










লেখক: ম্যাক্স, যিনি সর্বদা পথে, 01Founder
যদি ওপেনএআই-এর 2025 সালের জন্য একটি পর্যায়ক্রমিক সারসংক্ষেপ লিখতে হয়, তাহলে অনেকেই এটিকে সাধারণ বা এমনকি কিছুটা নিষ্ক্রিয় বলে বর্ণনা করবে।
গত এক বছরের বেশি সময়ের মধ্যে, তারা যুক্তিসঙ্গত যুক্তির পথটি ধাপে ধাপে বাস্তবায়ন করেছে, o3pro থেকে o4mini পর্যন্ত যুক্তিসংশ্লিষ্ট মডেলগুলি ঘনঘন প্রকাশ করেছে এবং GPT-4.5 এবং GPT-5-এর মতো সম্পূর্ণ নতুন বেস মডেলগুলি চালু করেছে।
কিন্তু সাধারণ ব্যবহারকারীদের সবচেয়ে বেশি অনুভব করা এবং স্বয়ংস্ফূর্ত প্রচারের জন্য সবচেয়ে সহজ ভিজ্যুয়াল জেনারেশন ক্ষেত্রে, তাদের উপস্থিতি ধীরে ধীরে কমে যাচ্ছে।
সোরার প্রাথমিক প্রকাশের আঁচড়ের পরে, ওপেনএআই এই পথে দীর্ঘ নীরবতায় প্রবেশ করেছে।
এর মধ্যে, টেবিলের অন্যান্য খেলোয়াড়রা বসে থাকেননি।
ওপেন সোর্স ইকোসিস্টেমে, ফ্লাক্সের মতো মডেলগুলি উচ্চ মানের স্থানীয় ছবি তৈরির বাধা সম্পূর্ণভাবে ভেঙে দিয়েছে;
ব্যবসায়িক প্রান্তে, শুধু পুরনো প্রতিদ্বন্দ্বীদের দ্বারা চরম সৌন্দর্যের বাধা নিয়ন্ত্রিত হয়নি, বরং ন্যানো-ব্যানানের মতো নিজস্ব ইন্টারনেট অনুসন্ধান ফাংশন সহ নতুন প্রতিযোগীদেরও উত্থান ঘটেছে।
অপেক্ষাকৃত, ওপেনএআইয়ের পূর্ববর্তী প্রধান ইমেজ জেনারেশন মডেল GPT-Image-1.5 ইতিমধ্যেই পুরনো মনে হচ্ছে:
ছবির গুণমান খারাপ, লেআউট কঠিন এবং জটিল টেক্সটের সামনে প্রায়শই ক্র্যাশ হয়।
ধীরে ধীরে, শিল্পে একটি সমঝোতা গড়ে উঠেছে:
ওপেনএআই ভিজুয়াল জেনারেশনে প্রযুক্তিগত বাধার সম্মুখীন হয়েছে এবং বিভিন্ন প্রতিদ্বন্দ্বীর আক্রমণে এখন এটি ক্ষমতার বাইরে মনে হচ্ছে।
কয়েক সপ্তাহ আগまで, মোড়টি একটি অত্যন্ত গোপনীয় উপায়ে প্রকাশ পেয়েছিল।
LM Arena নামক একটি পরিচিত বড় মডেল ব্লাইন্ড টেস্টিং প্ল্যাটফর্মে, একটি গোপন চিত্র মডেল, যার কোডনাম Duct Tape, চুপচাপ প্রবেশ করেছে।
অংশগ্রহণকারী ব্যবহারকারীরা দ্রুত বুঝতে পারল যে কিছু ভুল হচ্ছে:
এই মডেলটি কেবল চরম অনুপাতের নিয়ন্ত্রণে অত্যন্ত সঠিক নয়, বরং এটি অসংখ্য ভাষার টেক্সট সহ বিন্যাসযুক্ত পোস্টারও দোষমুক্তভাবে উত্পাদন করে, এমনকি চিত্র তৈরির আগে একটি অদৃশ্য যুক্তিগত পরিকল্পনা প্রক্রিয়াও থাকে বলে মনে হয়।
একসময় বিভিন্ন প্রযুক্তিগত সম্প্রদায় এটি কোন প্রতিষ্ঠানের গোপনে চালু করা বড় হাতিয়ার হতে পারে তা নিয়ে অনুমান করছিল, কিন্তু ওপেনএআই পক্ষ সর্বদা নীরব থাকে।
আজ রাতের মাঝে, বুট চূড়ান্তভাবে পড়ে গেল।
দীর্ঘ প্রেস বিজ্ঞপ্তি বা ব্যাপক মার্কেটিং প্রচার ছাড়াই, ওপেনএআই এই কোডনেম টেপ মডেলটিকে সরাসরি ChatGPT GPT-Image-2 নামে ঘোষণা করে এটিকে বাজারে চালু করেছে।
এর সাথে একটি চাপা প্রতিবেদন করা হয়েছে টেক্সট-টু-ইমেজ অ্যারেনা র্যাঙ্কিং।
GPT-Image-2 সরাসরি 1512 পয়েন্ট স্কোর নিয়ে শীর্ষে আসে, যা দ্বিতীয় স্থানীয় (যা ইন্টারনেট সার্চ ফাংশন সহ Nano-banana-2) থেকে 242 পয়েন্ট এগিয়ে।
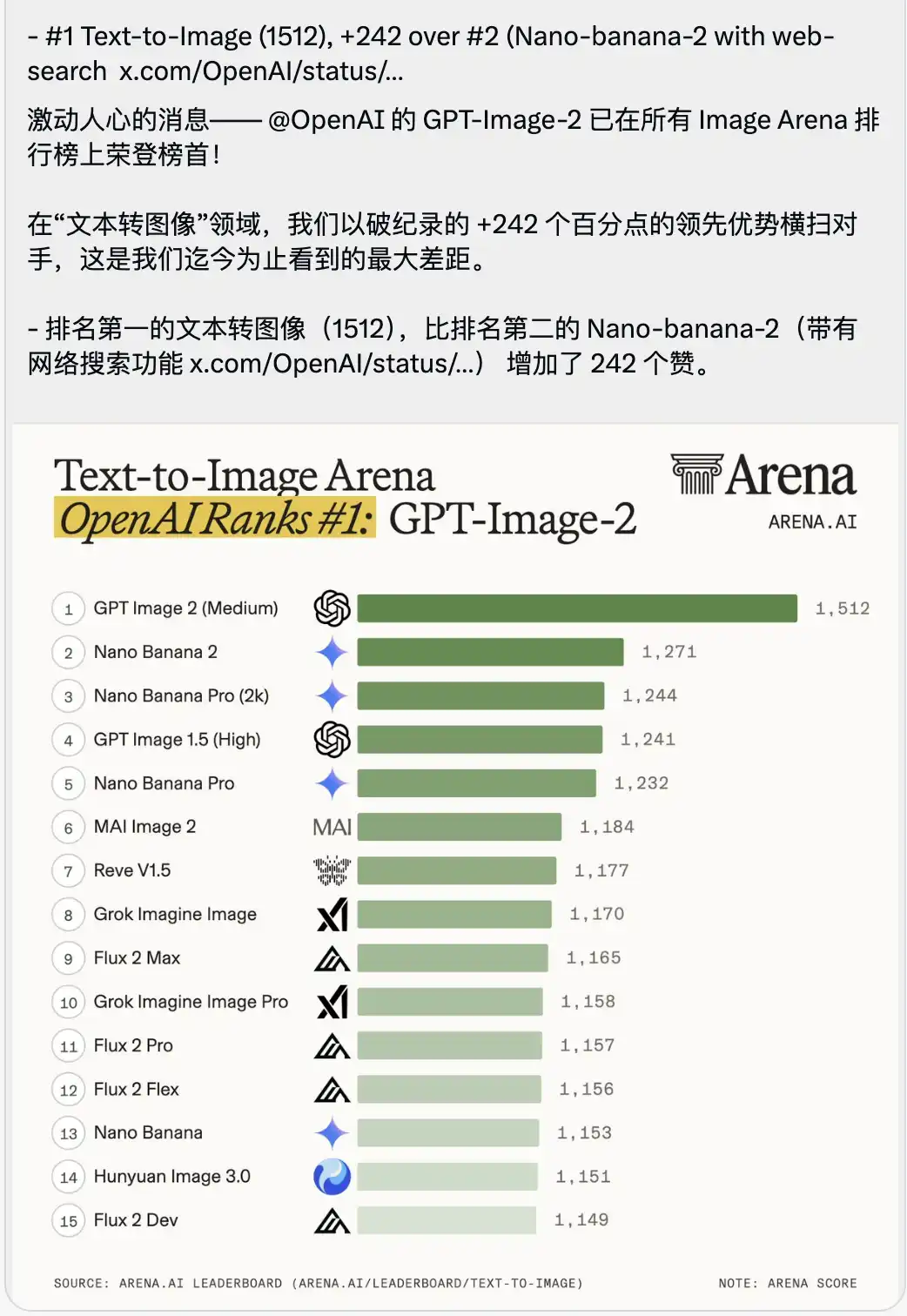
বড় মডেলের স্কোরিংয়ের প্রেক্ষাপটে, সাধারণত শূন্যের কিছু ভগ্নাংশ বা একক সংখ্যার অগ্রগতির বিষয়ে বড় আলোচনা হয়, এবং শীর্ষস্থানীয় মডেলগুলির মধ্যে স্কোর খুব কাছাকাছি।
একটি 242 পয়েন্টের এগিয়ে থাকার পার্থক্য এরিনার ইতিহাসে কখনও দেখা যায়নি।
এটি কোনও ক্ষুদ্র সংস্করণ আপডেট নয়, এটি একটি ক্রুদ্ধ প্রজন্মের দমন।
আমি এর বিভিন্ন সীমানা এবং সর্বশেষ API ডকুমেন্টেশন পর্যালোচনা করতে অর্ধদিন ব্যয় করেছি।
কেবল একটিই সর্বাধিক অনুভূতি:
OpenAI এখনও সেই OpenAI।
যখন এটি নিজের ক্ষতি পুনরুদ্ধারের সিদ্ধান্ত নেয়, তখন এটি পুরনো টেবিলটিকে উল্টে দেয়।
এই মডেলের সামনে, যে ভিজুয়াল ডিজাইনের কাজগুলি আমরা মনে করতাম যে এগুলি আরও দুই বা তিন বছর পরে এআই দ্বারা সম্পূর্ণরূপে প্রতিস্থাপিত হবে, আজকে এগুলি প্রায় শেষ হয়ে গেছে।
পার্ট.01 ছবি তৈরি: মডেল থেকে ভিজুয়াল এজেন্ট
জিপিট-ইমেজ-2 কেন এত বড় স্কোর পার্থক্য তৈরি করেছে তা বুঝতে, আপনাকে পাঠ্য-থেকে-ছবি মডেলগুলির পুরনো ধারণা বাদ দিতে হবে।
আগে আমরা এআই ব্যবহার করে চিত্র আঁকতাম, যা মূলত একটি অজানা বাক্স খোলার মতো ছিল—কিছু প্রম্পট দিয়ে ফেলে দিয়ে অপেক্ষা করতাম যেন পিক্সেলগুলো আপনার চাওয়া আকারে সাজে।
কিন্তু GPT-Image-2 একটি ভিজুয়াল ইঞ্জিন সংযুক্ত স্মার্ট এজেন্টের মতো।
সবচেয়ে স্পষ্ট পরিবর্তনটি হল এটি মেকানিজমের মধ্যে দুটি সম্পূর্ণ ভিন্ন মোড সরাসরি বিভক্ত করেছে।
একটি সকল ব্যবহারকারীর জন্য উন্মুক্ত ইনস্ট্যান্ট মোড (Instant Mode)।
এই মডেলটি দ্রুত প্রতিক্রিয়া এবং জীবনযাপন ও কাজের প্রবাহের অন্তর্ভুক্তির উপর জোর দেয়।
যেমন আপনি আপনার মোবাইলে এটিকে একটি নির্দেশ পাঠান, এটি কয়েক সেকেন্ডের মধ্যে আপনাকে একটি সম্পূর্ণ কাঠামোবদ্ধ চিত্র দেবে।
এর অধীনস্থ দৃশ্য বোঝার ক্ষমতা অত্যন্ত শক্তিশালী, কিন্তু এটি মূলত প্রায়শই এবং একবারের জন্য দৃশ্য রূপান্তরের প্রয়োজনীয়তা সমাধান করে।
পেইড ইউজারদের জন্য উন্মুক্ত থিংকিং মোড।
এটি একটিও পিক্সেল রেন্ডার করার আগে একটি দশকগুলির দীর্ঘ যুক্তিগত যুক্তি এবং ইন্টারনেট অনুসন্ধানে প্রবেশ করে।
এই মডেলটিই একটি অত্যন্ত মৌলিক কিন্তু অত্যন্ত কঠিন প্রশ্নের সমাধান করেছে:
মডেলটি প্রথমবারের মতো বুঝতে পারল যে এটি কী আঁকবে।
সবচেয়ে সরাসরি উদাহরণটি হলো।
আপনি চ্যাট বক্সে টাইপ করুন:
ডাক্ট টেপ এই রহস্যময় মডেলটির সম্পর্কে অনলাইনে মানুষের মতামত খুঁজুন এবং চ্যাটজিপিটির কোড যুক্ত করুন।

পূর্বের মডেল ব্যবহার করলে, এটি ওয়েব ব্যবহারকারীদের কী বলেছেন তা জানত না, শুধু একটি অবিশ্বাস্য অক্ষরযুক্ত পোস্টার এবং স্ক্যান করা যায় না এমন একটি কাল্পনিক কোয়ার্ট কোড তৈরি করত।
কিন্তু চিন্তার মোডে, এর কাজের প্রবাহ এররকম:
এটি আঁকা বন্ধ করে দেবে, ইন্টারনেট অনুসন্ধান টুল চালু করবে, এবং Reddit, Threads বা LinkedIn-এ ব্যবহারকারীদের প্রকৃত মন্তব্য সংগ্রহ করবে;
তারপর, এটি পোস্টারের লেআউট, ফাঁকা জায়গা এবং ফন্ট হায়ারার্কি পরিকল্পনা শুরু করে;
শেষে, এটি একটি বাস্তবিক ও ব্যবহারযোগ্য কোড তৈরি করে যা সরাসরি স্ক্যান করে রিডাইরেক্ট করা যায়, এবং পুরো ছবিটি রেন্ডার করে।

এটি শুধু চিত্র আঁকা নয়, এটি বাস্তবে গবেষণা, পরিকল্পনা, পাঠ্য নির্বাচন এবং লেআউট ডিজাইনের একটি সম্পূর্ণ প্রক্রিয়া।
এখানে একটি সমান্তরাল তুলনা করা প্রয়োজন।
ইন্টারনেট এবং সার্চ ক্ষমতা সহ চিত্র তৈরি মডেলের ধারণা অবশ্যই OpenAI-এর আবিষ্কার নয়, যারা বড় মডেলের সম্প্রদায়কে অনুসরণ করেন।
দ্বিতীয় স্থানের ন্যানো-বানানা ইতিমধ্যেই এই কৌশলটি অন্তর্ভুক্ত করেছে।
কিন্তু ন্যানো-বানানা ব্যবহার করার সময় আপনি দেখতে পাবেন যে এটি অনেক জায়গায় একটু অসুবিধাজনক মনে হয়।
ন্যানো-বানানার চিন্তা প্রায়শই একটি যান্ত্রিক সংযোগ যুক্তি হয়ে থাকে।
যেমন আপনি এটিকে একটি ইন্ডাস্ট্রি ট্রেন্ড খুঁজে বের করে পোস্টার তৈরি করতে বলেন, এটি সত্যিই খুঁজে বের করে, কিন্তু সাধারণত শুধু উইকিপিডিয়ার বাক্যগুলিকে কঠোরভাবে কেটে নিয়ে চিত্রের উপর জোর করে লাগিয়ে দেয়।
যখন কোনো বিমূর্ত ব্যবসায়িক চাহিদা ব্যাখ্যা করার নির্দেশ পায়, তখন এটি সহজেই বিভ্রান্ত হয়ে যায়।

এটি ঠিক এমন অনুভূতি, যেন একজন কথা বুঝতে পারে কিন্তু কোনও কাজের অভিজ্ঞতা নেই এমন ইন্টার্ন, যে কাজ করতে পারে কিন্তু কোনও কৌশল বুঝে না।
কিন্তু GPT-Image-2 এই ক্ষেত্রে এর পারফরম্যান্স বর্ণনা করার জন্য অতিশয়োক্তি ছাড়া হয় না।
এটি শুধু একটি ফর্মালিটি পালন করেনি, বরং পেছনের সাংস্কৃতিক প্রেক্ষাপট এবং ব্যবসায়িক উদ্দেশ্যকে প্রকৃতপ্রস্তে বুঝেছে।
আমি পরীক্ষার সময় একটি অত্যন্ত সংক্ষিপ্ত চীনা নির্দেশ দিয়েছিলাম: আমাকে একটি স্ক্রিনশট আঁকুন যেখানে মাস্ক ডাওয়িনে ডোবাও বিক্রি করছেন।
পূর্বের চিত্র তৈরি মডেল ব্যবহার করলে, সম্ভাবনা অনেক বেশি যে আপনাকে একজন সাদা ব্যক্তি আঁকবে যার চেহারা মাস্কের মতো, হাতে একটি বাওজি ধরে, পটভূমি অস্পষ্ট, এমনকি ডিজিটাল টিকটক কীভাবে দেখায় তা জানেও না।
কিন্তু থিংকিং মোডে, GPT-Image-2 এর ফলাফল কিছুটা ভয়াবহ মনে হয়।
এটি শুধু উপাদানগুলি জোড়া দেয়নি, বরং চীনা ইন্টারনেটের প্রতি নিজস্ব বোঝাপড়া ব্যবহার করে একটি পিক্সেল-লেভেল প্রতিলিপি তৈরি করেছে ডাওয়েন লাইভস্ট্রিম ইউআই স্ক্রিনশট।
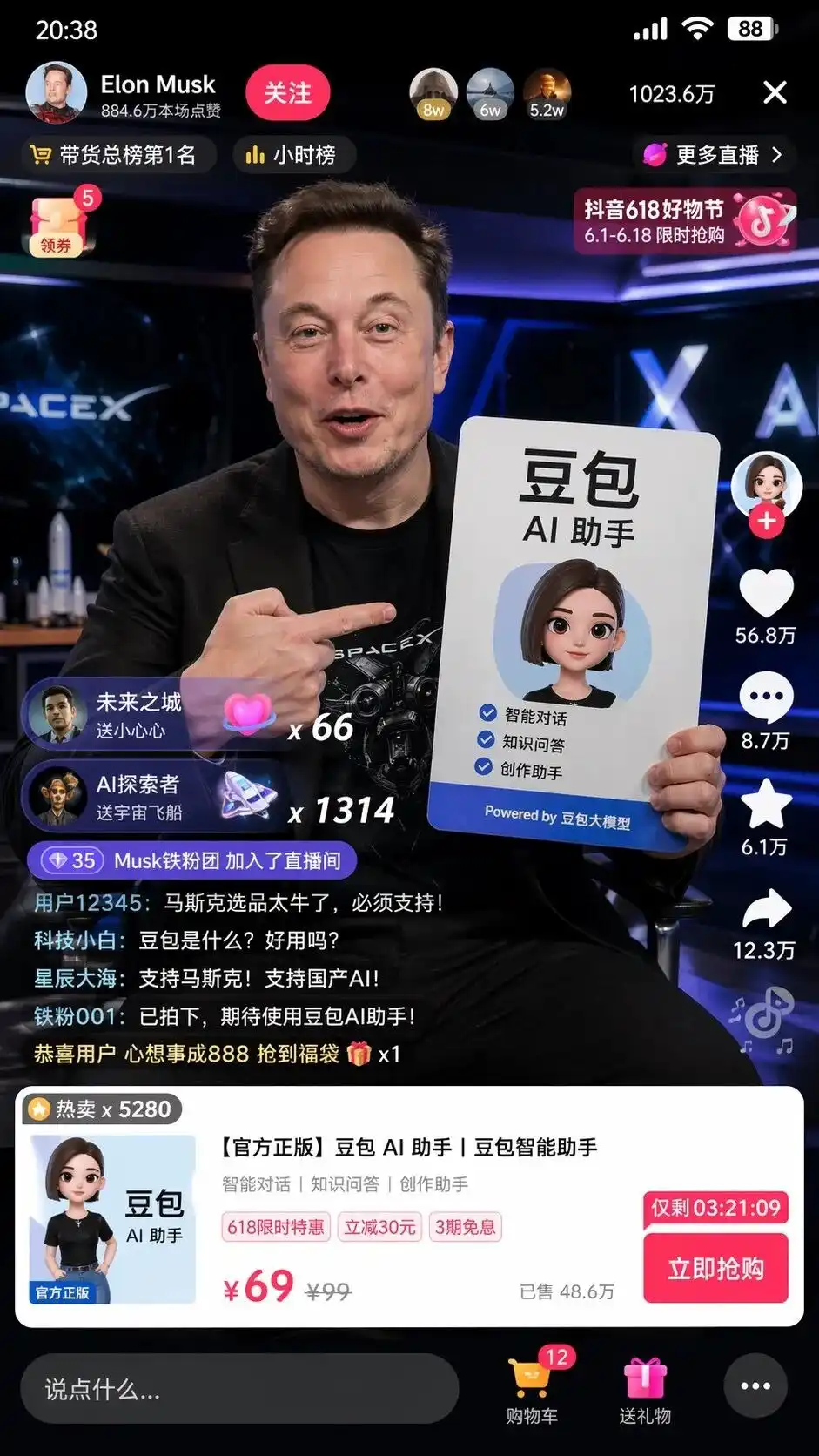
পর্দায় শুধু পারফেক্ট লেআউট সহ ডোবাও AI অ্যাসিস্ট্যান্টের বিজ্ঞাপন বোর্ড তুলে ধরা মাস্কের বাস্তবসম্মত চিত্রই নয়, বরং প্রম্পটে উল্লেখ না করা অনেক বিস্তারিত বিষয়ও রয়েছে:
বাম উপরের ফলো বোতাম, ঘন্টার লিস্ট, ডান উপরের 1023.6 মিলিয়ন অনলাইন ব্যবহারকারী, নিচের পপ-আপ স্ট্যান্ডার্ড প্রোডাক্ট কার্ড, এমনকি কাটা মূল্য 99, বিশেষ মূল্য 69 এবং কাউন্টডাউন সহ তাত্ক্ষণিক কেনার বোতাম চিহ্নিত করা হয়েছে।
নীচের বাম কোণে অত্যন্ত বাস্তবসম্মতভাবে স্ক্রোল করছে ব্যবহারকারীদের মন্তব্য:
টেক নিউব: ডোবাও কী? এটি ব্যবহার করা যায় কি?
স্টার সি অ্যান্ড ওশন: মাস্ককে সমর্থন করুন! দেশীয় AI-কে সমর্থন করুন!
কেউ তাকে বলেনি যে চ্যাট বার কী লিখবে, পণ্যের ইউআই কেমন হবে, বা মূল্য কত হবে।
এই ব্যবসায়িক UI ডিজাইন এবং অপারেশন পরিকল্পনা হল ডাওয়েন এবং ডোবাও মডেল এই দুটি ট্যাগ বিশ্লেষণের পরে মডেল দ্বারা মানুষের মস্তিষ্কের জন্য পূরণ করা এবং বাস্তবায়িত।
এই মুহূর্তে চিত্র তৈরির ক্ষেত্রে বড় মডেলের মূল্যায়নের মাপকাঠি শুধুমাত্র সুন্দর আঁকা যায় কিনা থেকে কৌশল এবং লেআউট যুক্তি বোঝা পর্যন্ত বিস্তৃত হয়েছে।
পার্ট.02 কোর ক্ষমতার পরীক্ষা
এটির সীমানা পরীক্ষা করতে, আমি ব্যবসায়িক ডিজাইনের মানদণ্ড অনুসারে কয়েকটি প্রায়শই ব্যবহৃত এবং জটিল পরিস্থিতি পরীক্ষা করেছি।
এটি সমস্যার সমাধানের ক্ষুদ্রতম স্তর পর্যন্ত পৌঁছেছে, যা ভয়ঙ্কর মনে হয়।
প্রথম দৃশ্য: দৃশ্য বুঝতে এবং ব্যবসায়িক বন্ধন (মডেলকে পোশাক পরানো)
প্রাচীন ই-কমার্স ভিজুয়াল বা ফ্যাশন প্ল্যানিংয়ে, একটি ধারণা থেকে এটি পরিধানের ফলাফল দেখা পর্যন্ত বাস্তবায়নের খরচ অত্যন্ত বেশি।
আপনাকে মডেল খুঁজতে হবে, পোশাক ভাড়া নিতে হবে, স্টুডিও সজ্জিত করতে হবে, এবং পোস্ট-প্রোডাকশন সম্পাদনা করতে হবে।
পরে এআই আসে, এবং মানুষ লোরা মডেল ট্রেন করতে শুরু করে চেহারা স্থির করার জন্য, কিন্তু এটি এখনও কয়েক দশটি ছবির মেটিরিয়াল এবং বড় শেখার খরচ প্রয়োজন।
GPT-Image-2-এ, এই প্রক্রিয়াটি চরম পর্যায়ে সংকুচিত হয়েছে।
আমি আমার একটি দৈনিক সেলফি আপলোড করেছিলাম, এবং এটিকে বলেছিলাম যে আমি পরের মাসে একটি দ্বীপে ছুটিতে যাচ্ছি, এবং এটিকে আমার জন্য কয়েকটি আউটফিট সুপারিশ করতে বলেছিলাম।
এটি আমাকে প্রথমে 8 টি সম্পূর্ণ ভিন্ন স্টাইলের গ্রীষ্মকালীন পোশাকের গাইড দিয়েছিল, যার লেআউট পেশাদার ই-কমার্স লুকবুকের মতো দেখাচ্ছিল, প্রতিটি আইটেমের পাশে সঠিক টেক্সট লেবেলও ছিল।
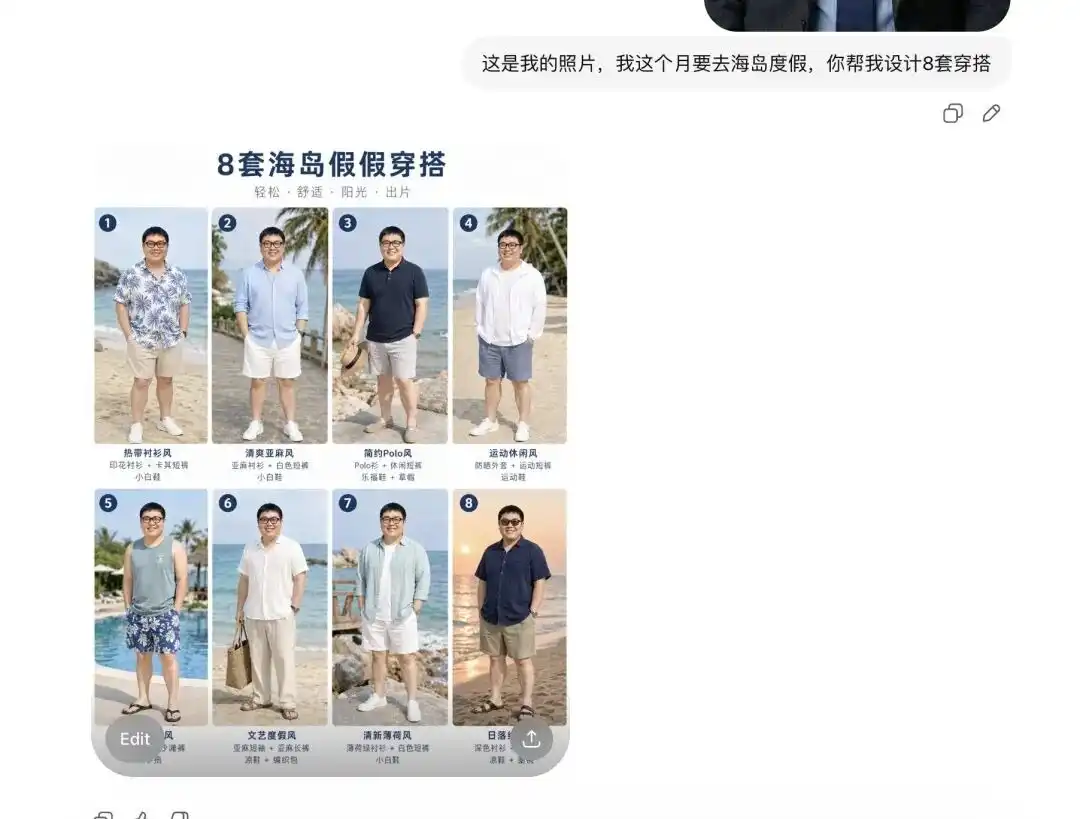
এর চেয়ে গুরুত্বপূর্ণ বিষয় হলো, এটি এই মুহূর্তেই আমার মুখের বৈশিষ্ট্য এবং শরীরের অনুপাত সঠিকভাবে বিশ্লেষণ করেছে।
যখন আমি তাকে বললাম যে আমি প্রথম সেটটি পরে কী দেখাচ্ছে তা দেখতে চাই এবং বিভিন্ন কোণ থেকে বিস্তারিত ছবি চাই, তখন এটি সরাসরি আমার সেলফির ব্যক্তিটিকে বের করে নিয়ে সেই গ্রীষ্মকালীন পোশাকটি পরিয়ে পাশাপাশি, অর্ধেক দেহের মতো বিভিন্ন দৃশ্যের ছবি তৈরি করল।

এই রূপান্তরটি খুবই স্বাভাবিক। এর অর্থ হলো, প্রাথমিক পোশাক ডিজাইন রেন্ডারিং বা মডেলদের দ্বারা পোশাক পরানোর বাইরের কাজগুলির জন্য প্রতিযোগিতামূলক সুবিধা সম্পূর্ণরূপে কেটে যাচ্ছে।
দ্বিতীয় পরিস্থিতি: সামঞ্জস্যতা এবং নিরবচ্ছিন্ন বর্ণনা সমাধান করুন (একটি বাক্য দিয়ে কমিক তৈরি করুন)
এআই ছবি তৈরি করা অভিজ্ঞ সবাই জানেন, একটি সুন্দর ছবি আঁকতে এআইকে বলা কঠিন নয়, কিন্তু একই ব্যক্তির দশটি ছবি আঁকানো এবং তাদের অবস্থান ও দৃষ্টিভঙ্গি সংযুক্ত রাখা কঠিন।
এটিই প্রচলিত সামঞ্জস্যতা (Consistency) সমস্যা।
কিন্তু এই পরীক্ষায়, আমি অতীতের অভিজ্ঞতার বিপরীতে একটি অত্যন্ত অসাধারণ কেস দেখেছি।
আপনি শুধু গতকাল আপনার বন্ধুর সাথে একটি ছবি আপলোড করতে পারেন, তারপর একটি অত্যন্ত সাধারণ প্রম্পট লিখতে পারেন:
আমাদ়কে প্রধান চরিত্র বানান, তিনটি তিন-পৃষ্ঠার জাপানি ম্যাঙ্গা আঁকুন, প্লট আপনি নির্ধারণ করুন
কয়েক সেকেন্ডের মধ্যে, এটি স্ট্যান্ডার্ড শট লিস্ট সহ তিন পৃষ্ঠার ব্ল্যাক-অ্যান্ড-ওয়াইট কমিক আউটপুট দিয়েছে।
সবচেয়ে ভয়ঙ্কর বিষয় হলো, এই দুটি বাস্তব মানুষ থেকে তৈরি কমিক চরিত্র তিন পৃষ্ঠার বিভিন্ন ফ্রেমে রয়েছে।

নিকট ক্লোজ-আপ, দূরের দৌড়ানো, বা পিছনের দিক, এমনকি তাদের মুখের বৈশিষ্ট্য, চুলের বিস্তারিত এবং পোশাকের ভাঁজগুলি সবকিছুই পারফেক্ট সামঞ্জস্যতা বজায় রেখেছে।
আরও বেশি বিস্ময়ের বিষয় হলো, কমিকের গল্প সম্পূর্ণরূপে সংযুক্ত, এমনকি ডায়ালগ বক্সের লেখাগুলিও পূর্ণাঙ্গ গল্পের যুক্তি গঠন করে।

সময় এবং স্থানের সামঞ্জস্যতা বজায় রাখা যাওয়া মানে এটি একক চিত্র তৈরির পরিধি থেকে বেরিয়ে গেছে এবং ধারাবাহিক গল্প বলার পরিচালকের ক্ষমতা অর্জন করেছে।
তৃতীয় দৃশ্য: টেক্সট রেন্ডারিংয়ের শেষ বাধা পার হওয়া (বহুভাষিক টাইপোগ্রাফি)
যদি সামঞ্জস্যতা বর্ণনামূলক সমস্যার সমাধান করে, তবে বহুভাষিক টেক্সটের সঠিক রেন্ডারিংই প্রকৃতপক্ষে গ্রাফিক ডিজাইনারদের পিছনের দেয়ালের কাছে ঠেলে দেয়।
আগে ছবিতে কিছু লেখা থাকলেই বড় মডেল অর্থহীন চিত্র আঁকত।
কারণ মডেল যে টেক্সট বুঝে, তা হল টোকেন (অর্থবহ ব্লক), আর যে ইমেজ তৈরি করে, তা হল পিক্সেল পয়েন্ট, যা আগে পৃথক ছিল।
GPT-Image-2 এই সমস্যাটি সম্পূর্ণরূপে সমাধান করেছে।
আমি একটি ফরাসি ফ্যাশন ম্যাগাজিনের কভার তৈরি করেছি, একটি জাপানি রেস্তোঁরার মেনু তৈরি করেছি যাতে ম্যানা এবং ক্যানজি পূর্ণ ছিল, এবং এমনকি অত্যন্ত ঘন রুশ টিপ্পনির লেআউটও পরীক্ষা করেছি।

ফলাফল একক প্রক্রিয়ায় তৈরি, কোনও বানান ভুল ছাড়া।
সবচেয়ে নিরাশাজনক বিষয় হলো, এটি শুধু শব্দগুলি সঠিকভাবে লিখেছে মাত্র নয়, এটি ভাষার সাথে স্থানীয় সংস্কৃতির সৌন্দর্য এবং ফন্ট ডিজাইনের সাথে মানিয়ে নিতে পারে।
উদাহরণস্বরূপ, জাপানি প্রচারপত্রের হানজি অত্যন্ত স্বাভাবিক জাপানি পুরনো শিল্পী অক্ষর ব্যবহার করে, এবং হিরাগানার সাজানো জাপানি উল্লম্ব পাঠের অভ্যাসের সাথে সামঞ্জস্যপূর্ণ।
লেআউট ডিজাইন একসময় গ্রাফিক ডিজাইনারদের একটি ব্যক্তিগত ক্ষেত্র ছিল।
বর্ণের মধ্যে স্থান কিভাবে সামঞ্জস্য করবেন, প্রাধান্য কিভাবে নির্ধারণ করবেন, এবং টেক্সট ও ব্যাকগ্রাউন্ডের মধ্যে দৃশ্যমান ভারসাম্য কিভাবে বজায় রাখবেন—এগুলোর জন্য অসংখ্য অনুশীলনের প্রয়োজন।
কিন্তু যখন এআই এতগুলি ভাষা শূন্য ত্রুটিতে পরিচালনা করতে পারে এবং এর নিজস্ব উন্নত লেআউট সৌন্দর্য থাকে, তখন দৈনিক পোস্টার, প্রচারপত্র এবং ইনফোস্ট্রিম বিজ্ঞাপনগুলির জন্য ম্যানুয়ালি রেফারেন্স লাইন সারিবদ্ধ করার দরকার থাকে না।
চতুর্থ দৃশ্য: বিকৃত অনুপাত এবং চরম মাইক্রো নিয়ন্ত্রণ (ভাতের দানার উপর খোদাই)
শেষে, এটির আনুগত্য কতটা ভয়ঙ্কর তা দেখতে, আমি এটিকে কয়েকটি খুব কঠিন নির্দেশ দিয়েছিলাম।
আমি প্রথমে এর চরম অনুপাত পরীক্ষা করেছি।
প্রচলিত ডিফিউশন মডেলগুলি অস্ট্যান্ডার্ড অনুপাতের প্রতি অত্যন্ত ভয় পায়।
আগে ছবিটিকে কিছুটা লম্বা করলেই চিত্রে দুটি মাথা বেরিয়ে আসত।
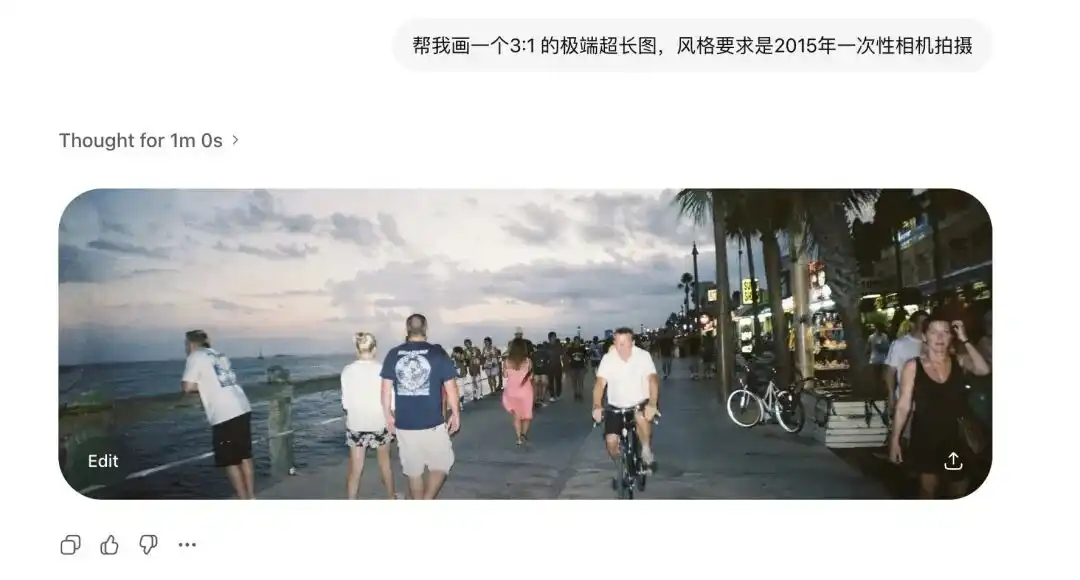
কিন্তু আমি Images 2.0 কে 3:1 এর অতি-প্রস্থ ছবি এবং 1:3 এর উল্টো লম্বা ছবি তৈরি করতে বলেছিলাম, এটি শুধু ভাঙেনি, বরং শুরু এবং শেষ যুক্ত করে একটি 360 ডিগ্রির প্যানোরামিক ছবি তৈরি করেছে।
2015 সালের একবারের জন্য ক্যামেরা দিয়ে তোলা ছবিগুলির পর, পুরনো লেন্সের বিকৃতি এবং ফ্ল্যাশের দেয়ালে পড়া খারাপ প্রতিফলনও স্পষ্টভাবে পুনর্নির্মিত হয়েছে।
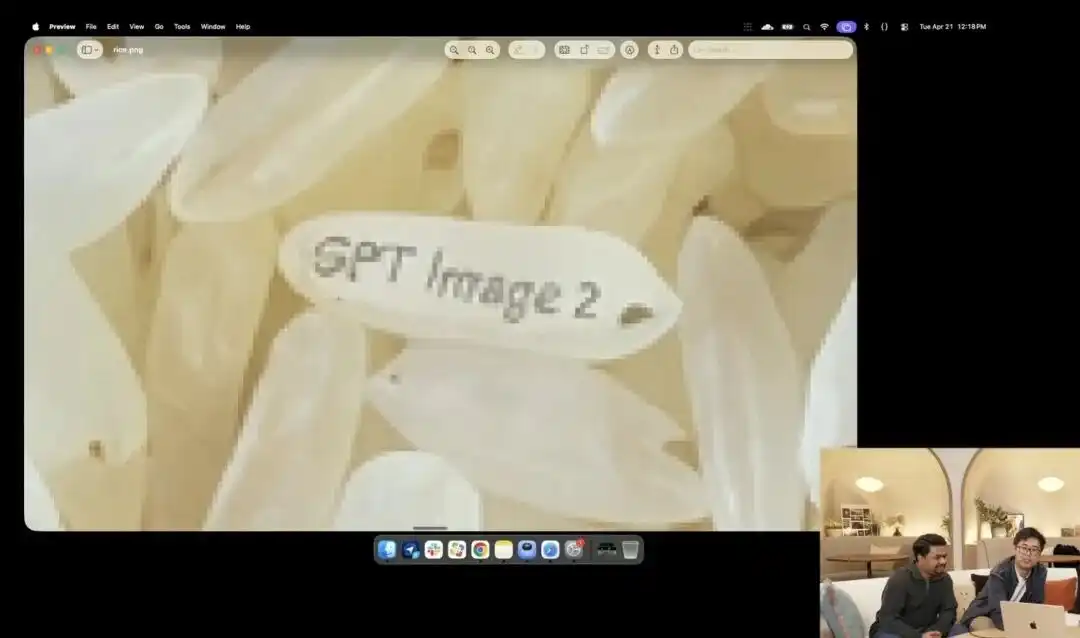
এবং এর মাইক্রো-নিয়ন্ত্রণ ক্ষমতাকে আরও ভালোভাবে প্রকাশ করে অফিসিয়াল প্রেজেন্টেশনে দেখানো একটি অসাধারণ ধানের কণা টেস্ট।
গবেষকরা বর্তমানে অন্তর্গত পরীক্ষামূলক 4K API কল করেছেন, তারা মাইক্রোফোটোগ্রাফি, 8K হাই-ডিফিনিশন ইত্যাদি কোনো বর্ণনামূলক শব্দ ব্যবহার করেননি, শুধু একটি অত্যন্ত বিস্তৃত সাধারণ নির্দেশনা দিয়েছেন:
একটি ভাতের ঢেঁকি। এই ভাতের ঢেঁকির মধ্যে একটি শুধুমাত্র ভাতের দানায় লেখা আছে GPT Image 2।
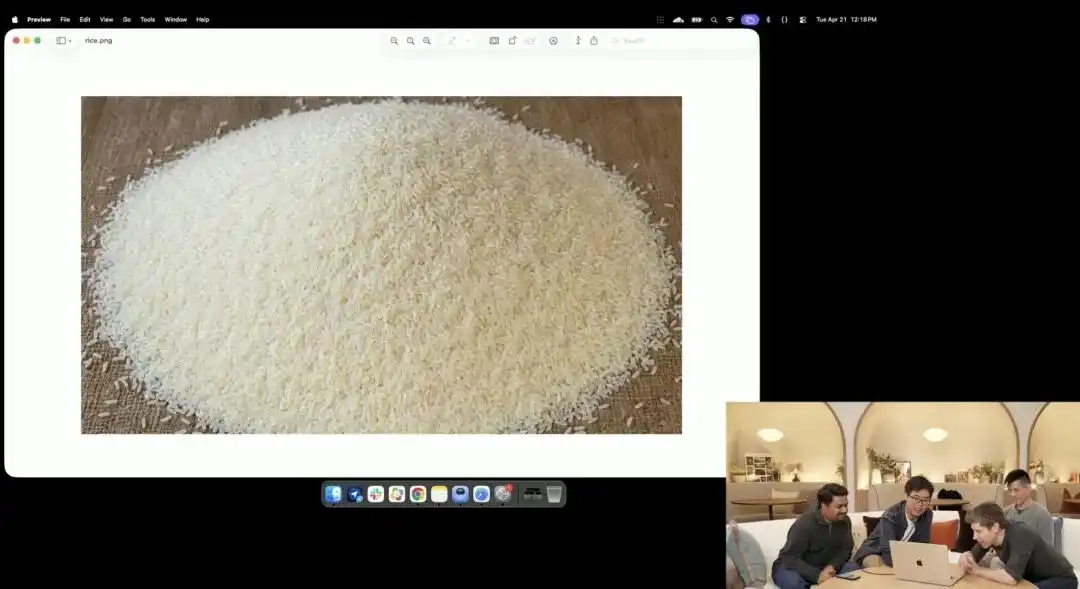
যখন পর্দায় ছবিটি দশগুণ বা তার বেশি বড় করা হয় এবং পিক্সেলের কণা দেখা যায়, তখন আসলেই তুমি এক ঢেঁকি চালের মধ্যে একটি অক্ষর খোদাইকৃত অতি সূক্ষ্ম কণা খুঁজে পাবে।
এই চালের পৃষ্ঠে পদার্থবিদ্যার সূত্রগুলি এখনও প্রযোজ্য, এবং অক্ষরগুলি চালের ক্ষুদ্র বক্রতার সাথে সঠিকভাবে সমন্বিত হয়েছে।
বাকি সবকিছু—মাইক্রো ভিউ কল করা, ডিপথ অফ ফিল্ড গণনা করা, লেটেন্ট স্পেসে একটি ডানা পাওয়ার জন্য ফিজিক্যাল কোঅর্ডিনেট খোঁজা এবং অক্ষর মুদ্রণ করা—সবকিছুই বড় মডেল দ্বারা থিংকিং মোডে স্বয়ংক্রিয়ভাবে কল্পনা করা এবং সম্পন্ন করা হয়েছে।
এই কেসটি স্পষ্টভাবে দেখায় যে মডেলটি স্থানীয় অবস্থানের বোঝাপড়া পিক্সেল-স্তরের স্ক্যালপেল সূক্ষ্মতায় পৌঁছেছে।
এর অর্থ হল ভবিষ্যতে বাস্তব কাজে আপনি ডিজাইন ফাইলের যেকোনো ক্ষুদ্র অংশকে সঠিকভাবে সংশোধন করতে পারবেন, যেখানে ইচ্ছা সেখানেই সংশোধন করতে পারবেন, আগের মতো একটি গলা পরিবর্তন করতে চাইলে পুরো ছবিটি পরিবর্তিত হওয়ার প্রয়োজন হবে না।
পার্ট.03 কিছু প্রযুক্তিগত বিস্তারিত
এই চরম নিয়ন্ত্রণ এবং কৌশলগত বুদ্ধিমত্তা শুধুমাত্র বোকামির সাথে গণনা ক্ষমতা জমা করে পাওয়া যায় না।
এটির আসল ক্ষমতা কী তা বুঝতে, আমি GPT-Image-2-এর জন্য কিছু প্রোব পরীক্ষা করেছি।
একটি খুব আকর্ষণীয় বিষয় উদঘাটন করা গেল।
যদিও অফিসিয়াল ডকুমেন্টে GPT-Image-2-এর সামগ্রিক জ্ঞানভাণ্ডারের সময়সীমা 2025 সালের ডিসেম্বর পর্যন্ত আপডেট করা হয়েছে বলে দাবি করা হয়েছে, আমার প্রাকটিক্যাল টেস্টে।
ইনস্ট্যান্ট মোডের ট্রেনিং ডেটা এখনও ২০২৪ সালের মে মাসের শেষ পর্যন্ত সীমাবদ্ধ।

এবং যে দীর্ঘ চিন্তার মোড (Thinking Mode) প্রয়োজন, তার মূল জ্ঞান বেস প্রায় 2024 সালের জুন পর্যন্ত থামা আছে (তবে বাস্তবসময়ে ইন্টারনেটের মাধ্যমে বর্তমান সঠিক তারিখ পাওয়া যায়)।

এই দুটি সময়বিন্যাসের ভিত্তিতে অনুমান করা যায় যে GPT-Image-2-এর নীচের স্তরে কিছুটা ধারণা পাওয়া যাচ্ছে।
প্রথমে হাই-ফ্রিকোয়েন্সি আউটপুটের জন্য ইমিডিয়েট মোড নিয়ে কথা বলি।
মে ২০২৪-এর ডেডলাইন বলতে বোঝায় যে এটি সম্ভবত সরাসরি o4-mini ব্যবহার করা হয়েছে, অথবা GPT-5 পরিবারের একটি হালকা সংস্করণ (GPT-5 mini বা এমনকি অত্যন্ত কম প্যারামিটারযুক্ত GPT-5 nano)।
কারণ এই হালকা বেস মডেলগুলি ইতিমধ্যেই অত্যন্ত শক্তিশালী স্পেস প্ল্যানিং এবং জটিল নির্দেশাবলী বুঝতে পারে, উপরের ইমেজ জেনারেশন স্থিতিশীল থাকতে পারে।
এবং সেই অত্যন্ত বুদ্ধিমান, ব্যবসায়িক কৌশল বোঝা চিন্তার প্যাটার্নটির ভিত্তি হতে পারে না GPT-5 মডেল।
কারণ GPT-5-এর মৌলিক জ্ঞানের সময়সীমা 2024 সালের সেপ্টেম্বর।
চিন্তার মোডটি ব্যাকগ্রাউন্ডে নিয়মিত আপডেট হচ্ছে ও সিরিজ ইনফারেন্স মডেল (যেমন o4 বা আপডেটকৃত o3) এর সাথে সংযুক্ত হওয়ার অত্যন্ত উচ্চ সম্ভাবনা রাখে।
বড় মডেলটি প্রথমে O সিরিজের বিশেষ দীর্ঘ চিন্তার মেকানিজম ব্যবহার করে, প্রায়োগিক লজিক, দর্শকের মনোবিজ্ঞান এবং লেআউট কোঅর্ডিনেটগুলি সম্পূর্ণরূপে গণনা করে, তারপর চূড়ান্ত পিক্সেল রেন্ডারিংয়ের জন্য ভিজুয়াল মডিউলকে হস্তান্তর করে।
অবশ্যই, একটি অন্যান্য সম্ভাব্য পথ রয়েছে:
OpenAI-এর অত্যন্ত সূক্ষ্ম কম্পিউটিং রিসোর্স বণ্টন মেকানিজমের অধীনে, দ্রুত মোডটি গ্যারান্টি হিসাবে GPT-5 nano ব্যবহার করতে পারে, যখন চিন্তা মোডটি কিছুটা বড় GPT-5 mini এবং বাহ্যিক টুলগুলির সংমিশ্রণ ব্যবহার করে।
কিন্তু যেকোনো বেস কম্বিনেশনের ক্ষেত্রেই, যদি আপনি অপেনএআইয়ের API ইকোসিস্টেম নিয়মিত অনুসরণ করেন, তাহলে আপনি দেখতে পাবেন যে এর নীচের জেনারেটিভ লজিক ইতিমধ্যেই মিডজার্নির সাথে সম্পূর্ণভাবে একই মাত্রায় নেই।
পার্ট.04 সবচেয়ে বেশি আগ্রহের বিষয় মূল্যনির্ধারণ
কিন্তু বেস অনুমানের চেয়ে এটিকে তাদের কাজের প্রবাহে সংযোগ করতে চাওয়া ডেভেলপার এবং প্রতিষ্ঠানগুলির জন্য আরও গুরুত্বপূর্ণ হল সেই অত্যন্ত বাস্তবিক এবং বিপরীতমুখী API মূল্যনির্ধারণ টেবিল।
পূর্বে DALL-E 3 প্রতি ছবির জন্য চার্জ করা হত (যেমন: প্রতি ছবি 0.04 ডলার)।
তবে প্রথম প্রজন্ম GPT-Image-1 থেকেই, OpenAI এটিকে টোকেন ভিত্তিক চার্জিং ফ্রেমওয়ার্কে সম্পূর্ণরূপে পরিবর্তন করেছে।
এই GPT-Image-2 এও এই মানদণ্ড অনুসরণ করা হয়েছে, এছাড়াও এটি পরিমাণ বাড়িয়ে মূল্য কমিয়েছে।
অফিসিয়ালভাবে সাম্প্রতিকভাবে প্রকাশিত মূল্য তালিকা অনুযায়ী, প্রতি মিলিয়ন টোকেনের মূল্য নিম্নরূপ।
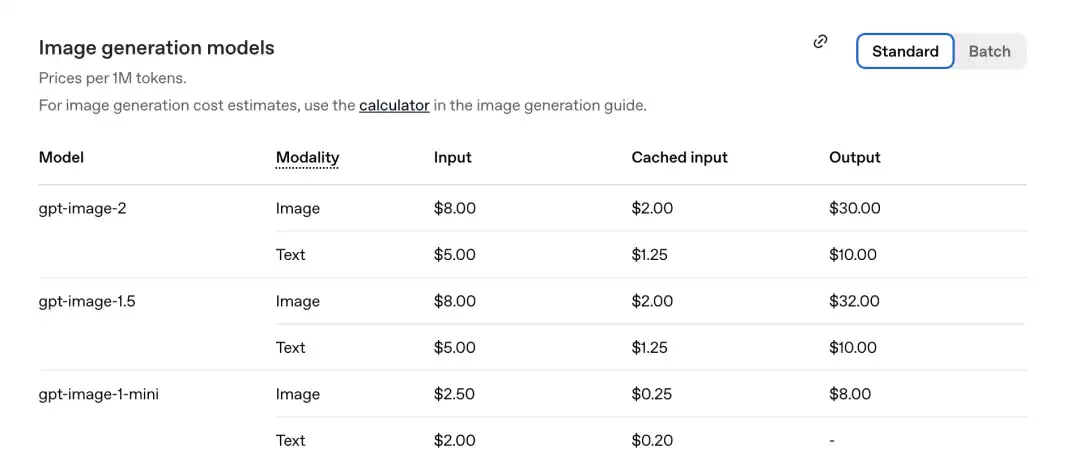
GPT-Image-2 চিত্র অংশ: ইনপুট 8.00, ক্যাশেড ইনপুট (Cachedinputs) 2.00, আউটপুট $30.00।
পূর্বপুরুষ gpt-image-1.5 এর তুলনায়: আউটপুট হল $32.00।
নতুন মডেলটি আরও সস্তা।
চলুন একটি হিসাব করি।
গত মডেলগুলিতে, একটি উচ্চ মানের ছবি তৈরি করতে প্রায় 1000 থেকে 1500 আউটপুট টোকেন খরচ হয়।
প্রতি মিলিয়ন আউটপুট টোকেনের জন্য 30 ডলারের মূল্য অনুযায়ী, একটি চিত্র তৈরির প্রকৃত খরচ প্রায় 0.03 থেকে 0.045 ডলারের মধ্যে (প্রায় 2 থেকে 3 মাও চীনা রেনমিনবি)।
যদি আপনি সেকেন্ডে প্রতিক্রিয়া চান না, বরং অফিসিয়াল ব্যাচ (ব্যাচ) API মোড ব্যবহার করেন, তাহলে এই দাম আরও অর্ধেক হয়ে যাবে (আউটপুট সরাসরি $15.00-এ নেমে যাবে)।
গণনা করে দেখা যায়, একটি চিত্র তৈরি করতে শুধুমাত্র 1 মাও এর বেশি খরচ পড়ে।
এই একক মূল্যটি ইতিমধ্যেই খুবই মূল্যবান, কিন্তু এর প্রকৃত হত্যাকারী হল মূল্য তালিকায় উপস্থিত ক্যাশড ইনপুট (Cached inputs)।
পূর্বে কমিক বুক বা একই সিরিজের পোস্টার ডিজাইন করার সময়, প্রতিবার পুনরায় জেনারেট করার জন্য আপনাকে অসংখ্য চরিত্রের রেফারেন্স ছবি, আগের পরিস্থিতি এবং দীর্ঘ প্রম্পট পুনরায় আপলোড করতে হত, যা ইনপুট খরচকে অত্যন্ত বেশি করে তোলে।
কিন্তু বর্তমান টোকেন চার্জিং মডেলে, আপনি যদি একসাথে 8টি সংযুক্ত কমিক জেনারেট করেন, তাহলে প্রথম চিত্রের ভিজুয়াল উপাদানগুলি সরাসরি কনটেক্সট ক্যাশে হিসাবে সংরক্ষিত হবে।
দ্বিতীয় চিত্র থেকে শুরু করে, ইমেজ ইনপুট খরচ সরাসরি $8.00 থেকে $2.00-এ পতন হয়েছে (অর্থাৎ শুধুমাত্র 25% টাকা নেওয়া হচ্ছে)।
এর অর্থ হলো, বড় পরিসরে ব্যবসায়িক ব্যাচ ইমেজ জেনারেশন বা চরিত্রের অত্যন্ত উচ্চ সামঞ্জস্যতা প্রয়োজনীয় ক্রমাগত জেনারেশনের ক্ষেত্রে, এর প্রান্তিক খরচ সরাসরি কমে যায়।
যত বেশি বুদ্ধিমান মডেল এবং যত বেশি চিত্র তৈরি করা হয়, প্রতিটি চিত্রের গড় খরচ তত কমে যায়।
এই ঔদ্যোগিক বিলিং যুক্তি হল সেই বাস্তবিক জিনিস যা লাইন আঁকনোর শ্রমিকদের প্রায়শই প্রান্তে ঠেলে দেয়।
পার্ট.05 পিছনের দলের পরিচয়
শেষে, আমরা আবার লাইভ প্রেজেন্টেশনে উপস্থিত হওয়া OpenAI-এর ভিজুয়াল ড্রীম টিমের দিকে ফিরে তাকাই, যেসব ফিচার আগে অসম্ভব মনে হচ্ছিল, এখন সম্পূর্ণভাবে বুঝতে পারছি।
উদাহরণস্বরূপ, এটি বহুভাষিক জটিল ফরম্যাটিং এবং অবিশ্বাস্য লেখার সমস্যা কীভাবে সমাধান করে।
এটি দলের প্রবীণ বিজ্ঞানী গ্যাব্রিয়েল গোহের অবদানের জন্যই সম্ভব।

এই শিক্ষাগত পরিবেশে, তিনি ক্রান্তিকারী মাল্টিমোডাল মডেল CLIP-এর প্রধান লেখক হিসাবে সবচেয়ে বেশি পরিচিত।
CLIP মানুষের ভাষা এবং ইমেজ পিক্সেলের মধ্যে সম্পর্ক বুঝতে আধুনিক এআইয়ের জন্য ভিত্তি স্থাপন করেছে।
এই বহুমাধ্যমিক অর্থ ম্যাপিংয়ের বিশেষজ্ঞের নেতৃত্বে, GPT-Image-2 শুধু টেক্সটের আকৃতি অনুমান করছে না, বরং পিক্সেল স্তরে প্রকৃতপক্ষে লিখছে।
আবার, এটি কিভাবে ত্রিমাত্রিক স্থানিক সম্পর্ক বুঝতে পারে, এমনকি চরম দৈর্ঘ্য-প্রস্থ অনুপাতের 360 ডিগ্রি প্যানোরামিক ছবি তৈরি করতে পারে এবং চালের দানার উপরের মাইক্রো-দূরত্বের আলো-ছায়া বুঝতে পারে।
এটি অন্য একজন কোর সদস্য আলেক্স ইউ-এর কারণে।

ওপেনএআই-এ যোগ দেওয়ার আগে, তিনি 3D জেনারেশন ক্ষেত্রের স্টার্টআপ Luma AI-এর সহ-প্রতিষ্ঠাতা এবং পূর্বের CTO ছিলেন এবং 3D নিউরাল রেন্ডারিং (NeRF ইত্যাদি) নিয়ে কাজ করা শীর্ষস্থানীয় গবেষক ছিলেন।
তার উপস্থিতিতে, GPT-Image-2 আসলে প্রাচীন 2D পিক্সেল পেইন্টিং থেকে বেরিয়ে এসেছে।
এটি সম্ভবত মস্তিষ্কে প্রথমে একটি ত্রিমাত্রিক দৃশ্য তৈরি করে, আলো সাজিয়ে, তারপর আপনাকে একটি সঠিক 2D কাটা রেন্ডার করে।
কিভাবে এই অত্যন্ত ভয়ঙ্কর বহুপৃষ্ঠের কমিক সামঞ্জস্যতা অর্জন করা হয়েছে।
এটি ম্যাসাচুসেটস ইনস্টিটিউট অফ টেকনোলজি (MIT CSAIL) থেকে সাম্প্রতিক প্রাপ্তিসম্পন্ন যুব জুটির সাথে সামঞ্জস্যপূর্ণ:
বয়ুয়ান চেন (বাম) এবং কিওয়ান সং (ডান)।
তাদের শিক্ষাগত ক্ষেত্রের মূল দিকগুলি হল ওয়ার্ল্ড মডেলস এবং এমবডিড ইন্টেলিজেন্স।
শিক্ষা দেওয়া যায় মেশিনকে পদার্থবিজ্ঞানের বিশ্ব কীভাবে কাজ করে তা বুঝতে, এবং চরিত্রগুলিকে বিভিন্ন সময় এবং স্থানের স্কিটসে সম্পূর্ণভাবে একই বৈশিষ্ট্য ধরে রাখতে, বিকৃতি ছাড়া, ঠিক এই দুই পণ্ডিতই সর্বদা সমাধানের চেষ্টা করেছেন।
শেষে, যুক্ত করুন যিনি রিজনিং বড় মডেল এবং ভিজুয়াল বেসিক লজিকের মধ্যে সংযোগ স্থাপনের জন্য সর্বদা কাজ করেছেন, নিথান্থ কুডিগে (বাম, O-সিরিজ রিজনিং মডেলের প্রধান লেখক) এবং কেনজি হাতা (ডান, পূর্বের গুগল গবেষক, স্ট্যানফোর্ড ভিজুয়াল ল্যাবরেটরি থেকে স্নাতক)।

যখন এই দলটি একত্রিত হয়, তখন মৌলিক যুক্তিবিদ্যা, 3D স্পেস রেন্ডারিং, গ্রাফিক্স এবং টেক্সটের পরম সামঞ্জস্য এবং ভৌত বিশ্বের নিয়মগুলি একই মডেলের মধ্যে সহজেই সংযুক্ত হয়ে যায়।
পার্ট.06 GPT-Image-2-এর সীমানা
প্রতিটি মডেলেরই সীমাবদ্ধতা আছে।
অফিসিয়ালও স্বীকার করেছে যে কিছু চরম পরিস্থিতির মুখোমুখি হলে এটি এখনও সংগ্রাম করে।
যেমন কঠোর ভৌত স্থান উল্টানোর প্রয়োজন হওয়া কাগজের গুচ্ছের নির্দেশিকা, রুবিক্স কিউব সমাধান, বা অত্যন্ত ঘন বালির কণার মতো অত্যধিক পুনরাবৃত্তিমূলক বিস্তারিত, এগুলি এখনও এর ক্ষমতার সীমানা স্পর্শ করে।
কিন্তু বাণিজ্যিক প্রয়োগের প্রেক্ষাপটে, এটি অত্যন্ত ক্ষুদ্র ত্রুটি।
ডিজাইন শিল্পের জন্য আমাদের উদ্বেগ বিক্রি করার প্রয়োজন নেই, এটি সৌন্দর্যের অবসানকে প্রতিনিধিত্ব করে না।
স্বাদ, ব্যবসায়িক দৃষ্টিভঙ্গি এবং কৌশল বোঝা মানুষ এখনও এটি দিয়ে অসাধারণ কিছু তৈরি করতে পারেন।
কিন্তু বাস্তবিক ঘটনা হলো, ডিজাইনার হিসেবে একটি পেশার প্রতিরক্ষামূলক সীমানা বাস্তবিকভাবে ধ্বংস হয়ে গেছে।
আগে, ডিজাইন সফটওয়্যারের শর্টকাট কীগুলি মুখস্থ করে, ফন্টগুলিকে সুষমভাবে সারিবদ্ধ করতে পারার মাধ্যমে, ভাষা অনুযায়ী টাইপোগ্রাফি করতে পারার মাধ্যমে, এবং সূক্ষ্মভাবে ছবি সংশোধন ও ব্যাকগ্রাউন্ড সরিয়ে ফেলার মাধ্যমে জীবিকা নির্বাহ করতাম।
কিন্তু ভবিষ্যতে এটি কঠিন হয়ে যাবে, কারণ এই অতীতে স্পষ্টভাবে মূল্যায়ন করে বিক্রি করা যায় এমন দক্ষতাগুলি এখন যেকোনো ব্যক্তি একটি বাক্য দিয়ে বিনামূল্যে ব্যবহার করতে পারে এমন একটি মৌলিক নির্দেশনা হয়ে গেছে।
একটি দীর্ঘ নীরবতার পর, ওপেনএআই একটি অত্যন্ত শান্ত, কিন্তু অত্যন্ত প্রভাবশালী উপায়ে প্রমাণ করেছে যে এই টেবিলে কার হাতেই প্রকৃতপক্ষে বেস কার্ডগুলি রয়েছে।
পুরনো এক্সিকিউশন টুলচেইন ভেঙে পড়ছে, এবং শিল্পের জন্য প্রশ্ন এখন এই নয় যে AI কি আমাদের প্রতিস্থাপন করবে, বরং আমাদের এই সম্পূর্ণ নতুন উৎপাদন লাইনের সাথে কীভাবে খাপ খাইয়ে নেওয়া উচিত।