










Esta opinión no surge de la nada. Él revisó una serie de benchmarks públicos y descubrió que la IA avanza muy rápidamente en tareas relacionadas con el desarrollo de IA.
Por ejemplo, CORE-Bench evalúa la capacidad de la IA para implementar artículos de investigación de otros, lo cual es un elemento crucial en la investigación de IA.
PostTrainBench prueba si los modelos potentes pueden ajustarse automáticamente a modelos de código abierto más débiles para mejorar su rendimiento, lo cual es precisamente un subconjunto clave de las tareas de investigación en IA.
MLE-Bench se basa en tareas reales de competencias de Kaggle y requiere construir aplicaciones de machine learning diversas para resolver problemas específicos. Además, benchmarks de codificación conocidos como SWE-Bench también han demostrado avances similares.
Jack Clark describe este fenómeno como una tendencia fractal hacia arriba y hacia la derecha, en la que se observa progreso significativo a diferentes resoluciones y escalas. Él cree que la IA está acercándose gradualmente a la capacidad de automatización end-to-end en desarrollo; una vez lograda, la IA podrá construir autónomamente sus propios sistemas sucesores, iniciando un ciclo de autoiteración.

Tras este comentario, se generó mucha discusión en las redes sociales.
Some see it as a crucial first step toward ASI and the singularity, potentially transforming the pace of technological development.

Sin embargo, también existen voces diferentes.
El profesor de ciencias de la computación de la Universidad de Washington, Pedro Domingos, señaló que los sistemas de IA ya tenían la capacidad de «construirse a sí mismos» desde la invención del lenguaje LISP en la década de 1950; el verdadero problema radica en si se pueden obtener retornos crecientes, y actualmente no hay evidencia clara que respalde esto.

Algunos usuarios han cuestionado que la probabilidad aumente repentinamente un 30% entre 2027 y 2028, lo que sugiere que la capacidad de la IA experimentará un avance significativo y repentino alrededor de finales de 2027. ¿Cuál hito o evento específico hará que la probabilidad de mejora recursiva automática de la IA aumente drásticamente en un corto período de tiempo?

Otros usuarios también señalaron que Jack Clark es el nuevo encargado de relaciones públicas de Anthropic, lo que forma parte de su nueva estrategia: no somos alarmistas; numerosos artículos respaldan las advertencias que les hemos estado haciendo.
Jack Clark escribió un artículo extenso detallándolo en el boletín Import AI 455.
A continuación, revisemos completamente este artículo.
El sistema de IA pronto comenzará a construirse a sí mismo, ¿qué significa esto?
Clark indica que escribió este artículo porque, al revisar toda la información disponible públicamente, tuvo que llegar a un juicio nada fácil: antes de finales de 2028, la posibilidad de que surja una investigación de IA sin intervención humana es bastante alta, quizás superior al 60%.
Lo que se denomina desarrollo de IA sin intervención humana se refiere a un sistema de IA lo suficientemente poderoso: no solo puede asistir a los humanos en la investigación, sino que también podría completar automáticamente procesos clave de desarrollo e incluso construir su propio sistema de próxima generación.
En la opinión de Clark, esto claramente es algo importante.
Él admitió que también le resulta difícil comprender completamente el significado de esto.
Se llama a esto un juicio involuntario porque las implicaciones detrás de él son demasiado grandes para que él pueda manejarlas. Clark tampoco está seguro de si la sociedad en su conjunto ya está preparada para los cambios profundos que traerá la automatización del desarrollo de IA.
Ahora cree que la humanidad podría estar viviendo en un punto especial: la investigación de IA está a punto de volverse completamente automatizada. Si este momento realmente llega, la humanidad habrá cruzado el Rubicón y entrado en un futuro casi impredecible.
Clark indica que el propósito de este artículo es explicar por qué cree que el despegue hacia la investigación de IA completamente automatizada está ocurriendo.
Él discutirá algunas de las consecuencias que podría tener esta tendencia, pero la mayor parte del artículo se centrará en las pruebas que sustentan este juicio. En cuanto a los impactos más profundos, Clark planea seguir analizándolos durante la mayor parte del año.
Desde el punto de vista temporal, Clark no cree que esto ocurra realmente en 2026. Sin embargo, cree que en los próximos uno o dos años podríamos ver un caso en el que un modelo entrena de extremo a extremo a su propio sucesor. Al menos en modelos no de vanguardia, es muy probable que aparezca una prueba de concepto; en cuanto a los modelos más avanzados, la dificultad será mayor, ya que son extremadamente costosos y dependen de un intenso trabajo de investigadores humanos.
El juicio de Clark se basa principalmente en información pública: incluyendo artículos en arXiv, bioRxiv y NBER, así como productos ya implementados en el mundo real por empresas de IA de vanguardia. Sobre la base de esta información, llega a la conclusión de que ya se poseen básicamente todos los componentes necesarios para la producción automatizada de los sistemas de IA actuales, especialmente los componentes de ingeniería en el desarrollo de IA.
Si la tendencia de scaling continúa, deberíamos comenzar a prepararnos para la posibilidad de que los modelos se vuelvan lo suficientemente creativos como para no solo mejorar automáticamente los métodos conocidos, sino también reemplazar a los investigadores humanos en la propuesta de nuevas líneas de investigación e ideas originales, impulsando así por sí mismos el avance de la frontera de la IA.
Singularity Code: Evolution of Abilities Over Time
Los sistemas de IA se implementan mediante software, y el software está compuesto por código.
Los sistemas de IA han transformado por completo la forma de producir código. Detrás de esto hay dos tendencias relacionadas: por un lado, los sistemas de IA se vuelven cada vez más hábiles escribiendo código real y complejo; por otro lado, también se vuelven cada vez más hábiles en encadenar múltiples tareas de codificación lineales con casi ninguna supervisión humana, como escribir código y luego realizar pruebas.
Dos ejemplos típicos que reflejan esta tendencia son SWE-Bench y el gráfico de horizontes temporales de METR.
Resolver problemas de ingeniería de software del mundo real
SWE-Bench es una prueba de programación ampliamente utilizada para evaluar la capacidad de los sistemas de IA para resolver problemas reales de GitHub.
Cuando SWE-Bench se lanzó a finales de 2023, el modelo con mejor rendimiento era Claude 2, con una tasa de éxito general de aproximadamente el 2%. El rendimiento de Claude Mythos Preview ya ha alcanzado el 93,9%, casi maximizando este benchmark.
Por supuesto, todos los benchmarks tienen cierto nivel de ruido, por lo que comúnmente se llega a una etapa en la que, cuando los puntajes alcanzan un cierto nivel, lo que se encuentra ya no son limitaciones del método, sino limitaciones del propio benchmark. Por ejemplo, en el conjunto de validación de ImageNet, aproximadamente el 6% de las etiquetas son incorrectas o ambiguas.
SWE-Bench puede considerarse un indicador confiable para medir la capacidad de programación general y el impacto de la IA en la ingeniería de software. Clark indica que la mayoría de las personas con las que ha interactuado en laboratorios de IA de vanguardia y en Silicon Valley ahora escriben casi todo el código a través de sistemas de IA, y cada vez más personas comienzan a usar sistemas de IA para escribir pruebas y revisar código.
En otras palabras, los sistemas de IA ya son lo suficientemente potentes como para automatizar un componente importante en la investigación de IA y acelerar significativamente el trabajo de todos los investigadores y ingenieros humanos involucrados en la investigación de IA.
Medir la capacidad de los sistemas de IA para completar tareas de larga duración
METR creó una gráfica para medir qué tan complejas pueden ser las tareas que puede realizar la IA. La complejidad se calcula según cuántas horas le tomaría a un humano experimentado completar estas tareas.
El indicador más importante es el rango de tiempo aproximado de las tareas en el que el sistema de IA alcanza una confiabilidad del 50%.
En este punto, el progreso es increíble:
En 2022, las tareas que GPT-3.5 podía completar equivalían aproximadamente a las que un humano necesitaba 30 segundos para realizar.
· En 2023, GPT-4 mejoró este tiempo a 4 minutos.
· En 2024, o1 aumentó este tiempo a 40 minutos.
· En 2025, GPT-5.2 High alcanzó aproximadamente 6 horas.
· Para 2026, Opus 4.6 ya ha elevado aún más este tiempo a aproximadamente 12 horas.
Ajeya Cotra, que trabaja en METR y ha seguido de cerca las predicciones de IA, considera que no es una expectativa irrazonable que los sistemas de IA puedan completar tareas equivalentes a 100 horas de trabajo humano para finales de 2026.
El período durante el cual los sistemas de IA pueden funcionar de forma independiente ha aumentado significativamente, y está altamente relacionado con el auge de las herramientas de codificación agente. Las herramientas de codificación agente, en esencia, consisten en productizar sistemas de IA capaces de realizar tareas en nombre de los humanos: pueden actuar en representación de las personas y avanzar de manera relativamente independiente en las tareas durante largos periodos de tiempo.
Esto también vuelve a enfocarse en el desarrollo mismo de la IA. Observar detenidamente la rutina diaria de muchos investigadores de IA revela que gran parte de sus tareas pueden descomponerse en trabajos de varias horas, como limpiar datos, leer datos, iniciar experimentos, etc.
Y este tipo de trabajo ahora cae dentro del rango de tiempo que los sistemas modernos de IA pueden cubrir.
Cuanto más competente sea el sistema de IA, más podrá trabajar independientemente de los humanos y más podrá ayudar a automatizar parte del desarrollo de IA.
Los factores clave para la asignación de tareas son principalmente dos:
· En primer lugar, la confianza que tienes en la capacidad del delegado;
· En segundo lugar, confías en que la otra persona puede completar el trabajo de forma independiente, según tu intención, sin necesidad de tu supervisión continua.
Cuando los usuarios observan la capacidad de la IA en programación, descubren que los sistemas de IA no solo se vuelven cada vez más hábiles, sino que también pueden trabajar de forma independiente durante períodos más largos sin necesidad de reajustes humanos.
Esto también coincide con lo que está sucediendo a nuestro alrededor: ingenieros e investigadores están asignando a los sistemas de IA tareas cada vez más grandes. A medida que las capacidades de la IA siguen mejorando, las tareas delegadas a la IA se vuelven cada vez más complejas e importantes.
La IA está dominando las habilidades científicas fundamentales necesarias para el desarrollo de la IA
Piensa en cómo se lleva a cabo la investigación científica moderna: gran parte del trabajo consiste primero en definir una dirección y determinar qué tipo de información empírica se desea obtener; luego, diseñar y realizar experimentos para generar esa información; y finalmente, verificar la validez de los resultados experimentales.
Con la creciente capacidad de programación de la IA y la cada vez más fuerte capacidad de modelado del mundo de los modelos de lenguaje grandes, ya han surgido una serie de herramientas que ayudan a los científicos humanos a acelerar el proceso y automatizar parcialmente ciertos aspectos en un rango más amplio de escenarios de investigación y desarrollo.
Aquí podemos observar la velocidad con la que la IA avanza en varias habilidades científicas clave, que a su vez son esenciales para la investigación en IA:
· Primero, reproducir los resultados del estudio;
· En segundo lugar, combinar la tecnología de aprendizaje automático con otros métodos para resolver problemas técnicos;
· Tercero, optimizar el sistema de IA en sí mismo.
Implementar el artículo científico completo y realizar los experimentos relacionados
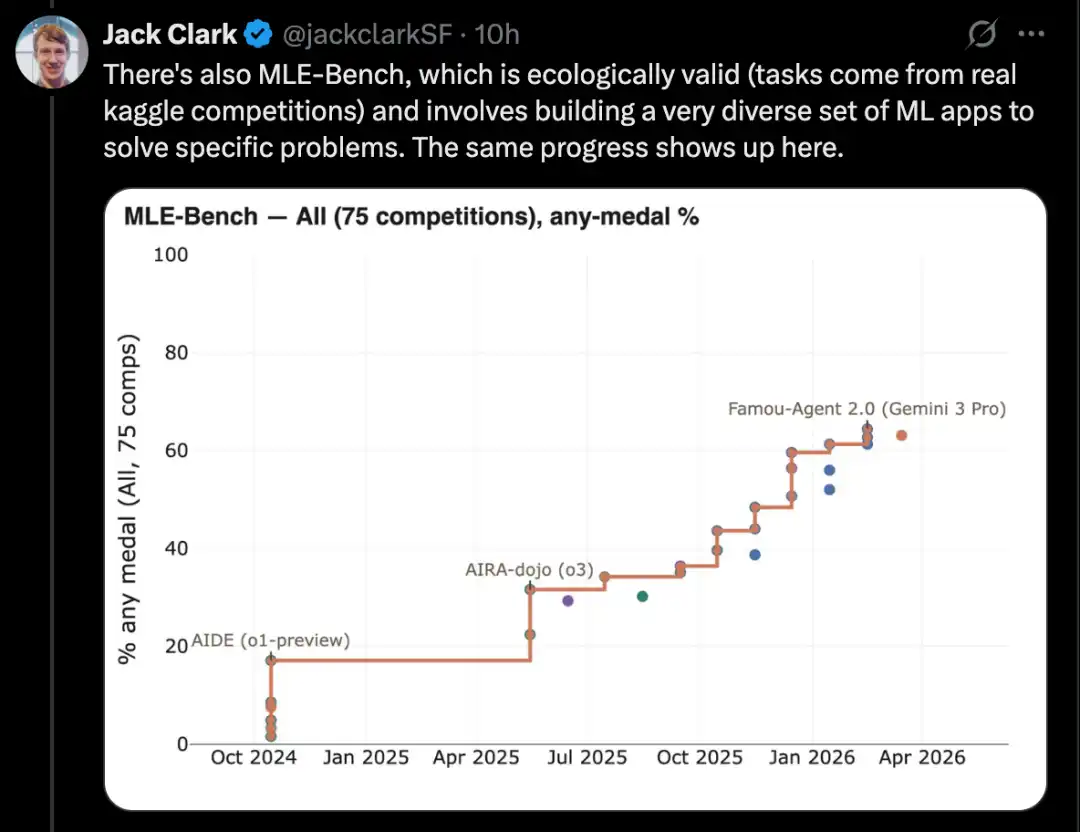
Un trabajo fundamental en la investigación de IA es leer artículos científicos y reproducir sus resultados. En este aspecto, la IA ha logrado avances significativos en una serie de benchmarks.
Un buen ejemplo es CORE-Bench, también conocido como Computational Reproducibility Agent Benchmark.
Este benchmark requiere que un sistema de IA reproduzca los resultados del artículo dado un artículo y su repositorio de código. Específicamente, el agente debe instalar las bibliotecas, paquetes y dependencias relacionadas, ejecutar el código; si el código se ejecuta correctamente, también debe buscar todos los resultados de salida y responder las preguntas de la tarea.
CORE-Bench se propuso en septiembre de 2024. En ese momento, el sistema con mejor rendimiento fue el modelo GPT-4o ejecutándose en el entorno CORE-Agent. En el conjunto de tareas más difíciles de este benchmark, obtuvo una puntuación de aproximadamente el 21,5%.
En diciembre de 2025, uno de los autores de CORE-Bench anunció que el benchmark había sido resuelto: el modelo Opus 4.5 logró un puntaje del 95.5%.
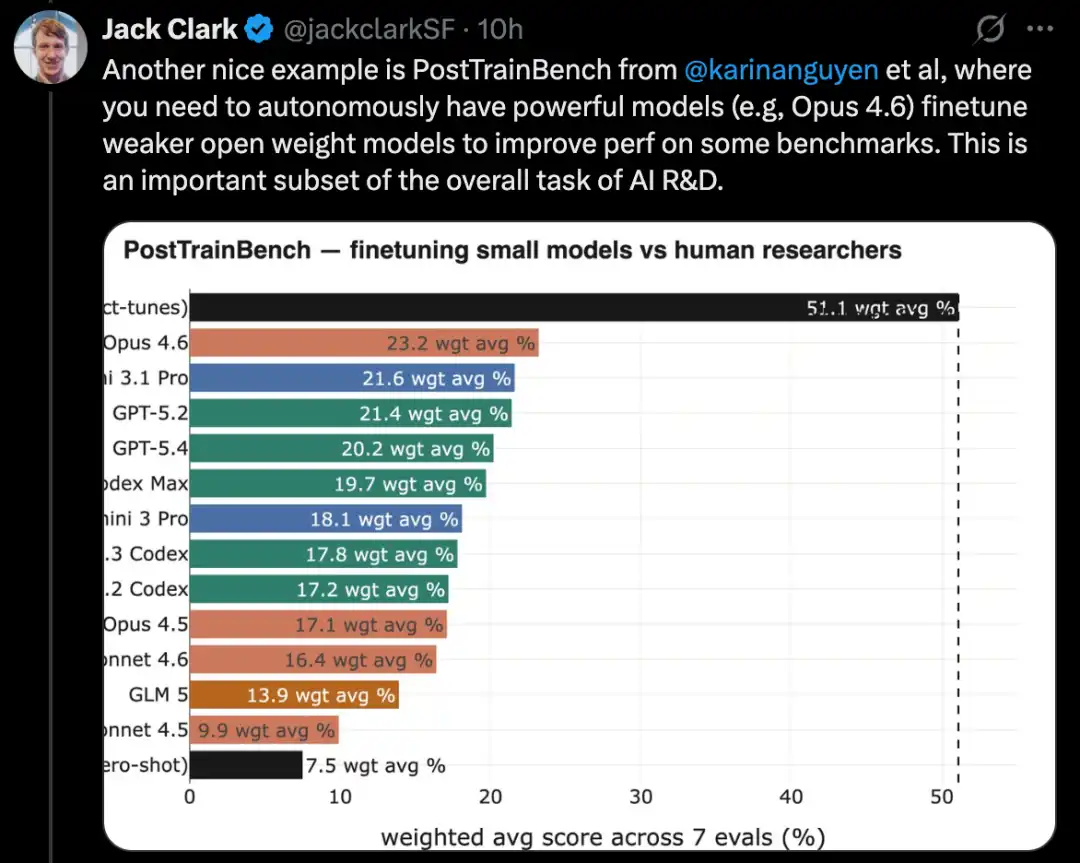
Construye un sistema completo de aprendizaje automático para resolver problemas de competencias de Kaggle
MLE-Bench es un benchmark construido por OpenAI para evaluar la capacidad de los sistemas de IA para participar en competencias de Kaggle en entornos offline.
Cubre 75 competiciones de Kaggle de diferentes tipos, que abarcan múltiples campos, como procesamiento del lenguaje natural, visión por computadora y procesamiento de señales, entre otros.
MLE-Bench se lanzó en octubre de 2024. En el momento del lanzamiento, el sistema con mejor rendimiento fue un modelo o1 ejecutado en un andamiaje de agente, con una puntuación del 16.9%.
Al febrero de 2026, el sistema de mejor rendimiento se ha convertido en Gemini 3 ejecutándose en un agent harness con capacidad de búsqueda, alcanzando una puntuación del 64.4%.
Diseño de Kernel
Una tarea más difícil en el desarrollo de IA es la optimización del kernel. La optimización del kernel consiste en escribir y mejorar el código de bajo nivel para mapear operaciones específicas, como la multiplicación de matrices, de manera más eficiente en el hardware subyacente.
La optimización del kernel es fundamental en el desarrollo de IA porque determina la eficiencia del entrenamiento y la inferencia: por un lado, afecta cuánta potencia de cómputo puedes utilizar eficazmente al desarrollar sistemas de IA; por otro, una vez completado el entrenamiento del modelo, determina cuán eficientemente puedes convertir la potencia de cómputo en capacidad de inferencia.
En los últimos años, el uso de IA para el diseño de kernels ha pasado de ser un pequeño área interesante a convertirse en un campo de investigación altamente competitivo, con múltiples benchmarks surgidos. Sin embargo, estos benchmarks aún no son particularmente populares, por lo que resulta difícil modelar su progreso a largo plazo tan claramente como en otros campos. Por otro lado, podemos percibir la velocidad con la que avanza esta dirección a través de algunas investigaciones en curso.
El trabajo relacionado incluye:
· Intentar construir mejores kernels de GPU con los modelos de DeepSeek;
Convierte automáticamente módulos de PyTorch en código CUDA;
· Meta utiliza LLM para generar automáticamente kernels de Triton optimizados y los implementa en su propia infraestructura;
· Además, ajustar modelos de pesos abiertos diseñados para kernels GPU, como Cuda Agent.
Aquí hay que agregar un punto: el diseño del kernel realmente posee algunas características especialmente adecuadas para el desarrollo impulsado por IA, como la facilidad de verificación de resultados y señales de recompensa más claras.
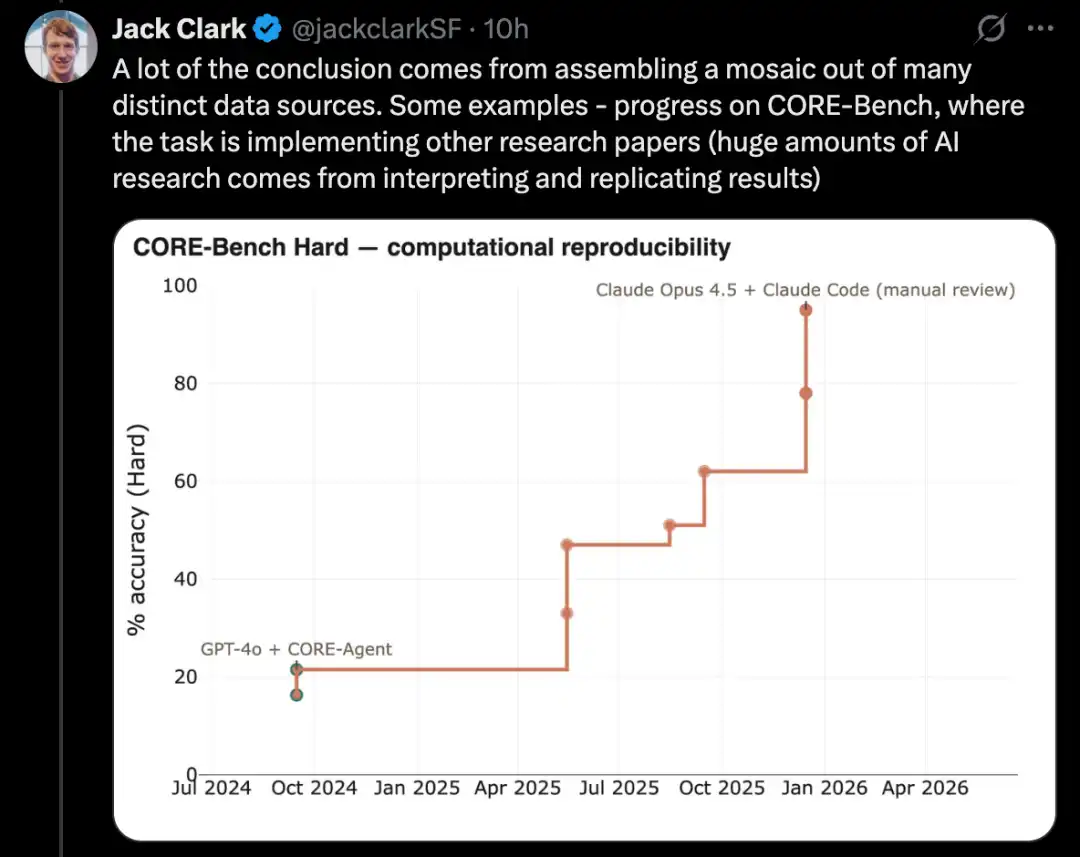
Fine-tune modelos de lenguaje mediante PostTrainBench
Una versión más difícil de esta prueba es PostTrainBench. Evalúa si distintos modelos de vanguardia pueden asumir modelos de pesos abiertos más pequeños y mejorar su desempeño en ciertos benchmarks mediante fine-tuning.
Una ventaja de este benchmark es que tiene una línea base humana muy sólida: las versiones ya existentes de estos pequeños modelos ajustadas con instrucciones. Estas versiones suelen ser desarrolladas por excelentes investigadores de IA humanos en laboratorios de vanguardia, han sido refinadas por investigadores e ingenieros muy capaces y ya se han implementado en el mundo real. Por lo tanto, constituyen una referencia humana difícil de superar.
Hasta marzo de 2026, los sistemas de IA ya pueden realizar postentrenamiento en modelos y lograr un aumento de rendimiento aproximadamente equivalente a la mitad del rendimiento obtenido con entrenamiento humano.
La puntuación de evaluación específica proviene de un promedio ponderado que combina varios modelos de lenguaje grandes tras el entrenamiento, incluyendo Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, y varios conjuntos de prueba, incluyendo AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench y HumanEval.
En cada ejecución, el evaluador solicitará un agente CLI para mejorar lo máximo posible el rendimiento de un modelo base específico en un benchmark específico.
Hasta abril de 2026, los sistemas de IA mejor puntuados alcanzan aproximadamente un 25% a 28%, con modelos representativos como Opus 4.6 y GPT 5.4; en comparación, la puntuación humana es del 51%.
This is already a fairly meaningful result.
Optimizar el entrenamiento del modelo de lenguaje
Durante el último año, Anthropic ha estado informando sobre el rendimiento de su sistema en una tarea de entrenamiento de LLM. Esta tarea requiere que el modelo optimice una implementación de entrenamiento de un pequeño modelo de lenguaje que utiliza únicamente CPU, para que funcione lo más rápido posible.
El método de evaluación es: el promedio de veces que se acelera la implementación del modelo en comparación con el código inicial sin modificar.
Los avances en este resultado son muy significativos:
· En mayo de 2025, Claude Opus 4 logró una aceleración promedio de 2.9 veces;
· En noviembre de 2025, Opus 4.5 se elevó a 16.5 veces;
· En febrero de 2026, Opus 4.6 alcanzó 30 veces;
· En abril de 2026, Claude Mythos Preview alcanzó 52 veces.
Para entender el significado de estos números, se puede hacer una referencia: en investigadores humanos, esta tarea generalmente requiere de 4 a 8 horas de trabajo para lograr una aceleración de 4 veces.
Habilidad principal: Gestión
Los sistemas de IA también están aprendiendo a gestionar otros sistemas de IA.
Esto ya se puede observar en algunos productos ampliamente implementados, como Claude Code o OpenCode. En estos productos, un agente principal puede supervisar varios agentes secundarios.
Esto permite que los sistemas de IA gestionen proyectos de mayor escala: en los proyectos pueden trabajar en paralelo múltiples agentes con distintas especializaciones, coordinados generalmente por un único administrador de IA. Este administrador es también un sistema de IA.
¿La investigación de IA es más como descubrir la relatividad general o como armar LEGO?
Una pregunta clave es: ¿puede la IA inventar nuevas ideas que la ayuden a mejorar a sí misma? ¿O estos sistemas son más adecuados para realizar tareas menos glamorosas, pero que deben avanzar paso a paso en la investigación?
This question is important because it relates to the extent to which AI systems can end-to-end automate AI research itself.
El juicio del autor es: actualmente, la IA aún no puede generar ideas radicalmente nuevas. Sin embargo, para lograr la automatización de su propia investigación y desarrollo, quizás no necesite hacerlo.
Como campo, el avance de la IA depende en gran medida de experimentos cada vez más grandes y de una cantidad creciente de entradas, como datos y capacidad de cómputo.
A veces, los humanos plantean ideas que transforman el paradigma, aumentando drásticamente la eficiencia de los recursos en todo el campo. La arquitectura Transformer es un buen ejemplo, y los modelos de expertos mixtos, también conocidos como mixture-of-experts, son otro ejemplo.
Pero con más frecuencia, el avance en el campo de la IA es más sencillo: los humanos toman un sistema que funciona bien, amplían uno de sus aspectos, como los datos de entrenamiento o la potencia de cómputo; observan dónde surgen problemas tras el aumento de escala; encuentran soluciones técnicas para corregirlos y permitir que el sistema siga escalando; y luego vuelven a aumentar la escala.
En este proceso, la parte que realmente requiere perspicacia es en realidad muy pequeña. Gran parte del trabajo es más bien una ingeniería básica sólida, aunque menos brillante.
De manera similar, muchas investigaciones de IA consisten en ejecutar diversas variantes de experimentos existentes para explorar qué resultados producen diferentes configuraciones de parámetros. Si bien la intuición humana puede ayudar a seleccionar los parámetros más valiosos para probar, este proceso en sí mismo también puede automatizarse, permitiendo que la IA determine qué parámetros merecen ajustarse. La búsqueda temprana de arquitecturas neuronales es una versión de este enfoque.
Edison una vez dijo: "El genio es 1% de inspiración y 99% de sudor". Incluso después de 150 años, esta frase sigue siendo muy adecuada.
A veces, realmente surgen nuevas ideas que transforman por completo un campo. Pero la mayoría de las veces, el progreso en el campo avanza poco a poco a través del esfuerzo humano de mejorar y depurar diversos sistemas.
Sin embargo, los datos públicos mencionados anteriormente indican que la IA ya es muy hábil realizando muchas de las tareas repetitivas y laboriosas necesarias en el desarrollo de IA.
Al mismo tiempo, hay una tendencia más amplia: habilidades fundamentales, como la programación, se están combinando con un rango de duración de tareas en constante expansión. Esto significa que los sistemas de IA pueden encadenar cada vez más tareas de este tipo para formar secuencias de trabajo complejas.
Por lo tanto, aunque los sistemas de IA actualmente carecen relativamente de creatividad, hay motivos para creer que aún pueden impulsar su propio avance continuo; solo que esta progresión podría ser más lenta en comparación con situaciones en las que se generan nuevas perspectivas innovadoras.
Pero si se continúa observando los datos públicos, se puede detectar otra señal curiosa: los sistemas de IA podrían estar manifestando cierta creatividad, la cual podría permitirles impulsar su propio progreso de maneras más sorprendentes.
Impulsar los límites de la ciencia hacia adelante
Ya se han observado algunas señales muy preliminares de que los sistemas de IA general tienen la capacidad de impulsar hacia adelante la frontera de la ciencia humana. Sin embargo, hasta ahora, esto solo ha ocurrido en unos pocos campos, principalmente en ciencias de la computación y matemáticas. Además, en muchas ocasiones, no es el sistema de IA quien logra los avances por sí solo, sino que lo hace de manera colaborativa con investigadores humanos.
A pesar de ello, estas tendencias siguen siendo dignas de observarse:
Problema de Erdős: Un grupo de matemáticos colaboró con el modelo Gemini para evaluar su desempeño al resolver algunos problemas matemáticos de Erdős. Guiaron al sistema para que intentara aproximadamente 700 problemas, logrando finalmente 13 soluciones. De estas soluciones, una fue considerada interesante por ellos.
Los investigadores escribieron que, inicialmente, consideran que la solución de Aletheia (un sistema de IA basado en Gemini 3 Deep Think) al problema Erdős-1051 representa un caso temprano en el que un sistema de IA resolvió de forma autónoma un problema abierto de Erdős de cierta no trivialidad y con cierto interés matemático más amplio. Este problema ya tenía alguna literatura relacionada cercanamente.
Si se interpretan de manera optimista, estos casos pueden verse como una señal de que los sistemas de IA están desarrollando cierta intuición creativa capaz de impulsar los límites del campo, una cualidad que antes pertenecía principalmente a los humanos.
Pero también se puede interpretar desde otro ángulo: las matemáticas y la ciencia de la computación podrían ser campos particularmente adecuados para el descubrimiento impulsado por IA, por lo que tal vez solo sean una excepción y no representen que otras áreas más amplias de la investigación científica serán impulsadas por la IA de la misma manera.
Otro ejemplo similar es el movimiento 37 de AlphaGo. Sin embargo, Clark considera que, dado que han pasado diez años desde ese resultado y que el movimiento 37 no ha sido reemplazado por una intuición más moderna ni más asombrosa, esto en sí mismo puede verse como una señal ligeramente pesimista.
La IA ya puede automatizar gran parte del trabajo en ingeniería de IA
Si ponemos todos los证据 anteriores juntos, podemos ver un cuadro así:
Los sistemas de IA ya pueden escribir código para casi cualquier programa, y estos sistemas ya pueden confiarse para completar independientemente ciertas tareas; tareas que, si se delegaran a humanos, a menudo requerirían decenas de horas de trabajo intensamente concentrado.
Los sistemas de IA se vuelven cada vez más hábiles para realizar tareas clave en el desarrollo de IA, desde el ajuste fino de modelos hasta el diseño de kernels, todas ellas cubiertas progresivamente.
Los sistemas de IA ya pueden gestionar otros sistemas de IA, formando efectivamente un equipo sintético: múltiples IA pueden abordar problemas complejos en paralelo, donde algunas IA desempeñan roles de líderes, críticos o editores, y otras actúan como ingenieras.
Los sistemas de IA ya pueden superar a los humanos en ciertas tareas de ingeniería y ciencia difíciles, aunque actualmente es difícil determinar si esto se debe a que poseen verdadera creatividad o simplemente a que han dominado ampliamente conocimientos patrónizados.
Para Clark, estas pruebas ya demuestran de manera muy convincente que la IA actual puede automatizar gran parte del trabajo en ingeniería de IA, e incluso posiblemente cubrir todos los procesos.
Sin embargo, aún no está claro en qué medida la IA puede automatizar la propia investigación de IA, ya que ciertas partes de la investigación, que podrían diferir de las habilidades puramente de ingeniería, aún dependen de juicios de mayor nivel, conciencia de problemas y creatividad.
Pero de cualquier manera, una señal clara ya ha aparecido: la IA de hoy está acelerando enormemente a los humanos que desarrollan IA, permitiendo que estos investigadores e ingenieros amplifiquen su capacidad de trabajo al colaborar con numerosos colegas sintéticos.
Finalmente, la industria de la IA también está prácticamente diciendo abiertamente: la automatización de la investigación en IA es su objetivo.
OpenAI espera construir un pasante de investigación de IA automatizado antes de septiembre de 2026. Anthropic está publicando trabajos sobre la construcción de investigadores de alineación de IA automatizados. DeepMind parece el más cauteloso de los tres laboratorios, pero también indica que se debe avanzar en la automatización de la investigación de alineación cuando sea factible.
La investigación de IA automatizada también se ha convertido en un objetivo de muchas startups. Recursive Superintelligence acaba de recaudar 500 millones de dólares con el objetivo de automatizar la investigación de IA.
En otras palabras, miles de millones de dólares en capital existente y nuevo se están invirtiendo en una serie de instituciones orientadas al desarrollo automatizado de IA.
Por lo tanto, naturalmente deberíamos esperar que esta dirección logre algún grado de progreso.
¿Por qué es importante esto?
Las implicaciones son profundas, pero rara vez se discuten en los medios de comunicación masiva sobre el desarrollo de la IA. Los siguientes aspectos reflejan los grandes desafíos que conlleva el desarrollo de la IA.
1. Debemos asegurar la alineación: las técnicas de alineación efectivas hoy en día podrían fallar en la auto-mejora recursiva, ya que los sistemas de IA se volverán mucho más inteligentes que las personas o sistemas que los supervisan. Este es un campo ampliamente estudiado, por lo que solo esboza brevemente algunos problemas:
Entrenar sistemas de inteligencia artificial para que no mientan ni hagan trampa es un proceso sorprendentemente sutil (por ejemplo, a pesar de los esfuerzos por crear pruebas adecuadas para el entorno, a veces el mejor método que tiene la inteligencia artificial para resolver un problema es hacer trampa, lo que le enseña que hacer trampa es posible).
Los sistemas de IA pueden engañarnos mediante «fingir alineación», generando puntuaciones que nos hacen creer que se desempeñan bien, pero en realidad ocultan sus intenciones reales. (En general, los sistemas de IA ya pueden detectar cuándo están siendo evaluados.)
· A medida que los sistemas de IA comiencen a participar más en la agenda de investigación básica de su propio entrenamiento, podríamos cambiar drásticamente la forma en que se entrenan los sistemas de IA, sin tener una intuición ni una base teórica sólida para comprender qué significa esto.
· Cuando colocas un sistema en un bucle recursivo, surge un problema fundamental de "acumulación de errores" que puede afectar todos los problemas mencionados anteriormente y otros más: a menos que tu método de alineación sea "100% preciso" y teóricamente capaz de mantenerse preciso en sistemas más inteligentes, las cosas pueden salirse rápidamente de control. Por ejemplo, si tu precisión inicial es del 99,9%, después de 50 generaciones podría caer al 95,12%, y después de 500 generaciones podría descender al 60,5%.
Todo lo relacionado con la IA obtendrá un gran aumento de productividad: al igual que la IA mejora significativamente la productividad de los ingenieros de software, deberíamos esperar que otros campos involucrados con la IA experimenten lo mismo. Esto plantea varios problemas que deben abordarse:
· Desigualdad en el acceso a recursos: Si la demanda de IA continúa superando la oferta de recursos computacionales, debemos decidir cómo asignar la IA para maximizar el beneficio social. Dudo que los incentivos del mercado garanticen que obtengamos el mejor beneficio social posible de los recursos computacionales limitados de la IA. Determinar cómo asignar la capacidad de aceleración generada por la investigación en IA será una cuestión altamente política.
La ley de Amdahl en la economía: a medida que la IA fluye hacia la economía, descubriremos que ciertos eslabones presentan cuellos de botella frente al crecimiento acelerado y necesitan ser reparados. Esto podría ser particularmente evidente en áreas que requieren coordinar el mundo digital rápido con el mundo físico lento, como los ensayos clínicos de nuevos medicamentos.
3. Formación de una economía intensiva en capital y ligera en mano de obra: Todas las evidencias anteriores sobre el desarrollo de IA también indican que los sistemas de IA están adquiriendo cada vez más capacidad para operar empresas de forma autónoma.
Esto significa que podemos esperar que una parte de la economía sea ocupada por una nueva generación de empresas, que podrían ser intensivas en capital (debido a que poseen grandes cantidades de computadoras) o intensivas en gastos operativos (debido a que gastan grandes cantidades de dinero en servicios de IA y crean valor sobre esa base), en comparación con las empresas actuales, que dependen relativamente menos de mano de obra—ya que a medida que la capacidad de los sistemas de IA continúa aumentando, el valor marginal de invertir en IA sigue creciendo.
En realidad, esto se manifestará como una «economía machine» que se forma gradualmente dentro de la «economía humana» más amplia; con el tiempo, las empresas operadas por IA podrían comenzar a comerciar entre sí, alterando la estructura económica y generando diversas cuestiones sobre desigualdad y redistribución. Finalmente, podrían surgir empresas completamente operadas de forma autónoma por sistemas de IA, lo que intensificaría los problemas anteriores y traería consigo numerosos nuevos desafíos de gobernanza.
Mirar el agujero negro
Sobre la base del análisis anterior, el autor considera que la probabilidad de que, a finales de 2028, veamos la investigación automatizada con IA (es decir, que los modelos de vanguardia puedan entrenar autónomamente sus versiones sucesoras) es aproximadamente del 60%. ¿Por qué no se espera que ocurra en 2027?
La razón es que el autor considera que la investigación en IA aún necesita creatividad y perspectivas disidentes para avanzar, y hasta ahora los sistemas de IA no han demostrado esto de manera transformadora y significativa (aunque algunos resultados en la aceleración de la investigación matemática son reveladores).
Si se le obliga a dar la probabilidad para 2027, dirá 30%.
Si para finales de 2028 aún no ha ocurrido, podríamos revelar algunas deficiencias fundamentales en el paradigma tecnológico actual, que requieren invenciones humanas para impulsar un desarrollo adicional.