










উৎস: CoinW গবেষণা প্রতিষ্ঠান
সারাংশ
Gradients হল Bittensor-এর উপর নির্মিত একটি ডিসেন্ট্রালাইজড এআই ট্রেনিং সাবনেট (SN56), যার মূল কাজ হল "টাস্ক পোস্টিং, মাইনার প্রতিযোগিতা, ভেরিফিকেশন সিলেকশন" ইত্যাদি মেকানিজমের মাধ্যমে মডেল ট্রেনিংকে জটিল টেকনিক্যাল প্রক্রিয়া থেকে মার্কেট-ড্রিভেন নেটওয়ার্ক কোঅপারেশনে রূপান্তরিত করা। আর্কিটেকচারে, এটি AutoML এবং ডিস্ট্রিবিউটেড কম্পিউটিংকে একত্রিত করে একটি ইনসেন্টিভ-ভিত্তিক ট্রেনিং মার্কেট গঠন করে, যা এআই ব্যবহারের বাধা কমায় এবং কম্পিউটিং ক্ষমতার ব্যবহারের দক্ষতা বাড়ায়। ইকোসিস্টেম এবং ডেটা পারফরম্যান্সের দিক থেকে, Gradients এখনও বেসিক নেটওয়ার্ক ইনফ্রাস্ট্রাকচার সম্পন্ন করেছে, তবে বর্তমানে ইনসেন্টিভওয়েটস এবং ফান্ডস ইনফ্লো সীমিত। Gradients TAO ইকোসিস্টেমের ট্রেনিং ইনফ্রাস্ট্রাকচারকে পূরণ করে এবং "মার্কেট-ড্রিভেন AI অপটিমাইজেশন"-এর একটি নতুন প্যারাডাইমকে অনুসন্ধান করছে, যা দীর্ঘমেয়াদীভাবে ডিসেন্ট্রালাইজড AI ট্রেনিংয়ের একটি গুরুত্বপূর্ণ এন্ট্রি-লেয়ার হিসাবে বিকশিত হওয়ার সম্ভাবনা রাখে।
1. ওয়েব2 অটোএমএল থেকে শুরু করি: এআই ট্রেনিংয়ের বর্তমান অবস্থা এবং সীমাবদ্ধতা
1.1 অটোএমএল কী
প্রাচীন ধারণায়, একটি এআই মডেল প্রশিক্ষণ দেওয়া হল একটি উচ্চ বাধা বিশিষ্ট কাজ, যেখানে ইঞ্জিনিয়ারদের ডেটা পরিচালনা, মডেল নির্বাচন, প্যারামিটার বারবার সামঞ্জস্য করতে হয় এবং ফলাফল মূল্যায়ন করতে হয়—সম্পূর্ণ প্রক্রিয়াটি জটিল এবং সময়সাপেক্ষ। AutoML (অটোমেটেড মেশিন লার্নিং)-এর আবির্ভাব মূলত এই জটিল ধাপগুলিকে “অটোমেটেড প্যাকেজ”-এ রূপান্তরিত করে। এটিকে একটি “অটোমেটিক মডেল তৈরির টুল” হিসেবে বুঝা যেতে পারে: ব্যবহারকারীকে শুধুমাত্র ডেটা প্রদান করতে হবে এবং সিস্টেমকে বলতে হবে যে তিনি কী লক্ষ্য চান—যেমন, শ্রেণীবদ্ধকরণ, ভবিষ্যদ্বাণী বা চিহ্নিতকরণ—এবং বাকি সমস্ত প্রক্রিয়া, যেমন মডেল নির্বাচন, প্যারামিটার সামঞ্জস্য, প্রশিক্ষণ এবং অপ্টিমাইজেশন, সিস্টেমটি স্বয়ংক্রিয়ভাবে সম্পন্ন করবে। এটি AI-কে কয়েকজন 전专业ইঞ্জিনিয়ারদেরই সীমিত টুলথেকে,সাধারণডেভেলপারদেরএবংব্যবসাগুলিওব্যবহারযোগ্যক্ষমতায়পরিণতকরেছে,যাAI-এরজনপ্রিয়তারদিকেএকটিমুখ্যপদক্ষেপ।
1.2 প্রাচীন AutoML-এর মূল সীমাবদ্ধতা
বর্তমানে অটোএমএল-এর প্রধান বাস্তবায়নগুলি ক্লাউড প্রোভাইডার প্ল্যাটফর্মগুলিতে কেন্দ্রীভূত, যেমন Google Vertex AI এবং AWS SageMaker, যেগুলি "AI ট্রেনিং অ্যাস এ সার্ভিস" প্রদান করে। যদিও Web2 AutoML AI ব্যবহারের বাধা উল্লেখযোগ্যভাবে কমিয়েছে, তবুও এর নীচের মডেলগুলিতে স্পষ্ট সীমাবদ্ধতা রয়েছে। প্রথমত, কেন্দ্রীয়করণের সমস্যা, যেখানে কম্পিউটিং শক্তি, মূল্যনির্ধারণ এবং নিয়মগুলি সম্পূর্ণরূপে প্ল্যাটফর্মগুলির নিয়ন্ত্রণে থাকে, ফলে ব্যবহারকারীরা একটি একক সরবরাহকারীর উপর অত্যধিক নির্ভরশীল হয়ে পড়েন এবং বাজেটের জন্য আলোচনার ক্ষমতা অভাব থাকে। দ্বিতীয়ত, খরচ উচ্চ এবং অস্বচ্ছ, কারণ AI ট্রেনিংয়ের জন্য GPU সম্পদগুলি মূলত ক্লাউড প্রোভাইডারদের হাতেই কেন্দ্রীভূত, এবং মূল্যনির্ধারণের কৌশলগুলিতে বাজার-ভিত্তিক প্রতিযোগিতা অনুপস্থিত। আরও গুরুত্বপূর্ণভাবে, অপটিমাইজেশনের দক্ষতা একটি সীমা অতিক্রম করতে পারে। পারম্পরিক AutoML-এর মূলত "একটি সিস্টেম আপনার জন্য সর্বোত্তম সমাধানটি খুঁজছে", যদিও এই সিস্টেমটি কতটা জটিলই হোক, এটি本质上ইএকটি একক-পথ-অপটিমাইজেশন।এটিরঅনসন্ধানকৃতক্ষেত্রসীমিত,এবংএকসঙ্গেঅনেকগুলিসমEscapeপথপরীক্ষাকরা"সহজনয়।অতএববর্তমানWeb2AIট্রেনিংএকটি"বন্ধপদ্ধতি",যা"একটিমাত্রপ্ল্যাটফর্মদ্বারানিয়ন্ত্রিতপরিবেশে"মডেলট্রেনিং,অপটিমাইজেশনএবংসম্পদসংহতকরণহয়।এইপদ্ধতিটি"যদিওদক্ষ,তবুওচাহিদাবৃদ্ধিরসঙ্গেসঙ্গেএটিরসীমা"ধীরেধীরেপরিষ্কারহয়েউঠছে।
2. গ্রেডিয়েন্টস: এআই ট্রেনিংকে "নেটওয়ার্ক" দিয়ে পুনর্গঠন করুন
2.1 গ্রেডিয়েন্টস কী: একটি ডিসেন্ট্রালাইজড অটোএমএল প্ল্যাটফর্ম
পূর্ববর্তী অধ্যায়ে আমরা উল্লেখ করেছি যে, প্রাচীন Web2 AutoML-এর মূল সমস্যা হল “বন্ধ সিস্টেম” — মডেল প্রশিক্ষণ প্ল্যাটফর্মের উপর নির্ভরশীল, অপ্টিমাইজেশনের পথ সীমিত এবং সম্পদের প্রবাহ সীমিত। Gradients এই মডেলের একটি পুনঃগঠন। Gradients WanderingWeights দ্বারা শুরু করা একটি ডিসেন্ট্রালাইজড ইঞ্জিনিয়ার সম্প্রদায় থেকে উদ্ভূত হয়েছে, যা Bittensor নেটওয়ার্কের উপর ভিত্তি করে গঠিত এবং Subnet 56-এ চলমান AI প্রশিক্ষণ সাবনেট। প্রাচীন প্ল্যাটফর্মগুলির বিপরীতে, এটি কেন্দ্রীয়ভাবে সেবা প্রদান করে না, বরং প্রশিক্ষণ প্রক্রিয়াকে ভাগ করে একটি খোলা নেটওয়ার্কের মাধ্যমে সম্পন্ন করে। ব্যবহারকারীদের শুধুমাত্র একটি কাজের লক্ষ্য সংজ্ঞায়িত করতে হয়, যেমন: মডেলের ধরন এবং ডেটা, বাকি প্রক্রিয়াগুলি —যেমন: প্রশিক্ষণ বাস্তবায়ন, পরামিতি অপটিমাইজেশন এবং ফলাফলের ছাঁটাই—সমস্তই নেটওয়ার্কটি স্বয়ংক্রিয়ভাবে সম্পন্ন করে। এই মডেলে, AI প্রশিক্ষণকে জটিল ইঞ্জিনিয়ারিংপ্রক্রিয়াগুলির থেকে “অনুরোধ জমা দিন,ফলাফল পান” —এই সহজপদ্ধতিতে সহজভাবে abstracটিংয়ের (সহজভাবে)পরিণতকরা হয়,যাএকটিবিশেষজ্ঞপদক্ষমতা-এরচেয়েএকটিসাধারণক্ষমতারসমান।
2.2 বন্ধ সিস্টেম থেকে খোলা সহযোগিতায়: গ্রেডিয়েন্টস কী সমস্যার সমাধান করে
গ্রেডিয়েন্টসের মূল পরিবর্তন হল একটি একক প্ল্যাটফর্মের ভিতরে বন্ধ প্রশিক্ষণ প্রক্রিয়াকে একটি খোলা সহযোগিতামূলক নেটওয়ার্ক প্রক্রিয়াতে রূপান্তরিত করা। প্রশিক্ষণ কাজগুলি একটি একক সিস্টেম দ্বারা সম্পন্ন হয় না, বরং এগুলি বিভিন্ন অংশগ্রহণকারীদের দ্বারা সমান্তরালভাবে চেষ্টা করা হয় এবং একটি একীভূত মূল্যায়ন পদ্ধতির মাধ্যমে সর্বোত্তম ফলাফলগুলি বাছাই করা হয়। এই কাঠামোটি প্রথমতঃ কেন্দ্রীয় সেবাদাতাদের উপর নির্ভরশীলতা কমিয়ে প্রশিক্ষণকে বিতরণকৃত কম্পিউটিং ক্ষমতার উপর ভিত্তি করে গড়ে তোলে; এছাড়াও, বিকেন্দ্রীভূত GPU সম্পদগুলি একই নেটওয়ার্কের মধ্যে একত্রিত হয়, যা প্রতিযোগিতার মাধ্যমে বাজার-সদৃশ সম্পদ বণ্টনের দিকে নিয়ে যায়। আরও গুরুত্বপূর্ণভাবে, মডেলের অপটিমাইজেশনটি একটি একক পথের সীমার মধ্যেই सीमित नहीं है, बल्कि विभिन्न विधियों के समानांतर अन्वेषण में लगातार अधिक उत्तम समाधान की ओर अग्रसर होता है, जिससे समग्र अपटिमाइजेशन सीमा बढ़ जाती है।
2.3 মূল পরিবর্তন: টুল থেকে “ট্রেনিং মার্কেট”
প্রাচীন AutoML-এ, প্ল্যাটফর্মটি একটি টুলের মতো কাজ করে, যা অন্তর্নিহিত অ্যালগরিদমের মাধ্যমে ব্যবহারকারীদের সর্বোত্তম সমাধান খুঁজে বের করতে সাহায্য করে। কিন্তু Gradients-এ, এই প্রক্রিয়াটি একটি নিরন্তর চলমান “বাজার”-এর মতো: ব্যবহারকারীরা তাদের প্রয়োজনীয়তা প্রকাশ করে, বিভিন্ন অংশগ্রহণকারীরা একই কাজের চারপাশে প্রতিযোগিতা করে, এবং মূল্যায়ন পদ্ধতির মাধ্যমে ফলাফলগুলি বাছাই করা হয়। এইভাবে, মডেলের কর্মক্ষমতা একক সিস্টেমের ক্ষমতার উপর নির্ভর করে না, বরং বহুপক্ষীয় অংশগ্রহণের মাধ্যমে নিরন্তর প্রতিযোগিতা এবং পুনরাবৃত্তির ফলে উৎপন্ন হয়। AutoML-ও একটি আপেক্ষিকভাবে বন্ধ প্রযুক্তিগত অপটিমাইজেশনের সমস্যা থেকে একটি উদ্দীপনা-চালিত গতিশীল প্রক্রিয়ায় পরিণত হয়েছে, যা অংশগ্রহণকারীদের সংখ্যা বৃদ্ধির সাথে সাথে অপটিমাইজেশনের ক্ষমতা বিস্তৃত করতে পারে। এই পরিবর্তনটি AI-এর প্রশিক্ষণকে বাজারের মতো আত্ম-বিকাশশীল বৈশিষ্ট্যগুলির সঙ্গে শুরু করেছে।
2.4 TAO ইকোসিস্টেমে ভূমিকা: এআই প্রশিক্ষণ ইনফ্রাস্ট্রাকচার লেয়ার
বিটটেনসরের সাবনেট সংগঠনে, বিভিন্ন সাবনেট যথাক্রমে যুক্তিসঙ্গত করা, ডেটা প্রক্রিয়াকরণ এবং প্রশিক্ষণের মতো বিভিন্ন কাজ পালন করে, এবং গ্রেডিয়েন্টস প্রশিক্ষণ স্তরে অবস্থিত। এটি বিকেন্দ্রীকৃত ক্ষমতাকে বাস্তব মডেল আউটপুটে রূপান্তরিত করে এবং টাস্ক বন্টন এবং মূল্যায়ন পদ্ধতির মাধ্যমে এই সম্পদগুলিকে নিরন্তরভাবে সমন্বয় এবং অপ্টিমাইজ করে। এটি ক্ষমতা সরবরাহ এবং মডেলের চাহিদাকেও সংযুক্ত করে, যার ফলে প্রশিক্ষণকে শুধুমাত্র একটি সম্পদ খরচের প্রক্রিয়া থেকে একটি সংগঠিত এবং অপ্টিমাইজড নেটওয়ার্ক-ভিত্তিক সহযোগিতার প্রক্রিয়ায় রূপান্তরিত করে। এই ব্যবস্থায়, গ্রেডিয়েন্টস একটি কেন্দ্রীয় পদক্ষেপের মতো, যা বিকেন্দ্রীকৃত সম্পদগুলিকে ব্যবহারযোগ্য AI ক্ষমতায় রূপান্তরিত করে এবং উপরের অ্যাপ্লিকেশনগুলির উন্নয়নকে সমর্থন করে।
3. কোর আর্কিটেকচার: এআই ট্রেনিং কীভাবে নেটওয়ার্কে সম্পন্ন হয়
পূর্ববর্তী অধ্যায়ে আমরা উল্লেখ করেছিলাম যে, গ্রেডিয়েন্টস এআই প্রশিক্ষণকে “প্ল্যাটফর্মের ভিতরে সম্পন্ন” থেকে “নেটওয়ার্কের মাধ্যমে সহযোগিতায় সম্পন্ন”-এ রূপান্তরিত করেছে। তাহলে, এই নেটওয়ার্কটি ঠিক কিভাবে কাজ করে? এই অধ্যায়টির মূল বিষয় হলো এই প্রক্রিয়াটিকে আরও সহজভাবে বিশ্লেষণ করা।
3.1 ডিস্ট্রিবিউটেড ট্রেনিং: একটি টাস্ক কীভাবে “একাধিক ব্যক্তি দ্বারা” সম্পন্ন হয়
গ্রেডিয়েন্টসকে একটি চলমান “ট্রেনিং কো-অপারেটিভ নেটওয়ার্ক” হিসাবে কল্পনা করুন। যখন কোনো ব্যবহারকারী একটি ট্রেনিং টাস্ক জমা দেয়, তখন এই টাস্কটি শুধুমাত্র একটি সিস্টেমের দ্বারা সম্পন্ন হয় না, বরং এটি নেটওয়ার্কের একাধিক অংশগ্রহণকারীর মধ্যে একসাথে বিতরণ করা হয়। এই অংশগ্রহণকারীদের প্রত্যেকে একই ডেটা এবং লক্ষ্যের ভিত্তিতে বিভিন্ন ট্রেনিং পদ্ধতির চেষ্টা করেন এবং নির্ধারিত সময়ের মধ্যে ফলাফল জমা দেন। তারপর, সিস্টেমটি এই ফলাফলগুলির একটি সমন্বিত মূল্যায়ন করে, এবং সর্বোত্তমভাবে পারফর্ম করা সমাধানটি বাছাই করে। শেষপর্যন্ত, সর্বোত্তমভাবে পারফর্ম করা ফলাফলগুলিকেই পুরস্কার দেওয়া হয়, অন্যান্য সমাধানগুলি বাদ পড়ে। ব্যবহারকারীর দৃষ্টিকোণে, এই প্রক্রিয়াটির জন্য শুধুমাত্র একবার টাস্কটি শুরু করলেই, এটি “একসাথে” বিভিন্ন অপটিমাইজেশনের ধারণা “কল” করা হয়, এবং সর্বোত্তম সমাধানটি 자동으로 নির্বাচিত হয়। এইপদ্ধতির মূলগতভাবে,একটি nodedeশক্তিশালীহওয়ায়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নয়নay
এই নেটওয়ার্কে মূলত তিনটি প্রতিভাগী রয়েছে: ব্যবহারকারী, মাইনার এবং যাচাইকারী। ব্যবহারকারীরা প্রশিক্ষণের প্রয়োজনীয়তা প্রস্তাব করে; মাইনাররা কম্পিউটিং পাওয়ার প্রদান করে এবং বিভিন্ন প্রশিক্ষণ পদ্ধতি পরীক্ষা করে; যাচাইকারীরা ফলাফল মূল্যায়ন করে এবং সর্বোত্তম মডেলটি বাছাই করে। এই বিভাজনটি প্রশিক্ষণ প্রক্রিয়াকে চলমান রাখে এবং ধাপে ধাপে উৎকৃষ্টতর সমাধানগুলি বাছাই করে। সামগ্রিকভাবে, এটি “প্রয়োজনীয়তা, যোগান, মূল্যায়ন”-এর দ্বারা পরিচালিত একটি সহযোগিতামূলক নেটওয়ার্ক গঠন করে।
3.2 মার্কেট-ড্রিভেন অটোএমএল
পূর্ববর্তী মেকানিজম বিশ্লেষণে দেখা যায় যে, গ্রেডিয়েন্টস শুধুমাত্র অটোএমএলকে ব্লকচেইনে স্থানান্তরিত করে না, বরং একাধিক পক্ষের অংশগ্রহণ এবং উদ্দীপনা ব্যবস্থার মাধ্যমে মডেল অপ্টিমাইজেশনের মৌলিক যুক্তি পরিবর্তন করে। প্রচলিত অটোএমএল একক সিস্টেমের উপর নির্ভর করে সীমিত পথে সর্বোত্তম সমাধান খুঁজে বারায়, কিন্তু গ্রেডিয়েন্টস-এ এই প্রক্রিয়াটি পুরো নেটওয়ার্কে প্রসারিত হয়: বিভিন্ন অংশগ্রহণকারীরা একই কাজের জন্য বিভিন্ন পদ্ধতি চেষ্টা করে এবং একটি একক মূল্যায়নের মাধ্যমে ধারাবাহিকভাবে ছাঁটাই এবং পুনরায় পরিবর্তন করে। এটি মডেল অপ্টিমাইজেশনকে একবারের গণনা প্রক্রিয়ার বদলে পুনরাবৃত্তির মাধ্যমে বিকশিত হওয়ার একটি গতিশীল প্রক্রিয়ায় পরিণত করে। এই মেকানিজমের অধীনে, উৎকৃষ্টতর ফলাফলগুলি বেশি আয় অর্জন করে, যা অংশগ্রহণকারীদেরকে পুনরায় কৌশলগতভাবে উন্নতির জন্য আকৃষ্ট করে, ফলস্বরূপ সমগ্রফলটির গুণগতমানকে ধারাবাহিকভাবেউন্নতির দিকে নিয়ে যায়।
৪. উৎসাহ এবং প্রতিযোগিতার কাঠামো: এআই প্রশিক্ষণ কীভাবে “সক্রিয় চক্র” গঠন করে
4.1 ইনসেন্টিভ মেকানিজম (TAO-ড্রাইভন): ট্রেনিং অ্যাকশন থেকে রিওয়ার্ড পর্যন্ত
গ্রেডিয়েন্টসের দীর্ঘমেয়াদি কার্যক্ষমতার চাবিকাঠি হল এর পিছনের উদ্দীপনা ব্যবস্থা। এটি বিটটেনসর দ্বারা প্রদানকৃত নেটিভ উদ্দীপনা ব্যবস্থার উপর নির্ভর করে। এখানে, TAO হল বিটটেনসর নেটওয়ার্কের নেটিভ টোকেন, যা পুরো নেটওয়ার্কের “মূল্য বহনকারী”: একদিকে এটি কম্পিউটেশনাল পাওয়ার এবং মডেল অবদান রাখা প্রতিভাগীদের পুরস্কার হিসেবে ব্যবহৃত হয়, অন্যদিকে এটি স্টেকিংয়ের মতো পদ্ধতির মাধ্যমে সাবনেট ওজন বণ্টনেও অংশগ্রহণ করে, যা বিভিন্ন সাবনেটের মধ্যে সম্পদের প্রবাহকে প্রভাবিত করে।
বিটটেনসর মেইননেট নিয়মিত নতুন ইমিশন (টিএও) উৎপাদন করে (বর্তমানে প্রতিদিন প্রায় 3600 টিএও), এবং এটি বিভিন্ন সাবনেটে নির্দিষ্ট নিয়ম অনুযায়ী বণ্টন করা হয়। প্রতিটি সাবনেট কতটা পাবে, তা নির্ভর করে এর পুরো নেটওয়ার্কে “পারফরম্যান্স”-এর উপর, যেমন সক্রিয়তা, অবদানের গুণগত মান এবং ফান্ডিং সমর্থন ইত্যাদি। গ্রেডিয়েন্টসের সাবনেটের ক্ষেত্রে, এই বণ্টিত টিএও অন্তর্গত পুনরায় অংশগ্রহণকারীদের মধ্যে বণ্টন করা হয়। বণ্টনের মূল ভিত্তি হলো—কে কোন মডেলটি ভালোভাবে অবদান রাখে, সেই ব্যক্তিরই বেশি আয় হয়।
বিস্তারিতভাবে দেখুন, মাইনাররা প্রশিক্ষণের ফলাফল জমা দেয়, যেখানে যাচাইকারীরা এই ফলাফলগুলি পরীক্ষা করে এবং স্কোর দেয়। সিস্টেম স্কোরিংয়ের ভিত্তিতে প্রতিটি অংশগ্রহণকারীর “অবদান ওজন” গণনা করে, এবং এই ওজনের ভিত্তিতে পুরস্কার বণ্টন করে। ভালো পারফরম্যান্স করা মডেলগুলি (যেমন, যেগুলির জেনারেলাইজেশন ক্ষমতা বেশি এবং ফলাফল স্থিতিশীল) বেশি আয় পায়, আর যাচাইকারীদেরও যদি তাদের স্কোরিংটি আরও সঠিক হয় এবং বাস্তবিক মানকে ভালোভাবে প্রতিফলিত করে, তবে তাদেরও বেশি উৎসাহিত করা হয়। এই ডিজাইনটি “ভালোভাবে করা”-কে “বেশি আয়”-এর সঙ্গে সরাসরি সংযুক্ত করে, যা অংশগ্রহণকারীদেরকে মডেলগুলি নিয়মিতভাবে উন্নতির জন্য উৎসাহিত করে।
4.2 সাবনেটের মধ্যে প্রতিযোগিতা: কেবল অভ্যন্তরীণ প্রতিযোগিতা নয়, বাহ্যিক র্যাঙ্কিংও
সাবনেটের ভিতরের প্রতিযোগিতার পাশাপাশি, গ্রেডিয়েন্টস বিটটেনসর নেটওয়ার্কের মধ্যে “হরিজন্টাল কম্পিটিশন”-এরও মুখোমুখি হয়। যেহেতু TAO-এর বণ্টন ডাইনামিক, বিভিন্ন সাবনেটগুলি উচ্চতর ওয়েটেজের জন্য প্রতিদ্বন্দ্বিতা করে। শুধুমাত্র সেই সাবনেটগুলিই বড় পুরস্কার শেয়ার পায়, যারা নিরন্তরভাবে উচ্চমানের ফলাফল তৈরি করে এবং বেশি প্রতিভাগকারীকে আকর্ষণ করে। তাই, গ্রেডিয়েন্টস-এর ইনসেন্টিভ শুধুমাত্র অভ্যন্তরীণ মডেল পারফরম্যান্সের উপর নির্ভরশীল নয়, বরং এটি পুরো ইকোসিস্টেমের মধ্যে এর আপেক্ষিক প্রতিযোগিতামূলকতারও উপর। সমগ্র সিস্টেমটি একটি বহু-স্তরীয় চক্রকে গঠন করে: সাবনেটের ভিতরে মডেলগুলির মধ্যে প্রতিযোগিতা; সাবনেটগুলির মধ্যে সামগ্রিক পারফরম্যান্সের প্রতিযোগিতা। শেষপর্যন্ত, কম্পিউটিং পাওয়ার, মডেলের কার্যকারিতা এবং আর্থিক ফলাফলকে একত্রিত করা হয়, যা একটি চলমান, ধনাত্মক-ফিডব্যাক মেকানিজমকে গঠন করে।
4.3 গ্রেডিয়েন্ট 5.0: প্রতিযোগিতা থেকে “টুর্নামেন্ট মেকানিজম”
প্রাথমিক স্থির প্রতিযোগিতার ভিত্তিতে, গ্রেডিয়েন্টস আরও সংগঠিত পদ্ধতি, অর্থাৎ “টুর্নামেন্ট-ভিত্তিক প্রশিক্ষণ”-এ বিকশিত হয়েছে। এটিকে একটি পৌনঃপুনিক প্রতিযোগিতা হিসাবে বুঝা যায়: প্রতিটি প্রশিক্ষণ চক্রে সময়ের একটি জানালা নির্ধারণ করা হয়, যেখানে একই কাজের জন্য অনেকগুলি অংশগ্রহণকারী প্রতিদ্বন্দ্বিতা করে এবং একাধিক পর্যায়ে বাছাইয়ের মাধ্যমে ধীরে ধীরে বাদ পড়ে, শেষপর্যন্ত সর্বোত্তম সমাধানটি নির্বাচিত হয়। এই ফরম্যাটটি পর্যায়ক্রমিক তুলনা এবং কেন্দ্রীয় মূল্যায়নকে জোর দেয়। একটি গুরুত্বপূর্ণ পরিবর্তন হলো, মাইনাররা প্রশিক্ষণের ফলাফল সরাসরি জমা দেয় না, বরং “প্রশিক্ষণ পদ্ধতি” (কোড) জমা দেয়, যা পরবর্তীতে যাচাইকারী নোডগুলি একসাথে চালায়। এটি একদিকে নিরপেক্ষতা বাড়ায়, বিভিন্ন গণনা পরিবেশের বিঘ্ন এড়ায়, আবার অন্যদিকে ডেটা এবং প্রশিক্ষণ প্রক্রিয়ার গোপনীয়তা ভালভাবে সুরক্ষিত করে। অতিরিক্তভাবে, বিজয়ী সমাধানগুলির অধিকাংশই সঞ্চয়িত হয়, যা পুনঃব্যবহারযোগ্য পদ্ধতিরূপে কাজ করে, যা ধীরেধীরে “সেরা অনুশীলন”-এর মতোই tích lũy।দীর্ঘমেয়াদি,এইপদ্ধতিটিশুধুমাত্রসেরামডেলগুলিকেবাছাইকরছে,এটিএকটিনিরন্তরবিকশিতপ্রশিক্ষণপদ্ধতিরবইখানা-ওগড়েতুলছে।
5. ইকোসিস্টেমের বর্তমান অবস্থা
5.1 প্রতিভাগী কাঠামো: চাহিদা, যোগান এবং মূল্যায়ন দ্বারা গঠিত সহযোগিতামূলক নেটওয়ার্ক
গ্রেডিয়েন্টস ইকোসিস্টেম তিনটি কেন্দ্রীয় ভূমিকা দ্বারা গঠিত: ব্যবহারকারী (চাহিদা পক্ষ), মাইনার (সরবরাহ পক্ষ) এবং যাচাইকারী (মূল্যায়ন পক্ষ)। ব্যবহারকারীদের মধ্যে প্রধানত AI ডেভেলপার, ক্ষুদ্র ও মাঝারি উদ্যোগ এবং Web3 বিল্ডার অন্তর্ভুক্ত, যাদের সাধারণত কিছুটা প্রযুক্তিগত জ্ঞান থাকে, কিন্তু কম্পিউটেশনাল পাওয়ার বা সম্পূর্ণ মডেল ট্রেনিংয়ের ক্ষমতা নেই, তাই তারা Gradients-এর মাধ্যমে কম খরচে মডেল তৈরির পক্ষে পছন্দ করে। মাইনাররা GPU কম্পিউটেশনাল পাওয়ার প্রদান করে এবং ট্রেনিং টাস্কের জন্য প্রতিযোগিতা করে, যাদের মূল উদ্দেশ্য TAO আয় অর্জন; যাচাইকারীরা ট্রেনিংয়ের ফলাফল মূল্যায়ন এবং র্যাঙ্কিংয়ের দায়িত্ব বহন করে, যা মডেলের গুণগতমান এবং পদ্ধতির কার্যকরীভাবে চলমানতা নিশ্চিতকরণের জন্য একটি কীভূমিকা।
আরও বিস্তারিত ব্যবহারকারী প্রোফাইলের দিক থেকে, গ্রেডিয়েন্টসের প্রকৃত ব্যবহারকারী দলটি স্পষ্টভাবে "অর্ধ-ডেভেলপার-কেন্দ্রিক" বৈশিষ্ট্য প্রদর্শন করে: এটি শীর্ষ AI ল্যাবগুলির মতো নয়, এবং সম্পূর্ণ অ-প্রযুক্তিগত সাধারণ ব্যবহারকারীদেরও নয়, বরং এটি কিছুটা ইঞ্জিনিয়ারিং দক্ষতা সম্পন্ন ডেভেলপারদের এবং Web3 প্রযুক্তি ব্যবহারকারীদের উপর ভিত্তি করে। এই বিষয়টি তাদের সম্প্রদায়ের কাঠামোতেও প্রতিফলিত হয়, যেখানে বর্তমান ইকোসিস্টেমটি ইংরেজি ভাষাকে কেন্দ্র করে, মূল ব্যবহারকারীরা উত্তর আমেরিকা এবং ইউরোপের ডেভেলপারদের মধ্যে অবস্থিত, একইসঙ্গে দক্ষিণ-পূর্ব এশিয়ার কয়েকজন মাইনার এবং বিশ্বব্যাপী GPU সম্পদ প্রদানকারীদেরও কভার করে। সামগ্রিকভাবে, এটি একটি প্রযুক্তি-চালিত ডেভেলপার সম্প্রদায়ের কাছাকাছি।
5.2 ইকোসিস্টেমের বর্তমান পরিচালনা
মে 12 এর পর্যন্ত, গ্রেডিয়েন্টসের অ্যালফা টোকেনের দাম প্রায় 0.0255 TAO, ধারক ঠিকানা প্রায় 4,890টি, মাইনার 243টি, যাচাইকারী 12টি, এবং ইমিশনের অনুপাত 1.61%। একইসময়ে, এর তরলতা পুলে TAO অনুপাত 2.19% এবং Alpha অনুপাত 97.81%। দাম এবং ধারক সংখ্যা দেখে, গ্রেডিয়েন্টসের কিছুটা ব্যবহারকারী ভিত্তি এবং মনোযোগ রয়েছে, তবে সমগ্রভাবে এখনও প্রাথমিক ছড়িয়েপড়ার পর্যায়ে। Chutes-এর সাথে তুলনা করলে, TAO ইকোসিস্টেমের শীর্ষ প্রকল্প, ঐদিনের অ্যালফা টোকেনের দাম 0.0877 TAO, এবং ধারক ঠিকানা 13,409টি।
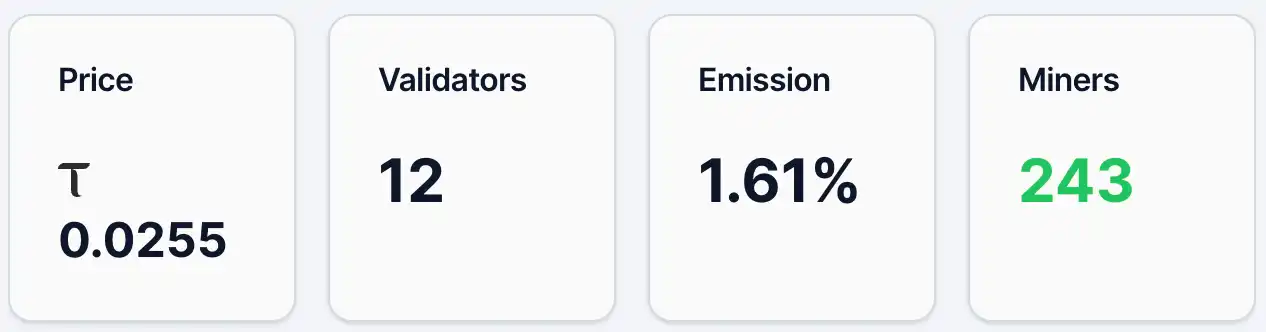
চিত্র 1. গ্রেডিয়েন্টস ডেটা।
উৎস:https://bittensormarketcap.com/subnets/56
পরবর্তী হল Emission ইনসেন্টিভ মেকানিজম। বিটটেনসর সিস্টেমে, Emission বলতে সেই সাবনেটটির রিয়েল-টাইম বণ্টন ওজনকে বোঝায় যা পুরো নেটওয়ার্কের নতুন পুরস্কারের মধ্যে বণ্টিত হয়। বিটটেনসর নেটওয়ার্ক নিয়মিত নতুন TAO তৈরি করে এবং ওজন অনুযায়ী বিভিন্ন সাবনেটগুলিকে বণ্টন করে, যেখানে Gradients-এর বর্তমান 1.61% মানে এটি পুরো নেটওয়ার্কের নতুন ইনসেন্টিভের মধ্যে কেবলমাত্র একটি ছোট অংশই পায়। এই সূচকটি মূলত বাজারকে প্রতিফলিত করে—যেমন staking-এর মাধ্যমে—বিভিন্ন সাবনেটগুলির উপর “ভোট”। তাই, 1.61% স্তরটি সাধারণত বর্তমানে বাজারের স্বীকৃতি এবং ফান্ড ইনফ্লোয়ের সীমিত পরিমাণকেই নির্দেশ করে, অন্যদিকে, এটি ভবিষ্যতেও ওজন বাড়ানোর জন্য সম্ভাবনা রাখে। ফান্ডিং স্ট্রাকচার (লিকুইডিটি পুল) দেখলে, TAO-এর অংশশতাংশ মাত্র 2.19%, যখন Alpha-এর 97.81%—যা বাইরের ফান্ড ইনফ্লোয়েরও সীমিততা প্রকাশ করে, এখনও মূলত সাবনেট-ভিত্তিক সরবরাহই প্রধান। দামগুলি নতুন ফান্ডের প্রতি অত্যন্ত সংবেদনশীল; TAO-এর আরও প্রবাহের সঙ্গে, একটি প্রখরতর গুণিতক প্রভাবও দেখা দিতে পারে।
6. প্রতিযোগিতামূলক পরিস্থিতি এবং সুবিধা-অসুবিধা
6.1 ইন্ডাস্ট্রি পজিশনিং: ডিসেন্ট্রালাইজড AutoML ট্রেনিং ইনফ্রাস্ট্রাকচার
গ্রেডিয়েন্টস একটি নির্দিষ্ট সাব-সেগমেন্টে কাজ করে যা "AI ট্রেনিং ইনফ্রাস্ট্রাকচার + ডিসেন্ট্রালাইজড অটোএমএল"। এটি মডেল ট্রেনিংকে সেন্ট্রালাইজড প্ল্যাটফর্মগুলি থেকে মুক্ত করার চেষ্টা করে এবং নেটওয়ার্ককৃত মেকানিজমের মাধ্যমে সম্পদের দক্ষতার সাথে মডেল অপ্টিমাইজেশন অর্জন করে। Web2 সিস্টেমে, এই সাব-সেগমেন্টটি আপেক্ষিকভাবে পরিপক্ক, যার প্রতিনিধিত্বকারীগুলির মধ্যে রয়েছে Google Vertex AI এবং AWS SageMaker। এই প্ল্যাটফর্মগুলি ক্লাউড কম্পিউটিংয়ের মাধ্যমে ডেভেলপারদের এক-স্টপ মডেল ট্রেনিং এবং ডিপ্লয়মেন্ট সেবা প্রদান করে, তবে এর মূলভিত্তি এখনও সেন্ট্রালাইজড আর্কিটেকচার। এর বিপরীতে, Gradients-এর পার্থক্য "আরও বেশি ফিচার" নয়, বরং এটির মৌলিক যুক্তি: এটি "প্ল্যাটফর্ম-সার্ভিস"কে "নেটওয়ার্ক-কোঅপারেশন"এ রূপান্তরিত করে এবং প্রতিযোগিতামূলক মেকানিজমের মাধ্যমে সর্বোত্তম ফলাফলগুলি বাছাই করে, যা এটিকে একটি বাজার-ভিত্তিক ট্রেনিং সিস্টেমের কাছাকাছি নিয়ে আসে।
6.2 তুলনামূলক বিশ্লেষণ: Web2 এবং Web3 AutoML-এর পার্থক্য
Web2 এবং Web3-এর মধ্যে AutoML-এর দিক থেকে পার্থক্যটি মূলত দুটি ভিন্ন প্যারাডাইমের তুলনা। Web2 মডেলটি দক্ষতা এবং স্থিতিশীলতাকে জোর দেয়, কেন্দ্রীয় সম্পদ এবং ইঞ্জিনিয়ারিং অপ্টিমাইজেশনের মাধ্যমে নিয়ন্ত্রিত এবং পরিপক্ক সেবা অভিজ্ঞতা প্রদান করে; অন্যদিকে, Web3 মডেলটি খোলামেলা প্রকৃতি এবং উৎসাহীকরণ ব্যবস্থাকে বেশি গুরুত্ব দেয়, বহুপক্ষীয় অংশগ্রহণকে অন্তর্ভুক্ত করে মডেল অপ্টিমাইজেশনকে প্রতিযোগিতার মধ্যে ধারাবাহিকভাবে উন্নতির দিকে নিয়ে যায়। বিশদভাবে দেখলে, Web2 AutoML বেশি একটি “শক্তিশালী টুল”-এর মতো, যেখানে ব্যবহারকারীরা কাজটি প্ল্যাটফর্মকে দিয়ে দেন, এবং সিস্টেমটি অভ্যন্তরীণভাবে সর্বোত্তম সমাধানটি খুঁজে বার করে; অন্যদিকে, Gradients-এর মতো Web3 AutoML, একটি “খোলা বাজার”-এর মতো, যেখানে ব্যবহারকারীরা প্রয়োজনীয়তা প্রকাশ করে, এবং বিভিন্ন অংশগ্রহণকারীরা সমাধানগুলি প্রদান করে, তারপর মূল্যায়ন ব্যবস্থার মাধ্যমে ফলাফলগুলির মধ্যে বাছাই করা হয়। এই পার্থক্যটির প্রত্যক্ষ প্রভাবটি:前者更稳定、可控,但优化路径有限;后者探索空间更大,潜在上限更高,但在稳定性与成熟度上仍有提升空间।
6.3 ওয়েব ৩-এ গ্রেডিয়েন্টসের পার্থক্য
বর্তমান ওয়েব৩ এআই ক্ষেত্রে, বেশিরভাগ প্রকল্প এখনও ইনফারেন্স লেয়ার বা এআই এজেন্ট দিকে কেন্দ্রীভূত, যেখানে “ট্রেনিং ইনফ্রাস্ট্রাকচার”-এ ফোকাস করা প্রকল্পগুলি তুলনামূলকভাবে কম। কিছু প্রকল্প ক্যালকুলেশন নেটওয়ার্ক বা ডেটা নেটওয়ার্কের সাথে একীভূত হয়ে ট্রেনিং ক্ষমতা প্রদানের চেষ্টা করছে, তবে সামগ্রিকভাবে, বেশিরভাগই এখনও সম্পদ সুসংগঠন বা ক্যালকুলেশন মার্কেটের মাত্রা পর্যন্তই সীমাবদ্ধ। Gradients-এর পার্থক্য হলো, এটি শুধুমাত্র ক্যালকুলেশন ম্যাচমেকিং প্রদান করে না, বরং “মডেল অপটিমাইজেশন মেকানিজম”-এর দিকেও উপরের দিকে বিস্তৃত, মূল্যায়ন এবং প্রতিযোগিতা ব্যবস্থা চালু করে, যাতে ট্রেনিং প্রক্রিয়াটির ধারাবাহিকভাবে উন্নয়নের ক্ষমতা থাকে। এর অর্থ, এটি “ক্যালকুলেশনটি কোথা থেকে আসছে”-এর সমস্যা সমাধানের পাশাপাশি “এই ক্যালকুলেশনগুলির সবচেয়ে দক্ষতার সাথে”-এরও সমস্যা সমাধান করছে। Gradients-এর অবস্থানটি, “ট্রেনিং-ফলাফল-অরিয়েন্টেড” নেটওয়ার্ক-এর সমীপবর্তী, ১০০%ই “ক্যালকুলেশন মার্কেট” বা “টুলসপ্ল্যাটফর্ম”-এর মতো, ।
6.4 মূল সুবিধা: মেকানিজম-চালিত দক্ষতা বৃদ্ধি
সামগ্রিকভাবে, গ্রেডিয়েন্টসের সুবিধাগুলি মূলত এর মেকানিজম ডিজাইনে প্রকাশ পায়। প্রথমত, এটি টাস্ক অ্যাবস্ট্রাকশনের মাধ্যমে ব্যবহারের বাধা কমিয়ে দেয়, যার ফলে ব্যবহারকারীদের জটিল ট্রেনিং প্রক্রিয়ায় গভীরভাবে জড়িয়ে পড়ার প্রয়োজন ছাড়াই মডেলের ফলাফল পাওয়া যায়, যা সম্ভাব্য ব্যবহারকারীদের সংখ্যা বাড়ায়। দ্বিতীয়ত, সম্পদের দিক থেকে, ডিস্ট্রিবিউটেড কম্পিউটিং ক্ষমতার প্রবর্তনের ফলে ট্রেনিং একক ক্লাউড প্রোভাইডারের উপর নির্ভরশীল হয়ে পড়েনি, এবং তত্ত্বগতভাবে প্রতিযোগিতার মাধ্যমে আরও নমনীয় খরচের কাঠামো গড়ে তোলা সম্ভব। এরচেয়েও গুরুত্বপূর্ণ, এটির অপটিমাইজেশনের পদ্ধতির পরিবর্তন। একাধিক অংশগ্রহণকারীদের সম song-সময়িকভাবে অনুসন্ধানের সঙ্গে ফিল্টারিং মেকানিজমকে একীভূত করে, Gradients একটি ঐতিহ্যগত একক-পথ অপটিমাইজেশনের থেকে ভিন্ন একটি সমাধান প্রদান করে, যা মডেলকে কম সময়ের মধ্যেই উৎকৃষ্টতর কর্মক্ষমতা অর্জনের সুযোগ দেয়। “প্রতিযোগিতা-চালিত অপটিমাইজেশন”-এর এই মডেলটিই এর সবচেয়ে গুরুত্বপূর্ণ সুবিধা।
6.5 সম্ভাব্য চ্যালেঞ্জ
মডেলের গুণগত স্থিতিশীলতার সমস্যা থাকতে পারে। ডিসেন্ট্রালাইজড ট্রেনিংয়ে অনেকগুলি পক্ষের অংশগ্রহণ প্রয়োজন, যা সীমানা বাড়াতে পারে, কিন্তু ফলাফলের ওঠানামা সৃষ্টি করতে পারে, কেন্দ্রীয় ব্যবস্থার তুলনায় নিয়ন্ত্রণে কিছুটা অনিশ্চয়তা রয়েছে। দ্বিতীয়ত, এন্টারপ্রাইজ-লেভেল বিশ্বাসের সমস্যা। এন্টারপ্রাইজ ব্যবহারকারীদের জন্য, ডেটা নিরাপত্তা এবং ট্রেনিং প্রক্রিয়ার যাচাইযোগ্যতা অত্যন্ত গুরুত্বপূর্ণ, এবং ডিসেন্ট্রালাইজড পরিবেশে ডেটা দুর্ব্যবহার থেকে রক্ষা করা এবং ফলাফলগুলির অডিটযোগ্যতা নিশ্চিত করা এখনও একটি প্রধান চ্যালেঞ্জ। শেষ করে, টোকেন অর্থনীতির উপর নির্ভরশীলতা। Gradients-এর কার্যকলাপ উদ্দীপনা ব্যবস্থার উপর অত্যন্ত নির্ভরশীল; TAO-এর আয়ের吸引力 কমে গেলে, মাইনারদের অংশগ্রহণ এবং সমগ্র নেটওয়ার্কের সক্রিয়তা প্রভাবিত হতে পারে। তাই, এর দীর্ঘমেয়াদি টেকসইতা কিছুটা এই অর্থনৈতিক মডেলটির উপর নির্ভরশীল, যা একটি স্থিতিশীল, ইতিবাচক-চক্র (positive cycle) গঠন করতে পারে।
7. ভবিষ্যৎ পরিকল্পনা: ডিসেন্ট্রালাইজড AutoML কি সম্ভব হবে?
বর্তমান পর্যায়ে, Gradients এখনও প্রাথমিক অবস্থায় রয়েছে, এবং এর ভবিষ্যতের সফলতা কয়েকটি কী বিষয়ের উপর নির্ভর করে। সবচেয়ে গুরুত্বপূর্ণ হলো প্রেরণামূলক অংশগ্রহণের পরিবর্তে বাস্তব প্রশিক্ষণ চাহিদা আকর্ষণ করা যাচ্ছে কিনা; এরপর মডেলের গুণগত মান, যেমন কেন্দ্রীয়করণহীন পদ্ধতি স্থিতিশীলভাবে ব্যবহারযোগ্য, এমনকি উন্নত ফলাফল উৎপাদন করতে পারে কিনা; এবং অর্থনৈতিক কাঠামোটি কি একটি ইতিবাচক চক্র গঠন করতে পারবে, যাতে ক্যালকুলেশন সরবরাহ এবং আয়ের মধ্যে দীর্ঘমেয়াদী ভারসাম্য বজায় থাকে।
বড় শিল্পের প্রেক্ষাপটে, এআই প্রশিক্ষণ দুটি পথে বিভক্ত হচ্ছে। একটি হল Web2 মডেল, যা শীর্ষ প্রযুক্তি কোম্পানিগুলি দ্বারা নিয়ন্ত্রিত এবং কেন্দ্রীয় সম্পদ এবং ইঞ্জিনিয়ারিং ক্ষমতার মাধ্যমে মডেলের কার্যকারিতা বাড়ানো হয়, এর সুবিধা হল স্থিতিশীলতা এবং পরিপক্কতা; অন্যটি হল Gradients-এর মতো Web3 পথ, যা খোলা নেটওয়ার্ক এবং উদ্দীপনার মাধ্যমে আরও বেশি অংশগ্রহণকারীকে মডেল অপ্টিমাইজেশনে অংশগ্রহণের জন্য অনুপ্রাণিত করে, প্রতিযোগিতার মধ্যে ধারাবাহিকভাবে সীমানা বাড়ায়। প্রথমটি “একটি শক্তিশালী সিস্টেম তৈরি” করছে, অন্যটি “একটি নিজেকে উন্নত করতে পারে এমন নেটওয়ার্ক” গড়ে তুলছে।
এই দৃষ্টিকোণ থেকে, Gradients-এর অন্বেষণ একটি নতুন সম্ভাবনার প্রতিনিধিত্ব করে: AI প্রশিক্ষণ এখন শুধুমাত্র একটি প্রযুক্তিগত সমস্যা নয়, বরং “ক্ষমতা + ডেটা + বাজার প্রক্রিয়া”-এর সমন্বয়। যদি এই মডেলটি কার্যকর হয়, তবে এটি ডিসেন্ট্রালাইজড AI-এর প্রশিক্ষণের একটি প্রবেশদ্বার হিসাবে কাজ করতে পারে এবং Bittensor ইকোসিস্টেমে একটি মৌলিক অবকাঠামোর ভূমিকা পালন করতে পারে। অবশ্যই, এই দিকটি যাচাইয়ের জন্য সময়ের প্রয়োজন, তবে এটি AutoML-এর জন্য একটি পারম্পরিক পথের বিপরীতে একটি বিকাশের দিশা প্রদান করেছে।
প্রসঙ্গ
1. বিটটেনসর ডকুমেন্টেশন:https://docs.learnbittensor.org
2. গ্রেডিয়েন্টস ওয়েবসাইট:https://www.gradients.io/
3. গ্রেডিয়েন্টস:https://bittensormarketcap.com/subnets/56
4. গ্রেডিয়েন্টস এক্স: https://x.com/gradients_ai
5. টাওস্ট্যাটস:https://taostats.io/subnets/56/chart