









Autor: Shenchao TechFlow
Un artículo de Google que afirma haber reducido el uso de memoria de IA a 1/6 provocó la pérdida de más de 90.000 millones de dólares en capitalización bursátil de acciones globales de chips de almacenamiento, como Micron y SanDisk, la semana pasada.
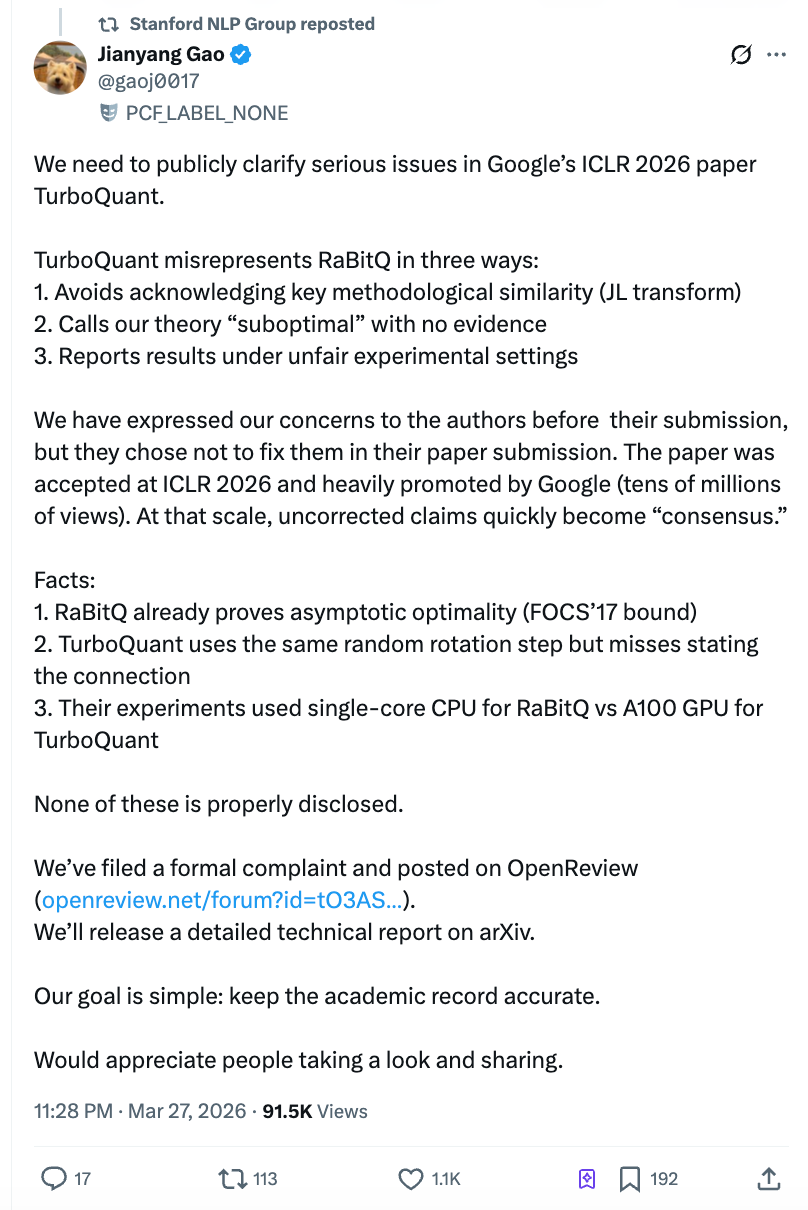
Sin embargo, apenas dos días después de la publicación del artículo, el postdoctorando Gao Jianyang del ETH Zúrich, cuyo algoritmo fue «sobrepasado» por el estudio, publicó una carta abierta de diez mil palabras acusando al equipo de Google de probar a sus competidores con un script de Python en una CPU de un solo núcleo, mientras utilizaba una GPU A100 para probar su propio modelo, y de rechazar corregir el problema a pesar de haber sido informados previamente antes de la presentación. La lectura en Zhihu superó rápidamente los 4 millones, y la cuenta oficial de Stanford NLP lo compartió, provocando una conmoción simultánea en la comunidad académica y en el mercado.
(Lectura de referencia: Un artículo académico que hizo caer las acciones de almacenamiento)
La cuestión central de esta controversia no es compleja: ¿una ponencia de la conferencia de IA ampliamente promovida por Google y que desencadenó directamente una venta masiva en el sector de chips, distorsionó sistemáticamente un trabajo previo ya publicado y creó una narrativa falsa de ventaja de rendimiento mediante experimentos injustos deliberadamente diseñados?
Lo que hizo TurboQuant: redujo la «hoja de borrador» de la IA a un sexto de su tamaño original
Cuando los modelos de lenguaje grande generan respuestas, necesitan revisar constantemente los cálculos previos mientras escriben. Estos resultados intermedios se almacenan temporalmente en la memoria VRAM, y en la industria se conocen como «KV Cache» (caché de clave-valor). Cuanto más larga sea la conversación, más gruesa se vuelve esta «hoja de borrador», lo que aumenta el consumo de memoria VRAM y también el costo.
El algoritmo TurboQuant, desarrollado por el equipo de investigación de Google, tiene como punto clave comprimir este borrador a 1/6 de su tamaño original, afirmando pérdida cero de precisión y una velocidad de inferencia hasta 8 veces mayor. El artículo se publicó por primera vez en la plataforma de preimpresiones académicas arXiv en abril de 2025, fue aceptado en enero de 2026 por la conferencia líder en el campo de la IA, ICLR 2026, y el 24 de marzo fue promovido nuevamente por el blog oficial de Google.
En términos técnicos, la lógica de TurboQuant se puede entender simplemente como: primero, se aplica una transformación matemática para "limpiar" los datos desordenados y convertirlos en un formato uniforme; luego, se comprimen individualmente utilizando una tabla de compresión óptima precalculada; finalmente, se corrige el sesgo computacional introducido por la compresión mediante un mecanismo de corrección de errores de 1 bit. La implementación independiente por la comunidad ha verificado que los efectos de compresión son esencialmente reales, y la contribución matemática en el nivel algorítmico es auténtica.
El debate no es si TurboQuant se puede usar, sino lo que Google hizo para demostrar que es "mucho más allá de sus competidores".
Carta abierta de Gao Jianyang: tres acusaciones, cada una golpea en el punto clave
El 27 de marzo a las 10 p.m., Gao Jianyang publicó un artículo extenso en Zhihu y presentó un comentario formal en la plataforma oficial de revisión de ICLR, OpenReview. Gao Jianyang es el autor principal del algoritmo RaBitQ, publicado en 2024 en la conferencia líder en el campo de bases de datos, SIGMOD, que aborda el mismo tipo de problema: la compresión eficiente de vectores de alta dimensión.
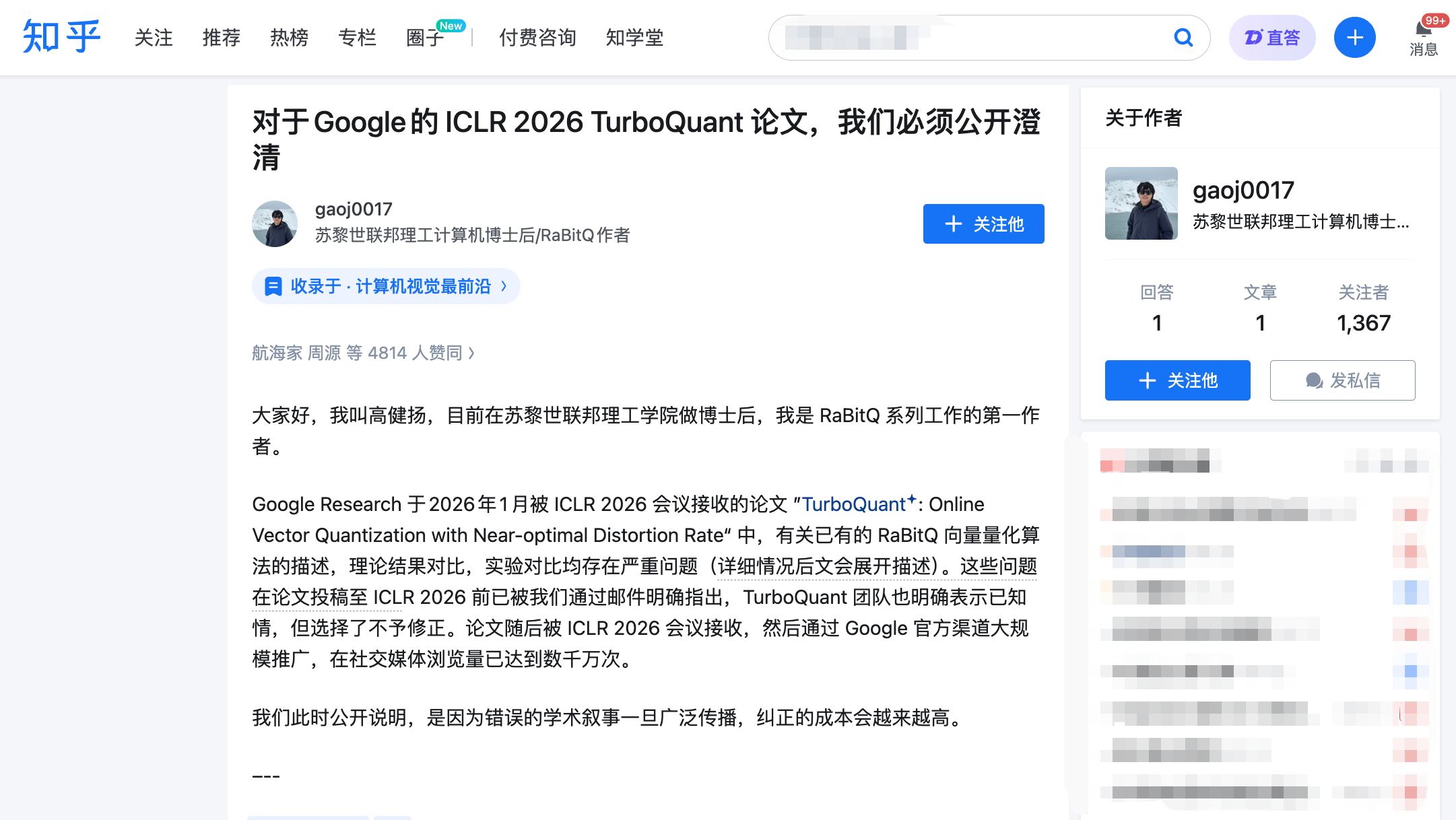
Sus acusaciones son tres, cada una respaldada por registros de correo electrónico y una línea de tiempo.
Acusación uno: utilizó el método central de otra persona sin mencionarlo en todo el texto.
Un paso clave común en los núcleos técnicos de TurboQuant y RaBitQ es realizar una «rotación aleatoria» de los datos antes de comprimirlos. Esta operación transforma datos originalmente distribuidos de forma irregular en una distribución uniforme predecible, reduciendo significativamente la dificultad de compresión. Es la parte más central y más similar entre ambos algoritmos.
El propio autor de TurboQuant reconoció esto en su respuesta a la revisión, pero nunca mencionó directamente la relación entre este método y RaBitQ en todo el artículo. El contexto aún más crucial es que Majid Daliri, el segundo autor de TurboQuant, se puso en contacto activamente con el equipo de Gao Jianyang en enero de 2025 para solicitar ayuda en la depuración de su versión en Python modificada a partir del código fuente de RaBitQ. El correo electrónico describió detalladamente los pasos para reproducir el problema y la información de error: en otras palabras, el equipo de TurboQuant tenía un conocimiento muy detallado de los aspectos técnicos de RaBitQ.
Un revisor anónimo de ICLR también señaló independientemente que ambos utilizaron la misma técnica, solicitando una discusión adecuada. Sin embargo, en la versión final del artículo, el equipo de TurboQuant no solo no añadió ninguna discusión adicional, sino que también trasladó la descripción (ya incompleta) de RaBitQ del cuerpo principal al apéndice.
Cargos dos: Afirmar sin fundamento que la teoría del otro es «subóptima».
El artículo de TurboQuant etiqueta directamente a RaBitQ como "subóptimo" debido a que su análisis matemático es "bastante burdo". Sin embargo, Gao Jianyang señala que la versión extendida del artículo de RaBitQ ha demostrado rigurosamente que su error de compresión alcanza el límite óptimo matemático, una conclusión publicada en una conferencia de primer nivel en ciencias de la computación teórica.
En mayo de 2025, el equipo de Gao Jianyang explicó detalladamente la optimalidad de la teoría RaBitQ a través de múltiples correos electrónicos. Daliri, segundo autor de TurboQuant, confirmó haber informado a todos los autores. Sin embargo, el artículo final mantuvo la expresión «subóptima» sin proporcionar ningún argumento de rechazo.
Carga tres: En la comparación experimental, «la mano izquierda atada a una persona, la mano derecha con un cuchillo».
Esta es la más impactante de todas las afirmaciones. Gao Jianyang señala que el artículo de TurboQuant agregó dos condiciones injustas en los experimentos de comparación de velocidad:
En primer lugar, RaBitQ oficial proporcionó código C++ optimizado (con soporte multihilo activado por defecto), pero el equipo de TurboQuant no lo utilizó, sino que probó RaBitQ con su propia versión traducida a Python. En segundo lugar, durante la prueba de RaBitQ se utilizó una CPU de un solo núcleo con multihilo desactivado, mientras que TurboQuant utilizó una GPU NVIDIA A100.
El efecto combinado de estas dos condiciones es que el lector llega a la conclusión de que «RaBitQ es varios órdenes de magnitud más lento que TurboQuant», sin saber que esta conclusión se basa en el hecho de que el equipo de Google le ató las manos al oponente antes de competir. Las diferencias en estas condiciones experimentales no se divulgan adecuadamente en el artículo.
Respuesta de Google: "La rotación aleatoria es una técnica general, no es posible citar cada artículo."
Según reveló Gao Jianyang, el equipo de TurboQuant respondió en un correo electrónico de marzo de 2026: "El uso de rotaciones aleatorias y la transformación de Johnson-Lindenstrauss ya es una técnica estándar en este campo, y no podemos citar cada artículo que utiliza estos métodos."
El equipo de Gao Jianyang considera que esto es un cambio de concepto: la cuestión no es si se deben citar todos los artículos que usaron rotación aleatoria, sino que RaBitQ fue el primer trabajo que combinó este método con compresión vectorial y demostró su optimalidad bajo el mismo conjunto de condiciones, por lo que el artículo de TurboQuant debería describir con precisión la relación entre ambos.
El cuenta oficial de X del Stanford NLP Group compartió la declaración de Gao Jianyang. El equipo de Gao Jianyang ha publicado un comentario público en la plataforma ICLR OpenReview y ha presentado una queja formal al presidente y al comité ético de ICLR, y posteriormente publicará un informe técnico detallado en arXiv.
El blogger técnico independiente Dario Salvati ofreció una evaluación relativamente neutral en su análisis: TurboQuant tiene contribuciones reales en su método matemático, pero su relación con RaBitQ es mucho más estrecha de lo que sugiere el artículo.
90 mil millones de dólares en capitalización de mercado desaparecidos: controversia académica sumada al pánico del mercado
El momento en que ocurrió esta controversia académica fue extremadamente delicado. Después de que Google publicara TurboQuant en su blog oficial el 24 de marzo, el sector global de chips de almacenamiento sufrió una fuerte venta. Según múltiples medios, incluidos CNBC, Micron Technology cayó durante seis días consecutivos, acumulando una caída superior al 20%; SanDisk descendió un 11% en un solo día; SK Hynitz de Corea del Sur bajó aproximadamente un 6%, Samsung Electronics cayó cerca del 5%, y Kioxia de Japón descendió alrededor del 6%. La lógica de pánico del mercado es simple y directa: la compresión por software puede reducir la demanda de memoria para inferencia de IA hasta seis veces, lo que llevaría a una revisión estructural a la baja de las perspectivas de demanda para los chips de almacenamiento.
El analista de Morgan Stanley, Joseph Moore, refutó este razonamiento en un informe del 26 de marzo, manteniendo la calificación de «comprar» para Micron y SanDisk. Moore señaló que TurboQuant solo comprime un tipo específico de caché, el KV Cache, y no el uso total de memoria, calificándolo como una «mejora normal de la productividad». El analista de Wells Fargo, Andrew Rocha, también citó la paradoja de Jevons, argumentando que los aumentos de eficiencia que reducen costos podrían estimular una implementación aún mayor de IA, lo que finalmente aumentaría la demanda de memoria.
Antiguos artículos, nuevo empaque: riesgos de la cadena de transmisión de la investigación en IA a las narrativas de mercado
Según el analista técnico Ben Pouladian, el artículo de TurboQuant ya se publicó públicamente en abril de 2025 y no es una investigación nueva. El 24 de marzo, Google lo reempaquetó y promovió a través de su blog oficial, pero el mercado lo valoró como un avance completamente nuevo. Esta estrategia de promoción de "artículo antiguo, lanzamiento nuevo", combinada con posibles sesgos experimentales en el artículo, refleja los riesgos sistémicos en la cadena de transmisión desde la investigación académica de IA hasta las narrativas del mercado.
Para los inversores en infraestructura de IA, cuando un artículo afirma haber logrado una mejora de rendimiento de «varios órdenes de magnitud», la primera pregunta que se debe hacer es si las condiciones de comparación del benchmark son justas.
El equipo de Gao Jianyang ha indicado claramente que continuará impulsando la resolución formal del problema. Google aún no ha respondido oficialmente a las acusaciones específicas de la carta abierta.