









Este ajuste de precio de DeepSeek ha forzado a la industria a entrar en una nueva era de costos mediante una caída abrupta y no lineal.
Autor del artículo, fuente: 0x9999in1, ME News
TL;DR
- El precio rompe el piso: a fin de abril de 2026, DeepSeek redujo el precio de salida de su modelo V4-Pro a 0,878 dólares por millón de tokens mediante la combinación de descuentos limitados y reducciones de caché, y el precio de entrada con acierto de caché bajó aún más a 0,0037 dólares (aproximadamente 0,025 yuanes chinos), rompiendo por completo el punto de referencia de precios de la industria de modelos grandes.
- Hay una brecha en la fijación de precios entre China y EE. UU.: en comparación con los principales fabricantes globales, el costo total de llamadas a la API de DeepSeek-V4-Pro es aproximadamente un treintavo del de OpenAI GPT-5.5 y Anthropic Claude Opus 4.7, generando una diferencia de costos extremadamente significativa.
- La competencia interna enfrenta presión: ante la agresiva estrategia de precios de DeepSeek, modelos principales como Zhipu GLM 5.1 y Moonshot Kimi K2.6 sufren una fuerte presión comercial y podrían verse obligados a seguir reduciendo precios, acelerando significativamente la consolidación del sector.
- La "tasa de acierto en caché" se convierte en la economía central: DeepSeek reduce el precio de la tasa de acierto en caché a la décima parte del precio original, una estrategia que beneficia enormemente desde la lógica subyacente los escenarios de procesamiento de textos largos, RAG (generación reforzada por recuperación) e interacciones continuas y multirround de Agentes.
- Conclusión del análisis del think tank: Los modelos base grandes están acelerando su conversión en infraestructura como "agua y electricidad"; el foco de la competencia futura pasará completamente de la competencia por el tamaño de los parámetros del modelo a la capacidad de optimización del costo de inferencia y la cuota de mercado del ecosistema de desarrolladores.
Introducción: El momento "singularidad" del costo de la capacidad de cómputo de los modelos grandes
El avance tecnológico suele ir acompañado de una caída exponencial en los costos, un camino inevitable para que cualquier tecnología disruptiva logre una adopción generalizada. Del 25 al 26 de abril de 2026, la industria de la IA vivió un momento sumamente significativo: la principal empresa de modelos grandes, DeepSeek, lanzó dos "bombas de profundidad" consecutivas. Primero anunció un descuento exclusivo por tiempo limitado del 75% para la API del modelo DeepSeek-V4-Pro; inmediatamente después, anunció que el precio por coincidencia de caché de entrada en toda la serie de servicios API se redujo directamente a la décima parte del precio original.
Tras estas dos rondas de estrategias de ajuste de precios acumulativas, el precio de acierto de caché de entrada para DeepSeek-V4-Flash ha caído hasta un asombroso 0,0029 dólares por millón de tokens (aproximadamente 0,02 yuanes chinos) antes del 5 de mayo de 2026, mientras que el precio de acierto de caché de entrada para DeepSeek-V4-Pro, que compite con los niveles más altos a nivel mundial, es de solo 0,0037 dólares (aproximadamente 0,025 yuanes chinos).
Antes de esto, la industria preveía que el costo de inferencia de los grandes modelos disminuiría aproximadamente un 50% anualmente, pero este ajuste de precios de DeepSeek provocó una caída abrupta y no lineal, forzando a la industria a entrar en una nueva era de costos. Creemos que esto no es simplemente una actividad de marketing o una “guerra de precios” a corto plazo, sino el resultado inevitable de optimizaciones en la arquitectura algorítmica subyacente (como mecanismos de atención dispersa y una evolución extrema de la arquitectura MoE), junto con mejoras en la capacidad de ingeniería de los clusters de cómputo. Este informe, basado en los datos más recientes de precios a nivel industrial, analizará en profundidad el impacto del descenso de precios de DeepSeek y comparará horizontalmente la competitividad comercial de los principales modelos grandes a nivel global, con el objetivo de proporcionar a los tomadores de decisiones un mapa claro de la evolución industrial.
Fenómeno clave: Rotura límite del sistema de precios de la serie DeepSeek-V4
Para comprender la magnitud de este recorte de precios, debemos analizar profundamente las tres dimensiones clave de la facturación de la API de modelos grandes: precio de entrada (sin acierto en caché), precio de entrada (con acierto en caché) y precio de salida. Los modelos anteriores de facturación solían distinguir únicamente entre entrada y salida, pero con el maduramiento de la tecnología de contexto largo (Long-Context), la "tasa de acierto en caché (Cache Hit)" se está convirtiendo en una variable clave para redefinir la economía de la API.
Desglose de la estrategia de precios: acumulación de descuentos y apalancamiento en caché
Según los datos más recientes publicados, DeepSeek ha implementado una estrategia de triple impacto: reducción de precios base + descuento limitado en el tiempo + apalancamiento de caché.
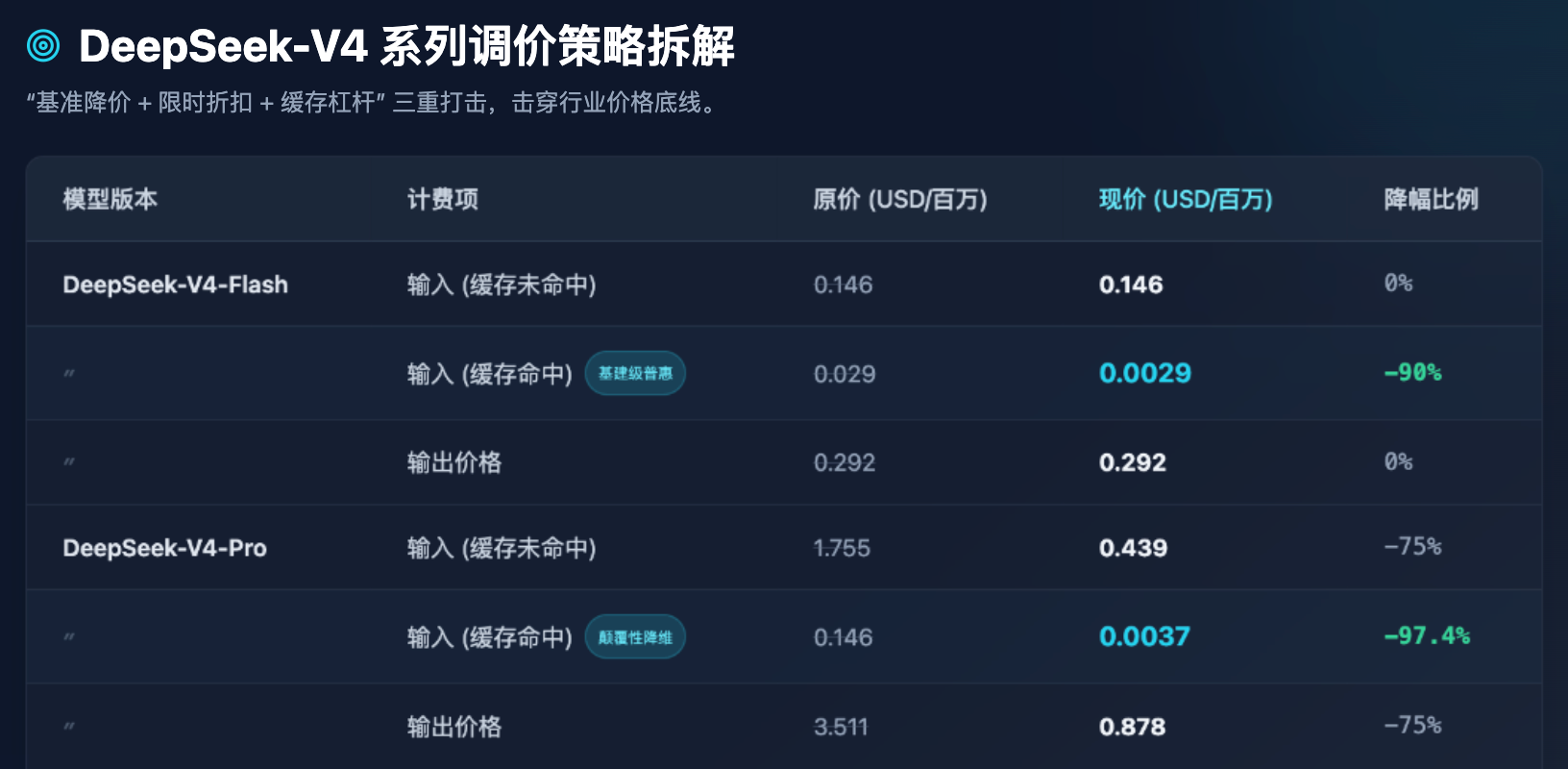
Tabla 1: Comparación antes y después del nuevo precio de la API de la serie DeepSeek-V4 (unidad: dólares por millón de tokens)
De la Tabla 1 podemos extraer varias observaciones industriales extremadamente claras:
En primer lugar, la democratización del modelo Flash ya ha tocado fondo. Para los modelos Flash, que se centran en alta concurrencia y baja latencia, el precio de salida se mantiene en 0,292 dólares por millón de tokens, lo cual ya está extremadamente cerca del límite inferior del costo real de la capacidad de procesamiento del servidor. DeepSeek no ha seguido modificando el precio base del Flash, sino que hábilmente redujo un 90% el precio de "aciertos en caché". Esto significa que, al procesar grandes cantidades de indicaciones del sistema (System Prompt) repetitivas o preguntas y respuestas con documentos fijos, el costo del modelo Flash es casi despreciable.
En segundo lugar, el impacto de reducción de dimensionalidad del modelo Pro. Como modelo insignia diseñado para competir con los primeros niveles globales (como GPT-5), el precio de salida del V4-Pro cayó de 3,511 dólares a 0,878 dólares. Aún más sorprendente, el precio de entrada para aciertos en caché, que anteriormente era de 0,146 dólares, tras aplicar el descuento temporal del 25% y una reducción adicional de 1/10, se redujo directamente a 0,0037 dólares. Este es un número extremadamente impactante: significa que el costo de acceder a la inteligencia más avanzada del mundo se ha comprimido hasta el punto de que incluso pequeñas y medianas empresas o desarrolladores individuales pueden utilizarlo con frecuencia sin ninguna restricción.
Tercero, impulsa a los desarrolladores a optimizar la ingeniería de prompts. Establecer el precio de un acierto en caché como una fracción de la décima parte del precio de un fallo (por ejemplo, en el modelo Pro: $0.0037 frente a $0.439, una diferencia de aproximadamente 118 veces) no es solo una estrategia de precios, sino también una forma de guiar el ecosistema tecnológico mediante medios comerciales. DeepSeek le dice claramente a los desarrolladores: si su diseño arquitectónico es adecuado (por ejemplo, colocar el contexto largo fijo al principio y la pregunta corta variable al final), podrán disfrutar de una capacidad de cálculo de entrada casi gratuita.
Comparación horizontal: la brecha en la fijación de precios entre modelos globales y locales
Solo comparar verticalmente la reducción de precios de DeepSeek consigo mismo no permite ver la imagen completa; cuando lo situamos en el sistema de coordenadas del mercado global de modelos grandes en 2026, el contraste “fracturado” generado por esta estrategia de precios resulta verdaderamente escalofriante.
Basándonos en OpenRouter y la información pública de diversas empresas, hemos recopilado los últimos datos de precios de API de los 9 modelos más representativos del mercado nacional e internacional.

Tabla 2: Comparación de precios de API de modelos grandes principales a nivel mundial en 2026 (unidad: dólares por millón de tokens)
Combatir a los gigantes globales: destrozar el mito de la “alta inteligencia y alta prima”
Durante los últimos dos años de narrativa sobre IA, OpenAI y Anthropic han mantenido un entendimiento tácito: los modelos más inteligentes deberían disfrutar de los márgenes brutos más altos. Actualmente, los precios de salida de GPT-5.5 y Claude Opus 4.7 alcanzan los 30 dólares y 25 dólares por millón de tokens, respectivamente. Estas dos gigantes de Silicon Valley intentan mantener su alto impuesto por capacidad de cómputo mediante el monopolio de las capacidades de inferencia más avanzadas.
Sin embargo, la aparición de DeepSeek-V4-Pro y su precio de salida de 0,878 dólares ha roto directamente esta fina capa. Suponiendo que V4-Pro pueda alcanzar o acercarse al nivel de GPT-5.5 en todas las pruebas de referencia (Benchmarks) y en la experiencia real, la diferencia de precio de salida de 34 veces entre ambos destruirá por completo la lógica de prima de los gigantes extranjeros en el mercado B2B.
«ME News智库» estima que para una empresa de exportación altamente dependiente del contenido generado por IA, si consume 1.000 millones de tokens de salida mensuales, el costo fijo utilizando GPT-5.5 sería de 30.000 dólares; al cambiar a DeepSeek-V4-Pro, este costo se reduciría drásticamente a 878 dólares. Esta diferencia de costo a esta escala puede determinar la supervivencia o el fracaso de una empresa emergente. Esto indica que las empresas chinas de IA han adoptado un enfoque completamente distinto al de Silicon Valley, combinando igualmente «estética de la fuerza bruta» y «optimización de ingeniería extrema» en la eficiencia del entrenamiento de modelos subyacentes y la optimización de clústeres de inferencia.
Cercar a los competidores nacionales: acelerar la reestructuración del sector
Si DeepSeek representa una ventaja abrumadora sobre los gigantes extranjeros, para sus competidores nacionales es una cruel batalla de suma cero.
Como se puede ver en la Tabla 2, los principales fabricantes nacionales, como Zhipu (GLM 5.1, salida de 4.4 dólares) y Moonshot (Kimi K2.6, salida de 4 dólares), se encuentran en una situación incómoda en términos de fijación de precios. Estos precios se consideraban hace unos meses “razonables y con buena relación calidad-precio”, pero frente a DeepSeek-V4-Pro (salida de 0.878 dólares), perdieron por completo su defensa de precios. Incluso Alibaba Cloud, conocida por su enfoque de código abierto y precios bajos (Qwen3.6 Plus, salida de 1.96 dólares), ya no parece “barata”.
En el campo de los modelos Flash ligeros, la batalla también está muy caldeada. Step 3.5 Flash de Jiepao Xingchen tiene una entrada de solo 0.028 dólares y una salida de 0.299 dólares, muy cerca de DeepSeek-V4-Flash (0.292 dólares de salida). Esto demuestra que en el ámbito de los modelos ligeros, la presión sobre los costos de cómputo ha llegado al nivel nanométrico, y todos están volando justo por encima de la línea de costos.
En general, DeepSeek está utilizando capacidades de nivel Pro para competir con los precios de las versiones Plus o estándar de sus competidores domésticos, y al mismo tiempo emplea precios de nivel Flash para captar todo el volumen masivo de tráfico de cola larga con baja densidad de valor. Esta estrategia de “pinzamiento en ambos extremos” comprime enormemente el espacio de supervivencia de otras empresas de modelos grandes, acelerando significativamente la eliminación de modelos grandes de IA en China tras esta ronda de reducciones de precios.
Visión profunda: La tecnología y la lógica comercial detrás de los precios extremadamente bajos
Los precios bajos sin fundamentos no son sostenibles. DeepSeek se atreve a implementar esta estrategia de reducción de precios tan drástica para 2026 gracias a un sólido respaldo técnico y ambiciosas intenciones comerciales.
Lógica técnica: de "fuerza bruta" a "triunfo arquitectónico"
La caída brusca de los precios es, en esencia, la liberación de los beneficios derivados de la evolución de la arquitectura técnica.
- El beneficio profundo de la arquitectura MoE (Mixture of Experts): a diferencia de los grandes modelos densos tempranos de OpenAI, los modelos avanzados actuales generalmente adoptan una arquitectura MoE altamente optimizada. DeepSeek probablemente reduzca aún más la proporción de parámetros activados en la arquitectura V4. Esto significa que, incluso con un volumen total de parámetros enorme, solo una mínima parte de los "expertos" se activan durante cada inferencia, reduciendo significativamente la cantidad de cálculos (FLOPs) y la presión sobre el ancho de banda de memoria gráfica por llamada.
- Revolución en la gestión del KV Cache: el punto más destacado de este ajuste es la reducción de la tasa de aciertos en el caché de entrada a 1/10. En la arquitectura Transformer, el mayor cuello de botella en la inferencia de textos largos no es el cálculo, sino el consumo de memoria GPU por parte del KV Cache que almacena la información de contexto. DeepSeek ha logrado, aparentemente, una tecnología de agrupación del KV Cache a nivel de sistema, compartida globalmente entre solicitudes (por ejemplo, una versión mejorada de la técnica RadixAttention). Cuando numerosas solicitudes simultáneas de usuarios contienen configuraciones del sistema o bases de conocimiento de fondo idénticas, el modelo ya no necesita volver a calcular estos tokens, sino que puede leerlos directamente desde la memoria o incluso desde un pool distribuido de memoria GPU. Esto hace que el costo marginal de las entradas de texto largo se acerque a cero.
Lógica comercial: intercambiar ganancias por espacio, redefinir el foso ecológico
«ME News智库» considera que la estrategia de descuento limitado y precio mínimo de DeepSeek tiene un propósito comercial claro y decidido:
Primero, destruye por completo el ecosistema de "ajustes superficiales", forzando la explosión de aplicaciones nativas de IA. Cuando el costo de invocar los modelos base más potentes se acerque infinitamente a cero, será económicamente sin sentido que los emprendedores inviertan grandes sumas en entrenar o ajustar sus propios modelos pequeños para industrias específicas. DeepSeek, mediante precios bajos, intenta atraer a todos los desarrolladores de IA de la sociedad hacia su ecosistema de API, convirtiéndolo en el "agua, electricidad y gas" subyacente de la era de la IA, como Amazon AWS o Microsoft Azure.
En segundo lugar, el amanecer de la explosión de los Agentes de posicionamiento. Las aplicaciones verdaderamente agenciales requieren que el modelo realice una gran cantidad de auto-reflexión, planificación y llamadas cíclicas múltiples (Loop). Durante este proceso, se generan enormes cantidades de consumo de tokens implícitos. Los costosos API son el mayor obstáculo para la adopción de Agentes. DeepSeek, al reducir el precio de acierto en caché a 0,0037 dólares, está haciendo económicamente viable "que la IA corra diez mil vueltas". Quien ofrezca el costo de prueba y error más bajo será quien fomente la creación de las superaplicaciones nativas de IA más grandes.
Impacto y análisis de tendencias de la industria: de la "guerra de modelos" a la "guerra de ecosistemas"
Para mostrar de manera más intuitiva el impacto de este cambio de precios en las decisiones empresariales, realizamos una simulación de costos para aplicaciones empresariales.
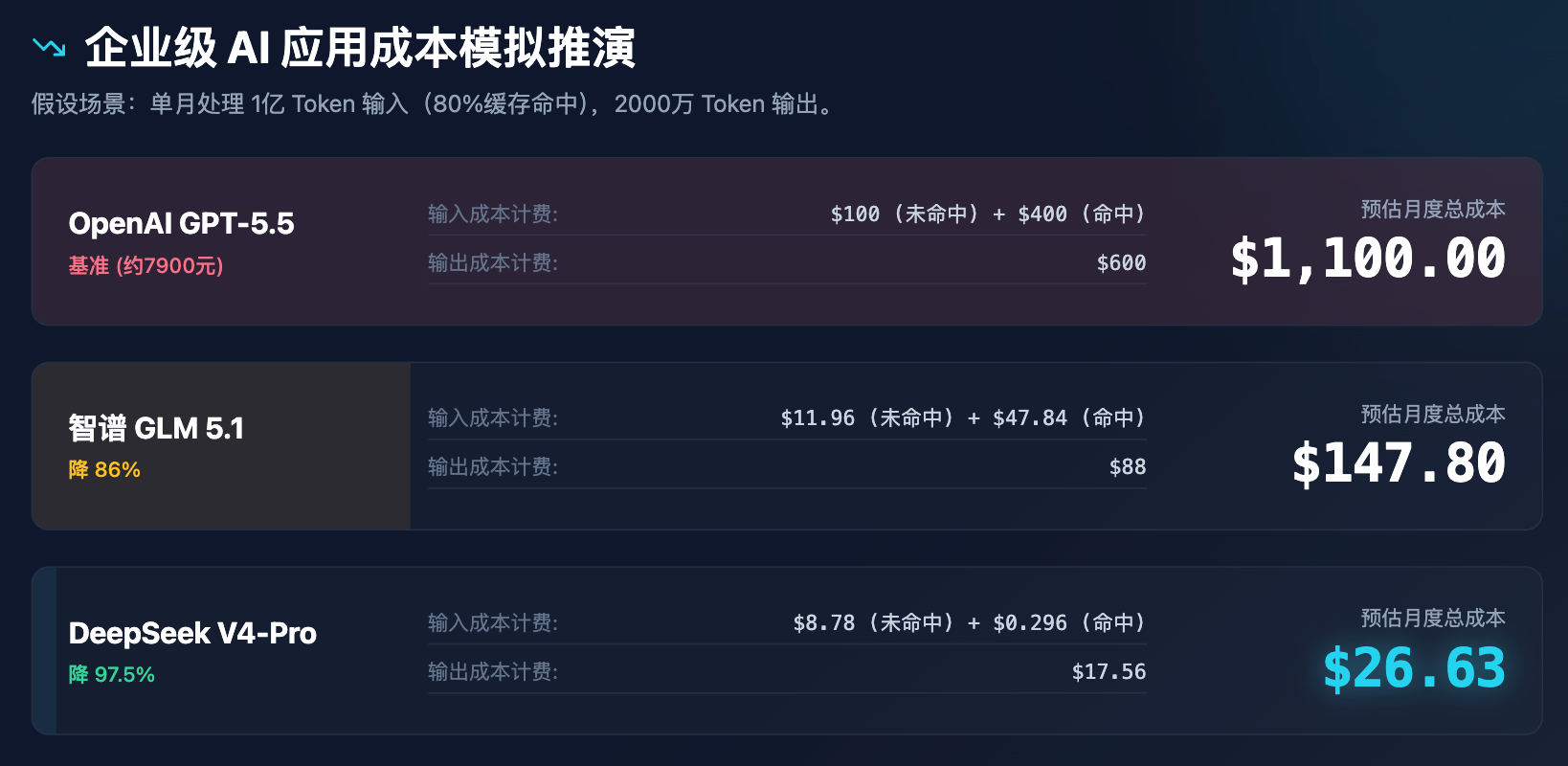
Tabla 3: Análisis de simulación de costos para aplicaciones de IA empresarial (suponiendo 100 millones de tokens de entrada y 20 millones de tokens de salida por mes)
A través de la simulación anterior, se puede ver claramente que la tarificación de DeepSeek no solo está ofreciendo un descuento, sino que está reestructurando el modelo de costos. Un costo de menos de 30 dólares al mes puede satisfacer todas las necesidades de asistencia al cliente, análisis de documentos y verificación de código de una empresa mediana, lo que sin duda desencadenará una serie de reacciones en cadena:
- Cambio fundamental en la lógica de inversión en IA: el capital perderá completamente el interés en "recrear un modelo grande general". Salvo por unas pocas entidades estatales o gigantes de internet, la puerta de los modelos grandes básicos generales ya está soldada. Las inversiones futuras fluirán integralmente hacia la capa de aplicaciones (Application Layer) y los middleware de infraestructura (enrutadores de infraestructura, puertas de IA, etc.).
- La estrategia de enrutamiento multipropósito (LLM Routing) se convierte en estándar: las empresas ya no se aferrarán a un solo modelo. El sistema distribuirá automáticamente las tareas según su complejidad. Por ejemplo, el 90% de la limpieza de datos diaria y la clasificación sencilla se realizará con DeepSeek-V4-Flash o Step 3.5 Flash a un costo extremadamente bajo; el 10% de la inferencia lógica compleja y la generación de informes ejecutivos utilizará DeepSeek-V4-Pro o GPT-5.5 según sea necesario.
- Las aplicaciones de texto largo llegan a un verdadero punto de inflexión comercial: hasta ahora, aunque “subir informes financieros de millones de caracteres para que la IA los resuma” suena ideal, el costo de la API, que suele ser de varios dólares por uso, disuade a las empresas B2B. Con el precio de la coincidencia en caché de entrada reducido a nivel de 0.02 yuanes chinos por millón de tokens, “leer toda la documentación de la biblioteca e interactuar en tiempo real” se convertirá en una función estándar en todos los software OA y ERP empresariales.
Conclusión y recomendaciones estratégicas
La ola de reducciones de precios de abril de 2026 marca el fin oficial de la era clásica romántica del sector de modelos grandes, caracterizada por la competencia en parámetros y puntuaciones, y da paso a una era industrial brutal centrada en la competencia por costos, capacidad de cómputo y dominio ecológico. DeepSeek, mediante su estrategia de precios de presión extrema, no solo demuestra al mundo la profunda experiencia de las empresas chinas de IA en ingeniería de modelos, sino que también rompe activamente la burbuja de sobreprecio en la capacidad de cómputo de IA.
Para esto, «ME News智库» tiene tres recomendaciones:
- Para desarrolladores de capa de aplicación: dejen de temer el costo de llamar a modelos grandes. Dejen inmediatamente de construir y ajustar modelos base con menos de 10 mil millones de parámetros, y dirijan todos los recursos de desarrollo hacia la experiencia del producto, la adaptación en el extremo, la construcción de barreras de datos propios y la perfección de flujos de trabajo de Agentes. Aprovechen esta ola de “potencia de cálculo barata y de alta inteligencia” para ocupar rápidamente los escenarios.
- Para CIOs/CTOs de empresas tradicionales: Reevalúe la estrategia de inteligencia artificial de su empresa. Proyectos anteriormente pospuestos por consideraciones de costo, como preguntas y respuestas en bases de conocimiento, atención al cliente automatizada y Copilot de código, ahora tienen una ROI (retorno de la inversión) extremadamente alta bajo los precios actuales de las API. Se recomienda implementar una plataforma madura de LLMOps y establecer una puerta de enlace de IA empresarial para conectar de forma flexible los modelos más rentables actuales.
- Para competidores de modelos base: se debe abandonar por completo la estrategia de seguimiento. Frente a la guerra de precios, o bien se reduce aún más el costo mediante una optimización extremadamente avanzada entre chips y marcos, o bien se establece una barrera tecnológica insustituible en áreas diferenciadas como la inteligencia encarnada, la multimodalidad nativa (generación de video/3D) o el razonamiento lógico fuerte en industrias verticales. La banalización pura de los grandes modelos de lenguaje ya no tiene salida.
Los modelos grandes ya no son dioses encerrados en laboratorios; están descendiendo de sus altares a una velocidad sin precedentes, convirtiéndose en una poderosa corriente que impulsa la inteligencia de todo. Y todo esto acaba de comenzar.
Fuente de referencia:
- OpenRouter. (2026). Base de datos de comparación de precios de la API.
- Anuncio oficial de DeepSeek. (25 de abril de 2026).Plan de oferta limitada para la API DeepSeek-V4-Pro.
- Announcement oficial de DeepSeek. (2026, 26 de abril).Computación accesible en la era de los grandes modelos: Propuesta de ajuste de precios para la caché global de API.