










এই দৃশ্যটি কল্পনা করুন:
আপনি একটি এআই এজেন্টকে একটি কোড বাগ ঠিক করতে বলেছেন। এটি প্রকল্পটি খুলে ২০টি ফাইল পড়ল, কিছু পরিবর্তন করল, টেস্ট চালাল, কিন্তু ফেল করল, আবার পরিবর্তন করল, আবার টেস্ট চালাল, এখনও ফেল করল... এভাবে দশটিরও বেশি রাউন্ড ঘুরে বেড়াল, শেষপর্যন্ত—এখনও ঠিক হয়নি।
আপনি কম্পিউটার বন্ধ করে একটি নিঃশ্বাস ফেললেন। তারপর আপনি API বিল পেলেন।
উপরের সংখ্যাগুলি আপনাকে শ্বাস নিতে বাধ্য করতে পারে—AI এজেন্ট বিদেশি অফিসিয়াল API-এর নিচে বাগ স্বয়ংক্রিয়ভাবে ঠিক করলে, প্রতিবার অনির্দিষ্ট টাস্কের জন্য লক্ষ লক্ষ টোকেন ব্যয় হয়, যার খরচ হতে পারে দশ থেকে একশো ডলারেরও বেশি।
2026 এর এপ্রিলে, স্ট্যানফোর্ড, এমআইটি, মিশিগান বিশ্ববিদ্যালয় ইত্যাদির একটি যৌথ গবেষণা পেপার প্রথমবারের মতো কোড টাস্কে AI এজেন্টের “খরচের ব্ল্যাক বক্স” খুলে দেয়—টাকা কোথায় খরচ হচ্ছে, এটি কি মূল্যবান, এবং এটি কি আগে থেকেই পূর্বানুমান করা যায়, উত্তরটি অবাক করে দেয়।
প্রথম পাওয়া: এজেন্ট কোড লেখার খরচের হার সাধারণ AI কথোপকথনের চেয়ে 1000 গুণ বেশি
অনেকে মনে করতে পারেন যে, AI কে আপনার জন্য কোড লেখার জন্য ব্যবহার করা এবং AI এর সাথে কোড নিয়ে কথা বলা একই পরিমাণ খরচ হবে।
পেপারটি তুলনামূলক প্রদর্শন দেয়:
এজেন্টিক কোডিং টাস্কের টোকেন খরচ সাধারণ কোড প্রশ্নোত্তর এবং কোড রিজনিং টাস্কের প্রায় 1000 গুণ।
পুরোপুরি তিনটি ক্ষমতার পার্থক্য।
এটা কেন হচ্ছে? পেপারটি একটি তথ্য উল্লেখ করেছে—টাকা কোড লেখার উপর নয়, বরং কোড পড়ার উপর খরচ হয়।
এখানে “পড়া” মানে মানুষ কোড পড়া নয়, বরং এজেন্ট তার কাজের সময় পুরো প্রকল্পের কনটেক্সট, ইতিহাসের অপারেশন রেকর্ড, এরর তথ্য, ফাইলের কনটেন্ট সবকিছু মডেলকে খাওয়ায়। প্রতিটি ডায়ালগ রাউন্ডের সাথে এই কনটেক্সট আরও একটি রাউন্ড দীর্ঘ হয়; আর মডেলটি Token সংখ্যা অনুযায়ী চার্জ করে—আপনি যত বেশি খাওয়াবেন, তত বেশি পরিশোধ করবেন।
একটা উদাহরণ দিই: এটা ঠিক তেমনই, যেন আপনি একজন মেকানিককে ডাকলেন, যে প্রতিবার ওয়েন্চ ঘুরানোর আগে আপনাকে পুরো ভবনের প্ল্যান শুরু থেকে শেষ পর্যন্ত পড়ে শোনাতে হয়—প্ল্যান পড়ার খরচ, স্ক্রু ঘোরানোর খরচের চেয়ে অনেক বেশি।
এই ঘটনাটিকে প্রবন্ধটি একটি বাক্যে সারাংশ করে: এজেন্টের খরচ পরিচালনা করে আউটপুট টোকেন নয়, বরং ইনপুট টোকেনের সূচকীয় বৃদ্ধি।
দ্বিতীয় পর্যবেক্ষণ: একই বাগ দুবার চালানোর সময় খরচ দ্বিগুণ পার্থক্য হতে পারে—এবং যত বেশি দামি বাগ, তত অস্থির
আরও বিরক্তিকর বিষয় হলো র্যান্ডমনেস।
গবেষকরা একই এজেন্টকে একই কাজে চারবার চালানোর ফলে পাওয়া গেল:
- বিভিন্ন কাজের মধ্যে, সবচেয়ে ব্যয়বহুল কাজটি সবচেয়ে সস্তা কাজের চেয়ে প্রায় 70 লাখ টোকেন ব্যয় করে (চিত্র 2a)
- একই মডেল এবং একই কাজের জন্য একাধিক রানে, সবচেয়ে ব্যয়বহুল রানটি প্রায় সবচেয়ে সস্তা রানের দ্বিগুণ (চিত্র 2b)
- এবং যদি একই কাজের জন্য বিভিন্ন মডেলের তুলনা করা হয়, তবে সর্বোচ্চ এবং সর্বনিম্ন খরচের মধ্যে 30 গুণ পর্যন্ত পার্থক্য হতে পারে।
শেষ সংখ্যাটি বিশেষভাবে মনোযোগ দেওয়ার মতো: এর অর্থ হল সঠিক মডেল এবং ভুল মডেল বাছার মধ্যে খরচের পার্থক্য কেবল “কিছুটা বেশি” নয়, বরং “এক ক্রম বেশি”।
আরও বেশি খরচ করা মানে ভালো কাজ করা নয়।
গবেষণাপত্রটি একটি "উল্টো U আকৃতির" বক্ররেখা আবিষ্কার করেছে:
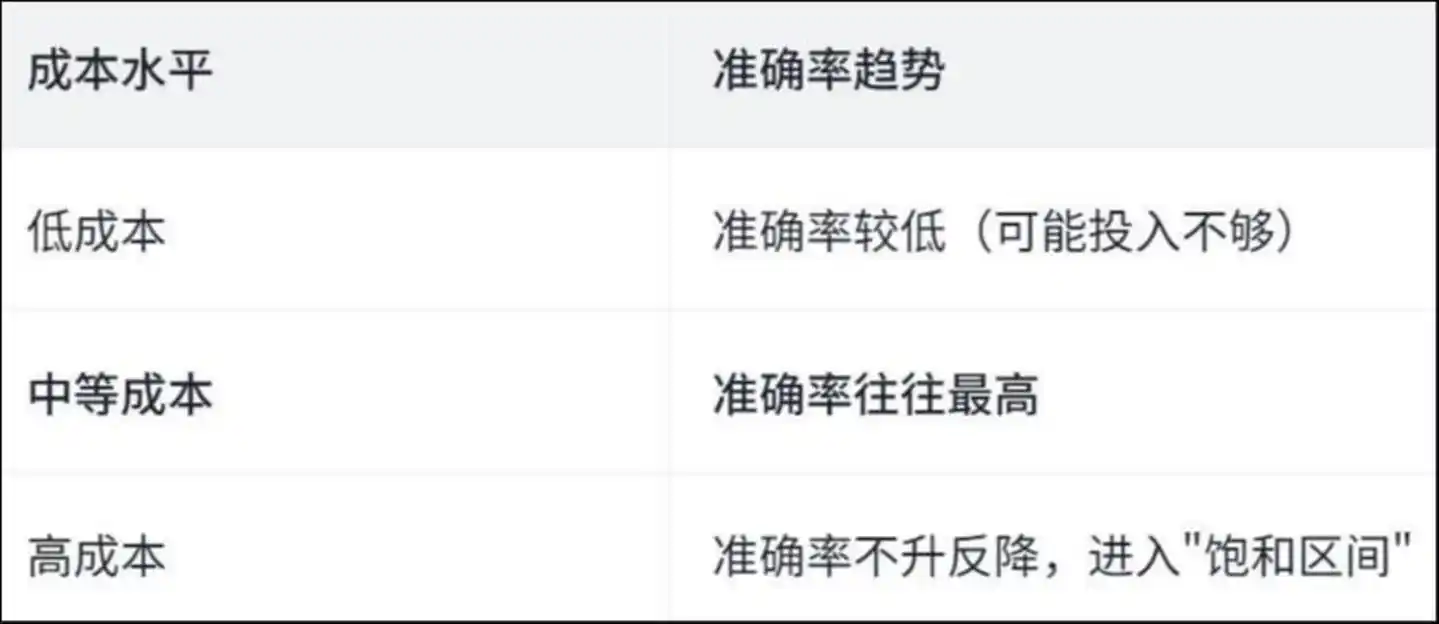
খরচের স্তর সঠিকতার প্রবণতা কম খরচ: সঠিকতা কম (সম্ভবত পর্যাপ্ত বিনিয়োগ নেই) মধ্যম খরচ: সঠিকতা প্রায়শই সর্বোচ্চ উচ্চ খরচ: সঠিকতা বৃদ্ধি পায় না, বরং হ্রাস পায়, "সম্পৃক্ত অঞ্চল" এ প্রবেশ করে
এটা কেন হচ্ছে? পেপারটি এজেন্টের নির্দিষ্ট অপারেশন বিশ্লেষণ করে উত্তর দিয়েছে—
উচ্চ খরচের পরিস্থিতিতে, এজেন্ট অসংখ্য সময় পুনরাবৃত্তির কাজে ব্যয় করে।
অধ্যয়নে দেখা গেছে যে, উচ্চ খরচের পরিস্থিতিতে প্রায় 50% ফাইল দেখা এবং ফাইল সংশোধনের অপারেশন পুনরাবৃত্তি হয়—অর্থাৎ, এজেন্ট একই ফাইলটি বারবার পড়ছে এবং একই কোড লাইনটি বারবার পরিবর্তন করছে, যেন কেউ একটি ঘরের মধ্যে ঘুরছে, ঘুরতে ঘুরতে মাথা ঘুরছে, আর মাথা ঘুরলেই আবার ঘুরছে।
টাকা সমস্যা সমাধানে খরচ হয়নি, হারিয়ে যাওয়ায় খরচ হয়েছে।
তিনতম প্রত্যক্ষীকরণ: মডেলগুলির মধ্যে "শক্তি দক্ষতা" অসীম পার্থক্য—GPT-5 সবচেয়ে কম শক্তি খরচ করে, কিছু মডেল 1.5 মিলিয়ন টোকেন বেশি ব্যয় করে।
পেপারটি শিল্প মানদণ্ডের SWE-bench Verified (500টি বাস্তব GitHub Issue) এর উপর আটটি অগ্রগামী বড় মডেলের এজেন্ট পারফরম্যান্স পরীক্ষা করেছে। ডলারে রূপান্তরিত করলে, টোকেন দক্ষতা বেশি মডেলগুলি প্রতিটি টাস্কের জন্য কয়েক দশক বেশি খরচ করতে পারে। এন্টারপ্রাইজ-লেভেলের অ্যাপ্লিকেশনে—একদিনে কয়েকশো টাস্ক চালানো—এই পার্থক্যটি বাস্তব টাকা-পয়সা।
একটি আরও আকর্ষণীয় আবিষ্কার হলো: টোকেন দক্ষতা মডেলের “অন্তর্নিহিত ব্যক্তিত্ব”, কাজের ফলাফল নয়।
গবেষকরা সমস্ত মডেল দ্বারা সফলভাবে সমাধানকৃত কাজগুলি (230টি) এবং সমস্ত মডেল দ্বারা ব্যর্থ হওয়া কাজগুলি (100টি) আলাদাভাবে তুলনা করে দেখেন যে মডেলগুলির আপেক্ষিক র্যাঙ্কিং প্রায় অপরিবর্তিত থাকে।
এটি ব্যাখ্যা করে: কিছু মডেল স্বাভাবিকভাবেই "বেশি কথা বলে", যা কাজের কঠিনতার সাথে তেমন সম্পর্কিত নয়।
একটি গভীর চিন্তার বিষয় হল: মডেলটির “স্টপ লস সচেতনতা” নেই।
যখন সমস্ত মডেলই অসাধ্য কাজে ব্যর্থ হয়, তখন আদর্শভাবে এজেন্টটিকে অতিরিক্ত খরচ এড়াতে শীঘ্রই বাতিল করা উচিত। কিন্তু বাস্তবতায়, মডেলগুলি ব্যর্থ কাজে আরও বেশি টোকেন ব্যয় করে—এগুলি “হার মানে” না, বরং অবিরতভাবে অনুসন্ধান, পুনরায় চেষ্টা এবং প্রসঙ্গ পুনরায় পড়ে, যেন একটি অয়েল লেভেল ইনডিকেটর ছাড়াই গাড়ি যা চলতে থাকে যতক্ষণ না এটি বন্ধ হয়ে যায়।
চতুর্থ আবিষ্কার: মানুষ যা কঠিন বলে মনে করে, এজেন্ট তা ব্যয়বহুল বলে মনে করে না—কঠিনতার অনুভূতি সম্পূর্ণভাবে বিকৃত
আপনি ভাবতে পারেন: তাহলে কমপক্ষে আমি কাজের কঠিনতা অনুযায়ী খরচ অনুমান করতে পারি?
একটি পেপারে মানুষের বিশেষজ্ঞদের কাছে ৫০০টি টাস্কের কঠিনতা স্কোর করানো হয়েছিল, এবং তারপর এটি এজেন্টের প্রকৃত টোকেন খরচের সাথে তুলনা করা হয়েছিল—
ফলাফল: দুটির মধ্যে কেবল দুর্বল সম্পর্ক রয়েছে।
মানুষ যা খুব কঠিন মনে করে, এজেন্ট সহজেই সমাধান করতে পারে কম খরচে; আবার যা মানুষ খুব সহজ মনে করে, এজেন্ট তা করতে গিয়ে নিজেকেই সন্দেহ করতে শুরু করতে পারে।
কারণ মানুষ এবং এআই যেভাবে “দেখে” তা সম্পূর্ণ ভিন্ন:
- মানুষ দেখে: লজিক্যাল কমপ্লেক্সিটি, অ্যালগরিদমের কঠিনতা, ব্যবসায়িক বোঝার বাধা
- এজেন্ট দেখছে: প্রকল্পটি কতটা বড়, কতগুলো ফাইল পড়তে হবে, অনুসন্ধানের পথটি কতটা দীর্ঘ, এবং একই ফাইলে বারবার পরিবর্তন হবে কিনা
একজন মানুষ যখন মনে করেন যে “শুধু একটি লাইন পরিবর্তন করলেই চলবে” এমন বাগ, এজেন্টকে সম্ভবত পুরো কোডবেসের কাঠামোটি বুঝতে হবে যাতে সেই লাইনটি খুঁজে পায়—এবং শুধু “পড়া” মাত্রেই অনেক টোকেন ব্যয় হয়। আবার, যে অ্যালগরিদমিক সমস্যা একজন মানুষের জন্য “খুবই জটিল” মনে হয়, সেটির জন্য এজেন্টের ঠিকই স্ট্যান্ডার্ড সমাধানটি জানা থাকতে পারে, আর তা খুবই দ্রুত সমাধান করে ফেলতে পারে।
এর ফলে একটি অস্বস্তিকর বাস্তবতা তৈরি হয়েছে: ডেভেলপারদের জন্য এজেন্টের চলার খরচ অনুমান করা প্রায় অসম্ভব।
পাঁচতম পর্যবেক্ষণ: মডেলটিও নিজের কত খরচ হবে তা ঠিক করতে পারছে না
যদি মানুষ ঠিক পূর্বানুমান করতে না পারে, তাহলে কেন AI-কে নিজেই পূর্বানুমান করতে দেওয়া হচ্ছে না?
পরিশোধকরা একটি পরিকল্পিত পরীক্ষা ডিজাইন করেছেন: এজেন্টকে আসলে বাগ ঠিক করার আগে কোডবেসটি “পরীক্ষা” করতে হবে, এবং নিজের কতটা টোকেন খরচ হবে তা অনুমান করতে হবে—কিন্তু ঠিক করা বাস্তবায়ন করবে না।
ফলাফল কেমন?
সমস্ত মডেল, সম্পূর্ণ ধ্বংস।
সর্বোত্তম ফলাফল হল Claude Sonnet-4.5-এর আউটপুট টোকেনের পূর্বানুমানের সম্পর্ক—0.39 (সর্বোচ্চ 1.0)। বেশিরভাগ মডেলের পূর্বানুমানের সম্পর্ক শুধুমাত্র 0.05 থেকে 0.34 এর মধ্যে, যেখানে Gemini-3-Pro-এর সবচেয়ে কম, মাত্র 0.04—যা প্রায় অনুমানের মতো।
আরও অস্বাভাবিক বিষয় হলো: সমস্ত মডেল তাদের টোকেন খরচকে প্রায়শই কম অনুমান করে। চিত্র 11-এর স্ক্যাটার প্লটে, প্রায় সমস্ত ডেটা পয়েন্ট “পারফেক্ট প্রেডিকশন লাইন”-এর নিচে অবস্থিত—মডেলগুলি মনে করে যে “এতটা খরচ হবে না”, কিন্তু বাস্তবে তা আরও বেশি খরচ হয়। এবং এই অনুমানের বিষয়টি উদাহরণ প্রদান না করলে আরও বেশি গুরুতর হয়।
আরও হাস্যকর বিষয় হলো—পূর্বানুমান করতেও টাকা লাগে।
Claude Sonnet-3.7 এবং Sonnet-4-এর পূর্বানুমানের খরচ এমনকি কাজের খরচের দ্বিগুণেরও বেশি। অর্থাৎ, তাদের আগে "মূল্যায়ন" করানো, সরাসরি কাজ করার চেয়েও বেশি খরচবহন করে।
প্রবন্ধের সিদ্ধান্তটি সরাসরি:
বর্তমানে, অগ্রণী মডেলগুলি নিজেদের টোকেন ব্যবহার সঠিকভাবে পূর্বানুমান করতে পারে না। "Agent চালু করুন" ক্লিক করা হলো একটি ব্লাইন্ড বক্স খোলা—বিল আসা পর্যন্ত জানা যায় না কতটা খরচ হয়েছে।
এই “অস্পষ্ট হিসাব” এর পিছনে লুকিয়ে আছে একটি বড় শিল্প সমস্যা
এটি পড়ে আপনি হয়তো প্রশ্ন করছেন: এই ফলাফলগুলি কোম্পানিগুলির জন্য কী অর্থ বহন করে?
"মাসিক সাবস্ক্রিপশন" প্রাইসিং মডেলটি এখন এজেন্ট দ্বারা ভাঙ্গা হচ্ছে
পেপারটি বলে যে, চ্যাটজিপিটি প্লাসের মতো সাবস্ক্রিপশন মডেল কার্যকর হয় কারণ সাধারণ কথোপকথনের টোকেন খরচ সাপেক্ষে নিয়ন্ত্রিত এবং পূর্বানুমানযোগ্য। কিন্তু এজেন্ট টাস্কগুলি এই ধারণাকে সম্পূর্ণভাবে ভেঙে দেয়—একটি টাস্ক এজেন্টের সাইকেলে আটকে যাওয়ার কারণে অসংখ্য টোকেন ব্যয় করতে পারে।
এর অর্থ হলো, এজেন্ট স্কেনারিওর জন্য শুধুমাত্র সাবস্ক্রিপশন প্রাইসিং টেকসই হতে পারে না, এবং পে-অ্যাস-ইউ-গো (Pay-as-you-go) পদ্ধতি দীর্ঘসময়ের জন্যই সবচেয়ে বাস্তবসম্মত বিকল্প। কিন্তু পে-অ্যাস-ইউ-গোর সমস্যা হলো—ব্যবহারের পরিমাণই অপ্রতুল।
2. টোকেন দক্ষতা মডেল নির্বাচনের "তৃতীয় সূচক" হওয়া উচিত
প্রায়শই ব্যবসাগুলি মডেল বাছাইয়ের জন্য দুটি মাপকাঠি ব্যবহার করে: ক্ষমতা (এটি করতে পারে কিনা) এবং গতি (এটি কত দ্রুত করে)। এই পেপারটি তৃতীয় একটি সমান গুরুত্বপূর্ণ মাপকাঠি দেয়: শক্তি দক্ষতা (এটি সম্পন্ন করতে কতটা খরচ হয়)।
একটি কিছুটা কম ক্ষমতাসম্পন্ন কিন্তু তিনগুণ দক্ষ মডেল স্কেলিং স্কেনারিওতে "সবচেয়ে শক্তিশালী কিন্তু সবচেয়ে ব্যয়বহুল" মডেলের চেয়ে আর্থিকভাবে বেশি মূল্যবান হতে পারে।
৩. এজেন্টকে "অয়েল মিটার" এবং "ব্রেক" প্রয়োজন
পেপারটি একটি গুরুত্বপূর্ণ ভবিষ্যত দিক উল্লেখ করে—বাজেট-সচেতন টুল-ব্যবহার নীতি। সহজ কথায়, এটি এজেন্টকে একটি "অয়েল গেজ" সংযোগ করে: যখন টোকেন খরচ বাজেটের কাছাকাছি পৌঁছায়, তখন এটিকে অপ্রয়োজনীয় অনুসন্ধান বন্ধ করতে বাধ্য করা হয়, যাতে এটি শেষ পর্যন্ত বাজেট শেষ না করে।
বর্তমানে, প্রায় সমস্ত প্রধান এজেন্ট ফ্রেমওয়ার্ক এই মেকানিজমটি অভাবে রয়েছে।
এজেন্টের "পয়সা পোড়ানোর সমস্যা" একটি বাগ নয়, বরং শিল্পের অপরিহার্য বেদনা
এই পেপারটি কোনো মডেলের ত্রুটি নয়, বরং একটি সম্পূর্ণ Agent প্যারাডাইমের গঠনগত চ্যালেঞ্জকে প্রকাশ করে—যখন AI “একটি প্রশ্ন, একটি উত্তর” থেকে “স্বাধীনভাবে পরিকল্পনা, বহু-পদক্ষেপ বাস্তবায়ন, পুনরাবৃত্তি ডিবাগিং”-এ উন্নীত হয়, তখন Token খরচের অপ্রতুলতা প্রায় একটি অপরিহার্যতা।
ভালো খবর হলো, এটি প্রথমবারের মতো কেউ এই অস্পষ্ট খাতা প্রণালীবদ্ধভাবে পুনরায় পরীক্ষা করেছে। এই ডেটার সাহায্যে, ডেভেলপাররা মডেল বাছাই, বাজেট সেটআপ এবং স্টপ-লস মেকানিজম ডিজাইন করতে আরও বুদ্ধিমানের সাথে সিদ্ধান্ত নিতে পারবেন; মডেল প্রোভাইডারদেরও একটি নতুন অপ্টিমাইজেশন দিক পাওয়া গেল—শুধু আরও শক্তিশালী করা নয়, আরও কম খরচেও করা।
অবশ্যই, AI এজেন্ট প্রকৃতপক্ষে সমস্ত শিল্পের উৎপাদন পরিবেশে প্রবেশ করার আগে, প্রতিটি টাকা কোথায় খরচ হচ্ছে তা পরিষ্কারভাবে বুঝতে পারা, প্রতিটি লাইন কোড সুন্দরভাবে লেখার চেয়ে বেশি গুরুত্বপূর্ণ। (এই নিবন্ধটি প্রথম প্রকাশিত হয়েছে টাইমেডিয়া অ্যাপ-এ, লেখক | সিলিকন ভ্যালি Tech news, সম্পাদক | ঝাও হংযু)
নোট: এই লেখাটি 2026 সালের 24 এপ্রিলে arXiv-এ প্রকাশিত প্রিন্ট পেপার *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei) এর উপর ভিত্তি করে তৈরি। লেখকদের মধ্যে রয়েছে ভার্জিনিয়া বিশ্ববিদ্যালয়, স্ট্যানফোর্ড বিশ্ববিদ্যালয়, MIT, মিশিগান বিশ্ববিদ্যালয় ইত্যাদি। এই গবেষণাটি এখনও পিয়ার-রিভিউড হয়নি।