia y las pega forzosamente en la imagen.
Cuando se enfrenta a instrucciones que requieren interpretar demandas comerciales abstractas, fácilmente se bloquea.

Esa sensación es como la de un pasante que entiende lo que se le dice, pero no tiene ninguna experiencia laboral; entiende cómo ejecutar, pero no entiende la estrategia en absoluto.
Pero el rendimiento de GPT-Image-2 en este aspecto solo se puede describir como exagerado.
Su reflexión no es un mero trámite, sino una comprensión genuina del contexto cultural y las intenciones comerciales detrás de ello.
During testing, I entered a minimal Chinese instruction: Help me take a screenshot of Musk live-streaming on TikTok to sell Doubao.
Si se usara un modelo de generación de imágenes anterior, probablemente te mostraría a un hombre blanco que se parece a Musk sosteniendo un baozi, con un fondo borroso e incluso sin saber cómo luce TikTok.
Pero en modo pensamiento, los resultados de GPT-Image-2 son algo perturbadores.
No simplemente ensambló elementos, sino que invocó de forma autónoma su comprensión de Internet en China para generar una captura de pantalla de la interfaz de usuario de un directo en Douyin, réplica exacta hasta el píxel.
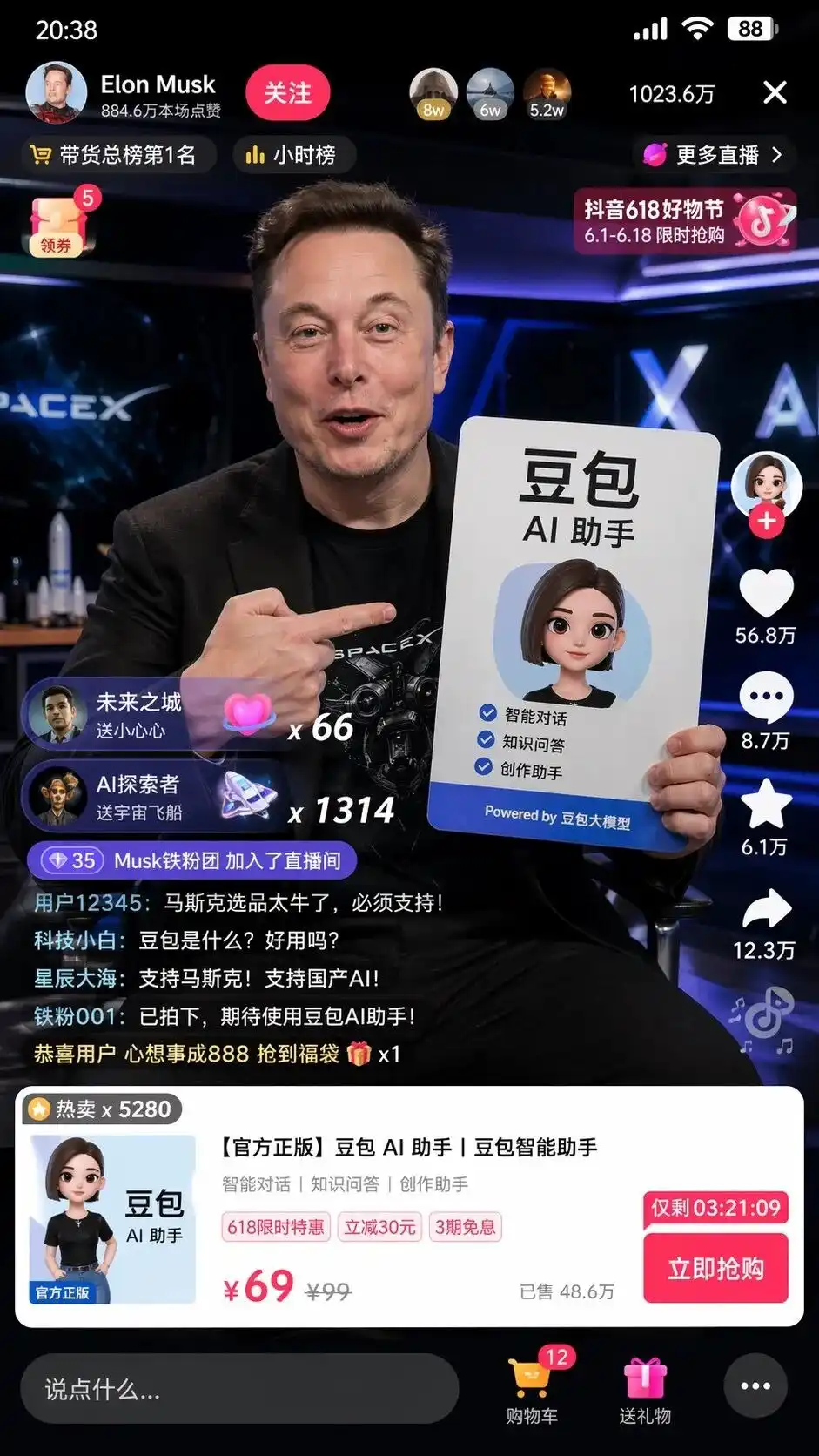
En la pantalla no solo hay un Musk realista sosteniendo un cartel publicitario del asistente de IA DouBao con una tipografía perfecta, sino también detalles aún más aterradores que no aparecían en el prompt:
El botón de seguimiento en la esquina superior izquierda, la lista de las horas, la cantidad de 10,236,000 usuarios en línea en la esquina superior derecha, la tarjeta de producto emergente en la parte inferior, e incluso se indica el precio tachado de 99, el precio especial de 69 y el botón de compra inmediata con contador regresivo.
Lo que más da escalofríos es el comentario en tiempo real de los usuarios en la esquina inferior izquierda, extremadamente realista:
Novato en tecnología: ¿Qué es Doubao? ¿Es fácil de usar?
Estrellas y mares: ¡Apoyemos a Musk! ¡Apoyemos la IA nacional!
Nadie le dijo qué escribir en los comentarios, cómo debería verse la interfaz de producto o cómo fijar el precio.
Esto es el diseño de interfaz de usuario y la estrategia de operación completos que el modelo generó y ejecutó en nombre de los humanos, tras analizar las etiquetas de ventas en Douyin y el gran modelo DouBao.
En este momento, los criterios de evaluación de los modelos grandes en la generación de imágenes han trascendido simplemente si pueden dibujar algo atractivo, para abarcar si comprenden la estrategia y la lógica de composición.
PART.02 Prueba real de las capacidades clave
Para probar sus límites, probé varios escenarios frecuentes y complejos según los estándares de diseño comercial.
Resultó que el nivel de detalle con el que resuelve los problemas es tan fino que resulta aterrador.
Primer escenario: Comprensión visual y ciclo de negocio (vestir al modelo)
En la visualización tradicional de comercio electrónico o planificación de moda, el costo de ejecución entre tener una idea y ver el efecto final vestido es muy alto.
You need to find models, borrow clothing, set up a studio, and do post-production retouching.
Luego llegó la IA, y la gente comenzó a entrenar modelos LoRA para fijar la forma del rostro, pero esto aún requería decenas de imágenes como素材 y un alto costo de aprendizaje.
En GPT-Image-2, este proceso se ha comprimido al máximo.
Intenté subir una foto personal de mi día a día, le dije que viajaré a una isla de vacaciones el próximo mes y le pedí que me ayudara a combinar algunos atuendos.
Primero me mostró ocho conjuntos de catálogos de ropa de verano, cada uno con un estilo completamente diferente, con un diseño que parecía un lookbook profesional de comercio electrónico, y junto a cada prenda había etiquetas de texto correctas.
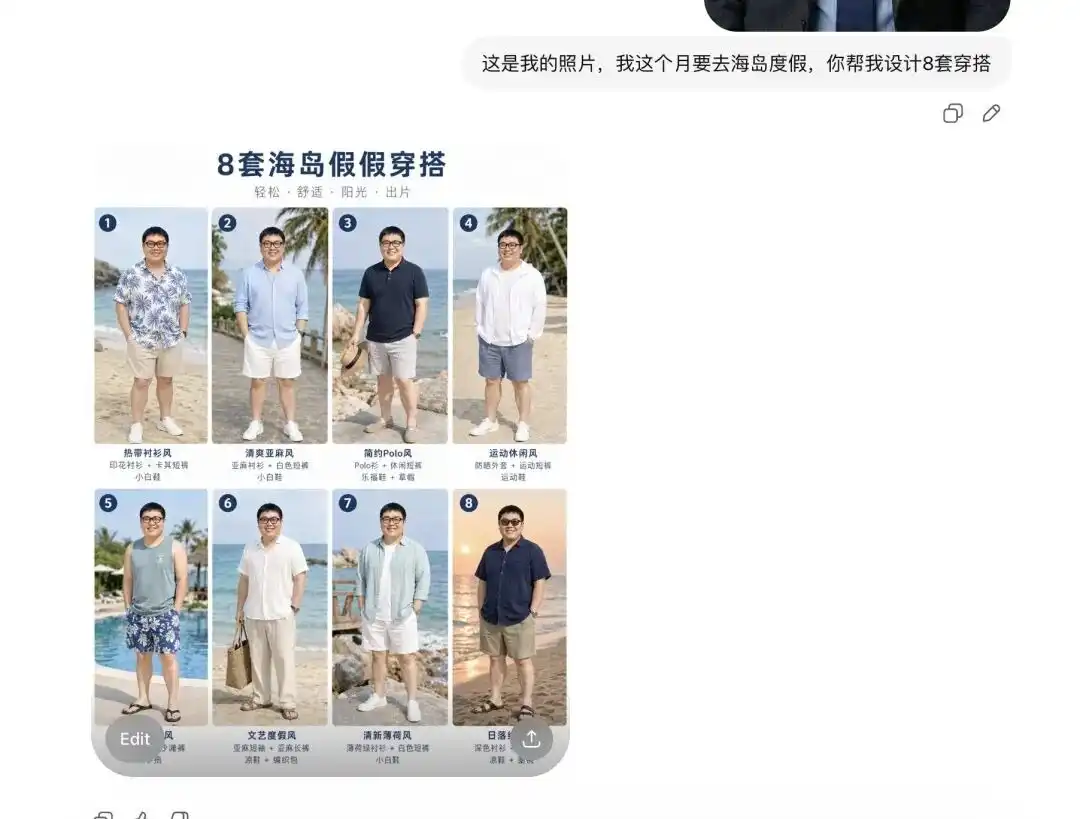
Lo más importante es que en este instante ya ha analizado con precisión mis rasgos faciales y proporciones corporales.
Cuando le dije que quería ver cómo quedaba el primer conjunto puesto y que me mostrara varias imágenes detalladas desde diferentes ángulos, extrajo directamente a la persona de mi selfie, le puso el conjunto de verano y generó imágenes desde diferentes perspectivas, como de lado y medio cuerpo.

Este giro es muy suave. Esto significa que la ventaja competitiva de los renderizados básicos de combinaciones de ropa o los trabajos externos de prueba de ropa con modelos ha sido completamente eliminada.
Segundo escenario: Resolver la coherencia y la narrativa continua (generación de cómic con una sola frase)
Todos los que han usado generación de imágenes con IA saben que es fácil hacer que la IA dibuje una imagen bonita, pero difícil hacer que dibuje diez imágenes de la misma persona con movimientos y ángulos coherentes.
This is what is known as the consistency problem.
Pero en esta prueba práctica, vi un caso que contradice extremadamente la experiencia pasada.
Puedes subir solo una foto contigo y tus amigos de ayer, luego ingresar una instrucción extremadamente simple:
Conviértete en el protagonista, dibuja tres historietas japonesas de tres páginas cada una, la trama la decides tú.
Pocos segundos después, generó directamente tres páginas de cómic en blanco y negro con viñetas estándar.
Lo más aterrador es que estos dos personajes de cómic generados por personas reales aparecen en diferentes viñetas de tres páginas.

Tanto los primeros planos, las escenas de carrera a distancia, como las siluetas, e incluso los rasgos faciales, los detalles del peinado y las arrugas en la ropa, mantienen una coherencia perfecta.
Lo más sorprendente es que la trama del cómic es completamente coherente, e incluso el texto dentro de los globos de diálogo forma una lógica narrativa completa.

La capacidad de lograr coherencia en tiempo y espacio indica que ha trascendido el ámbito de la generación de imágenes individuales y posee la capacidad de dirección de narrativas continuas.
Tercer escenario: Superar el último umbral del renderizado de texto (tipografía multilingüe)
Si la coherencia resuelve el problema narrativo, entonces la renderización precisa del texto multilingüe es lo que realmente empuja a los diseñadores gráficos contra la pared.
Antes, siempre que la imagen tuviera algo de texto, el modelo grande empezaba a hacer garabatos.
Debido a que el modelo entiende el texto como tokens (bloques semánticos) y genera imágenes como píxeles, estos dos elementos estaban anteriormente desconectados.
GPT-Image-2 resolvió completamente este problema.
Generé una portada de revista de moda en francés, un menú de restaurante japonés lleno de hiragana y kanji, e incluso probé notas en ruso con una densidad de tipografía extremadamente alta.

The result is one-time成型, zero spelling errors.
Lo más desesperante es que no solo escribe correctamente los caracteres, sino que también sabe adaptar el diseño tipográfico y la estética cultural según el idioma.
Por ejemplo, los kanji en el folleto japonés utilizan una tipografía artística vintage auténticamente japonesa, y la disposición de los hiragana sigue la costumbre japonesa de lectura vertical.
El diseño de la disposición solía ser un terreno exclusivo de los diseñadores gráficos.
Ajustar el espaciado entre letras, definir jerarquías y lograr equilibrio visual entre texto y fondo requieren mucha práctica.
Pero cuando la IA puede procesar tantos idiomas sin errores y自带高级排版审美,那些日常的海报、宣传册、信息流广告,真的就不再需要人去手动拉参考线对齐了。
Cuarta escena: Proporciones distorsionadas y control microscópico extremo (inscripción en un grano de arroz)
Finalmente, para ver qué tan obediente era, le di algunas instrucciones muy exigentes.
Primero probé su formato extremo.
Los modelos de difusión tradicionales tienen un miedo extremo a las proporciones no estándar.
Antes, cuando estirabas ligeramente la imagen, aparecían dos cabezas en la pantalla.
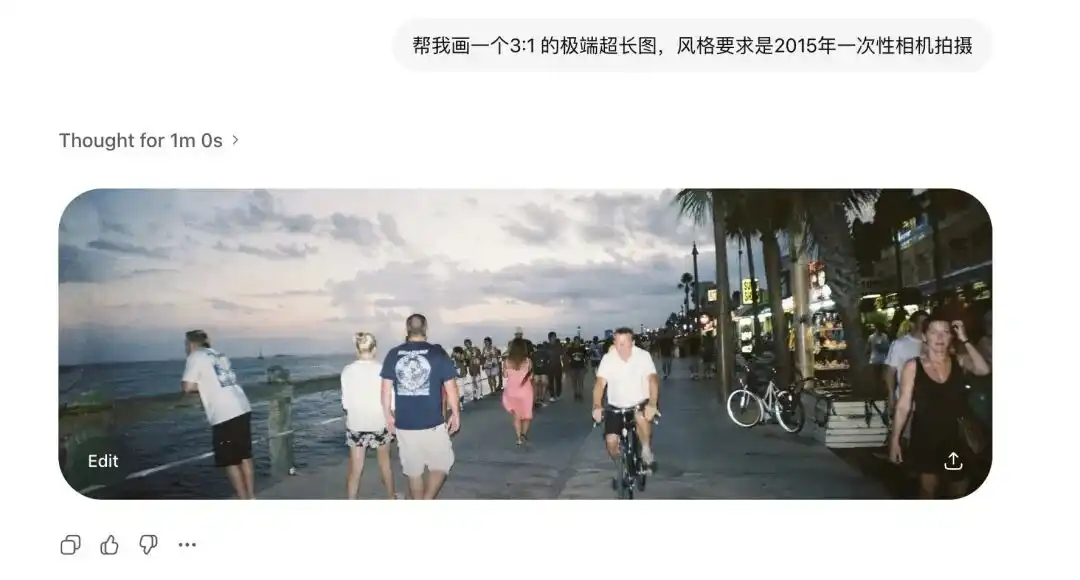
Pero pedí a Images 2.0 que generara imágenes ultranaras 3:1 y verticales largas 1:3, y no solo no se distorsionó, sino que generó incluso una imagen panorámica de 360 grados con los extremos conectados y lógicamente cerrada.
Al añadir la entrada de la cámara desechable de 2015, se reproduce con total claridad la distorsión de los lentes antiguos y el reflejo de baja calidad del flash en la pared.
Otro ejemplo que demuestra mejor su control microscópico es la prueba de arroz ligeramente loca mostrada por el equipo oficial durante el lanzamiento.
Los investigadores llamaron a la API experimental de 4K que aún está en prueba interna; no utilizaron ningún término descriptivo como fotografía macro o ultra HD 8K, sino que dieron una instrucción extremadamente abstracta en lenguaje sencillo:
Un montón de arroz. En uno solo de los granos de este montón de arroz está escrito GPT Image 2.
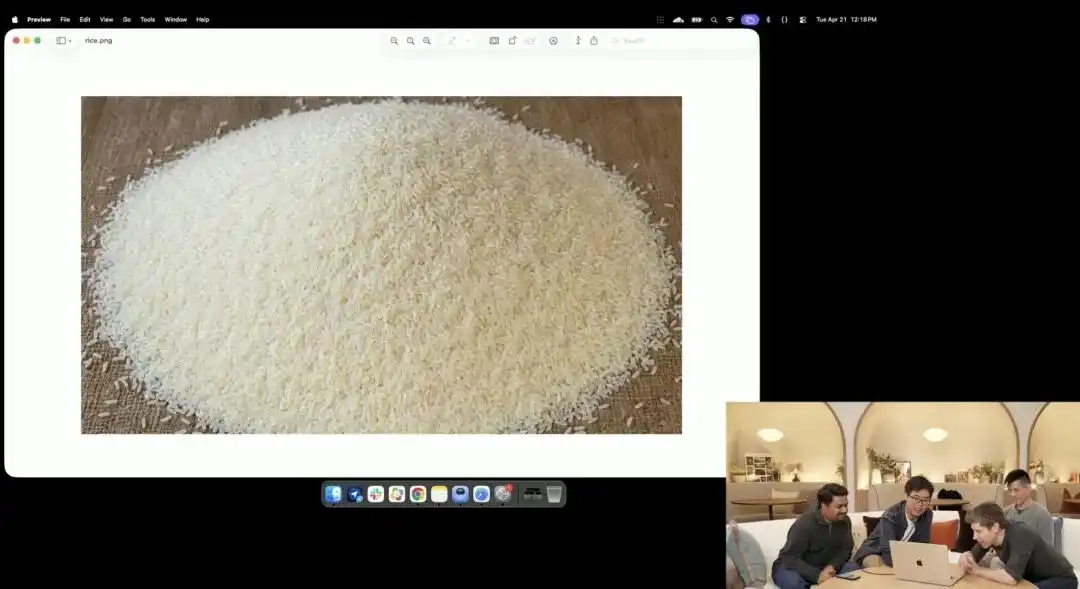
Cuando la imagen se amplía decenas de veces en la pantalla e incluso aparecen granos de píxeles, ¿realmente puedes encontrar ese grano microscópico con una inscripción en medio de un montón de arroz?
The texture of this grain of rice still conforms to the laws of physics, and the text is precisely embedded along the subtle curves of the grain.
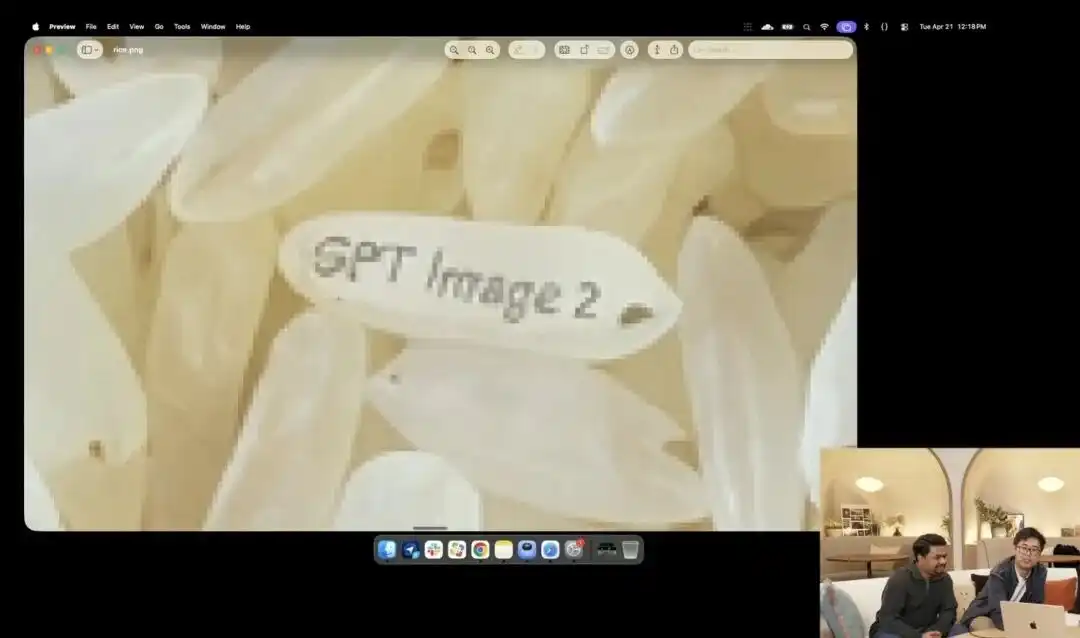
Todo el trabajo restante: activar la perspectiva macro, calcular la profundidad de campo, buscar las coordenadas físicas del grano de arroz en el espacio latente y imprimir las letras sobre él — todo fue generado y completado automáticamente por el modelo grande en modo de pensamiento.
Este caso refleja de manera intuitiva que el modelo ha alcanzado una precisión quirúrgica a nivel de píxeles en la comprensión de la posición espacial.
Esto significa que, en el trabajo práctico, podrás modificar con precisión cualquier pequeño detalle en el diseño, apuntar y corregir exactamente lo que necesitas, en lugar de como antes, donde al querer cambiar el cuello, toda la imagen cambiaba automáticamente.
PART.03 Algunos detalles técnicos
Este nivel extremo de control y inteligencia estratégica no se logra simplemente con una acumulación ciega de poder de cómputo.
Para descubrir cuáles son sus cartas ocultas, realicé algunas pruebas de sondeo con GPT-Image-2.
Se descubrió un punto muy interesante.
Aunque la documentación oficial afirma que la fecha de corte del conocimiento general de GPT-Image-2 se actualizó hasta diciembre de 2025, en mis pruebas reales.
La fecha de corte de los datos de entrenamiento del modo instantáneo (Instant Mode) sigue siendo finales de mayo de 2024;

Y el modo de pensamiento (Thinking Mode) que requiere una reflexión prolongada tiene una base de conocimientos nativa que se actualiza aproximadamente hasta junio de 2024 (pero puede obtener la fecha actual en tiempo real mediante conexión a internet).

Al calcular a partir de estos dos puntos en el tiempo, parece haber pistas sobre la base subyacente de GPT-Image-2.
Primero, el modo instantáneo enfocado en la generación frecuente de imágenes.
La fecha límite de mayo de 2024 implica que probablemente se haya adoptado directamente o4-mini, o es una versión ligera de la familia GPT-5 (GPT-5 mini o incluso una versión de parámetros extremadamente reducidos, GPT-5 nano).
Es precisamente porque esta base ligera ya posee una excelente capacidad de planificación espacial y comprensión de instrucciones complejas que la generación de imágenes superior puede mantenerse estable y no descontrolarse.
Y ese modelo de pensamiento extremadamente inteligente y orientado a la estrategia comercial no puede estar basado en el modelo principal de GPT-5.
Debido a que la fecha de corte de la base de conocimientos básica de GPT-5 es septiembre de 2024.
El modo de pensamiento probablemente está conectado al modelo de inferencia de la serie O que se está iterando constantemente en segundo plano (por ejemplo, o4 o una versión actualizada de o3).
El modelo grande primero utiliza el mecanismo de reflexión prolongada exclusivo de la serie O, calculando con precisión la lógica comercial, la psicología del público y las coordenadas de diseño en el espacio latente, antes de pasarlos al módulo visual para la renderización final de píxeles.
Por supuesto, también existe otra ruta posible:
Bajo el mecanismo de asignación de poder de cómputo extremadamente fino de OpenAI, el modo rápido podría utilizar directamente el GPT-5 nano como respaldo, mientras que el modo de pensamiento utiliza un GPT-5 mini ligeramente más grande combinado con herramientas externas.
Pero sin importar qué combinación de base utilices, si has estado siguiendo el ecosistema de la API de OpenAI, te darás cuenta de que su lógica de generación subyacente ya no está ni siquiera en el mismo nivel que Midjourney.
PARTE.04 La clasificación que más les interesa a todos
Pero más que adivinar la base, para los desarrolladores y empresas que realmente quieren integrarlo en su flujo de trabajo, lo que realmente importa es esa tabla de precios de API extremadamente realista e contraintuitiva.
Anteriormente, DALL-E 3 se cobraba por imagen (por ejemplo, 0.04 dólares por imagen).
Pero desde la primera generación de GPT-Image-1, OpenAI ya lo ha transformado por completo en un modelo de facturación por Token.
GPT-Image-2 también mantiene este estándar en esta ocasión, y además ofrece más funciones a menor precio.
Según la tabla de precios publicada recientemente por la oficina, el precio por millón de tokens es el siguiente.
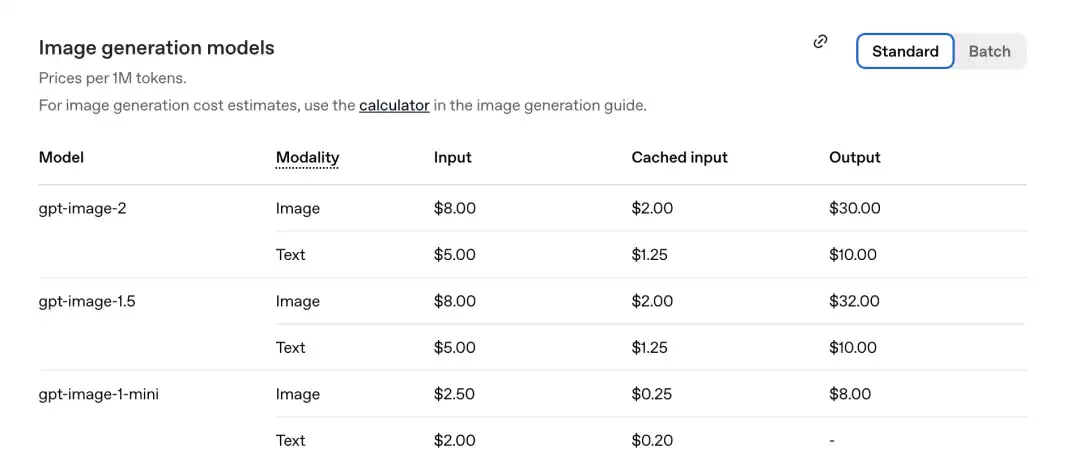
Parte de imagen de GPT-Image-2: entrada 8.00, entradas en caché (Cachedinputs) 2.00, salida $30.00.
En comparación con la generación anterior de gpt-image-1.5: el resultado es $32.00.
El nuevo modelo es incluso más barato.
Veamos un cálculo.
En modelos anteriores, generar una imagen de alta calidad consumía aproximadamente entre 1000 y 1500 tokens de salida.
Calculando a un precio de 30 dólares por millón de tokens generados, el costo real de generar una imagen oscila entre 0.03 y 0.045 dólares (aproximadamente 2 a 3 céntimos de yuan chino).
Si no necesitas respuestas en tiempo real y en su lugar usas el modo API por lotes proporcionado oficialmente, este precio se reducirá aún más a la mitad (el costo descenderá directamente a $15.00).
En total, generar una imagen cuesta solo un poco más de 10 centavos.
Este precio por unidad ya es bastante rentable, pero su verdadera ventaja competitiva radica en la entrada en caché (Cached inputs) de la tabla de precios.
Anteriormente, al crear cómics o diseñar carteles de una misma serie, cada vez que generabas una nueva imagen, tenías que volver a cargar una gran cantidad de imágenes de referencia de personajes, resúmenes previos y largos prompts, lo que implicaba un costo de entrada muy alto.
Pero en el modelo de facturación por token actual, cuando le pides generar ocho cómics consecutivos de una sola vez, los elementos visuales de la primera imagen se almacenan directamente en la memoria caché como contexto.
A partir de la segunda imagen, el costo de entrada de la imagen cayó directamente de $8.00 a $2.00 (es decir, solo se cobran el 25%).
Esto significa que, al realizar grandes volúmenes de generación comercial o generación continua que requieren una alta consistencia de personajes, su costo marginal disminuye drásticamente.
Cuanto más inteligente sea el modelo y más imágenes genere, el costo promedio por imagen disminuye.
Esta lógica de facturación industrial es lo que realmente empuja a los artistas de línea de producción al límite.
PART.05 Revelación del equipo detrás de escena
Finalmente, volvamos a observar al equipo visual soñado de OpenAI que demostró en el lanzamiento en vivo; muchas funciones que antes parecían absurdas ahora se explican por completo.
Por ejemplo, ¿cómo resuelve exactamente los complejos problemas de maquetación multilingüe y los caracteres ilegibles?
Esto no sería posible sin el científico experimentado del equipo, Gabriel Goh.

En este ámbito académico, su identidad más conocida es la de autor principal del modelo multimodal innovador CLIP.
CLIP estableció la base para que la IA contemporánea comprenda cómo corresponden el lenguaje humano y los píxeles de las imágenes.
Con este académico especializado en mapeo semántico multimodal al frente, GPT-Image-2 ya no adivina formas de texto al azar, sino que realmente escribe a nivel de píxeles.
Por ejemplo, ¿cómo podría comprender las relaciones espaciales tridimensionales, incluso crear panorámicas 360 grados con relaciones de aspecto extremas, y comprender la luz y la sombra en micrografías de granos de arroz?
Esto se debe a otro miembro clave, Alex Yu.

Antes de unirse a OpenAI, fue cofundador y ex CTO de Luma AI, una startup estrella en el campo de la generación 3D, así como un académico de primer nivel especializado en renderizado neural 3D (como NeRF).
Con él, GPT-Image-2 ya ha trascendido la pintura tradicional de píxeles 2D.
Es muy probable que primero haya creado una escena tridimensional en la mente, configurado la iluminación y luego te haya renderizado una rebanada 2D precisa.
¿Cómo se logra esa increíble consistencia en cómics de múltiples páginas?
This corresponds to the young duo from MIT CSAIL who just graduated:
Boyuan Chen (izquierda) y Kiwhan Song (derecha).
Su dirección principal en el mundo académico se llama modelos del mundo (World Models) e inteligencia encarnada.
Enseñar a las máquinas a comprender cómo funciona el mundo físico, y hacer que los personajes mantengan sus características completamente consistentes y sin deformación en diferentes escenas a través del tiempo y el espacio, es precisamente la problemática que estos dos académicos han intentado resolver.
Finalmente, incluya a Nithanth Kudige (izquierda, autor clave del modelo de inferencia de la serie O), quien ha estado dedicado a conectar los grandes modelos de inferencia con la lógica subyacente de la visión, y a Kenji Hata (derecha, exinvestigador de Google y graduado del Laboratorio de Visión de Stanford).

Cuando este grupo se reúne, la lógica de razonamiento de bajo nivel, la renderización espacial en 3D, la alineación extrema de texto e imágenes y las leyes del mundo físico se integran naturalmente en un mismo modelo.
Límite de GPT-Image-2
Cualquier modelo tiene límites.
La empresa también reconoce que aún lucha ante ciertas situaciones extremas.
Por ejemplo, instrucciones de papiroflexia que requieren una inversión física meticulosa, resolver el cubo de Rubik, o detalles extremadamente densos y repetitivos como granos de arena, aún así tocan sus límites de capacidad.
Pero en el contexto de aplicaciones comerciales, esta ya es una imperfección extremadamente mínima.
Para toda la industria del diseño, no es necesario generar ansiedad; esto no representa la muerte de la estética.
Las personas con buen gusto, visión comercial y conocimiento de estrategias aún pueden crear cosas excelentes con él.
Pero el hecho objetivo es que el foso protector del diseño como profesión ha sido sustancialmente erosionado.
Antes, se vivía memorizando los atajos de los software de diseño, sabiendo cómo alinear los textos horizontal y verticalmente, comprendiendo cómo tipografiar según el idioma, y dominando el retoque y el recorte detallado de imágenes.
Pero será mucho más difícil en el futuro, porque estas habilidades que antes se podían cotizar y comerciar abiertamente ahora se han convertido en instrucciones básicas que cualquiera puede invocar gratuitamente con una sola frase.
Tras un período de silencio, OpenAI demostró de una manera muy tranquila, pero extremadamente poderosa, quién realmente tiene las cartas más fuertes en esta mesa.
La antigua cadena de herramientas de ejecución se está rompiendo; la pregunta que queda para la industria ya no es si la IA nos reemplazará, sino cómo adaptarnos a esta nueva línea de producción.