










Fuente: Instituto de Investigación de CoinW
Resumen
Gradients es una subred descentralizada de entrenamiento de IA construida sobre Bittensor (SN56), cuyo núcleo consiste en transformar el entrenamiento de modelos de un proceso técnico complejo en un proceso de colaboración de red impulsado por el mercado, mediante mecanismos como “publicación de tareas, competencia entre mineros y verificación filtrada”. En su arquitectura, combina AutoML con capacidad de cómputo distribuida para formar un mercado de entrenamiento centrado en mecanismos de incentivos, reduciendo así la barrera de entrada para el uso de IA y mejorando la eficiencia en el uso de la capacidad de cómputo. Desde la perspectiva ecológica y los datos, Gradients ha completado la infraestructura básica de la red, pero actualmente los pesos de incentivo y el flujo de fondos son relativamente limitados. Gradients completa la infraestructura de entrenamiento en el ecosistema TAO y explora un nuevo paradigma de “optimización de IA impulsada por el mercado”, con potencial a largo plazo para convertirse en una capa de entrada importante para el entrenamiento descentralizado de IA.
1. Comenzando con Web2 AutoML: Estado y limitaciones del entrenamiento de IA
1.1 ¿Qué es AutoML?
En la percepción tradicional, entrenar un modelo de IA era una tarea de alto umbral, que requería que los ingenieros procesaran datos, eligieran modelos, ajustaran parámetros repetidamente y evaluaran los resultados, un proceso complejo y demorado. La aparición del AutoML (aprendizaje automático automatizado) consiste esencialmente en “empaquetar y automatizar” estos pasos繁琐. Puede entenderse como una “herramienta automática para crear modelos”: el usuario solo necesita proporcionar los datos y especificar el objetivo deseado, como clasificación, predicción o reconocimiento, y el sistema se encarga automáticamente del resto del proceso, incluyendo la selección del modelo, el ajuste de parámetros y la optimización del entrenamiento. Esto ha convertido la IA de una herramienta exclusiva de unos pocos ingenieros especializados en una capacidad accesible para desarrolladores comunes e incluso empresas, representando un paso crucial hacia la popularización de la IA.
1.2 Limitaciones fundamentales del AutoML tradicional
Actualmente, las implementaciones principales de AutoML se centran en plataformas de proveedores en la nube, como Google Vertex AI y AWS SageMaker, que ofrecen “entrenamiento de IA como servicio”. Aunque AutoML en Web2 ha reducido significativamente la barrera de entrada para usar IA, su modelo subyacente aún presenta limitaciones evidentes. En primer lugar, existe el problema de la centralización: la capacidad de cómputo, los precios y las reglas son controlados por la plataforma, lo que genera una fuerte dependencia de los usuarios hacia un solo proveedor y una falta de poder de negociación. En segundo lugar, los costos son altos y poco transparentes: los recursos GPU necesarios para el entrenamiento de IA están principalmente en manos de los proveedores en la nube, y su mecanismo de precios carece de competencia de mercado. Más importante aún, existe un límite en la eficiencia de optimización. El AutoML tradicional sigue siendo esencialmente “un sistema que te ayuda a encontrar la mejor solución”; sin importar cuán complejo sea este sistema, en esencia sigue siendo una optimización dentro de una única vía tecnológica. Su espacio de exploración es limitado y es difícil que intente simultáneamente múltiples enfoques completamente distintos. Por lo tanto, el entrenamiento actual de IA en Web2 es un “sistema cerrado”, donde el entrenamiento, la optimización y la programación de recursos ocurren dentro de un entorno controlado por una sola plataforma. Este modelo, aunque eficiente, está comenzando a mostrar sus límites a medida que crece la demanda.
2. Gradientes: Reconfigurar el entrenamiento de IA con "redes"
2.1 Gradients es una plataforma de AutoML descentralizada
En el capítulo anterior mencionamos que el problema central del AutoML tradicional Web2 es el "sistema cerrado": el entrenamiento del modelo depende de la plataforma, las rutas de optimización son limitadas y el flujo de recursos está restringido. Gradients representa una reestructuración de este modelo. Gradients surgió de la comunidad descentralizada de ingenieros iniciada por WanderingWeights y se construye sobre la red Bittensor, siendo una subred de entrenamiento de IA que opera en el Subnet 56. A diferencia de las plataformas tradicionales, no ofrece servicios centralizados, sino que descompone el proceso de entrenamiento y lo delega a una red abierta. El usuario solo necesita definir el objetivo de la tarea, como el tipo de modelo y los datos; el resto del proceso —incluyendo la ejecución del entrenamiento, la optimización de parámetros y la selección de resultados— lo realiza automáticamente la red. En este modelo, el entrenamiento de IA se abstrae de un proceso de ingeniería complejo hasta convertirse en un proceso simple de "enviar una solicitud y recibir un resultado", acercándose más a una capacidad general que a un trabajo técnico con una barrera profesional muy alta.
2.2 De un sistema cerrado a la colaboración abierta: ¿Qué problemas resuelve Gradients?
El cambio fundamental de Gradients consiste en transformar el proceso de entrenamiento, anteriormente confinado dentro de una sola plataforma, en un proceso de red abierto y colaborativo. Las tareas de entrenamiento ya no las realiza un solo sistema, sino que se distribuyen entre múltiples participantes que las ejecutan en paralelo, y luego se selecciona el mejor resultado mediante un mecanismo de evaluación unificado. Esta estructura reduce en primer lugar la dependencia de proveedores centralizados, estableciendo el entrenamiento sobre una capacidad de cómputo distribuida; al mismo tiempo, los recursos de GPU dispersos se integran en la misma red, generando, a través de la competencia, un enfoque de asignación de recursos más cercano al mercado. Más importante aún, la optimización del modelo ya no se limita a una sola vía, sino que avanza constantemente hacia soluciones superiores mediante la exploración paralela de múltiples métodos, elevando así el límite general de optimización.
2.3 Cambio esencial: de herramienta a "mercado de entrenamiento"
En el AutoML tradicional, la plataforma actúa más como una herramienta que ayuda a los usuarios a encontrar la mejor solución mediante algoritmos internos. En Gradients, este proceso se asemeja más a un “mercado” en funcionamiento continuo: los usuarios publican necesidades, diferentes participantes compiten por la misma tarea y los resultados se filtran mediante un mecanismo de evaluación. Así, el rendimiento del modelo ya no depende de la capacidad de un solo sistema, sino de la competencia y la iteración continuas impulsadas por múltiples participantes. El AutoML se transforma así de un problema técnico relativamente cerrado en un proceso dinámico impulsado por incentivos, permitiendo que la capacidad de optimización se expanda continuamente a medida que aumenta el número de participantes. Este cambio hace que el entrenamiento de IA comience a exhibir características de autoevolución similares a las de un mercado.
2.4 Papel en el ecosistema TAO: Capa de infraestructura para el entrenamiento de IA
En la arquitectura de subredes de Bittensor, diferentes Subnets desempeñan funciones diversas como inferencia, procesamiento de datos y entrenamiento, y Gradients se encuentra en la capa de entrenamiento. Se encarga de convertir la capacidad de cómputo distribuida en resultados de modelos reales, y mediante mecanismos de asignación y evaluación de tareas, permite que estos recursos sean continuamente programados y optimizados. Al mismo tiempo, conecta la oferta de poder de cómputo con la demanda de modelos, transformando el entrenamiento de un proceso meramente consumidor de recursos en un proceso colaborativo organizado y optimizable. En esta arquitectura, Gradients actúa como un eslabón central que convierte recursos distribuidos en capacidad de IA utilizable y respalda el desarrollo de aplicaciones de nivel superior.
3. Arquitectura principal: ¿Cómo se realiza el entrenamiento de IA en la red?
En el capítulo anterior mencionamos que Gradients transformó el entrenamiento de IA de “completado dentro de la plataforma” a “realizado mediante colaboración en red”. ¿Cómo funciona exactamente esta red? El núcleo de este capítulo es desglosar este proceso de manera más intuitiva.
3.1 Entrenamiento distribuido: ¿Cómo se completa una tarea entre varias personas?
Puedes imaginar a Gradients como una red de colaboración de entrenamiento en funcionamiento continuo. Cuando un usuario envía una tarea de entrenamiento, esta no se asigna a un solo sistema para su ejecución, sino que se distribuye simultáneamente a múltiples participantes de la red. Estos participantes, basándose en los mismos datos y objetivos, intentan distintos métodos de entrenamiento y envían sus resultados dentro del plazo establecido. Luego, el sistema evalúa uniformemente estos resultados y selecciona la mejor solución. Finalmente, las soluciones con mejor desempeño reciben recompensas, mientras que las demás son descartadas. Desde la perspectiva del usuario, este proceso requiere solo el inicio de una tarea, lo que equivale a “llamar” simultáneamente a múltiples enfoques de optimización y seleccionar automáticamente la mejor solución. La clave de este método no radica en la potencia individual de cada nodo, sino en la combinación de intentos paralelos múltiples + selección automática, lo que permite que los resultados se acerquen constantemente al óptimo.
En esta red, hay tres tipos principales de participantes: usuarios, mineros y validadores. Los usuarios se encargan de plantear las necesidades de entrenamiento; los mineros proporcionan potencia de cómputo y prueban distintos métodos de entrenamiento; los validadores evalúan los resultados y seleccionan el mejor modelo. Esta división de tareas permite que el proceso de entrenamiento funcione de forma continua y filtre constantemente soluciones cada vez mejores. En conjunto, constituye una red colaborativa impulsada por “demanda, oferta y evaluación”.
3.2 AutoML impulsado por el mercado
Como se puede ver en la descomposición del mecanismo anterior, Gradients no simplemente traslada AutoML a la cadena, sino que cambia la lógica subyacente de la optimización de modelos mediante la introducción de múltiples participantes y mecanismos de incentivos. Mientras que el AutoML tradicional depende de un sistema único que busca la solución óptima dentro de rutas limitadas, en Gradients este proceso se extiende a toda la red: diferentes participantes intentan continuamente distintos enfoques para la misma tarea y filtran e iteran constantemente mediante una evaluación unificada. Esto convierte la optimización del modelo en un proceso dinámico que puede evolucionar repetidamente, en lugar de ser un cálculo único. Bajo este mecanismo, los resultados con mejor rendimiento obtienen mayores recompensas, atrayendo continuamente a participantes para optimizar sus estrategias y impulsar una mejora constante del rendimiento general.
4. Mecanismo de incentivos y competencia: ¿Cómo el entrenamiento de IA genera un "círculo virtuoso"?
4.1 Mecanismo de incentivos (impulsado por TAO): De la actividad de entrenamiento al retorno de beneficios
La clave para el funcionamiento a largo plazo de Gradients radica en su mecanismo de incentivos, que depende del sistema de incentivos nativo proporcionado por Bittensor. En este contexto, TAO es el token nativo de la red Bittensor y actúa como el "vehículo de valor" dentro de toda la red: por un lado, se utiliza para recompensar a los participantes que aportan capacidad de cómputo y contribuciones de modelos; por otro lado, también participa en la asignación de pesos de subredes a través de mecanismos como el staking, influyendo en cómo fluyen los recursos entre diferentes subredes.
La red principal de Bittensor generará continuamente nuevas emisiones de incentivos, es decir, TAO (actualmente alrededor de 3600 TAO por día), y las asignará a diferentes subredes según ciertas reglas. La cantidad que recibe cada subred depende de su "rendimiento" dentro de la red total, como su nivel de actividad, la calidad de sus contribuciones y el respaldo financiero, entre otros factores. Para la subred en la que se encuentra Gradients, esta parte de TAO asignada se distribuirá internamente entre los participantes. El criterio fundamental para la distribución es quién aporte modelos de mejor calidad, ya que obtendrá mayores beneficios.
Concretamente, los mineros envían los resultados del entrenamiento, y los verificadores se encargan de probar y calificar estos resultados. El sistema calcula el “peso de contribución” de cada participante según las calificaciones, y distribuye las recompensas según este peso. Los modelos con mejor rendimiento (por ejemplo, con mayor capacidad de generalización y mayor estabilidad) obtendrán mayores ingresos, mientras que los verificadores que otorguen calificaciones más precisas y que reflejen mejor la calidad real también recibirán mayores incentivos. Este diseño hace que “hacerlo mejor” se corresponda directamente con “ganar más”, impulsando a los participantes a optimizar continuamente sus modelos.
4.2 Competencia entre subredes: no solo competencia interna, sino también clasificación externa
Además de la competencia dentro de la subred, Gradients enfrenta una "competencia horizontal" dentro de toda la red Bittensor. Dado que la asignación de TAO es dinámica, las distintas subredes compiten por obtener mayores pesos. Solo aquellas subredes que generen consistentemente resultados de alta calidad y atraigan a más participantes podrán obtener una mayor parte de las recompensas. Por lo tanto, los incentivos de Gradients no dependen únicamente del rendimiento interno de los modelos, sino también de su competitividad relativa dentro del ecosistema. Todo el sistema forma un ciclo multilayer: dentro de la subred, los modelos compiten entre sí; entre subredes, compiten por el rendimiento general. En última instancia, la inversión en capacidad de cómputo, la calidad del modelo y los retornos económicos quedan vinculados, creando un mecanismo de retroalimentación positiva en constante funcionamiento.
4.3 Gradientes 5.0: De la competencia al "mecanismo de torneo"
Sobre la base de la competencia continua inicial, Gradients evolucionó hacia un mecanismo más estructurado denominado “entrenamiento tipo torneo”. Puede entenderse como una competencia periódica: en cada ronda de entrenamiento se establece una ventana de tiempo, durante la cual múltiples participantes compiten en la misma tarea y se eliminan progresivamente a través de varias etapas hasta seleccionar la mejor solución. Este enfoque enfatiza la comparación por etapas y la evaluación concentrada. Un cambio importante es que los mineros ya no envían directamente los resultados del entrenamiento, sino que envían el “método de entrenamiento” (código), que luego es ejecutado de forma unificada por los nodos de validación. Esto mejora la equidad al eliminar interferencias causadas por diferentes entornos de cómputo, y también protege mejor la privacidad de los datos y del proceso de entrenamiento. Además, las soluciones ganadoras suelen consolidarse como métodos reutilizables, similares a “mejores prácticas” que se acumulan progresivamente. A largo plazo, este mecanismo no solo selecciona los modelos óptimos, sino que también construye una biblioteca de métodos de entrenamiento en constante evolución.
5. Estado ecológico
5.1 Estructura de participantes: red colaborativa compuesta por demanda, oferta y evaluación
El ecosistema de Gradients está compuesto por tres tipos de actores clave: usuarios (lado de la demanda), mineros (lado de la oferta) y verificadores (lado de la evaluación). Los usuarios incluyen principalmente desarrolladores de IA, pequeñas y medianas empresas y creadores de Web3, grupos que suelen tener cierta base técnica pero carecen de capacidad de cómputo o habilidades completas para entrenar modelos, por lo que prefieren utilizar Gradients para construir modelos a un costo más bajo. Los mineros proporcionan capacidad GPU y participan en la competencia por tareas de entrenamiento, con su motivación principal siendo la obtención de recompensas en TAO; los verificadores se encargan de evaluar y ordenar los resultados del entrenamiento, siendo un elemento clave para garantizar la calidad del modelo y el funcionamiento efectivo del mecanismo.
Desde una segmentación más detallada del perfil de usuario, el grupo real de usuarios de Gradients presenta una característica claramente "semidesarrolladora": ni se asemeja a los laboratorios de IA de élite ni es un usuario promedio sin antecedentes técnicos, sino que está compuesto principalmente por desarrolladores con cierta capacidad de ingeniería y usuarios de tecnología Web3. Esto también se refleja en su estructura comunitaria: actualmente, el ecosistema está dominado por el inglés, con usuarios clave ubicados principalmente en grupos de desarrolladores de América del Norte y Europa, y abarcando también a algunos mineros del sudeste asiático y proveedores globales de recursos GPU. En general, se aproxima a una comunidad de desarrolladores impulsada por la tecnología.
5.2 Estado actual del ecosistema
Al 12 de mayo, el precio del token alpha de Gradients era de aproximadamente 0.0255 TAO, con alrededor de 4,890 direcciones poseedoras, 243 mineros y 12 validadores, representando un 1.61% de la emisión. Al mismo tiempo, en su pool de liquidez, el porcentaje de TAO es del 2.19% y el de Alpha es del 97.81%. Desde el punto de vista del precio y el número de direcciones poseedoras, Gradients ya cuenta con una base de usuarios y cierta atención, pero aún se encuentra en una etapa temprana de difusión. En comparación con Chutes, el proyecto líder en el ecosistema TAO, el precio del token alpha ese día era de 0.0877 TAO, con 13,409 direcciones poseedoras.
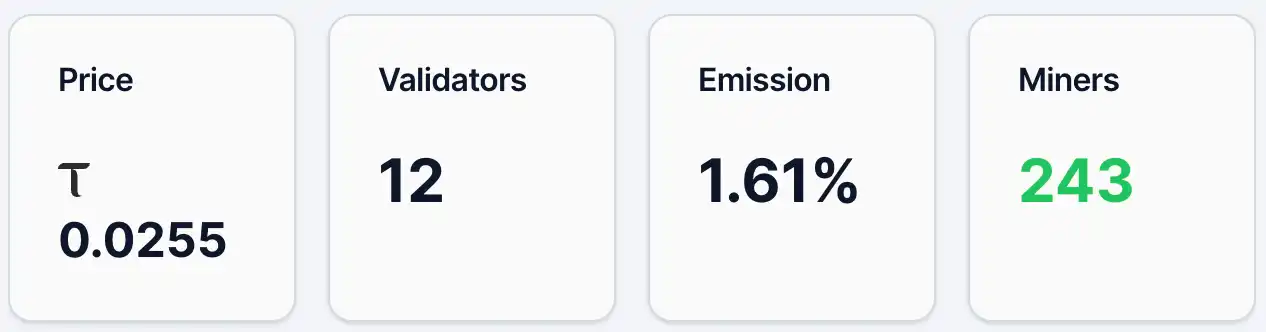
Figura 1. Datos de gradientes.
Origen:https://bittensormarketcap.com/subnets/56
Luego está el mecanismo de emisión. En el sistema de Bittensor, la emisión se refiere al peso de asignación en tiempo real de las recompensas nuevas de toda la red a cada subred. La red Bittensor genera continuamente nuevos TAO y los distribuye según estos pesos entre las distintas subredes; el 1,61% actual de Gradients significa que recibe solo una pequeña parte de las recompensas nuevas de toda la red. Este indicador refleja esencialmente el "resultado de la votación" del mercado a través del flujo de fondos (como el staking) hacia distintas subredes. Por lo tanto, un nivel del 1,61% generalmente indica una aceptación y entrada de fondos relativamente limitadas en el mercado actual, pero también implica que aún existe potencial para aumentar su peso en el futuro. Desde la perspectiva de la estructura de fondos (pools de liquidez), el porcentaje de TAO es solo del 2,19%, mientras que Alpha alcanza el 97,81%, lo que indica que la entrada de fondos externos sigue siendo limitada y que actualmente prevalece principalmente la oferta interna de la subred. El precio es sensible a nuevos fondos; una mayor entrada de TAO podría generar un efecto multiplicador más notable.
6. Escenario competitivo y ventajas y desventajas
6.1 Posicionamiento de la industria: infraestructura de entrenamiento de AutoML descentralizada
Gradients opera en el segmento de "infraestructura de entrenamiento de IA + AutoML descentralizado". Busca liberar el entrenamiento de modelos de las plataformas centralizadas y lograr una utilización más eficiente de los recursos y una optimización de modelos mediante mecanismos en red. En el ecosistema Web2, este segmento ya es relativamente maduro, con representantes típicos como Google Vertex AI y AWS SageMaker. Estas plataformas ofrecen a los desarrolladores servicios integrales de entrenamiento y despliegue de modelos mediante computación en la nube, pero su esencia sigue siendo una arquitectura centralizada. En comparación, la diferencia de Gradients no radica en "tener más funciones", sino en una lógica subyacente distinta: transforma el entrenamiento de un "servicio de plataforma" en una "colaboración en red", y utiliza mecanismos de competencia para seleccionar los mejores resultados, acercándose así a un sistema de entrenamiento operado como un mercado.
6.2 Comparación horizontal: Diferencias entre Web2 y Web3 AutoML
Desde una perspectiva más amplia, la diferencia entre Web2 y Web3 en la dirección de AutoML es esencialmente una comparación entre dos paradigmas distintos. El modelo Web2 enfatiza la eficiencia y la estabilidad, proporcionando una experiencia de servicio controlada y madura mediante la concentración de recursos y la optimización de ingeniería; mientras que el modelo Web3 enfatiza mayormente la apertura y los mecanismos de incentivos, permitiendo que la optimización de modelos evolucione constantemente a través de la participación múltiple. Concretamente, AutoML en Web2 es más como “una herramienta poderosa”, donde el usuario entrega la tarea a la plataforma para que el sistema busque internamente la mejor solución; en cambio, AutoML en Web3, representado por Gradients, es más como “un mercado abierto”, donde los usuarios publican sus necesidades y diferentes participantes ofrecen soluciones, las cuales luego se filtran mediante un mecanismo de evaluación. Esta diferencia tiene un impacto directo: el primero es más estable y controlable, pero con rutas de optimización limitadas; el segundo ofrece un mayor espacio de exploración y un límite potencial más alto, aunque aún tiene margen de mejora en estabilidad y madurez.
6.3 Diferenciación de Gradients en Web3
En el actual ecosistema Web3 AI, la mayoría de los proyectos aún se centran en la capa de inferencia o en AI Agent, mientras que los proyectos enfocados en “infraestructura de entrenamiento” son relativamente escasos. Algunos proyectos intentan combinar redes de poder de cómputo o redes de datos para proporcionar capacidad de entrenamiento, pero en general, la mayoría aún se queda en el nivel de programación de recursos o mercados de poder de cómputo. La diferencia de Gradients radica en que no solo ofrece emparejamiento de poder de cómputo, sino que también se extiende más allá hacia el “mecanismo de optimización del modelo” mismo, introduciendo un sistema de evaluación y competencia que otorga al proceso de entrenamiento una capacidad de evolución continua. Esto significa que no solo resuelve la pregunta “¿de dónde proviene el poder de cómputo?”, sino también “¿cómo usar este poder de cómputo de manera más eficiente?”. Desde su posicionamiento, Gradients se asemeja más a una red orientada a resultados de entrenamiento, en lugar de ser simplemente un mercado de poder de cómputo o una plataforma de herramientas, lo cual constituye la diferencia fundamental con la mayoría de los proyectos Web3 AI.
6.4 Ventaja principal: mejora de la eficiencia impulsada por mecanismos
En general, las ventajas de Gradients se manifiestan principalmente en su diseño de mecanismo. En primer lugar, reduce la barrera de entrada mediante la abstracción de tareas, permitiendo a los usuarios obtener resultados del modelo sin necesidad de participar profundamente en procesos de entrenamiento complejos, lo que amplía el grupo de usuarios potenciales. En segundo lugar, en términos de recursos, la introducción de capacidad de cómputo distribuida hace que el entrenamiento ya no dependa de un único proveedor de nube, teóricamente permitiendo formar una estructura de costos más resiliente mediante la competencia. Más importante aún es el cambio en su enfoque de optimización. Al permitir la exploración paralela por múltiples participantes y combinarla con un mecanismo de selección, Gradients ofrece una solución distinta a la optimización tradicional de una sola vía, brindando a los modelos la oportunidad de alcanzar un rendimiento superior en menos tiempo. Este modelo de "optimización impulsada por la competencia" es su ventaja más fundamental.
6.5 Potential challenges
La calidad del modelo puede presentar problemas de estabilidad. El entrenamiento descentralizado depende de la participación de múltiples partes; aunque puede elevar el límite superior, también puede generar variabilidad en los resultados, lo que implica cierta incertidumbre en comparación con los sistemas centralizados en términos de control. En segundo lugar, se encuentra el problema de confianza empresarial. Para los usuarios empresariales, la seguridad de los datos y la verificabilidad del proceso de entrenamiento son cruciales, y garantizar que los datos no se utilicen de manera indebida y que los resultados sean auditables en un entorno descentralizado sigue siendo una prueba clave. Finalmente, existe la dependencia del modelo económico de tokens. El funcionamiento de Gradients depende en gran medida de los mecanismos de incentivos; si la atractividad de los ingresos de TAO disminuye, podría afectar la participación de los mineros y la actividad general de la red. Por lo tanto, su sostenibilidad a largo plazo depende en cierta medida de que el modelo económico logre formar un ciclo positivo estable.
7. Visión futura: ¿Puede establecerse el AutoML descentralizado?
Desde la fase actual, Gradients aún se encuentra en etapas tempranas, y su capacidad para lograr un funcionamiento real en el futuro depende de varios puntos clave. El más fundamental es si puede atraer continuamente demandas reales de entrenamiento, y no solo participación impulsada por incentivos; en segundo lugar, la calidad del modelo: ¿puede el enfoque descentralizado producir de manera estable resultados útiles, e incluso superiores?; y finalmente, si el mecanismo económico puede generar un ciclo positivo que mantenga un equilibrio a largo plazo entre la oferta de capacidad de cómputo y los rendimientos.
En el contexto más amplio de la industria, el entrenamiento de IA se está dividiendo en dos caminos. Uno es el modelo Web2, liderado por las principales empresas tecnológicas, que refuerzan continuamente el rendimiento del modelo mediante recursos y capacidad de ingeniería centralizados, con la ventaja de estabilidad y madurez; el otro es el camino Web3 representado por Gradients, que, a través de redes abiertas y mecanismos de incentivos, permite que más participantes colaboren en la optimización del modelo, elevando constantemente su límite superior en la competencia. El primero está “creando sistemas más potentes”, mientras que el segundo parece más bien “construir una red que se autoevoluciona”.
Desde este ángulo, la exploración de Gradients representa una nueva posibilidad: el entrenamiento de IA ya no es solo un problema técnico, sino una combinación de “poder de cómputo + datos + mecanismos de mercado”. Si este modelo puede consolidarse, tiene el potencial de convertirse en la puerta de entrada para el entrenamiento de IA descentralizada y desempeñar un papel clave como infraestructura fundamental en el ecosistema de Bittensor. Por supuesto, esta dirección aún requiere tiempo para ser validada, pero ya ha ofrecido a AutoML una línea de evolución distinta a la tradicional.
Referencia
1. Documentación de Bittensor:https://docs.learnbittensor.org
2. Sitio web de Gradients:https://www.gradients.io/
3. Degradados:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats:https://taostats.io/subnets/56/chart