










Autor original: KarenZ, Foresight News
El 20 de marzo de 2026, hubo una conversación inusual en el podcast de All-In Ventures.
El inversionista de capital riesgo Chamath Palihapitiya le lanzó la palabra al CEO de NVIDIA, Jensen Huang, diciendo que en Bittensor hay un proyecto que "logró un logro técnico bastante loco": entrenó un modelo de lenguaje grande en internet utilizando poder de cómputo distribuido, de forma completamente descentralizada, sin participar ningún centro de datos centralizado.
Huang Renxun no evitó el tema. Lo comparó con una versión moderna de Folding@home, el proyecto distribuido de los años 2000 que permitía a usuarios comunes contribuir con su potencia informática inactiva para combatir conjuntamente el desafío del plegamiento de proteínas.
Cuatro días antes, el 16 de marzo, Jack Clark, cofundador de Anthropic, también dedicó una gran parte de su informe sobre avances en investigación de IA a destacar y citar este logro: la subred del ecosistema Bittensor Templar (SN3) completó el entrenamiento distribuido de un modelo de 72 mil millones de parámetros (Covenant 72B), cuyo rendimiento es comparable al de LLaMA-2 lanzado por Meta en 2023.
Jack Clark tituló este capítulo «Desafiar la política económica de la IA mediante el entrenamiento distribuido» y enfatizó en su análisis que se trata de una tecnología que merece ser seguida de cerca: puede imaginar un futuro en el que la IA en el dispositivo adopte masivamente modelos entrenados de forma descentralizada, mientras que la IA en la nube continúa ejecutando modelos grandes propietarios.
La reacción del mercado fue ligeramente retardada pero muy intensa: SN3 aumentó más del 440% en el último mes y más del 340% en las últimas dos semanas, con una capitalización de mercado de 130 millones de dólares. La narrativa de la subred explotó, transfiriéndose directamente en presión de compra sobre TAO. Por ello, TAO subió rápidamente, alcanzando temporalmente los 377 dólares, duplicando su valor en el último mes, con una FDV de aproximadamente 7.500 millones de dólares.
La pregunta es: ¿Qué hizo exactamente SN3? ¿Por qué fue llevado al centro de la atención? ¿Cómo evolucionará la narrativa de valor del entrenamiento distribuido y la IA descentralizada?
Ese modelo de 72B
Para responder a esta pregunta, primero hay que examinar cuidadosamente el desempeño de SN3.
El 10 de marzo de 2026, el equipo de Covenant AI publicó un informe técnico en arXiv, anunciando oficialmente que Covenant-72B completó su entrenamiento. Este es un modelo de lenguaje grande de 72 mil millones de parámetros, entrenado en aproximadamente 1.1 billones de tokens utilizando más de 70 nodos independientes (aproximadamente 20 nodos sincronizados por ronda, cada uno equipado con 8 tarjetas B200).
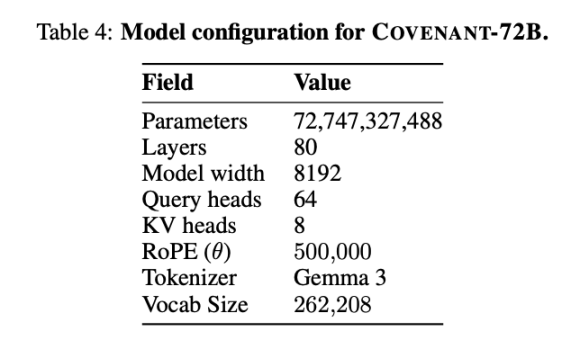
Templar proporcionó algunos datos en términos de pruebas de referencia, donde el LLaMA-2-70B comparado es el modelo grande lanzado por Meta en 2023. Como dijo Jack Clark, cofundador de Anthropic, Covenant-72B podría estar obsoleto para 2026. La puntuación de 67.1 de Covenant-72B en MMLU se corresponde aproximadamente con el LLaMA-2-70B lanzado por Meta en 2023 (65.6 puntos).
Mientras tanto, los modelos de vanguardia de 2026, ya sea la serie GPT, Claude o Gemini, ya han sido entrenados en cientos de miles de GPU con parámetros mucho mayores que 100 mil millones; la brecha en capacidad de inferencia, codificación y matemáticas es de orden de magnitud, no de porcentaje. Esta realidad no debería ser ahogada por el estado de ánimo del mercado.
Pero bajo el supuesto de "entrenado con potencia de cómputo distribuida en Internet abierto", el significado es completamente diferente.
Hagamos una comparación: INTELLECT-1 (desarrollado por el equipo Prime Intellect, 10 mil millones de parámetros) obtuvo una puntuación MMLU de 32.7 en un entrenamiento descentralizado; otro proyecto de entrenamiento distribuido, Psyche Consilience (40 mil millones de parámetros), realizado entre participantes autorizados, obtuvo una puntuación de 24.2. Covenant-72B, con una escala de 72B y una puntuación MMLU de 67.1, destaca como una cifra notable en la categoría de entrenamiento descentralizado.
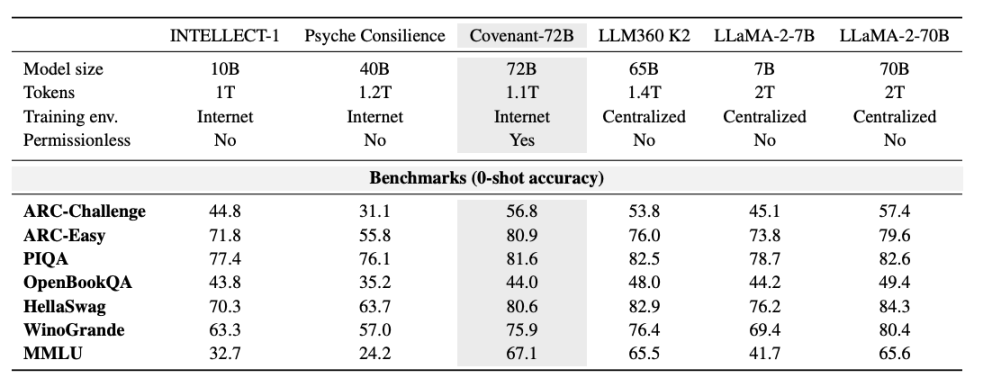
Más importante aún, este entrenamiento es «sin permiso». Cualquier persona puede conectarse como nodo participante sin necesidad de revisión previa ni lista blanca. Más de 70 nodos independientes participaron en la actualización del modelo, conectándose desde todo el mundo para aportar potencia de cálculo.
Qué dijo y qué no dijo Jensen Huang
Reconstruir los detalles de la conversación del podcast ayudará a corregir la interpretación externa de este «respaldo».
Chamath Palihapitiya presentó los logros técnicos de Bittensor en la conversación ante Huang Renxun, describiéndolos como el entrenamiento de un modelo Llama utilizando capacidad de cómputo distribuida, de forma «completamente distribuida, manteniendo el estado al mismo tiempo». La respuesta de Huang Renxun fue compararlo con una «versión moderna de Folding@home» y profundizar en la necesidad de la coexistencia paralela de modelos abiertos y propietarios.
Es importante destacar que Huang Renxun no mencionó directamente el token de Bittensor ni ninguna implicación de inversión, ni discutió adicionalmente el entrenamiento descentralizado de IA.
Comprender las subredes de Bittensor y SN3
Para comprender el avance de SN3, primero es necesario entender cómo funcionan Bittensor y sus subredes. En términos simples, Bittensor puede verse como una cadena de bloques y plataforma de IA, y cada subred equivale a una «línea de producción de IA» independiente, con tareas centrales definidas y mecanismos de incentivo diseñados específicamente, colaborando para conformar un ecosistema descentralizado de IA.
Su proceso de funcionamiento es claro y descentralizado: los propietarios de las subredes definen los objetivos de la subred y diseñan modelos de incentivos; los mineros proporcionan potencia de cómputo dentro de la subred y completan tareas relacionadas con la IA (como inferencia, entrenamiento, almacenamiento, etc.); los validadores califican las contribuciones de los mineros y cargan estas puntuaciones en la capa de consenso de Bittensor; finalmente, el algoritmo de consenso Yuma de Bittensor asigna beneficios a los participantes de la subred en función de las recompensas acumuladas por cada subred.
Actualmente, Bittensor tiene 128 subredes que cubren diversas tareas de IA, como inferencia, servicios de nube AI sin servidor, imágenes, etiquetado de datos, aprendizaje por refuerzo, almacenamiento y cálculo.
SN3 es una de estas subredes. No actúa como una capa de aplicación ni alquila API de modelos grandes existentes, sino que se enfoca directamente en uno de los segmentos más caros y cerrados de toda la cadena de valor de la IA: el entrenamiento previo de los modelos grandes.
SN3 busca aprovechar la red Bittensor para coordinar el entrenamiento distribuido de recursos de cómputo heterogéneos, demostrando mediante un entrenamiento distribuido incentivado de modelos grandes que es posible entrenar modelos base potentes sin depender de costosos clústeres centralizados de supercomputadoras. Su atractivo principal radica en la «igualdad»: romper el monopolio de recursos del entrenamiento centralizado y permitir que individuos comunes o instituciones medianas y pequeñas participen en el entrenamiento de modelos grandes, reduciendo al mismo tiempo los costos de entrenamiento mediante capacidad de cómputo distribuida.
La fuerza impulsora detrás del desarrollo de SN3 es Templar, cuyo equipo de investigación es Covenant Labs. Este equipo también opera otros dos subredes: Basilica (SN39, enfocada en servicios de cómputo) y Grail (SN81, enfocada en post-entrenamiento RL y evaluación de modelos). Las tres subredes forman una integración vertical que cubre completamente el ciclo completo desde el preentrenamiento hasta la optimización de alineación de modelos grandes, construyendo un ecosistema completo de entrenamiento descentralizado de modelos grandes.
Específicamente, los mineros contribuyen con recursos de cómputo para cargar las actualizaciones de gradiente (la dirección y magnitud de los ajustes de los parámetros del modelo) a la red; los validadores evalúan la calidad de la contribución de cada minero y otorgan una puntuación en la cadena según el grado de mejora en el error. El resultado determina los pesos de recompensa, que se asignan automáticamente sin necesidad de confiar en ningún tercero.
El diseño clave del mecanismo de incentivos es que los premios estén directamente vinculados a "cuánto mejoró el modelo gracias a tu contribución", y no simplemente a la capacidad de cálculo asistida. Esto resuelve fundamentalmente el problema más difícil en escenarios descentralizados: cómo evitar que los mineros hagan trampa.
¿Cómo resuelve Covenant-72B los problemas de eficiencia de comunicación y compatibilidad de incentivos?
Coordinar decenas de nodos que no se confían entre sí, con hardware diverso y calidad de red desigual para entrenar el mismo modelo presenta dos desafíos: primero, la eficiencia de comunicación, ya que los esquemas tradicionales de entrenamiento distribuido requieren interconexiones de alta ancho de banda y baja latencia entre nodos; segundo, la compatibilidad de incentivos, cómo evitar que nodos maliciosos envíen gradientes erróneos y cómo garantizar que cada participante esté entrenando honestamente en lugar de copiar los resultados de otros.
SN3 resuelve estos dos problemas con dos componentes clave: SparseLoCo y Gauntlet.
SparseLoCo resuelve el problema de la eficiencia de comunicación. El entrenamiento distribuido tradicional requiere sincronizar gradientes completos en cada paso, lo que genera una cantidad de datos enorme. La solución adoptada por SparseLoCo es: cada nodo realiza 30 pasos de optimización local (AdamW) y luego comprime los «seudogradientes» generados antes de subirlos a otros nodos. Los métodos de compresión incluyen esparsificación Top-k (mantener solo los componentes de gradiente más críticos), retroalimentación de error (almacenar las partes descartadas y acumularlas para el siguiente ciclo) y cuantización de 2 bits. La relación de compresión final supera los 146 veces.
En otras palabras, lo que antes requería transmitir 100 MB ahora solo necesita menos de 1 MB.
Esto permite que el sistema mantenga una utilización del cálculo de aproximadamente el 94,5% bajo las limitaciones de ancho de banda de Internet común (110 Mbps de subida y 500 Mbps de bajada): 20 nodos, cada uno con 8 B200, y solo 70 segundos por ciclo de comunicación.
Gauntlet resuelve el problema de la compatibilidad de incentivos. Se ejecuta en la blockchain de Bittensor (Subnet 3) y se encarga de verificar la calidad de los pseudo-gradientes enviados por cada nodo. El método consiste en probar con un pequeño lote de datos cuánto se reduce la pérdida del modelo al aplicar el gradiente de ese nodo; el resultado se denomina LossScore. Además, el sistema verifica si el nodo está entrenando con los datos que le fueron asignados: si un nodo logra una mejora en la pérdida con datos aleatorios mayor que con sus propios datos asignados, recibe una puntuación negativa.
Al final, solo los gradientes del nodo con la puntuación más alta de cada ronda participan en la agregación, mientras que los demás nodos son eliminados de esa ronda. Los participantes adicionales se incorporan en tiempo real para mantener la estabilidad del sistema. Durante todo el proceso de entrenamiento, en promedio se incluyeron los gradientes de 16.9 nodos por ronda, y más de 70 IDs únicos de nodos participaron en total.
La narrativa de valor de la IA descentralizada está experimentando un cambio fundamental
Desde una perspectiva técnica e industrial, el rumbo que representa Covenant-72B tiene varios significados reales.
En primer lugar, se rompió la suposición de que el entrenamiento distribuido solo es adecuado para modelos pequeños. Aunque aún está lejos de los modelos más avanzados, se demostró la escalabilidad de esta dirección.
En segundo lugar, la participación sin permiso es real y factible. Este punto ha sido subestimado. Los proyectos anteriores de entrenamiento distribuido dependían de listas blancas: solo los participantes aprobados podían contribuir con capacidad de cómputo. En este entrenamiento de SN3, cualquier persona con suficiente capacidad de cómputo puede conectarse, y el mecanismo de validación se encarga de filtrar contribuciones maliciosas. Esto representa un paso concreto hacia la «descentralización verdadera».
En tercer lugar, el mecanismo dTAO de Bittensor permite el descubrimiento de mercado del valor de las subredes. dTAO permite que cada subred emita su propio token Alpha, utilizando un mecanismo AMM para que el mercado determine qué subredes reciben más emisiones de TAO. Esto proporciona un mecanismo de captura de valor, aunque rudimentario pero efectivo, para subredes como SN3 que han producido resultados concretos. Por supuesto, este mecanismo también es susceptible a ser influenciado por narrativas y emociones, ya que la calidad de los resultados del entrenamiento de LLM es difícil de evaluar independientemente por participantes comunes del mercado.
Cuarto, las implicaciones político-económicas del entrenamiento de IA descentralizado. Jack Clark, en Import AI, eleva esta cuestión al nivel de «¿quiénes poseen el futuro de la IA?». Actualmente, el entrenamiento de modelos de vanguardia está monopolizado por unas pocas instituciones que poseen grandes centros de datos, lo cual no es solo un problema comercial, sino también una cuestión de estructura de poder. Si el entrenamiento distribuido logra continuar avanzando tecnológicamente, podría generar un ecosistema de desarrollo verdaderamente descentralizado para ciertos tipos de modelos (como modelos pequeños de vanguardia en dominios específicos). Por supuesto, este panorama aún está muy lejos de materializarse.
Resumen: Un hito real, junto con una serie de problemas reales
Huang Renxun dijo que esto es como una «versión moderna de Folding@home». Folding@home hizo contribuciones reales en el campo de la simulación molecular, pero no amenazó la posición central de investigación y desarrollo de las grandes empresas farmacéuticas. Esta analogía es muy precisa.
SN3 implementó el protocolo y validó la dirección factible del entrenamiento distribuido. Pero desde una perspectiva técnica e industrial, detrás de este informe de resultados hay una serie de problemas que muy pocas personas están dispuestas a discutir seriamente:
MMLU también es una métrica controvertida en la comunidad académica, ya que existe el riesgo de que las preguntas y respuestas de los benchmarks públicos se filtren en los conjuntos de entrenamiento. Lo que merece mayor atención es la elección de las líneas base: los modelos comparados en el artículo, LLaMA-2-70B y LLM360 K2, son modelos antiguos de 2023 a 2024, mientras que puntuaciones entre 65 y 70 en ese mismo período se consideran de nivel medio-bajo o introductorio cuando se evalúan modelos como Grok y Doubao, y se consideran gravemente rezagados según Claude. Si se colocaran en listas dinámicamente actualizadas o en benchmarks de nueva generación diseñados para resistir la contaminación, las conclusiones serían probablemente más honestas.
Más importante aún, los datos de alta calidad que determinan el límite de capacidad del modelo —datos de conversación, código, deducciones matemáticas y literatura científica— probablemente están en manos de grandes empresas, editoriales y bases de datos académicas. La computación se ha democratizado, pero el lado de los datos sigue siendo una estructura oligopólica, y esta contradicción no ha sido discutida.
En cuanto a la seguridad, la participación sin permiso significa que no sabes quién está detrás de esos más de 70 nodos ni qué datos están utilizando para entrenar. Gauntlet puede filtrar gradientes obviamente anómalos, pero no puede prevenir envenenamiento de datos sutil: si un nodo entrena sistemáticamente varias rondas adicionales en direcciones de contenido dañino, los cambios en el gradiente pueden ser lo suficientemente sutiles como para pasar la inspección de puntuación de pérdida, pero generar un desplazamiento acumulativo en el comportamiento del modelo. La pregunta final es: ¿qué riesgos implica utilizar un modelo entrenado por unos pocos nodos anónimos con fuentes de datos no completamente rastreables, en escenarios de alta conformidad y seguridad como finanzas, medicina o derecho?
También hay un problema estructural que merece ser mencionado directamente: Covenant-72B es de código abierto bajo la licencia Apache 2.0 y no utiliza el token SN3. Poseer el token SN3 implica compartir los ingresos por emisión generados por la producción continua de nuevos modelos en esta subred, no cualquier beneficio directo derivado del uso del modelo. Esta cadena de valor depende de la producción constante de entrenamientos y del funcionamiento saludable del mecanismo de emisión general de la red Bittensor. Si en el futuro el entrenamiento se detiene o los nuevos resultados de entrenamiento no cumplen con las expectativas de calidad, la lógica de valoración del token se debilitará.
Listar estas preguntas no tiene como objetivo negar el significado de Covenant-72B. El hecho de que haya logrado algo que antes se consideraba imposible no desaparecerá. Pero lograrlo y lo que eso implica son dos cosas distintas.
El token SN3 ha aumentado un 440% en el último mes. Esta brecha podría no ser simplemente especulación, sino que la narrativa siempre avanza más rápido que la realidad. Que esta brecha最终 sea cerrada por la realidad o absorbida por la corrección del mercado dependerá de lo que realmente entregue el equipo de Covenant AI en los próximos pasos.
Es importante destacar que Grayscale presentó una solicitud de ETF para TAO en enero de 2026, lo que indica una señal de entrada de capital institucional en este sector. Además, en diciembre de 2025, Bittensor redujo a la mitad la emisión diaria de TAO, y la contracción estructural en la oferta sigue en curso.
Enlace de referencia:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95