









¿Sueñan los androides con ovejas eléctricas?

Captura de pantalla de la película Blade Runner
En 1968, cuando el autor de la novela original de la película de ciencia ficción Blade Runner, Philip K. Dick, escribió esta pregunta abstracta y adelantada en su máquina de escribir, probablemente no imaginó que medio siglo después, los gigantes tecnológicos de Silicon Valley responderían con seriedad.
Sí, no solo pueden soñar con ovejas electrónicas, sino también visualizar los sueños.
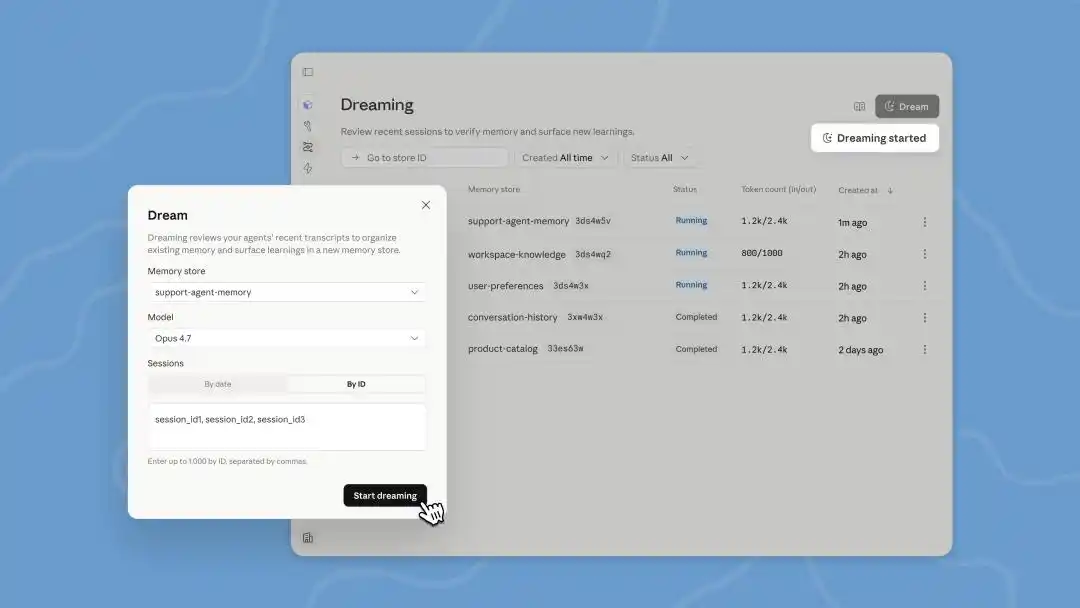
Ayer, Anthropic lanzó una serie de nuevas funciones para su plataforma de construcción de agentes, Managed Agents, en la conferencia de desarrolladores en San Francisco: expansión de memoria, salida de resultados, colaboración entre múltiples agentes y el modo «soñar (Dreaming)».
Según Anthropic, "la memoria y los sueños juntos forman un sistema de memoria robusto y automejorable".

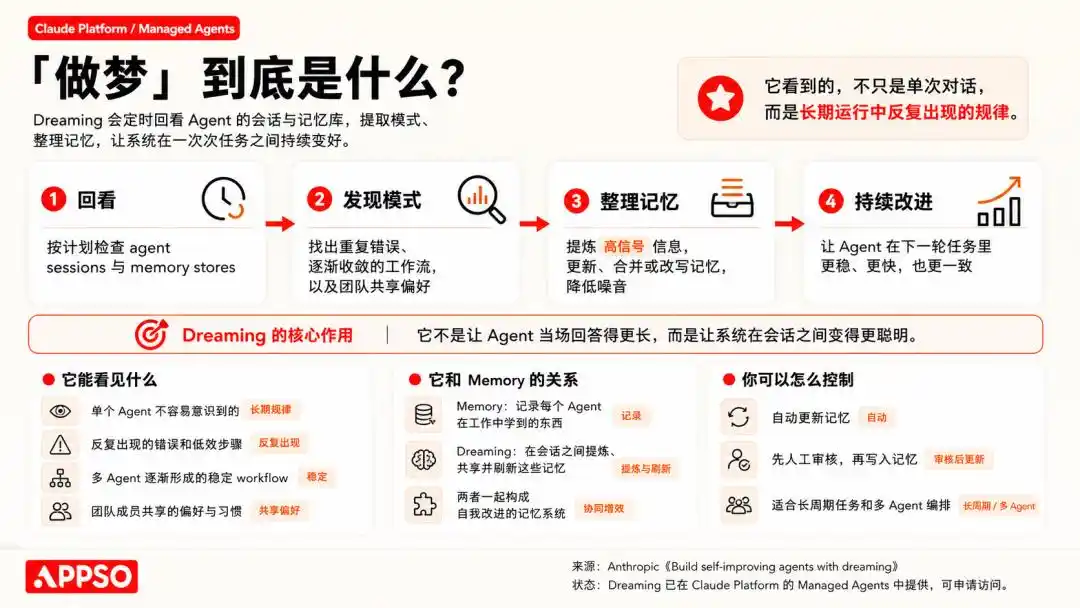
Otra vez soñar, otra vez memoria: los amigos que no siguen de cerca el campo de la IA probablemente se quedarán con la cabeza llena de preguntas, pues ¿cuándo comenzaron estas palabras humanas a aplicarse tan naturalmente a la IA?
Ya en 2024, cuando OpenAI lanzó la serie o1, «una serie de modelos de IA diseñados para dedicar más tiempo a pensar antes de responder», el término «pensar» se usó de manera extremadamente natural, tan natural que nadie se detuvo a preguntar: ¿cómo puede un programa que estadísticamente predice el siguiente token llamarse pensamiento?
A continuación, reasoning (razonamiento), memory (memoria), reflection (reflexión), Imagining (imaginación), llevando uno por uno los procesos que solo los humanos pueden realizar, uno tras otro, a los lanzamientos de productos.

Capturas de pantalla de la película de Sueños, "Paprika"
«Pensar» aún puede interpretarse como metáfora, «memoria» también puede considerarse una extensión del jerga técnica, pero «soñar» realmente va demasiado lejos. La filosofía, la historia y la literatura han estudiado durante miles de años sin aclararlo, y sin embargo, las empresas de IA afirman directamente: no solo hemos creado máquinas que piensan, sino también máquinas que sueñan.
¿Qué es soñar? ¿No existe ningún término técnico que pueda describir con precisión este evento, además de soñar?
Incluso los sueños de la IA cuestan dinero
Durante el incidente de fuga de código de Claude Code, algunos usuarios descubrieron que Anthropic estaba preparando una función llamada Auto Dreaming. En ese momento, todos se preguntaban: ¿acaso la IA también necesita dormir y descansar adecuadamente, como los seres humanos, para concentrarse mejor y volverse más inteligente?
Pero al comprender cómo funcionan actualmente los AI Agentes, se descubre que lo que se llama «soñar» es, en esencia, un procesamiento por lotes automático y fuera de línea de registros.
Los agentes de IA ahora son expertos en completar tareas complejas de larga cadena. Por ejemplo: «Ayúdame a investigar los últimos estados financieros de estas cinco empresas competidoras y organízalos en una tabla». Durante este proceso, el agente debe navegar entre diferentes páginas web, leer múltiples documentos, utilizar diversas herramientas e incluso puede encontrarse con mecanismos anti-scraping que requieren reintentos.
Cuando finalice esta larga serie de tareas en línea, el backend del agente dejará una gran cantidad de registros de ejecución.
La imagen fue generada por IA
La función de "soñar" de Anthropic permite que el agente, durante tiempos de inactividad, reorganice estos registros históricos. Busca patrones, como descubrir que "cada vez que aparece esta ventana emergente, hacer clic en la esquina superior derecha la cierra", optimizando así la ruta de operación siguiente.
La «memoria» se encarga de capturar lo aprendido durante el trabajo, mientras que «soñar» refine estas memorias entre conversaciones y las comparte entre diferentes Agentes.
En otras palabras, se trata de un mecanismo de aprendizaje por refuerzo y autocorrección basado en datos históricos.

Introducción a Dream: https://platform.claude.com/docs/en/managed-agents/dreams
En esta conferencia de desarrolladores, se actualizó Dreams en Managed Agents, una tarea de procesamiento en segundo plano que debemos activar manualmente. Claude puede leer hasta 100 sesiones de historial de conversación a la vez y generar un nuevo memory, que debemos revisar antes de decidir si utilizarlo.
AutoDream, que ya se había lanzado silenciosamente en Claude Code, verifica en segundo plano tras cada conversación con el agente si "debe soñar", por defecto cada 24 horas.
Hermes Agent también tiene funciones similares a soñar. Lo principal de Hermes Agent es su capacidad de autoaprendizaje y evolución, no solo admite resumir automáticamente experiencias de tareas pasadas y almacenarlas en archivos de memoria.

Una de las funciones llamada Curator también puede organizar automáticamente estas guías de operaciones en Skill.
Estas Skill serán puntuadas, se combinarán las duplicadas, las que no se utilicen durante mucho tiempo se archivarán automáticamente, e incluso tienen un ciclo de vida con estados como active, stale y archived. También podemos fijar las Skill importantes para que el sistema no las elimine automáticamente.
OpenClaw también ha añadido mecanismos relacionados en las últimas actualizaciones, como memoria persistente entre conversaciones, programación de tareas programadas, ejecución aislada de sub-Agents y la función de soñar directamente llamada Dreaming.
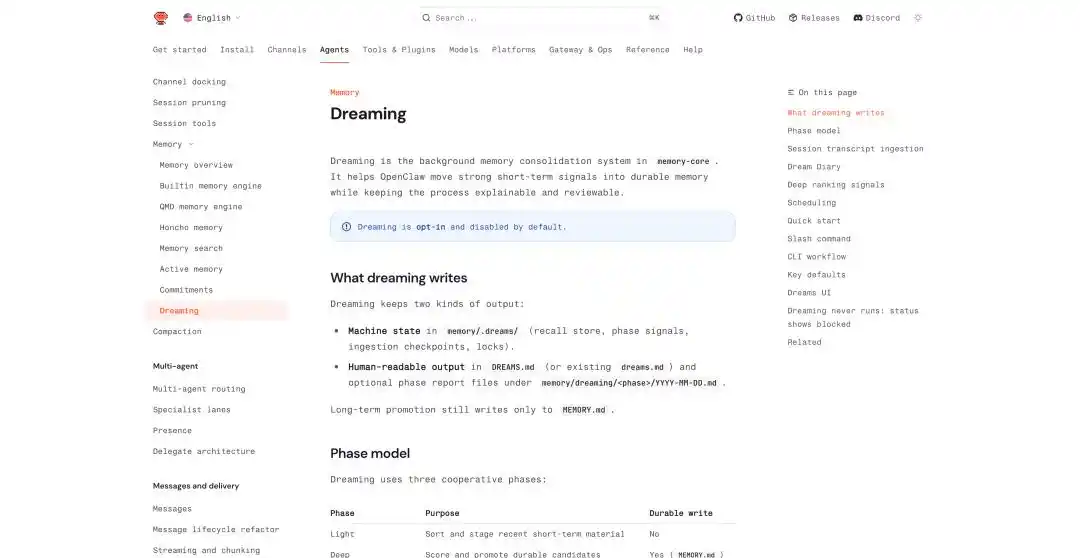
El sueño de OpenClaw: https://docs.openclaw.ai/concepts/dreaming
En el mecanismo de sueños de OpenClaw, resume el recorrido del sueño en tres etapas: light, REM, deep. Las dos primeras se encargan de organizar, reflexionar y sintetizar temas, mientras que deep es la que realmente escribe el contenido en MEMORY.md.
La consolidación en la fase de sueño profundo será determinada por seis señales ponderadas sobre si se debe escribir en la memoria a largo plazo. Estas seis señales incluyen frecuencia, relevancia, diversidad de consultas, actualidad, repetición entre días y riqueza conceptual.

La imagen fue generada por IA
Al escribir en la memoria a largo plazo, se generarán dos archivos: un archivo de estado dirigido a máquinas, ubicado en memory/.dreams/; y un registro legible para usuarios, que se escribirá en DREAMS.md y en informes generados por etapas.
Además, Dreaming puede ejecutarse automáticamente según un horario programado, ejecutando un proceso completo diariamente a las 3:00 a.m., en el orden: light → REM → deep.
Además de la salida de los sueños, OpenClaw mantiene un documento llamado Dream Diary, en el que el sistema genera automáticamente un "diario de sueños" que registra el proceso de organización de la memoria de forma narrativa, enfatizando la explicabilidad y la revisabilidad, en lugar de ser una base de datos opaca.
En neurociencia, existe una comprensión muy clásica: la información adquirida por los humanos durante el día entra primero en un sistema más orientado al almacenamiento temporal; durante el sueño, el cerebro vuelve a reproducir, consolida y limpia esta información, conservando lo importante y descartando lo sin sentido.
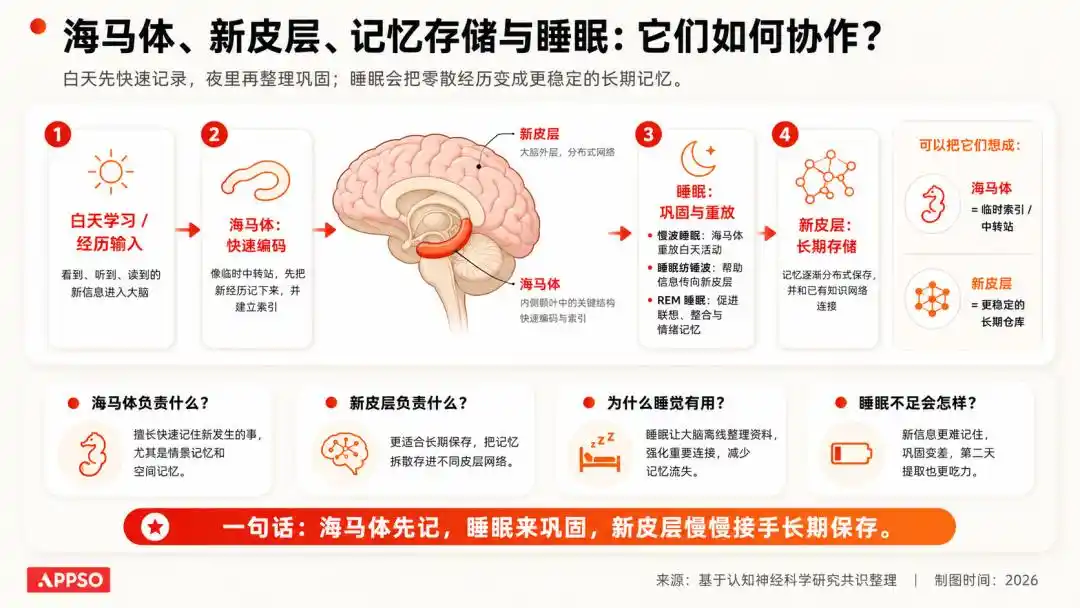
La imagen fue generada por IA
No recordaremos el color de cada coche en el camino al trabajo ayer, pero sí recordaremos cómo llegar a la oficina.
Estos sueños, escuchados, son realmente iguales a los sueños humanos; si se busca alguna diferencia, probablemente sea que cuando Claude sueña, todavía está consumiendo nuestros tokens.
Pero Anthropic y OpenClaw no eligieron llamarlo "optimización basada en sesiones" o "ajuste posterior a la tarea", nombres con enfoque técnico.
Después de todo, cuando esos nombres complejos se convierten directamente en «soñar», lo que sentimos ya no es una función del software, sino más bien una «vida digital con actividad interior».
La memoria de la IA es contexto trivial.
Dado que se mencionó "soñar", no se puede omitir su condición previa: la memoria (Memory).
En el último período, la palabra más popular en el mundo de la IA pasó de la ingeniería de prompts a la ingeniería de contexto, ingeniería de Skill e ingeniería de Harness, pero independientemente de los cambios, la ingeniería de contexto sigue siendo la más valiosa en la actualidad.
Las capas que se superponen: indicaciones del sistema, entrada del usuario, conversaciones a corto plazo, memoria a largo plazo, documentos recuperados, salidas de llamadas a herramientas y habilidades, y el estado actual del usuario, constituyen el «contexto» que realmente utiliza el agente.
Hacer que el agente pueda recordar más y almacenar información más útil ha sido un desafío durante mucho tiempo.
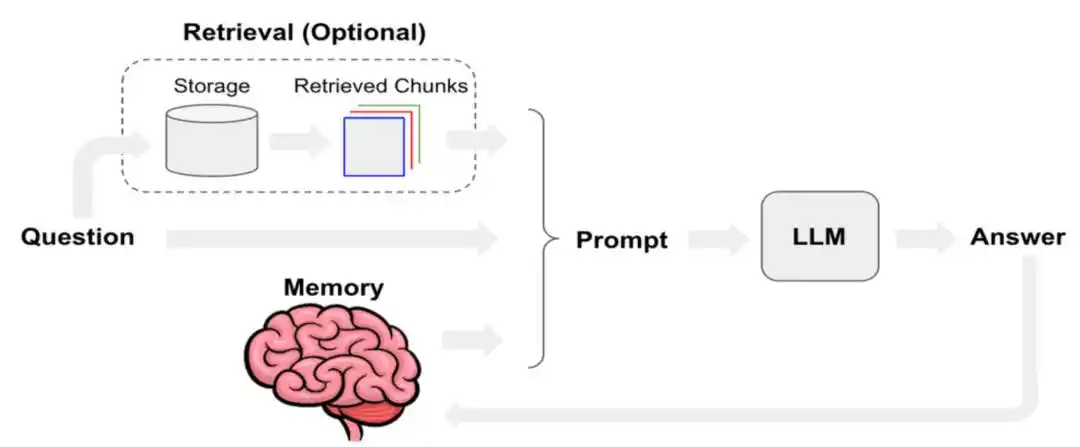
Manus publicó un blog técnico el año pasado que explicaba cómo Manus optimiza la ingeniería de contexto. En él se menciona que se define la tasa de aciertos del KV-Cache como uno de los indicadores individuales más importantes para los agentes de IA en entornos de producción. Al mismo tiempo, en el nivel de llamadas a herramientas, se prioriza el «enmascaramiento» en lugar de la «eliminación»; así como el uso del sistema de archivos como contexto definitivo.
Para comprender lo que se denomina KV Cache (cache de clave-valor), podemos imaginar un modelo grande como un paciente con un trastorno obsesivo-compulsivo extremo que solo puede leer una palabra a la vez.
Cuando procesa una oración, calcula un vector Key (clave) y un vector Value (valor) para cada token generado. Para evitar recalcularlos cada vez, almacena estos pares clave-valor (K, V), lo que se conoce como KV Cache.
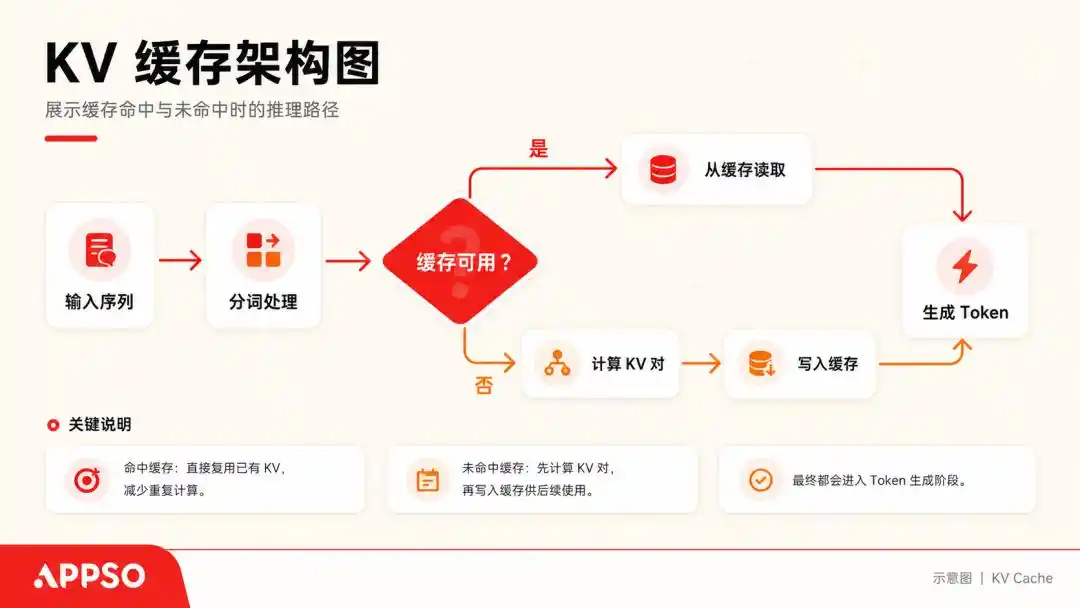
KV Cache (cache de clave-valor) es una técnica de aceleración subyacente utilizada por modelos grandes al generar texto, que intercambia espacio por tiempo. El cache permite que el modelo, al predecir la siguiente palabra, no necesite recalcular todas las palabras anteriores. Imagen generada por IA.
Mientras la conversación continúe, la caché KV se almacenará continuamente. En general, al enfrentarse a modelos grandes con contextos de hasta 128k, un modelo de 70 mil millones de parámetros que procese un contexto completo de 128k consumirá solamente la caché KV hasta 64 GB de memoria VRAM.
Por eso, la ventana de contexto de la mayoría de los modelos actualmente es de hasta un millón.
Ayer, la nueva empresa Subquadratic, que recibió una ronda de financiación semilla de 29 millones de dólares, lanzó en X el nuevo modelo SubQ, enfocado en contextos más largos.

SubQ afirma admitir un contexto de hasta 12 millones de tokens, el contexto más grande actualmente disponible en todos los modelos grandes.
Aunque aún no existe un paper técnico ni documentación del modelo, el video de presentación menciona que la línea principal de tecnología de SubQ pasa de la «atención densa» tradicional de Transformer a una arquitectura de «subcuadrática / lineal» con atención dispersa. Esta nueva arquitectura tiene el potencial de resolver el problema del costo computacional que se dispara con contextos más largos.

Los resultados de prueba también son bastante agresivos: con 1 millón de tokens, la velocidad aumenta más de 50 veces y los costos se reducen más de 50 veces; con 12 millones de tokens, la demanda de potencia de cómputo puede reducirse hasta 1000 veces en comparación con los modelos de vanguardia.
En la benchmark de contexto largo RULER 128K, Subquadratic afirma que SubQ logra un 95% de precisión con un costo de 8 dólares, en comparación con el 94% de precisión y un costo aproximado de 2600 dólares de Claude Opus, lo que representa una reducción de costos de aproximadamente 300 veces.
O amplía la ventana de contexto, o haz que el modelo aprenda a soñar y descarte algunas cosas.
Por eso, productos de agentes como Anthropic ahora deben implementar Dreaming. Bajo ventanas de contexto limitadas, una IA más inteligente no puede depender solo de insertar más contenido; necesita ser estratégica.
Admitir que las máquinas son solo máquinas es más difícil de lo que se imagina
Al comprender el mecanismo de los sueños y la memoria de la IA, tal vez podamos conocer la relación entre ella y las actividades humanas.
Pero juntar todas estas palabras que las empresas de IA han creado para usar en máquinas: el thinking (pensamiento) de OpenAI, la memory (memoria) y la hallucination (ilusión) del sector, el dreaming (soñar) de Anthropic en esta ocasión, y las virtudes y la sabiduría de la constitución de Anthropic.
Podemos ver que las empresas de IA no solo venden productos; están reclamando la propiedad de los términos dentro del concepto de "ser humano". Cada vez que se apropian de una palabra, la frontera entre máquina y humano se vuelve más borrosa.

El lenguaje moldea las expectativas, las expectativas moldean la tolerancia, y la tolerancia determina cuánto estamos dispuestos a entregarle. Es una cadena larga, pero el punto de partida son las palabras inofensivas del evento de lanzamiento.
Una influencia más sutil es la asignación de responsabilidad. Cuando se describe a las herramientas como entidades que «piensan», «recuerdan» o tienen «valores», al surgir problemas, tendemos naturalmente a considerarlas como «agentes independientes» y a responsabilizarlas, creyendo que esta IA necesita ser «educada», «depurada» o «calibrada».
Lo que realmente debería cuestionarse es la empresa que implementó este programa en nuestro flujo de trabajo y el equipo de producto que escribió la palabra «dreaming». Al cambiar la palabra, también cambia la persona que se sienta en el banquillo de los acusados.
Y mientras observamos una máquina que «piensa», «recuerda» y ahora también «sueña», comenzamos a creer instintivamente que hay algo dentro. Porque reconocer que es solo una máquina hace que desaparezca la sensación de «estoy hablando con un ser que piensa», volviendo a una relación fría y mecánica.

Función de sueño despierto | Imagen generada por IA
Ya lo pensé: Dreaming, soñar, trata el contenido del pasado, y a continuación, las empresas de IA lanzarán Daydreaming, el sueño despierto, para ensayar el futuro.
La idea es que, durante momentos de ensueño o distracción, el agente, en estado activo, utilice una pequeña parte de su capacidad de cómputo ociosa, combinada con el proyecto actual, para realizar generación exploratoria y prepararse para tareas futuras posibles.
Este artículo proviene del canal de WeChat "APPSO", autor: APPSO, que descubre productos del mañana